Muitas vezes encontramos a palavra otimização de desempenho em trabalhos iniciais ou entrevistas, parece que isso não é difícil de dizer, afinal todos podem falar sobre isso. Mas se você deseja ter uma solução direta de desempenho ao encontrar gargalos de desempenho em vários cenários no trabalho, ou para impressionar o entrevistador durante uma entrevista, então você não pode simplesmente se limitar a “diga o que vier à mente” ou “Para dar uma ideia aproximada”. ideia, precisamos ter um mapa de conhecimento sistemático e aprofundado de todos os ângulos. Este artigo também pode ser considerado um resumo do meu conhecimento pessoal de front-end, porque “otimização de desempenho” não é apenas “otimização”, o que significa? Antes de implementar um plano de otimização, você deve primeiro saber por que precisa otimizar dessa forma e qual é o propósito de fazê-lo. Isso requer que você tenha um bom entendimento dos princípios de framework, js, css, navegador, mecanismo js, rede, etc. Portanto, a otimização de desempenho realmente cobre muito conhecimento de front-end, até mesmo a maior parte do conhecimento de front-end.
Primeiro, vamos falar sobre a essência do desempenho do front-end. O front-end é um aplicativo de rede. O desempenho do aplicativo é determinado pela sua eficiência operacional. Se adicionarmos a rede antes, isso está relacionado à eficiência da rede. Portanto, acho que a essência do desempenho front-end é o desempenho da rede e o desempenho operacional. Portanto, as duas categorias principais no sistema de otimização de desempenho front-end são: rede e tempo de execução, e então subdividimos cada pequena área desses dois temas principais, o que é suficiente para tecer um enorme gráfico de conhecimento front-end.
nível de rede
Se compararmos a conexão de rede a um cano de água, se você quiser abrir uma página agora, pode ser visto como se tivesse um copo d’água na mão da outra pessoa, e você deseja conectar a água ao seu copo. Se quiser ir mais rápido, existem três maneiras: 1. Fazer com que o fluxo do cano de água seja maior e mais rápido; 2. Deixar o outro lado reduzir a água do copo; 3. Tenho água no copo e não preciso do seu. O tráfego da tubulação de água é a largura de banda da rede, a otimização do protocolo e outros fatores que afetam a velocidade da rede; quando um copo de água diminui, significa compactação, divisão de código, carregamento lento e outros meios para reduzir solicitações; o último é usar o cache.
Vamos falar primeiro sobre a velocidade da rede. A velocidade da rede não é determinada apenas pela operadora do usuário, mas também pela familiarização com os princípios dos protocolos de rede e pelo ajuste dos protocolos de rede para otimizar sua eficiência.
A rede de computadores é teoricamente um modelo OSI de sete camadas, mas na prática pode ser vista como cinco camadas (ou modelo de quatro camadas), nomeadamente a camada física, a camada de enlace de dados, a camada de rede, a camada de transporte e a camada de aplicação. Cada camada é responsável por encapsular, desmontar e analisar seus próprios protocolos e executar suas próprias tarefas. Por exemplo, é como se a empregada do palácio vestisse e despisse o imperador camada por camada: você é responsável pelo casaco e eu pela roupa íntima, cada um desempenhando suas funções. Como front-end, focamos principalmente na camada de aplicação e na camada de transporte, começando com o protocolo HTTP da camada de aplicação com o qual lidamos todos os dias.
Otimização do protocolo http
1. Em HTTP/1.1, é necessário evitar atingir o limite máximo simultâneo de solicitações do navegador para o mesmo nome de domínio (geralmente 6 para Chrome)
- Quando há um grande número de solicitações de recursos de página, você pode preparar vários nomes de domínio e usar diferentes solicitações de nomes de domínio para ignorar o limite máximo de simultaneidade.
- Vários ícones pequenos podem ser mesclados em uma imagem grande, de modo que vários recursos de imagem exijam apenas uma solicitação. O front-end exibe os ícones correspondentes (também chamados de imagens sprite) por meio do estilo CSS de posição de fundo.
2. Reduza o tamanho do cabeçalho HTTP
- Por exemplo, solicitações do mesmo domínio carregarão automaticamente cookies, o que é um desperdício se não for necessária autenticação. Este tipo de recurso não deve estar no mesmo domínio do site.
3. Faça uso total do cache HTTP. O cache pode eliminar solicitações diretamente e melhorar significativamente o desempenho da rede.
- Os navegadores podem usar valores de cabeçalho HTTP, como no-cache e max-stale de controle de cache, para controlar se devem usar cache forte, negociar cache e se a expiração do cache ainda está disponível e outras funções.
- O servidor usa valores de cabeçalho http, como max-age, public, stale-while-revalidate de cache-control para controlar o tempo de cache forte, se ele pode ser armazenado em cache pelo servidor proxy, por quanto tempo o cache expira e como tempo que leva para atualizar automaticamente o cache.
4. A atualização para HTTP/2.0 ou superior pode melhorar significativamente o desempenho da rede. (Deve usar TLS, ou seja, https)
5. Otimize HTTPS
Existem dois aspectos principais que consomem muito desempenho do HTTPS:
- A primeira etapa é o processo de handshake do protocolo TLS;
- A segunda etapa é a transmissão de mensagens criptografadas simetricamente após o handshake.
Para a segunda etapa, os atuais algoritmos de criptografia simétrica convencionais AES e ChaCha20 têm bom desempenho, e alguns fabricantes de CPU também fizeram otimizações no nível de hardware para eles, portanto, o consumo de desempenho de criptografia nesta etapa pode ser considerado muito pequeno.
Na primeira etapa, o processo de handshake do protocolo TLS não apenas aumenta o atraso da rede (pode levar até 2 tempos de ida e volta da rede RTT), mas algumas etapas do processo de handshake também causarão perdas de desempenho, como:
Se o algoritmo de acordo de chave ECDHE for usado, tanto o cliente quanto o servidor precisarão gerar temporariamente chaves públicas e privadas de curva elíptica durante o processo de handshake; quando o cliente verificar o certificado, ele acessará o servidor CA para obter a CRL ou OCSP em para verificar se o certificado do servidor foi revogado; Em seguida, ambas as partes calculam o Pré-Mestre, que é a chave de criptografia simétrica. Para entender melhor em qual estágio de todo o handshake do protocolo TLS estão essas etapas, você pode consultar esta imagem:
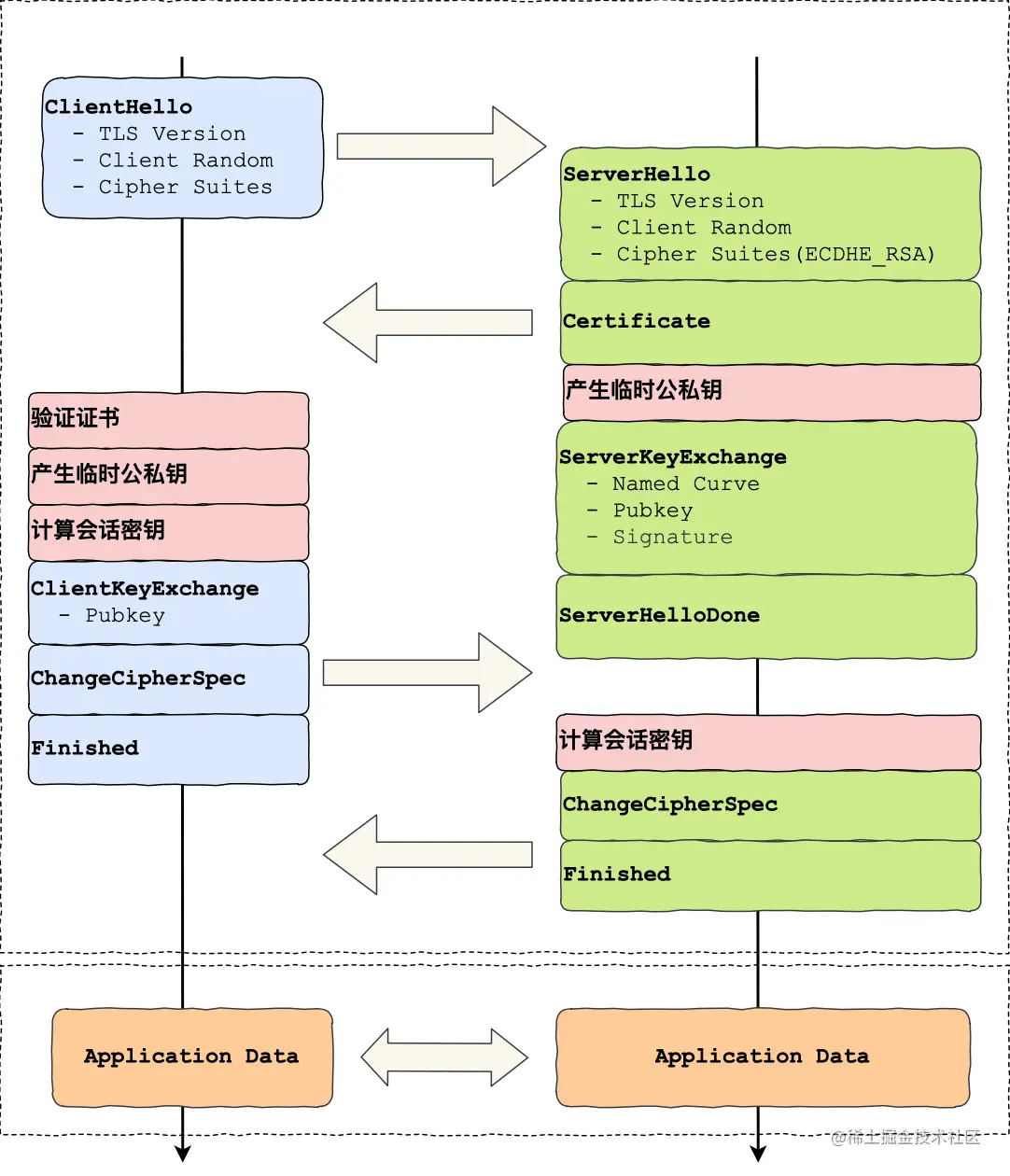
HTTPS pode ser otimizado usando os seguintes meios:
- Otimização de hardware: O servidor usa uma CPU que suporta o conjunto de instruções AES-NI
- Otimização de software: atualize a versão Linux e a versão TLS. O TLS/1.3 otimizou bastante o número de handshakes, exigindo apenas 1 tempo RTT, e oferece suporte à segurança de encaminhamento (o que significa que se a chave for quebrada agora ou no futuro, isso não afetará a segurança das mensagens interceptadas anteriormente).
- Otimização de certificado: grampeamento OCSP. Em circunstâncias normais, o navegador precisa verificar com a CA se o certificado foi revogado, e o servidor pode consultar periodicamente a CA para obter o status do certificado, obter um resultado de resposta com carimbo de data e hora e assinatura e armazená-lo em cache. Quando um cliente inicia uma solicitação de conexão, o servidor envia diretamente o "resultado da resposta" ao navegador durante o processo de handshake TLS, para que o próprio navegador não precise solicitar a CA.
- Reutilização de sessão 1: ID da sessão. Ambas as partes retêm a sessão na memória. Na próxima vez que uma conexão for estabelecida, a mensagem de saudação carregará o ID da sessão. Depois que o servidor a receber, ele a pesquisará na memória. Se encontrá-la , ele usará diretamente a chave de sessão para restaurar o estado da sessão, ignorando o resto do processo. Por segurança, as chaves de sessão na memória expiram periodicamente. Mas tem duas desvantagens: 1. O servidor deve salvar a chave de sessão de cada cliente. À medida que o número de clientes aumenta, o uso de memória do servidor aumenta. 2. Hoje em dia, os serviços do site são geralmente fornecidos por vários servidores por meio de balanceamento de carga. Quando o cliente se conecta novamente, ele pode não atingir o servidor que visitou da última vez. Se não conseguir atingir o servidor, ainda terá que passar pelo processo completo Processo de handshake TLS.
- Reutilização de sessão 2: Ticket de sessão, quando o cliente e o servidor estabelecem uma conexão pela primeira vez, o servidor irá criptografar a "chave de sessão" e enviá-la ao cliente como um Ticket, e o cliente salvará o Ticket. Isso é semelhante ao esquema de token usado para verificar a identidade do usuário no desenvolvimento web. Quando o cliente se conectar ao servidor novamente, o cliente enviará um ticket. Se o servidor puder descriptografá-lo, ele poderá obter a última chave de sessão e, em seguida, verificar o período de validade. Se não houver problema, a sessão poderá ser restaurada e a comunicação criptografada começa diretamente. Como somente o servidor pode criptografar e descriptografar essa chave, desde que ela possa ser descriptografada, significa que não há fraude. Para servidores de cluster, certifique-se de que a chave usada para criptografar a “chave de sessão” em cada servidor seja consistente, para que quando o cliente trouxer o Ticket para acessar qualquer servidor, a sessão possa ser restaurada.
Nem o ID de sessão nem o ticket de sessão têm segurança de encaminhamento, porque uma vez que a chave que criptografa a "chave de sessão" é quebrada ou o servidor vaza a chave, o texto cifrado de comunicação anteriormente sequestrado pode ser quebrado. Ao mesmo tempo, também é difícil enfrentar ataques de repetição.O chamado ataque de repetição consiste em assumir que o intermediário intercepta a mensagem de pós-solicitação, embora não possa descriptografar as informações nela contidas, ele pode reutilizar a mensagem não idempotente para solicite o servidor. Porque existe um servidor de tickets que pode reutilizar https diretamente. Para reduzir os danos dos ataques de repetição, um tempo de expiração razoável pode ser definido para a chave de sessão criptografada.
A seguir está uma introdução detalhada aos pontos de conhecimento http.
HTTP/0.9
A versão inicial é muito simples, com o objetivo de promover rapidamente seu uso. A função é apenas um simples get html. O formato da mensagem de solicitação é o seguinte:
GET /index.html
HTTP/1.0
Com o desenvolvimento da Internet, o http precisa atender a mais funções, por isso possui o familiar cabeçalho http, código de status, método de solicitação GET POST HEAD, cache, etc.
A desvantagem desta versão é que a conexão TCP será desconectada após cada solicitação, e a próxima solicitação HTTP exigirá que o TCP restabeleça a conexão. Portanto, alguns navegadores adicionaram um cabeçalho Connection: keep-alive não padrão, e o servidor responderá com o mesmo cabeçalho. Através deste acordo, o TCP pode manter uma conexão longa. Solicitações http subsequentes podem reutilizar este TCP até que uma parte feche ativamente isto.
HTTP/1.1
A versão 1.1 é atualmente amplamente utilizada. Nesta versão, a conexão longa tcp é usada por padrão. Se quiser fechá-la, você precisa adicionar ativamente o cabeçalho Connection: close.
Além disso, também possui um mecanismo de pipeline (pipelining), onde o cliente pode enviar continuamente várias solicitações http na mesma conexão tcp sem esperar o retorno do http. No passado, o design das solicitações HTTP era que apenas uma solicitação HTTP pudesse ser enviada por vez em uma conexão TCP. Somente após receber seu valor de retorno a solicitação HTTP seria concluída e a próxima solicitação HTTP poderia ser enviada. Embora a versão http/1.1 possa enviar vários https continuamente com base no mecanismo de pipeline, a versão 1.1 ainda só pode retornar respostas na ordem FIFO (primeiro a entrar, primeiro a sair) no servidor, portanto, se o primeiro http for muito lento durante a resposta, o os subsequentes ainda serão bloqueados pelo primeiro http. Ao receber múltiplas respostas consecutivas, o navegador irá dividi-las por Conteúdo-Comprimento.
Além disso, foi adicionada codificação de transferência em partes, substituindo o formato do buffer por um fluxo de fluxo. Por exemplo, para um vídeo, você não precisa mais lê-lo completamente na memória e depois enviá-lo. Você pode usar o fluxo para enviar uma pequena parte após cada pequena parte ser lida. Use o cabeçalho Transfer-Encoding: chunked para ativar. Haverá um número hexadecimal na frente de cada pedaço para representar o comprimento do pedaço. Se o número for 0, significa que o pedaço foi enviado. Em cenários como transferência ou processamento de arquivos grandes, o uso desse recurso pode melhorar a eficiência e reduzir o uso de memória.
Esta versão tem as seguintes desvantagens:
1. Bloqueio frontal. Uma solicitação-resposta é necessária antes que um http completo seja concluído e, em seguida, o próximo http possa ser enviado. Se o http anterior for lento, isso afetará o próximo horário de envio. Ao mesmo tempo, o navegador possui um número máximo de solicitações HTTP simultâneas para o mesmo nome de domínio, caso ultrapasse o limite, deverá aguardar a conclusão da anterior.
2. Redundância de cabeçalho http. Talvez cada cabeçalho de solicitação HTTP na página seja basicamente o mesmo, mas esses textos devem ser carregados sempre, o que é um desperdício de recursos de rede.
Na verdade, as deficiências do http1.1 são essencialmente causadas pelo seu posicionamento inicial como um protocolo de texto simples. Se quiser enviar fora de ordem, você precisará modificar o próprio protocolo, como adicionar um identificador exclusivo à solicitação/resposta e, em seguida, analisar o texto na outra extremidade para encontrar a ordem correspondente. Você precisa encapsular o protocolo http novamente, converter o texto em dados binários e realizar processamento de encapsulamento adicional. De acordo com o princípio de abertura e fechamento, novas adições são melhores que modificações, então obviamente a última solução é mais razoável. Portanto, http/2.0 dividirá os dados originais em quadros binários para facilitar as operações subsequentes. Isso equivale a adicionar mais algumas etapas ao original, e o núcleo http original não mudou.
HTTP/2.0
Novas melhorias não incluem apenas a otimização da multiplexação de longa data em HTTP/1.1, corrigindo o problema de bloqueio de cabeçalho, permitindo que a prioridade da solicitação seja definida, mas também incluem um algoritmo de compactação de cabeçalho (HPACK). Além disso, o HTTP/2 usa texto binário em vez de texto simples para empacotar e transmitir dados entre o cliente e o servidor.
Quadros, mensagens, fluxos e conexões TCP
Podemos pensar na versão 2.0 como a adição de uma camada de enquadramento binário em http. Uma mensagem (uma solicitação ou resposta completa é chamada de mensagem) é dividida em vários quadros. O quadro contém: tipo, comprimento, sinalizadores, identificador de fluxo Stream e carga útil do quadro. Ao mesmo tempo, o conceito abstrato de fluxo também é adicionado. O identificador de fluxo de cada quadro representa a qual fluxo ele pertence. Como http/2.0 pode ser enviado fora de ordem sem esperar, o remetente/receptor enviará fora de ordem de acordo com ao identificador de fluxo. Os dados são montados. Para evitar conflitos causados por IDs de fluxo duplicados em ambas as extremidades, o fluxo iniciado pelo cliente possui um ID ímpar e o fluxo iniciado pelo servidor possui um ID par. O conteúdo do protocolo original não é afetado. O primeiro cabeçalho de informação em http1.1 é encapsulado no quadro Headers e o corpo da solicitação será encapsulado no quadro Data. Múltiplas solicitações usam apenas um canal TCP. Esta iniciativa mostrou na prática que o carregamento de novas páginas pode ser acelerado de 11,81% a 47,7% em comparação com HTTP/1.1. Métodos de otimização como vários nomes de domínio e imagens sprite não são mais necessários em http/2.0.
