

Fonte do artigo | Equipe de criação inteligente da ByteDance
Temos o prazer de compartilhar com vocês nosso mais recente modelo gráfico vicentino, SDXL-Lightning, que atinge velocidade e qualidade sem precedentes e agora está disponível para a comunidade.
Modelo: https://huggingface.co/ByteDance/SDXL-Lightning
Artigo: https://arxiv.org/abs/2402.13929

Geração de imagens extremamente rápida
A IA generativa está ganhando atenção global por sua capacidade de criar imagens impressionantes e até vídeos com base em instruções de texto. No entanto, os atuais modelos generativos de última geração dependem da difusão, um processo iterativo que transforma gradualmente o ruído em amostras de imagens. Este processo requer enormes recursos computacionais e é lento. No processo de geração de amostras de imagens de alta qualidade, o tempo de processamento de uma única imagem é de cerca de 5 segundos, o que geralmente requer múltiplas chamadas (20 a 40 vezes) para uma enorme rede neural. . Essa velocidade limita os cenários de aplicação que exigem geração rápida e em tempo real. Como acelerar a geração e ao mesmo tempo melhorar a qualidade é uma área importante da pesquisa atual e o objetivo central do nosso trabalho.
SDXL-Lightning rompe esta barreira através de uma tecnologia inovadora - Destilação Adversarial Progressiva - para atingir velocidades de geração sem precedentes. O modelo é capaz de gerar imagens de altíssima qualidade e resolução em apenas 2 ou 4 etapas, reduzindo o custo e o tempo computacional por um fator de dez. Nosso método pode até gerar imagens em uma única etapa para aplicativos sensíveis ao tempo limite, embora alguma qualidade possa ser ligeiramente sacrificada.
Além da vantagem de velocidade, o SDXL-Lightning também oferece desempenho significativo em qualidade de imagem e supera tecnologias de aceleração anteriores em avaliações. Obtenha maior resolução e melhores detalhes, mantendo uma boa diversidade e correspondência entre imagem e texto.
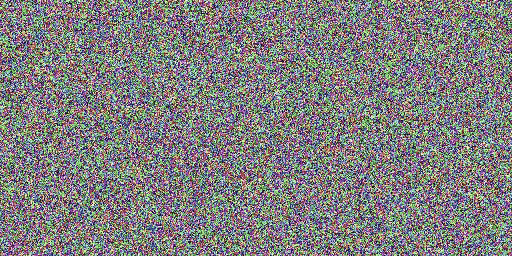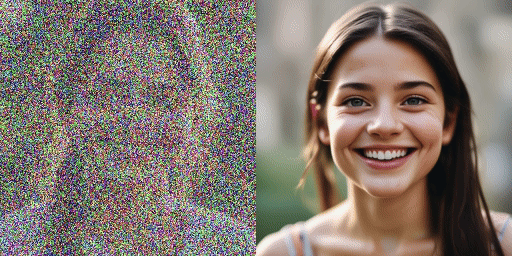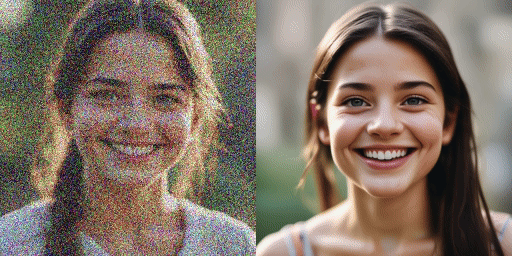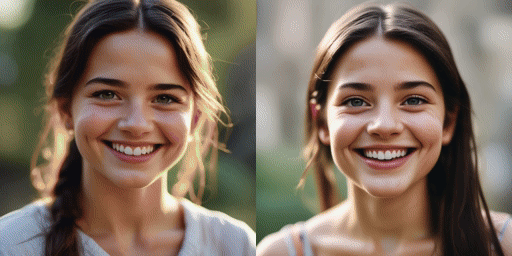 comparação de velocidade
comparação de velocidade
Modelo original (20 passos), nosso modelo (2 passos)
Efeito modelo
Nosso modelo pode gerar imagens em 1 etapa, 2 etapas, 4 etapas e 8 etapas. Quanto mais etapas de inferência houver, melhor será a qualidade da imagem.
Aqui estão os resultados do nosso processo de 4 etapas:
Aqui estão os resultados de nossa construção em duas etapas:
Comparado aos métodos anteriores (Turbo e LCM), nosso método gera imagens significativamente melhoradas em detalhes e mais fiéis ao estilo e layout do modelo generativo original.

