
Recentemente, usei o JMeter para testes de interface e encontrei um cenário que exigia o uso de um banco de dados de dados: uma página sobre relatórios de dados que precisava somar ou calcular a média dos dados no banco de dados antes de exibi-los.
Se quiser fazer uma afirmação, você precisa se conectar ao banco de dados e comparar os resultados da consulta SQL com os resultados da página, escrevendo instruções SQL.
Tomando o banco de dados MySQL como exemplo, as etapas específicas de implementação são as seguintes:
一、加载JDBC驱动
二、连接数据库
三、数据库的查询(单值/多值引用)
1. Carregue o driver JDBC
1) Prepare o pacote jar do driver localmente
注意:驱动包的版本一定要与数据库的版本匹配,驱动版本太低可能导致连接报错。
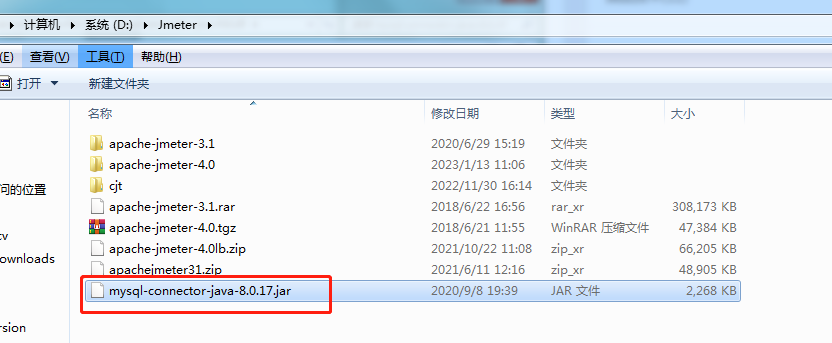
1. Download do disco de rede
Prepare o driver MySQL. Se você não conseguir encontrá-lo, poderá baixá-lo do disco de rede: link: https://pan.quark.cn/s/b59620ad7f30, código de extração: 6WWw, coloque o arquivo na pasta de instalação do JMeter
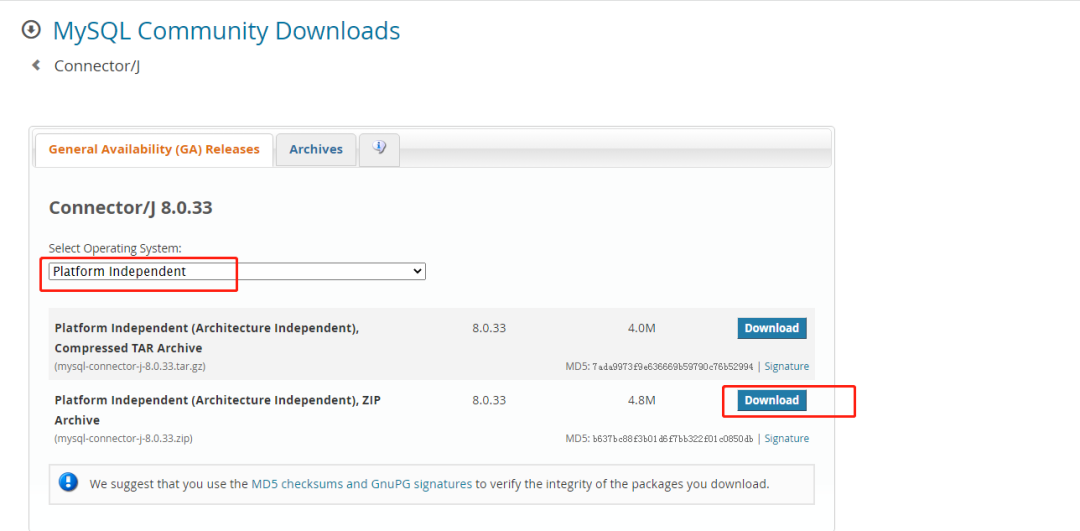
2. Baixe do site oficial
Entre no site oficial https://dev.mysql.com/downloads/connector/j/ e selecione: Independente de plataforma. Clique em Download, descompacte e encontre o arquivo jar e coloque-o na pasta de instalação do JMeter.