Algoritmo HPACK
O algoritmo HPACK é um algoritmo recentemente introduzido no HTTP/2 e é usado para compactar cabeçalhos HTTP. O princípio é:
De acordo com o Apêndice A da RFC 7541, o cliente e o servidor mantêm um dicionário estático comum (Tabela Estática), que contém códigos para nomes de cabeçalhos comuns e combinações de nomes e valores de cabeçalhos comuns; o cliente e o servidor seguem a primeira entrada O primeiro a
sair princípio mantém um dicionário dinâmico comum (tabela dinâmica) que pode adicionar conteúdo dinamicamente; o
cliente e o servidor suportam a codificação Huffman com base nesta tabela de código Huffman estática de acordo com o Apêndice B da RFC 7541).
envio de servidor
No passado, os navegadores precisavam iniciar ativamente solicitações para obter dados do servidor. Isso requer a adição de scripts de solicitação js adicionais ao site, e você também precisa aguardar o carregamento dos recursos js antes de ligar. Isso resulta em atraso no tempo de solicitação e em mais solicitações. HTTP/2 oferece suporte a push ativo do lado do servidor, o que não exige que o navegador envie solicitações ativamente, economizando a eficiência das solicitações e otimizando a experiência de desenvolvimento. O front-end pode escutar eventos push do servidor por meio do EventSource.
HTTP/3.0
O HTTP/2.0 fez muitas otimizações em comparação com seu antecessor, como multiplexação, compactação de cabeçalho, etc., mas como a camada subjacente é baseada em TCP, alguns pontos problemáticos são difíceis de resolver.
bloqueio de linha
O HTTP é executado sobre o TCP. Embora o enquadramento binário já possa garantir que várias solicitações no nível HTTP não sejam bloqueadas, você pode saber pelos princípios do TCP mencionados acima que o TCP também possui bloqueio e retransmissão head-of-line. O recebimento do pacote não será devolvido e os subsequentes não serão enviados. Portanto, HTTP/2.0 resolve apenas o bloqueio inicial no nível HTTP e ainda é bloqueado em todo o link de rede. Seria ótimo se um novo protocolo pudesse ser usado para transmitir mais rapidamente em ambientes de rede modernos.
Latência de handshake TCP, TLS
O TCP possui 3 handshakes, o TLS (1.2) possui 4 handshakes e um total de 3 atrasos RTT são necessários para emitir uma solicitação http real. Ao mesmo tempo, como o mecanismo de prevenção de congestionamento do TCP começa a partir de um início lento, ele diminuirá ainda mais a velocidade.
Trocar de rede causa reconexão
Sabemos que a exclusividade de uma conexão TCP é determinada com base no IP e na porta de ambas as extremidades. Hoje em dia, as redes móveis e o transporte estão muito desenvolvidos. Quando você entra no escritório ou vai para casa, seu celular se conecta automaticamente ao WIFI. É muito comum que as redes de telefonia móvel mudem as estações base de sinal em metrôs e trens de alta velocidade em dez segundos. Todos eles causarão alterações de IP, invalidando assim a conexão TCP anterior. O que se manifesta é que uma página da web que está parcialmente aberta de repente não pode ser carregada, e um vídeo que está armazenado em buffer até a metade não pode ser armazenado em buffer no final.
Protocolo QUIC
Os problemas acima são inerentes ao TCP. Para resolvê-los, só podemos alterar o protocolo. http/3.0 usa o protocolo QUIC. Um protocolo completamente novo requer suporte de hardware, que inevitavelmente levará muito tempo para se popularizar, então o QUIC é construído sobre um protocolo UDP existente.
O protocolo QUIC tem muitas vantagens, como:
Sem bloqueio de cabeçalho
O protocolo QUIC também possui o conceito de Stream e multiplexação semelhante ao HTTP/2. Ele também pode transmitir vários Streams simultaneamente na mesma conexão. Um Stream pode ser considerado como uma solicitação HTTP.
Como o protocolo de transporte usado pelo QUIC é o UDP, o UDP não se preocupa com a ordem dos pacotes, nem o UDP se os pacotes forem perdidos.
No entanto, o protocolo QUIC ainda precisa garantir a confiabilidade dos pacotes de dados. Cada pacote de dados é identificado exclusivamente por um número de sequência. Quando um pacote em um fluxo é perdido, mesmo que outros pacotes no fluxo cheguem, os dados não podem ser lidos pelo HTTP/3. Os dados não serão entregues ao HTTP/3 até que o QUIC retransmita o pacote perdido.
Desde que o pacote de dados de um determinado fluxo seja totalmente recebido, o HTTP/3 pode ler os dados desse fluxo. Isso é diferente do HTTP/2, onde se um pacote for perdido em um fluxo, outros fluxos serão afetados.
Portanto, não há dependência entre vários Streams na conexão QUIC. Eles são todos independentes. Se um determinado stream perder pacotes, isso afetará apenas esse stream e outros streams não serão afetados.
Estabelecimento de conexão mais rápido
Para os protocolos HTTP/1 e HTTP/2, TCP e TLS são camadas e pertencem à camada de transporte implementada pelo kernel e à camada de apresentação implementada pela biblioteca OpenSSL, respectivamente. Portanto, eles são difíceis de mesclar e precisam ser abalados em lotes. Primeiro o handshake TCP e depois o handshake TLS.
Embora HTTP/3 também exija um handshake de protocolo QUIC antes de transmitir dados, esse processo de handshake requer apenas 1 RTT. O objetivo do handshake é confirmar o "ID de conexão" de ambas as partes, como migração de conexão (por exemplo, a rede precisa a ser migrado devido à comutação de IP) Implementado com base no ID de conexão.
O protocolo QUIC de HTTP/3 não está em camadas com TLS, mas QUIC contém TLS internamente. Ele carregará o "registro" em TLS em seu próprio quadro. Além disso, QUIC usa TLS 1.3, portanto, apenas um RTT pode completar o estabelecimento da conexão e negociação de chave "simultaneamente". Mesmo durante a segunda conexão, o pacote de dados do aplicativo pode ser enviado junto com as informações de handshake QUIC (informações de conexão + informações TLS) para obter o efeito de 0-RTT.
Conforme mostrado na parte direita da figura abaixo, quando a sessão HTTP/3 é restaurada, os dados da carga útil são enviados junto com o primeiro pacote, que pode atingir 0-RTT: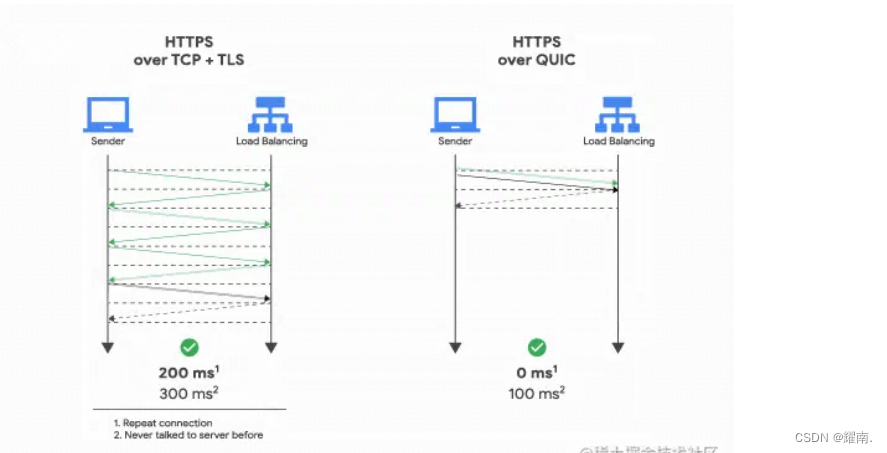
Migração de conexão
Quando a rede do dispositivo móvel muda de 4G para WiFi, significa que o endereço IP mudou, portanto a conexão deve ser desconectada e depois restabelecida. O processo de estabelecimento de uma conexão inclui o atraso do handshake triplo TCP e o Aperto de mão de quatro vias TLS. E o processo de desaceleração do início lento do TCP dá aos usuários a sensação de que a rede está travada repentinamente, então o custo de migração da conexão é muito alto. Se você estiver em um trem de alta velocidade, seu IP hUI poderá mudar continuamente, o que fará com que sua conexão TCP seja reconectada constantemente.
O protocolo QUIC não usa um método de quatro tuplas para "ligar" a conexão, mas usa o ID de conexão para marcar os dois pontos finais da comunicação. O cliente e o servidor podem escolher cada um um conjunto de IDs para se marcar, então mesmo se a rede do dispositivo móvel Após a alteração, o endereço IP muda. Contanto que as informações de contexto (como ID de conexão, chave TLS, etc.) ainda sejam retidas, a conexão original pode ser reutilizada "perfeitamente", eliminando o custo de reconexão sem qualquer atraso, conseguindo A função de migração de conexão é fornecida.
Estrutura de quadro simplificada, compressão de cabeçalho otimizada QPACK
O HTTP/3 usa a mesma estrutura de quadro binário do HTTP/2. A diferença é que o Stream precisa ser definido no quadro binário do HTTP/2, enquanto o próprio HTTP/3 não precisa mais definir o Stream e usa o Stream no QUIC. diretamente, então HTTP/ A estrutura do quadro 3 também se tornou mais simples.
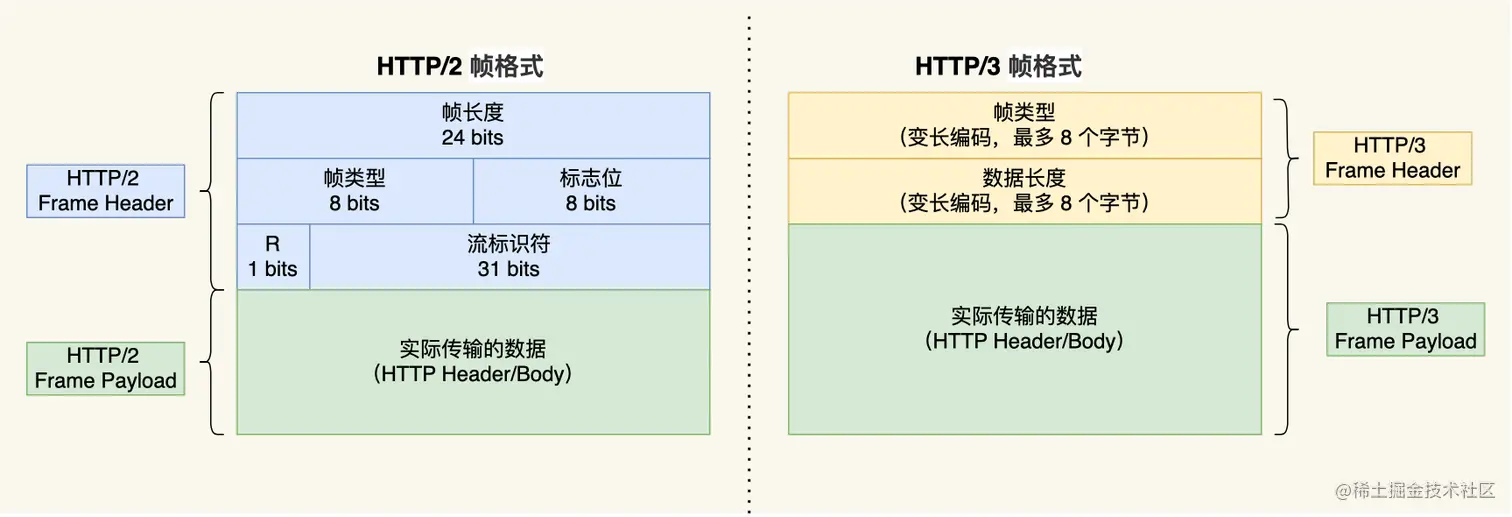
De acordo com os diferentes tipos de quadros, eles são geralmente divididos em duas categorias: quadros de dados e quadros de controle. Os quadros de cabeçalho (cabeçalhos HTTP) e os quadros de DADOS (corpos de pacotes HTTP) pertencem a quadros de dados.
HTTP/3 também foi atualizado em termos de algoritmo de compactação de cabeçalho, que foi atualizado para QPACK. Semelhante ao método de codificação HPACK em HTTP/2, QPACK em HTTP/3 também usa tabela estática, tabela dinâmica e codificação Huffman.
Em relação às mudanças na tabela estática, a tabela estática do HPACK no HTTP/2 possui apenas 61 entradas, enquanto a tabela estática do QPACK no HTTP/3 foi ampliada para 91 entradas.
A codificação Huffman de HTTP/2 e HTTP/3 não é muito diferente, mas os métodos de codificação e decodificação de tabela dinâmica são diferentes.
Na chamada tabela dinâmica, após a primeira solicitação-resposta, ambas as partes atualizarão os itens de cabeçalho (como alguns cabeçalhos customizados) não incluídos na tabela estática em suas respectivas tabelas dinâmicas, e então usarão apenas 1 número para representá-los em transmissões subsequentes.Então a outra parte pode consultar os dados correspondentes da tabela dinâmica com base neste número, sem ter que transmitir dados longos todas as vezes, o que melhora muito a eficiência da codificação.
Pode-se observar que a tabela dinâmica é sequencial, se o primeiro cabeçalho da solicitação for perdido e as solicitações subsequentes encontrarem esse cabeçalho novamente, o remetente pensará que a outra parte já o armazenou na tabela dinâmica, então comprimirá o cabeçalho No entanto, a outra parte não pode decodificar o cabeçalho HPACK porque a outra parte não estabeleceu uma tabela dinâmica. Portanto, a decodificação de solicitações subsequentes deve ser bloqueada até que o pacote de dados perdido na primeira solicitação seja retransmitido antes que a decodificação normal possa ser alcançada.
O QPACK do HTTP/3 resolve esse problema, mas como ele o resolve?
O QUIC terá dois fluxos unidirecionais especiais. Apenas uma extremidade do chamado fluxo unidirecional pode enviar mensagens. Fluxos bidirecionais são usados para transmitir mensagens HTTP. O uso desses dois fluxos unidirecionais:
Um é chamado QPACK Encoder Stream, que é usado para passar um dicionário (valor-chave) para a outra parte.Por exemplo, ao se deparar com um cabeçalho de solicitação HTTP que não pertence a uma tabela estática, o cliente pode enviar o dicionário por meio deste Stream; o outro é chamado QPACK Decoder Stream, que é usado para responder à outra parte e informar que o dicionário que acabou de ser enviado foi atualizado para sua tabela dinâmica local, e você pode usar este dicionário para codificação posteriormente. Esses dois fluxos unidirecionais especiais são usados para sincronizar as tabelas dinâmicas de ambas as partes.A parte codificadora usará a tabela dinâmica para codificar o cabeçalho HTTP após receber a notificação de confirmação de atualização da parte decodificadora. Se a mensagem de atualização da tabela dinâmica for perdida, isso fará com que apenas alguns cabeçalhos não sejam compactados e não bloqueará a solicitação HTTP.
Explicação detalhada do cache HTTP
Se um recurso de rede não precisar ser solicitado e for obtido diretamente do cache local, é naturalmente o mais rápido. O mecanismo de cache é definido no protocolo http, que é dividido em cache local (também chamado de cache forte) e cache que precisa ser verificado por meio de solicitações (também chamado de cache de negociação).
Cache local (cache forte)
Em http1.0, o cabeçalho de resposta expires é usado para indicar o tempo de expiração do valor de retorno.Dentro desse tempo, o navegador pode usar o cache diretamente sem solicitar novamente. Após http1.1, ele foi alterado para o cabeçalho de resposta Cache-Control, que pode atender a mais requisitos de cache.A idade máxima interna indica que o recurso expirará N segundos após a solicitação. Observe que a idade máxima não é o tempo decorrido após o navegador receber a resposta. É o tempo decorrido após a geração da resposta no servidor de origem e não tem nada a ver com o tempo do navegador. Portanto, se outro servidor de cache na rede armazenar a resposta por 100 segundos (indicado pelo campo Idade do cabeçalho de resposta), o cache do navegador deduzirá 100 segundos do seu tempo de expiração. Quando o cache expirar (ignoramos o impacto de obsoleto enquanto revalida, máximo obsoleto etc.), o navegador iniciará uma solicitação condicional para verificar se o recurso está atualizado (também chamado de cache de negociação).
Solicitação condicional (negociar cache)
O cabeçalho da solicitação terá os campos If-Modified-Since e If-None-Match, que são Last-Modified e etag no último cabeçalho de resposta da solicitação, respectivamente. Last-Modified indica a hora em que o recurso foi modificado pela última vez, em segundos. Etag é o identificador de uma versão específica de um recurso (por exemplo, um etag pode ser gerado por hash do conteúdo). O servidor retornará uma resposta de código de status 304 quando não houver alteração em If-None-Match ou If-Modified-Since. O navegador pensará que o recurso não foi atualizado e reutilizará o cache local. Como o tempo de modificação do registro da Última Modificação é em segundos, se a frequência de modificação ocorrer dentro de 1 segundo, não será possível avaliar com precisão se ele foi atualizado, portanto, a prioridade de julgamento do etag é maior do que a da Última Modificação.
Se no-cache for definido em Cache-Control, o cache forte será forçado a não ser usado e o cache negociado será usado diretamente, ou seja, max-age=0. Se nenhum armazenamento for definido, nenhum cache será usado.
A estratégia de cache do navegador para solicitações é simplesmente assim. Podemos ver que o cache é determinado pelos cabeçalhos de resposta e de solicitação. Durante o processo de desenvolvimento, o gateway e o navegador geralmente o configuram automaticamente para nós. Se você tiver necessidades específicas, pode ser personalizado para usar mais funções de controle de cache.
Funcionalidade completa de controle de cache
Cache-Control também possui recursos de controle de cache mais detalhados. Para o significado completo dos cabeçalhos de resposta e cabeçalhos de solicitação, consulte a tabela abaixo.
cabeçalho de resposta
 Cabeçalhos de solicitação (apenas aqueles que não estão incluídos nos cabeçalhos de resposta são listados) |max-stale|O cache ainda está disponível quando expira não mais do que o máximo de segundos obsoletos | |min-fresh|Requer que o serviço de cache retorne novos caches dados em min-fresh segundos, caso contrário, não usará cache local | |only-if-cached| O navegador exige que o recurso de destino seja retornado somente se o servidor de cache o tiver armazenado em cache |
Cabeçalhos de solicitação (apenas aqueles que não estão incluídos nos cabeçalhos de resposta são listados) |max-stale|O cache ainda está disponível quando expira não mais do que o máximo de segundos obsoletos | |min-fresh|Requer que o serviço de cache retorne novos caches dados em min-fresh segundos, caso contrário, não usará cache local | |only-if-cached| O navegador exige que o recurso de destino seja retornado somente se o servidor de cache o tiver armazenado em cache |
Otimização do protocolo TCP
Você pode precisar dele ao escrever node. Está tudo bem, não se preocupe, quem está interessado apenas em front-end puro pode pular :)
Primeiro, forneceremos diretamente métodos de otimização para diferentes problemas.Os princípios específicos do TCP e por que esses fenômenos ocorrem serão introduzidos em detalhes posteriormente.
