Cressy de Aofei Temple
Qubit | Conta pública QbitAI
A família de modelos multimodais de grande porte tem um novo membro!
Não só múltiplas imagens e textos podem ser combinados e analisados, mas também a relação espaço-temporal no vídeo pode ser processada.
Este modelo gratuito e de código aberto liderou as listas MMbench e MME e atualmente permanece nas três primeiras classificações flutuantes.
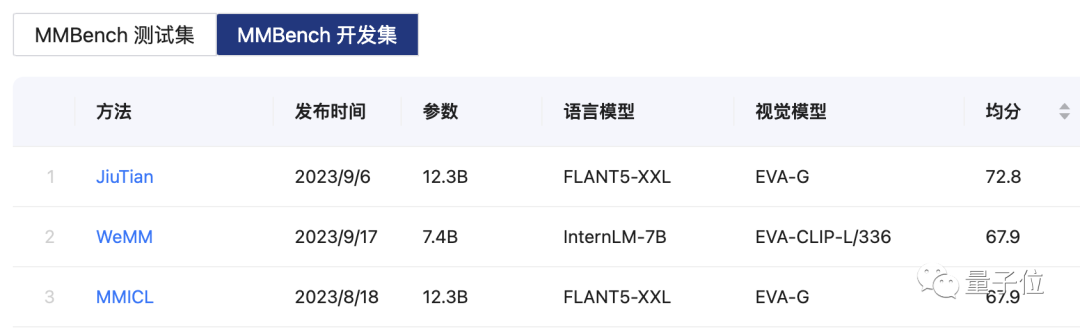
△ Lista MMBench, MMBench é um sistema abrangente de avaliação de capacidade multimodo baseado em ChatGPT lançado em conjunto pelo laboratório de IA de Xangai e pela Universidade Tecnológica de Nanyang
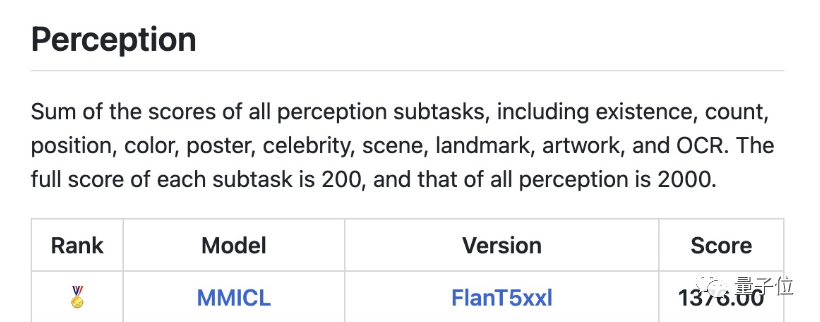
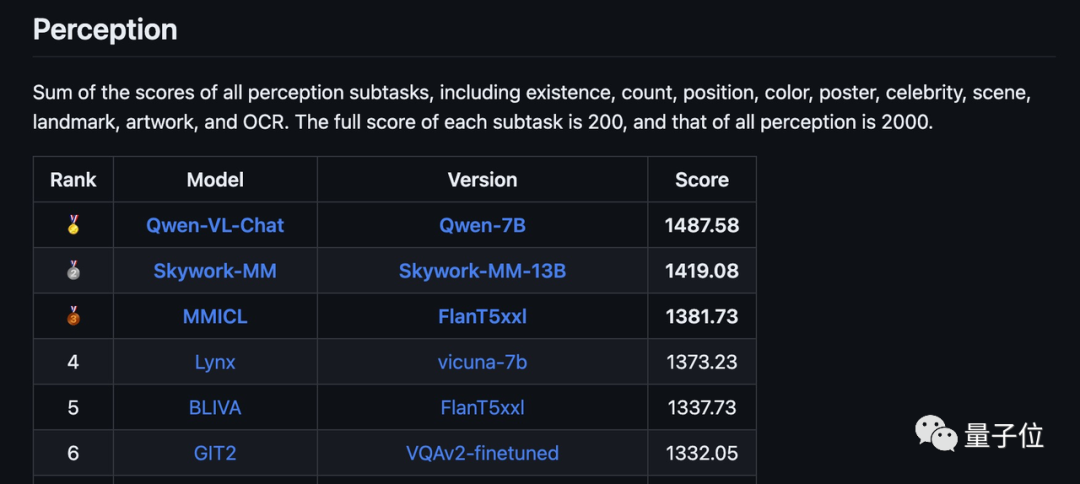
△Lista MME, MME é uma avaliação multimodal de modelo de linguagem grande conduzida pelo Tencent Youtu Lab e pela Universidade de Xiamen
Este grande modelo multimodal é denominado MMICL e foi lançado conjuntamente pela Universidade Jiaotong de Pequim, Universidade de Pequim, UCLA, Zuzhi Multi-Mode Company e outras instituições.
