
Эта статья составлена на основе стенограммы выступления на конференции Юньци 2023 г. Информация о выступлении следующая:
Докладчик : Линь Вэй | Исследователь Alibaba Cloud, главный архитектор подразделения платформы облачных вычислений Alibaba, руководитель платформы искусственного интеллекта Alibaba Cloud PAI и платформы разработки и управления большими данными DataWorks
Тема выступления : Интерпретация интеграции больших данных с использованием искусственного интеллекта.
Этот год стал годом бурного развития искусственного интеллекта. Рождение больших языковых моделей способствовало увлечению большими моделями, охватившему всю отрасль. Многие люди считают, что наступила «эра искусственного интеллекта для iPhone». Обучение больших моделей на самом деле непростое дело, поскольку увеличение количества параметров модели означает, что для обучения необходимы более высокие вычислительные мощности и больше данных, а также необходимы соответствующие инструменты, позволяющие разработчикам быстро выполнять итерацию модели. точность модели будет улучшаться быстрее. В последние несколько лет Alibaba Cloud продвигает разработку и масштабирование искусственного интеллекта, что на самом деле является основной движущей силой этого этапа бурного развития искусственного интеллекта.

Давайте посмотрим на типичный процесс разработки модели, включая предварительное обучение данных, обучение модели и развертывание модели. Мы склонны уделять столько внимания обучению, что пренебрегаем всем производственным процессом. Но для обучения хорошей модели данные становятся все более важными. Включая сбор данных, очистку данных, извлечение признаков, управление данными, а затем процесс обучения, какие данные необходимо распространить для участия в обучении и какие данные используются для оценки качества модели. Все данные должны иметь часть проверки для проверки качества.Этот шаг очень важен. Вред некачественных данных для модели невозможно себе представить. Вот почему У Даен продвигает идею о том, что лучшее машинное обучение — это 80% обработки данных + 20% модели.
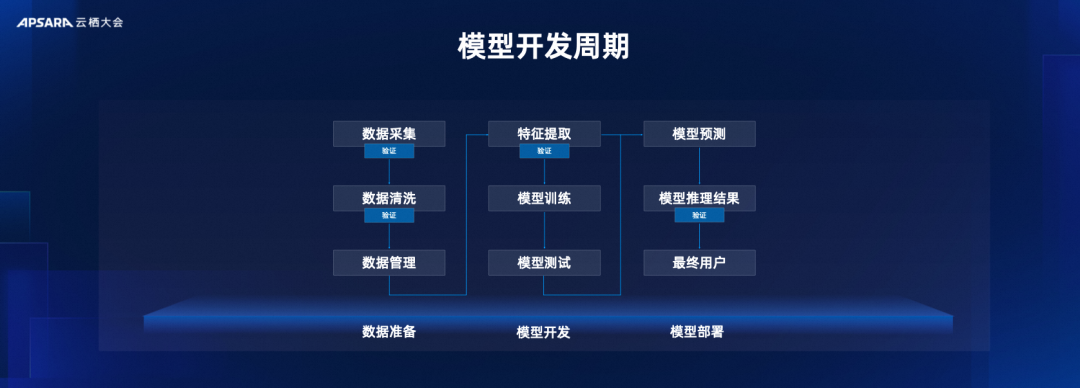
Эволюция подходов к разработке моделей, «ориентированных на модели» и «ориентированных на данные».
Это также отражает эволюцию способов разработки моделей. Раньше мы часто говорили о разработке моделей, ориентированных на модели.Инженеры-алгоритмы тратили много времени на корректировку структуры модели, надеясь улучшить способность модели к обобщению и решить различные проблемы шума с помощью структуры модели. Если вы посмотрите на Paper пятилетней давности, вы обнаружите, что вокруг структур моделей было проведено большое количество исследований. Данных и вычислительных мощностей в то время было недостаточно для поддержки сегодняшней эпохи больших моделей. В то время обучение модели представляло собой скорее «обучение с учителем», и использовались все помеченные данные. Эти данные были очень дорогими, что также определяло, что в процессе обучения не было большого пространства для маневрирования с данными. изменения в структуре модели.