A seguinte otimização tcp geralmente ocorre no lado da solicitação
1. O tamanho da primeira solicitação não deve exceder 14kb, o que pode efetivamente utilizar o início lento do tcp. O mesmo pode ser feito para o primeiro pacote da página front-end.
- Supondo que a janela TCP inicial seja 10 e o MSS seja 1460, o tamanho do recurso da primeira solicitação não deve exceder 14.600 bytes, que é cerca de 14kb. Desta forma, o TCP do extremo oposto pode ser enviado de uma só vez, caso contrário, será enviado pelo menos 2 vezes, o que requer um RTT (tempo de ida e volta da rede) adicional.
2. O que devo fazer se o TCP for bloqueado devido ao envio frequente de pequenos pacotes de dados (menos que MSS)?
Isso é muito comum em operações de jogos (embora o protocolo tcp geralmente não seja usado) e em linha de comando ssh
- Desligue o algoritmo de Nagel
- Evite confirmação atrasada
Como otimizar a retransmissão de perda de pacotes TCP
- Ative o SACK via net.ipv4.tcp_sack (habilitado por padrão)
- Ative o D-SACK via net.ipv4.tcp_dsack (habilitado por padrão)
A seguinte otimização tcp geralmente ocorre no lado do servidor
1. O número de solicitações simultâneas recebidas pelo servidor é muito alto ou ele encontra um ataque SYN, fazendo com que a fila SYN fique cheia e incapaz de responder às solicitações.
- Usesyn cookies
- Reduza o número de novas tentativas de sincronização
- Aumentar o tamanho da fila de sincronização
2. Muitos TIME-WAITs fazem com que as portas disponíveis fiquem cheias e nenhuma outra solicitação possa ser enviada.
- Use a configuração tcp_max_tw_buckets do sistema operacional para controlar o número de TIME-WAITs simultâneos
- Se possível, aumente o intervalo de portas e o endereço IP do cliente ou servidor
O método de otimização TCP acima é baseado na compreensão do mecanismo TCP e no ajuste dos parâmetros do sistema operacional, o que pode alcançar a otimização do desempenho da rede até certo ponto. A seguir começaremos com o mecanismo de implementação do tcp e depois explicaremos o que esses métodos de otimização fazem.
Todos sabemos que uma conexão deve ser estabelecida antes da transmissão TCP, mas na verdade, a transmissão em rede não requer o estabelecimento de uma conexão. A rede foi originalmente projetada para ser em rajadas e enviar a qualquer momento, então o projeto da rede telefônica foi abandonado . Normalmente, a chamada conexão TCP é, na verdade, apenas um estado entre dois dispositivos que salva alguma comunicação entre si, e não é uma conexão real. O TCP precisa distinguir se é a mesma conexão por meio de cinco tuplas, uma das quais é o protocolo e as quatro restantes são src_ip, src_port, dst_ip, dst_port (ip duplo e número da porta). Além disso, há quatro coisas importantes no cabeçalho do segmento de mensagem TCP: Número de sequência é o número de sequência (seq) do pacote, que indica a posição do primeiro bit da parte de dados deste pacote em todo o fluxo de dados , que é usado para resolver o problema de caos de pacotes de rede. Número de confirmação (ack) representa o comprimento dos dados recebidos desta vez + o seq recebido desta vez.É também o próximo número de sequência da outra parte (remetente), que é usado para confirmar o recebimento e resolver o problema de não perder pacotes . Janela, também chamada de janela anunciada, é uma janela deslizante usada para implementar o controle de fluxo. Flag TCP é o tipo de pacote, como SYN, FIN, ACK, etc., que é usado principalmente para controlar a máquina de estado TCP.
A parte principal é apresentada abaixo:
tcp três vezes "aperto de mão"
A essência do handshake de três vias é saber o número de sequência inicial, MSS, janela e outras informações de ambas as partes, para que os dados possam ser unidos de maneira ordenada em uma situação fora de ordem, e o máximo capacidade de carga da rede e do hardware pode ser determinada.
O número de sequência sequencial inicial (ISN) é de 32 bits, que é gerado pelo relógio virtual adicionando 1 continuamente a uma frequência de 4 microssegundos. Ele retorna a 0 quando excede 2 ^ 32 e um ciclo leva 4,55 horas. A razão pela qual cada estabelecimento de conexão não inicia em 0 é para evitar o problema de conflito sequencial entre pacotes novos e pacotes antigos que chegam atrasados após a conexão ser desconectada e restabelecida. 4,55 horas excederam o Tempo de Vida Máximo do Segmento (MSL) e o pacote antigo não existe mais.
- O cliente envia um pacote SYN (flags: SYN), assumindo que a sequência inicial é x, então seq = x. O cliente tcp entra no estado SYN_SEND.
- O servidor tcp está inicialmente no estado LISTEN. Após recebê-lo, ele envia um pacote ACK (flags: ACK, SYN). Suponha que a sequência inicial seja y, seq = y, ack = x + 1. Isso ocorre porque os flags têm SYN e ocupa 1 comprimento. Então, em seguida, o cliente deve começar em x + 1. O servidor entra no estado SYN_RECEIVED.
- O cliente envia um pacote ACK após recebê-lo, seq = x + 1, ack = y + 1. Em seguida, continue a enviar o conteúdo real do pacote PSH (assumindo que o comprimento dos dados é 100), seq = x + 1, ack = y + 1. A razão pela qual o conteúdo real de seq e ack permanece inalterado em relação ao pacote ack é porque o sinalizador é ACK, que é usado apenas para confirmação e não ocupa o comprimento em si. O cliente entra no estado ESTABLISHED.
- O servidor envia um pacote ACK após recebê-lo, seq = y + 1, ack = x + 101. O servidor entra no estado ESTABLISHED.
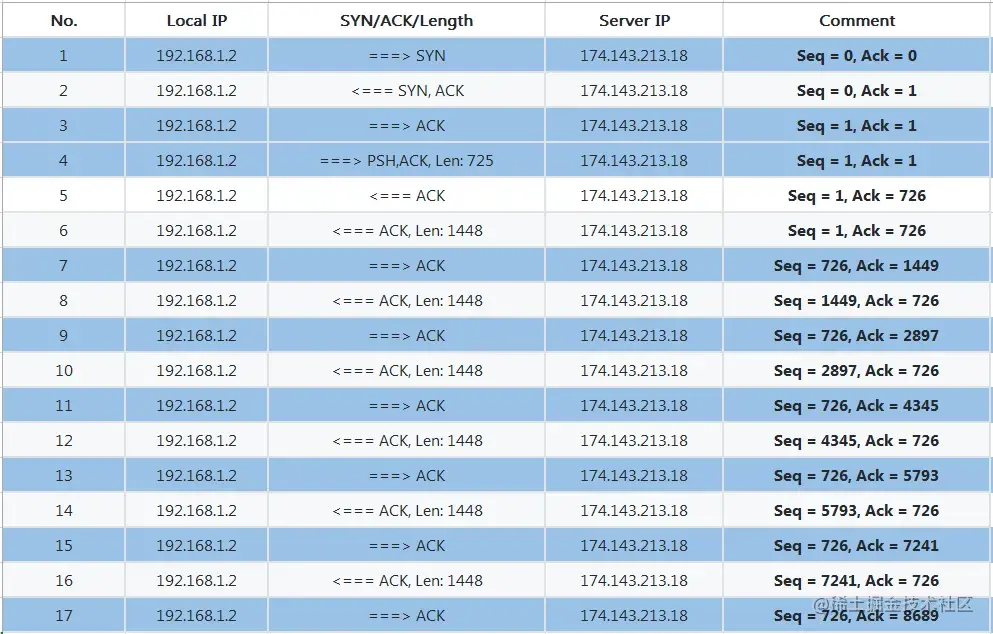
O cálculo de seq e ack pode ser comparado com esta imagem de captura de pacote (a imagem é da Internet, o número de sequência nela é um número de sequência relativo)
Tempo limite e ataques de SYN
Durante o handshake de três vias, depois que o servidor recebe o pacote SYN e retorna o SYN-ACK, o TCP está em um estado intermediário de semi-conexão. O kernel do sistema operacional colocará temporariamente a conexão na fila SYN. Após o três- Se o handshake for bem-sucedido, a conexão será colocada na fila completa. Se o servidor não receber o ACK do cliente, ele irá expirar e tentar novamente. A repetição padrão é 5 vezes, dobrando de 1s, 1s, 2s, 4s... até o quinto tempo limite, levará um total de 63s, momento em que o tcp será desconectado. Elimine esta conexão. Alguns invasores aproveitarão esse recurso para enviar um grande número de pacotes SYN ao servidor e depois se desconectar. O servidor terá que esperar 63 segundos antes de limpar a conexão da fila SYN, fazendo com que a fila SYN do TCP do servidor fique cheia e incapazes de continuar a prestar serviços. Essa situação também pode ocorrer em condições normais de grande concorrência. Neste momento podemos definir os seguintes parâmetros no Linux:
- tcp_syncookies, ele pode gerar um número de sequência especial (também chamado de cookie) a partir das informações quádruplas, o carimbo de data / hora incrementado a cada 64s e o valor da opção MSS após a fila SYN estar cheia.Este cookie pode ser enviado diretamente ao cliente como um seq. Jianlian. Desta forma inteligente, tcp_syncookies salva algumas informações em SYN sem precisar armazená-las localmente. Os observadores cuidadosos descobrirão que o tcp_syncookies parece exigir apenas dois apertos de mão para estabelecer uma conexão. Por que não incorporá-lo ao padrão tcp? Porque também tem deficiências, 1. A codificação do MSS é de apenas 3 bits, portanto, apenas 8 valores MSS podem ser usados no máximo. 2. O servidor deve rejeitar outras opções na mensagem SYN do cliente que sejam negociadas apenas em SYN e SYN+ ACK, pois o servidor não possui local para salvar essas opções, como Wscale e SACK. 3. Adicionadas operações criptográficas. Portanto, quando a fila SYN estiver cheia devido à grande simultaneidade normal, não use este método, pois é apenas uma versão emasculada do tcp.
- tcp_synack_retries, use-o para reduzir o número de novas tentativas para o tempo limite do SYN-ACK, o que também reduz o tempo de limpeza da fila SYN.
- tcp_max_syn_backlog, aumenta o número máximo de conexões SYN, ou seja, aumenta a fila SYN.
- tcp_abort_on_overflow, rejeita a conexão quando a fila SYN está cheia.
tcp "onda" quatro vezes
Supondo que o cliente se desconecte primeiro, a sequência no exemplo segue o último handshake.
Antes de fechar, o status tcp de ambas as extremidades é ESTABELECIDO.
- O cliente envia um pacote FIN (flags: FIN) para indicar que pode ser fechado, seq = x + 101, ack = y + 1. O cliente muda para o estado FIN-WAIT-1.
- O servidor recebe este FIN e retorna um ACK, seq = y + 1, ack = x + 102. O servidor muda para o estado CLOSE-WAIT. Após receber este ACK, o cliente muda para o estado FIN-WAIT-2.
- O servidor pode ter algum trabalho inacabado e, após a conclusão, enviará um pacote FIN para decidir fechar, seq = y + 1, ack = x + 102. O servidor muda para o estado LAST-ACK.
- O cliente retorna um ACK de confirmação após receber o FIN, seq = x + 102, ack = y + 2. O cliente muda para o estado TIME-WAIT
- Após receber o ACK do cliente, o servidor fecha diretamente a conexão e passa para o estado CLOSED. Se o cliente não receber novamente o FIN do servidor após aguardar o tempo 2*MSL, ele fecha a conexão e passa para o estado CLOSED.
Por que é necessário um longo TEMPO DE ESPERA? 1. Ele pode evitar que a nova conexão que reutiliza as quatro tuplas receba pacotes antigos atrasados. 2. Ele pode garantir que o servidor foi fechado.
Por que o tempo TIME-WAIT é 2*MSL (tempo máximo de sobrevivência do segmento, RFC793 define MSL como 2 minutos e o Linux o define como 30s)? Porque após o envio do FIN, o servidor irá reenviar se a espera pelo ACK expirar. O FIN tem o maior tempo de sobrevivência MSL, e a retransmissão deve ocorrer antes disso. O FIN reenviado também tem o maior tempo de sobrevivência MSL. Portanto, após 2 vezes o tempo MSL, o cliente ainda não recebeu o reenvio do servidor, indicando que o servidor recebeu o ACK e fechou, então o cliente pode ser fechado.
O que devo fazer se houver muitos TIME-WAITs gerados pela desconexão?
Sabemos que o Linux irá esperar 1 minuto por padrão antes de fechar a conexão, neste momento a porta está sempre ocupada. Se houver uma grande conexão curta simultânea, muitos TIME-WAITs podem fazer com que a porta fique cheia ou a CPU fique muito ocupada.
As duas últimas configurações são fortemente recomendadas para não serem usadas.
- tcp_max_tw_buckets, controla o número de TIME-WAITs simultâneos. O valor padrão é 180000. Se exceder, o sistema destruirá e registrará o log.
- ip_local_port_range, aumente o intervalo de portas do cliente
- Se possível, aumente a porta de serviço do servidor (as conexões TCP são baseadas em IP e porta, quanto mais, mais conexões estarão disponíveis)
- Se possível, aumente o IP do cliente ou servidor
- tcp_tw_reuse, o carimbo de data/hora deve estar habilitado no cliente e no servidor antes de poder ser usado. Ele só entra em vigor no cliente. Após a abertura, não há necessidade de aguardar o TIME-WAIT, leva apenas 1s. Novas conexões podem reutilizar diretamente este soquete. Por que preciso ativar o carimbo de data/hora? Porque o pacote da conexão antiga pode circular e finalmente chegar ao servidor, e o novo quíntuplo de conexão que reutiliza o soquete é o mesmo que o pacote antigo.Desde que o carimbo de data / hora seja anterior ao novo pacote, deve ser o pacote da conexão antiga, que pode ser evitada. Pacotes antigos inúteis foram aceitos erroneamente.
- tcp_tw_recycle, o processamento tcp_tw_recycle é mais agressivo, ele reciclará rapidamente o soquete no estado TIME_WAIT. A reciclagem rápida só ocorrerá quando tcp_timestamps e tcp_tw_recycle estiverem habilitados. Quando o cliente acessa o servidor através do ambiente NAT, o estado TIME_WAIT será gerado após o servidor ser fechado ativamente. Se o servidor tiver as opções tcp_timestamps e tcp_tw_recycle ativadas, o tempo de segmentação TCP do mesmo host IP de origem dentro de 60 segundos O carimbo deve ser incrementado, caso contrário será descartado. O Linux removeu a configuração tcp_tw_recycle a partir da versão 4.12 do kernel.
janela deslizante tcp e controle de fluxo
O sistema operacional abriu uma área de cache para tcp, que limita o número máximo de pacotes de dados enviados e recebidos pelo tcp. Ela pode ser visualizada como uma janela deslizante. A janela do remetente é chamada de janela de envio swnd, e a do destinatário é chamada de janela de recebimento rwnd. O comprimento dos dados que foram enviados, mas não recebidos, + o comprimento dos dados armazenados em buffer a serem enviados = o comprimento total da janela de envio.
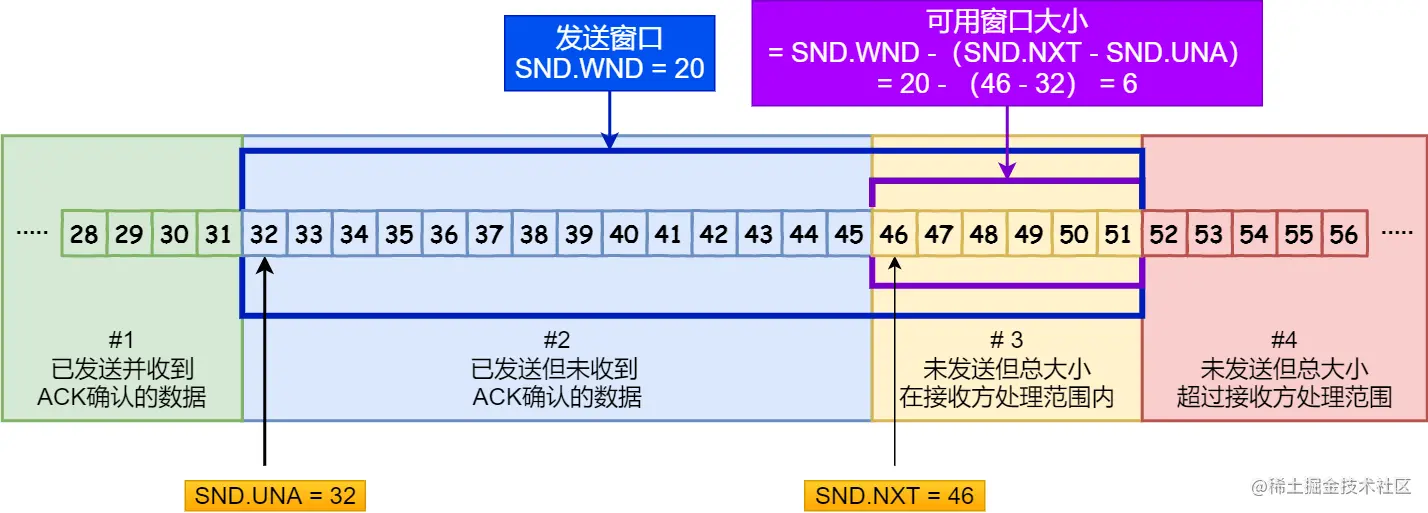
Durante o handshake, ambas as extremidades trocam valores da janela e o valor mínimo será eventualmente obtido. Suponha que o tamanho da janela do remetente seja 20 e que 10 pacotes sejam enviados no início, mas nenhuma confirmação foi recebida ainda, portanto, apenas mais 10 pacotes poderão ser colocados no buffer no futuro. Se o buffer estiver cheio, nenhum outro dado poderá ser enviado. Quando o receptor recebe dados, ele também os coloca no buffer. Se a capacidade de processamento for menor que a capacidade de envio do peer, o buffer se acumulará e a janela de recebimento disponível ficará menor. O valor da janela carregado pelo ack permitirá que o remetente para reduzir a quantidade de dados enviados. Além disso, o sistema operacional também ajustará o tamanho do buffer. Neste momento, uma situação pode ocorrer. A janela de recebimento original disponível é 10, que foi notificada ao peer por meio de confirmação, mas o sistema operacional diminui repentinamente o buffer e a janela é reduzida em 15. Em vez disso, a janela de recebimento disponível é reduzida em 15. Devo 5. O remetente recebeu anteriormente que a janela disponível é 10, então os dados ainda serão enviados, mas os dados não podem ser processados pelo destinatário, então o tempo limite. Para evitar esta situação, o TCP impõe que se o sistema operacional quiser modificar o buffer, ele deve enviar antecipadamente a janela disponível modificada.
