

O paradigma de geração visual da nova geração "VAR: Visual Auto Regressive" está aqui! O modelo autoregressivo estilo GPT supera pela primeira vez o modelo de difusão na geração de imagens , e a lei de escala das Leis de Escala e a capacidade de generalização de Generalização de Tarefa Zero-shot semelhantes ao modelo de linguagem grande são observadas :
论文标题:Modelagem visual autorregressiva: geração de imagem escalonável por meio de previsão de próxima escala
Este novo trabalho chamado VAR foi proposto por pesquisadores da Universidade de Pequim e da ByteDance . Ele está nas listas de favoritos do GitHub e do Paperwithcode e tem recebido muita atenção de colegas:
Atualmente, o site da experiência, documentos, códigos e modelos foram lançados:
- Site de experiência: https://var.vision/
- Link do artigo: https://arxiv.org/abs/2404.02905
- Código-fonte aberto: https://github.com/FoundationVision/VAR
- Modelo de código aberto: https://huggingface.co/FoundationVision/var
Introdução ao histórico
No processamento de linguagem natural, o modelo autoregressivo autoregressivo, tomando como exemplos grandes modelos de linguagem, como as séries GPT e LLaMa, obteve grande sucesso. Em particular, a lei de escalonamento da Lei de Escala e a Generalização de Tarefas Zero-shot têm uma generalização de tarefas zero-shot muito impressionante. capacidades, inicialmente mostrando o potencial para levar à "inteligência artificial geral AGI".