MMICL possui duas versões baseadas em LLMs diferentes, baseadas em dois modelos principais: Vicuna e FlanT5XL.
Ambas as versões são de código aberto, entre elas a versão FlanT5XL pode ser usada comercialmente, enquanto a versão Vicuna só pode ser usada para fins de pesquisa científica.
No teste multitarefa do MME, a versão FlanT5XL do MMICL manteve sua posição de liderança por várias semanas.
Dentre eles, o aspecto cognitivo alcançou pontuação total de 428,93 (pontuação total de 800), ficando em primeiro lugar, superando significativamente outros modelos.
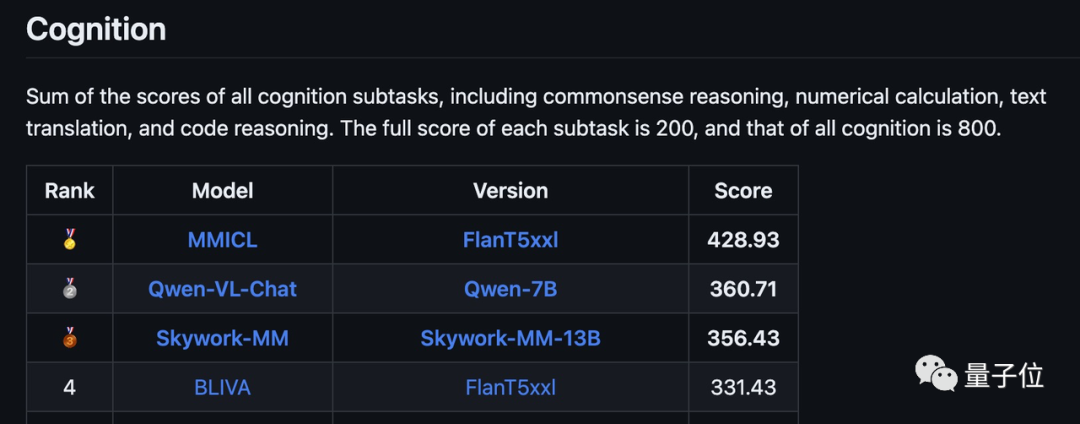
A pontuação total em termos de percepção é 1381,78 (em 2000), ficando atrás apenas do modelo Qianwen-7B do Alibaba e do modelo Tiangong de Kunlun Wanwei na versão mais recente da lista.
Em termos de configuração necessária, a declaração oficial é que são necessários seis A40 durante a fase de treinamento, e a fase de inferência pode ser executada em um A40.
Apenas 0,5 milhão de dados construídos a partir do conjunto de dados de código aberto são necessários para concluir a segunda fase do treinamento, que leva apenas dezenas de horas.
Então, quais são as características deste grande modelo multimodal?
Posso assistir a vídeos e “aprender agora e vender agora”
MMICL oferece suporte a prompts na forma de texto e imagens intercalados e é tão natural de usar quanto o bate-papo do WeChat.
