Clique no texto azul
Siga-nos para tornar o desenvolvimento mais interessante
O artigo a seguir vem da Intel Internet of Things, escrito por Wu Zhuo, evangelista da Intel AI
Falando em IA generativa, ela se tornou popular desde o ano passado, acredito que seja você um desenvolvedor na área de IA ou não, você conhece esse conceito. Falando em cenários e modelos típicos de aplicação no campo da IA generativa, acredito que a primeira coisa que vem à mente é o diagrama vicentino e uma série de modelos de difusão latente (LDMs) por trás dele. Com os poderosos recursos desses modelos, qualquer pessoa pode se tornar um designer ou ilustrador e criar belas imagens simplesmente inserindo um texto. No entanto, ao chamar o modelo gráfico Vincent, se você optar por chamar a API em execução na nuvem, poderá precisar pagar e também poderá enfrentar problemas como esperar na fila. Se você optar por executá-lo em uma máquina local, ele terá requisitos maiores de poder de computação e memória da máquina e também exigirá uma longa espera. Afinal, esses modelos geralmente precisam ser iterados dezenas de vezes antes de poderem gerar uma imagem relativamente bonita.
Recentemente, foi lançado um modelo denominado LCMs (Latent Consistency Models), que possibilita a geração rápida de imagens de modelos de diagramas de Vincent. Inspirados em Modelos de Consistência (CM), os Modelos de Consistência Latente (LCMs) permitem inferência rápida com etapas mínimas em qualquer modelo de difusão latente pré-treinado, incluindo Difusão Estável. Os modelos de consistência são uma nova família de modelos generativos que permitem a geração em uma etapa ou em um pequeno número de etapas. A ideia central é aprender funções de soluções para PF-ODEs (trajetórias de fluxos probabilísticos de equações diferenciais ordinárias). Ao aprender um mapa consistente que mantém a consistência dos pontos na trajetória da EDO, esses modelos permitem a geração em uma única etapa, eliminando a necessidade de iterações computacionalmente intensivas. No entanto, o CM está limitado à tarefa de geração de imagens no espaço de pixels e, portanto, não é adequado para sintetizar imagens de alta resolução. Os LCMs empregam um modelo de coerência no espaço latente da imagem para gerar imagens de alta resolução. Considere o processo de retrodifusão guiada como um processo para resolver PF-ODE. Os LCMs são projetados para prever diretamente a solução de tais EDOs no espaço latente, reduzindo a necessidade de um grande número de iterações e permitindo uma amostragem rápida e de alta fidelidade. A utilização do espaço latente da imagem em modelos de difusão em grande escala (como a Difusão Estável) melhora efetivamente a qualidade da geração de imagens e reduz a carga computacional, possibilitando a geração rápida de imagens.
Mais detalhes sobre o método e modelo proposto podem ser encontrados na página do projeto [1], no artigo [2] e no repositório original [3].
É claro que nosso OpenVINO™ pode otimizar, compactar, inferir, acelerar e implantar totalmente um modelo mágico de gráfico Vincent de LCMs. A seguir, vamos aprender mais sobre as etapas específicas por meio do código do Jupyter Notebook [4] e da desmontagem do modelo LCMs em nosso repositório OpenVINO™ Notebooks comumente usado.

Passo um:
Instale o pacote de ferramentas correspondente e carregue o modelo
e convertido para o formato OpenVINO™ IR
%pip install -q "torch" --index-url https://download.pytorch.org/whl/cpu
%pip install -q "openvino>=2023.1.0" transformers "diffusers>=0.22.0" pillow gradio "nncf>=2.6.0" datasetsDeslize para a esquerda para ver mais
Baixar modelo
Semelhante ao pipeline de difusão estável tradicional, o modelo LCMs também contém três modelos: codificador de texto, U-Net e decodificador VAE.