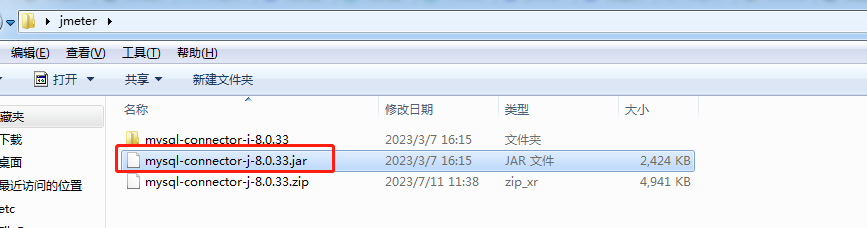
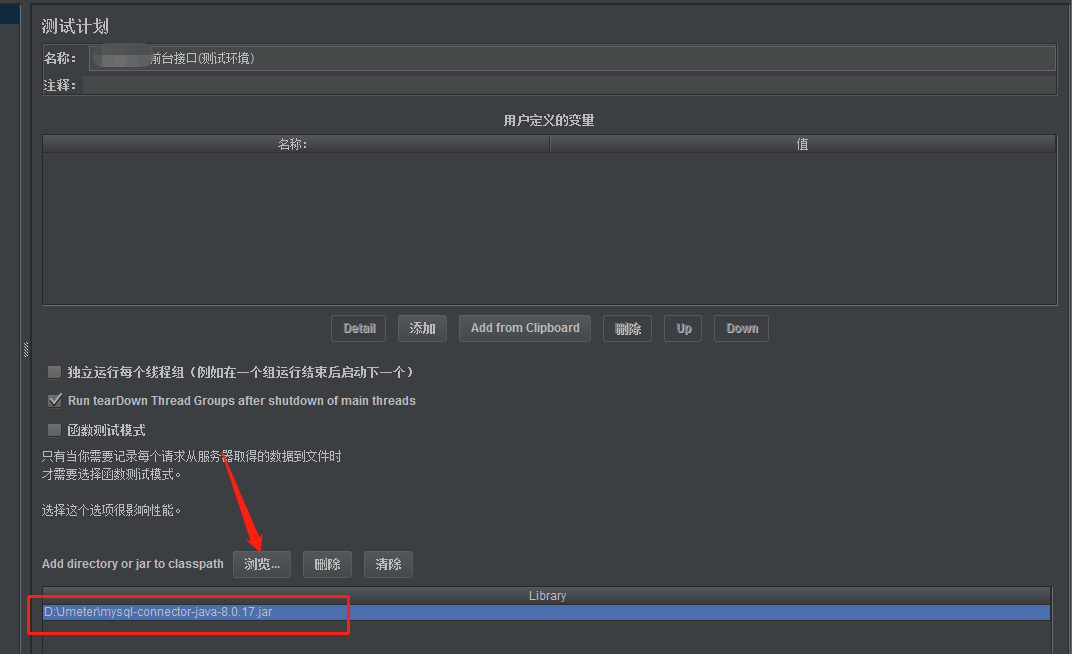
2) Importe o pacote de driver
No plano de teste do JMeter, encontre Adicionar diretório ou jar ao caminho de classe, clique em Procurar ao lado dele, selecione o pacote e importe-o.