Alimente as duas imagens ao MMICL de maneira normal e você poderá analisar suas semelhanças e diferenças.

Além de seus fortes recursos de análise de imagem, o MMICL também sabe “aprender agora e vender agora”.
Por exemplo, demos ao MMICL a imagem de um cavalo estilo pixel em “Minecraft”.
Como os dados de treinamento são todos cenas do mundo real, o MMICL não reconhece esse estilo de pixel excessivamente abstrato.

Mas, contanto que deixemos o MMICL aprender alguns exemplos, ele poderá realizar rapidamente o raciocínio analógico .
Na imagem abaixo, o MMICL aprendeu três cenários: cavalos, burros e nada, e então julgou corretamente o cavalo pixel após mudar o fundo.

Além das imagens, os vídeos dinâmicos também não são um problema para o MMICL, pois ele não apenas entende o conteúdo de cada quadro, mas também analisa com precisão a relação espaço-temporal.
Vamos dar uma olhada nesta batalha futebolística entre Brasil e Argentina: o MMICL analisou com precisão as ações das duas equipes.

Você também pode perguntar ao MMICL sobre os detalhes do vídeo, como como os jogadores brasileiros bloquearam os jogadores argentinos.

Além de compreender com precisão a relação espaço-temporal no vídeo, o MMICL também suporta entrada de fluxo de vídeo em tempo real.
Podemos ver que a pessoa na tela de vigilância está caindo. O MMICL detectou esta anomalia e emitiu um aviso perguntando se é necessária ajuda.

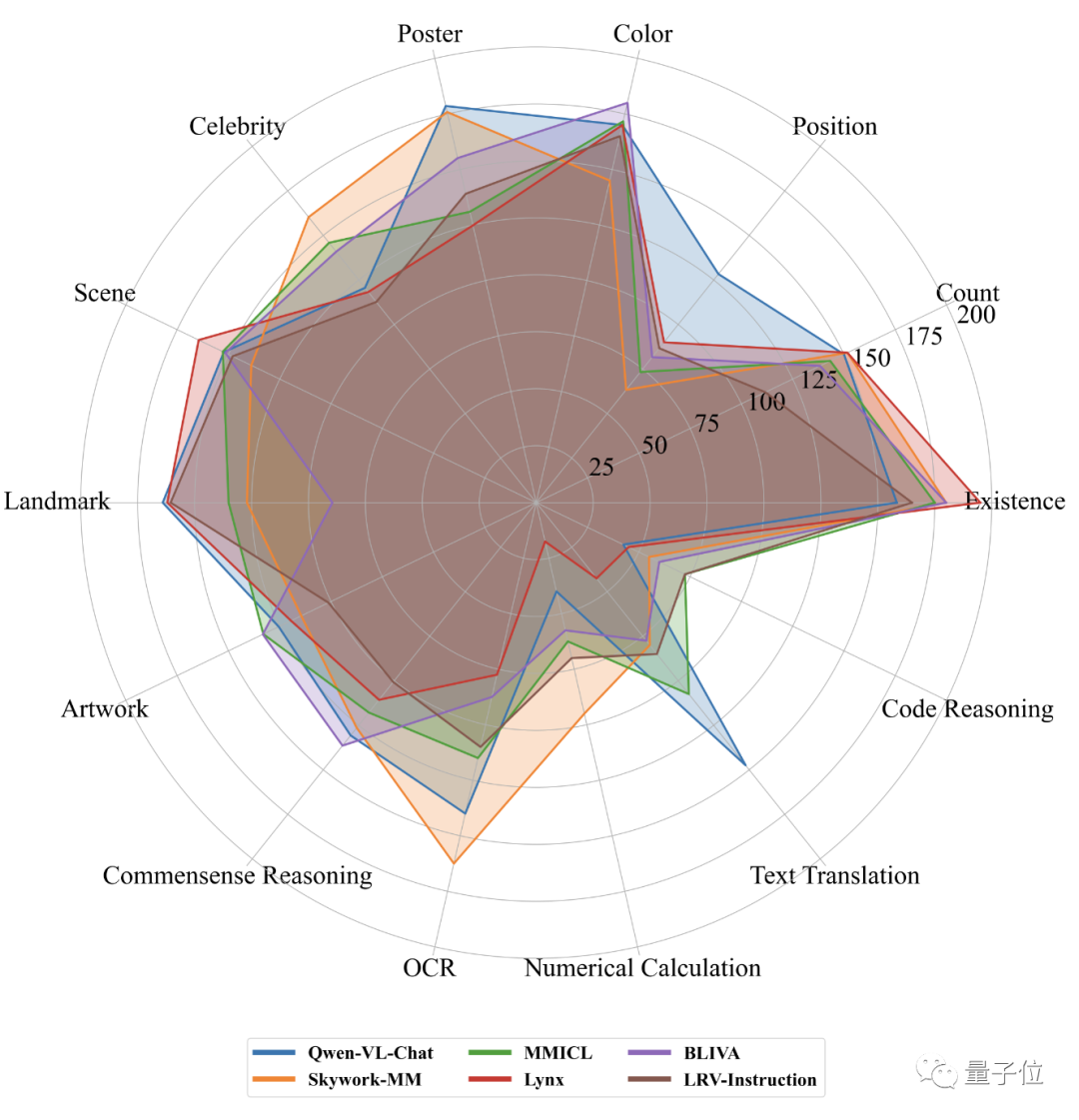
Se compararmos os cinco primeiros em percepção e cognição da lista do MME em uma única imagem, podemos ver que o desempenho do MMICL alcançou bons resultados em todos os aspectos.
Então, como o MMICL faz isso e quais são os detalhes técnicos por trás disso?
O treinamento é concluído em duas fases
O MMICL visa resolver os problemas encontrados pelos modelos de linguagem visual na compreensão de entradas multimodais complexas com múltiplas imagens.
MMICL usa o modelo Flan-T5 XXL como backbone.A estrutura e o processo de todo o modelo são mostrados na figura abaixo:
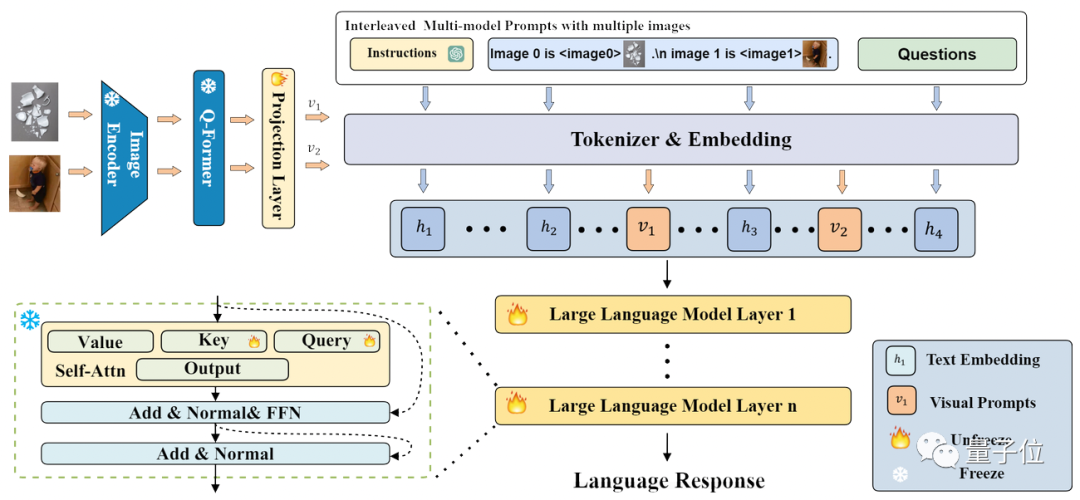
MMICL usa uma estrutura semelhante ao BLIP2, mas pode aceitar gráficos intercalados e entrada de texto.
