Link original: https://arxiv.org/abs/2307.02270
1. Introdução
Os métodos atuais para gerar representações de pseudo-sensores a partir de câmeras monoculares dependem de redes pré-treinadas de estimativa de profundidade. Esses métodos exigem rótulos de profundidade para treinar a rede de estimativa de profundidade, e métodos pseudo-estéreo sintetizam imagens estéreo por meio de deformação direta de imagens, o que pode levar a artefatos de pixel, distorções e buracos em áreas ocluídas. Além disso, a geração de pseudoestereogramas em nível de recurso é difícil de aplicar diretamente e tem adaptabilidade limitada.
Então, como contornar a estimativa de profundidade e projetar um gerador de perspectiva no nível da imagem? Comparado ao GAN, o modelo de difusão tem uma estrutura mais simples, menos hiperparâmetros e etapas de treinamento mais simples, mas atualmente não há pesquisas sobre geração de pseudo-visualização para detecção de alvos 3D.
Este artigo projeta um modelo de difusão de visão única (SVDM) para síntese de pseudo-visão. O SVDM assume que a imagem da vista esquerda é conhecida, substitui o ruído gaussiano pelos pixels da imagem à esquerda e difunde gradualmente os pixels da imagem à direita para toda a imagem. Devido à paralaxe sutil das imagens estereoscópicas, bons resultados podem ser produzidos em apenas algumas etapas. O SVDM não usa informações profundas e pode ser treinado de ponta a ponta.
3. Método
3.1 Conhecimento de preparação
3.1.a Detector 3D estéreo
Ele pode ser dividido em 3 categorias: modelos que requerem apenas treinamento de imagem estéreo (como Stereo R-CNN), modelos que requerem treinamento adicional de verdade em profundidade (YOLOStereo3D) e modelos baseados em grades de volume (como LIGA-Stereo).
3.1.b Modelo de probabilidade de difusão com eliminação de ruído (DDPM)
Para obter detalhes , consulte Introdução ao modelo de difusão . O objetivo do DDPM é otimizar o limite inferior de confiança (ELBO). A maioria dos modelos de difusão condicional retém o processo de difusão e adiciona a condição yyDetermine a função de y : E t , x 0 , ϵ [ ∥ ϵ − ϵ θ ( xt , y , t ) ∥ 2 2 ] \mathbb{E}_{t,x_0,\epsilon}[\|\epsilon- \épsilon_\theta(x_t,y,t)\|_2^2]Et , x0, ϵ[ ∥ϵ _-ϵeu( xt,sim ,t ) ∥22] Mas comop ( xt ∣ y ) p(x_t|y)p ( xt∣ y ) não aparece explicitamente no alvo de treinamento e é difícil garantir que o modelo de difusão possa aprender a distribuição condicional desejada.
3.2 Modelo de difusão de visão única
Este modelo trata a nova tarefa de geração de visualização como uma tarefa de conversão imagem em imagem (I2I) baseada em um modelo de difusão. O método neste artigo é mostrado na figura abaixo, que inclui três métodos de modelo de difusão: operador de ruído gaussiano, operador de visualização de imagem e geração em uma etapa.
3.2.a Operador de ruído gaussiano
Para aprender a transformação entre dois domínios de visão, de acordo com o BBDM, este artigo utiliza o processo de difusão em ponte browniana em vez do método DDPM.
O processo de ponte browniana é um modelo estocástico de tempo contínuo no qual a distribuição de probabilidade no processo de difusão está condicionada aos estados inicial e final. Lembre-se de que o estado inicial é x 0 ∼ qdata ( x 0 ) x_0\sim q_{data}(x_0)x0∼qdat a _ _( x0) , o estado terminal éx T x_TxT, então a distribuição de estado do processo de difusão da ponte browniana é q BB ( xt ∣ x 0 , y ) = N ( xt ; ( 1 − mt ) x 0 + mty , δ t I ) q_{BB}(x_t|x_0, y) =\mathcal{N}(x_t;(1-m_t)x_0+m_ty,\delta_tI)qBB( xt∣x _0,você )=N ( xt;( 1-eut) x0+eutsim ,dtI )其中mt = t / T m_t=t/Teut=t / T,δ t \delta_tdté a variação. Para evitar variância excessiva que impossibilite o treinamento, utiliza-se o seguinte escalonamento de variância: δ t = s [ 1 − ( ( 1 − mt ) 2 + mt 2 ) ] = 2 s ( mt − mt 2 ) \delta_t=s [1-( (1-m_t)^2+m_t^2)]=2s(m_t-m_t^2)dt=s [ 1-(( 1-eut)2+eut2)]=2s ( m _t-eut2) ondesss controla a diversidade de amostras e o padrão é 1.
