Bem-vindo a seguir a conta oficial do WeChat do "CVHub"!

Título: Segmentação semântica eficiente alterando resoluções para vídeos compactados
PDF: https://arxiv.org/pdf/2303.07224
Código: https://github.com/THU-LYJ-Lab/AR-Seg
Introdução
A segmentação semântica de vídeo (VSS) é uma tarefa computacionalmente intensiva porque requer previsão quadro a quadro de vídeos com alta taxa de quadros. Em pesquisas recentes, para alcançar eficiência computacional VSS, foram propostas arquiteturas de redes compactas ou estratégias de redes adaptativas. Porém, nenhum desses trabalhos leva em consideração um fator chave que afeta o custo computacional: a resolução de entrada . Portanto, os autores propõem uma AR-Segestrutura de rede de resolução alternada chamada Rede de Resolução Alternada para segmentação de vídeo para alcançar alta eficiência VSS. AR-Seg visa reduzir custos computacionais usando baixa resolução para quadros não-chave; ao mesmo tempo, a fim de evitar a degradação do desempenho da segmentação causada pelo downscaling, o autor projetou um módulo de fusão de recursos de resolução cruzada e usou uma nova similaridade de CR-eFFrecursos estratégia de treinamento FSTpara supervisão. Especificamente: CReFFprimeiro, os vetores de movimento armazenados no vídeo compactado são usados para fundir eficientemente os recursos de quadros-chave de alta resolução com quadros não-chave de baixa resolução para obter melhor alinhamento espacial, e um mecanismo de atenção local é usado para agregar seletivamente locais recursos em quadros-chave. Além disso, a proposta FSTsupervisiona os recursos agregados através de perda de similaridade explícita e restrições implícitas de camadas de decodificação compartilhadas. Experimentos em conjuntos de dados CamVid e Cityscapes mostram que o AR-Seg pode economizar 67% dos custos de computação, mantendo alta precisão de segmentação.
introdução
O objetivo da segmentação semântica de vídeo é prever o rótulo semântico de cada pixel de quadro em uma sequência de vídeo, que geralmente é uma série de quadros de imagem consecutivos gravados em uma determinada taxa de quadros (25 fps ou superior).
Métodos de segmentação baseados em imagens aplicados a quadros de vídeo quadro a quadro consomem recursos computacionais consideráveis.
A fim de melhorar a eficiência computacional do VSS, os métodos existentes concentram-se principalmente no projeto da arquitetura de rede:
- Uma abordagem convencional propõe arquiteturas compactas e eficientes baseadas em imagens para reduzir a sobrecarga computacional de cada quadro.
- Outro método convencional é aplicar modelos profundos a quadros-chave, enquanto modelos de rede superficiais são aplicados a quadros não-chave para evitar cálculos repetidos de quadros de vídeo.
Os dois métodos principais existentes mencionados acima ignoram um fator-chave que afeta o custo computacional da segmentação de vídeo: a resolução de entrada.
A resolução de entrada determina diretamente a quantidade de cálculo. Por exemplo, o custo computacional da convolução 2D é proporcional ao produto da largura e altura da imagem. Depois de reduzirmos a resolução do quadro de entrada em 0,5 × 0,5, a sobrecarga computacional pode ser reduzida diretamente em 75%. A redução da resolução pode, de fato, reduzir bastante a sobrecarga computacional, mas geralmente também perde parte das informações da imagem e leva ainda mais a uma redução na precisão da segmentação.
Considerando a particularidade da segmentação de vídeo ( informações de quadros adjacentes geralmente são fortemente correlacionadas ), este artigo propõe utilizar a correlação temporal no vídeo (correlação de quadros adjacentes) para evitar a perda de precisão causada pela redução da resolução. Sua ideia central é que as informações de características locais ausentes em quadros de baixa resolução possam ser obtidas a partir de quadros de referência esparsos de alta resolução.