2. Conecte-se ao banco de dados
1) Adicionar configuração de conexão JDBC do componente
Selecione o grupo de threads, clique com o botão direito, adicione – Elemento de configuração – Configuração de conexão JDBC
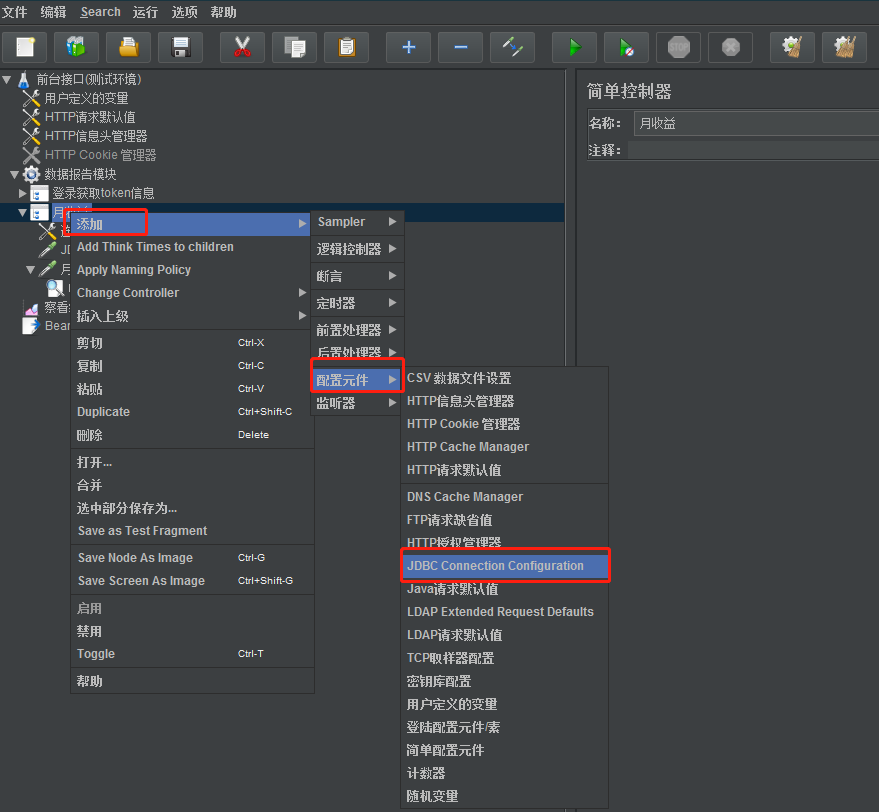
2) Configuração de conexão JDBC de posicionamento
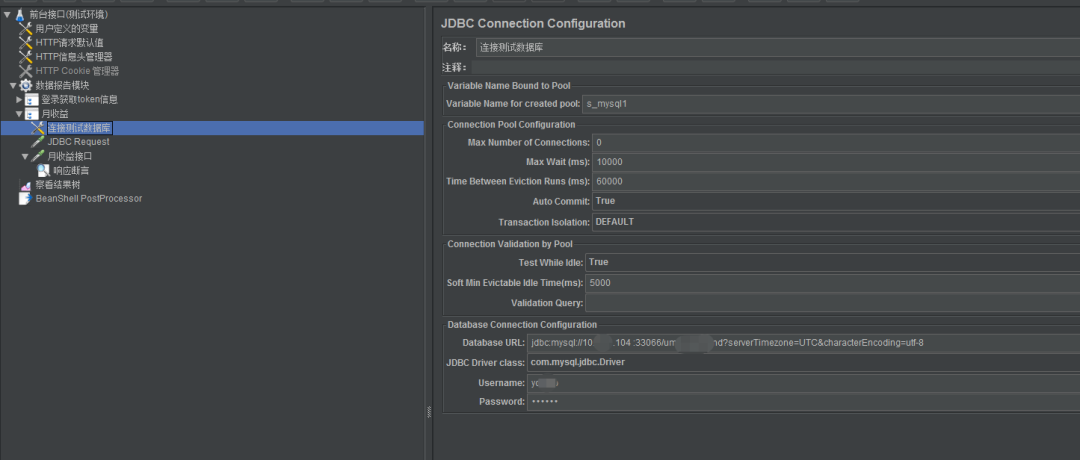
1. Nome: vazio por padrão, você pode personalizar o nome ou deixá-lo vazio
2. Comentário: vazio por padrão, pode ser personalizado ou vazio
3. Nome da variável para o pool criado: um nome de conexão, por exemplo chamado s_mysql1, precisa ser identificado exclusivamente e precisa ser usado em solicitações JDBC subsequentes, portanto, precisa ser consistente com o nome no amostrador JDBC. Um entendimento simples é que precisa ser determinado ao fazer uma solicitação jdbc. Qual banco de dados solicitar.
4. Número Máximo de Conexões: O número máximo de conexões de banco de dados permitidas no pool de conexões. O padrão é 10. Ao fazer testes de desempenho, é recomendado preencher 0.
5. Max Wait (ms): O tempo máximo de espera para recuperar uma conexão do pool de conexões, em milissegundos, o padrão é 10.000, o padrão é suficiente
6. Tempo entre execuções de despejo (ms): O tempo ocioso do thread, em milissegundos, o padrão é 60.000, o padrão é suficiente 7. Auto
Commit: Envie automaticamente a instrução sql, existem três opções: True, False, Edit (configurações de função fornecidas pelo JMeter), o padrão é verdadeiro, o padrão é bom
8. Isolamento de transação: nível de isolamento de transação, o padrão é DEFAULT, o padrão é suficiente
9. Testar enquanto ocioso: Se deve ser desconectado quando a conexão estiver ociosa. O padrão é Verdadeiro. O padrão é OK.