No entanto, no campo da geração de imagens, os modelos autorregressivos geralmente ficam atrás dos modelos de difusão: DALL-E3, Difusão Estável3, SORA e outros modelos que se tornaram populares recentemente, todos pertencem à família Difusão. Além disso, ainda não se sabe se existe uma "Lei de Escala" no campo da geração visual , ou seja, se a perda de entropia cruzada do conjunto de teste pode mostrar uma tendência previsível de queda da lei de potência com modelo ou sobrecarga de treinamento permanece para ser explorado.
As poderosas capacidades e a Lei de Escala do modelo autorregressivo formal GPT parecem estar "bloqueadas" no campo de geração de imagens:

O modelo autorregressivo fica atrás de muitos modelos de difusão na lista de efeitos de geração
Com foco em "desbloquear" a capacidade dos modelos autorregressivos e das leis de escala, a equipe de pesquisa partiu da natureza inerente das modalidades de imagem, imitou a sequência lógica do processamento humano de imagens e propôs um novo paradigma de geração "autoregressivo visual": VAR, Visual AutoRegressive Modelagem, pela primeira vez, a geração visual autorregressiva no estilo GPT supera a Difusão em termos de efeito, velocidade e capacidades de escala, e inaugurou Leis de Escala no campo da geração visual:

O núcleo do método VAR: imitar a visão humana e redefinir a sequência autoregressiva da imagem
Quando os humanos percebem imagens ou pinturas, eles tendem a obter primeiro uma visão geral e depois se aprofundar nos detalhes. Esse tipo de pensamento do grosseiro ao fino, da compreensão do todo ao ajuste fino da parte é muito natural:
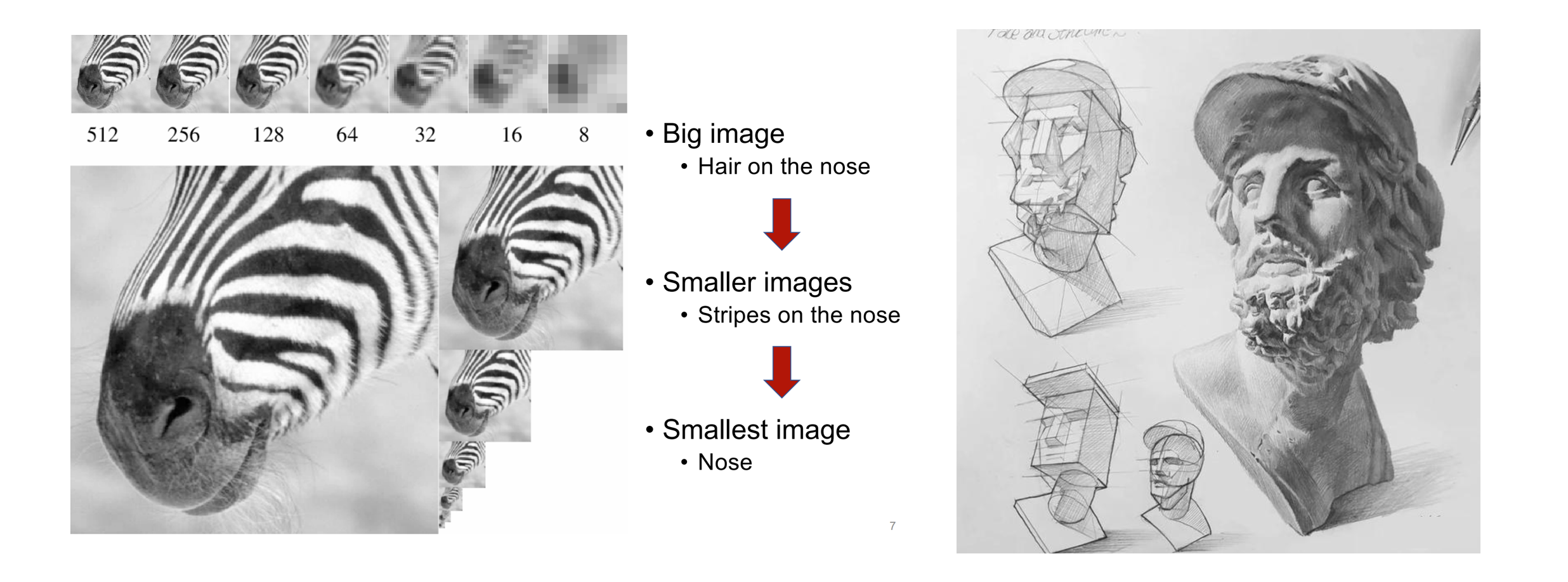