Sabemos pelo conteúdo acima que o TCP limita o tráfego de envio pelas janelas em ambas as extremidades. Se a janela for 0, significa que o envio deve ser interrompido temporariamente. Quando o buffer do receptor estiver cheio e uma confirmação com janela 0 for enviada, e após um período de tempo o receptor for capaz de receber, uma confirmação com janela diferente de 0 será enviada para notificar o remetente para continuar enviando. Se esse ack for perdido, será muito grave, o remetente nunca saberá que o destinatário pode recebê-lo e ficará esperando e entrará em situação de impasse. Para evitar esse problema, o projeto do TCP é que após o remetente ser notificado para interromper o envio (ou seja, após receber a confirmação da janela 0), ele iniciará um cronômetro e enviará uma sonda de janela (sonda de janela) a cada 30 -60 segundos. Após receber a mensagem, o destinatário deve responder na janela atual. Se a detecção da janela for 0 por três vezes consecutivas, algumas implementações TCP enviarão pacotes RST para interromper a conexão.
Se a janela do receptor já for muito pequena, o remetente ainda usará esta janela para enviar dados. O cabeçalho tcp + cabeçalho ip tem 40 bytes, e os dados podem ter apenas alguns bytes, o que é muito antieconômico. Como evitar esta situação? Vamos dar uma olhada em como otimizar o pacote de drama decimal.
pacote pequeno tcp
Para o receptor, desde que não seja permitido enviar em uma janela pequena, o receptor geralmente tem esta estratégia: se a janela de recebimento for menor que o valor mínimo de MSS e espaço de cache/2, diga ao peer que a janela é 0 e pare de enviar dados. Até que a janela seja maior que essa condição.
Para o remetente, usando o algoritmo Nagle, apenas uma das duas condições a seguir é atendida antes do envio:
- Tamanho da janela >= MSS e tamanho total dos dados >= MSS
- Receba a confirmação dos dados enviados anteriormente
Se nenhum deles for atendido, ele continuará acumulando dados e os enviará todos juntos quando uma determinada condição for atendida.
O pseudocódigo é o seguinte
if there is new data to send then
if the window size ≥ MSS and available data is ≥ MSS then
send complete MSS segment now
else
if there is unconfirmed data still in the pipe then
enqueue data in the buffer until an acknowledge is received
else
send data immediately
end if
end if
end if
O algoritmo Nagle está ativado por padrão, mas em cenários como ssh com pequenos dados e muitas interações, Nagle será muito ruim quando encontrar confirmação atrasada, por isso precisa ser desligado. (O algoritmo Nagle não possui configuração global do sistema e precisa ser desligado de acordo com as respectivas aplicações)
Depois de falar sobre otimização de pequenos dados, agora vamos falar sobre a janela deslizante. Na verdade, a janela finalmente adotada pelo tcp não é inteiramente determinada pela janela deslizante. A janela deslizante apenas evita que ambas as extremidades excedam as capacidades de envio e recebimento. A rede as condições entre as duas extremidades também devem ser consideradas. Se ambas as extremidades enviam e recebem As capacidades são muito fortes, mas o ambiente de rede é muito ruim no momento. O envio de uma grande quantidade de dados só tornará a rede mais congestionada, então há ainda uma janela de congestionamento. O TCP assumirá o valor mínimo da janela deslizante e da janela de congestionamento.
início lento tcp e prevenção de congestionamento
Primeiro de tudo, vamos falar sobre o que é MSS. MSS é o comprimento máximo permitido de bytes de dados de um segmento tcp, que é o MTU (comprimento máximo de dados da camada de enlace de dados, especificado pelo hardware) menos o cabeçalho IP 20 bytes menos o cabeçalho tcp 20 Calculado em bytes, geralmente é 1460. Isso significa que um pacote TCP pode transportar até 1.460 bytes de dados da camada superior. O MSS mínimo é negociado em ambas as extremidades durante o handshake TCP. Em um ambiente de rede real, as solicitações passarão por vários dispositivos intermediários, e o MSS no SYN será modificado por eles.No final, será o valor mínimo em todo o caminho, não apenas o valor mínimo em ambas as extremidades.
O TCP possui uma cwnd (janela de congestionamento) responsável por evitar o congestionamento da rede. Seu valor é um múltiplo inteiro do tamanho do segmento TCP, que representa quantos pacotes o TCP pode enviar de uma vez (por conveniência, partimos de 1 para representá-lo). Seu valor inicial é muito pequeno, aumentará gradativamente até que ocorra perda de pacotes e retransmissão para detectar recursos de transmissão de rede disponíveis. No algoritmo clássico de início lento, no modo de confirmação rápida, cada vez que uma confirmação é recebida com sucesso, cwnd + 1, então cwnd aumenta exponencialmente, 1, 2, 4, 8, 16... até que o limite de início lento ssthresh seja atingido. (limiar de início lento), ssthresh é geralmente igual a max (valor de dados externos/2, 2*SMSS), SMSS é o tamanho máximo do segmento do remetente. Quando cwnd < ssthresh, o algoritmo de início lento é usado. Quando cwnd >= ssthresh, o algoritmo para evitar congestionamento é usado.
Algoritmo para evitar congestionamento, após o recebimento de cada confirmação de confirmação, cwnd aumentará em 1/cwnd, ou seja, todos os últimos pacotes enviados serão confirmados, cwnd + 1. Diferente do algoritmo de início lento, o algoritmo de prevenção de congestionamento aumenta linearmente até que dois tipos de retransmissões ocorram e então diminui, 1. ocorre retransmissão de tempo limite, 2. ocorre retransmissão rápida.
Confirmação rápida/atrasada, retransmissão de tempo limite e retransmissão rápida
No modo de confirmação rápida, o receptor envia uma confirmação imediatamente após receber o pacote, mas o TCP não retorna uma confirmação toda vez que recebe um pacote, o que é um desperdício de largura de banda da rede. O TCP também pode entrar no modo de confirmação atrasada. A extremidade receptora iniciará o temporizador de confirmação atrasada e verificará se a confirmação deve ser enviada a cada 200 ms. Se houver dados a serem enviados, eles também poderão ser mesclados com a confirmação. Supondo que o remetente envie vários pacotes de uma vez, o peer não pode responder com 10 acks, mas responderá apenas com o último ack do maior pacote consecutivo recebido. Por exemplo, se 1, 2, 3,...10 são transmitidos, o terminal receptor recebe todos eles, então ele responde com uma confirmação de 10, para que o terminal emissor saiba que todos os 10 primeiros foram recebidos, e o próximo um é iniciado a partir de 11. Se houver uma perda de pacote no meio, o reconhecimento antes da perda de pacote será retornado.
Retransmissão de tempo limite: O remetente iniciará um cronômetro após o envio. O tempo limite (RTO) é adequado para ser definido como um pouco maior que um RTT (tempo de ida e volta do pacote). Se o tempo limite de recebimento expirar, o pacote de dados será reenviado. Se os dados reenviados expirarem, o tempo limite será duplicado. Neste momento, ssthresh se torna cwnd/2, cwnd é redefinido para o valor inicial e o algoritmo de início lento é usado. Pode-se observar que o cwnd cai de um penhasco, portanto a ocorrência de retransmissão de tempo limite tem um grande impacto no desempenho da rede. Temos que esperar pelo RTO antes de retransmitir?
Retransmissão rápida: O TCP possui um design de retransmissão rápida. Se o receptor não receber o pacote em ordem, ele responderá com a maior confirmação consecutiva. Se o remetente receber 3 dessas confirmações consecutivas, ele considerará o pacote perdido e poderá rapidamente Retransmita esse pacote uma vez sem voltar ao início lento. Por exemplo, o receptor recebeu 1, 2 e 4, então respondeu com um ACK de 2 e depois recebeu 5 e 6. Como 3 foi interrompido no meio, ele ainda respondeu com um ACK de 2 duas vezes. O remetente recebeu o mesmo ack três vezes seguidas, então sabia que 3 estava perdido e retransmitiu rapidamente 3. O receptor recebe 3 e os dados são contínuos, então uma confirmação de 6 é retornada e o remetente pode continuar a transmitir a partir de 7. Assim como a imagem abaixo:
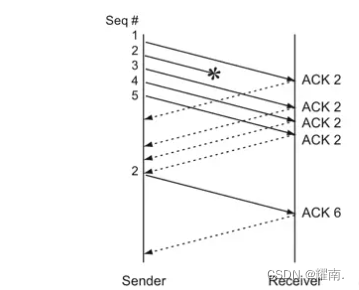
Quando ocorre uma retransmissão rápida:
- ssthresh = cwnd/2, cwnd = ssthresh + 3, comece a retransmitir pacotes perdidos e insira o algoritmo de recuperação rápida. A razão para +3 é que 3 acks duplicados foram recebidos, indicando que a rede atual pode pelo menos enviar e receber normalmente esses 3 pacotes adicionais.
- Quando um ACK duplicado é recebido, a janela de congestionamento aumenta em 1
- Quando o ACK do novo pacote de dados é recebido, cwnd é definido com o valor ssthresh na primeira etapa.
O algoritmo de retransmissão rápida apareceu pela primeira vez na versão Tahoe do 4.3BSD, e a recuperação rápida apareceu pela primeira vez na versão Reno do 4.3BSD, também chamada de versão Reno do algoritmo de controle de congestionamento TCP. Pode-se observar que o algoritmo de retransmissão rápida de Reno visa a retransmissão de um pacote, porém, na prática, um tempo limite de retransmissão pode causar a retransmissão de muitos pacotes de dados, portanto, quando vários pacotes de dados são perdidos de uma janela de dados, surgem problemas quando rápido algoritmos de retransmissão e recuperação rápida são acionados. Portanto, surge o NewReno, que é ligeiramente modificado com base na recuperação rápida do Reno e pode recuperar múltiplas perdas de pacotes em uma janela. Especificamente: Reno sai do estado de recuperação rápida quando recebe um ACK de novos dados, e NewReno precisa receber confirmação de todos os pacotes de dados na janela antes de sair do estado de recuperação rápida, melhorando ainda mais o rendimento.
Como retransmitir TCP "com precisão"
Se ocorrer perda parcial de pacotes, o remetente não sabe quais pacotes foram perdidos parcial ou completamente. Por exemplo, se a extremidade receptora receber 1, 2, 4, 5, 6, a extremidade emissora poderá saber por meio de confirmação que os pacotes após 3 serão perdidos e acionará uma retransmissão rápida. Haverá duas decisões neste momento: 1. Retransmitir apenas o terceiro pacote. 2. Não sei se os pacotes 4, 5, 6... também foram perdidos, então simplesmente retransmito tudo depois do 3. Ambas as opções não são muito boas, se você reenviar apenas 3, se realmente perdê-las depois, cada uma terá que aguardar a retransmissão. Mas se todos forem retransmitidos diretamente, seria um desperdício perder apenas 3. Como deveríamos otimizá-lo?
A retransmissão rápida apenas reduz a chance de acionar a retransmissão por tempo limite.Nem a retransmissão rápida nem a retransmissão por tempo limite resolvem o problema de saber com precisão se deve retransmitir um ou todos eles. Existe um método melhor chamado Reconhecimento Seletivo (SACK), que precisa ser suportado por ambas as extremidades. O Linux o alterna através do parâmetro net.ipv4.tcp_sack. O SACK adicionará um dado ao cabeçalho tcp para informar ao remetente quais segmentos de dados foram recebidos além do máximo contínuo, para que o remetente saiba que os dados não precisam ser retransmitidos. Uma imagem vale mais que mil palavras:
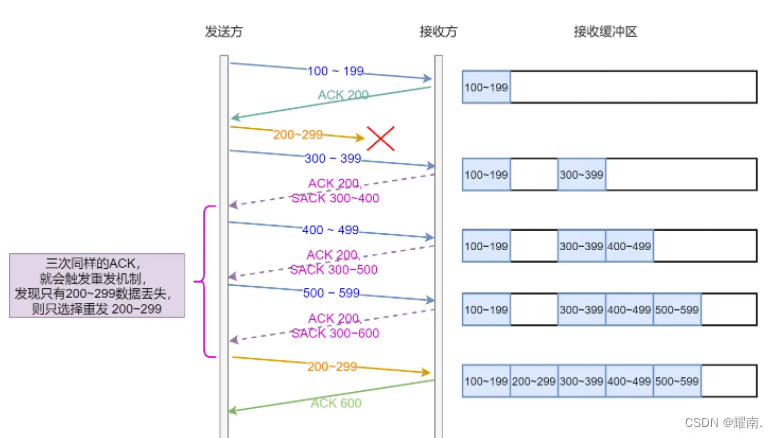
Há também SACK Duplicado (D-SACK). Se o ACK de confirmação do destinatário for perdido, o remetente pensará erroneamente que o destinatário não o recebeu, acionando um tempo limite e uma retransmissão. Neste momento, o destinatário receberá dados duplicados. Ou porque o pacote enviado encontra congestionamento na rede, o pacote retransmitido chega antes do pacote anterior e o receptor também receberá dados duplicados. Neste momento, você pode adicionar um pedaço de dados SACK ao cabeçalho tcp. O valor é o intervalo do segmento de dados repetido. Como o segmento de dados é menor que o ack, o remetente sabe que o destinatário recebeu os dados e não os retransmitirá .

D-SACK é ligado e desligado no Linux através do parâmetro net.ipv4.tcp_dsack.
Resumindo, a função do SACK e do D-SACK é informar ao remetente quais pacotes não foram recebidos e se os pacotes foram recebidos repetidamente. Ele pode determinar se o pacote de dados foi perdido, o ack foi perdido, os dados o pacote foi atrasado pela rede ou a rede foi interrompida. Copiou o pacote de dados.
Um cache mais poderoso: Service Worker
O controle de cache HTTP mencionado acima é principalmente no backend, e se o cache expirar, embora haja um cache negociado, ainda haverá mais ou menos solicitações, o que requer uma rede, e geralmente só pode armazenar em cache solicitações de obtenção. Essas limitações impedem que o front-end seja capaz de executar aplicativos locais como o cliente. Então, há alguma maneira de tornar o front-end completamente cache de proxy? Sejam recursos estáticos ou interfaces de API, tudo pode ser decidido pelo próprio front-end. Ele pode até transformar a página da web em um aplicativo local completo, como um aplicativo . Este é o Service Worker sobre o qual falaremos a seguir, vamos ver quais recursos ele possui.
Cache off-line
O Service Worker pode ser considerado um proxy entre o aplicativo e a solicitação de rede, ele pode interceptar a solicitação e tomar as ações apropriadas com base na disponibilidade da rede ou em outra lógica personalizada. Por exemplo, você pode armazenar em cache HTML, CSS, JS, imagens e outros recursos depois que o aplicativo for aberto pela primeira vez. Na próxima vez que você abrir a página da web, intercepte a solicitação e retorne-a diretamente ao cache, para que seu aplicativo pode ser aberto off-line. Se o dispositivo estiver conectado à Internet posteriormente, você poderá solicitar os recursos mais recentes em segundo plano e determinar se ele foi atualizado. Se tiver sido atualizado, você pode lembrar o usuário de atualizar e atualizar. Em termos de inicialização, os aplicativos front-end que usam Service Worker não exigem nenhuma rede, assim como os aplicativos clientes.
notificação push
Além das solicitações de proxy, o Service Worker também pode permitir ativamente que o navegador envie notificações, assim como as notificações do aplicativo. Você pode usar esta função para fazer "recuperação do usuário", "notificações quentes", etc.
Itens proibídos
Nosso código js principal é executado no thread de renderização, e o Service Worker é executado em outro thread de trabalho, portanto, não bloqueará o thread principal, mas também fará com que algumas APIs fiquem inutilizáveis, como operar dom. Ao mesmo tempo, ele foi projetado para ser completamente assíncrono, de modo que APIs síncronas, como XHR e Web Storage, não possam ser usadas e solicitações de busca possam ser usadas. Import() dinâmico também não é possível, apenas módulos de importação estáticos são possíveis.
Por motivos de segurança, o Service Worker só pode ser executado no protocolo HTTPS (use localhost para permitir http). Afinal, sua capacidade de assumir solicitações já é muito poderosa. Se for adulterado maliciosamente por um intermediário, usuários comuns podem fazer isso A página da web nunca renderizará o conteúdo correto. No FireFox, também não está disponível no modo de navegação anônima.
Instruções
O código do Service Worker deve ser um arquivo js independente e pode ser acessado por meio de solicitações https. Se você estiver em um ambiente de desenvolvimento, poderá permitir o acesso a partir de endereços como http://localhost. Depois de prepará-los, você deve primeiro registrá-los no código do projeto:
if ("serviceWorker" in navigator) {
navigator.serviceWorker.register("/js/service-worker.js", {
scope: "../",
});
} else {
console.log("浏览器不支持Service Worker");
}
Suponha que o endereço do seu site seja https://www.xxx.com e que o js do Service Worker esteja preparado em https://www.xxx.com/js/service-worker.js e /js/service-worker .js é na verdade A solicitação é https://www.xxx.com/js/service-worker.js. O escopo na configuração indica o caminho sob o qual o Service Worker entra em vigor. Se o escopo não for definido, o diretório raiz padrão entrará em vigor. O Service Worker será usado em qualquer caminho na página da web. De acordo com o método de escrita no exemplo, se ./ estiver definido, o caminho efetivo será /js/* e ../ será o diretório raiz.
O Service Worker passará por esses 3 ciclos de vida
- Download
- Instalar
- Ativar
A primeira é a fase de download. Ao entrar em uma página da web controlada por um Service Worker, o download começará imediatamente. Se você já baixou antes, a atualização poderá ser determinada após esse download. A atualização será determinada nas seguintes circunstâncias:
- Ocorreu um salto de página dentro do escopo
- Um evento foi acionado no Service Worker e não foi baixado em 24 horas.
Quando o arquivo baixado for novo, ele tentará instalar o Install.Os critérios para julgar se é um arquivo novo são: primeiro download e comparação byte a byte com o arquivo antigo.
Se esta for a primeira vez que o Service Worker é usado, uma instalação será tentada e, após a instalação bem-sucedida, ative-o.
Se um Service Worker antigo já estiver em uso, ele será instalado em segundo plano e não será ativado após a instalação. Esta situação é chamada de trabalhador em espera. Imagine que o js antigo e o novo podem ter conflitos lógicos. O js antigo está em execução há algum tempo. Se você substituir diretamente o antigo pelo novo e continuar a executar a página da web, ela poderá travar diretamente.
Quando o novo Service Worker será ativado? Você deve esperar até que todas as páginas que usam o Service Worker antigo sejam fechadas antes que o novo Service Worker se torne um trabalhador ativo. Você também pode usar ServiceWorkerGlobalScope.skipWaiting() para pular a espera diretamente. Clients.claim() permite que o novo Service Worker controle as páginas existentes atualmente (aquelas que usam o antigo Service Worker).
