Diretório de artigos
1. O que é um pipeline?
O comando pipeline é um pouco diferente do comando de execução contínua no Linux Learning 18. Ele só executará comandos de pipeline quando as instruções anteriores forem executadas corretamente.
Ou seja, este comando de pipeline "|" só pode processar as informações corretas transmitidas pelo comando anterior, ou seja, as informações de saída padrão, e não tem capacidade de tratar diretamente o erro padrão.
O processo de execução dos comandos do pipeline pode ser representado pelo seguinte diagrama:

Os primeiros dados conectados após cada pipeline devem ser um "comando", e este comando deve ser capaz de aceitar dados de entrada padrão. Somente esse comando pode ser chamado de "comando de pipeline". Por exemplo, menos, mais, cabeça, cauda, etc. são todos comandos de pipeline que podem aceitar entrada padrão. Quanto a ls, cp, mv, etc., eles não são comandos de pipeline. Porque ls, cp, mv não aceitarão dados de stdin. Em outras palavras, há duas coisas principais a serem observadas nos comandos do pipeline:
O comando pipeline processará apenas a saída padrão e ignorará a saída de erro padrão.
O comando pipeline deve ser capaz de aceitar dados do comando anterior como entrada padrão para continuar o processamento.
Para dar um exemplo prático:
usamos ls /etc para verificar quantos arquivos estão em /etc/, mas como há muitos arquivos em /etc, e o comando irá pular automaticamente para a última linha após a execução, temos que usar menos comando.de assistência.
instrução:ls -al /etc | less

Use a roda do mouse para navegar e digite qpara sair.
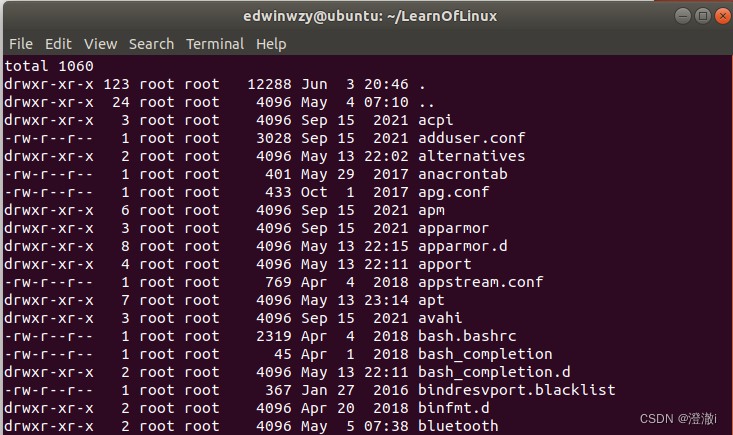
2. Comandos de extração: cut, grep
Quando modifiquei e adicionei a variável de ambiente PATH antes, às vezes eu só queria pegar uma seção dela para operação, mas não sabia como fazer na hora. Na interface gráfica, era fácil usar o mouse para ajudar, mas algumas interfaces de linha de comando foram diretamente obscurecidas.
Neste capítulo, escreveremos o comando de extração.
Os comandos de extração geralmente são analisados “linha por linha”, não a mensagem inteira.
2.1 corte
Uso geral: cut -option parameter
cut -d 'caractere separador' -f campos------->geralmente usado para caracteres delimitadores específicos
cut -c intervalo de caracteres--------->geralmente usado para mensagens bem organizadas
Opções e parâmetros:
-d: seguido por um caractere delimitador. Usado junto com -f;
-f: particiona uma mensagem em vários segmentos com base no caractere delimitador de -d, e usa -f para obter o significado de qual segmento;
-c: obtém o intervalo fixo de caracteres em unidades de caracteres;
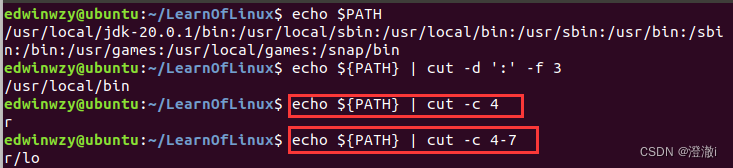
例1:Extraia o terceiro caminho de PATH.
Primeiro verifique o valor de PATH por meio de echo. Podemos saber que o terceiro caminho que queremos seguir é o /usr/local/bin

comando do pipeline cut to extract .

