Índice
- escreva na frente
- definição de substantivo
- Política de trânsito relacionada
-
- Pergunta 1: Os serviços de primeiro nível serão despejados? Caso contrário, o que acontecerá se o serviço de primeiro nível falhar? Existe alguma maneira de falhar rapidamente?
- Pergunta 2: Devem ser criados pools de conexões para serviços secundários e pós-secundários? Se um pool de conexões for configurado, seu serviço downstream será removido porque o pool de conexões de serviço upstream transbordará se a detecção de valores discrepantes estiver configurada?
- Pergunta 3: Se os pools de conexões não forem configurados para serviços secundários e subsequentes, como esses serviços secundários deverão ser protegidos do impacto de um grande tráfego? É limitação de taxa através do envoyfilter?
- Pergunta 4: Se for HTTP/2, as restrições do connectionPool entram em vigor? Por que o HTTP/2 estabelece duas conexões por instância?
- Pergunta 5: Como é implementado o disjuntor do serviço upstream?
- Pergunta 6: O tamanho do pool de conexões está definido para limitar o fluxo atual?
- Pergunta 7: Dentro de um grid pod, qual é a relação entre o link do aplicativo com o sidecar e o link do sidecar com o serviço upstream?
- Pergunta 8: Depois que o pool de conexões transbordar e causar um disjuntor, o serviço downstream receberá 503. Quem retorna esse 503?
escreva na frente
Devido às necessidades do negócio, atualizamos nossa arquitetura técnica e, depois de muitas comparações, finalmente escolhemos o servicemesh de framework de tecnologia de ponta... um dos representativos é o istio. Depois de entrar no poço, descobri que realmente não há muita informação sobre isso na China. Embora várias configurações sejam introduzidas em documentos oficiais, a maioria delas é brevemente mencionada em alguns traços. Quando é realmente usado na produção, , você precisa explorar constantemente seu mecanismo de implementação por conta própria, caso contrário não saberá por que esse parâmetro está definido dessa forma e se essa configuração é apropriada para o seu cenário de negócios.
Embora o istio seja uma estrutura de código aberto, como função de operação e manutenção, não tenho um conhecimento profundo de código. Não posso analisar diretamente a essência estudando o código como muitos grandes mestres. Portanto, só posso encontrar a "verdade" por meio de prática e experimentos constantes., este artigo tem como objetivo registrar as várias questões que encontrei no processo de uso do istio. Algumas foram realmente verificadas e outras não têm resultados específicos e precisam ser continuamente exploradas em trabalhos e estudos subsequentes.
O artigo será atualizado continuamente para adicionar novos problemas, resolver problemas antigos ou atualizar problemas antigos.
definição de substantivo
Nível de serviço
注意:以下设定仅是本文为方便描述自行定义。
-
Serviço de primeiro nível: neste artigo, refere-se ao serviço que é mapeado diretamente pela porta do ingressgateway e pode ser chamado diretamente de fora do cluster.
-
Serviços de segundo nível: serviços chamados por serviços de primeiro nível, serviços de terceiro e quarto níveis, e assim por diante.
Nota: Os níveis de serviço aqui são relativos e não absolutos, pretendendo facilitar a posterior explicação da relação de chamada entre cada serviço. Por exemplo, se houver três serviços A\B\C, um serviço mapeia o gateway de entrada, A chama B e B chama C, então A é o serviço de primeiro nível, B é o serviço de segundo nível e C é o terceiro. serviço de nível. Se houver um D que também mapeie o gateway de entrada e D chamar C, então C será o serviço secundário.
Política de trânsito relacionada
Pergunta 1: Os serviços de primeiro nível serão despejados? Caso contrário, o que acontecerá se o serviço de primeiro nível falhar? Existe alguma maneira de falhar rapidamente?
Resposta: (resposta inferida)
以下仅为推论,我还没有实际证据证明,希望有同学了解的,给一个准确答案:
1. Não possui serviços downstream (se não incluir o ingressgateway) e não há serviço para realizar detecção passiva de valores discrepantes.Desde que não seja devido a problemas de verificação de integridade, a instância não deve ser despejada, mas a integridade problemas de verificação ainda ocorrerão. será expulso.
2. O serviço de primeiro nível é um serviço chamado diretamente fora do cluster, portanto, o serviço (ou cliente) que o chama externamente deve definir políticas correspondentes, como tempo limite, nova tentativa, etc. também defina o que acontece se a solicitação falhar, exibir problemas, etc.
Pergunta 2: Devem ser criados pools de conexões para serviços secundários e pós-secundários? Se um pool de conexões for configurado, seu serviço downstream será removido porque o pool de conexões de serviço upstream transbordará se a detecção de valores discrepantes estiver configurada?
Resposta: (consulte a pergunta 8)
Pergunta 3: Se os pools de conexões não forem configurados para serviços secundários e subsequentes, como esses serviços secundários deverão ser protegidos do impacto de um grande tráfego? É limitação de taxa através do envoyfilter?