Você pode saber quando a instalação ou ativação ocorre ouvindo eventos. O evento mais comumente usado é FetchEvent, que é acionado quando a página inicia uma solicitação. Você também pode usar Cache para armazenar dados em cache e usar FetchEvent.respondWith() para retornar a solicitação valor de retorno que você deseja. A seguir está uma maneira comum de escrever uma solicitação de cache:
// 缓存版本,可以升级版本让过去的缓存失效
const VERSION = 1;
const shouldCache = (url: string, method: string) => {
// 你可以自定义shouldCache去控制哪些请求应该缓存
return true;
};
// 监听每个请求
self.addEventListener("fetch", async (event) => {
const { url, method } = event.request;
event.respondWith(
shouldCache(url, method)
? caches
// 查找缓存
.match(event.request)
.then(async (cacheRes) => {
if (cacheRes) {
return cacheRes;
}
const awaitFetch = fetch(event.request);
const awaitCaches = caches.open(VERSION);
const response = await awaitFetch;
const cache = await awaitCaches;
// 放进缓存
cache.put(event.request, response.clone());
return response;
})
.catch(() => {
return fetch(event.request);
})
: fetch(event.request)
);
});
O cache de código acima não será atualizado após ser estabelecido. Se o seu conteúdo puder mudar e você estiver preocupado com a possibilidade de o cache ficar obsoleto, você pode retornar ao cache primeiro para garantir que os usuários possam ver o conteúdo o mais rápido possível, e em seguida, solicite o mais recente no plano de fundo do Service Worker. Os dados são atualizados no cache e, finalmente, o thread principal é notificado para informar ao usuário que o conteúdo foi atualizado, permitindo que o usuário decida se deseja atualizar o aplicativo. Você pode tentar escrever o código para solicitação em segundo plano e atualizar o julgamento sozinho. Aqui falamos principalmente sobre como o Service Worker informa ao thread principal que o conteúdo solicitado foi atualizado. Como se comunicar entre os dois threads?
Como o Service Worker se comunica com o thread principal
Por que a comunicação é necessária? Primeiro de tudo, se você quiser depurar, o console.log no thread de trabalho não aparecerá no DevTools. Em segundo lugar, se o seu recurso Service Worker for atualizado, ele deverá ser notificado ao thread principal, para que sua página possa exibir uma mensagem para lembrar ao usuário se ele deseja atualizar. Portanto, a comunicação pode ser uma necessidade comercial. Como o Service Worker é um thread separado, ele não pode se comunicar diretamente com nosso thread principal. Mas uma vez resolvido o problema de comunicação, ele pode ter muitos usos maravilhosos. Por exemplo, várias páginas no mesmo site podem usar threads de Service Worker para se comunicar entre páginas. Então, como resolver o problema de comunicação? Podemos criar um canal de mensagens new MessageChannel(), que possui duas portas que podem enviar e receber mensagens de forma independente. Forneça uma das portas, port2, ao Service Worker e deixe a porta port1 ativada o tópico principal, então eles poderão se comunicar através deste canal. O código a seguir mostrará como permitir que dois threads se comuniquem entre si para obter funções como "imprimir log de thread de trabalho", "notificar atualização de conteúdo" e "atualizar aplicativo".
código no thread principal
const messageChannel = new MessageChannel();
// 将port2交给控制当前页面的那个Service Worker
navigator.serviceWorker.controller.postMessage(
// "messageChannelConnection"是自定义的,用来区分消息类型
{ type: "messageChannelConnection" },
[messageChannel.port2]
);
messageChannel.port1.onmessage = (message) => {
// 你可以自定义消息格式来满足不同业务
if (typeof message.data === "string") {
// 可以打印来自worker线程的日志
console.log("from service worker message:", message.data);
} else if (message.data && typeof message.data === "object") {
switch (message.data.classification) {
case "content-update":
// 你可以自定义不同的消息类型,来做出不同的UI表现,比如『通知用户更新』
alert("有新内容哦,你可以刷新页面查看");
break;
default:
break;
}
}
};
Código no Service Worker
let messageChannelPort: MessagePort;
self.addEventListener("message", onMessage);
// 收到消息
const onMessage = (event: ExtendableMessageEvent) => {
if (event.data && event.data.type === "messageChannelConnection") {
// 拿到了port2保存起来
messageChannelPort = event.ports[0];
} else if (event.data && event.data.type === "skip-waiting") {
// 如果主线程发出了"skip-waiting"消息,这里就会直接更新Service Worker,也就让应用升级了。
self.skipWaiting();
}
};
// 发送消息
const postMessage = (message: any) => {
if (messageChannelPort) {
messageChannelPort.postMessage(message);
}
};
Compressão de arquivos, desempenho de imagem, adaptação de pixels do dispositivo
A compactação de arquivos de recursos, como js, css, imagens, etc. pode reduzir bastante o tamanho e melhorar bastante o desempenho da rede. Geralmente, o serviço de back-end configurará automaticamente o cabeçalho de compactação para nós, mas também podemos mudar para um algoritmo de compactação mais eficiente para obter uma melhor taxa de compactação.
codificação de conteúdo
Se você abrir qualquer site e olhar sua rede de recursos, verá que há um cabeçalho de codificação de conteúdo nos cabeçalhos de resposta, que pode ser gzip, compress, deflate, identidade, br e outros valores. Além da identidade não representar compactação, você pode definir outros valores para compactar o arquivo e acelerar a transmissão http, sendo o mais comum o gzip. Com suporte de compatibilidade, você pode definir especificamente alguns formatos de compactação mais recentes, como br (Brotli), para obter uma taxa de compactação superior a gzip.
arquivo de fonte
Se uma fonte especial for necessária na página e o texto na página for fixo ou pequeno (por exemplo, apenas letras e números), você poderá cortar manualmente o arquivo de fonte para que contenha apenas o texto necessário, o que pode reduzir bastante o tamanho do arquivo.
Se as palavras na página forem dinâmicas, você não terá como saber quais serão. Em cenários apropriados, como cenários em que os usuários podem visualizar efeitos de fonte ao inserir texto. Os usuários geralmente inserem apenas algumas palavras, portanto não há necessidade de apresentar todo o pacote de fontes, mas você não sabe o que o usuário irá inserir. Assim, você pode permitir que o back-end (ou construir uma camada de bff baseada em nodejs) gere dinamicamente um arquivo de fonte contendo apenas algumas palavras e retorne-o para você com base nas palavras desejadas. Embora haja mais uma solicitação de consulta, arquivos de fontes de vários Mb ou até mais de dez Mb podem ser reduzidos para alguns KB.
Formato de imagem
As imagens geralmente não são compactadas pelos métodos acima, porque esses formatos de imagem já foram compactados para você e a compactação novamente não terá muito efeito. Portanto, a escolha do formato da imagem é a chave para afetar o tamanho e a qualidade da imagem. De um modo geral, quanto menor for a compressão, mais tempo demora e pior é a qualidade da imagem. Mas não é absoluto: o novo formato pode fazer tudo melhor que o formato antigo, mas tem pouca compatibilidade. Então você precisa encontrar um equilíbrio.
Em termos de formatos de imagem, além dos comuns PNG-8/PNG-24, JPEG e GIF, prestamos mais atenção a vários outros formatos de imagem mais recentes:
- WebP
- JPEGXL
- AVIF
Use uma tabela para compará-los em termos de tipo de imagem, canal de transparência, animação, desempenho de codificação e decodificação, algoritmo de compactação, suporte de cores, uso de memória e compatibilidade:

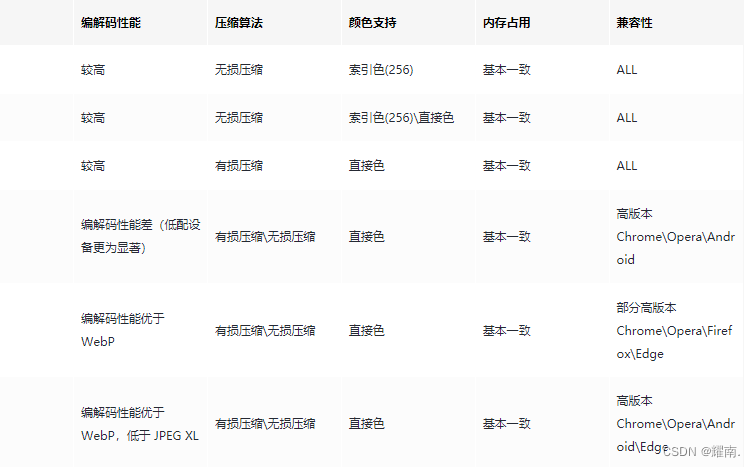
Do ponto de vista do desenvolvimento técnico, é dada prioridade ao uso de formatos de imagem relativamente novos: WebP, JPEG XL e AVIF. JPEG XL é muito promissor para substituir o formato de imagem tradicional, mas a compatibilidade ainda é muito ruim. A compatibilidade com AVIF é melhor que JPEG XL, mantendo alta qualidade de imagem após a compactação e evitando artefatos de compactação irritantes e outros problemas. No entanto, as velocidades de decodificação e codificação não são tão rápidas quanto JPEG XL e a renderização progressiva não é suportada. Basicamente, o WebP é suportado por todos os navegadores, exceto o IE. Para imagens complexas (como fotos), o desempenho da codificação sem perdas do WebP não é bom, mas o desempenho da codificação com perdas é muito bom. A velocidade de decodificação de imagem do WebP com qualidade semelhante não é muito diferente da do JPEG XL, mas a taxa de compactação do arquivo pode ser muito melhorada. Então, por enquanto, parece que se você deseja melhorar o desempenho da imagem do seu site, seria melhor usar WebP em vez do formato tradicional.
Uso do elemento Imagem
Então, há algo que possa nos ajudar automaticamente a usar formatos de imagem semelhantes a WebP, AVIF e JPEG XL mencionados acima em navegadores que suportam alguns formatos de imagem modernos, enquanto navegadores que não suportam recorrem ao método JPEG, PNG normal? A especificação HTML5 adiciona um novo elemento Picture. O elemento <picture> fornece versões de uma imagem para diferentes cenários de exibição/dispositivo contendo zero ou mais elementos <source> e um elemento <img>. O navegador selecionará o elemento filho <source> com melhor correspondência ou, se não houver correspondência, selecionará a URL no atributo src do elemento <img>. A imagem selecionada é então renderizada no espaço ocupado pelo elemento <img>.
<picture>
<!-- 可能是一些对兼容性有要求的,但是性能表现更好的现代图片格式-->
<source src="image.avif" type="image/avif" />
<source src="image.jxl" type="image/jxl" />
<source src="image.webp" type="image/webp" />
<!-- 最终的兜底方案-->
<img src="image.jpg" type="image/jpeg" />
</picture>
Adaptação do tamanho da imagem: pixels físicos, pixels independentes do dispositivo
Se você deseja um ótimo desempenho de imagem, deve usar tamanhos de imagem apropriados para elementos de tamanhos diferentes. Se uma imagem de 500*500 for exibida em uma área de 100*100 pixels, isso é obviamente um desperdício; pelo contrário, uma imagem de 100*100 em 500*500 pixels fica muito borrada, o que reduz a experiência do usuário. Antes de falar sobre adaptação de tamanho, devemos primeiro falar sobre o que são pixels independentes de dispositivo e pixels físicos, e o que é DPR.
Quando escrevemos width: 100px em CSS, o que é exibido na tela é na verdade um pixel independente do dispositivo (também chamado de pixel lógico) de 100px de comprimento, que não é necessariamente os 100 pixels (pixels físicos) da tela. Na tela original, os pixels independentes do dispositivo e os pixels físicos eram 1:1, ou seja, largura: 1px corresponde a 1 ponto emissor de luz de pixel na tela. Com o subsequente desenvolvimento da tecnologia de exibição, os pixels das telas do mesmo tamanho tornaram-se cada vez mais refinados. Talvez a posição original de 1 pixel agora seja composta por 4 pixels. Isso traz maior densidade de pixels e uma melhor experiência visual, mas também cria um problema. Se width: 1px representar um ponto de luz de pixel como antes, a mesma página diminuirá neste dispositivo porque os pixels agora são menores. Para resolver esse problema, os fabricantes criaram o conceito de pixels independentes de dispositivos, que não são pixels reais, mas sim lógicos. Se 1 pixel no dispositivo for agora substituído por 2 pixels menores, então a proporção de pixels do dispositivo (DPR) do dispositivo será 2, e uma imagem desenhada com largura: 1px será desenhada por 2 pixels, então o tamanho e usado para ser consistente. Da mesma forma, em um dispositivo com uma tela mais fina, supondo que ele seja composto de 3 pixels menores em vez do tamanho tradicional de 1 pixel, então seu DPR é 3 e width: 1px é na verdade desenhado por 3 pixels. Agora você pode entender por que o entrevistador fez perguntas como "Como desenhar uma borda de 1px", porque sob alto DPR seu 1px na verdade não é 1px.
Portanto, podemos obter esta equação de pixel: 1 pixel css = 1 pixel independente do dispositivo = pixel físico * DPR.
Forneça imagens apropriadas para diferentes telas DPR
Portanto, embora nossos elementos img tenham todos 100px, o tamanho ideal da imagem que precisamos exibir é, na verdade, diferente em diferentes dispositivos DPR. Quando DPR = 2, uma imagem de 200px deve ser exibida, e quando DPR = 3, uma imagem de 300px deve ser exibida, caso contrário ocorrerão condições desfocadas.
Então, quais são algumas soluções possíveis?
Opção 1: gráficos múltiplos simples e brutos
O DPR mais alto em dispositivos comuns agora é 3, então a maneira mais simples é usar a exibição de imagem 3x mais alta por padrão. Mas isso causará muito desperdício de largura de banda, diminuirá o desempenho da rede e reduzirá a experiência do usuário, o que definitivamente não está de acordo com o “estilo” do nosso artigo.
Opção 2: consulta à mídia
Podemos usar consultas de mídia @media para aplicar diferentes CSS com base no DPR do dispositivo atual
#img {
background: url([email protected]);
}
@media (device-pixel-ratio: 2) {
#img {
background: url([email protected]);
}
}
@media (device-pixel-ratio: 3) {
#img {
background: url([email protected]);
}
}
A vantagem desta solução é que ela pode exibir imagens com diferentes ampliações sob diferentes DPR.
As desvantagens desta solução são:
- Existem muitas ramificações lógicas, e não existem apenas dispositivos no mercado com DPR = 2 ou 3, mas também alguns dispositivos com DPR decimal. Você precisa escrever muito código para cobrir tudo.
- Problemas de compatibilidade de sintaxe, por exemplo, em alguns navegadores é -webkit-min-device-pixel-ratio. Você pode resolver isso com o autoprefixer, mas isso também apresenta um custo adicional.
Opção 3: sintaxe de conjunto de imagens css
#img {
/* 不支持 image-set 的浏览器*/
background-image: url("../[email protected]");
/* 支持 image-set 的浏览器*/
background-image: image-set(
url("./[email protected]") 2x,
url("./[email protected]") 3x
);
}
Entre eles, 2x e 3x correspondem a diferentes DPR. As desvantagens da solução de conjunto de imagens são as mesmas das consultas de mídia, por isso não entrarei em detalhes. A vantagem é que é mais específico do que consultas de mídia e permite que você finja ser uma onda.
Opção 4: atributo do elemento srcset
<img src="[email protected]" srcset="[email protected] 2x, [email protected] 3x" />
Os 2x e 3x internos indicam a correspondência de DPRs diferentes e [email protected] é o resultado final. As vantagens e desvantagens são as mesmas do conjunto de imagens. A vantagem pode ser que não requer escrita de CSS e é mais conciso.
Opção 5: atributo srcset combinado com atributo tamanhos
<img
sizes="(min-width: 600px) 600px, 300px"
src="[email protected]"
srcset="[email protected] 300w, [email protected] 600w, [email protected] 900w"
/>
tamanhos = "(largura mínima: 600px) 600px, 300px" significa: se a largura de pixel CSS atual da tela for maior ou igual a 600px, a largura CSS da imagem será 600px. Caso contrário, a largura CSS da imagem será 300px. Como seu layout pode ser flexível, o tamanho do elemento img pode ser diferente em diferentes tamanhos de tela. As outras soluções acima só podem ser avaliadas com base no DPR, o que não pode ser alcançado. tamanhos também exige que @media altere realmente a largura do img com base no limite de largura.
srcset="[email protected] 300w, [email protected] 600w, [email protected] 900w" Os 300w, 600w e 900w internos são chamados de descritores de largura. Se você estiver em um dispositivo com DPR 2 e os pixels CSS do elemento img forem 300 com base nos tamanhos, os pixels físicos reais serão 600, portanto, uma imagem de 600w será usada.
A desvantagem desta solução ainda é a mesma de antes, ela precisa escrever imagens diferentes para DPR diferentes. Mas tem a vantagem única de poder alterar com flexibilidade a resolução real da imagem de acordo com o tamanho do elemento img em um layout responsivo. Portanto, recomendo a opção cinco.
Carregamento lento e decodificação assíncrona de imagens
O carregamento lento de imagens significa que quando a página não rola até a área de destino, as imagens ali não são solicitadas e exibidas, de forma a agilizar a exibição do conteúdo na área visível. As especificações atuais do front-end são muito ricas, temos js, html e outros métodos para implementar o carregamento lento de imagens.
Opção 1: usar onscroll em js
Esta é uma solução simples e grosseira. Obtenha a distância de todas as imagens na página do topo da janela de visualização por meio de getBoundingClientRectAPI, monitore a rolagem da página através do evento onscroll e calcule quais imagens aparecem na área visível com base na altura da janela de visualização e defina o atributo src do elemento img.Valor para controlar o carregamento da imagem.
A vantagem desta solução é que a lógica é simples e fácil de entender, não são utilizadas novas APIs e a compatibilidade é boa.
As desvantagens desta solução são:
- Precisa introduzir js, que traz alguma quantidade de código e custo de cálculo
- Necessidade de obter informações de posição de todos os elementos da imagem, o que pode desencadear refluxo adicional
- Precisa monitorar a rolagem o tempo todo e acionar retornos de chamada com frequência
- Se uma lista de rolagem estiver aninhada na página, esta solução não poderá saber a visibilidade dos elementos na lista de rolagem aninhada e exigirá uma escrita mais complexa.
Opção 2: usar IntersectionObserver em js
Por meio da API IntersectionObserver do HTML5, o Intersection Observer (observador de interseção) coopera com o atributo isIntersecting do elemento de monitoramento para determinar se o elemento está dentro da área visível e pode implementar uma solução de carregamento lento para imagens com melhor desempenho do que o monitoramento na rolagem. O elemento observado acionará um retorno de chamada quando aparecer ou desaparecer na área visível, e o limite da proporção de aparência também pode ser controlado. Consulte a documentação do mdn para obter detalhes.
As vantagens desta solução são:
- O desempenho é muito melhor do que onscroll. Ele não precisa monitorar a rolagem o tempo todo, nem obter a posição do elemento. A visibilidade é conhecida pelo thread de renderização ao desenhar e não há necessidade de julgá-la por meio de js Esta forma de escrever é mais natural.
