

Em 30 de outubro, o Grupo Kunlun Wanwei lançou oficialmente a série Skywork-13B, o primeiro modelo totalmente aberto da China e o mais poderoso modelo de dezenas de bilhões. O Grupo Kunlun Wanwei lançou simultaneamente dois modelos de código aberto com 13 bilhões de parâmetros, que podem ser considerados os modelos comerciais de código aberto de alta qualidade mais completos do setor: além de modelos de código aberto e dados de treinamento de código aberto, também suporta modelos de código aberto sem necessidade de aplicação. Comercial.
O código aberto da série Skywork-13B fornecerá o melhor suporte técnico para a aplicação de cena de grandes modelos e o desenvolvimento vigoroso do código aberto da comunidade. Os algoritmos e modelos de Kunlun Wanwei e outros projetos de código aberto permitirão que pesquisadores e empresas em vários setores alcancem o dobro do resultado com metade do esforço e, ao mesmo tempo, fornecerão o apoio mais sincero para a implementação comercial de tecnologia de grandes modelos de todas as esferas da atividade. vida.
O modelo de código aberto de 13 bilhões de parâmetros fornece duas versões de modelos grandes: modelo Skywork-13B-Base, modelo Skywork-13B-Math e versão quantificada de cada modelo para apoiar a implantação e inferência dos usuários em placas gráficas de nível consumidor.
As características do projeto de código aberto Skywork são:
Modelo Skywork-13B-Base
O modelo Skywork-13B-Base é treinado em 3,2 trilhões de dados multilíngues (principalmente chinês e inglês) e de código que foram filtrados por limpeza de alta qualidade. Ele tem um bom desempenho em múltiplas avaliações e vários benchmarks. Os testes mostraram os melhores resultados para modelos do mesmo tamanho.
Modelo Skywork-13B-Math
O modelo Skywork-13B-Math foi especialmente treinado para fortalecer suas capacidades matemáticas. Na escala 13B, o modelo Skywork-13B-Math obteve a primeira pontuação na avaliação GSM8K. Ele também teve um desempenho muito bom no conjunto de dados MATH e fora dele. dados de domínio.O desempenho no CMATH também é muito bom, no nível superior do modelo 13B.
Conjunto de dados Skypile-150B
Este conjunto de dados consiste em dados de alta qualidade filtrados de páginas da web chinesas de acordo com nosso processo de processamento de dados cuidadosamente filtrado. O tamanho do conjunto de dados de código aberto desta vez é de cerca de 600 GB e o número total de tokens é de cerca de 150 B. Atualmente é um dos maiores conjuntos de dados chineses de código aberto.
Além disso, também divulgamos os métodos de avaliação, pesquisa de relação de dados e soluções de ajuste de infraestrutura de treinamento utilizadas no treinamento do modelo Skywork-13B. Esperamos que estes conteúdos de código aberto possam inspirar ainda mais a compreensão da comunidade sobre o pré-treinamento de modelos em grande escala e promover a realização da inteligência artificial geral (AGI).
Conjuntos de dados chineses de alta qualidade podem ser baixados do Huggingface. Para obter detalhes, consulte o espaço oficial do Github ⬇ ️
Endereço de download do Skywork-13B (Github) :
https://github.com/SkyworkAI/Skywork
Estrutura do modelo
Comparado com o modelo LLaMA2-13B, o modelo Skywork-13B adota uma estrutura de rede relativamente mais fina com 52 camadas, ao mesmo tempo, o FFN Dim e o Hidden Dim são reduzidos para 12288 e 4608, garantindo assim que o número de parâmetros do modelo seja o mesmo do LLaMA-13B original. O modelo é comparável. De acordo com nossa comparação experimental preliminar, uma estrutura de rede relativamente delgada pode obter melhores efeitos de generalização sob treinamento de lote grande. A comparação entre os modelos Skywork-13B e LLaMA-2-13B é a seguinte:

dados de treinamento
Dados de páginas da web em inglês 39,8% Dados de livros 3,6% Artigos acadêmicos 3,0% Enciclopédia 2,9% Outros (relatórios anuais, documentos, etc.) 2,9% Dados de páginas da web em chinês 30,4% Dados de mídia social 5,5% Enciclopédia 0,8% Outros (relatórios anuais, documentos, etc.) 3,1% código GitHub 8,0%