Сегодняшнее обучение больших моделей включает в себя много неконтролируемого обучения. Напротив, структура модели не сильно меняется: похоже, все сходятся и используют структуру Трансформера. В это время мы постепенно перешли к парадигме разработки моделей, ориентированной на данные. Что это за парадигма развития? Это требует использования большого объема данных для обучения без присмотра, использования большой вычислительной мощности, большого механизма обработки данных и относительно фиксированной структуры модели для извлечения некоторых интересных и интеллектуальных вещей.
Следовательно, объем данных, используемых для обучения, будет стремительно расти, и для очистки и оценки данных необходимо будет использовать различные методы. Мы видим, что многие крупные исследовательские группы по моделированию тратят много энергии на обработку данных и проверяют качество данных неоднократно и под разными углами в различных средах. По различным измерениям иногда даже создаются модели для оценки, а качество данных отражается в результатах модели. В этом процессе необходимо накопить множество инструментов обработки данных.Только таким образом можно будет эффективно поддерживать требования к качеству данных при разработке моделей, ориентированных на данные. Это также основная идея, о которой все говорят о парадигме разработки моделей, ориентированных на данные.

Именно в рамках этой тенденции мы всегда считали, что большие данные и ИИ — это две стороны одной медали, и необходимо добиться интеграции больших данных и ИИ, чтобы соответствовать эволюции текущей парадигмы развития моделей.
В Alibaba Cloud мы усердно работаем над тесной интеграцией двух систем данных и искусственного интеллекта. На уровне вычислительной инфраструктуры мы предоставляем вычислительные кластеры, подходящие для различных сценариев, в том числе кластеры на базе ЦП, подходящие для больших данных, и гетерогенные вычислительные кластеры, требующие сетей RDMA, подходящих для обучения больших моделей. Кроме того, была создана интегрированная платформа больших данных и искусственного интеллекта, охватывающая весь процесс разработки модели, включая сбор и интеграцию данных.Платформа больших данных затем используется для проведения крупномасштабного автономного анализа для проверки качества данных. Кроме того, имеются возможности потоковых вычислений. После того, как данные будут обработаны на платформе больших данных, они будут «переданы» PAI, платформе, отвечающей за разработку искусственного интеллекта, для обучения и итерации. Наконец, что касается инкубации модельных приложений, мы полагаемся на базы данных векторных движков, такие как Hologres, для создания приложений на основе сценариев.

Сценарии применения интеграции больших данных с искусственным интеллектом
Прежде чем официально рассказать о технических аспектах интеграции ИИ с большими данными, давайте приведем два примера применения.
Первый пример — это большая модель системы ответов на вопросы, дополненная поиском из базы знаний. Вы можете видеть, что многие из последних тенденций в крупномасштабных моделях упоминают этот сценарий.С помощью большой модели можно получить вертикальную базу знаний для конкретной отрасли. Как это делается? Сначала данные в этой базе знаний нужно очистить и фрагментировать, преобразовать в вектор через большую модель, а затем эти векторы сохранить в системе данных.Это система данных для векторного поиска. Когда поступает реальный запрос, сначала будет найден вектор, соответствующий запросу, преобразован в знания, а затем использован для ограничения большой модели и управления «бессмысленным» импульсом большой модели, чтобы результаты обратной связи были более точными. точный.
В этом сценарии используется множество возможностей большой модели, включая крупномасштабную распределенную пакетную обработку, поскольку при создании внедрения на самом деле используется очень большой объем данных. В то же время будут также использоваться такие сервисные возможности, как базы данных векторов.Реальные бизнес-сценарии очень чувствительны к задержкам запросов и требуют очень быстрого предоставления векторов. Конечно, используется и возможность обучения больших моделей, для чего нужна хорошая система ИИ.
Второй пример — система персонализированных рекомендаций. В процессе выдачи рекомендаций в режиме реального времени интересы всех рекомендуемых объектов динамически изменяются.Часто модель такой системы постоянно обновляется, причем модель необходимо обновлять на основе последних поведенческих данных. Мы часто обрабатываем собранные журналы в режиме реального времени или в автономном режиме. Автономные данные используются для создания более качественной базовой модели. Данные в реальном времени также извлекают эту функцию. После обучения модели генерируется дельта модели, а затем это delta. Приложение применяется к онлайн-системе и обновляется ежедневно. Здесь мы видим, что существует множество систем данных, включая системы потоковых вычислений в реальном времени, системы искусственного интеллекта и системы пакетной обработки.
