Wenyuan Xinzhiyuan Editor: LRS Com tanto sono
[Introdução Xinzhiyuan] O narrador pode gerar interações de cena humana de forma natural e controlada a partir de descrições de texto e é adequado para várias situações: interação guiada por relações espaciais, interação guiada por múltiplas ações, interação de cena com várias pessoas e combinação livre dos tipos acima.
A geração natural e controlável de interação de cena humana (HSI) desempenha um papel importante em muitos campos, como criação de conteúdo de realidade virtual/realidade aumentada (VR/AR) e inteligência artificial centrada no ser humano.
No entanto, os métodos existentes têm controlabilidade limitada, tipos de interação limitados e resultados gerados não naturais, o que limita seriamente os seus cenários de aplicação prática.
Em resposta a este problema, a equipe da Universidade de Tianjin e da Universidade de Tsinghua propuseram o Narrador no trabalho do ICCV 2023, concentrando-se em uma tarefa desafiadora, que é gerar de forma natural e controlada pessoas e cenas realistas e diversas a partir de descrições de texto.

Página inicial do projeto: http://cic.tju.edu.cn/faculty/likun/projects/Narrator
Código: https://github.com/HaibiaoXuan/Narrator
Do ponto de vista cognitivo humano, um modelo generativo ideal deve ser capaz de raciocinar corretamente sobre relações espaciais e explorar graus de liberdade interativos.
Portanto, o autor propõe um modelo generativo baseado no raciocínio relacional, modelando as relações espaciais em cenas e descrições respectivamente por meio de gráficos de cena, e introduzindo um mecanismo de interação em nível de parte que representa ações interativas como estados atômicos de partes do corpo.
Em particular, beneficiando-se do raciocínio relacional, o autor propôs ainda uma estratégia de geração multipessoas simples, mas eficaz, que foi a primeira exploração da geração interativa controlável de cenas multipessoas naquela época.
Finalmente, o autor conduziu um grande número de experimentos e pesquisas com usuários, provando que o Narrador pode gerar diversas interações de maneira controlada e seu efeito é significativamente melhor do que o trabalho existente.
motivação do método
Os métodos existentes de geração de interação humano-cena concentram-se principalmente na relação geométrica física da interação, mas carecem de controle semântico sobre a geração e são limitados à geração de uma única pessoa.
Portanto, os autores se concentram na desafiadora tarefa de gerar de forma controlada interações realistas e diversas entre cenas humanas a partir de descrições em linguagem natural. Os autores observaram que os humanos normalmente usam a percepção espacial e o reconhecimento de ações para descrever naturalmente pessoas envolvidas em diversas interações em diferentes locais.