O MMICL trata imagens e textos igualmente e une os recursos de imagem e texto processados em uma forma de imagem e texto intercalada de acordo com o formato de entrada e os insere no modelo de linguagem para treinamento e inferência.
Semelhante ao InstructBLIP, o processo de desenvolvimento do MMICL consiste em congelar o LLM, treinar o Q-former e ajustá-lo em um conjunto de dados específico.
O processo de treinamento e a estrutura de dados do MMICL são mostrados na figura abaixo:
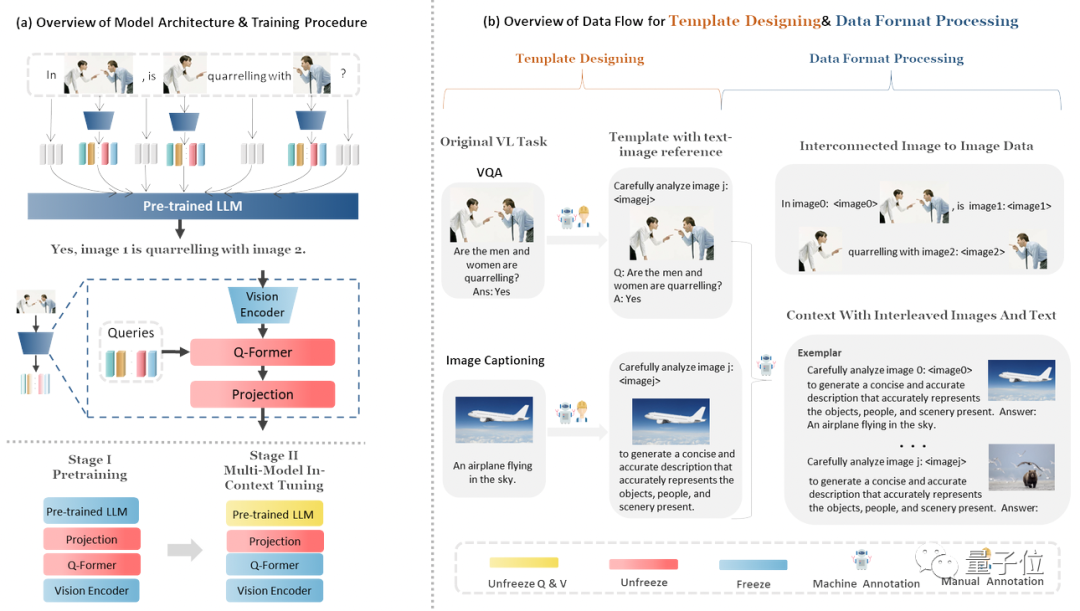
Especificamente, a formação do MMICL é dividida em duas etapas:
Na etapa de pré-treinamento, foi utilizado o conjunto de dados LAION-400M (consulte LLaVA)
Ajuste multimodal no contexto, usando seu próprio conjunto de dados MIC (Multi-Model In-Context Learning)

O conjunto de dados MIC é construído a partir de conjuntos de dados públicos. A figura acima mostra o conteúdo contido no conjunto de dados MIC. O conjunto de dados MIC também possui as seguintes características:
A primeira é a referência explícita estabelecida entre imagens e textos. O MIC insere declarações de imagem nos dados entrelaçados de imagens e textos, usa tokens proxy de imagem para fazer proxy de imagens diferentes e usa linguagem natural para criar imagens. Relações referenciais entre textos.

O segundo é um conjunto de dados multi-imagem que está interligado no espaço, no tempo ou na lógica, garantindo que o modelo MMICL possa ter uma compreensão mais precisa da relação entre as imagens.

A terceira característica é o conjunto de dados de exemplo, que é semelhante ao processo de "aprendizagem no local" do MMICL. Ele usa aprendizado de contexto multimodal para aprimorar a compreensão do MMICL de gráficos complexos e entradas de texto intercaladas com gráficos e texto.