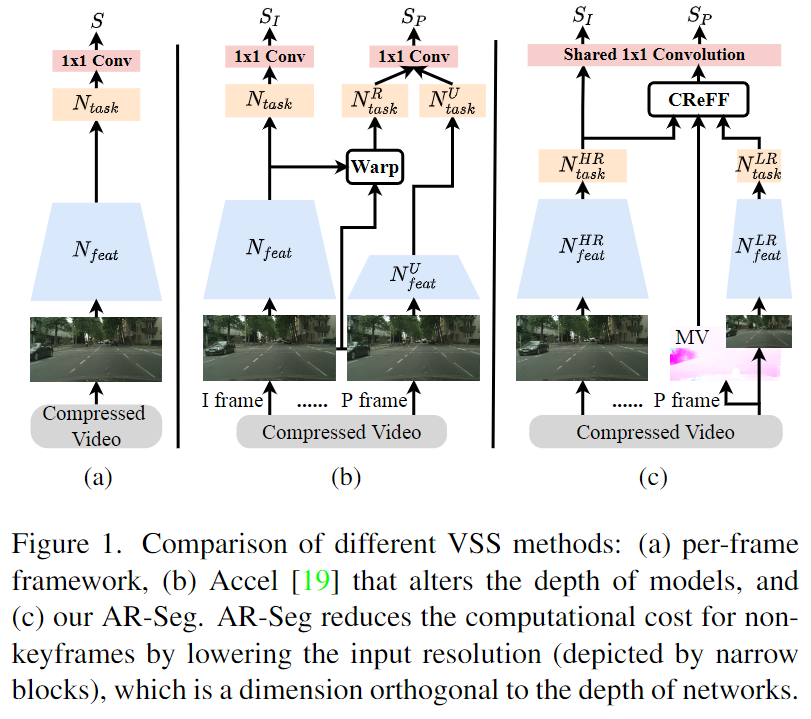
Este artigo propõe uma rede de quadros alternados de resolução para compactação de vídeo AR-Seg, obtendo segmentação de vídeo eficiente com esforço computacional extremamente baixo, conforme mostrado na Figura 1 (c) acima. AR-SegA rede usa uma ramificação HR para processar quadros-chave de alta resolução e uma ramificação LR para processar quadros não-chave de baixa resolução. Para evitar a degradação do desempenho da segmentação causada pela redução da resolução (redução da resolução), o autor inseriu um CReFFmódulo (Cross Resulution Feature Fusion) no ramo LR e FSTtreinou usando a estratégia (Feature Similarity Training) para enriquecer os recursos do LR. como recursos locais.
Especificamente, CReFFas informações de recursos locais em quadros-chave HR são eficientemente integradas em quadros não-chave LR nas duas etapas a seguir:
- Isso pode ser obtido a partir de vídeo compactado quase sem custo adicional, usando vetores de movimento para distorção de recursos para alinhar a estrutura espacial de recursos de diferentes quadros.
- Use um mecanismo de atenção local para agregar seletivamente recursos distorcidos (que podem ter ruído após distorção) em recursos LR. Como o mecanismo de atenção local atribui importância diferente a cada posição na vizinhança, é a melhor maneira de evitar ser distorcido pelo ruído. maneira eficaz de enganar recursos.
A FSTestratégia de treinamento orienta o aprendizado de recursos agregados por meio de perda de similaridade explícita (perda de similaridade entre recursos agregados e recursos de alta resolução inferidos de quadros não-chave) e restrições implícitas para ajudar o ramo de baixa resolução a ramificar-se de recursos confiáveis e eficazes de alta resolução CReFF. aprendido no ramo de taxas.
Em resumo, AR-Segao alterar a resolução de entrada, o custo computacional do VSS é significativamente reduzido, mantendo ao mesmo tempo uma alta precisão de segmentação.