Figura 1 O narrador pode gerar de forma natural e controlada interações entre cenas humanas semanticamente consistentes e fisicamente razoáveis, e é adequado para as seguintes situações: (a) interações guiadas por relações espaciais, (b) interações guiadas por múltiplas ações, (c) multipessoas interação de cena e (d) interação humano-cena que combina os tipos de interação acima.
Especificamente, as relações espaciais podem ser representadas como inter-relações entre diferentes objetos em uma cena ou área local, enquanto as ações interativas são especificadas por estados atômicos de partes do corpo, como os pés de uma pessoa no chão, inclinação do tronco, batidas com a mão direita e abaixamento. .
Tomando isso como ponto de partida, o autor usa gráficos de cena para representar relações espaciais e propõe um mecanismo Joint Global and Local Scene Graph (JGLSG) para fornecer consciência de posição global para a geração subsequente.
Ao mesmo tempo, considerando que o estado das partes do corpo é a chave para simular interações realistas consistentes com o texto, o autor introduziu um mecanismo de Ação em Nível de Parte (PLA) para estabelecer a correspondência entre partes e ações do corpo humano.
Beneficiando-se da cognição observacional eficaz e da flexibilidade e reutilização do raciocínio relacional proposto, os autores propõem ainda uma estratégia de geração multijogador simples e eficaz, que é a primeira estratégia de geração multijogador naturalmente controlável e fácil de usar no momento. Solução de geração de interação de cena (Multi-Human Scene Interaction, MHSI).
Ideias de métodos
Visão geral da estrutura do narrador
O objetivo do Narrador é gerar interações homem-cena de forma natural e controlada que sejam semanticamente consistentes com as descrições do texto e correspondam fisicamente à cena tridimensional.
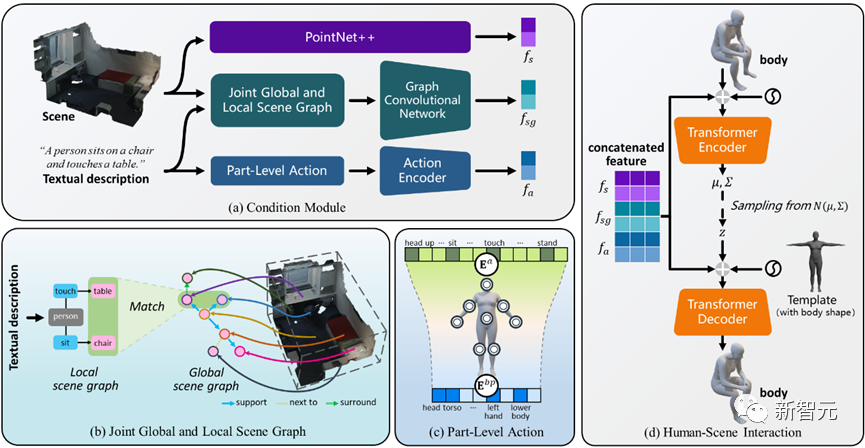
Figura 2 Visão geral da estrutura do narrador
Conforme mostrado na Figura 2, este método usa um autoencoder condicional variacional baseado em transformador (cVAE), que inclui principalmente:
1) Em comparação com a pesquisa existente que considera cenas ou objetos isoladamente, um mecanismo conjunto de gráfico de cena global e local é projetado para raciocinar sobre relações espaciais complexas e alcançar consciência de posicionamento global;
2) Com base na observação de que as pessoas realizarão ações interativas através de diferentes partes do corpo ao mesmo tempo, é introduzido um mecanismo de ação em nível de componente para alcançar interações realistas e diversas;
3) Uma perda bifacial interativa é adicionalmente introduzida no processo de otimização com reconhecimento de cena para obter melhores resultados de geração;
4) Expande-se ainda mais para a geração de interação multipessoas e, em última análise, promove o primeiro passo na interação de cena multipessoas.
Mecanismo combinado de gráfico de cena global e local
O raciocínio das relações espaciais pode fornecer ao modelo pistas sobre cenas específicas, o que desempenha um papel importante na obtenção de controlabilidade natural na interação entre humanos e cenas.
Portanto, o autor projetou um mecanismo conjunto de gráfico de cena global e local, que é implementado através das três etapas a seguir:
1. Geração de gráfico de cena global: dada uma cena, use um modelo de gráfico de cena pré-treinado para gerar um gráfico de cena global, ou seja, onde está o 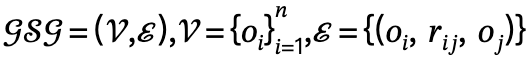 objeto com um rótulo de categoria, é a relação entre e , n é o número de objetos , m é o número de relacionamentos;
objeto com um rótulo de categoria, é a relação entre e , n é o número de objetos , m é o número de relacionamentos;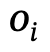
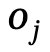
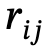
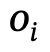
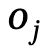
2. Geração de gráfico de cena local: Utilizar ferramentas de análise semântica para identificar a estrutura da frase descrita e extrair e gerar cenas locais 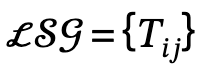 , nas quais
, nas quais 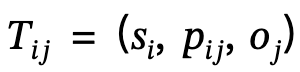 o trio sujeito-predicado-objeto é definido;
o trio sujeito-predicado-objeto é definido;
3. Correspondência de gráfico de cena: o modelo corresponde a nós nos gráficos de cena global e local com base nos mesmos rótulos semânticos de objeto e adiciona automaticamente um nó humano virtual para fornecer informações de localização, estendendo relacionamentos de borda.
Mecanismo de Ação em Nível de Componente (PLA)
As interações humanas na cena são compostas por estados de partes atômicas do corpo, então o autor propõe um mecanismo de ação de nível parcial refinado para que o modelo possa prestar atenção a partes importantes e ignorar partes irrelevantes de uma determinada interação.
Especificamente, os autores exploram ações interativas ricas e diversas e mapeiam essas ações possíveis para cinco partes principais do corpo humano: cabeça, tronco, braço esquerdo/direito, mão esquerda/direita e parte inferior esquerda/direita do corpo.