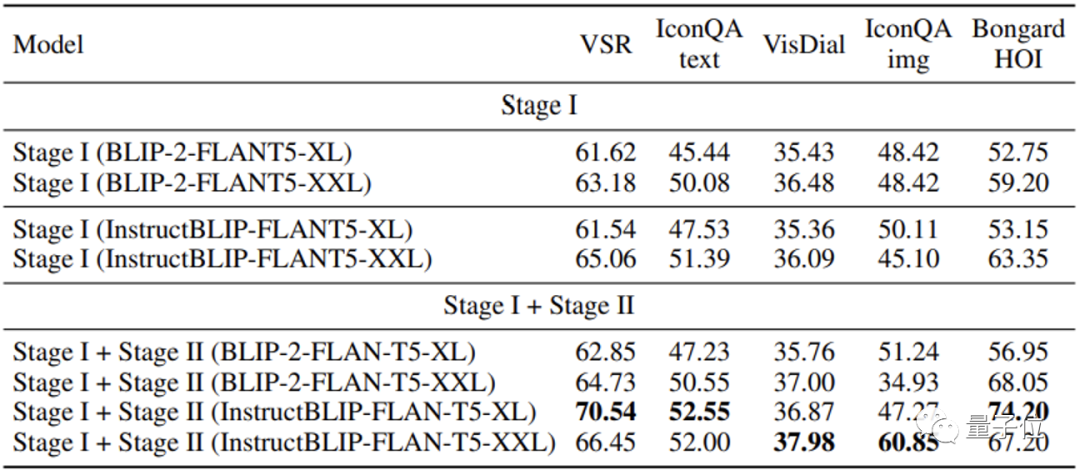
MMICL obtém melhores resultados em vários conjuntos de dados de teste do que BLIP2 e InstruçãoBLIP, que também usam FlanT5XXL.
Especialmente para tarefas que envolvem múltiplas imagens, o MMICL mostrou grande melhoria para imagens complexas e entrada de texto.
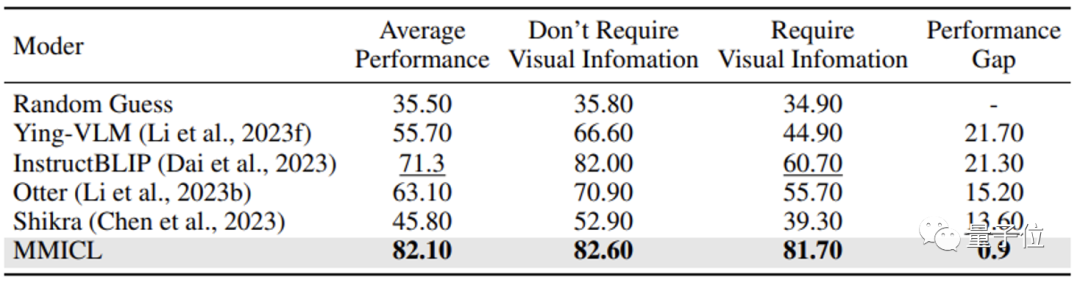
A equipa de investigação acredita que o MMICL resolve o problema do preconceito de linguagem que frequentemente existe nos modelos de linguagem visual e é uma das razões dos seus excelentes resultados.
A maioria dos modelos de linguagem visual ignora o conteúdo visual quando confrontado com o conteúdo contextual de grandes quantidades de texto, o que é uma falha fatal ao responder a questões que requerem informação visual.
Graças à abordagem da equipe de pesquisa, o MMICL alivia com sucesso esse viés de linguagem em modelos de linguagem visual.
Os leitores interessados neste grande modelo multimodal podem verificar a página ou artigo do GitHub para obter mais detalhes.
Página GitHub:
https://github.com/HaozheZhao/MIC
endereço do documento:
https://arxiv.org/abs/2309.07915
Demonstração online:
http://www.testmmicl.work/