Resposta: (consulte a pergunta 8)
envoyfilter进行限速是可行的,但是在生产中如何应用,需要持续探索
Pergunta 4: Se for HTTP/2, as restrições do connectionPool entram em vigor? Por que o HTTP/2 estabelece duas conexões por instância?
responder:
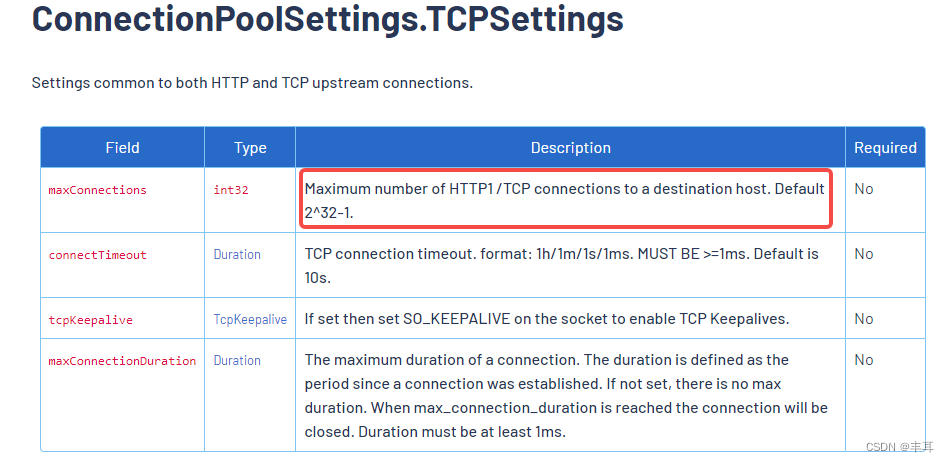
Se você usar HTTP/2, então connectionPool não terá sentido. Normalmente, há apenas um link entre duas instâncias de HTTP/2, portanto, definir mais ou menos não afetará o HTTP/2. E a documentação oficial é relativamente clara:
Mas ao usar HTTP/2 descobriremos que ele criará dois links. Procurei informações na Internet:
O proxy do Istio estabelece duas conexões TCP ao se comunicar por HTTP/2. Isso ocorre porque o proxy do Istio precisa multiplexar em duas conexões TCP. Uma das conexões TCP é usada para fluxo de controle e a outra conexão TCP é usada para fluxo de dados. Os quadros no fluxo de controle são usados para controlar o fluxo de mensagens, enquanto os quadros no fluxo de dados contêm os dados reais de solicitação e resposta.
Nota: Não estou muito familiarizado com protocolos de comunicação, se houver algum erro, corrija-me.
Pergunta 5: Como é implementado o disjuntor do serviço upstream?
responder:
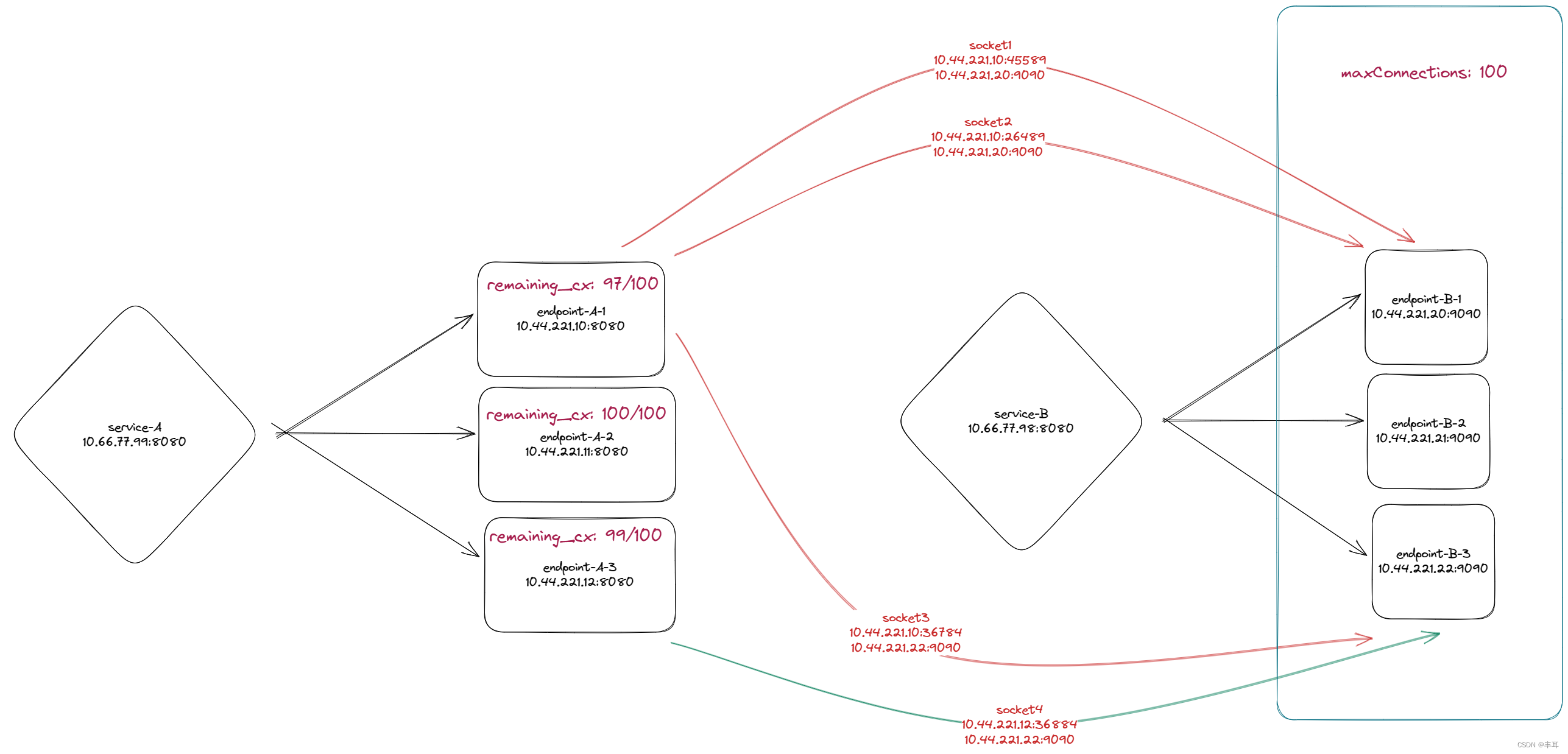
- No protocolo http/1.1, o serviço upstream configura o connectionPool na regra de destino e define o número máximo de conexões TCP de cada instância downstream para o cluster upstream em tcp.maxConnections.
ilustrar:
O número máximo de conexões TCP entre cada instância do serviço downstream e o cluster do serviço upstream, ou seja, se o serviço downstream tiver três instâncias e o serviço upstream também tiver três instâncias, e o serviço upstream definir o número máximo de conexões para 100, então a instância 1 do serviço downstream é igual ao serviço upstream. A soma máxima do número de conexões entre duas instâncias do serviço é 100. A soma do número máximo de conexões entre a instância 2 do serviço downstream e o serviço upstream também é 100. O mesmo se aplica à instância 3.