10. Soft Min Evictable Idle Time (ms): O tempo mínimo de inatividade da conexão no pool de conexões, em milissegundos. Quando as conexões no pool de conexões estão ociosas e excedem o valor definido de "Soft Min Evictable Idle Time", o pool de conexões pode optar por reciclar essas conexões ociosas. O padrão é 5000. O padrão é bom.
11. Consulta de validação: verifique a sintaxe sql, o padrão é select1, o padrão é suficiente
12. URL do banco de dados: URL de conexão do banco de dados, você pode trazer o conjunto de caracteres characterEncoding = utf-8, também pode permitir que várias instruções SQL executem allowMultiQueries = true e também pode especificar o fuso horário serverTimezone = UTC, como jdbc: mysql://10.0.41.104: 33066/u_backend?serverTimezone=UTC&characterEncoding=utf-8&allowMultiQueries=true
13. Classe JDBC Driver: Classe JDBC, vazia por padrão, obrigatória. Para mysql, selecione com.mysql.jdbc.Driver
14. Nome de usuário: Nome de usuário do banco de dados
15. Senha: senha do banco de dados
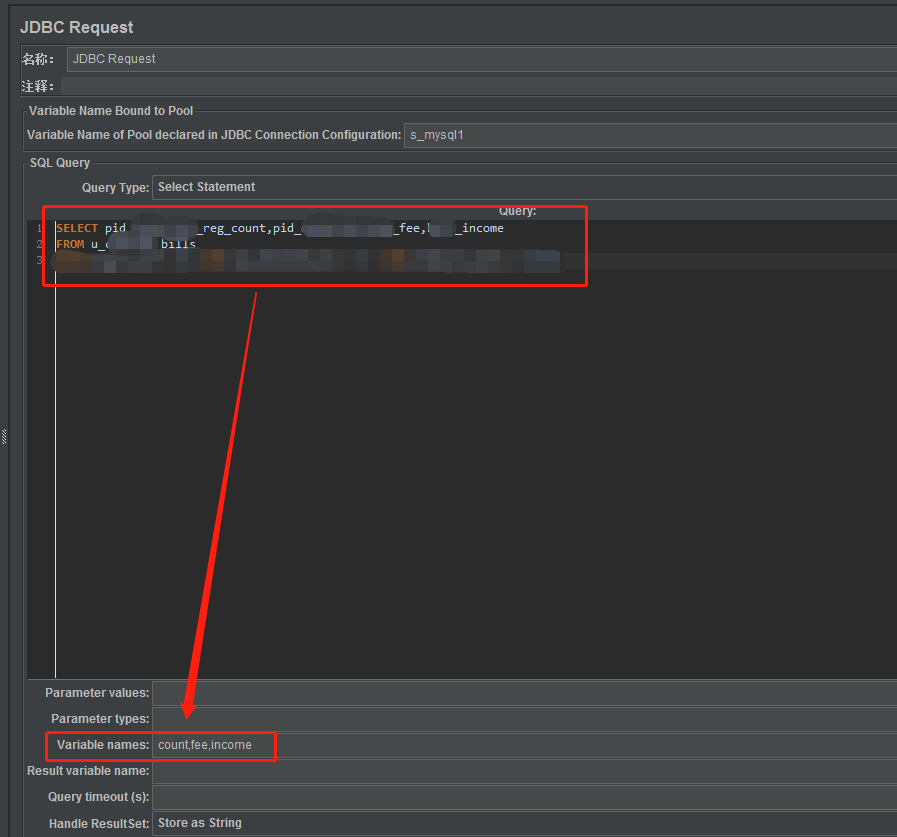
3. Consulta de banco de dados (referência de valor único/valor múltiplo)
1) Adicionar solicitação JDBC
1. Selecione o controlador simples, clique com o botão direito e adicione –Sample–JDBC Request
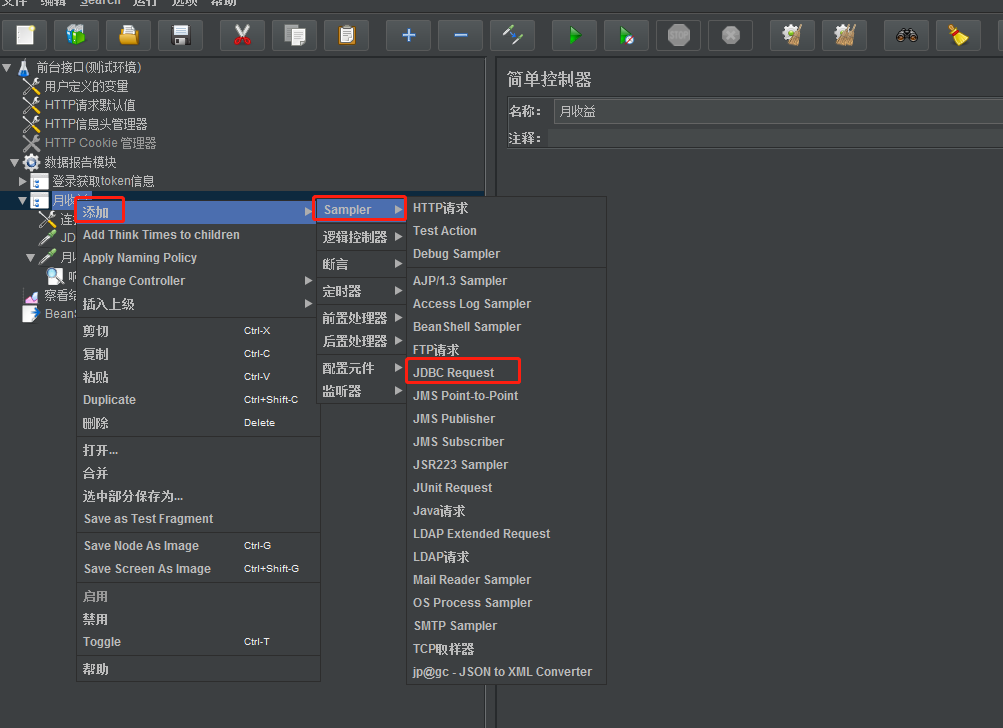
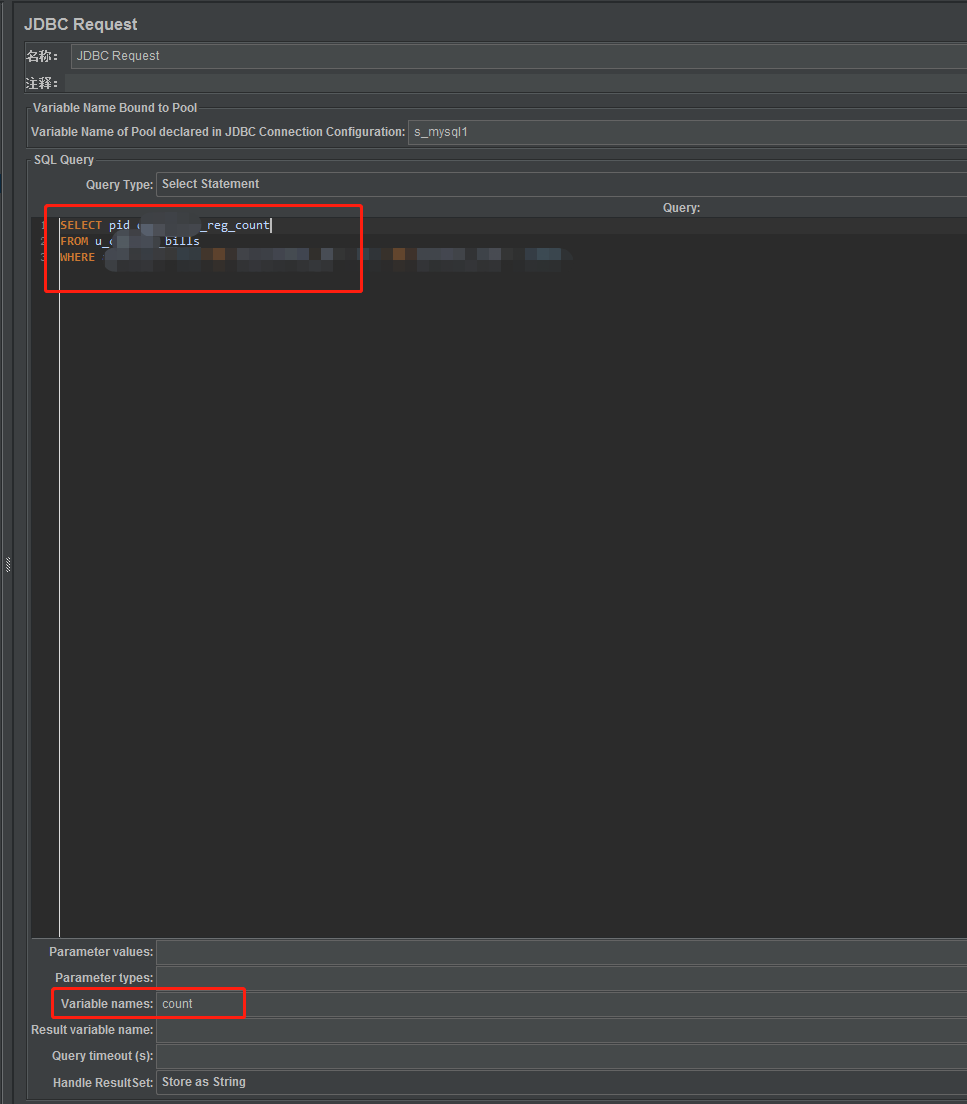
Após a adição ser bem-sucedida, preencha os parâmetros correspondentes:
Nome: Personalizado
Nome da variável do pool declarado na configuração da conexão JDBC: para ser consistente com o nome da variável para o valor do pool criado na configuração da conexão JDBC