O processo direto é o seguinte: quandot = 0 t=0t=0 ,mt = 0 m_t=0eut=0 , o valor médio neste momento éx 0 x_0x0, a variância é 0; quando t = T t=Tt=Quando T ,mt = 1 m_t=1eut=1 , o valor médio neste momento éyyy , a variância é 0. O processo intermediário é calculado da seguinte forma: xt = ( 1 − mt ) x 0 + mty + δ t ϵ x_t=(1-m_t)x_0+m_ty+\sqrt{\delta_t}\epsilonxt=( 1-eut) x0+eutsim+dtϵ incrementoϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I)ϵ∼N ( 0 ,eu ) . Utilizet − 1 t-1t-1Substitua ttna fórmula acimat , subtraia as duas equações para obter a probabilidade de transição: q BB ( xt ∣ xt − 1 , y ) = N ( xt ; 1 − mt 1 − mt − 1 xt − 1 + ( mt − 1 − mt 1 − mt − 1 mt − 1 ) y , δ t ∣ t − 1 I ) q_{BB}(x_t|x_{t-1},y)=\mathcal{N}(x_t;\frac{1-m_t}{1- m_{ t-1}}x_{t-1}+(m_t-\frac{1-m_t}{1-m_{t-1}}m_{t-1})y,\delta_{t|t- 1} eu)qBB( xt∣x _t − 1,você )=N ( xt;1-eut − 11-eutxt − 1+( mt-1-eut − 11-euteut − 1) sim ,dt ∣ t − 1I )其中δ t ∣ t − 1 = δ t − δ t − 1 ( 1 − mt ) 2 ( 1 − mt − 1 ) 2 \delta_{t|t-1}=\delta_t-\delta_{t-1 }\frac{(1-m_t)^2}{(1-m_{t-1})^2}dt ∣ t − 1=dt-dt − 1( 1-eut − 1)2( 1-eut)2 O processo inverso começa a partir da visão conhecida e gradativamente obtém a distribuição da visão alvo. ou seja, baseado em xt x_txtPrever xt − 1 x_{t-1}xt − 1: p θ ( xt − 1 ∣ xt , y ) = N ( xt − 1 ; μ θ ( xt , t ) , δ ~ t I ) p_\theta(x_{t-1}|x_t,y)=\mathcal {N}(x_{t-1};\mu_\theta(x_t,t),\tilde{\delta}_tI)peu( xt − 1∣x _t,você )=N ( xt − 1;eueu( xt,t ) ,d~tI )其中μ θ ( xt , t ) \mu_\theta(x_t,t)eueu( xt,t ) é o valor médio do ruído de predição, estimado pela rede neural com base no critério de máxima verossimilhança. δ ~ t \tilde{\delta}_td~té a variância do ruído em cada etapa, a forma analítica é δ ~ t = δ t ∣ t − 1 δ t − 1 δ t \tilde{\delta}_t=\frac{\delta_{t|t-1} \delta_{t -1}}{\delta_t}d~t=dtdt ∣ t − 1dt − 1.