Retribua à comunidade, modelo aberto
A onda do código aberto tornou-se uma força chave na promoção do rápido desenvolvimento da inteligência artificial, e a ByteDance tem orgulho de fazer parte desta onda. Nosso modelo é baseado em SDXL, atualmente o modelo aberto mais popular para geração de imagens de texto, que já possui um ecossistema próspero. Agora, decidimos abrir o SDXL-Lightning para desenvolvedores, pesquisadores e profissionais criativos em todo o mundo para que possam acessar e aplicar este modelo para promover ainda mais a inovação e a colaboração em toda a indústria.
Ao projetar o SDXL-Lightning, consideramos a compatibilidade com a comunidade de modelos abertos. Muitos artistas e desenvolvedores da comunidade criaram uma variedade de modelos estilizados de geração de imagens, como estilos de desenho animado e anime. Para oferecer suporte a esses modelos, fornecemos o SDXL-Lightning como um plug-in de aceleração, que pode ser perfeitamente integrado a esses vários estilos de modelos SDXL para acelerar a geração de imagens para vários modelos.
 Nosso modelo também pode ser combinado com o plug-in de controle ControlNet, atualmente muito popular, para obter geração de imagens extremamente rápida e controlável.
Nosso modelo também pode ser combinado com o plug-in de controle ControlNet, atualmente muito popular, para obter geração de imagens extremamente rápida e controlável.
 Nosso modelo também suporta ComfyUI, atualmente o software de geração mais popular na comunidade de código aberto, e o modelo pode ser carregado diretamente para uso:
Nosso modelo também suporta ComfyUI, atualmente o software de geração mais popular na comunidade de código aberto, e o modelo pode ser carregado diretamente para uso: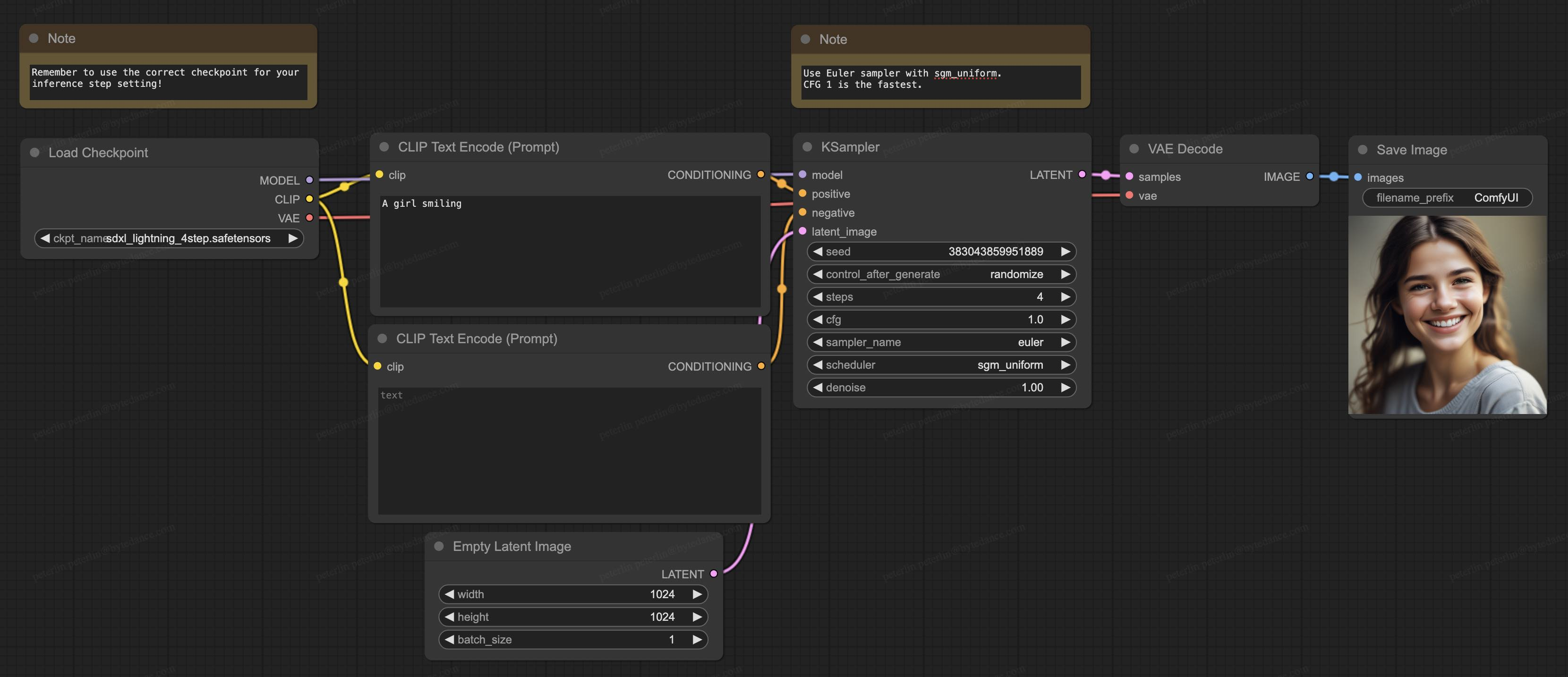
Sobre detalhes técnicos
Teoricamente, a geração de imagens é um processo passo a passo de transformação de ruído em imagens nítidas. Nesse processo, a rede neural aprende os gradientes em diversas posições do fluxo de transformação.