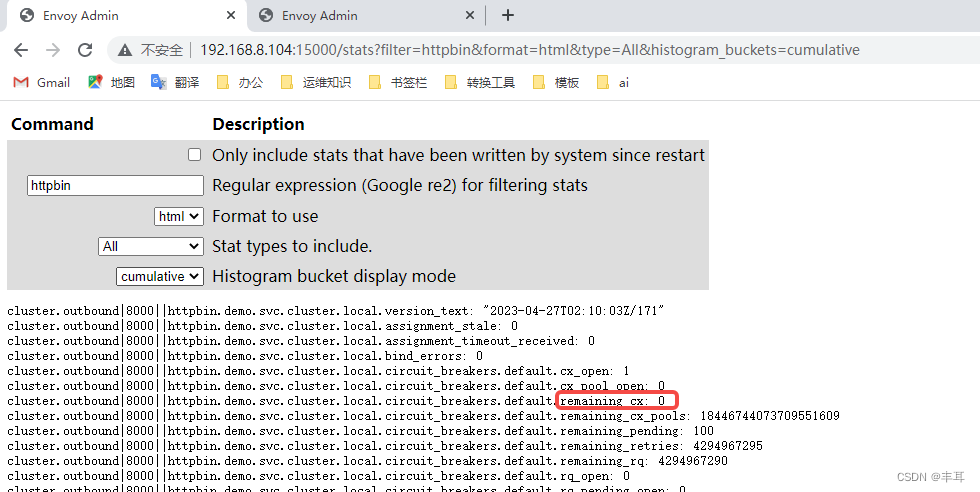
Em vez de dizer que o número máximo de conexões entre o cluster downstream e o cluster upstream é 100. O valor deste controle pode ser consultado em restantes_cx em 15000/stat do istio-proxy, conforme mostrado no exemplo abaixo.
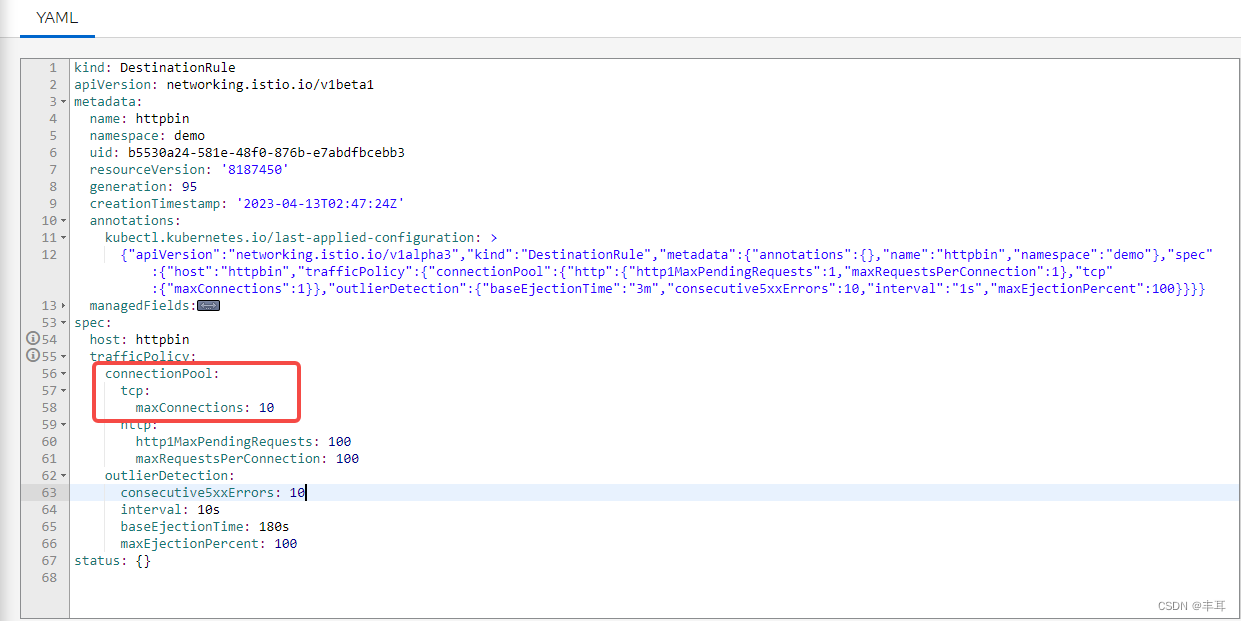
verificar:
httpbin define o número máximo de conexões para 10
Existem dois casos fortio aqui:
注意看访问的映射端口是不同的,一个是15000,一个是25000
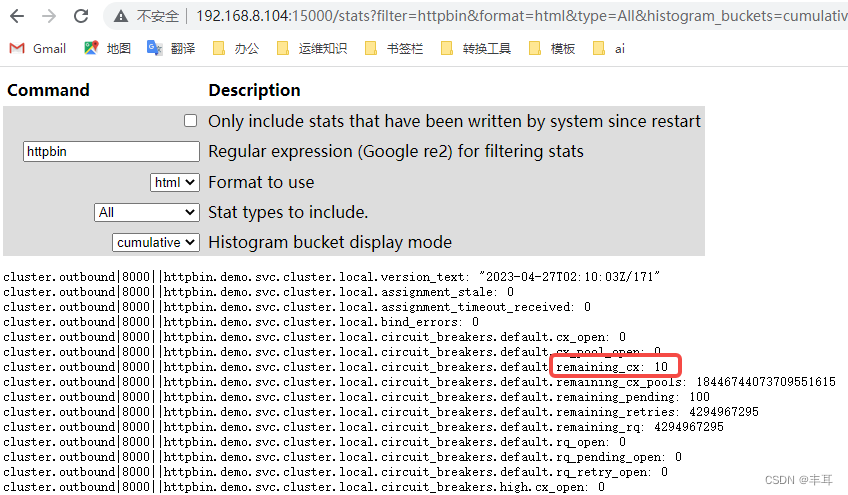
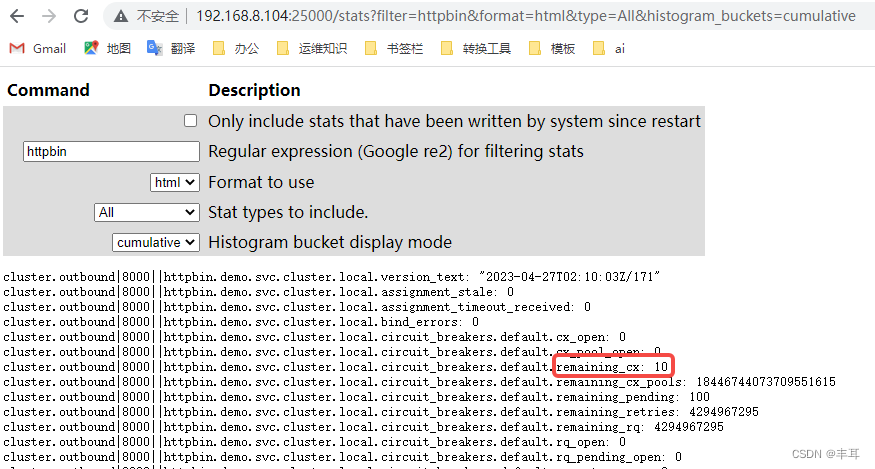
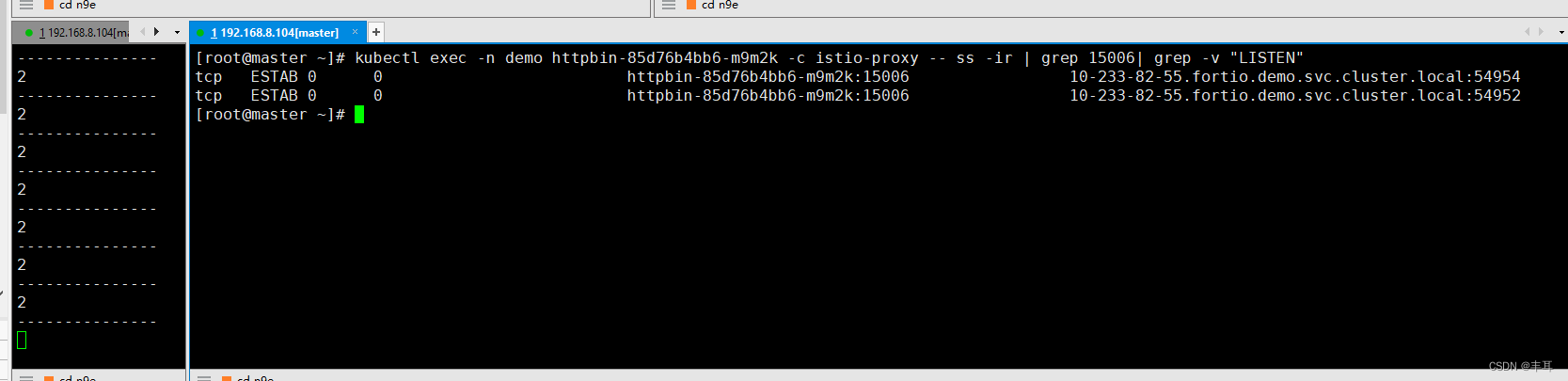