Техническая реализация интеграции больших данных с искусственным интеллектом
Унифицированное управление данными и рабочим пространством искусственного интеллекта
Прежде всего, мы соединяем процессы искусственного интеллекта и больших данных на самом внешнем уровне структуры модели. Это также наша оригинальная идея построить рабочее пространство в продукте PAI, чтобы несколько ресурсов можно было объединить на одной платформе разработки. . Теперь платформа искусственного интеллекта Alibaba Cloud PAI может поддерживать различные вычислительные ресурсы, включая ресурсы ECS, платформы потоковых вычислений и кластеры PAI Lingjun Intelligent Computing для обучения больших моделей, а также сервис контейнерных вычислений, который Yunqi выпустила на этот раз ACS. и так далее.
Простого доступа к этим ресурсам недостаточно. Пользователям нужно органично соединить доступные ресурсы. Поэтому мы запустили структуру Flow, чтобы соединить эти процессы и различные этапы обучения модели и обработки данных. Здесь мы предоставляем различные способы построения соединений, включая статическую композицию, SDK, графическое взаимодействие и т. д., для построения сложных блок-схем взаимодействия больших данных и искусственного интеллекта.
Бессерверные облачные сервисы
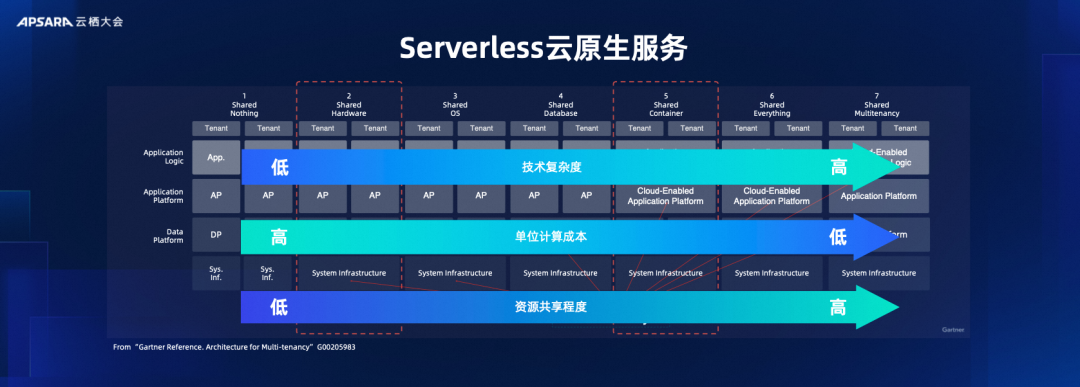
Если вы хотите продолжить интеграцию больших данных и искусственного интеллекта, пользователи надеются, что смогут предоставлять большие данные и услуги искусственного интеллекта в одном ресурсе. В настоящее время технология бессерверных облачных сервисов неотделима. Мы говорили о нативном облачном подходе, но на самом деле облачный нативный подход имеет множество измерений. Cloud Native больше связан с общими ресурсами, но что это за ресурсы? На самом деле, это тоже необходимо определить.
Это определение также имеет много уровней. Вы можете сказать, что вы делитесь на аппаратном уровне, тогда вы делитесь серверами и виртуальными серверами; вы также можете совместно использовать виртуальные ресурсы более высокого уровня, такие как сами контейнеры и сервисы. На разных уровнях, чем выше уровень совместного использования, тем ниже будут затраты на единичные вычисления и, конечно же, тем выше будет техническая сложность. Вот почему группы облачных вычислений улучшают облачную среду своих услуг или достигают более высоких технических возможностей, чтобы они могли обеспечить совместное использование вычислительных ресурсов более высокого уровня более экономичным и доступным способом. экономически эффективно.
Именно по этой причине все наши продукты для работы с большими данными находятся в шестом измерении, а именно в продукте Share Everything. Но мы все созданы в пятом измерении, то есть в общем контейнере, который представляет собой уровень обслуживания контейнерных вычислений, так что мы можем органично соединять большие данные и системы искусственного интеллекта с одним ресурсом.