Aqui, cut é primeiro -dconectado ao caractere de divisão :. Este caractere de divisão é baseado na situação real.Determinado, o delimitador do meu PATH aqui é :. Em seguida, use -f para decidir qual parágrafo usar.
例2:Pegue o quarto caractere do PATH, pegue os 4-7 caracteres do PATH
2.2 grep
Cut é extrair a parte que queremos de uma linha de informação, enquanto grep é analisar uma linha de informação e, se ela contiver a informação que precisamos, retirar a linha.
Uso geral: grep [-acinv] [--color=auto] '搜寻字串' filename
Opções e parâmetros:
-a: Pesquisa arquivos binários como arquivos de texto
-c: Calcula o número de vezes que a 'string de pesquisa' é encontrada
-i: Ignora a diferença entre maiúsculas e minúsculas, para que maiúsculas e minúsculas sejam tratadas como iguais
- n: A propósito, produza o número da linha
-v: Seleção reversa, ou seja, exiba a linha sem o conteúdo da 'string de pesquisa'
-color=auto: Você pode exibir a parte da palavra-chave encontrada em cores
grep é um comando muito poderoso que faz maravilhas quando combinado com expressões regulares. Escreverei um registro de blog após a expressão regular.
Você deve ser capaz de entender o uso do grep dando alguns exemplos.
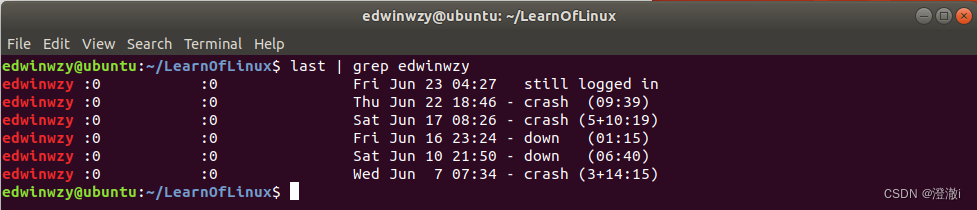
例1:Retire a última linha onde edwinwzy aparece;
comando:last | grep edwinwzy
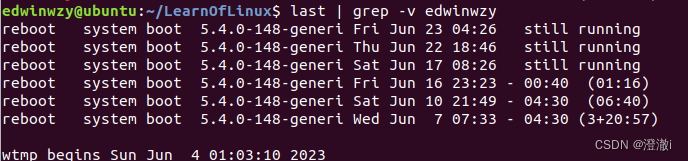
例2:Ao contrário do Exemplo 1, retire a instrução desde que não haja edwinwzy
: last | grep -v edwinwzy
例3:Na última mensagem de saída, enquanto houver edwinwzy, ele será retirado e apenas a primeira coluna que atender às condições será retirada.
last | grep edwinwzy |cut -d ' ' -f 1