可以看到每个都是显示剩余10个连接。
Então olhe para httpbin, cada conexão de 15006 é 0 (para exibir os resultados mais claramente, apenas fortio chama httpbin, então apenas filtre as conexões de 15006 diretamente)
- A primeira etapa é iniciar uma chamada de um fortio:

10 simultaneidades são iniciadas diretamente. Para durar mais, enviamos 2.000.000 solicitações. Você pode ver que o valor de restantes_cx neste momento se tornou 0,
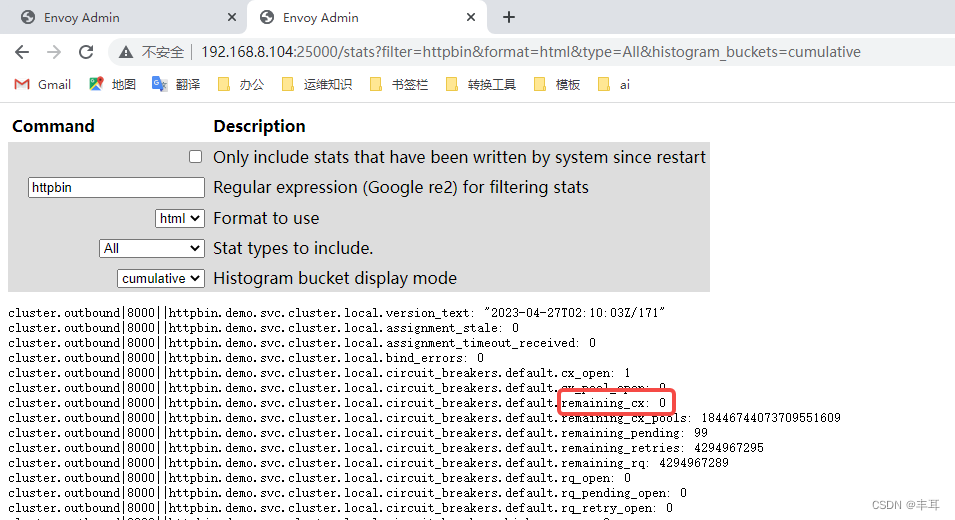
mas o restante_cx de outro pod foi alterado. O valor ainda é 10.