A sequência lógica do grosseiro ao fino da percepção humana de imagens (esquerda) e criação de pinturas (direita)
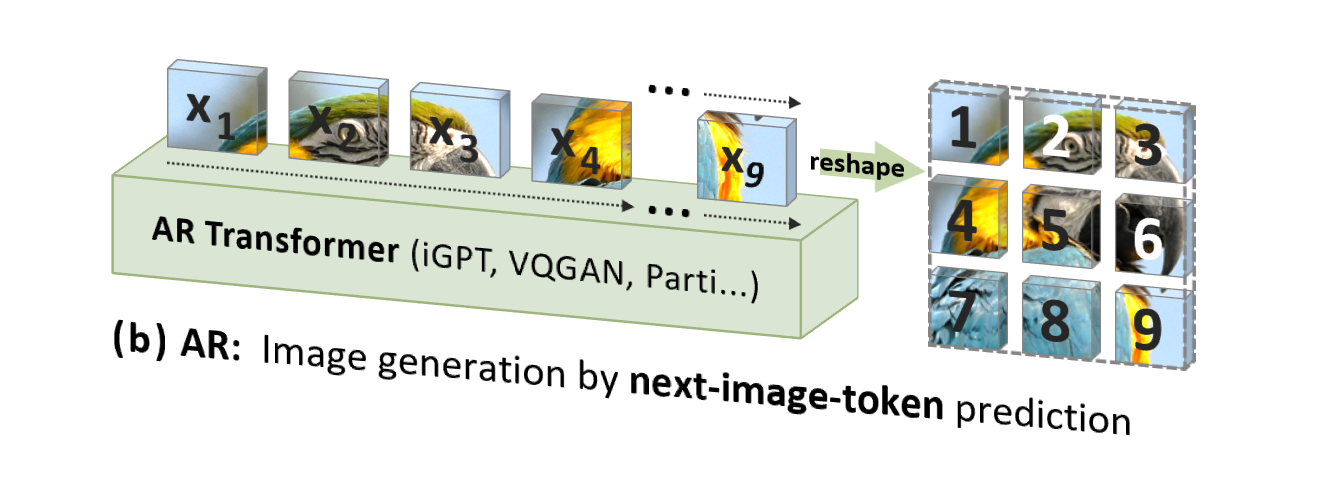
No entanto, a autorregressão de imagem tradicional (AR) usa uma ordem que não está de acordo com a intuição humana (mas adequada para processamento de computador), ou seja, uma ordem raster linha por linha de cima para baixo, para prever tokens de imagem um por um :
VAR é "orientado para as pessoas", imitando a sequência lógica da percepção humana ou imagens criadas pelo homem , e gera gradualmente um mapa de tokens usando uma sequência em várias escalas do todo aos detalhes:
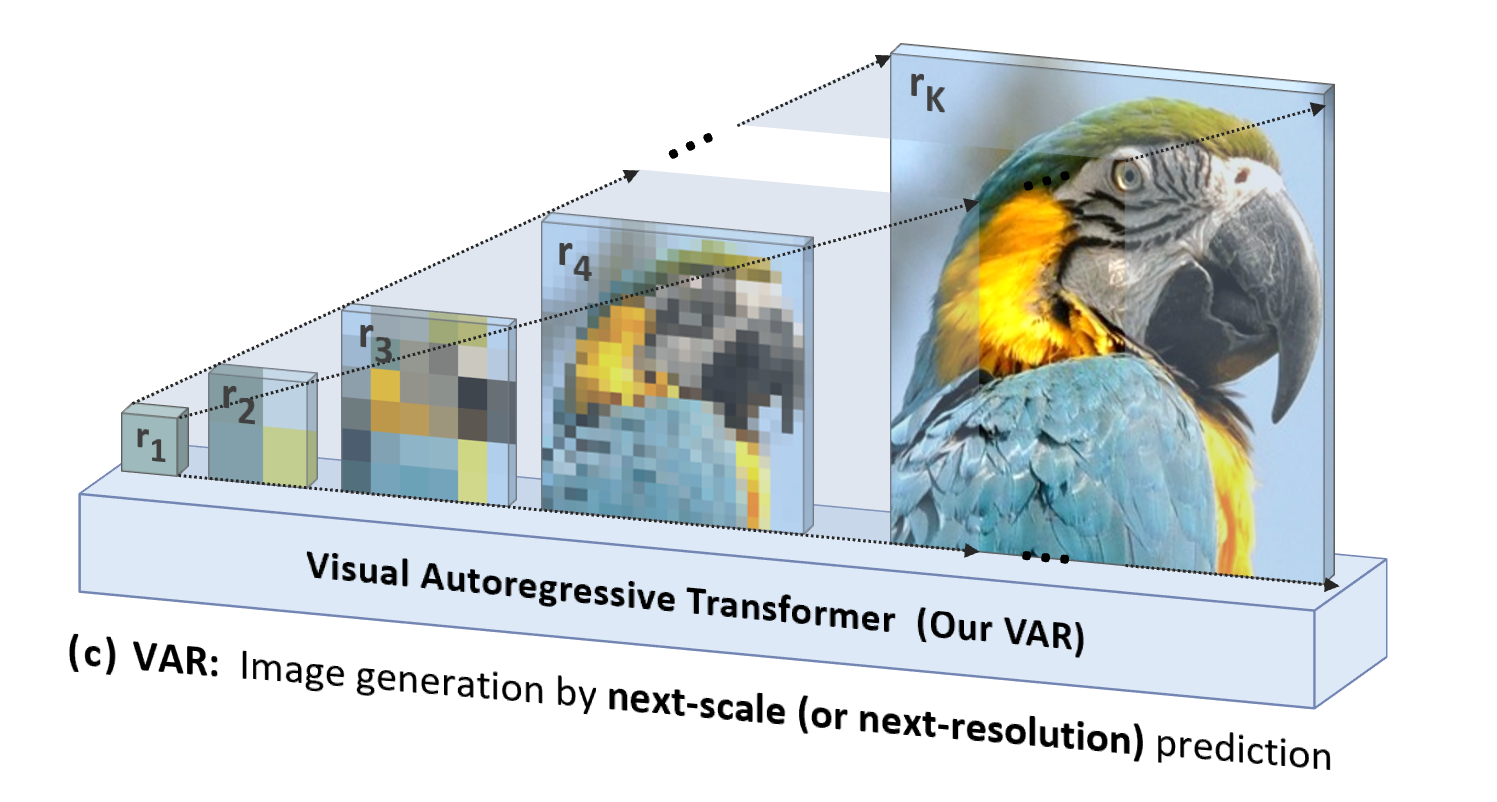
Além de ser mais natural e alinhado à intuição humana, outra vantagem significativa trazida pelo VAR é que ele aumenta muito a velocidade de geração: a cada passo da autorregressão (dentro de cada escala), todos os tokens de imagem são gerados em paralelo ao mesmo tempo; escalas É autoregressivo. Isso torna o VAR dezenas de vezes mais rápido que o AR tradicional quando os parâmetros do modelo e os tamanhos das imagens são equivalentes. Além disso, no experimento, o autor também observou que o VAR apresenta desempenho e capacidade de escala mais fortes do que o AR.
Detalhes do método VAR: treinamento em duas etapas
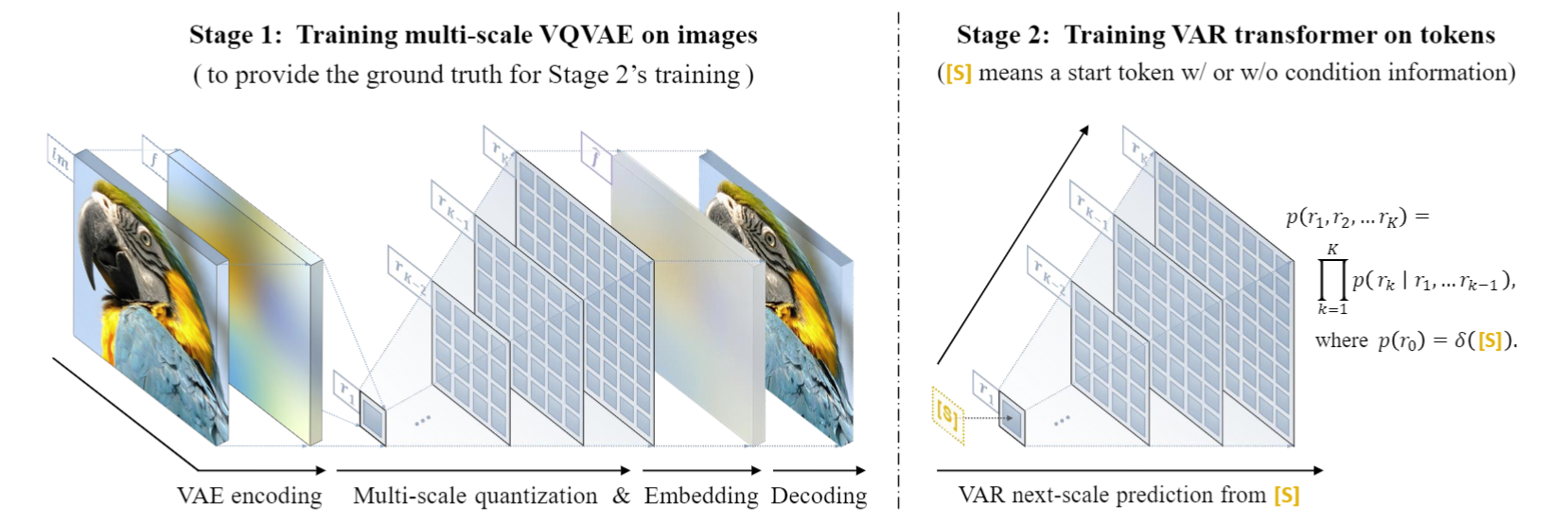
VAR treina um autoencoder de quantização multiescala (VQVAE multiescala) no primeiro estágio e treina um transformador autorregressivo consistente com a estrutura GPT-2 (combinado com AdaLN) no segundo estágio.