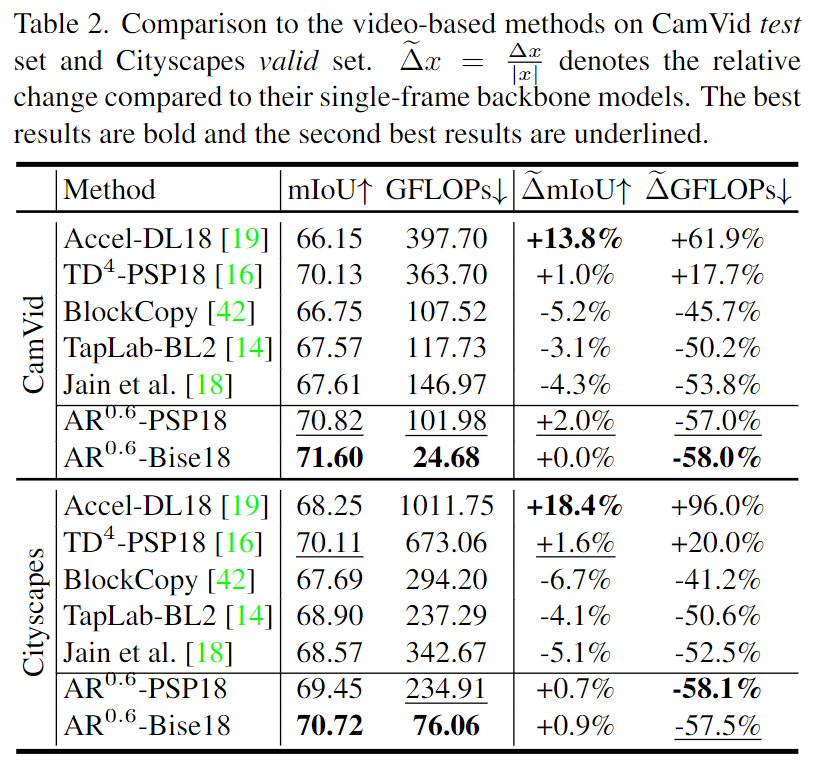
Os resultados experimentais mostram que AR-Sego custo computacional é reduzido em quase 70% em comparação com o modelo de linha de base de resolução convencional, mantendo ao mesmo tempo uma alta precisão de segmentação. Portanto, as contribuições deste artigo incluem:
- Proposta de uma estrutura eficiente de segmentação semântica de vídeo compactado
AR-Seg - Um módulo eficiente
CReFFé projetado para evitar perda de precisão causada pela redução da resolução - Uma nova
FSTestratégia de treinamento é proposta para orientar o ramo LR a aprender com o ramo RH
Trabalho relatado
Segmentação semântica leve
A fim de melhorar a eficiência da segmentação de imagens, muitas arquiteturas de rede leves foram propostas: DFANetusando redes de backbone leves para reduzir custos de computação e projetando agregação de nível cruzado para refinamento de recursos; DFNetusando algoritmos de classificação e poda parciais para procurar modelos de segmentação, para obter um bom equilíbrio entre velocidade e precisão; ICNetusar módulos de fusão em cascata e converter parte do cálculo de alta resolução para baixa resolução; Wang et al. projetaram aprendizado de super-resolução para melhorar o desempenho da segmentação de imagens; usar dois BiSeNetsCada caminho de fluxo lida com baixo nível detalhes e informações contextuais de alto nível, respectivamente; ESPNet usa pirâmides espaciais eficientes para acelerar cálculos de convolução. Essas redes de backbone leves e eficientes reduzem a carga computacional da segmentação de imagens únicas e podem ser aplicadas com eficácia a tarefas VSS.
Segmentação semântica de vídeo
Os métodos de segmentação semântica de vídeo reduzem o esforço computacional ao propagar recursos profundos extraídos de quadros-chave para quadros não-chave. Entre esses métodos, alguns reutilizam diretamente os resultados da segmentação de quadros-chave, alguns interpolam os resultados da segmentação dentro da vizinhança e alguns extraem recursos superficiais de quadros não-chave e os fundem em recursos profundos propagados por meio da convolução de variação espacial. Para resolver o problema de desalinhamento espacial entre quadros de vídeo, alguns métodos utilizam fluxo óptico para mapear recursos intermediários de quadros-chave para quadros não-chave, e alguns métodos também agregam recursos em diferentes carimbos de data/hora por meio de um mecanismo de atenção global.
Análise de vídeo de domínio compactado
Nos últimos anos, formatos de vídeo compactados têm sido amplamente utilizados em tarefas de visão computacional. Esses métodos inserem diretamente vetores de movimento e mapas residuais como modalidades adicionais na rede para reconhecimento de ação de vídeo e segmentação semântica.Essas informações de movimento também ajudam a compensar o desalinhamento espacial de recursos de diferentes quadros. Na segmentação de vídeo, também existem diversos métodos que propõem uma segmentação eficiente no domínio compactado. Esses métodos reduzem o custo computacional do VSS, mas devido às capacidades limitadas do módulo de refinamento de recursos sem quadro-chave, o desempenho será reduzido.