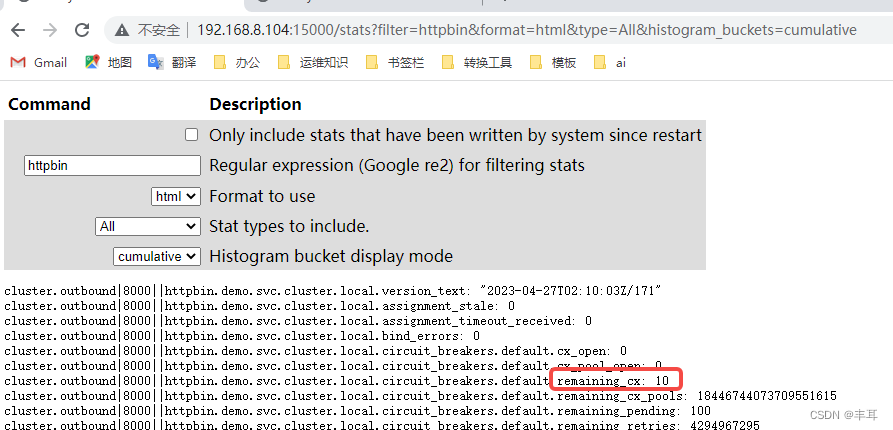
Observe o número de conexões nos três httpbins. A soma dos três pods é 10. Nesse momento, o número de simultaneidade é aumentado e a soma de suas somas também é 10.
- Então iniciamos outro pod e a soma das conexões de solicitação ao httpbin
já é 20.
-
Então, uma única instância httpbin excederá o conjunto de 10 conexões? Vamos mudar fortio para 3 instâncias e httpbin para 2 instâncias para testá-lo.

Obviamente, uma única instância excederá o número máximo de conexões definido. Isso também prova que o número máximo de conexões TCP é limitado. é o número de conexões entre uma única instância do serviço downstream e o cluster de serviço upstream. -
No protocolo http/1.1, em relação à configuração de maxRequestsPerConnection, os alunos que entendem o protocolo http devem entender o que está acontecendo. Mesmo no estado de link longo, http/1.1 só pode enviar uma solicitação por vez e não iniciará outra request até retornar., após atingir o número máximo de solicitações, a conexão será encerrada e uma nova conexão será estabelecida. Desta forma, todos entenderão o papel deste parâmetro na configuração do istio.
-
Não há muito a dizer sobre http1MaxPendingRequests, ele está apenas aguardando a fila, que é eficaz tanto para http/1.1 quanto para http2.
Com base nisso, podemos simplesmente deduzir a relação entre o número máximo de conexões e o número de instâncias de serviços upstream e downstream:
Tenho apenas meio nível em matemática e minha dedução está errada. Corrija-me.
B服务单个实例可承受最大链接数a,B服务设置最大连接数x,共有y个实例
A服务作为下游服务,共计b个实例,每个实例到B服务都可以发起x个链接,所以B服务共可以发起xb个链接
要使B服务不会过载,则应该满足:xb/y<=x<=a
当x=a时:
b/y<=1
b<=y
当x<a时:
b/y<a/x
由此可知:b<=ay/x
Esta é apenas uma derivação simples. A situação real é muito mais complicada do que isso, e cálculos específicos precisam ser feitos com base na situação real.
Pergunta 6: O tamanho do pool de conexões está definido para limitar o fluxo atual?
responder:
Há uma certa conexão entre a configuração do tamanho do pool de conexões e o limite atual, mas eles não são iguais.
O tamanho do pool de conexões é definido para limitar o número de conexões estabelecidas e mantidas com outros serviços, evitando assim sobrecarga de conexão ou desperdício de recursos, ao mesmo tempo em que otimiza o desempenho e a estabilidade do aplicativo.
A limitação atual limita o tráfego do aplicativo e a carga de solicitações, limitando o número de solicitações que podem ser processadas por segundo. No Istio, a limitação atual pode ser alcançada por meio de configurações de cotas baseadas em regras.
A diferença entre os dois é que o tamanho do pool de conexões é definido para o número de conexões estabelecidas e mantidas, enquanto o limite atual é definido para o número de solicitações que podem ser processadas por segundo. Embora a configuração do tamanho do pool de conexões possa controlar o tráfego do aplicativo até certo ponto, ela não é uma implementação direta da limitação de corrente.
Resumindo, a configuração do tamanho do pool de conexões e a limitação de corrente são meios de otimizar o desempenho e a estabilidade do aplicativo, mas são dois conceitos e métodos de implementação diferentes.
