Llama 2 é a última geração de grandes modelos de código aberto lançados oficialmente pela Meta AI, atingindo 2 trilhões de tokens . O modelo de bate-papo aprimorado foi treinado em 1 milhão de dados anotados por humanos . O Llama 2 supera outros modelos de linguagem de código aberto em muitos benchmarks externos, incluindo testes de inferência, codificação, domínio e conhecimento.
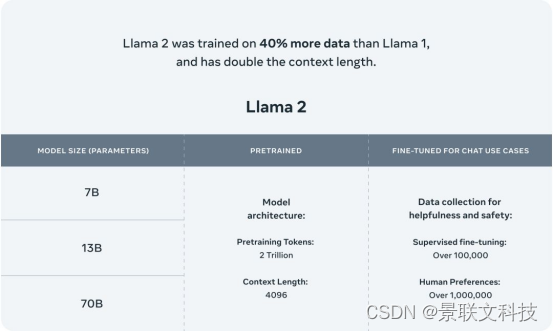
Llama 2 abre um novo capítulo no compartilhamento de modelos de IA em grande escala em todo o mundo. Inclui pesos de modelo e código inicial para pré-treinamento e ajuste fino de modelos de linguagem Llama com parâmetros que variam de 7 bilhões a 70 bilhões. Comparado com o modelo da geração anterior, o Llama 2 usa mais dados de treinamento e duplica diretamente o comprimento do contexto para 4.096. Além disso, o Llama 2 supera os modelos convencionais atuais no julgamento humano, incluindo conversas de rodada única e de rodada múltipla com duração de contexto de 4K.
O Llama 2 é muito semelhante ao modelo de primeira geração em termos de configurações de pré-treinamento e arquitetura do modelo.

Conforme mostrado na figura, todos os modelos da série Llama usam a arquitetura autoregressiva do Transformer, ou seja, a arquitetura somente decodificador do Transformer. A consistência foi mantida entre as duas gerações de modelos. Essa consistência se reflete nos seguintes aspectos:
Pré-normalização: A entrada da subcamada de cada transformador é normalizada e a função de normalização RMSNorm é usada para garantir que o modelo seja treinado de forma mais estável e eficiente.
Função de ativação SwiGLU: Use a função de ativação SwiGLU na rede neural feedforward (FFN) para substituir a função de ativação ReLU no Transformer, melhorando assim o desempenho do modelo.
Rotary Positional Embeddings (RoPE): RoPE permite que o modelo processe informações de posição relativa e posição absoluta simultaneamente, melhorando assim a capacidade de generalização do modelo. O uso desta técnica ajuda o modelo a compreender e processar melhor as informações da sequência.
Os dados são a chave para melhorar o desempenho do modelo. O Llama 2 não apenas aumenta a quantidade de dados de treinamento em 40% em comparação com a geração anterior do Llama 1, mas a fonte e a riqueza dos dados também foram significativamente aprimoradas.
O impacto da qualidade dos dados no modelo Llama 2 é muito significativo. O uso de dados de conversação de código aberto de baixa qualidade pode levar a um desempenho insatisfatório do modelo. Pelo contrário, se forem utilizados dados de diálogo de maior qualidade, o desempenho do modelo será significativamente melhorado. Portanto, quando Meta treinou o modelo Llama 2, ele rastreou rigorosamente os dados e selecionou dados de diálogo de alta qualidade.
Além disso, diferentes fontes de dados podem ter um impacto significativo nos resultados ajustados, o que realça ainda mais a importância da qualidade dos dados. Para verificar a qualidade dos dados, Meta examinou cuidadosamente 180 amostras e comparou os resultados da geração do modelo revisados manualmente com os resultados escritos por humanos. Os resultados mostram que os dados revisados por humanos também são competitivos com os dados escritos por humanos, o que significa que dados de alta qualidade são cruciais para o treinamento de modelos de conversação. Portanto, Meta despendeu muito esforço para coletar dados de feedback humano de alta qualidade ao treinar o modelo Llama 2.
Ao aumentar a quantidade de dados, melhorar a qualidade dos dados, aumentar a diversidade dos dados e melhorar a anotação dos dados, o efeito e o desempenho do modelo podem ser significativamente melhorados, permitindo que o modelo alcance resultados ideais, construindo assim uma IA mais inteligente, eficiente e precisa. formulários.
Somente dados de alta qualidade podem permitir que o modelo aprenda regras linguísticas e gramática corretas, reduzindo a possibilidade de preconceitos e mal-entendidos; dados de múltiplas fontes e origens podem aumentar a capacidade de generalização do modelo, permitindo-lhe adaptar-se a diferentes cenários e estilos de linguagem ; A anotação correta dos dados também é muito importante para o treinamento do modelo, pois pode ajudar o modelo a compreender melhor o significado e os objetivos dos dados de entrada, gerando melhor saída.
A Jinglianwen Technology tem vasta experiência em projetos de coleta e rotulagem de dados de texto e pode fornecer coleta de dados relacionados a texto e serviços de rotulagem de dados para grandes modelos de IA. A própria plataforma de gerenciamento de dados oferece suporte ao processamento de linguagem natural: limpeza de texto, transliteração de OCR, análise de sentimentos, marcação de classes gramaticais, escrita de frases, correspondência de intenções, julgamento de texto, correspondência de texto, extração de informações de texto, generalização de frases NLU, tradução automática, etc. Digite anotação de dados. Ao abrir o ciclo fechado de dados, a distribuição de dados, limpeza, anotação, inspeção de qualidade e outros links podem ser realizados de maneira ordenada, fornecendo dados de treinamento de alta qualidade, melhorando a eficiência do treinamento de dados de IA empresarial e acelerando a implementação ciclo de iteração de aplicações relacionadas à inteligência artificial.

Tecnologia Jinglianwen|Coleta de dados|Anotação de dados
Promover a tecnologia de inteligência artificial e capacitar a transformação e modernização inteligentes das indústrias tradicionais
Os direitos autorais dos gráficos e texto do artigo pertencem à Jinglianwen Technology. Para reimpressão comercial, entre em contato com a Jinglianwen Technology para autorização. Para reimpressão não comercial, indique a fonte.