O processo completo de treinamento e inferência é o seguinte:
Algoritmo de treinamento BBDM
- Par de dados de amostragem x 0 ∼ q ( x 0 ) , y ∼ q ( y ) x_0\sim q(x_0),y\sim q(y)x0∼q ( x0) ,sim∼q ( y ) ;
- Tempo de amostragem uniforme t ∈ { 1 , 2 , ⋯ , T } t\in\{1,2,\cdots,T\}t∈{ 1 ,2 ,⋯,T } ;
- Amostragem de ruído gaussiano ϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I)ϵ∼N ( 0 ,eu ) ;
- Difusão direta: xt = ( 1 − mt ) x 0 + mty + δ t ϵ x_t=(1-m_t)x_0+m_ty+\sqrt{\delta_t}\epsilonxt=( 1-eut) x0+eutsim+dtϵ ;
- Defina mt ( y − x 0 ) + δ t ϵ − ϵ θ ( xt , t ) ∥ 2 \|m_t(y-x_0)+\sqrt{\delta_t}\epsilon-\epsilon_\theta(x_t,t); \|^2∥m _t( você-x0)+dtϵ-ϵeu( xt,t ) ∥2 gradiente.
Algoritmo de amostragem BBDM:
- Entrada da condição de amostragem x T = y ∼ q ( y ) x_T=y\sim q(y)xT=sim∼q ( y ) ;
- De t = T t = Tt=A partir de T , prossiga com o seguinte processo atét = 1 t=1t=1 :
Cálculoz 〜 N ( 0 , I ) z\sim\mathcal{N}(0,I)z∼N ( 0 ,I )
计算xt − 1 = cxtxt + cyty − c ϵ t ϵ θ ( xt , t ) + δ ~ tz x_{t-1}=c_{xt}x_t+c_{yt}y-c_{\epsilon t} \epsilon_\theta(x_t,t)+\sqrt{\tilde{\delta}_t}zxt − 1=cx txt+csim _sim-cϵt _ϵeu( xt,t )+d~tz ;- t = 1 t = 1t=1º , calculex0 = cx 1 x 1 + cy 1 y − c ϵ 1 ϵ θ ( x 1 , 1 ) x_0=c_{x1}x_1+c_{y1}y-c_{\epsilon1}\epsilon_\theta ( x_1,1)x0=cx 1x1+ce 1sim-cϵ1 _ϵeu( x1,1 )。
3.2.b Visualizar manipulador de imagens
O modelo de difusão da ponte browniana introduz hiperparâmetros adicionais. Este artigo propõe um método baseado em operadores de visualização de imagem, que trata a imagem alvo como ruído especial e converte iterativamente a imagem alvo na imagem fonte. Dado o estado inicial x 0 x_0x0e estado de destino yyy , estado intermediárioxt x_txtPode ser escrito como: xt = α tx 0 + 1 − α ty x_t=\sqrt{\alpha_t}x_0+\sqrt{1-\alpha_t}yxt=atx0+1-aty é diferente do processo convencional de adição de ruído. O que é adicionado aqui é uma nova imagem de visualização que aumenta gradativamente o peso. O processo de amostragem é o seguinte:
- Imagem de origem de entrada x T x_TxT;
- De t = T t = Tt=A partir de T , prossiga com o seguinte processo atét = 0 t=0t=0:
x 0 ≤ f ( xt , t ) x_0\leq f(x_t,t)x0≤f ( xt,t )
xt − 1 = xt − D ( x 0 , t ) + D ( x 0 , t − 1 ) x_{t-1}=x_t-D(x_0,t)+D(x_0,t-1)xt − 1=xt-D ( x0,t )+D ( x0,t-1 )(Em relação ao algoritmo de amostragem deste método, os símbolos usados no artigo original devem ser problemáticos e carentes de explicação. Aqui só podemos adivinhar o ss no artigo original.s eiieu deveria estar realmentettt )
α t \alpha_tatO cronograma é o seguinte: α t = f ( t ) f ( 0 ) , f ( t ) = cos ( t / T + s 1 + s ⋅ π 2 ) 2 \alpha_t=\frac{f(t)} {f (0)},f(t)=\cos(\frac{t/T+s}{1+s}\cdot\frac{\pi}{2})^2at=f ( 0 )f ( t ),f ( t )=porque (1+ét / T+e⋅2p)2 Comparado ao agendamento linear, o agendamento cosseno adiciona visualizações de destino mais lentamente.