Унифицированное планирование: планирование с несколькими нагрузками, дифференцированное планирование с поддержкой SLO
Добиться таких возможностей не так-то просто, ведь сервисы контейнерных вычислений изначально создавались для поддержки микросервисов. Сила параллельного планирования микросервисов сильно отличается от сценариев больших данных и интеллектуальных вычислений с использованием искусственного интеллекта. Чтобы обеспечить возможность запуска различных задач и сервисов больших данных, а также задач и сервисов искусственного интеллекта в пуле ресурсов, нам на самом деле нужно проделать большую работу. Например, в сценариях больших данных существует множество краткосрочных задач с высокой степенью параллелизма.Необходимо значительно повысить пропускную способность самого K8S и решить проблемы производительности на всех уровнях, включая задержку и масштабирование.
В то же время перед нами стоят разнообразные задачи, включая не только онлайн-сервисы, но и вычислительные задачи. Например, в сложных сценариях ИИ требуется знание топологии сети, поскольку обучение крупных моделей ИИ предъявляет очень высокие требования к сети. Как мы в настоящее время воспринимаем эту топологию на этом уровне контейнерных сервисов и вычислительных сервисов и эффективно планируем? Как мы можем позволить рабочим нагрузкам больших данных и искусственного интеллекта хранить на ней ресурсы? Это требует высокой осведомленности о нагрузке и осведомленности о QS. планирования.

Многопользовательская изоляция безопасности
Для облачных сервисов самое главное — безопасная изоляция мультитенантов. Нам необходимо усилить возможности облачного K8S в этом направлении, чтобы мы могли безопасно повторно использовать большие данные и искусственный интеллект на одном и том же ресурсе. Мы используем множество технологий изоляции безопасности на уровне хранения и на сетевом уровне. Таким образом, многочисленные продукты для обработки больших данных и искусственного интеллекта, а также собственные онлайн-сервисы пользователей могут быть интегрированы в пул ресурсов для обеспечения корпоративного использования в облаке.

АСУ службы контейнерных вычислений
На конференции Yunqi был представлен сервис контейнерных вычислений ACS, а PAI также стал одним из первых продуктов, поддерживаемых первой партией сервисов контейнерных вычислений. На платформе ACS службы контейнерных вычислений пользователи могут хорошо распределять свои ресурсы в больших данных и искусственном интеллекте, а затем более естественным образом соединять их в единой базе ресурсов, сети и хранилищах ввода-вывода.
Многоуровневая квота
Все мы знаем, что вычислительные ресурсы для больших моделей очень дороги. Мы также продолжим укреплять некоторые усовершенствованные возможности управления ресурсами на этой основе, поэтому вскоре выпустим возможности многоуровневых квот, чтобы администраторы кластеров могли лучше управлять ресурсами и позволить каждой команде управлять своими собственными ресурсами.Но вот наступает критический момент. Например, когда дело доходит до этапа спринта, администратор может объединить все ресурсы и обучить несколько более крупных моделей. Это наша многоуровневая квота.
Автоматическое планирование с учетом топологии
Для обучения очень больших моделей нам необходимо расширить возможности планирования контейнерных сервисов. В качестве примера мы видим, что при обучении модели у нас часто есть шаг под названием All-Reduce. Если нет контроля планирования и порядок немного нарушен, чтобы сформировать кольцо сокращения, мы обнаружим, что будет некоторый перекрестный трафик. переключателя. Наконец, благодаря планированию с учетом и без учета топологии повышение производительности может быть увеличено на 30–40 %, что очень впечатляет.
MaxCompute 4.0 Данные+ИИ
Обучение больших моделей часто требует огромных объемов данных.Как мы уже говорили ранее, нам нужно не только сохранять данные, но, что более важно, нам необходимо выполнять пакетную обработку для очистки, неоднократно оценивать качество данных и корректировать данные на основе обратной связи. . В настоящее время нам нужна платформа больших данных и возможность интегрировать озера и склады, чтобы поддержать нас. Продукт хранилища данных Alibaba Cloud MaxCompute запустил открытый формат данных MaxFrame, который может органично и открыто соединять мощные возможности управления данными и вычислений с системами искусственного интеллекта. Кроме того, существует Flink-Paimon. В сценарии потоковых вычислений потоковые вычисления и онлайн-машинное обучение могут быть объединены, чтобы открыть путь между данными и обучением.