As etapas específicas para gerar uma imagem são as seguintes: primeiro, amostramos aleatoriamente uma amostra de ruído no ponto inicial do fluxo e, em seguida, usamos uma rede neural para calcular o gradiente. Com base no gradiente na posição atual, fazemos pequenos ajustes na amostra e depois repetimos o processo. A cada iteração, as amostras se aproximam da distribuição final da imagem até que uma imagem nítida seja obtida.
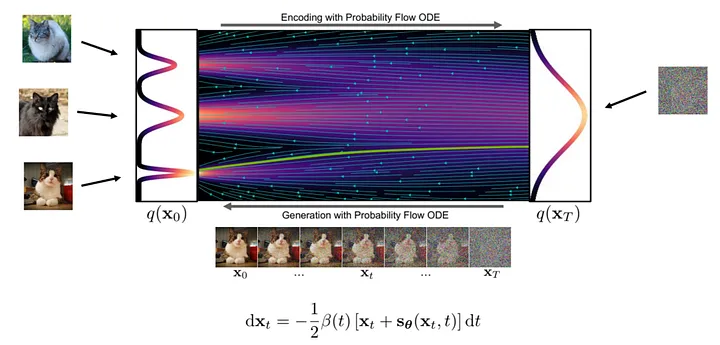 Figura: Processo de geração ( foto de : https://arxiv.org/abs/2011.13456 )
Figura: Processo de geração ( foto de : https://arxiv.org/abs/2011.13456 )
Como o fluxo de geração é complexo e não linear, o processo de geração deve dar apenas um pequeno passo de cada vez para reduzir o acúmulo de erros de gradiente, por isso são necessários cálculos frequentes da rede neural, razão pela qual a quantidade de cálculo é grande.
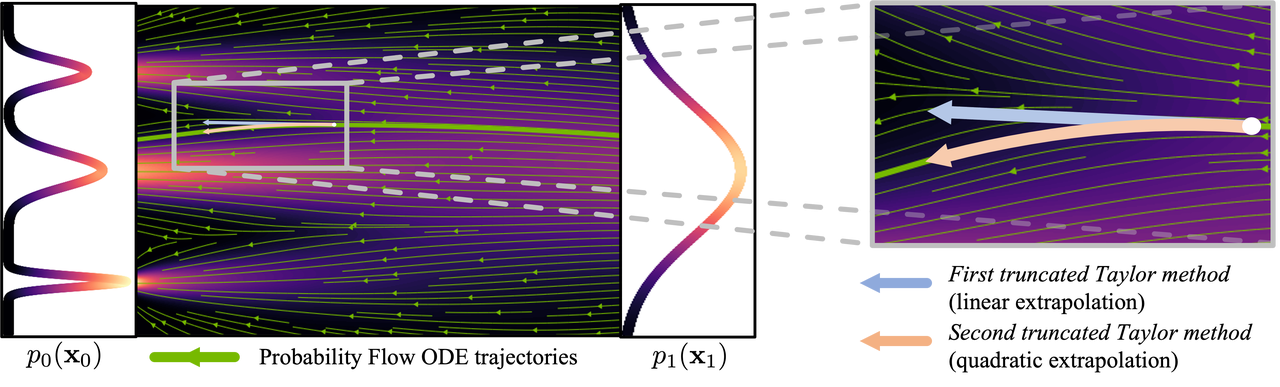 Figura: Processo de curva ( imagem de : https://arxiv.org/abs/2210.05475 )
Figura: Processo de curva ( imagem de : https://arxiv.org/abs/2210.05475 )
A fim de reduzir o número de etapas necessárias para gerar imagens, muitas pesquisas têm sido dedicadas à busca de soluções. Alguns estudos propõem métodos de amostragem que reduzem erros, enquanto outros tentam tornar o fluxo gerado mais linear. Apesar dos avanços nestes métodos, eles ainda requerem mais de 10 etapas de inferência para gerar imagens.