Pergunta 7: Dentro de um grid pod, qual é a relação entre o link do aplicativo com o sidecar e o link do sidecar com o serviço upstream?
responder:
- Se for HTTP/2, não há nada a dizer, é tudo um único link longo.
- Se o aplicativo usar HTTP/1.1, o arquivo secundário usará HTTP/1.1 para o upstream por padrão, a menos que seja configurado de outra forma. Embora o envoy suporte a conversão entre HTTP/1.1 e HTTP/2, o istio acredita que se você converter HTTP/1.1 e HTTP/2 à força, isso pode afetar a estabilidade, precisão, etc., como durante o processo de transmissão de HTTP/2 Uma vez o pacote for perdido, problemas ocorrerão facilmente no lado HTTP/1.1. Falando nisso, outro recurso do envoy pode ser introduzido: para o próprio envoy, seus links upstream e downstream são desacoplados, e é por isso que ele pode converter HTTP/1.1 e HTTP/2. O motivo: já que o envoy desacopla os links upstream e downstream, não existe uma relação inevitável entre os links upstream e downstream. No entanto, a correlação positiva indireta ainda existe, afinal, há mais links e solicitações downstream e, no âmbito do pool de conexões, os links e solicitações upstream também aumentarão.
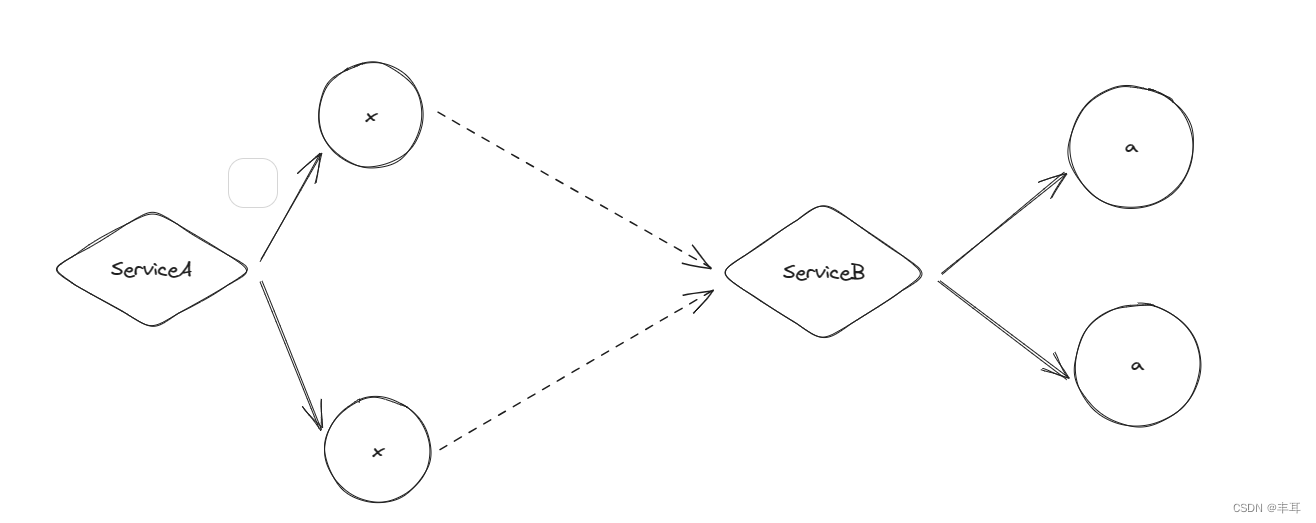
Vamos usar o exemplo do bookinfo para explicar:
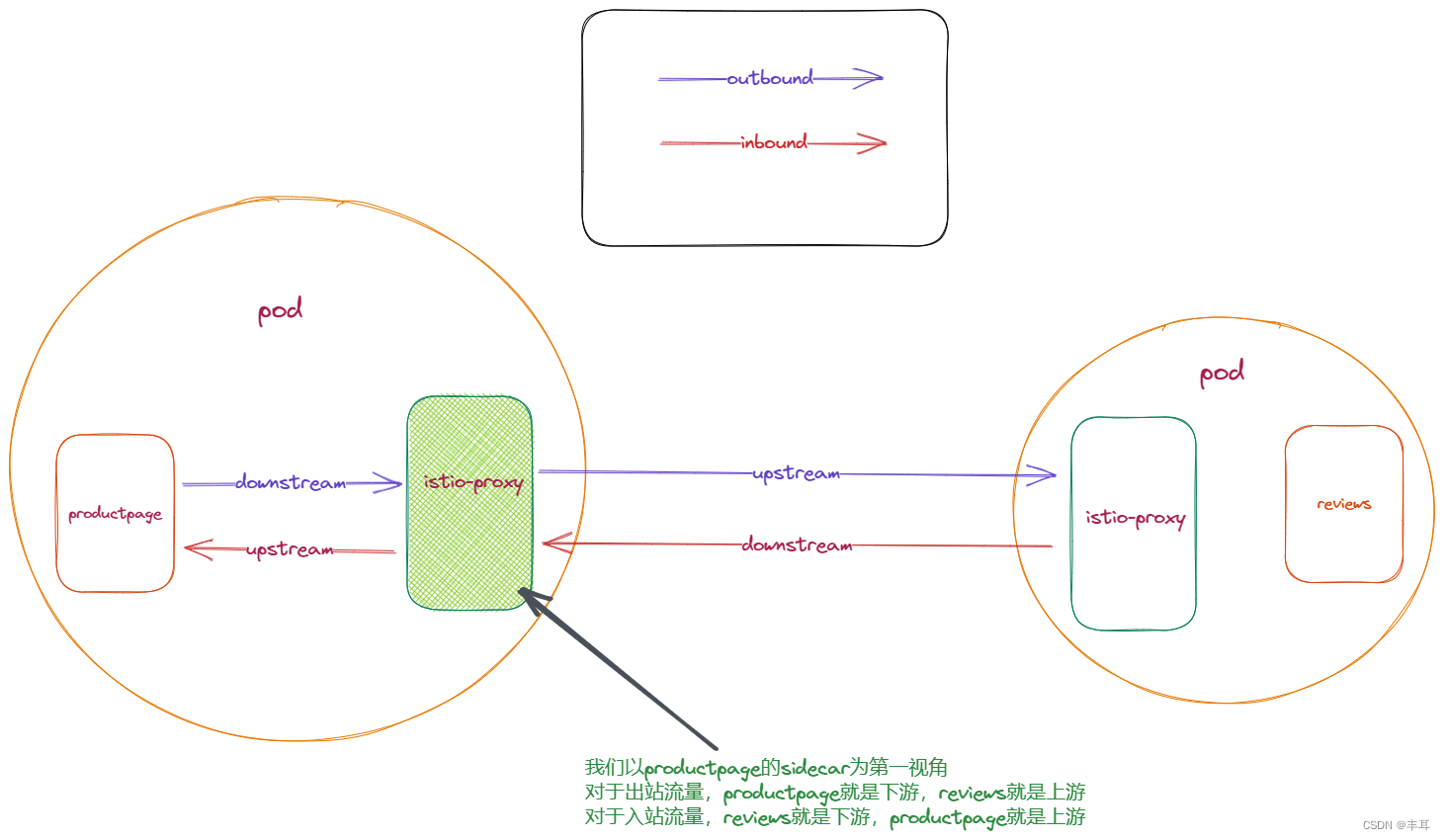
upstream e downstream são relativos. Quando olhamos para links da perspectiva do sidecar, para o tráfego de saída, seu downstream é o aplicativo no mesmo pod, e o upstream é o cluster de destino. Para tráfego de entrada. é exatamente o oposto.