Modelo de codificador de texto
Responsável por criar condições para geração de imagens a partir de prompt de texto

Modelo U-Net
Responsável pela remoção preliminar de ruído da representação de imagens latentes

Decodificador autoencoder (VAE)
Usado para decodificar o espaço latente na imagem final
Portanto, esses três modelos precisam ser baixados respectivamente. Parte do código é a seguinte:
import gc
import warnings
from pathlib import Path
from diffusers import DiffusionPipeline
warnings.filterwarnings("ignore")
TEXT_ENCODER_OV_PATH = Path("model/text_encoder.xml")
UNET_OV_PATH = Path("model/unet.xml")
VAE_DECODER_OV_PATH = Path("model/vae_decoder.xml")
def load_orginal_pytorch_pipeline_componets(skip_models=False, skip_safety_checker=True):Deslize para a esquerda para ver mais
skip_conversion = (
TEXT_ENCODER_OV_PATH.exists()
and UNET_OV_PATH.exists()
and VAE_DECODER_OV_PATH.exists()
)
(
scheduler,
tokenizer,
feature_extractor,
safety_checker,
text_encoder,
unet,
vae,
) = load_orginal_pytorch_pipeline_componets(skip_conversion)Deslize para a esquerda para ver mais
Conversão de modelo
Incluindo a conversão dos três modelos acima para o formato OpenVINO™ IR.

Passo dois:
Pronto com base em OpenVINO™
pipeline de raciocínio
O pipeline é mostrado na figura abaixo.
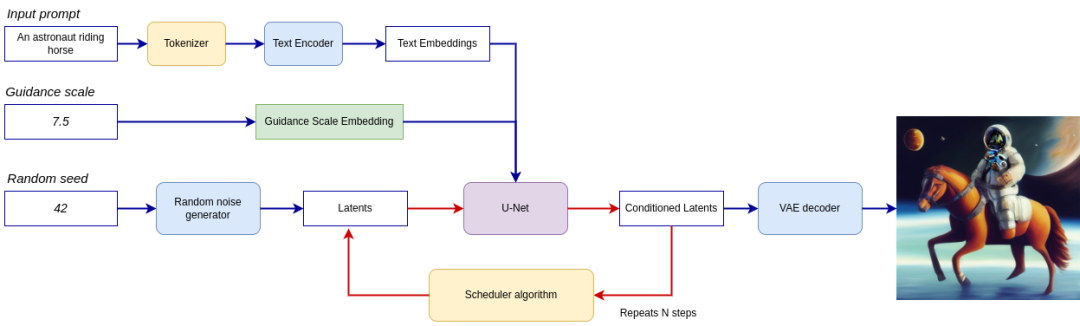
Todo o pipeline utiliza uma representação de imagem latente e uma dica de texto, que é convertida em incorporação de texto por meio do codificador de texto do CLIP como entrada. A representação inicial da imagem latente é gerada usando um gerador de ruído aleatório. Ao contrário do processo de Difusão Estável original, os LCMs também usam escalonamento de bootstrap para obter incorporações condicionais de passo de tempo como entrada para o processo de difusão, enquanto na Difusão Estável ele é usado para dimensionar a representação latente da saída.
Em seguida, o U-Net elimina iterativamente as representações aleatórias de imagens latentes enquanto condiciona as incorporações de texto. A saída do U-Net é o ruído residual, que é usado pelo algoritmo de escalonamento para calcular a representação da imagem latente sem ruído. LCMs introduzem seu próprio algoritmo de escalonamento que estende a orientação não-Markov introduzida em modelos probabilísticos de difusão com eliminação de ruído (DDPMs). O processo de remoção de ruído é repetido várias vezes (observação: o padrão é 50 vezes no pipeline SD original, mas com o LCM são necessários apenas pequenos passos de 2 a 8 vezes!) para obter gradualmente uma melhor representação da imagem subjacente. Depois de concluída, a representação da imagem latente é decodificada pelo decodificador variável VAE na saída da imagem final.
Defina classes relacionadas ao pipeline de inferência de LCMs. Parte do código é a seguinte:
from typing import Union, Optional, Any, List, Dict
from transformers import CLIPTokenizer, CLIPImageProcessor
from diffusers.pipelines.stable_diffusion.safety_checker import (
StableDiffusionSafetyChecker,
)
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.image_processor import VaeImageProcessor
class OVLatentConsistencyModelPipeline(DiffusionPipeline):Deslize para a esquerda para ver mais