Tipo de consulta: com base na seleção SQL preenchida, selecione Selecionar instrução para consulta e Atualizar instrução para atualização.
Nomes de variáveis: valores de campo correspondentes aos resultados da consulta SQL. Quantos valores de campo houver, haverá tantos valores correspondentes. Por exemplo, se o SQL encontrar um valor de campo reg_count, o seguinte corresponderá a uma contagem de variável .
Handle ResultSet: O padrão é Store as String. Basta selecionar o valor padrão. Quando esta opção for selecionada, os resultados da consulta serão armazenados em variáveis na forma de strings.
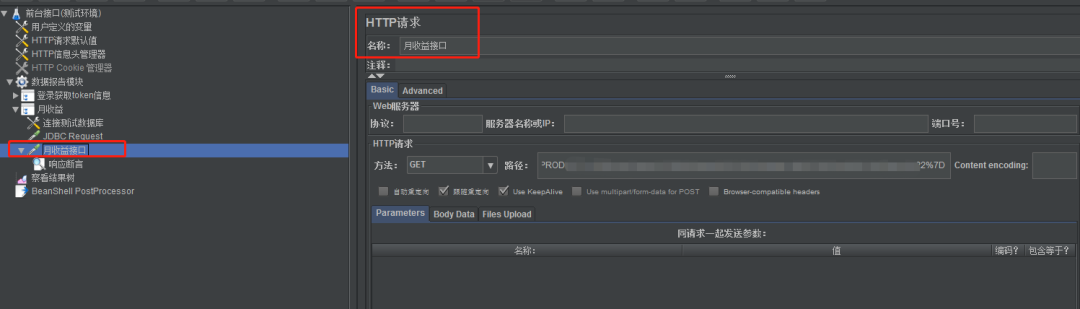
2) Adicionar solicitação HTTP
Adicione uma solicitação HTTP, preencha o nome, método de solicitação HTTP, caminho, etc.