Outro método é a destilação de modelo, capaz de gerar imagens de alta qualidade em menos de 10 etapas de inferência. Em vez de calcular o gradiente na posição de fluxo atual, a destilação do modelo altera o alvo da previsão do modelo para prever diretamente a próxima posição de fluxo mais distante. Especificamente, treinamos uma rede de alunos para prever diretamente o resultado da rede de professores após concluir o raciocínio em várias etapas. Tal estratégia pode reduzir significativamente o número de etapas de inferência necessárias. Ao aplicar este processo repetidamente, podemos reduzir ainda mais o número de etapas de inferência. Esta abordagem foi chamada de destilação progressiva por pesquisas anteriores.
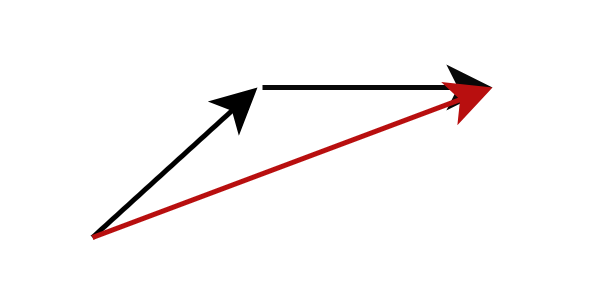 Figura: Destilação progressiva , a rede do aluno prevê o resultado da rede do professor após várias etapas
Figura: Destilação progressiva , a rede do aluno prevê o resultado da rede do professor após várias etapas
Na prática, as redes de estudantes muitas vezes têm dificuldade em prever com precisão as posições futuras dos fluxos. O erro aumenta à medida que cada etapa se acumula, fazendo com que as imagens produzidas pelo modelo comecem a ficar borradas com menos de 8 etapas de inferência.
Para resolver este problema, a nossa estratégia não é forçar a rede de alunos a corresponder exactamente às previsões da rede de professores, mas sim tornar a rede de alunos consistente com a rede de professores em termos de distribuição de probabilidade. Em outras palavras, a rede estudantil é treinada para prever uma localização probabilisticamente possível e, mesmo que essa localização não seja totalmente precisa, não a penalizamos. Este objetivo é alcançado através do treinamento contraditório, que introduz uma rede discriminativa adicional para ajudar a alcançar a correspondência de distribuição dos resultados da rede de alunos e professores.
Esta é uma breve visão geral de nossos métodos de pesquisa. Em nosso artigo técnico ( https://arxiv.org/abs/2402.13929 ), fornecemos uma análise teórica mais aprofundada, estratégia de treinamento e detalhes específicos da formulação do modelo.
Além do SDXL-Lightning
Embora este estudo explore principalmente como usar a tecnologia SDXL-Lightning para geração de imagens, o potencial de aplicação do nosso método de destilação adversária progressiva proposto não se limita a imagens estáticas. Esta tecnologia inovadora também pode ser usada para gerar vídeo, áudio e outros conteúdos multimodais de forma rápida e com alta qualidade. Sinceramente, convidamos você a experimentar o SDXL-Lightning na plataforma HuggingFace e aguardamos seus valiosos comentários e feedback.
Modelo: https://huggingface.co/ByteDance/SDXL-Lightning
Artigo: https://arxiv.org/abs/2402.13929
Companheiro de frango, deepin-IDE de "código aberto" e finalmente conseguiu a inicialização! Bom cara, a Tencent realmente transformou o Switch em uma "máquina de aprendizagem pensante" Revisão de falhas e explicação da situação da Tencent Cloud em 8 de abril Reconstrução de inicialização de desktop remoto RustDesk Cliente Web Banco de dados de terminal de código aberto do WeChat baseado em SQLite WCDB inaugurou uma grande atualização Lista de abril TIOBE: PHP caiu para o nível mais baixo, Fabrice Bellard, o pai do FFmpeg, lançou a ferramenta de compressão de áudio TSAC , o Google lançou um grande modelo de código, CodeGemma , isso vai te matar? É tão bom que é de código aberto - ferramenta de edição de imagens e pôsteres de código aberto