Independentemente de ser de saída ou de entrada, o sidecar é desacoplado de seus links upstream e downstream. Em outras palavras, o ciclo de vida de seus links upstream e downstream é inconsistente. Por exemplo, ao usar HTTP/1.1, o upstream pode ter 100 links e o downstream pode ter 50 links. Para outro exemplo, para saída, o downstream é HTTP /1.1. Na configuração h2UpgradePolicy: UPGRADE, o upstream é HTTP/2.
Pergunta 8: Depois que o pool de conexões transbordar e causar um disjuntor, o serviço downstream receberá 503. Quem retorna esse 503?
responder:
503 retornados pelo sidecar do serviço atual.
No istio, se o pool de conexões estiver esgotado, o envio de outra solicitação causará um disjuntor de estouro. Neste momento, 503 é retornado pelo Envoy . Isso ocorre porque o Envoy armazena em cache as conexões com os serviços upstream. Se as conexões com os serviços upstream falharem ou forem fechadas, o Envoy tentará enviar solicitações por meio dessas conexões, fazendo com que as conexões sejam redefinidas. O Envoy encapsulará esse erro em um 503 e o retornará. para o chamador downstream.
Análise:
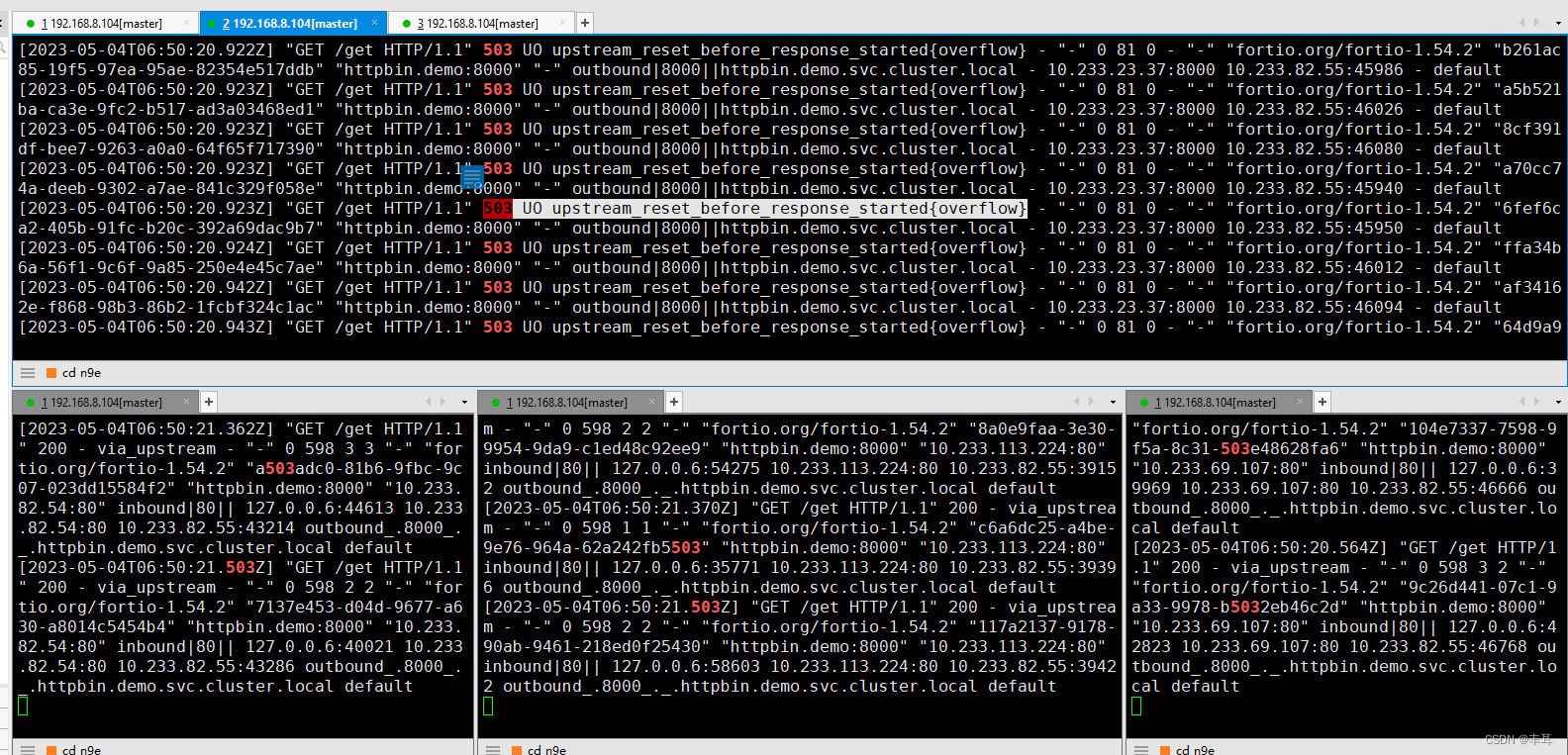
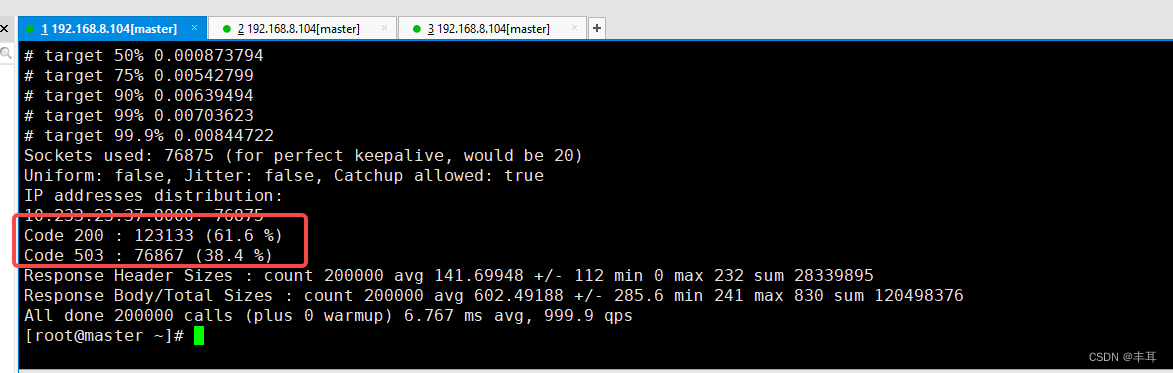
Primeiro, vemos que quando ocorre um erro 503, apenas o sidecar fortio do iniciador de solicitação apresenta um grande número de 503 erros, enquanto há apenas 200 no sidecar do httpbin;
Vejamos o log de retorno do fortio:503 UO upstream_reset_before_response_started{overflow}