Ускорение набора данныхDataSetAcc
В сценарии интеллектуальных вычислений AI кластера PAI Lingjun существуют не только задачи машинного обучения с высокой плотностью, но и задачи обработки данных. Однако вычислительные ресурсы с высокой плотностью очень ценны. В настоящее время вы можете подключиться к удаленное хранилище больших данных. Но здесь будет еще одно противоречие: удаленный ввод-вывод данных не может соответствовать вычислениям высокой плотности. Чтобы решить эту проблему, мы предоставляем возможность ускорения набора данных DatasetAcc, которая использует локальную SD и локальное хранилище кластера PAI Lingjun для создания ближнего кэша и асинхронно извлекает данные из удаленного хранилища данных в ближайший. -конец. . Это вполне может решить проблему объединения больших данных и интеллектуальных вычислительных кластеров искусственного интеллекта в сценариях обучения и повысить эффективность обучения.
Именно благодаря способности эффективно соединять большие данные и вычислительные кластеры искусственного интеллекта мы можем лучше использовать возможности анализа больших данных в крупномасштабном процессе обучения LLM. Например, в процессе обучения Тонги Цяньвэня мы получили большое количество повторяющейся текстовой информации. Удаление дубликатов является очень важным шагом. В противном случае весь набор обучающих данных будет смещен этими данными, что приведет к некоторым ситуациям переобучения. . производить. Мы использовали созданную нами библиотеку FlinkML для создания эффективного алгоритма дедупликации текста. Студенты, изучающие алгоритмы, могут быстро выполнять множественную дедупликацию текста и повышать эффективность разработки всей модели.

Ранее мы говорили о том, как большие данные могут помочь в обучении ИИ, и именно это мы часто слышим о «Данных для ИИ». Эффективность и текущий анализ данных также перешли от BI к BI+AI.
Второй пилот DataWorks
В прошлом анализ данных больше касался бизнес-аналитики, но теперь появилось больше технологий искусственного интеллекта, которые могут способствовать улучшению возможностей анализа данных. Мы проделали некоторую работу в этой области: например, в платформе разработки и управления данными DataWorks мы запустили DatawWorks Copilot — помощник по написанию кода. Помощник по коду может помочь пользователям использовать естественный язык для поиска интересующих таблиц, затем помочь пользователям создавать SQL-запросы и, наконец, выполнять их.
Конечно, чтобы сделать по-настоящему полезного помощника по программированию, недостаточно просто использовать базовую модель. Платформа DataWorks основана на большом количестве общедоступных запросов, а затем мы используем наш собственный язык, который является языком MaxCompute или Flink. В качестве набора данных мы берем базовую модель и выполняем тонкую настройку с этим набором данных для создания вертикальной модели. , а затем в этой вертикальной модели выполняется вывод и создается более эффективный инструмент помощи при написании кода в этом конкретном сценарии. Таким образом, нам удалось улучшить разработку кода на 30%.

Аналитика с расширенными возможностями ИИ DataWorks
В этом году мы не только помогли генерировать код, но и выпустили функцию анализа данных DataWorks. Мы можем использовать методы искусственного интеллекта и возможности искусственного интеллекта, чтобы автоматически предоставлять интеллектуальную информацию на основе существующих данных. Таким образом, мы можем позволить пользователям быстрее понять характеристики данных, тем самым ускоряя понимание и анализ данных пользователями.

Вышеизложенное предназначено для иллюстрации текущего процесса эволюции интеграции искусственного интеллекта и больших данных посредством некоторых только что упомянутых технических моментов и случаев. Мы твердо верим, что большие данные и искусственный интеллект дополняют друг друга, и мы также надеемся способствовать более быстрому внедрению и реализации анализа данных.
Microsoft официально запускает новое «приложение для Windows» .NET 8, последняя версия LTS. Xiaomi официально объявила, что Xiaomi Vela имеет полностью открытый исходный код, а базовым ядром является NuttX Alibaba Cloud 11.12. Причина сбоя раскрыта: Служба ключей доступа (Access) Ключевое) исключение Vite 5 официально выпустил отчет GitHub: TypeScript заменяет Java и становится третьим по популярности языком Предлагает вознаграждение в сотни тысяч долларов за переписывание Prettier на Rust Спрашивает автора открытого исходного кода: «Проект еще жив?» Очень грубо и неуважительный Bytedance: использование искусственного интеллекта для автоматической настройки операторов параметров ядра Linux. Магическая операция: отключить сеть в фоновом режиме, деактивировать широкополосную учетную запись и заставить пользователя сменить оптический модем.