método
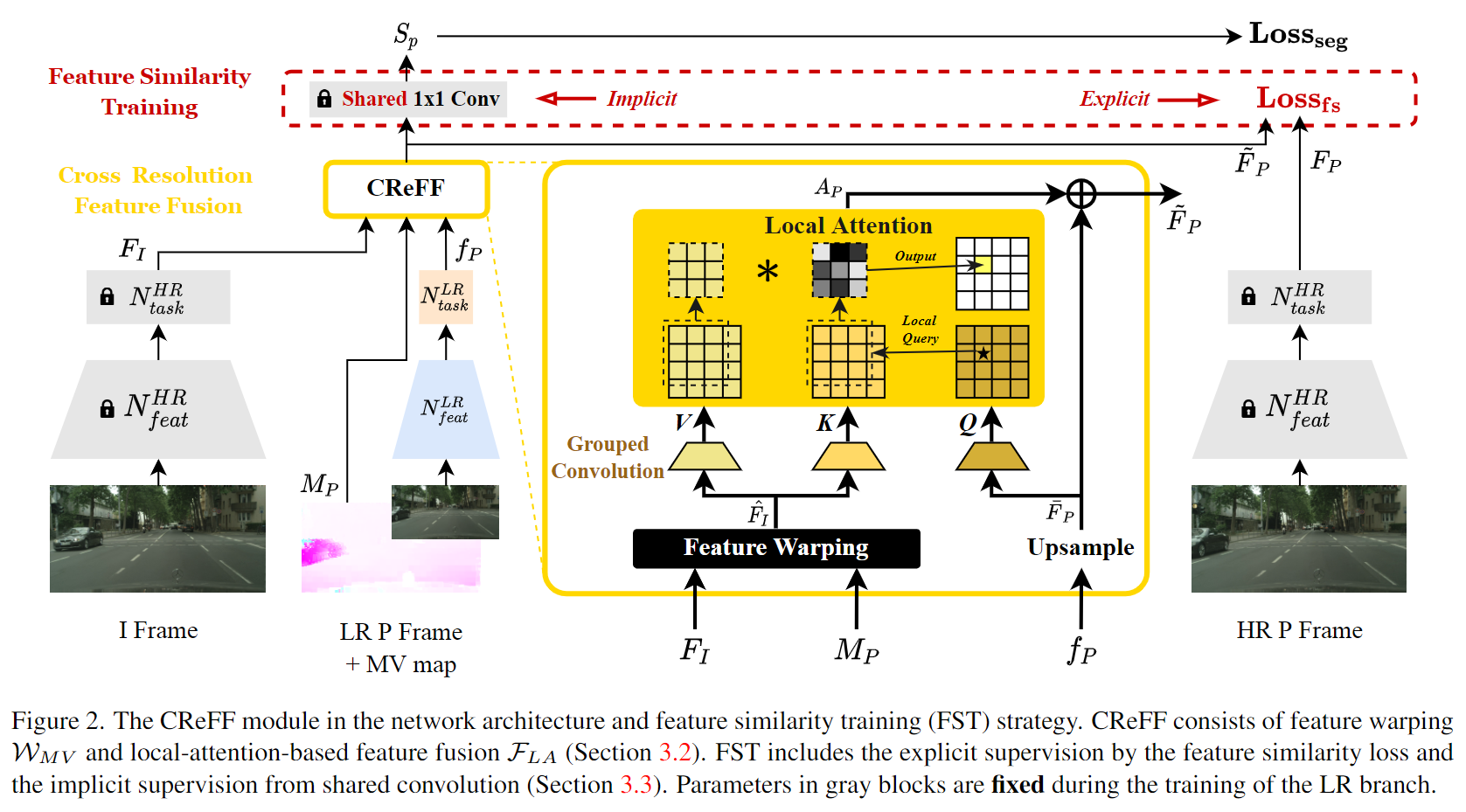
No AR-Seg, apenas alguns quadros-chave são processados para preservar detalhes, e outros quadros não-chave são processados em baixa resolução para reduzir o custo computacional. AR-SegA estrutura inclui duas filiais: filial RH e filial LR. A ramificação HR é usada para quadros-chave e a ramificação LR é usada para quadros não-chave. Ambas as filiais compartilham a mesma estrutura de rede backbone, mas são treinadas para resoluções diferentes. Antes da convolução final da rede de backbone LR, um módulo CReFF é adicionado para agregar recursos de RH e prever quadros não-chave de baixa resolução.