Conforme mostrado na imagem à esquerda, os detalhes do prequel de treinamento do VQVAE são os seguintes:
- Codificação discreta : o codificador converte a imagem em um mapa de token discreto R = (r1, r2, ..., rk), com resoluções de pequeno a grande
- Continuação : r1 a rk são primeiro convertidos em mapas de recursos contínuos através da camada de incorporação, depois interpolados uniformemente para a resolução máxima correspondente a rk e somados
- Decodificação contínua : O mapa de características somado passa pelo decodificador para obter a imagem reconstruída e é treinado por meio de uma mistura de três perdas: reconstrução + percepção + confronto.
Conforme mostrado na figura à direita, após a conclusão do treinamento VQVAE, será realizada a segunda etapa do treinamento autorregressivo do Transformer:
- A primeira etapa da autorregressão é prever o mapa de token 1x1 inicial a partir do token **** inicial [S]
- Em cada etapa subsequente, o VAR prevê o próximo mapa de tokens de maior escala com base em todos os mapas de tokens históricos .
- Durante a fase de treinamento, o VAR usa perda de entropia cruzada padrão para supervisionar a previsão de probabilidade desses mapas de tokens.
- Na fase de teste, o mapa de token amostrado será serializado, interpolado, somado e decodificado com a ajuda do decodificador VQVAE para obter a imagem final gerada.
O autor disse que a estrutura autoregressiva do VAR é totalmente nova e a tecnologia específica absorveu os pontos fortes de uma série de tecnologias clássicas, como o VAE residual do RQ-VAE, o AdaLN do StyleGAN e DiT e o treinamento progressivo do PGGAN. O VAR, na verdade, está sobre os ombros de gigantes e se concentra na inovação do próprio algoritmo autorregressivo.