- Ele pode realmente conhecer a visibilidade dos elementos, por exemplo, se um elemento for bloqueado por um elemento de nível superior, ele ficará invisível, mesmo que já apareça na área visível. Isso é algo que a solução onscroll não pode fazer.
As desvantagens desta solução são:
- Precisa introduzir js, que traz alguma quantidade de código e custo de cálculo
- Dispositivos mais antigos não são compatíveis e precisam usar polyfill
Opção 3: visibilidade de conteúdo em estilo CSS
Se um elemento com o estilo content-visibility: auto não estiver na tela, o elemento não será renderizado. Este método pode reduzir o trabalho de desenho e renderização de elementos em áreas não visíveis, mas os recursos de imagem são solicitados quando o HTML é analisado, portanto, esta solução CSS não pode realmente implementar o carregamento lento de imagens.
Solução 4: carregamento do atributo HTML = preguiçoso
<img src="xxx.png" loading="lazy" />
Solução de decodificação assíncrona de imagem
Como todos sabemos, imagens como jpeg, png, etc. são codificadas. Se você deseja que a GPU as reconheça e renderize, elas precisam ser decodificadas. Se determinados formatos de imagem forem decodificados muito lentamente, isso afetará a renderização de outros conteúdos. Portanto, o HTML5 adicionou um novo atributo de decodificação para informar ao navegador como analisar os dados da imagem.
Seus valores opcionais são os seguintes:
- sincronização: decodifique a imagem de forma síncrona para garantir que ela seja exibida junto com outro conteúdo.
- assíncrono: decodifique imagens de forma assíncrona para acelerar a exibição de outros conteúdos.
- auto: modo padrão, indicando que o modo de decodificação não é preferido. Cabe ao navegador decidir qual método é mais apropriado para o usuário.
<img src="xxx.jpeg" decoding="async" />
Isso permite que o navegador decodifique a imagem de forma assíncrona, acelerando a exibição de outros conteúdos. Esta é uma parte opcional do seu plano de otimização de imagem.
Resumo de otimização de desempenho de imagem
Em geral, para otimizar o desempenho da imagem, você precisa:
- Escolha um formato de imagem com alta taxa de compactação, velocidade de decodificação rápida e boa qualidade de imagem.
- Adapte a resolução de imagem apropriada de acordo com o DPR real e o tamanho do elemento
- Use uma solução de melhor desempenho para carregamento lento de imagens e use decodificação assíncrona dependendo da situação.
Otimização da ferramenta de construção
Existem muitas ferramentas populares de construção/empacotamento de front-end agora, como as antigas webpack, ,,,, rollupque se tornaram populares nos últimos anos vite, snowpacknovas forças esbuild,, swce turbopackassim por diante. Alguns deles são implementados em js, alguns são escritos em linguagens de alto desempenho, como go e ferrugem, e algumas ferramentas de construção usam recursos esm para empacotamento sob demanda. Mas essas são otimizações para velocidade durante o desenvolvimento ou construção e têm pouco a ver com o desempenho do cliente, por isso não entraremos nelas aqui. Falaremos principalmente sobre a otimização do desempenho da rede por meio do empacotamento do ambiente de produção. Embora essas ferramentas tenham várias configurações, os pontos de otimização comumente usados são: compactação de código, divisão de código, extração de código público, extração de CSS, uso de recursos CDN, etc., mas os métodos de configuração são diferentes. Basta verificar a documentação para isso. Existem muitos Funciona imediatamente. Algumas pessoas podem não entender muito bem essas palavras. Aqui está uma explicação.
Não há nada a explicar sobre compactação de código, significa substituir nomes de variáveis, remover novas linhas, remover espaços, etc., para tornar o código menor.
O objetivo da divisão de código é que, por exemplo, no SPA, a página A seja redirecionada da página inicial por meio de roteamento local, portanto, não há necessidade de empacotar este componente da página A com o aplicativo principal na página inicial, porque os usuários podem não necessariamente pular a ele e empacotá-lo. Ao mesmo tempo, aumenta o tamanho do pacote da página inicial e afeta a velocidade da primeira tela. Portanto, em algumas ferramentas de construção, você pode usar importação dinâmica ( import('PageA.js')), e a ferramenta de construção empacotará o código da página A referenciado na página inicial em um novo pacote, por exemplo a.js. Quando o usuário clica na página inicial para ir para a página A, a.jso código do componente interno será solicitado automaticamente e, em seguida, a rota será trocada e renderizada. Algumas estruturas funcionarão imediatamente e não exigirão que você escreva importações dinâmicas. Basta definir a rota e ela separará automaticamente o código para você, como a estrutura nextjs do react. Este é apenas um cenário de uso de separação de código. Em suma, contanto que você não queira que um determinado código de módulo seja empacotado com o aplicativo principal, você pode dividi-lo para obter melhor desempenho do primeiro lote de pacotes js.
O objetivo da extração de código comum é, supondo que você esteja escrevendo um SPA, você usa a biblioteca ramda nas páginas A, B e C, e o código é dividido nessas três páginas, e agora são três pacotes independentes: a.js, b.js, c.js. Portanto, de acordo com a lógica normal, a biblioteca ramda, como sua dependência, também será incluída nesses três pacotes, o que significa que essas três páginas possuem códigos ramda duplicados sem motivo. Então isso não é bom. A melhor maneira é colocar a biblioteca ramda como um pacote separado na aplicação principal, para que ela só precise ser solicitada uma vez, e o ABC possa usar essa biblioteca. Isto é o que a extração de código comum faz. Por exemplo, no webpack você pode definir quantas vezes um módulo depende repetidamente antes de ser extraído em um pacote separado como um pedaço comum.
optimization: {
// split-chunk-plugin 是webpack内置的插件 作用是自动将多个入口用到的公共文件抽离出来单独打包
splitChunks: {
chunks: 'all',
// 最小30kb
minSize: 30000,
// 被引用至少6次
minChunks: 6,
},
}
No entanto, a partir do webpack4, ele pode ajudá-lo automaticamente a otimizar o modo. Na verdade, você não precisa se preocupar com isso. Você pode ler mais sobre a documentação da ferramenta de construção usada para evitar otimizações desnecessárias.
O objetivo da extração de css é que, por exemplo, se você usar apenas css-loader + style-loader no webpack, então seu css será compilado em js, e js irá ajudá-lo a inserir o estilo ao renderizar o estilo. Então seu js ficará maior de forma invisível, e a renderização dos estilos css será atrasada até que js seja executado, e js geralmente é empacotado no final da página, ou seja, até que a solicitação e execução final de js sejam concluídas, sua página irá permanecer Não há estilo. A situação ideal deveria ser que css e dom fossem analisados e renderizados em paralelo, e é por isso que o css deve ser extraído. Ele irá empacotar o css em um arquivo css separadamente e colocá-lo na tag link no início do html em vez de colocá-lo em js.
Otimização da agitação da árvore
Sabemos que a ferramenta de empacotamento nos ajudará a remover o código morto com base no Tree Shaking do esm durante o empacotamento.
Por exemplo, aqui está bar.js
// bar.js
export const fn1 = () => {};
export const fn2 = () => {};
Em seguida, use sua função fn1 em index.js
// index.js
import { fn1 } from "./bar.js";
fn1();
Se usarmos index.js como ponto de entrada para empacotamento, fn2 será eventualmente removido.
Mas o tremor da árvore falhará em alguns cenários.Deve exigir que seu código não tenha "efeitos colaterais", ou seja, não possa afetar o mundo externo durante a inicialização, semelhante aos efeitos colaterais da programação funcional.
Veja o exemplo a seguir:
// bar.js
export const fn3 = () => {};
console.log(fn3);
export const fn4 = () => {};
window.fn4 = fn4;
export const fn5 = () => {};
// index.js
import { fn5 } from "./bar.js";
fn5();
Embora fn3 e fn4 não sejam usados, eles serão incluídos no pacote final. Porque existem efeitos colaterais ao declará-los: imprimir, modificar variáveis externas. Se você não os mantiver, poderão ocorrer bugs inconsistentes com as expectativas. Por exemplo, você acha que a janela foi alterada, mas na verdade não foi. As propriedades do objeto podem ter setters e pode até haver mais bugs inesperados.
Além disso, estes métodos de escrita também não são permitidos:
// bar.js
const a = () => {};
const b = () => {};
export default { a, b };
// import o from './bar.js'
// o.a()
// bar.js
module.exports = {
a: () => {},
b: () => {},
};
// import o from './bar.js'
// o.a()
Você não pode colocar coisas exportadas em um objeto. O Tree Shaking do esm é uma análise estática e não pode saber o que é feito em tempo de execução. A sintaxe modular Commonjs também é usada. Embora a ferramenta de empacotamento possa ser compatível com seu uso misto, ela pode facilmente causar falha no Tree Shaking.
Portanto, para utilizar totalmente o recurso Tree Shaking, você deve prestar atenção ao método de escrita. Antes de ficar online, você pode usar a ferramenta de análise de embalagens para ver quais pacotes têm tamanho anormal.
Otimização da pilha de tecnologia front-end
Além de afetar a velocidade do tempo de execução, a seleção da pilha de tecnologia também pode ter impacto na velocidade da rede.
Substituída por uma biblioteca menor. Por exemplo, se você usar lodash, mesmo que use apenas uma função nele, ele empacotará todo o conteúdo nele, porque é baseado em commonjs e não faz Tree Shaking. Se você é sensível à velocidade da página da web , você pode considerar usar outra coisa: substituição de biblioteca.
Redundância de código causada por métodos de desenvolvimento. Por exemplo, se você estiver usando soluções de estilo como atrevimento, menos, CSS nativo, componente estilizado, emoção, etc. É fácil escrever código de estilo repetido. Por exemplo, o componente A e o componente B têm largura: 120px;. Você provavelmente irá escrevê-lo duas vezes. É difícil conseguir uma reutilização refinada (quase ninguém irá repita uma linha de estilo). (talvez 7 ou 8 linhas sejam iguais antes de você pensar em reutilizá-las). Quanto maior o projeto, mais antigo ele é, mais códigos de estilo repetidos, e então seus arquivos de recursos ficarão cada vez maiores . Você pode mudar para tailwindcss, que é uma biblioteca css atômica. Se você precisar do estilo width: 120px;, no react você pode escrever <div className="w-[120px]"></div>, todas iguais As fórmulas são todos escritos assim e todos reutilizam a mesma classe. Usar o tailwind pode manter seus recursos CSS pequenos o suficiente, sem qualquer sobrecarga de tempo de execução. Ao mesmo tempo, por seguir componentes, você pode aproveitar a agitação da árvore do esm. Alguns componentes que não são mais usados serão automaticamente removidos do pacote junto com seus estilos. No caso de sass, css e outras soluções, é difícil remover automaticamente estilos que não são mais usados em um arquivo css. Além disso, soluções CSS-in-JS, como styled-component e Emotion, também podem causar tremores de árvore, mas apresentam problemas com duplicação de código e sobrecarga de tempo de execução. Existem também algumas deficiências do vento favorável, como o não suporte a versões inferiores do nodejs, e a gramática tem um custo de aprendizado.
nível de tempo de execução
O tempo de execução refere-se principalmente ao processo de execução de JavaScript e renderização de página, que envolve otimização de pilha de tecnologia, otimização multithread, otimização de nível V8, otimização de renderização de navegador, etc.
Como otimizar o tempo de renderização
O tempo de renderização não é afetado apenas pela complexidade do seu DOM e estilo, mas também por muitos aspectos.
Existem muitos tipos de tarefas no thread de renderização
Antes de falar sobre esta seção, precisamos primeiro falar sobre o conceito de tarefas. Algumas pessoas já podem ter algum conhecimento de tarefas de macro, como o código do script e alguns retornos de chamada (eventos, setTimeout, ajax, etc.).Essas são tarefas de macro. Mas você pode entender apenas os detalhes da tarefa macro e não ter uma compreensão mais ampla da tarefa. Somente entendendo-a de um nível superior você pode realmente entender por que js e renderização devem ser bloqueados e por que não há lacuna entre duas macros. tarefas próximas umas das outras. Pode não ser implementado rapidamente.
Quando você abre uma página, o navegador inicia um processo de renderização com um thread de renderização nele. A maioria das coisas de front-end são executadas neste thread de renderização, como dom, renderização de css e execução de js. Como há apenas um único thread, para processar tarefas demoradas sem bloqueio, uma fila de tarefas é projetada. Quando operações como solicitações e IO são encontradas, elas serão entregues a outros threads. Após a conclusão, os retornos de chamada serão ser colocado na fila e no thread de renderização A tarefa principal nesta fila é sempre pesquisada e executada.A maioria das tarefas de js pode ser entendida como tarefas macro. Mas não é só js. A renderização da página também é uma tarefa do thread de renderização. Você pode ver a tarefa responsável pela renderização em performance no DevTools (ela é composta por uma série de tarefas como Parse HTML, layout, paint, etc.), js A execução da chamada tarefa macro é na verdade a tarefa Avaliar Script (que inclui Compile Code, Cache Script Code e outras subtarefas, responsável pela compilação em tempo de execução, cache de código, etc.), que irá inicialmente ser uma subtarefa na tarefa Analisar HTML. Existem também muitas tarefas integradas, como coleta de lixo do GC. Há também um tipo especial de tarefa chamada microtarefas, que são Executar Microtarefas em desempenho.Eles são gerados em tarefas macro e colocados na fila de microtarefas dentro de tarefas macro. Quando a macrotarefa for executada e todas as pilhas de execução saírem, haverá um ponto de verificação. Se houver microtarefas na fila de microtarefas, todas serão executadas. Microtarefas podem ser criadas como Promise.then, queueMicrotask, eventos MutationObserver, nextTick no nó, etc.
Portanto, agora que entendemos as tarefas no thread de renderização, não é difícil descobrir que, como a renderização em si também é uma tarefa, ela deve ser sequencial na fila com tarefas js e outras tarefas, e precisa ser executada uma por uma É assim que ocorre o bloqueio. Vamos dar uma olhada na relação de bloqueio entre vários recursos.
Para dar um exemplo típico de renderização de bloqueio de js, você mesmo pode criar um arquivo html e experimentá-lo:
<html>
<head>
<title>Test</title>
</head>
<body>
<script>
const endTime = Date.now() + 3000;
while (Date.now() <= endTime) {}
</script>
<div>This is page</div>
</body>
</html>
O thread de renderização primeiro executa a tarefa Parse HTML e encontra o script durante o processo de análise do DOM, então Avaliar o script é executado. O código será executado por 3 segundos antes de terminar e, em seguida, continuará a analisar e renderizar o seguinte < div>Esta é a página</div>, portanto levará 3 segundos para a página aparecer. Se o script for um recurso remoto, a solicitação também bloqueará a análise e renderização do DOM subjacente.
Podemos otimizá-lo através do atributo defer do script.Defer atrasará o tempo de execução do script até depois que o DOM for analisado e antes do evento DOMContentLoaded.
<html>
<head>
<title>Test</title>
</head>
<body>
<script defer src="xxx.very_slow.js"></script>
<div>This is page</div>
</body>
</html>
Desta forma, não há necessidade de perder tempo esperando por solicitações, ao mesmo tempo, também pode garantir que js seja analisado no dom para obter elementos com mais segurança, e vários scripts de defer garantirão a ordem de execução original. Ou você pode conseguir um efeito semelhante escrevendo o script diretamente na parte inferior da página. Não se preocupe com o atraso da solicitação de script escrita na parte inferior. Os navegadores geralmente têm um mecanismo de otimização que verifica as solicitações de todos os recursos em HTML com antecedência e os pré-solicita quando a análise do documento é iniciada.
O script também possui outro atributo assíncrono. Se o recurso js ainda estiver sendo solicitado, a solicitação e a execução js também serão ignoradas. O conteúdo a seguir será analisado primeiro e executado imediatamente após a conclusão da solicitação js. Portanto, seu tempo de execução não é fixo e depende de quando a solicitação termina, e a ordem de execução de vários scripts assíncronos não é garantida.
O CSS bloqueará a renderização e o JS?
Apenas lembre-se de uma conclusão aqui: a solicitação e análise de css não bloqueará a análise do dom abaixo, mas bloqueará a renderização da árvore de renderização e a execução de js.
Quanto ao motivo pelo qual foi projetado assim:
A árvore de renderização está bloqueada porque é originalmente o produto da folha de estilo em cascata aplicada à árvore dom, portanto, ela deve esperar pelo css. Embora tenha sido projetada para não esperar pelo css, não há problema. Você pode renderizar a árvore dom primeiro e depois renderizar a árvore de renderização completa. , mas renderizar duas vezes é um desperdício e a experiência do usuário em uma árvore DOM simples não é boa.
A razão pela qual js será bloqueado por css pode ser porque o estilo pode ser modificado em js. Se o js posterior for executado e o estilo for modificado primeiro, e o css anterior for então aplicado, haverá um resultado de estilo que é inconsistente com a ordem de escrita do código. Você só pode continuar. É um desperdício renderizar os estilos em js duas vezes para obter o efeito real esperado. E o estilo do elemento pode ser obtido em js. Se o seguinte js for executado antes da solicitação css ser analisada, o estilo obtido não corresponderá à situação real.
Então, em resumo, embora o css não bloqueie diretamente a análise do dom, ele bloqueará a renderização da árvore de renderização e bloqueará indiretamente a análise do dom, bloqueando a execução do js.
Se estiver interessado, você mesmo pode construir um serviço de nó para experimentar. Ao controlar o tempo de resposta do recurso, você pode testar a influência mútua de vários recursos.
Por que a renderização do navegador demora tanto? Qual é o pipeline de renderização
Renderizar um HTML em uma página geralmente requer as seguintes etapas:
- Gerar árvore dom: Ao obter o html, o que exatamente o navegador fez para que a página aparecesse? Primeiro, pré-analise todas as solicitações de recursos internas e emita pré-solicitações. Em seguida, o HTML é analisado lexical e gramaticalmente.Quando encontra tags de elementos como <body> e <div> e atributos como classe e id, ele analisa e gera uma árvore dom. Durante esse período, você poderá encontrar tags css e js, como <style>, <link> e <script>. A solicitação de recurso css não bloqueará a análise da árvore dom. Se a árvore dom tiver concluído a análise do css, ela não será analisado até então. Bloqueie a criação da árvore de renderização e das árvores de layout subsequentes, etc. Se você encontrar js, seja execução de código ou solicitação de recurso, ele aguardará até que todas as execuções sejam concluídas antes de continuar a análise do dom, a menos que a tag de script tenha atributos async ou defer. Se houver um recurso css na frente do js, o js não será executado até que o css seja solicitado/analisado, o que fará com que o css bloqueie indiretamente a análise do dom. Se for encontrado código relacionado ao CSS, a próxima etapa será executada para analisar o CSS em uma folha de estilo.
- Gerando folha de estilo: o css também passa por análises lexicais e gramaticais, e alguns de seus valores serão padronizados. O que é padronização? Por exemplo, font-weight: bold e flex-flow: column nowrap que você escreveu não são estilos CSS padrão, mas uma abreviatura. Ele precisa ser convertido em um valor que o mecanismo possa entender: font-weight : 500, flex-direction: coluna, flex-wrap: nowrap. Finalmente, o texto serializado torna-se uma folha de estilo estruturada.