Para identificar quadros-chave, exploramos a GOPestrutura de quadros em grupos de imagens codificadas no vídeo compactado. GOPContém três tipos de quadros L consecutivos: quadro I, quadro P e quadro B. Os quadros I são codificados usando o modo de codificação intra, enquanto os quadros P e os quadros B são codificados usando o modo de codificação interativo e os vetores de movimento são calculados para compensação de movimento. Em cada um GOP, tratamos o primeiro quadro I como um quadro-chave e o processamos em alta resolução. GOPOs quadros L-1 restantes são quadros não-chave e são processados em baixa resolução.
CReFF: fusão de recursos de resolução cruzada
Conforme mostrado na Figura 2 acima, o ramo HR extrai características FI ∈ RC × H × W F_I \in R^{C \times H \times W}AR-Seg do quadro IFeu∈RC × H × W , o ramo LR extrai características f P ∈ RC × h × w f_P \in R^{C \times h \times w}do quadro PfP∈RC × h × w . Embora os quadros P sejam processados em baixa resolução,CReFFoFI F_IFeu、MP M_PMPe f P f_PfPComo entrada, gere recursos agregados FP ~ \tilde{F_P}FP~,其中MP ∈ R 2 × H × W M_P \in R^{2 \times H \times W}MP∈R2 × H × W representa o MV do quadro P ao quadro I. Deputado M_PMPOs dois canais correspondem às dimensões x e y do vetor de movimento, denotados como cx c_x respectivamentecx和cy c_ycvocê. Dentro CReFFdo módulo, a operação de deformação de recurso baseada em MV WMV W_{MV}CMV _Primeiro conjunto FI F_IFeuA distorção em direção ao layout espacial do quadro P pode ser formulada como uma mudança pixel por pixel.

Entre eles, $ \hat{F_I} \in R^{C \times H \times W}$ representa os recursos de alta resolução após a deformação, que serão posteriormente integrados aos recursos de baixa resolução.
Resumindo, CReFFo módulo primeiro alinha as informações de recurso extraídas do quadro I com o quadro P e, em seguida, Q_PPPJaponês KI K_IKeuAs semelhanças de pixels entre pixels são agregadas no ramo LR.
FST: Treinamento de similaridade de recursos
A estratégia de treinamento FST é usada para treinar o módulo de forma eficiente CReFF. FSTA ideia central é utilizar os recursos de alta resolução dos quadros P FP F_PFP(extraído do ramo RH) para orientar o aprendizado dos recursos agregados FP F_P no ramo LRFPtreinamento. Porque FP F_PFPContém informações detalhadas suficientes para produzir resultados de segmentação de alta qualidade e CReFFpode aprender como converter FP F_PFST sob supervisãoFPJaponês FI F_IFeuagregados em recursos eficazes de alta resolução. FSTO processo de formação do ramo LR é supervisionado explícita e implicitamente das seguintes formas.

onde a restrição explícita é usar a função de perda de similaridade de recurso L fs L_{fs}eufs _. O autor usa erro quadrático médio (MSE) para medir FP ~ \tilde{F_P}FP~e FP F_PFPA diferença entre os dois vetores de características (mede a distância entre os dois vetores de características), o que equivale à regularização adicional do modelo de baixa resolução: quando a distância é pequena, significa que a similaridade entre os dois é alta, então o O MSE pode ser usado como medida de similaridade para treinamento supervisionado de modelos de baixa resolução. O efeito desta restrição explícita é ajudar o modelo de baixa resolução a aprender melhor as informações agregadas do modelo de alta resolução e melhorar a qualidade dos resultados da segmentação.