Comparação de efeitos experimentais
Experimentos VAR em Conditional ImageNet 256x256 e 512x512:
- O VAR melhorou muito o efeito do AR, fazendo com que o AR ficasse atrás do Diffusion .
- O VAR requer apenas 10 etapas autoregressivas e sua velocidade de geração excede em muito o AR e a difusão, e até se aproxima da eficiência do GAN.
- Ao aumentar o VAR para 2B/3B , o VAR atingiu o nível SOTA, mostrando uma nova e potencial família de modelos generativos.

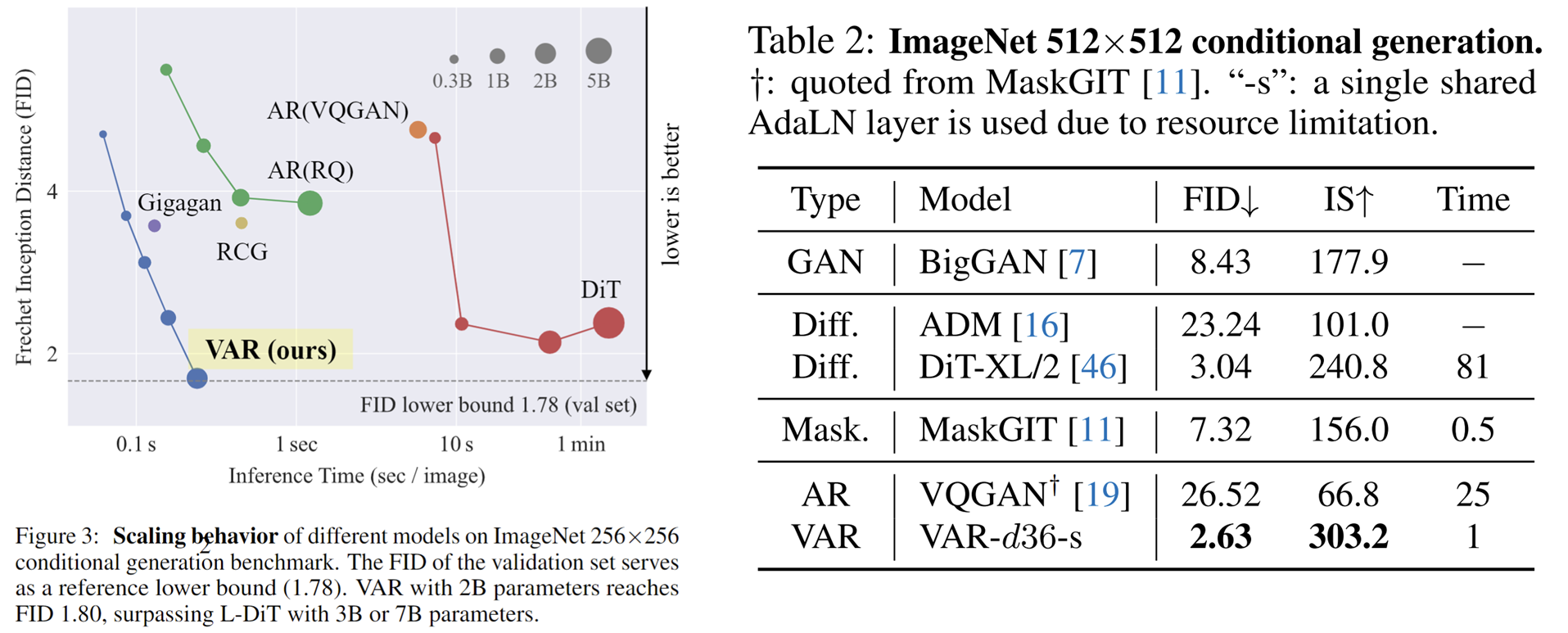
O que é interessante é que, comparado com SORA e Diffusion Transformer (DiT), o modelo fundamental do Stable Diffusion 3 , o VAR mostra:
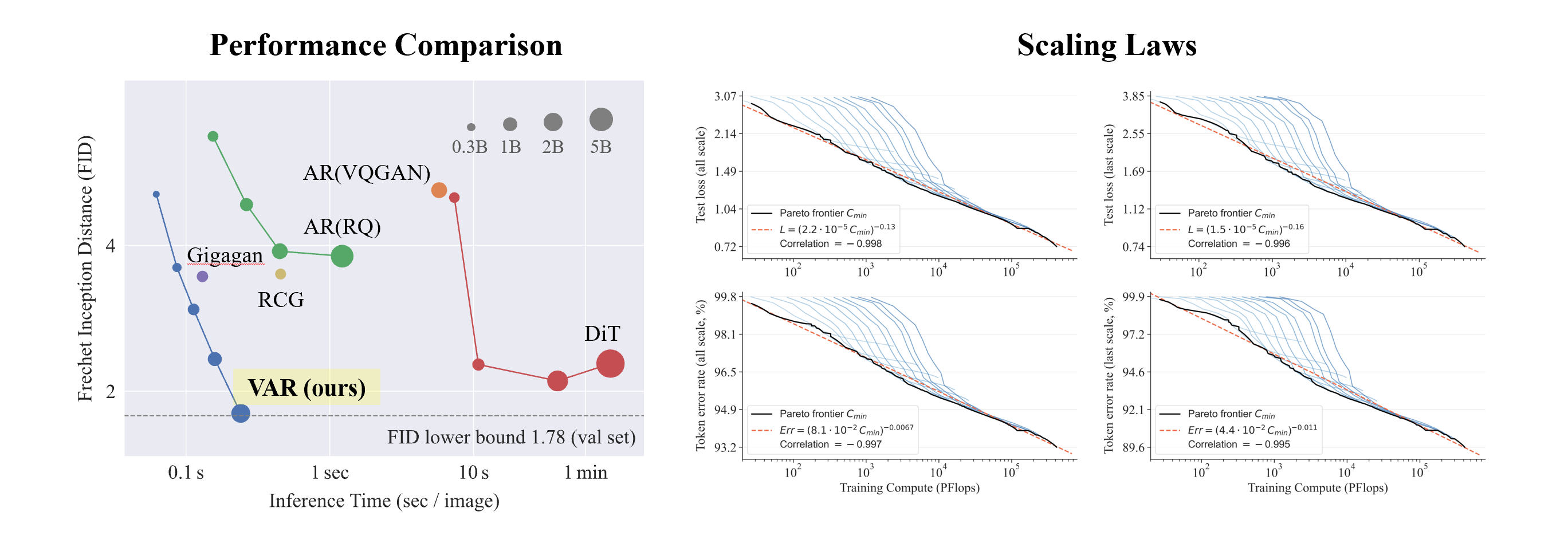
- Melhores resultados : Após a ampliação , o VAR finalmente atingiu FID = 1,80, aproximando-se do limite inferior teórico do FID de 1,78 (conjunto de validação ImageNet), significativamente melhor do que o ideal de 2,10 do DiT
- Velocidade mais rápida : VAR pode gerar uma imagem 256 em menos de 0,3 segundos , o que é 45 vezes mais rápido que DiT em 512, é 81 vezes mais rápido que DiT;
- Melhores capacidades de escalonamento: conforme mostrado na figura à esquerda, o modelo grande do DiT mostrou saturação após crescer para 3B e 7B e não conseguiu se aproximar do limite inferior do FID enquanto o VAR foi dimensionado para 2 bilhões de parâmetros, seu desempenho continuou a melhorar e; finalmente tocou o limite inferior do FID
- Utilização de dados mais eficiente : o VAR requer apenas um treinamento de 350 épocas, que é mais do que o treinamento de 1400 épocas do DiT.