Este erro indica que o pool de conexões do serviço upstream estourou, fazendo com que a solicitação fosse redefinida. UO é o sinalizador de resposta do Envoy, o que significa overflow upstream com interrupção de circuito , o que significa que o número de conexões com o serviço upstream excede o limite do fusível. Overflow é o tipo de redefinição do Envoy, indicando que o pool de conexões está esgotado. Como analisamos acima, o contador do pool de conexão está no sidecar do serviço downstream.Também é afirmado aqui indiretamente que este 503 deve ser o código de status gerado pelo próprio sidecar do fortio.
Isso também é afirmado na documentação do enviado:
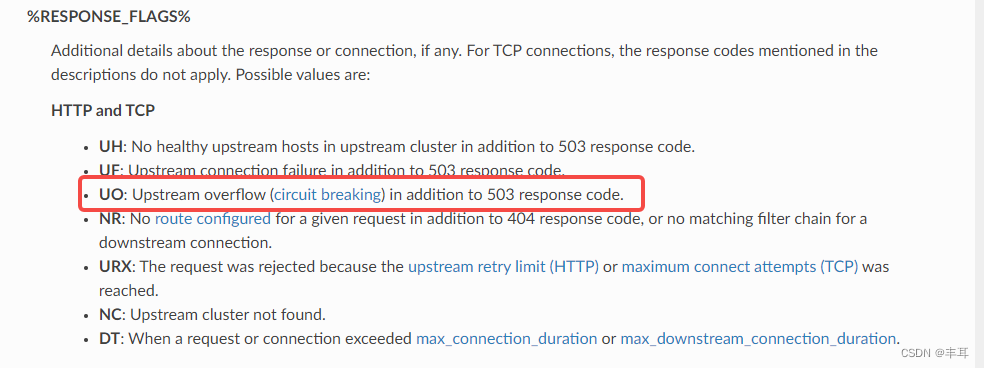
Com base no ponto de vista acima, acredita-se que o código de status 503 não seja retornado pelo serviço upstream, mas o sidecar do serviço atual é gerado automaticamente e retornado ao aplicativo downstream após julgamento com base no estouro do pool de conexões. em outras palavras, esse erro ocorre antes do balanceamento de carga. O Envoy descobriu que o número de conexões atingiu o limite do disjuntor antes de selecionar a instância de serviço upstream, portanto, rejeitou diretamente a solicitação sem realizar o balanceamento de carga.
Ao mesmo tempo, durante vários testes, nenhuma detecção de outlier foi acionada, o que também prova que o serviço retornado não deve ser o serviço upstream. Por sua vez, parece provar que o estouro do pool de conexões não aciona a detecção de valores discrepantes.