3.2.c Amostragem acelerada e geração em uma etapa
Como os modelos de probabilidade de difusão geralmente requerem um grande número de amostragem em etapas, a fim de acelerar o processo de inferência, este artigo propõe dois métodos: um é adicionar um solucionador de alta ordem para orientar a amostragem DPM, e o outro é introduzir um método de geração de etapas.
Amostragem acelerada : semelhante à ideia básica do DDIM, o BBDM também pode manter a mesma distribuição de arestas que o processo de inferência de Markov enquanto usa um processo não-Markov.
Dado { 1 , 2 , ⋯ , T } \{1,2,\cdots,T\}{
1 ,2 ,⋯,O comprimento de T } éSSSubsequência de S { T 1 , T 2 , ⋯ , TS } \{T_1,T_2,\cdots,T_S\}{
T1,T2,⋯,TS} , o processo de inferência pode ser determinado pelo subconjunto de variáveis latentes{ x T 1 , x T 2 , ⋯ , x TS } \{x_{T_1},x_{T_2},\cdots,x_{T_S}\}{
xT1,xT2,⋯,xTS}定义: q BB ( x T s − 1 ∣ x T s , x 0 , y ) = N ( ( 1 − m T s − 1 ) x 0 + m T s − 1 + δ T s − 1 − σ T s 2 δ T s ( x T s − ( 1 − m T s ) x 0 − m T sy ) , σ T s 2 I ) q_{BB}(x_{T_{s-1}}|x_{T_s} ,x_0,y)=\mathcal{N}((1-m_{T_{s-1}})x_0+m_{T_{s-1}}+\frac{\sqrt{\delta_{T_{s- 1}}-\sigma_{T_s}^2}}{\sqrt{\delta_{T_s}}}(x_{T_s}-(1-m_{T_s})x_0-m_{T_s}y),\sigma_{ T_s}^2I)qBB( xTs − 1∣x _Te,x0,você )=N (( 1-euTs − 1) x0+euTs − 1+dTedTs − 1-pTe2( xTe-( 1-euTe) x0-euTee ) ,pTe2I )
Geração em uma etapa: O objetivo é realizar a geração em uma etapa sem sacrificar as vantagens do refinamento iterativo. Essas vantagens incluem a capacidade de equilibrar computação e qualidade e a capacidade de editar dados de disparo zero. O método é baseado na equação diferencial ordinária (ODE) do modelo de difusão probabilística de fluxo em tempo contínuo, cuja trajetória se transforma suavemente da distribuição de dados para uma distribuição de ruído tratável. Use um modelo que aprenda a mapear pontos em qualquer etapa até o ponto inicial de uma trajetória para que o modelo seja autoconsistente (ou seja, pontos na mesma trajetória serão mapeados para o mesmo ponto inicial).
O modelo de consistência pode combinar o vetor de ruído aleatório (o ponto final da trajetória ODE,x T x_TxT) em amostras de dados (ponto inicial da trajetória EDO, x 0 x_0x0). Ao conectar a saída do modelo de consistência em múltiplas etapas, mais cálculos podem ser usados para melhorar a qualidade da amostra e realizar a edição de dados de amostra zero, mantendo assim as vantagens do refinamento iterativo.
