
O uso de bancos de dados de séries temporais (TSDBs) tem sido comum em vários setores há décadas, especialmente em sistemas de controle financeiro e industrial. No entanto, o surgimento da Internet das Coisas (IoT) levou a um aumento na quantidade de dados de séries temporais (abreviadamente, dados de séries temporais), o que impôs requisitos mais elevados ao desempenho do banco de dados e aos custos de armazenamento, promovendo assim a necessidade de servidores dedicados. bancos de dados de séries temporais.
Diante dos problemas de arquitetura desatualizada e escalabilidade limitada de soluções legadas de séries temporais, surgiu uma nova geração de bancos de dados de séries temporais. Eles adotam arquiteturas modernas que permitem processamento distribuído e expansão horizontal, bem como implantação flexível na nuvem ou no local.
No final de 2022, outro produto de grande sucesso juntou-se à trilha de banco de dados de série temporal de código aberto e foi testado e produzido por mais de 60 empresas em apenas um ano, atraindo mais de 70 colaboradores das principais universidades e empresas nacionais e estrangeiras —— openGemini, O banco de dados de séries temporais distribuído de código aberto da Huawei concentra-se principalmente no armazenamento e análise de dados massivos de séries temporais. Por meio da inovação tecnológica, ele simplifica a arquitetura do sistema de negócios, reduz o custo de armazenamento de dados massivos de séries temporais e melhora a eficiência de armazenamento e análise de dados. dados de série temporal.
Hoje convidamos Xiang Yu, líder da comunidade openGemini, para falar sobre sua história de código aberto ~
01 Originando-se de necessidades internas e avançando gradativamente para a autopesquisa
A pesquisa e o desenvolvimento do openGemini originaram-se originalmente das próprias necessidades da Huawei.
Em 2019, com o estabelecimento da Huawei Cloud, foram construídos centros de dados em Guangzhou, Xangai, Pequim, Guizhou e Hong Kong, e mais de 260 serviços em nuvem foram lançados. Em média, vários TB de dados de indicadores de monitoramento são coletados todos os dias. A solução original de big data está gradualmente sobrecarregada. Quanto maior a quantidade de dados, menor a eficiência da consulta e o custo do armazenamento de dados continua a aumentar. Há uma necessidade urgente de um banco de dados de série temporal dedicado de alto desempenho e alta escalabilidade.
Naquela época, não havia produtos úteis de banco de dados de séries temporais que pudessem acompanhar o desenvolvimento da demanda. O InfluxDB ainda é uma versão autônoma e o Apache IoTDB e o TDengine domésticos estão longe de atender aos requisitos de produção. Portanto, a Huawei está determinada a construir seu próprio banco de dados, otimizar o processamento de dados e resolver problemas de negócios muito importantes no momento. Neste contexto, surgiu o openGemini.
Segundo Xiang Yu, em termos de seleção de tecnologia, inicialmente realizaram a transformação do cluster com base no InfluxDB de código aberto. Porém, com o aumento do número de indicadores e o aumento da frequência de coleta, o aumento diário do volume de dados atingiu dezenas de terabytes. Neste momento, as falhas na arquitetura do próprio InfluxDB começaram a ficar aparentes, afetando o desempenho e a estabilidade do sistema. Portanto, eles optaram por reconstruir a arquitetura e iniciaram o autodesenvolvimento do kernel openGemini.
02 Personalidade única, desempenho líder
Desde a sua criação, o openGemini tem estado intimamente ligado às necessidades comerciais da Huawei, pelo que cada design está repleto de considerações práticas. Especificamente, o openGemini é diferente de outros bancos de dados de séries temporais em nove "personalidades" principais:
Vantagem de desempenho: Entre a competitividade diferenciada do openGemini, o alto desempenho é o mais importante. Em cenários de dados massivos, o openGemini melhora os cenários de consulta simples em mais de 2 vezes, os cenários de consulta média em mais de 5 vezes e os cenários de consulta complexa em mais de 10 vezes em comparação com o InfluxDB de código aberto. Comparado com outros produtos de código aberto semelhantes, o openGemini também tem vantagens óbvias de desempenho.