3. Comandos de classificação sort, wc, uniq
3.1 classificar
Veja a visualização /etc/passwd como exemplo
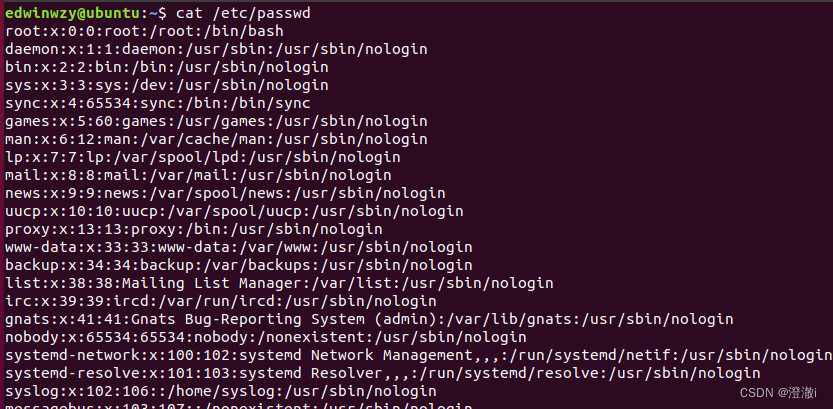
. Comando:cat /etc/passwd
A saída correspondente está fora de ordem. Se quisermos que ela seja exibida em ordem, temos que usar a instrução sort.
Uso geral do tipo:sort [-fbMnrtuk] [file or stdin]
Opções e parâmetros:
-f: Ignorar a diferença caso, por exemplo, A e a sejam considerados como a mesma codificação;
-b: Ignore a parte inicial do caractere em branco;
-M: Classifique pelo nome do mês, como JAN , DEC, etc. Método de classificação;
-n: Use "números puros" para classificação (o padrão é o formato de texto);
-r: Classificação reversa;
-u: É uniq, nos mesmos dados, apenas uma linha aparece;
- t: Símbolo delimitador, o padrão é usar a tecla [tab] para separar;
-k: significa classificar por esse intervalo (campo)
Classifique a saída passwd fora da ordem acima.
Instruções: cat /etc/passwd | sort
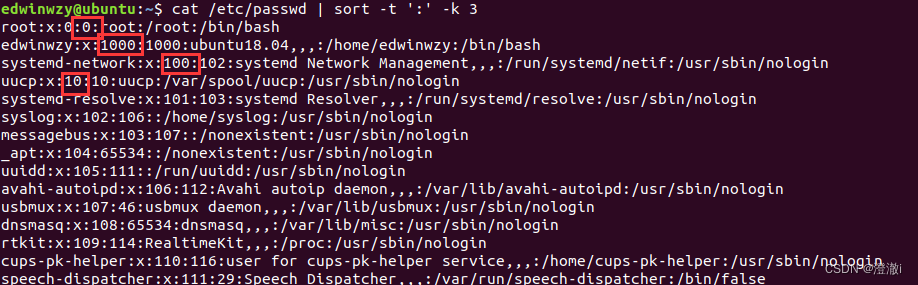
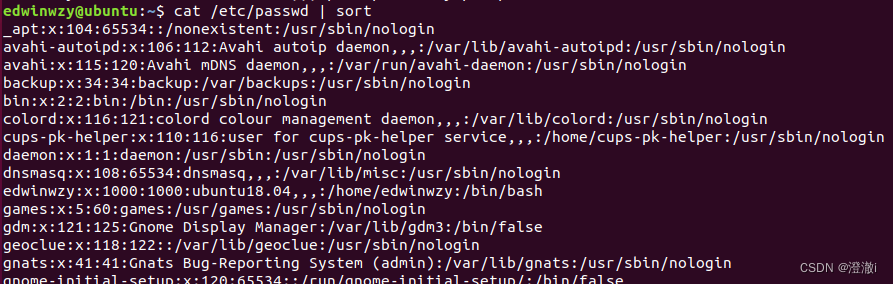 Use sort sozinho para classificar a primeira coluna. Se eu quiser que ela seja classificada pela terceira coluna, preciso usar alguns parâmetros opcionais de classificação.
Use sort sozinho para classificar a primeira coluna. Se eu quiser que ela seja classificada pela terceira coluna, preciso usar alguns parâmetros opcionais de classificação.
Instrução: cat /etc/passwd | sort -t ':' -k 3
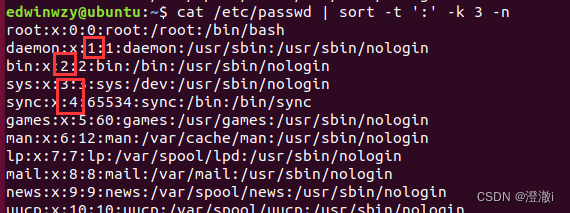
Mas essa classificação não parece estar correta. Isso ocorre porque ela é classificada por texto, não pelos números que vemos. Se você quiser classificar por números, será necessário adicionar-n
instrução:cat /etc/passwd | sort -t ':' -k 3- n
3.2 único
uniq é a abreviatura de exclusivo, portanto o significado deste comando é exibir apenas uma duplicata.
Você pode usar o último comando para listar contas, mas haverá muitos nomes duplicados, então usar exclusivo será muito mais simples.
Uso geral: uniq [-ic]
opções e parâmetros:
-i: ignora a diferença entre caracteres maiúsculos e minúsculos;
-c: conta
Instruções: Para a situação acima, se eu quiser exibir o número de logins de cada pessoa, só preciso adicionar a opção -c instrução last | cut -d ' ' -f1 | sort | uniq

após uniq :last | cut -d ' ' -f1 | sort | uniq -c

3,3 banheiro
wc é a abreviatura de wordcount, que é usada para contar quantos caracteres há em um arquivo ou quantos caracteres há no conteúdo de saída.
Uso geral: wc [-lwm]
opções e parâmetros:
-l : apenas linhas são listadas;
-w : apenas quantas palavras (palavras em inglês) são listadas;
-m : quantos caracteres;
Os três caracteres listados por padrão em wc sem parâmetros são “行、字数、字符数”, correspondendo às opções -l, -w,-m
Resumir
Este comando relacionado ao pipeline ainda é muito importante. Comparado com a próxima seção, a frequência real de aplicação das instruções escritas neste blog é muito maior, então você ainda precisa praticá-lo com cuidado.