A restrição implícita é FP ~ \tilde{F_P}FP~e FP F_PFPcamada de decodificação compartilhada. No modelo de backbone de segmentação treinado em imagens de RH, a última camada convolucional atua como um decodificador de segmentação, contendo informações semânticas profundas sobre recursos de RH de alta qualidade. Para explorar esta informação, passamos diretamente a última camada convolucional 1×1 do ramo HR para o ramo LR com parâmetros fixos. Como esses parâmetros são treinados em recursos de RH, quando FP ~ \tilde{F_P}FP~Mais próximo do recurso de RH FP F_PFPEles produzem melhores resultados de segmentação SP S_PSP。
Em resumo, através de restrições explícitas e implícitas, FSTo conhecimento das características de RH é efetivamente transferido do ramo de RH para o ramo de LR, conseguindo CReFFuma segmentação de alta qualidade com base em características agregadas. A Figura 2 acima mostra a estratégia geral de treinamento da filial LR. Os quadros I HR fornecem recursos FI para CReFFfusão de recursos e os quadros P HR fornecem recursos FP para FSTsupervisão explícita. Os parâmetros do ramo LR são treinados por retropropagação utilizando a perda total L, onde são fixados os parâmetros do ramo HR e da última camada convolucional compartilhada.
Resultados experimentais
::: Bloco 1

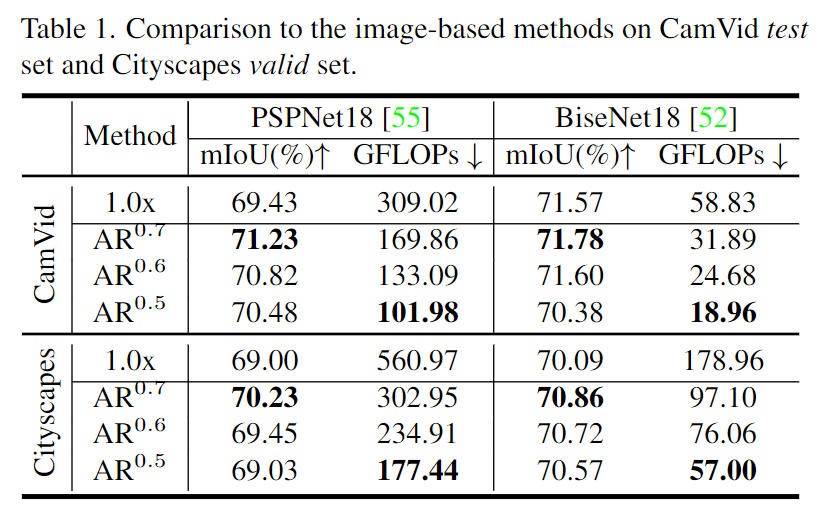
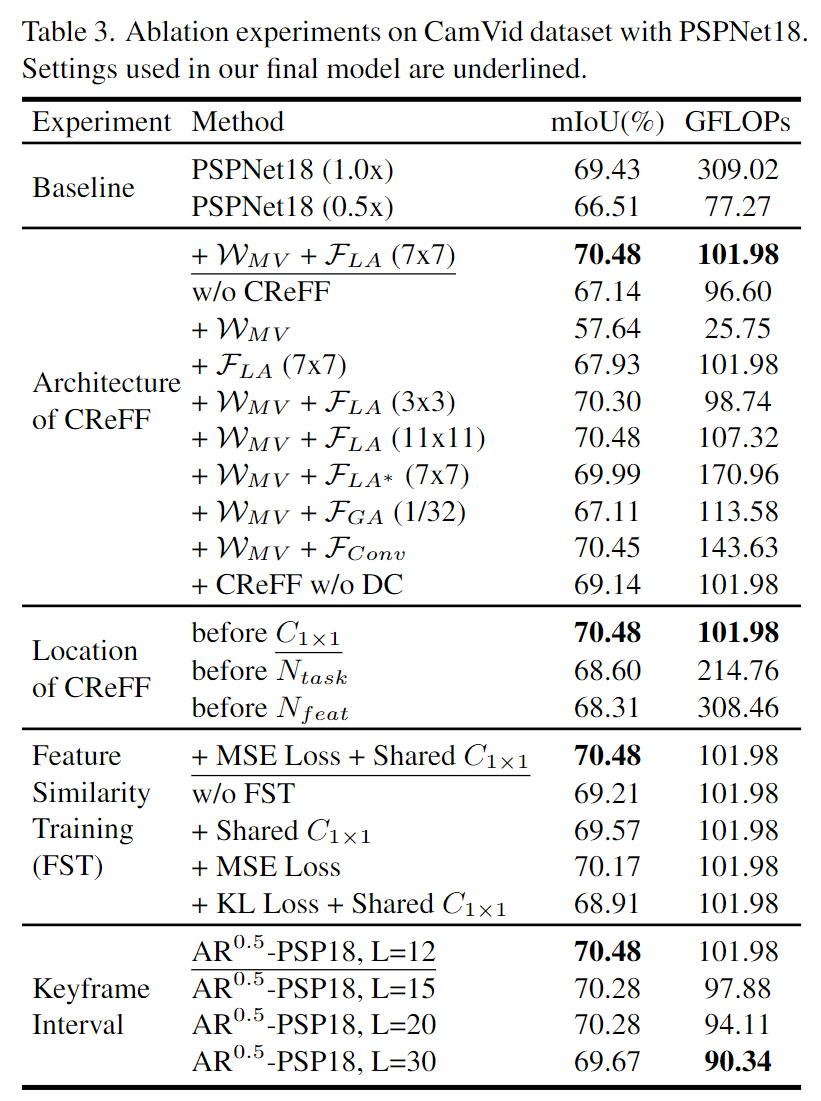
Resultados da segmentação semântica usando o modelo AR0.5-PSP18 com d=11 nos conjuntos de dados CamVid e Cityscapes. Pode-se observar que AR0.5-PSP18 prevê mais detalhes semânticos do que o PSPNet18 de resolução constante trabalhando com resolução de 0,5x. Comparado com a linha de base de resolução de 1,0x, AR0.5-PSP18 produziu resultados de segmentação semelhantes, mas consumiu apenas 33,0% do custo computacional (medido em GFLOPs).
:::
::: Bloco 1