Ao mesmo tempo, a codificação one-hot (One-Hot) é usada para representar essas ações e partes do corpo, respectivamente, e elas são conectadas de acordo com o relacionamento correspondente para codificação subsequente.
Para a geração interativa de multiações, o autor utiliza um mecanismo de atenção para aprender o estado de diferentes partes da estrutura corporal.
Numa determinada combinação de ações interativas, a atenção é automaticamente blindada entre a parte do corpo correspondente a cada ação e todas as outras ações.
Tomemos como exemplo "uma pessoa agachada no chão usando um armário", o agachamento corresponde ao estado da parte inferior do corpo, de modo que a atenção marcada por outras partes será bloqueada a zero.
Otimização de reconhecimento de cena
Os autores aproveitam restrições geométricas e físicas para otimização com reconhecimento de cena para melhorar os resultados de geração. Ao longo do processo de otimização, o método garante que as poses geradas não se desviem, ao mesmo tempo que estimula o contato com a cena e restringe o corpo para evitar a interpenetração com a cena.
Dada a cena tridimensional S e os parâmetros SMPL-X gerados, a perda de otimização é:
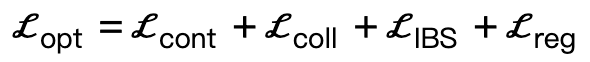
Entre eles, 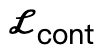 incentiva vértices do corpo a entrar em contato com a cena;
incentiva vértices do corpo a entrar em contato com a cena; 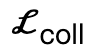 é um termo de colisão baseado na distância simbólica;
é um termo de colisão baseado na distância simbólica; 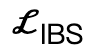 é uma perda bipartida interativa (IBS) introduzida adicionalmente em comparação com o trabalho existente, que é um conjunto de pontos equidistantes amostrados entre a cena e o corpo humano;
é uma perda bipartida interativa (IBS) introduzida adicionalmente em comparação com o trabalho existente, que é um conjunto de pontos equidistantes amostrados entre a cena e o corpo humano; 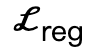 é um fator de regularização utilizado para penalizar parâmetros que se desviam de sua inicialização.
é um fator de regularização utilizado para penalizar parâmetros que se desviam de sua inicialização.
Interação de cena multijogador (MHSI)
Em cenários do mundo real, em muitos casos não há apenas uma pessoa interagindo com a cena, mas diversas pessoas interagindo de forma independente ou associada.
No entanto, devido à falta de conjuntos de dados MHSI, os métodos existentes geralmente requerem esforços manuais adicionais e não podem realizar esta tarefa de forma controlada e automatizada.
Para este fim, os autores utilizam apenas conjuntos de dados individuais existentes e propõem uma estratégia simples, mas eficaz, para direções de geração multipessoas.
Dada uma descrição de texto relacionada a várias pessoas, o autor primeiro a analisa em vários gráficos de cena local 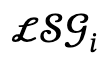 e ações interativas
e ações interativas 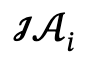 e define o conjunto candidato como
e define o conjunto candidato como 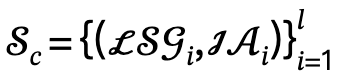 , onde l é o número de pessoas.
, onde l é o número de pessoas.
Para cada item do conjunto de candidatos, ele é primeiro alimentado no Narrador junto com a cena  e o gráfico de cena global correspondente e, em seguida, o processo de otimização é executado.
e o gráfico de cena global correspondente e, em seguida, o processo de otimização é executado.
Para lidar com colisões entre pessoas, é introduzida uma perda adicional no processo de otimização 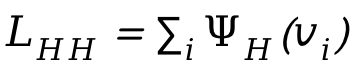 , onde
, onde 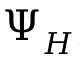 é a distância sinalizada entre pessoas.
é a distância sinalizada entre pessoas.
Então, quando a perda de otimização for inferior ao limite determinado com base na experiência experimental, o resultado gerado é aceito e atualizado pela adição de nós humanos 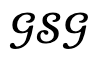 ; caso contrário, o resultado gerado é considerado não confiável e atualizado pela blindagem do nó do objeto correspondente
; caso contrário, o resultado gerado é considerado não confiável e atualizado pela blindagem do nó do objeto correspondente 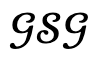 .
.
Vale ressaltar que este método de atualização estabelece a relação entre os resultados de cada geração e os resultados da geração anterior, evita certo grau de aglomeração e torna a distribuição espacial mais razoável e a interação mais realista do que a simples geração múltipla.
O processo acima pode ser expresso como:
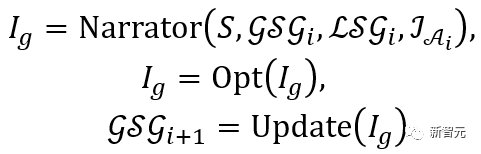
Resultados experimentais
Como os métodos atualmente existentes não podem gerar interações entre cenas humanas de forma natural e controlada diretamente a partir de descrições de texto, o autor estende razoavelmente PiGraph [1], POSA [2] e COINS [3] para métodos adequados para descrições de texto e usa o mesmo. conjuntos de dados usados para treinar seus modelos oficiais, os métodos modificados são definidos como PiGraph-Text, POSA-Text e COINS-Text.