Estas evidências de que é mais eficiente, mais rápido e mais escalável que o DiT trazem mais possibilidades para a próxima geração de caminhos de infraestrutura de geração visual.
Experimento de lei de escala
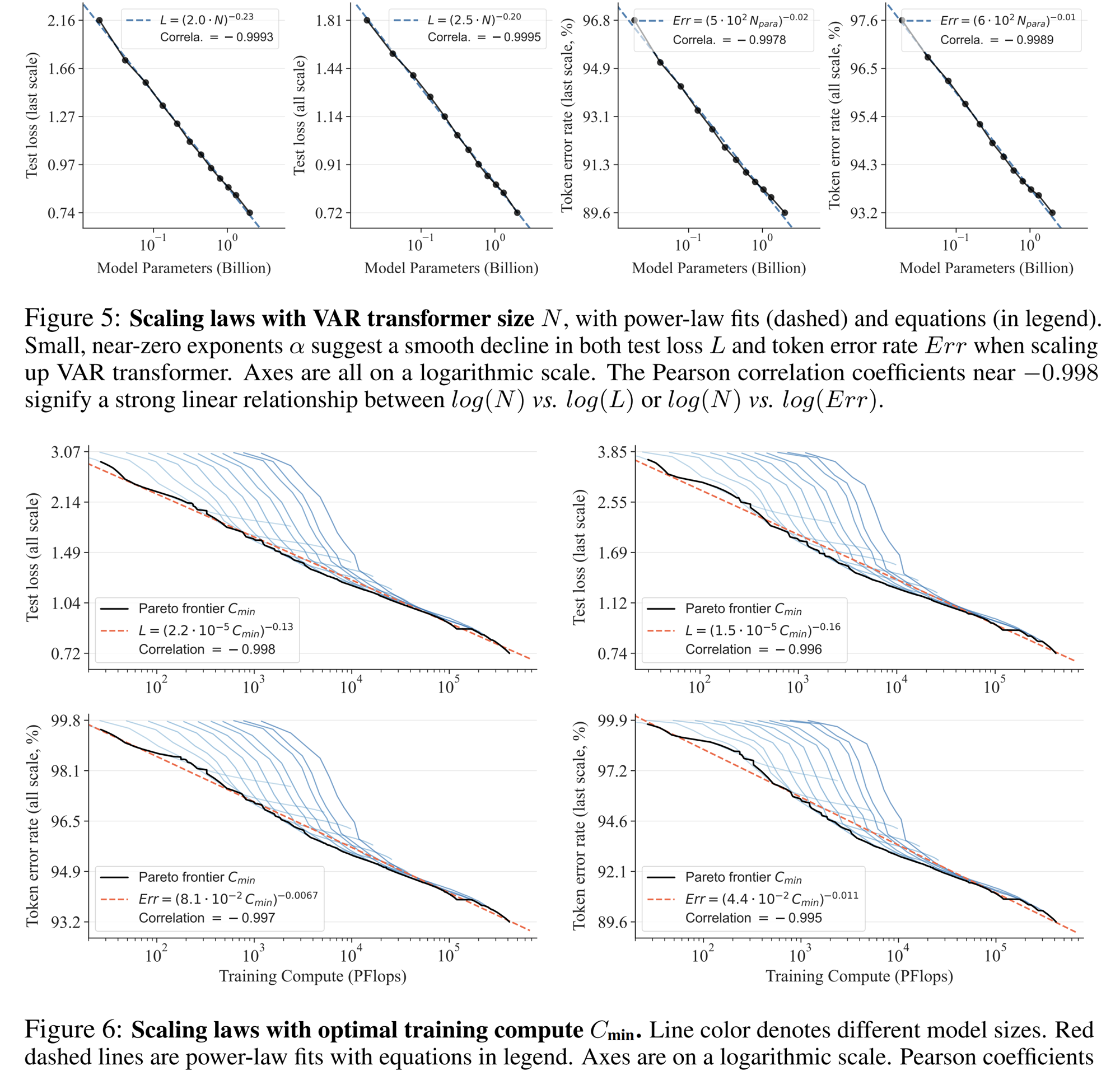
A lei de escala pode ser descrita como a "jóia da coroa" dos grandes modelos de linguagem. Pesquisas relevantes determinaram que, no processo de ampliação de modelos de linguagem autoregressivos em grande escala, a perda de entropia cruzada L no conjunto de teste diminuirá previsivelmente com o número de parâmetros do modelo N, o número de tokens de treinamento T e a sobrecarga computacional Cmin . Exponha a relação poder-lei.