Método de treinamento:
Desta vez, o modelo da série de código aberto Skywork-13B também abre o método de treinamento de todo o modelo. Para fazer um uso mais refinado dos dados, é adotado um método de treinamento em duas etapas. Na primeira etapa, o corpus geral é usado para aprender as capacidades gerais do modelo. Na segunda etapa, STEM (Ciência, Tecnologia, Engenharia, Dados relacionados à matemática) são adicionados para aprimorar ainda mais o raciocínio e as habilidades matemáticas do modelo., capacidade de resolução de problemas. (Para obter detalhes, consulte o documento de download da comunidade de código aberto)
Avaliação do modelo
- Avaliação de perplexidade de dados de domínio
A essência do treinamento do modelo de linguagem é tornar a previsão da próxima palavra mais precisa. Com base nesse entendimento, acreditamos que uma forma importante de avaliar grandes modelos básicos é avaliar a probabilidade de modelos de linguagem gerarem artigos em diversas áreas importantes. No treinamento do modelo, a função de perda de entropia cruzada é geralmente usada para prever a probabilidade da próxima palavra.A função de perda geral é a perda média de previsão da palavra real em cada posição, como segue:
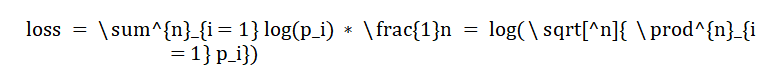
onde ![]() é o comprimento do documento, ou seja, o número de tokens, e
é o comprimento do documento, ou seja, o número de tokens, e ![]() é a probabilidade da palavra real na posição I. Sabemos que a multiplicação da probabilidade da palavra real em cada posição do documento é a probabilidade de gerando o documento, então combinamos a perda e o artigo gerado. As probabilidades estão interligadas. Diferentes modelos possuem diferentes números de tokens porque utilizam diferentes separadores de palavras, portanto, a função de perda é multiplicada pelo número de tokens,
é a probabilidade da palavra real na posição I. Sabemos que a multiplicação da probabilidade da palavra real em cada posição do documento é a probabilidade de gerando o documento, então combinamos a perda e o artigo gerado. As probabilidades estão interligadas. Diferentes modelos possuem diferentes números de tokens porque utilizam diferentes separadores de palavras, portanto, a função de perda é multiplicada pelo número de tokens, ![]() de forma que apenas a parte probabilística da geração de artigos seja considerada, e diferentes modelos também possam ser comparados. Convertemos o índice de perda normalizado em perplexidade para tornar a diferença no modelo mais legível. Para fins de leitura, a perda e o ppl mencionados posteriormente são a perda e a perplexidade após a padronização do modelo.
de forma que apenas a parte probabilística da geração de artigos seja considerada, e diferentes modelos também possam ser comparados. Convertemos o índice de perda normalizado em perplexidade para tornar a diferença no modelo mais legível. Para fins de leitura, a perda e o ppl mencionados posteriormente são a perda e a perplexidade após a padronização do modelo.
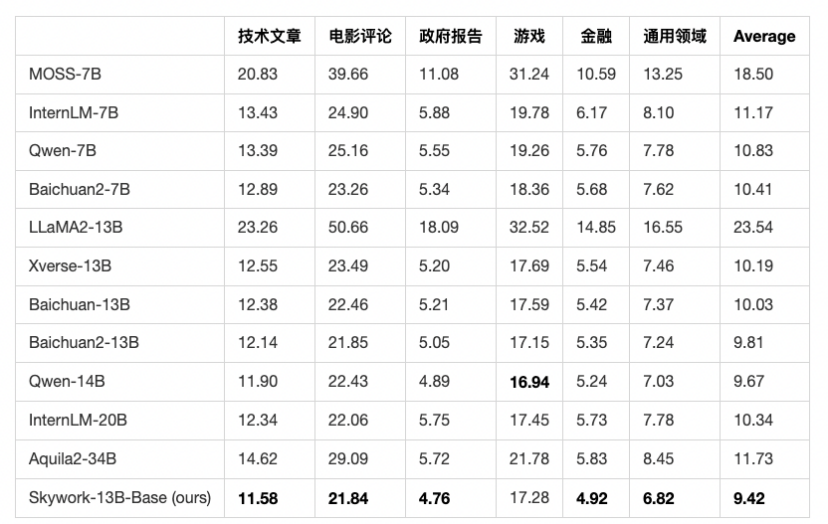
Com base na análise acima, selecionamos centenas a milhares de artigos de alta qualidade publicados recentemente em outubro de 2023 em vários campos e os verificamos manualmente. Certifique-se de que todos os dados de teste não estejam no conjunto de treinamento do modelo Tiangong e de todos os outros modelos, e que a fonte dos dados de teste seja ampla o suficiente e de alta qualidade. Podemos selecionar os artigos mais recentes para avaliar as pessoas de diferentes modelos.É difícil para os modelos trapacearem. A figura abaixo lista diferentes modelos de código aberto. Tiangong Skywork-13B-Base alcança os melhores resultados, provando que os recursos básicos do modelo Skywork Base estão no nível mais forte entre os modelos chineses de código aberto na China.
- Avaliação de referência
Avaliamos os resultados nos principais benchmarks de avaliação confiáveis como referência, incluindo C-Eval, MMLU, CMMLU e GSM8K. Seguindo o processo de avaliação anterior, C-Eval, MMLU e CMMLU testam resultados de 5 tentativas, e GSM8K testa resultados de 8 tentativas. Pode-se ver que o modelo Skywork-13B-Base está na vanguarda dos modelos chineses de código aberto e é o nível ideal na mesma escala de parâmetros.