(a) mostra AR-Sego desempenho em diferentes resoluções LR. (b) mostra o mIoUd (distância do quadro-chave) do quadro anotado em diferentes distâncias do quadro-chave. Quando d muda de 1 para L-1, o intervalo de valor de mIoUd é representado como uma barra colorida em (a).
:::
::: Bloco 1

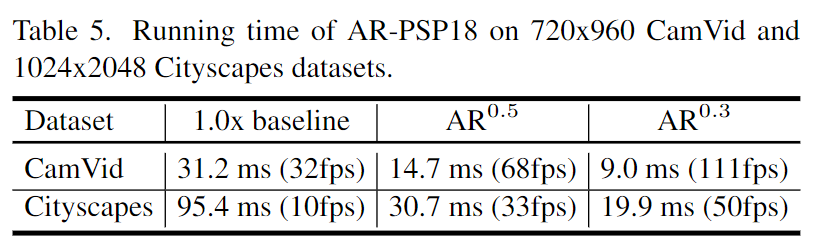
Mostrando AR-Sego desempenho em vídeos compactados usando diferentes codecs, verifica-se que a AR-Segprecisão é comparável, ou até melhor, do que sua contraparte com resolução constante baseada em imagem.
:::
para concluir
Este artigo propõe uma estrutura de alternância de resolução para segmentação semântica de vídeo compactado AR-Seg, que melhora de forma inovadora a eficiência da segmentação de vídeo do ponto de vista da resolução de entrada. Ao considerar conjuntamente o projeto da arquitetura e a estratégia de treinamento, o CReFFmódulo e FSTa estratégia propostos evitam efetivamente a perda de precisão causada pela redução da resolução. Os resultados avaliados em dois conjuntos de dados amplamente utilizados mostram que o AR-Seg pode alcançar precisão de segmentação competitiva e, ao mesmo tempo, reduzir o custo computacional em até 67%. Este estudo utiliza atualmente apenas duas resoluções alternadas (ou seja, HR e LR). Trabalhos futuros considerarão a aplicação de agendamento mais complexo de múltiplas resoluções e intervalos de quadros-chave para melhorar ainda mais o desempenho do VSS.
Se você também está interessado no campo full-stack de inteligência artificial e visão computacional, recomendamos fortemente que você siga a conta pública informativa, interessante e amorosa "CVHub", que lhe trará originais de alta qualidade, multicampos e em -profundidade de artigos científicos e tecnológicos de ponta todos os dias. Interpretação e soluções industriais maduras! Bem-vindo a adicionar o ID WeChat do editor: cv_huber, observação "CSDN", juntar-se ao grupo oficial de intercâmbio acadêmico e técnico do CVHub e discutir tópicos mais interessantes juntos!