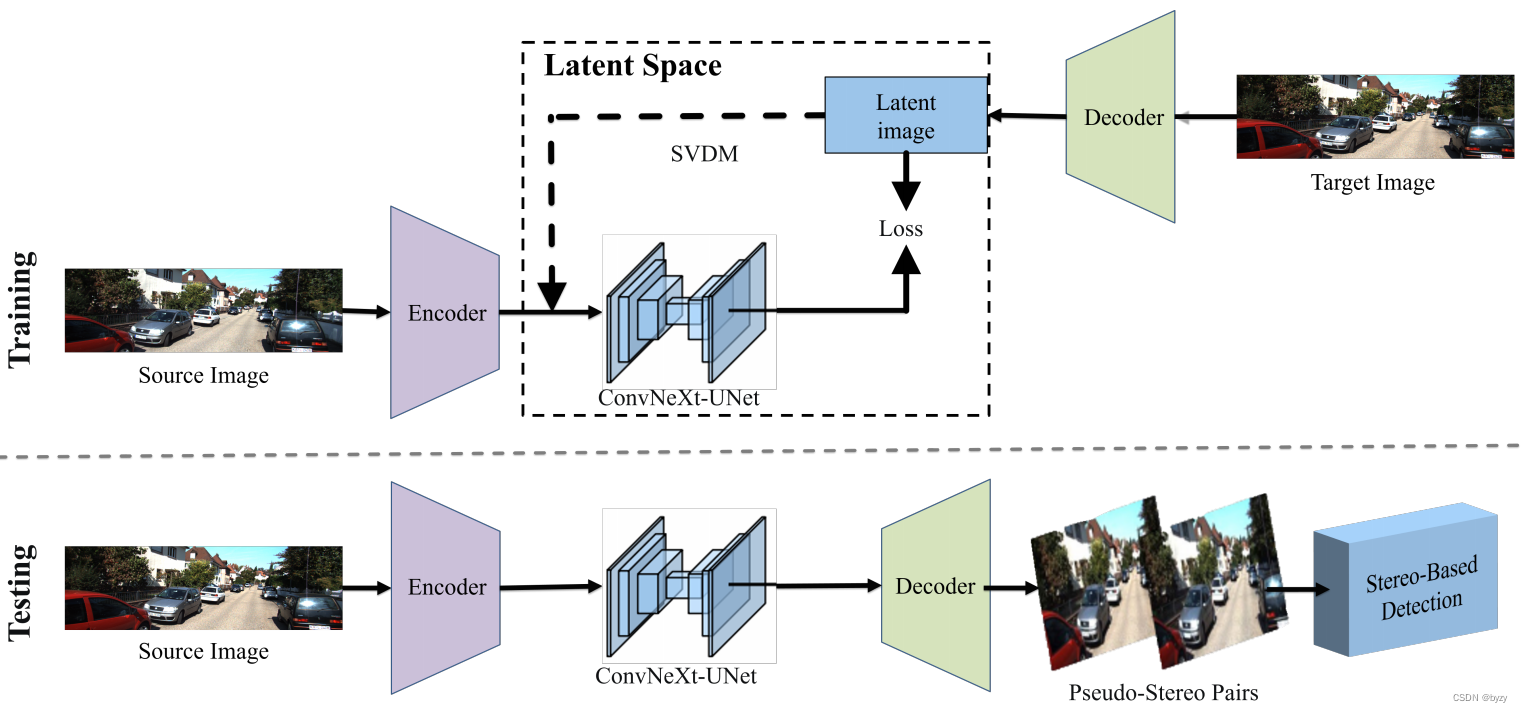
3.3 Estrutura da rede
De acordo com o modelo de difusão implícita (LDM), o SVDM realiza aprendizagem generativa no espaço latente em vez do espaço de pixel original para reduzir a computação. LDM usa codificador VAE EE
pré-treinadoE mapeia a imagemv ∈ R 3 × H × W v\in\mathbb{R}^{3\times H\times W}v∈R3 × H × W é codificado como uma incorporação implícitaz = E ( v ) ∈ R c × h × wz=E(v)\in\mathbb{R}^{c\times h\times w}z=E ( v )∈Rc × h × w . Seu processo progressivo move-se gradualmente em direção azzAdicione ruído a z e inverta o processo de eliminação de ruído para preverzzz . Finalmente, o LDM usa o decodificador VAEDDD decodificaçãozz_z , obtenha uma imagem de alta resoluçãov = D ( z ) v=D(z)v=D ( z ) . O codificador e o decodificador do VAE permanecem fixos durante o treinamento e a inferência, e comoh < H , w < W h<H,w<Wh<H ,c<W , a difusão no espaço latente de baixa resolução é mais eficiente do que a difusão no espaço de pixels. O método neste artigo é semelhante, dado o domínio escravoAAImagem IA I_Aamostrada em AEUUm, primeiro extraia os recursos latentes LA L_AeuUme, em seguida, execute o processo SVDM para converter LA L_AeuUmMapeie para o domínio BB correspondenteExpressão implícita LA em B → B L_{A\rightarrow B}euUMA → B. Finalmente, o decodificador VQGAN pré-treinado é usado para gerar a imagem IA → B I_{A\rightarrow B}EUUMA → B.