A lei de escala não só permite prever o desempenho de modelos grandes com base em modelos pequenos, economizando sobrecarga computacional e alocação de recursos, mas também reflete a poderosa capacidade de aprendizado do modelo AR autorregressivo. O desempenho do conjunto de testes aumenta com N, T e. Cmin.
Por meio de experimentos, os pesquisadores observaram que o VAR exibe uma lei de escala de potência que é quase idêntica ao LLM : os pesquisadores treinaram 12 tamanhos de modelos, com o número de parâmetros do modelo de escala variando de 18 milhões a 2 bilhões, e a quantidade total de cálculo abrangeu 6 ordens de grandeza, o número total máximo de tokens chega a 305 bilhões, e observa-se que a perda do conjunto de teste L ou a taxa de erro do conjunto de teste e N, entre L e Cmin mostram uma relação de lei de potência suave, e o ajuste é bom. :
No processo de ampliação dos parâmetros do modelo e volume de cálculo, a capacidade de geração do modelo pode ser gradualmente melhorada (como as listras do osciloscópio abaixo):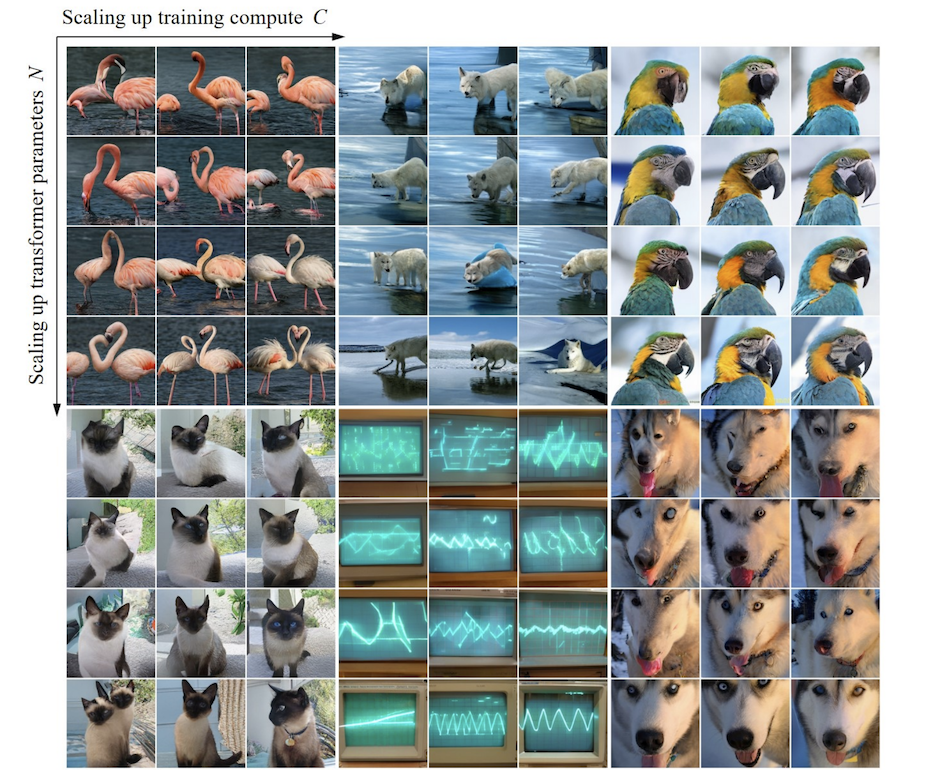
Experimento de tiro zero
Graças à excelente propriedade do modelo autorregressivo de poder usar o mecanismo de forçamento do professor para forçar certos tokens a permanecerem inalterados, o VAR também exibe certas capacidades de generalização de tarefas de amostra zero. O transformador VAR treinado na tarefa de geração condicional pode generalizar para algumas tarefas generativas sem qualquer ajuste fino, como conclusão de imagem (pintura), extrapolação de imagem (pintura externa) e edição de imagem (edição de condição de classe). ) e alcançou alguns resultados:
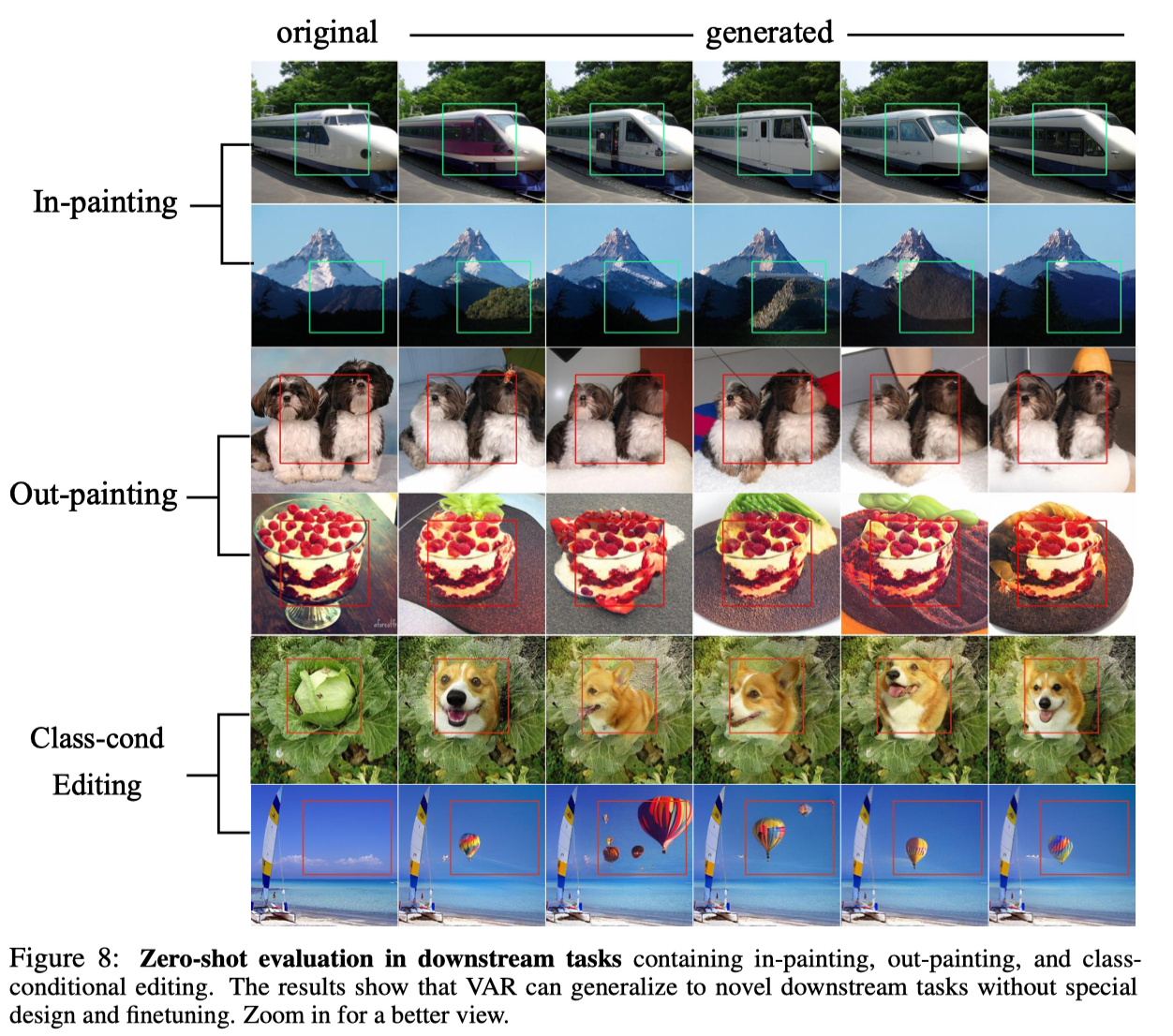
para concluir