O desempenho de escrita independente anunciado oficialmente é o seguinte (a ferramenta de teste é TSBS, consulte a documentação do site oficial do openGemini para obter detalhes relevantes do teste):

Comparação de desempenho de consulta de máquina única anunciada oficialmente em cenários DevOps (latência média, ms):

Comparação de desempenho de consulta de máquina única anunciada oficialmente em cenários de IoT (atraso médio, ms):
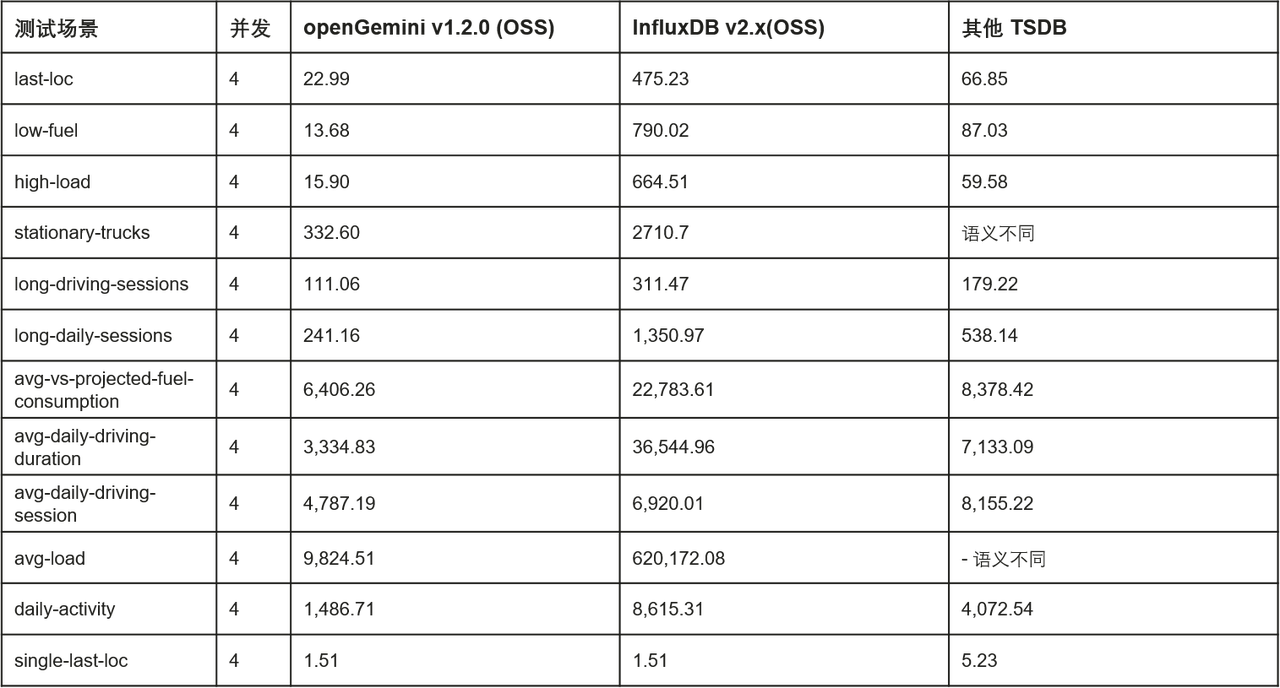
Além disso, openGemini lançou uma série de funções práticas em armazenamento e análise de dados para construir uma competitividade mais diferenciada:
Arquitetura distribuída exclusiva : openGemini oferece duas versões: cluster autônomo e distribuído. O cluster distribuído adota a arquitetura em camadas de processamento paralelo massivo MPP, que divide o mecanismo de computação, o mecanismo de armazenamento e o gerenciamento de metadados em componentes independentes. -store e ts-meta respectivamente. Diferentes componentes suportam expansão horizontal independente, tornando possível responder com flexibilidade a cenários de aplicação complexos.