Figura 3 Resultados de comparação qualitativa de diferentes métodos
A Figura 3 mostra os resultados da comparação qualitativa do Narrador com três linhas de base. PiGraph-Text apresenta problemas de penetração mais sérios devido a limitações em sua própria representação.
O POSA-Text frequentemente cai em mínimos locais durante o processo de otimização, resultando em interações indesejáveis. COINS-Text vincula ações a objetos específicos, não possui consciência global da cena, leva à penetração de objetos não especificados e é difícil de lidar com relações espaciais complexas.
Em contraste, o Narrador pode raciocinar corretamente sobre as relações espaciais e analisar os estados do corpo sob múltiplas ações com base em diferentes níveis de descrições de texto, alcançando assim melhores resultados de geração.
Em termos de comparação quantitativa, conforme mostrado na Tabela 1, o Narrador supera outros métodos em cinco indicadores, mostrando que os resultados gerados por este método apresentam consistência textual mais precisa e melhor plausibilidade física.
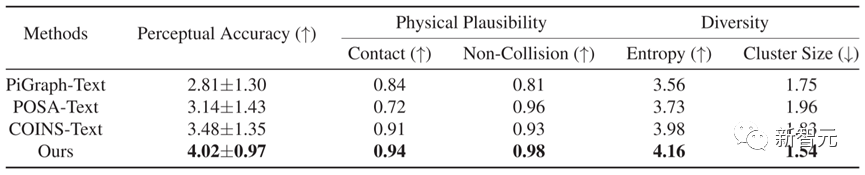
Tabela 1 Resultados de comparação quantitativa de diferentes métodos
Além disso, o autor também fornece comparações e análises detalhadas para compreender melhor a eficácia da estratégia MHSI proposta.
Considerando que atualmente não há trabalho sobre MHSI, escolheram uma abordagem simples como base, nomeadamente geração sequencial e otimização com COINS.
Para fazer uma comparação justa, também são introduzidas perdas artificiais por colisão. A Figura 4 e a Tabela 2 mostram os resultados qualitativos e quantitativos respectivamente, ambos comprovando fortemente que a estratégia proposta pelo autor é semanticamente consistente e fisicamente razoável no MHSI.