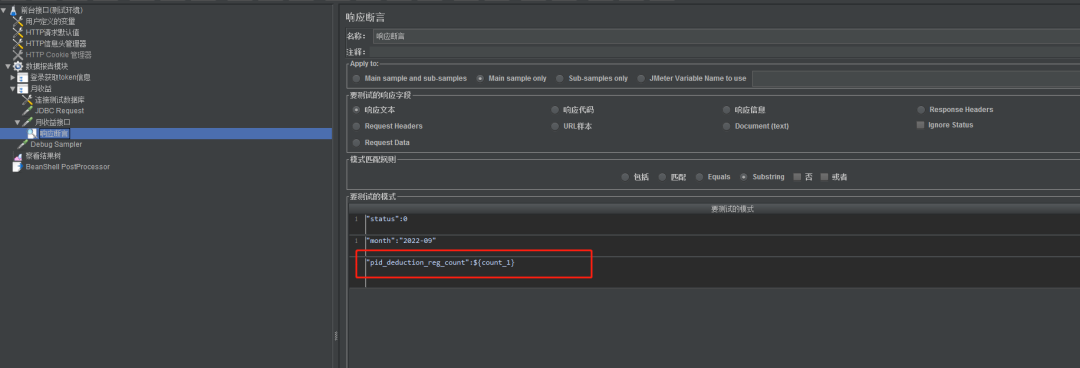
3) Adicione asserção de resposta
1. Faça referência a uma variável
A forma de citar uma variável é o número de linhas do nome da variável, como {nome da variável_número de linhas}, por exemplo, o número de linhas do nome da variável, como {
contagem_1
}
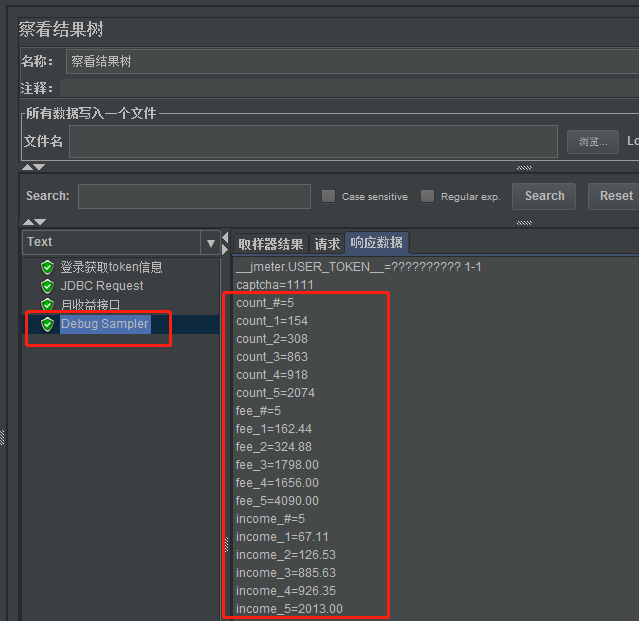
, o que significa referenciar os dados no primeira linha do campo de contagem no resultado da consulta, erro de análise KaTeX: Grupo esperado após '_' na posição 5: {Nome da variável_̲#} representa o número de linhas retornadas, por exemplo {count_#} representa quantas linhas foram retornadas .
2. Faça referência a múltiplas variáveis
Se houver vários valores retornados pela consulta SQL, por exemplo, 5 linhas de registros são consultadas, cada linha possui três campos, pid_reg_count corresponde à contagem variável, pid_fee corresponde à taxa variável e renda corresponde à renda variável .
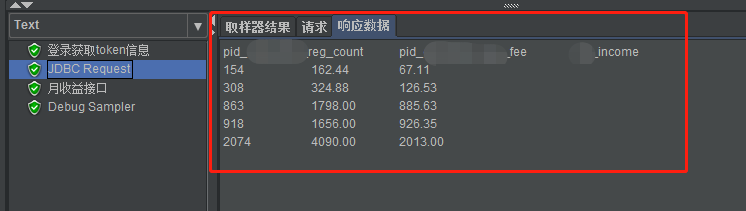
Você pode adicionar uma amostra de depuração para ver como cada valor é obtido. Erro de análise KaTeX: Grupo esperado após '_' na posição 7: {count_̲#} representa o número de linhas retornadas, {count_1} representa o primeiro número do campo de contagem retornado O valor da linha, ${count_2} representa o valor da segunda linha do campo de contagem retornado.
fee1 representa o valor da primeira linha do campo de taxa retornado e {income_1} representa o valor da primeira linha do campo de receita retornado. . . E assim por diante.
É isso para o compartilhamento de hoje, espero que possa inspirar a todos vocês.
Por fim, gostaria de agradecer a todos que lêem meu artigo com atenção. A reciprocidade é sempre necessária. Embora não seja algo muito valioso, se você puder usá-lo, poderá pegá-lo diretamente:

Esta informação deve ser o armazém de preparação mais abrangente e completo para amigos [de teste de software]. Este armazém também acompanhou dezenas de milhares de engenheiros de teste na jornada mais difícil. Espero que também possa ajudá-lo!