Mecanismo de alta cardinalidade: O problema de alta cardinalidade (também conhecido como desastre da dimensionalidade) fará com que o índice invertido se expanda, causando consumo excessivo de recursos de memória e redução do desempenho de leitura e gravação. Há muito que prejudica o desenvolvimento de bancos de dados de série temporal. O mecanismo openGemini high-radix resolve completamente esse problema construindo um índice esparso específico de série temporal, que é muito adequado para uso em monitoramento de rede, controle de risco financeiro, Internet das Coisas, transporte e outros campos.
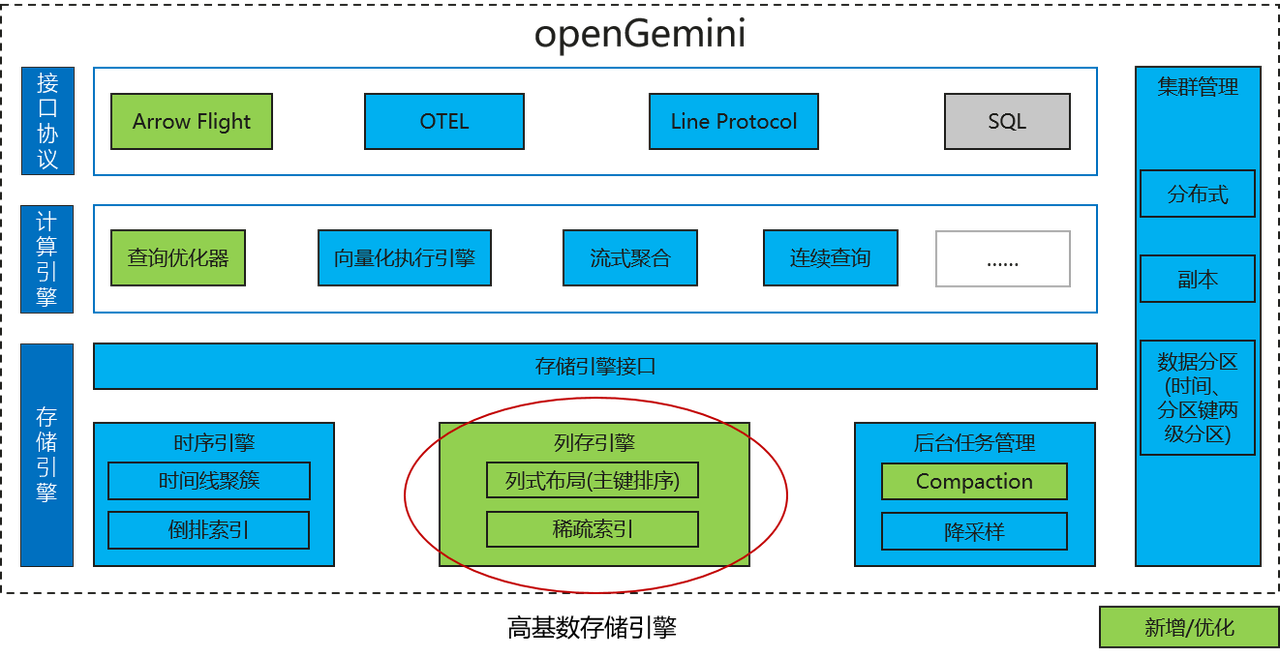
Recuperação de texto : dados de texto são um tipo de dados comum, o openGemini suporta a criação de índices em dados de texto, adota um método de segmentação de palavras de aprendizagem dinâmica, suporta correspondência precisa, de frase e difusa e tem baixo uso de recursos de memória e alta eficiência de recuperação.
Agregação de streaming: A agregação de streaming é um método de pré-agregação que reduz a resolução dos dados durante a gravação. Seu objetivo é resolver o problema dos métodos tradicionais de redução da resolução que leem uma grande quantidade de dados históricos do disco para cálculo, resultando em uma séria amplificação de E/S. O problema.