- Gerar árvore de renderização: com a árvore DOM e a folha de estilo, você pode adicionar estilos ao DOM correspondente por meio de herança, prioridade do seletor CSS e outras regras de estilo. O seletor CSS corresponderá às condições da direita para a esquerda, de modo que o número de correspondências seja relativamente mínimo e, eventualmente, formar uma árvore de renderização com estilos.
- Layout: alguns DOM não são exibidos, como display: none, portanto, uma árvore de layout será formada com base na árvore de renderização, que contém apenas nós que aparecerão no futuro para evitar cálculos inválidos. Ao mesmo tempo, o estágio de layout calculará as informações de posição do layout de cada elemento, o que é demorado e as posições dos elementos afetarão umas às outras.
- Camada: Em seguida, diferentes camadas serão formadas de acordo com alguns estilos especiais, como posição: absoluta, transformação, opacidade, etc. O nó raiz e a rolagem também serão contados como uma camada. Como os layouts de camadas diferentes geralmente não afetam uns aos outros, as camadas podem reduzir os custos de layout nas atualizações subsequentes e também facilitar que as camadas compostas subsequentes realizem transformações especiais em camadas individuais.
- Pintar (desenho): Na verdade, não se trata de desenhar para a tela, mas de gerar seus próprios comandos de desenho para cada camada.Esses comandos são comandos básicos para desenho de GPU, como desenhar uma linha reta, etc.
- Composto (composto): Nesta etapa, a CPU não executará mais a tarefa, e a tarefa será entregue à GPU para processamento, portanto, se js for bloqueado, não afetará este thread. A aceleração de hardware CSS também ocorre em este tópico. A lista de comandos de desenho no estágio de pintura será entregue à camada de composição. A camada de composição dividirá a área próxima à janela de visualização atual em blocos, em unidades de 512px, e renderizará a área do bloco primeiro. Outras páginas que não estão próximas do estágio de pintura a viewport pode esperar até que estejam livres. Renderize novamente. A camada de composição passa os comandos de desenho para a GPU através do pool de threads de rasterização para desenhar e gerar bitmaps.Uma vez que esses bitmaps pertencem a cada camada, essas camadas precisam ser sintetizadas em um bitmap pela camada de composição. Uma vez que uma camada tenha sido rasterizada, uma camada de composição pode compor múltiplas camadas, empilhando-as na ordem correta para formar a renderização final. Este processo geralmente é realizado na GPU para reduzir a carga de trabalho da CPU e melhorar o desempenho de renderização.
Explique a rasterização: A rasterização é um conceito em computação gráfica. Na camada de composição, converta gráficos vetoriais, texto, imagens e outros elementos da camada em imagens bitmap ou raster. Isso permite que esses elementos sejam renderizados e exibidos mais rapidamente porque os bitmaps são processados com mais eficiência no hardware gráfico. A camada de composição pode desenhar o conteúdo que precisa ser renderizado em uma área de memória fora da tela, em vez de renderizá-lo diretamente na tela. Isso evita problemas de desempenho causados pelo desenho diretamente na tela e permite que o navegador otimize o conteúdo fora da tela em segundo plano. Ao rasterizar o conteúdo da camada, o navegador pode aproveitar melhor a aceleração do hardware gráfico para renderização. Unidades de processamento gráfico (GPUs) em computadores modernos e dispositivos móveis podem processar imagens bitmap com eficiência, fornecendo animações mais suaves e velocidades de renderização mais rápidas.
- Exibição: Aguarde até que o monitor envie um sinal de sincronização, o que significa que o próximo quadro está prestes a ser exibido. O bitmap da camada composta será entregue ao componente biz no processo do navegador e o bitmap será colocado no buffer traseiro.Quando o monitor exibir o próximo quadro, os buffers frontal e traseiro serão trocados para exibir o mais recente imagem da página. O retorno de chamada de requestAnimationFrame em js também é acionado porque o sinal de sincronização sabe que o próximo quadro está prestes a ser renderizado. Também há sincronização vertical no jogo.
Durante a renderização, essas etapas são executadas em sequência como um pipeline. Se o pipeline iniciar a execução a partir de uma determinada etapa, ele inevitavelmente executará todas as etapas seguintes até o final.
Portanto, se a página for atualizada porque os estilos relacionados à posição/layout foram modificados, o layout de 2 estágios será acionado novamente para recalcular o layout, o que é chamado de refluxo (reflow ou refluxo). Como as posições de um grande número de elementos precisam ser calculadas e as posições afetarão umas às outras, pode-se observar que esta etapa consome muito tempo. Ao mesmo tempo, todas as etapas subsequentes também serão executadas, como pintura e compósito, portanto o refluxo deve ser acompanhado de repintura.
Se a página for atualizada devido a uma modificação de estilo independente de posição (como cor de fundo, cor), ela só será reativada a partir da pintura do 4º estágio, pois os dados dos quais o processo anterior depende não foram alterados. Isto irá regenerar o comando de desenho e então rasterizá-lo e compô-lo na camada de composição. Todo o processo ainda é muito rápido, então apenas redesenhar é muito mais rápido do que reordenar.
Como usar princípios de renderização para melhorar o desempenho
O próprio navegador possui alguns métodos de otimização. Por exemplo, você não precisa se preocupar com cor: vermelho; largura: 120px causando pintura repetida devido a problemas de pedido, e não precisa se preocupar com a deterioração do desempenho causada por vários resultados consecutivos modificações em estilos e vários elementos anexados consecutivos. O navegador não inicia a renderização imediatamente após você modificá-lo, apenas coloca as atualizações na fila de espera e as atualiza em lotes após um certo número de modificações ou um determinado período de tempo.
Quando escrevemos código para atualizar a página, o princípio é acionar o menor número possível de pipelines de renderização. Começar na fase de pintura será muito mais rápido do que na fase de layout. Aqui estão algumas considerações comuns:
- Evite refluxo indireto. Além de modificar diretamente os estilos relacionados à posição, algumas situações podem modificar indiretamente o layout. Por exemplo, se o tamanho da caixa não for border-box e a largura não for fixa, se você adicionar ou modificar a largura da borda, isso afetará a largura do modelo da caixa e a posição do layout. Por exemplo, <img /> não especifica uma altura, fazendo com que a altura da imagem aumente após o carregamento, fazendo com que a página reflua.
- O princípio da separação entre leitura e escrita. js que obtém informações de posição do elemento pode acionar refluxo forçado, como getBoundingClientRect, offsetTop, etc. Como mencionado anteriormente, o navegador é atualizado em lotes e há uma fila de espera, portanto, ao obter as informações de localização, a fila de espera pode não ser limpa devido às atualizações e a página pode não ser a mais recente. Para garantir que os dados obtidos sejam precisos, o navegador limpará a fila à força e forçará o refluxo da página. Ao obter as informações de localização pela segunda vez e nenhuma atualização ocorrer durante o período, a fila de espera estará vazia e o refluxo não será acionado novamente. Portanto, se você deseja modificar o tamanho de um lote de elementos e obter suas informações de tamanho, não deve escrever assim:
const elements = document.querySelectorAll(".target");
const count = 1000;
for (let i = 0; i < count; i++) {
// 将元素width增加20px
elements[i].style.width = parseInt(elements[i].style.width) + 20 + "px";
// 获取该元素最新宽度
console.log(elements[i].getBoundingClientRect().width);
}
Após a explicação acima sobre atualizações em lote do navegador e refluxo forçado, pode-se ver que escrever dessa forma é muito problemático e a página irá refluir 1000 vezes! Porque toda vez que você modifica style.width, o navegador colocará a atualização na fila de espera. Não há nada de errado com esta etapa. Mas então você começa a obter a largura desse elemento, então, para saber a largura mais recente, o navegador limpará a fila de espera, pulará a atualização em lote e forçará o refluxo da página. Então continue fazendo isso 1000 vezes.
E se você escrever assim, 1000 modificações de tamanho irão refluir apenas uma vez:
const elements = document.querySelectorAll(".target");
const count = 1000;
for (let i = 0; i < count; i++) {
// 将元素width增加20px
elements[i].style.width = parseInt(elements[i].style.width) + 20 + "px";
}
for (let i = 0; i < count; i++) {
// 获取该元素最新宽度
console.log(elements[i].getBoundingClientRect().width);
}
aceleração de hardware css
Os cálculos nas etapas anteriores à camada de síntese são basicamente realizados pela CPU. A CPU possui muito menos unidades de computação que a GPU. Embora seja poderosa para tarefas complexas, é muito mais lenta que a GPU para tarefas simples e repetitivas. Se a renderização da página começar diretamente na camada de composição e for calculada apenas pela GPU, a velocidade será inevitavelmente muito rápida, o que é aceleração de hardware. Quais métodos podem ser ativados?
Estilos CSS como transformação 3D e opacidade não envolvem refluxo e redesenho, mas apenas transformações de camada. Portanto, os estágios anteriores de layout e pintura são ignorados e entregues diretamente à camada de composição. A GPU executa algumas transformações simples na camada. Isso é isso, é muito simples para a GPU lidar com essas coisas. Há também um atributo CSS chamado will-change, usado especialmente para aceleração de hardware, que informará antecipadamente à GPU quais atributos serão alterados no futuro, para que você possa se preparar com antecedência.
Uma coisa a notar é que quando você usa js para modificar estilos, mesmo se você modificar os estilos acima que podem ser acelerados por hardware, eles ainda passarão pela CPU. Você se lembra do pipeline de renderização? JS só pode modificar o conteúdo da árvore DOM, o que inevitavelmente acionará alterações no DOM, portanto, começará da primeira etapa do pipeline de renderização até o final, e não começará diretamente na camada de composição .
Como o estilo modificado por js não pode ser acelerado por hardware, como pode ser modificado? Você pode usar métodos não-js, como animação ou transição. Você pode experimentar e ver se a animação ainda funciona quando js bloqueia completamente a página.
Como registrar o desempenho e solucionar problemas de congelamento de renderização
Para julgar se uma página está travada ou não, você não precisa apenas tentar e sentir que ela não está travada. Você não pode fornecer dados quantitativos com base em considerações subjetivas. Você deve começar a partir dos dados do seu trabalho para convencer os outros .
1. Métricas do desenvolvedor
Se quiser verificar o desempenho de abertura de uma determinada página localmente, você pode ir ao Lighthouse no DevTools
Clique no botão Analisar carregamento da página para gerar um relatório de desempenho.

Inclui indicadores de desempenho como tempo do primeiro sorteio e tempo interativo, indicadores de acessibilidade, indicadores de experiência do usuário, indicadores de SEO, PWA (aplicativos web progressivos), etc.
Se você quiser solucionar a causa do atraso de renderização nativa. Você pode acessar o desempenho no DevTools, que exibe claramente as tarefas de baixo para cima.  Podemos ver a palavra Long Task, que se refere a uma tarefa longa. A definição de uma tarefa longa é bloquear o thread principal por 50 milissegundos. ou tarefas acima. Você pode clicar em uma Tarefa Longa para ver em detalhes o que é feito nesta tarefa (no exemplo, querySelectorAll demora muito, então precisa ser otimizado)
Podemos ver a palavra Long Task, que se refere a uma tarefa longa. A definição de uma tarefa longa é bloquear o thread principal por 50 milissegundos. ou tarefas acima. Você pode clicar em uma Tarefa Longa para ver em detalhes o que é feito nesta tarefa (no exemplo, querySelectorAll demora muito, então precisa ser otimizado)
2. Monitoramento real do usuário
O acima é adequado apenas para solução de problemas temporários durante o processo de desenvolvimento, e o equipamento alvo é apenas o seu computador e as condições da sua rede. É impossível saber como o desempenho real do projeto após ficar online será realizado pelos usuários em diferentes ambientes de rede, dispositivos e localizações geográficas. Portanto, se você deseja conhecer os reais indicadores de desempenho, precisa de outros métodos.
Para avaliar se o desempenho é bom ou mau, primeiro deve ser definido um conjunto claro de nomes de indicadores. Então, quais indicadores são necessários para avaliar o desempenho?

Como obter esses indicadores? Os navegadores modernos geralmente possuem APIs de desempenho, nas quais você pode ver muitos dados detalhados de desempenho. Embora alguns dos dados acima não estejam disponíveis diretamente, você pode calculá-los por meio de algumas APIs básicas.

Você pode ver que existem, por exemplo: eventCounts - número de eventos, memória - uso de memória, navegação - método de abertura de página, número de redirecionamentos, tempo - tempo de consulta dns, tempo de conexão tcp, tempo de resposta, análise de dom e tempo de renderização, tempo interativo, etc.
Além disso, o desempenho também possui algumas APIs muito úteis, como performance.getEntries().
Ele retornará um array listando todos os recursos e o tempo gasto em momentos importantes. Entre eles estão os indicadores first-paint-FP e first-contentful-paint-FCP. Se quiser encontrar apenas determinados relatórios de desempenho específicos, você pode usar performance.getEntriesByName() e performance.getEntriesByType() para filtrar.
Vamos falar sobre como o indicador TTI (Time to Interactive time to interact) deve ser calculado:
- Primeiro, obtenha o primeiro tempo de desenho de conteúdo (FCP) do First Contentful Paint, que pode ser obtido por meio de performance.getEntries() acima.
- Procure uma janela silenciosa com duração de pelo menos 5 segundos na direção direta da linha do tempo, onde a janela silenciosa é definida como: sem tarefas longas (tarefas longas, js bloqueia tarefas por mais de 50 ms) e não mais que duas redes Solicitações GET sendo processadas.
- Pesquise a última tarefa longa antes da janela silenciosa na direção inversa ao longo da linha do tempo. Se nenhuma tarefa longa for encontrada, a execução será interrompida na etapa FCP.
- TTI é o horário de término da última tarefa longa antes da janela silenciosa (igual ao valor FCP se nenhuma tarefa longa for encontrada).
Talvez a dificuldade seja que as pessoas não sabem realizar tarefas longas. Existe uma classe chamada PerformanceObserver que pode ser usada para monitorar dados de desempenho. Adicione longtask a entryTypes para obter informações de tarefas longas. Você também pode adicionar mais tipos para obter outros indicadores de desempenho. Para detalhes, você pode ver a documentação desta classe. A seguir está um exemplo de monitoramento de tarefas longas:
const observer = new PerformanceObserver(function (list) {
const perfEntries = list.getEntries();
for (let i = 0; i < perfEntries.length; i++) {
// 这里可以处理长任务通知:
// 比如报告分析和监控
// ...
}
});
// register observer for long task notifications
observer.observe({ entryTypes: ["longtask"] });
// 之后如果有长任务执行的话,会把执行数据放入性能检测队列
// 于是就会在observer中得到"longtask" entries.
Depois de escrever o código para contar vários indicadores de desempenho (ou usar diretamente uma biblioteca pronta), você pode enterrá-lo na página do usuário e reportá-lo ao back-end de estatísticas de desempenho quando o usuário abrir a página.
Como otimizar js
Existem muitos ângulos de otimização para js, que precisam ser divididos em diferentes cenários, então temos que falar sobre isso do ponto de vista da seleção de pilha de tecnologia, multithreading e v8.
Seleção de pilha de tecnologia
1. Seleção da solução de renderização de página
1. Renderização CSR no navegador: Hoje em dia, estruturas front-end de spa, como react e vue, são bastante populares.Aplicativos de spa orientados pelo estado podem obter troca rápida de páginas. Mas a desvantagem que vem com isso é que toda a lógica está no js do lado do navegador, fazendo com que o processo de inicialização da primeira tela seja muito longo.
2. Renderização SSR do lado do servidor: como o processo de renderização inato do spa (renderização CSR do lado do navegador) é mais longo do que o da renderização do servidor (SSR), ele passará pela solicitação html -> solicitação js -> execução js -> js renderizando conteúdo -> Após montar o dom, solicite a interface -> atualize o conteúdo. A renderização do lado do servidor requer apenas as seguintes etapas: solicitação html -> renderização do conteúdo da página -> solicitação js -> execução js de adição de eventos. Quando se trata de renderização de conteúdo de página, a renderização no lado do servidor é muito mais rápida que o SPA, o que é muito adequado para cenários onde se espera que os usuários vejam o conteúdo o mais rápido possível.
Você pode usar a estrutura nextjs do react ou a estrutura nuxtjs do vue, que pode obter renderização isomórfica do lado do servidor com o mesmo conjunto de código no front e back-ends. O princípio essencial é o ambiente de execução do lado do servidor trazido pelo nodejs e os recursos de renderização multiplataforma trazidos pela camada de abstração de domínio virtual. Com o mesmo conjunto de código, tanto o navegador quanto o servidor podem renderizar (o servidor renderiza texto html), e o método spa ainda pode ser usado quando a página pula duas vezes, sem perder a velocidade da primeira tela. de termas. Ao mesmo tempo, o desempenho SSR dos dois principais frameworks também é constantemente otimizado. Por exemplo, no SSR do React18, a nova API renderToPipeableStream pode transmitir HTML e possui o recurso Suspense, que pode pular tarefas demoradas e permitir que os usuários vejam a página principal mais rapidamente. Você também pode usar a hidratação seletiva para agrupar seletivamente componentes que não precisam ser carregados de forma síncrona com preguiça e suspense (o mesmo que a renderização do lado do cliente), otimizar o tempo interativo da página principal e obter indiretamente o código na segmentação ssr.
3. Geração de página estática SSG: Por exemplo, a estrutura nextjs do React também suporta a geração de sites estáticos, executando seus componentes diretamente durante o empacotamento para gerar o HTML final. Suas páginas estáticas podem ser abertas sem tempo de execução, atingindo a velocidade de abertura máxima.
4. Renderização do lado do cliente do aplicativo: se sua página front-end for colocada no aplicativo, o cliente pode implementar o mesmo mecanismo da renderização do lado do servidor. Neste momento, abrir a página no aplicativo é semelhante à renderização do lado do servidor . Ou uma abordagem mais simples é colocar seu pacote de spa front-end no pacote do cliente, que também pode ser aberto instantaneamente. Seu maior ponto de aceleração é que os usuários também baixam recursos front-end ao instalar o aplicativo.
2. Escolha da estrutura front-end
No processo moderno de desenvolvimento front-end, o desenvolvimento de estruturas geralmente é escolhido sem hesitação. Mas se o seu projeto não for complicado agora ou no futuro, e você estiver buscando extremamente o desempenho, então não será necessário usar estruturas orientadas pelo estado, como react e vue. Embora você possa usá-los para aproveitar a conveniência do desenvolvimento de atualizar apenas a página de status, modificando-a, há também um custo de desempenho ao melhorar o DX (experiência do desenvolvedor). Em primeiro lugar, devido à introdução de tempo de execução adicional, o número de js aumentou. Em segundo lugar, porque são pelo menos renderização em nível de componente, ou seja, após a mudança de estado, os componentes correspondentes serão reexecutados por completo, então o DOM virtual obtido deve passar por diff para obter melhor desempenho de renderização do navegador. Esses links extras significam que definitivamente não é tão rápido quanto usar js ou jquery diretamente para modificar o dom com precisão. Portanto, se o seu projeto não for complicado agora ou no futuro e você quiser que ele seja rápido e leve o suficiente, poderá implementá-lo diretamente com js ou jquery.