O apoio mais sincero ao uso comercial de código aberto: não há necessidade de inscrição, o uso comercial pode ser alcançado
Atualmente, a maioria dos grandes modelos chineses na comunidade de código aberto não estão totalmente disponíveis comercialmente. Geralmente, os usuários da comunidade de código aberto geralmente precisam passar por um processo complexo de solicitação de autorização comercial. Em alguns casos, existem até regulamentos claros sobre tamanho da empresa, indústria, número de usuários e outras dimensões. Nenhuma licença comercial concedida. Kunlun Wanwei atribui grande importância à abertura e comercialização do código aberto Skywork-13B, simplificando o processo de autorização e removendo restrições à indústria, tamanho da empresa, usuários, etc., com o objetivo de ajudar mais pessoas interessadas nos grandes modelos chineses. usuários e empresas estão constantemente explorando e progredindo na indústria. Portanto, desta vez, quando o código-fonte do Skywork-13B for aberto, abriremos totalmente a licença comercial do modelo grande do Skywork-13B. Depois de baixar o modelo, os usuários concordam e cumprem o "Contrato de licença da comunidade do modelo Skywork" e podem usar o grande modelo sem solicitar autorização novamente. Para fins comerciais, o objetivo é facilitar aos usuários o uso do Skywork-13B para realizar testes e explorar aplicações comerciais em diferentes cenários.

Cadastre-se na plataforma aberta para saber mais sobre as informações do produto 1 3B
O Alibaba Cloud sofreu uma falha grave e todos os produtos foram afetados (restaurados). O Tumblr esfriou o sistema operacional russo Aurora OS 5.0. Nova UI revelada Delphi 12 e C++ Builder 12, RAD Studio 12. Muitas empresas de Internet recrutam urgentemente programadores Hongmeng. Hora do UNIX . está prestes a entrar na era de 1,7 bilhão (já entrou). Meituan recruta tropas e planeja desenvolver o aplicativo do sistema Hongmeng. Amazon desenvolve um sistema operacional baseado em Linux para se livrar da dependência do Android do .NET 8 no Linux. O tamanho independente é reduzido em 50%.O FFmpeg 6.1 "Heaviside" é lançado