Redução da resolução multinível : para dados históricos existentes, os métodos tradicionais de redução da resolução reterão os detalhes dos dados históricos. Em alguns cenários, os detalhes dos dados históricos não são importantes e apenas as características dos dados precisam ser retidas. A função de redução da amostragem em vários níveis pode extrair os recursos dos detalhes dos dados históricos e substituir os detalhes dos dados históricos existentes, o que pode reduzir ainda mais. o custo em 50%.
Detecção e previsão de anomalias: a detecção e previsão de anomalias são atualmente uma das aplicações mais maduras de análise de dados de séries temporais e são amplamente utilizadas em cenários como transações quantitativas, detecção de segurança de rede e manutenção diária de data centers, equipamentos industriais e TI. a infraestrutura. openGemini fornece uma biblioteca de detecção de anomalias - openGemini-castor, que encapsula algoritmos de detecção para 13 cenários de anomalias comuns. Possui as vantagens de velocidade de detecção rápida, alta precisão e integração de fluxo e lote, ajudando os aplicativos a melhorar a eficiência da análise de dados.
Armazenamento em camadas de dados quentes e frios : oferece suporte à transferência de dados históricos para armazenamento de objetos, permitindo um método de baixo custo para reter permanentemente dados históricos e também oferece suporte à análise offline de big data. [Este recurso está planejado para ser lançado no segundo semestre]
Confiabilidade dos dados : Suporta múltiplas cópias computacionais para melhorar ainda mais a confiabilidade dos dados. [Este recurso está planejado para ser lançado no segundo semestre]

03 Foco na experiência do usuário, facilitando o início
openGemini não só tem forte desempenho, mas seu design exclusivo também pode trazer muita experiência confortável em aplicações reais:
Em termos de introdução , o openGemini é totalmente compatível com o InfluxDB v1. Ao mesmo tempo, openGemini usa o mesmo protocolo de linha do InfluxDB. A modelagem de dados é simples e fácil de entender, além de ser amigável para desenvolvedores de bancos de dados relacionais. Por fim, o openGemini usa uma linguagem de consulta semelhante ao SQL, que não requer nenhum aprendizado adicional e é fácil de começar. Para implantação de cluster, a comunidade também fornece a ferramenta de implantação Gemix com um clique, que economiza muito trabalho de configuração.
Em termos de sistemas operacionais , o openGemini atualmente oferece suporte aos principais sistemas Linux (incluindo openEuler), Windows e MacOS, tornando o desenvolvimento e a depuração de aplicativos mais convenientes. O processador suporta arquiteturas X86 e ARM64.
Em termos de natividade da nuvem , o openGemini fornece imagens Dockerfile e Docker, suportando a implantação de Docker, K8s, KubeEdge e outras plataformas. Como o endereço IP muda após a reinicialização do contêiner, o openGemini adicionou uma função de nome de domínio para garantir que os nós do cluster ainda possam manter a conectividade após a reinicialização do contêiner. A comunidade também criou o projeto openGemini-operator para facilitar a implantação de contêineres com um clique dos usuários. openGemini oferece suporte à leitura e gravação remota do Prometheus e pode ser usado como armazenamento de back-end para o Prometheus resolver seu problema de capacidade de armazenamento insuficiente. [aliás: openGemini também oferecerá suporte direto ao PromQL, que está atualmente em desenvolvimento]
Em termos de observabilidade , a comunidade desenvolveu o componente ts-monitor, especializado na coleta de indicadores de nós e kernel. É dividido em 19 subcategorias e mais de 260 itens. Ele pode ser usado com o Grafana para obter monitoramento abrangente do status operacional. do openGemini. Por exemplo, indicadores como utilização de CPU e memória, largura de banda de gravação, latência de gravação, simultaneidade de gravação e QPS podem ser visualizados rapidamente por meio da interface visual, facilitando a visualização do status operacional, ajuste de desempenho do banco de dados e localização precisa de problemas a qualquer momento.