terceiro passo:
Configurar o pipeline de inferência
Primeiro, crie uma instância do modelo OpenVINO™ e compile-a com o dispositivo selecionado. Selecione um dispositivo na lista suspensa para executar inferência usando OpenVINO™.
core = ov.Core()
import ipywidgets as widgets
device = widgets.Dropdown(
options=core.available_devices + ["AUTO"],
value="CPU",
description="Device:",
disabled=False,
)
deviceDeslize para a esquerda para ver mais
text_enc = core.compile_model(TEXT_ENCODER_OV_PATH, device.value)
unet_model = core.compile_model(UNET_OV_PATH, device.value)
ov_config = {"INFERENCE_PRECISION_HINT": "f32"} if device.value != "CPU" else {}
vae_decoder = core.compile_model(VAE_DECODER_OV_PATH, device.value, ov_config)Deslize para a esquerda para ver mais
O tokenizador e o agendador do modelo também são partes importantes do pipeline. O pipeline também pode usar um verificador de segurança, um filtro usado para detectar se as imagens geradas correspondentes contêm conteúdo "Não seguro para o trabalho" (nsfw). O processo de detecção de conteúdo nsfw requer o uso de um modelo CLIP para obter embeddings de imagens, exigindo assim que um componente extrator de recursos adicional seja adicionado ao pipeline. Reutilizamos o etiquetador, o extrator de recursos, o agendador e o verificador de segurança do pipeline de LCMs original.
ov_pipe = OVLatentConsistencyModelPipeline(
tokenizer=tokenizer,
text_encoder=text_enc,
unet=unet_model,
vae_decoder=vae_decoder,
scheduler=scheduler,
feature_extractor=feature_extractor,
safety_checker=safety_checker,
)Deslize para a esquerda para ver mais

o quarto passo:
Geração de texto para imagem
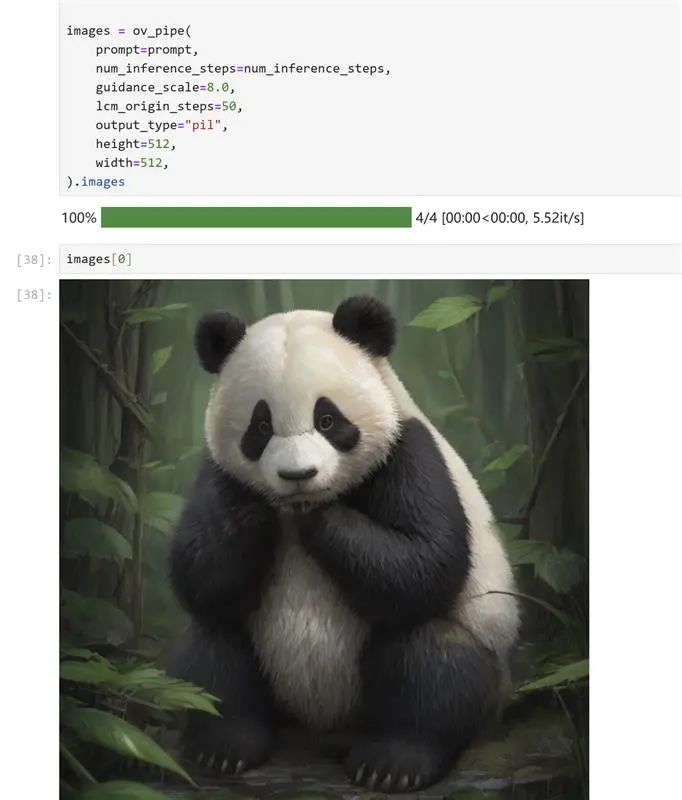
prompt = "a beautiful pink unicorn, 8k"
num_inference_steps = 4
torch.manual_seed(1234567)
images = ov_pipe(
prompt=prompt,
num_inference_steps=num_inference_steps,
guidance_scale=8.0,
lcm_origin_steps=50,
output_type="pil",
height=512,
width=512,
).imagesDeslize para a esquerda para ver mais
Na minha máquina local, usei minha CPU Intel® Core™ de 12ª geração e placa gráfica Intel Radar™ A770m para executar a inferência de modelo, e a geração da imagem foi realmente feita em um piscar de olhos!

Claro, para facilitar o uso dos desenvolvedores, nosso código de notebook [5] também projetou uma interface mais otimizada para o usuário baseada em Gradio para todos.

o quinto passo:
Use NNCF para quantizar e compactar o modelo
Além disso, se você tiver necessidades adicionais de compactação de tamanho de modelo e compactação de espaço de memória, nosso notebook também fornece exemplos de código para compactação de quantização baseada em NNCF.
O processo de compressão de quantização é dividido nas três etapas a seguir:
Crie um conjunto de dados de calibração para quantificação
Execute nncf.quantize() para obter o modelo quantizado
Use openvino.save_model() para salvar o modelo quantizado no formato INT8
Parte do código é a seguinte:
%%skip not $to_quantize.value
import nncf
from nncf.scopes import IgnoredScope
if UNET_INT8_OV_PATH.exists():
print("Loading quantized model")
quantized_unet = core.read_model(UNET_INT8_OV_PATH)
else:
unet = core.read_model(UNET_OV_PATH)
quantized_unet = nncf.quantize(
model=unet,
subset_size=subset_size,
preset=nncf.QuantizationPreset.MIXED,
calibration_dataset=nncf.Dataset(unet_calibration_data),
model_type=nncf.ModelType.TRANSFORMER,
advanced_parameters=nncf.AdvancedQuantizationParameters(
disable_bias_correction=True
)
)
ov.save_model(quantized_unet, UNET_INT8_OV_PATH)Deslize para a esquerda para ver mais
O efeito de execução é o seguinte:

Seguindo o mesmo prompt de texto, verifique o efeito de geração do modelo quantizado:

Claro, como o desempenho no tempo de inferência pode ser melhorado?Também convidamos todos a usar o seguinte código para testá-lo em sua própria máquina:
%%skip not $to_quantize.value
import time
validation_size = 10
calibration_dataset = datasets.load_dataset("laion/laion2B-en", split="train", streaming=True).take(validation_size)
validation_data = []
while len(validation_data) < validation_size:
batch = next(iter(calibration_dataset))
prompt = batch["TEXT"]
validation_data.append(prompt)
def calculate_inference_time(pipeline, calibration_dataset):
inference_time = []
pipeline.set_progress_bar_config(disable=True)
for prompt in calibration_dataset:
start = time.perf_counter()
_ = pipeline(
prompt,
num_inference_steps=num_inference_steps,
guidance_scale=8.0,
lcm_origin_steps=50,
output_type="pil",
height=512,
width=512,
)
end = time.perf_counter()
delta = end - start
inference_time.append(delta)
return np.median(inference_time)Deslize para a esquerda para ver mais

resumo
Esse é todo o processo! Comece a usar OpenVINO™ e LCMs agora seguindo o código e as etapas que fornecemos!
Detalhes sobre o conjunto de ferramentas de código aberto OpenVINO™[6], incluindo detalhes sobre os mais de trezentos modelos pré-treinados validados e otimizados que fornecemos.
Além disso, para que todos possam entender e dominar rapidamente o uso do OpenVINO™, também fornecemos uma série de demonstrações de notebooks Jupyter de código aberto. Ao executar esses notebooks, você pode entender rapidamente como usar o OpenVINO™ em diferentes cenários para implementar uma série de tarefas, incluindo tarefas de visão computacional, processamento de fala e linguagem natural.
[1] Endereço da página do projeto:
https://latent-consistency-models.github.io/
[2] Endereço do papel:
https://arxiv.org/abs/2310.04378
[3] Método e modelo de repositório original:
https://github.com/luosiallen/latent-consistency-model
[4] Endereço do código do notebook Jupyter:
https://github.com/openvinotoolkit/openvino_notebooks/tree/main/notebooks/263-latent-consistency-models-image-generation
[5] Recursos dos notebooks OpenVINO™:
https://github.com/openvinotoolkit/openvino_notebooks
[6] Detalhes do conjunto de ferramentas de código aberto OpenVINO™:
https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html
OpenVINO™
--FIM--
你也许想了解(点击蓝字查看)⬇️➡️ 开发者实战 | 介绍OpenVINO™ 2023.1:在边缘端赋能生成式AI➡️ 基于 ChatGLM2 和 OpenVINO™ 打造中文聊天助手➡️ 基于 Llama2 和 OpenVINO™ 打造聊天机器人➡️ OpenVINO™ DevCon 2023重磅回归!英特尔以创新产品激发开发者无限潜能➡️ 5周年更新 | OpenVINO™ 2023.0,让AI部署和加速更容易➡️ OpenVINO™5周年重头戏!2023.0版本持续升级AI部署和加速性能➡️ OpenVINO™2023.0实战 | 在 LabVIEW 中部署 YOLOv8 目标检测模型➡️ 开发者实战系列资源包来啦!➡️ 以AI作画,祝她节日快乐;简单三步,OpenVINO™ 助你轻松体验AIGC
➡️ 还不知道如何用OpenVINO™作画?点击了解教程。➡️ 几行代码轻松实现对于PaddleOCR的实时推理,快来get!➡️ 使用OpenVINO 在“端—边—云”快速实现高性能人工智能推理扫描下方二维码立即体验
OpenVINO™ 工具套件 2023.1Clique para ler o texto original e experimente o OpenVINO 2023.1 agora
O artigo é tão emocionante, você está “lendo” ele?