O modelo SVDM conecta duas imagens ao longo da dimensão do canal e usa a estrutura U-Net padrão e o bloco residual Conv-NeXt para amostragem ascendente e descendente para obter um grande campo receptivo para obter informações contextuais. Além disso, os bloqueios de atenção também são introduzidos em diferentes resoluções porque as interações globais podem melhorar significativamente a qualidade da reconstrução.
3.4 Função de perda
A função de perda contém 3 itens: perda RGB L1, perda RGB SSIM e perda perceptiva.
3.4.a Perda RGB L1 e perda SSIM
A perda L1 e a perda SSIM são as seguintes: LL 1 = 1 3 HW ∑ ∣ I ^ tgt − I tgt ∣ L ssim = 1 − SSIM ( I ^ tgt , I tgt ) \mathcal{L}_{L1}=\ frac{1}{3HW}\sum|\hat{I}_{tgt}-I_{tgt}|\\\mathcal{L}_{ssim}=1-SSIM(\hat{I}_{tgt} ,Eu_{tgt})eueu 1=3HW _ _1∑∣EU^t g t-EUt g t∣eussim=1-SSIM(EU^t g t,EUt g t) ondeeu ^ tgt \hat{I}_{tgt}EU^t g t与Eu tgt I_{tgt}EUt g tsão os valores previstos e os valores verdadeiros dos canais de pixels, respectivamente.
3.4.b Perda percebida
Com base em trabalhos anteriores, a perda perceptiva garante que a reconstrução seja restrita à variedade de imagens, reforçando a autenticidade local e evita o desfoque introduzido ao confiar apenas nas perdas RGB. L latente = 1 2 ∑ j = 1 J [ ( uj 2 + σ j 2 ) − 1 − log σ j 2 ] \mathcal{L}_{latente}=\frac{1}{2}\sum_{j =1}^J[(u_j^2+\sigma_j^2)-1-\log\sigma_j^2]eul a t e n t=21j = 1∑J[( vocêj2+pj2)-1-ei _pj2]
4. Experimente
4.4 Visualize os resultados da síntese com base em uma única imagem
Resultados quantitativos : O método deste artigo pode superar o SotA em termos de índice PSNR, mas os indicadores SSIM e LPIPS são ligeiramente inferiores ao SotA.
Resultados qualitativos : As visualizações mostram que nosso método gera imagens mais realistas com distorções e artefatos menores. Isso demonstra a capacidade do nosso método de modelar a geometria e a textura de cenas complexas.
4.5 Resultados de detecção de alvo 3D
Resultados quantitativos : Experimentos mostram que o SVDM pode superar os métodos mais avançados ao usar o BBDM. O uso do método de difusão de visualização pode melhorar ainda mais o desempenho, o que mostra que a estrutura de visualização tem melhor capacidade de generalização na detecção de alvos 3D.
Além disso, embora não possa superar completamente o SotA, o SVDM apresenta melhor desempenho na detecção de objetos difíceis. A razão para o baixo desempenho em objetos simples pode ser restrições limitadas. Tanto o cenário quanto os obstáculos interferem inevitavelmente na geração de novas visualizações. A estrutura ConvNeXt-UNet pode aliviar esse problema até certo ponto, mas não é perfeita.
4.3 Estudos de ablação
Resultados de detecção 3D de pedestres e bicicletas : Devido ao pequeno número de amostras, a detecção de pedestres e bicicletas é mais difícil do que a detecção de carros. Mas o método neste artigo pode superar o SotA em quase todas as dificuldades.
5. Conclusão e perspectivas futuras
Atualmente, uma desvantagem do SVDM é que ele não pode ser treinado de ponta a ponta.