O VAR fornece uma nova perspectiva sobre como definir a sequência autoregressiva de imagens, ou seja, a sequência do grosseiro ao fino, dos contornos globais ao ajuste fino local . Embora consistente com a intuição, tal algoritmo autorregressivo traz bons resultados: o VAR melhora significativamente a velocidade e a qualidade de geração do modelo autorregressivo, fazendo com que o modelo autorregressivo supere o modelo de difusão pela primeira vez em muitos aspectos . Ao mesmo tempo, o VAR exibe Leis de Escala e Generalização Zero-shot semelhantes ao LLM. Os autores esperam que as ideias, conclusões experimentais e código aberto do VAR possam contribuir para a exploração pela comunidade do uso do paradigma autorregressivo no campo da geração de imagens e promover o desenvolvimento de algoritmos multimodais unificados baseados em autorregressão no futuro.
Sobre a equipe de comercialização da Bytedance-GenAI
A equipe de Comercialização-GenAI da ByteDance se concentra no desenvolvimento de tecnologia avançada de inteligência artificial generativa e na criação de soluções técnicas líderes do setor, incluindo texto, imagens e vídeos. Ao usar IA generativa para realizar fluxo de trabalho criativo automatizado, ela fornece aos anunciantes instituições e criadores que melhoram a eficiência e o impulso criativos. valor.
Mais vagas na geração visual da equipe e nas direções LLM estão abertas. Fique atento às informações de recrutamento da ByteDance.
Companheiro de frango, deepin-IDE de "código aberto" e finalmente conseguiu a inicialização! Bom cara, a Tencent realmente transformou o Switch em uma "máquina de aprendizagem pensante" Revisão de falhas e explicação da situação da Tencent Cloud em 8 de abril Reconstrução de inicialização de desktop remoto RustDesk Cliente Web Banco de dados de terminal de código aberto do WeChat baseado em SQLite WCDB inaugurou uma grande atualização Lista de abril TIOBE: PHP caiu para o nível mais baixo, Fabrice Bellard, o pai do FFmpeg, lançou a ferramenta de compressão de áudio TSAC , o Google lançou um grande modelo de código, CodeGemma , isso vai te matar? É tão bom que é de código aberto - ferramenta de edição de imagens e pôsteres de código aberto