Figura 4 Comparação qualitativa do MHSI com o método de geração e otimização sequencial utilizando COINS

Tabela 2 Comparação quantitativa do MHSI com o método de geração sequencial e otimização com COINS
O vídeo de demonstração deste trabalho é o seguinte:
Sobre o autor

Xuan Haibiao, estudante de mestrado na Universidade de Tianjin
Principais direções de pesquisa: visão tridimensional, visão computacional, geração interativa de cena humana

Li Xiongzheng, doutorando de 19º nível na Universidade de Tianjin
Principais direções de pesquisa: visão 3D, visão computacional, reconstrução do corpo humano e do vestuário

Zhang Jinsong, candidato a doutorado pela Universidade de Tianjin
Principais direções de pesquisa: visão 3D, visão computacional, geração de imagens

Zhang Hongwen, pós-doutorado na Universidade Tsinghua
Principais direções de pesquisa: Visão computacional e gráficos centrados no ser humano

Liu Yebin, professor da Universidade Tsinghua
Principais direções de pesquisa: computação gráfica, visão tridimensional e fotografia computacional
Página inicial pessoal: https://liuyebin.com/

Li Kun (autor correspondente), professor e supervisor de doutorado na Universidade de Tianjin
Principais direções de pesquisa: visão 3D, reconstrução e geração inteligente
Página inicial pessoal: http://cic.tju.edu.cn/faculty/likun
Referências:
[1] Savva M, Chang AX, Hanrahan P, et al. Pigraphs: aprendendo instantâneos de interação a partir de observações[J]. Transações ACM em Gráficos (TOG), 2016, 35(4): 1-12.
[2] Hassan M, Ghosh P, Tesch J, et al. Preencher cenas 3D aprendendo a interação entre cena humana[C]. Anais da Conferência IEEE/CVF sobre Visão Computacional e Reconhecimento de Padrões. 2021: 14708-14718.
[3] Zhao K, Wang S, Zhang Y, et al. Síntese composicional da interação humano-cena com controle semântico[C]. Conferência Europeia sobre Visão Computacional. Cham: Springer Nature Suíça, 2022: 311-327.
Siga a conta pública [Aprendizado de máquina e criação gerada por IA], coisas mais interessantes estão esperando por você para ler
Uma introdução simples ao ControlNet, um algoritmo controlável de geração de pintura AIGC!
O GAN clássico deve ser lido: StyleGAN
 Clique em mim para ver a série de álbuns do GAN ~!
Clique em mim para ver a série de álbuns do GAN ~!
Uma xícara de chá com leite e torne-se o criador de tendências da visão AIGC + CV!
A coleção mais recente e completa de 100 artigos! Gerar modelos de difusãoModelos de difusão
ECCV2022 | Resumo de alguns artigos sobre Generative Adversarial Network GAN
CVPR 2022 | Mais de 25 direções, os 50 artigos GAN mais recentes
ICCV 2021 | Resumo de 35 artigos do GAN sobre tópicos
Mais de 110 artigos! Revisão de artigo GAN mais abrangente do CVPR 2021
Mais de 100 artigos! Revisão de artigo GAN mais abrangente do CVPR 2020
Descompactando um novo GAN: desacoplamento da representação MixNMatch
StarGAN versão 2: geração de imagens de diversidade multidomínio
Download em anexo | Versão chinesa de "Aprendizado de máquina explicável"
Download em anexo | "Prática de algoritmo de aprendizado profundo do TensorFlow 2.0"
Download em anexo | Compartilhamento de "Métodos Matemáticos em Visão Computacional"
"Uma revisão dos métodos de detecção de defeitos de superfície baseados em aprendizado profundo"
"Uma revisão da classificação de imagens de amostra zero: dez anos de progresso"
"Uma revisão do aprendizado de poucas amostras com base em redes neurais profundas"
O “Livro dos Ritos · Xue Ji” diz: Se você estudar sozinho, sem amigos, ficará solitário e ignorante.
Clique em uma xícara de chá com leite e torne-se o criador de tendências da visão AIGC + CV! , junte-se ao planeta da criação gerada por IA e do conhecimento de visão computacional!