3. Otimização do framework
Se você escolher a estrutura React, geralmente precisará fazer algumas otimizações adicionais durante o processo de desenvolvimento. Por exemplo, use useMemo para armazenar dados em cache quando as dependências permanecerem inalteradas, useCallback para armazenar funções em cache quando as dependências permanecerem inalteradas, shouldComponentUpdate do componente de classe para determinar se o componente precisa ser atualizado, etc. Como o React determina internamente se deve ser atualizado com base na mudança do endereço de referência da variável, mesmo que dois objetos ou literais de array sejam exatamente iguais, eles são dois valores diferentes. Isso deve ser observado.
Além disso, se possível, tente continuar usando a versão mais recente. Geralmente, novas versões otimizarão o desempenho.
Por exemplo, React18 adiciona um mecanismo de prioridade de tarefa para evitar que tarefas longas bloqueiem a interação da página. As atualizações de baixa prioridade serão interrompidas por atualizações de alta prioridade (como cliques e entradas do usuário), e as atualizações de baixa prioridade continuarão até que as atualizações de alta prioridade sejam concluídas. Desta forma, os usuários sentirão que a resposta é oportuna ao interagir. Você pode usar useTransition e useDeferredValue para gerar atualizações de baixa prioridade.
Além disso, o React18 também otimiza atualizações em lote. No passado, as atualizações em lote eram implementadas por meio de um mecanismo de bloqueio, semelhante a:
lock();
// 锁住了,更新只是放进队列并不会真的更新
update();
update();
unlock();
// 解锁,批量更新
Isso limitará o uso de atualizações em lote apenas em locais fixos, como ciclos de vida, ganchos e eventos de reação, porque não haverá bloqueios fora do react. Além disso, se você usar APIs como setTimeout e ajax que são independentes da tarefa de macro atual, as atualizações internas não serão atualizadas em lotes.
lock();
fetch("xxx").then(() => {
update();
update();
});
unlock();
// updates已经脱离了当前宏任务,一定在unlock之后才执行,这时已经没有锁了,两次update就会让react渲染两次。
A atualização em lote do React18 é projetada com base na prioridade, portanto, não precisa estar no local especificado pelo react para atualização em lote.
4. Seleção da ecologia estrutural
Além da própria estrutura, a sua selecção ecológica também terá um impacto no desempenho. A ecologia do vue é geralmente relativamente fixa, mas a ecologia do react é muito rica.Para buscar o desempenho, você precisa compreender as características e os princípios das diferentes bibliotecas. Aqui falamos principalmente sobre gestão global do estado e seleção de soluções de estilo.
Ao selecionar uma biblioteca de gerenciamento de estado, o react-redux pode ter problemas de desempenho sob condições extremas. Observe que estamos falando de react-redux, não de redux. Redux é apenas uma biblioteca geral. É muito simples e pode ser usada em vários lugares. É impossível falar diretamente sobre desempenho. react-redux é uma biblioteca usada para permitir que o react use redux. Como o estado redux é uma nova referência a cada vez, o react-redux não pode saber quais componentes que dependem do estado precisam ser atualizados. Você precisa usar um seletor para comparar os valores antes e depois. Se isso muda. Cada seletor de um componente que depende do estado global precisa ser executado uma vez. Se a lógica do seletor for pesada ou o número de componentes for grande, ocorrerão problemas de desempenho. Você pode tentar mbox. Seu princípio básico é o mesmo do vue. Ele aciona atualizações com base no getter e setter do objeto interceptado, para que saiba naturalmente qual componente precisa ser atualizado. Além disso, zustand tem uma boa experiência e é altamente recomendado. Embora também seja baseado em redux, é muito conveniente de usar e pode ser usado fora dos componentes sem muito código de modelo.
Dentre as soluções de estilo, apenas a solução css-in-js é possível com tempo de execução, como styled-component e Emotion. Mas não de forma absoluta, algumas bibliotecas css-in-js removerão o tempo de execução quando você não calcular dinamicamente estilos com base em adereços. Se o seu estilo for calculado com base nos adereços do componente, então o tempo de execução é essencial. Ele calculará o css ao executar o componente js e então adicionará a tag de estilo para você. Isso trará dois problemas, um é o custo de desempenho e o outro é que o tempo de renderização do estilo é atrasado até o estágio de execução do js. Você pode otimizar isso usando soluções diferentes de css-in-js, como css, sass, less, stylus e tailwind. O mais recomendado aqui é o tailwind, que foi mencionado quando se fala em otimização no nível da rede, pois não só tem tempo de execução zero, mas também permite reutilizar totalmente os estilos devido à atomização, e seus recursos CSS serão muito pequenos.
multithreading js
Sabíamos anteriormente que as tarefas js bloqueariam a renderização da página, mas e se uma tarefa longa for necessária para os negócios? Como hash de arquivo grande. Neste momento, podemos iniciar outro thread, deixá-lo executar esta longa tarefa e informar ao thread principal o resultado final.
Trabalhador da Web
const myWorker = new Worker("worker.js");
myWorker.postMessage(value);
myWorker.onmessage = (e) => {
const computeResult = e.data;
};
// worker.js
onmessage = (e) => {
const receivedData = e.data;
const result = compute(receivedData);
postMessage(result);
};
Um Web Worker só pode ser acessado pelo thread que o criou, que é a janela da página que o criou.
Trabalhador Compartilhado
O trabalhador compartilhado pode ser acessado por várias janelas, iframes e trabalhadores diferentes.
const myWorker = new SharedWorker("worker.js");
myWorker.port.postMessage(value);
myWorker.port.onmessage = (e) => {
const computeValue = e.data;
};
// worker.js
onconnect = (e) => {
const port = e.ports[0];
port.onmessage = (e) => {
const receivedData = e.data;
const result = compute(receivedData);
port.postMessage(result);
};
};
Sobre segurança de thread
Como o Web Worker controlou cuidadosamente os pontos de comunicação com outros threads, é realmente difícil causar problemas de simultaneidade. Ele não pode acessar componentes não thread-safe ou o DOM. Você deve passar dados específicos para dentro e para fora do thread por meio de objetos serializados. Então você tem que trabalhar muito para criar problemas em seu código.
Política de segurança de conteúdo
Os trabalhadores têm seu próprio contexto de execução, diferente do contexto do documento que os criou. Portanto, os Workers não serão gerenciados pela política de segurança de conteúdo do documento. Por exemplo, o documento é controlado por este cabeçalho http
Content-Security-Policy: script-src 'self'
Isso impedirá que todos os scripts da página usem eval(). Mas se um Worker for criado no script, eval() ainda poderá ser usado no thread Worker. Para controlar a Política de Segurança de Conteúdo no Worker, você precisa defini-la no cabeçalho de resposta http do script Worker. Uma exceção é que se a origem do seu Worker for um identificador globalmente exclusivo (como blob://xxx), ele herdará a Política de Segurança de Conteúdo do documento.
transferência de dados
Os dados passados entre o thread principal e o thread de trabalho são copiados em vez do endereço de memória compartilhada. Os objetos são serializados antes de serem transmitidos e desserializados quando recebidos. A maioria dos navegadores implementa cópia usando o algoritmo de clonagem estruturada.
Adapte-se à otimização interna do motor V8
Pipeline de compilação V8
- Prepare o ambiente: V8 primeiro preparará o ambiente de tempo de execução do código.Este ambiente inclui espaço de heap e espaço de pilha, contexto de execução global, escopo global, funções integradas integradas, funções de extensão e objetos fornecidos pelo ambiente host, e sistema de loop de mensagens. Inicialize o contexto de execução global e o escopo global. O contexto de execução inclui principalmente ambiente variável, ambiente léxico, este e cadeia de escopo. As variáveis declaradas por var e function serão colocadas no ambiente de variáveis. Esta etapa é realizada antes da execução do código, para que as variáveis possam ser promovidas. As variáveis declaradas por const e let serão colocadas no ambiente léxico, que é uma estrutura de pilha. Cada vez que você entrar e sair do bloco de código {}, elas serão empurradas e retiradas da pilha, e as que forem retiradas da pilha não será acessível, então const e let terão efeitos lexicais.
- Construa um sistema de loop de eventos: o thread principal precisa ler continuamente as tarefas da fila de tarefas para execução, portanto, é necessário construir um mecanismo de eventos de loop.
- Gerar bytecode: Depois que o V8 preparar o ambiente de tempo de execução, ele primeiro realizará a análise léxica e sintática (Parser) do código e gerará informações de AST e de escopo. Depois disso, as informações de AST e de escopo serão inseridas em um interpretador chamado Ignition. e convertidas. em bytecode. Bytecode é um código intermediário independente de plataforma. A vantagem de usar bytecode aqui é que ele pode ser compilado em código de máquina otimizado, e o cache de bytecode economiza muita memória do que o cache de código de máquina. A análise será atrasada ao gerar o bytecode. O V8 não compilará todo o código de uma vez. Se encontrar uma declaração de função, ele não analisará imediatamente o código dentro da função. Ele gerará apenas AST e bytecode da função de nível superior.
- Executar bytecode: O intérprete no V8 pode executar bytecode diretamente. No bytecode, o código-fonte é compilado em Ldar, Add e outras instruções semelhantes a assembly, que podem implementar instruções como busca, análise de instruções, execução de instruções e armazenamento de dados, etc. . Geralmente existem dois tipos de intérpretes: baseados em pilha e baseados em registro. Os intérpretes baseados em pilha usam pilhas para salvar parâmetros de função, resultados de cálculos intermediários, variáveis, etc. Máquinas virtuais baseadas em registros usam registros para salvar parâmetros e resultados de cálculos intermediários. A maioria dos intérpretes é baseada em pilha, como a máquina virtual Java, a máquina virtual .Net e a máquina virtual V8 inicial.A máquina virtual V8 atual adota um design baseado em registro.
- Compilação JIT just-in-time: Embora o bytecode possa ser executado diretamente, leva muito tempo. Para melhorar a velocidade de execução do código, o V8 adiciona um monitor no interpretador. Durante a execução do bytecode, se um determinado trecho de código é repetido. Se executado várias vezes, o monitoramento marcará esse código como código ativo.
Quando um determinado trecho de código é marcado como um código quente, o V8 entregará o bytecode ao compilador otimizador TurboFan. O compilador otimizador compilará o bytecode em código binário e, em seguida, executará a compilação no código binário compilado. Otimize a operação, e a eficiência de execução do código de máquina binário otimizado será bastante melhorada. Se este código for executado posteriormente, o V8 dará prioridade ao código binário otimizado. Este design é chamado JIT (compilação just-in-time).
No entanto, diferentemente das linguagens estáticas, o JavaScript é uma linguagem dinâmica e flexível. Os tipos de variáveis e as propriedades dos objetos podem ser modificados em tempo de execução. No entanto, o código otimizado pelo compilador de otimização só pode ter como alvo tipos fixos. Uma vez Durante o processo de execução, o variáveis são modificadas dinamicamente, então o código de máquina otimizado se tornará um código inválido. Neste momento, o compilador de otimização precisa realizar operações de desotimização e retornará ao intérprete para interpretação e execução na próxima vez que for executado. o processo de desotimização adicional é mais lento do que a execução direta convencional de bytecode.
A partir do pipeline de compilação acima, podemos saber que js executa repetidamente um pedaço do mesmo código várias vezes. Devido à existência do JIT, a velocidade é muito rápida (no mesmo nível de linguagens estaticamente fortemente tipadas, como java e c#). Mas a premissa é que seu tipo e estrutura de objeto não podem ser alterados à vontade. Por exemplo, o código a seguir.
const count = 10000;
let value = "";
for (let i = 0; i < count; i++) {
value = i % 2 ? `${i}` : i;
// do something...
}
Otimização de objetos de armazenamento do motor V8
Os objetos JS são armazenados no heap. É mais como um dicionário, com strings como nomes de chaves. Qualquer objeto pode ser usado como um valor-chave, e o valor-chave pode ser lido e escrito por meio do nome da chave. No entanto, quando o V8 implementou o armazenamento de objetos, ele não utilizou completamente o armazenamento de dicionário, principalmente devido a considerações de desempenho. Como o dicionário é uma estrutura de dados não linear, o cálculo de hash e os conflitos de hash fazem com que a eficiência da consulta seja menor do que as estruturas de dados armazenadas sequencialmente.Para melhorar o armazenamento e a eficiência da pesquisa, o V8 adota uma estratégia de armazenamento complexa. Estruturas de armazenamento sequencial são partes contínuas de memória, como listas e matrizes lineares. Estruturas não lineares geralmente ocupam memória não contígua, como listas vinculadas e árvores.
O objeto é dividido em propriedades regulares e propriedades de classificação. As propriedades numéricas são classificadas automaticamente em ordem crescente, chamadas de propriedades de classificação, e colocadas no início de todas as propriedades do objeto. As propriedades de string são colocadas dentro de propriedades regulares na ordem em que são criadas.
No V8, a fim de melhorar efetivamente o desempenho de armazenamento e acesso a essas duas propriedades, duas estruturas de dados lineares são usadas para armazenar propriedades de classificação e propriedades regulares, respectivamente, ou seja, as duas propriedades ocultas de elementos e propriedades.
Quando essas duas condições são atendidas: nenhum novo atributo é adicionado após a criação do objeto; nenhum atributo é excluído após a criação do objeto, o V8 criará uma classe oculta para cada objeto e haverá um valor de atributo de mapa no objeto apontando para isto. A classe oculta de um objeto registra algumas informações básicas de layout do objeto, incluindo os dois pontos a seguir: todos os atributos contidos no objeto; e o deslocamento de cada valor de atributo em relação à memória inicial do objeto. Desta forma, não há necessidade de uma série de processos na leitura dos atributos, você pode obter diretamente o deslocamento e calcular o endereço da memória.
Mas js é uma linguagem dinâmica e as propriedades do objeto podem ser alteradas. Adicionar novos atributos a um objeto, excluir atributos ou alterar o tipo de dados de um atributo alterará a forma do objeto, fazendo com que o V8 reconstrua novas classes ocultas e reduza o desempenho.
Portanto, não é recomendado usar a palavra-chave delete para excluir os atributos de um objeto ou adicionar/modificar atributos, a menos que seja necessário. É melhor determinar quando o objeto é declarado. É melhor garantir que os mesmos literais de objeto sejam exatamente iguais quando declarados ao mesmo tempo:
// 不好,x、y顺序不同
const object1 = { a: 1, b: 2 };
const object2 = { b: 1, a: 2 };
// 好
const object1 = { a: 1, b: 2 };
const object2 = { a: 1, b: 2 };
A primeira forma de escrever os dois objetos possui formatos diferentes, o que gerará diferentes classes ocultas e não poderá ser reutilizado.
Quando as propriedades do mesmo objeto são lidas várias vezes, o V8 criará um cache embutido para ele. Por exemplo este código:
const object = { a: 1, b: 2 };
const read = (object) => object.a;
for (let i = 0; i < 1000; i++) {
read(object);
}
O processo normal para ler atributos de objetos é: encontrar classes ocultas -> encontrar compensações de memória -> obter valores de atributos. O V8 otimiza esse processo quando as operações de leitura são executadas diversas vezes.
O cache embutido é conhecido como IC. Quando o V8 executa uma função, ele observará alguns dados intermediários importantes no site de chamada (CallSite) na função e, em seguida, armazenará esses dados em cache. Quando a função for executada novamente na próxima vez, o V8 poderá usar diretamente esses dados intermediários. Isso salva o processo de obtenção desses dados novamente, para que o V8 possa efetivamente melhorar a eficiência de execução de alguns códigos repetitivos usando IC.
O cache inline mantém um vetor de feedback (FeedBack Vector) para cada função. O vetor de feedback é composto de muitos itens, cada item é chamado de slot.No código acima, V8 escreverá sequencialmente os dados intermediários executados pela função de leitura no slot do vetor de feedback.
Retornar object.a no código é um ponto de chamada, porque ele lê as propriedades do objeto, então V8 alocará um slot para este ponto de chamada no vetor de feedback da função de leitura, e cada slot inclui o índice do slot (índice de slot ), tipo de slot (tipo), estado do slot (estado), endereço da classe oculta (mapa) e deslocamento do atributo.Quando V8 chama a função de leitura novamente e executa return object.a, ele pesquisará o deslocamento do atributo a no slot correspondente, e então o V8 pode obter diretamente o valor do atributo de object.a na memória, que tem eficiência de execução mais rápida do que pesquisar na classe oculta.
const object1 = { a: 1, b: 2 };
const object2 = { a: 3, b: 4 };
const read = (object) => object.a;
for (let i = 0; i < 1000; i++) {
read(object1);
read(object2);
}
Se o código ficar assim, descobriremos que as formas dos dois objetos lidos em cada loop são diferentes, portanto suas classes ocultas também são diferentes. Quando o V8 lê o segundo objeto, ele descobrirá que a classe oculta no slot é diferente daquela que está sendo lida, portanto, adicionará uma nova classe oculta e um deslocamento de memória de valor de atributo ao slot. Neste momento, haverá duas classes e compensações ocultas no slot. Cada vez que as propriedades de um objeto são lidas, o V8 as compara uma por uma. Se a classe oculta do objeto que está sendo lido for igual a uma das classes ocultas no slot, então o deslocamento da classe oculta atingida será usado. Se não houver equivalente, as novas informações também serão adicionadas a esse slot.
-
Se um slot contém apenas 1 classe oculta, esse estado é denominado monomórfico (
monomorphic); -
Se um slot contém de 2 a 4 classes ocultas, esse estado é chamado de polimorfismo (
polymorphic); -
Se houver mais de 4 classes ocultas em um slot, esse estado é chamado de superestado (
magamorphic).
Pode-se observar que o desempenho do monomorfismo é o melhor, portanto, podemos tentar evitar a modificação de objetos ou a leitura de vários objetos em uma função que é executada várias vezes para obter um melhor desempenho.
Isso pode levar a uma coisa. Quando olhei para a versão React17 antes, a explicação oficial sobre "Por que usar _jsx em vez de createElement" falava sobre algumas deficiências de createElement. Mencionou que createElement é "altamente polimórfico" e difícil de ser otimizado a partir do Nível V8. Na verdade, se você entender este artigo, entenderá o que essa frase significa: na verdade, é o superestado mencionado no artigo, então você entenderá por que o funcionário disse que createElement é difícil de otimizar. A função createElement será chamada muitas vezes na página, mas os adereços do componente e outros parâmetros que ela aceita são diferentes, portanto, muitos caches embutidos serão gerados, por isso é considerado "altamente polimórfico (hiperestado)". (Mas pelo menos este point_jsx ainda parece não ter sido resolvido, mas ainda é muito poderoso que eles possam perceber isso)
Finalmente acabou! Não é fácil de fazer, indique ao reimprimir. Dê um joinha! ! !