04 Após testes internos de combate reais, devolva ao código aberto
Como um banco de dados de série temporal, o openGemini é atualmente mais comumente usado na Internet das Coisas e no monitoramento de operação e manutenção. Em termos de processamento de dados massivos, tem vantagens que os bancos de dados comuns não conseguem igualar. Ao mesmo tempo, o openGemini, como projeto interno da Huawei, passou no teste de “seu próprio pessoal”:
Huawei Cloud SRE usa openGemini como base de armazenamento de dados de monitoramento. Um total de 25 clusters são implantados em toda a rede, com um tamanho máximo de cluster de 70 nós. Ele resistiu com sucesso ao teste real de 40 milhões de gravações de dados por segundo e 50.000 simultâneas. consultas. Em comparação com a solução original, ao realizar o mesmo negócio, o atraso ponta a ponta do sistema original é reduzido em 50%, os recursos da CPU podem ser economizados em 68%, os recursos de memória podem ser economizados em 50% e o disco rígido os recursos podem ser economizados em mais de 90%.
A plataforma IoT industrial da Huawei Cloud já usava a versão autônoma do InfluxDB desde a mudança para o openGemini, e o desempenho de consulta e de ponta a ponta aumentou 3 vezes. os acessos a dispositivos aumentaram para o nível de milhões.
Xiang Yu apresentou que o openGemini se originou de código aberto e se beneficiou muito do projeto de código aberto InfluxDB. Portanto, aderindo ao espírito de código aberto, todos os códigos openGemini são de código aberto. Ele espera que mais empresas e desenvolvedores em todo o mundo se beneficiem. e também espera que, por meio da comunidade aberta, a plataforma, junto com os desenvolvedores, promova conjuntamente a inovação tecnológica e compartilhe resultados de código aberto.
Atualmente, o openGemini possui apenas versão de código aberto e serviço em nuvem. Não planeja se envolver em versões comerciais off-line e está disposto a doar para a fundação. Atualmente, a comunidade ainda tem muitas imperfeições. Em seguida, a comunidade enriquecerá ainda mais as ferramentas ecológicas do openGemini (como ferramentas de migração de dados, SDK, integração ecológica de big data, etc.), interfaces de gerenciamento visual, documentos, etc.
"Atualmente, o planejamento técnico da comunidade geralmente se concentrará nos três importantes cenários de aplicação da Internet das Coisas, monitoramento e observabilidade de operação e manutenção, e fortalecerá a compatibilidade ecológica e a construção de capacidade central de tecnologias relacionadas. Estamos começando a demonstrar o próximo arquitetura de software de geração do openGemini." Xiang Yu disse.
“No curto prazo, o openGemini não considerará cenários relacionados à indústria, porque os cenários de negócios na área industrial são muito complexos, os requisitos de tempo real são extremamente altos, os fossos dos fabricantes de software industrial são muito profundos e as coisas que Os bancos de dados de séries temporais podem fazer são limitados. Além disso, a comunidade não tem experiência no setor e não sabemos o suficiente sobre esse cenário, consideraremos a procura de alguns parceiros na área industrial, como fornecedores de software industrial. fornecedores, etc., para cooperar e melhorar juntos”, disse Xiang Yu.
Página inicial do site oficial do openGemini: https://www.openGemini.org/
Endereço de código aberto openGemini: https://github.com/openGemini
Companheiro de frango, deepin-IDE de "código aberto" e finalmente conseguiu a inicialização! Bom cara, a Tencent realmente transformou o Switch em uma "máquina de aprendizagem pensante" Revisão de falhas e explicação da situação da Tencent Cloud em 8 de abril Reconstrução de inicialização de desktop remoto RustDesk Cliente Web Banco de dados de terminal de código aberto do WeChat baseado em SQLite WCDB inaugurou uma grande atualização Lista de abril TIOBE: PHP caiu para o nível mais baixo, Fabrice Bellard, o pai do FFmpeg, lançou a ferramenta de compressão de áudio TSAC , o Google lançou um grande modelo de código, CodeGemma , isso vai te matar? É tão bom que é de código aberto - ferramenta de edição de imagens e pôsteres de código aberto