-
I. Introdução
1 Introdução aos mapas de calor
Normalmente, um mapa de calor usa mudanças de cores para representar visualmente as mudanças entre diferentes amostras após normalizar os dados obtidos ou outros fatores. Essencialmente, é uma matriz de dados composta por pequenos quadrados com cores predefinidas que representam valores numéricos.Ao agrupar fatores ou amostras, pode-se observar a semelhança entre diferentes dados amostrais.
2 Método de desenho de mapa de calor
Software de desenho comumente usado: origin , excel, Tbtools, GraphPadPrism
Pacote R para desenhar mapas de calor de cluster na linguagem R: pheatmap , heatmap, corrplot, complexHeatmap
Entre eles, pheatmap é o pacote de desenho mais utilizado na linguagem R para desenhar mapas de calor de cluster. O uso deste pacote de plotagem pode nos ajudar a gerar rapidamente mapas de calor contendo resultados de agrupamento.
2. Use o pacote pheatmap para desenhar mapas de calor de cluster
1 Preparação de dados
Formato de entrada de dados (formato csv):

Carregamento de pacotes 2 R e importação de dados
#下载包#
install.packages("pheatmap")
install.packages("RColorBrewer")
#加载包#
library("pheatmap")
library("RColorBrewer")
#加载绘图数据#
data<-read.table(file='C:/Rdata/jc/pheatmap.csv',header=TRUE,row.names= 1,sep=',')
head(data) #查看数据 
#data=log2(data[,1:6]+1) #对基因表达量数据处理
#data <- as.matrix(data) #转变为matrix格式矩阵
#head(data)3 Desenho do mapa de calor
3.1 Mapa de calor básico e padronização
pheatmap(data) #基础热图绘制 
Figura 1 Mapa de calor com dados não normalizados
3.2 Executar desenho normalizado
3.2.1 Preparação para desenho de mapa de calor – homogeneização
Desenhar um mapa de calor geralmente requer a normalização dos dados para que os fatores com grandes diferenças estejam na mesma ordem de magnitude, facilitando a observação dos padrões de mudança de diferentes fatores entre diferentes amostras. De modo geral, a distribuição de um fator entre diferentes amostras será exibida na direção da linha do mapa de calor, portanto, para exibir a distribuição de um fator entre diferentes amostras, o processo de normalização será realizado de acordo com a “linha”.
pheatmap(data, scale='row') #标准化的方法,row是按照进行标准化(归一化),column是按照列进行标准化,none为不进行标准化 
Figura 2 Mapa de calor normalizado
3.3 Método de agrupamento de mapa de calor e ajuste de árvore de agrupamento
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为“euclidean”,也可为 "correlation"即按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行、列聚类,根据行、列聚类数量分隔热图行
treeheight_row = 30, treeheight_col = 30) #、行、列聚类树高度调整 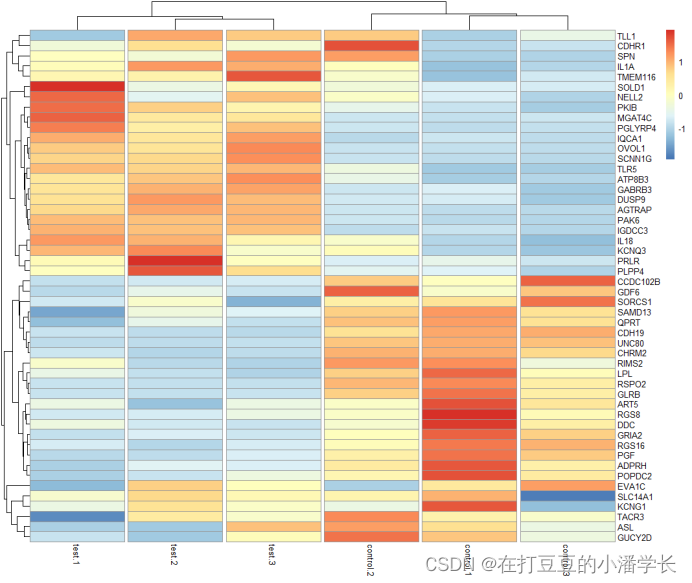
Figura 3 Mapa de calor após definir o método de agrupamento do mapa de calor e ajuste da árvore de agrupamento
3.4 Ajuste do formato da célula do mapa de calor de agrupamento
3.4.1 Ajuste de comprimento, largura e cor da borda da célula
Use "cellwidth", "cellheight" e "border_color" para definir a largura, altura e cor da borda da célula do mapa de calor:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = NA, #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5) #表示单个单元格的宽度\高度,默认为 “NA”

Figura 4 Mapa de calor após definir a largura, altura e cor da borda da célula
3.4.2 Ajuste da exibição numérica e tamanho da fonte numérica nas células
Use "display_numbers", "fontsize_number", "number_format" e "number_color" para definir a exibição numérica, o tamanho da fonte numérica, o formato numérico e a cor da fonte na célula do mapa de calor:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = NA, #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = T, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30") #表示热图单元格上显示的数据字体颜色
Figura 5 Mapa de calor após definir a exibição numérica e o tamanho da fonte numérica na célula
3.4.3 Marcadores de distinção de células do mapa de calor
Use "display_numbers" para marcar de acordo com o valor da célula do mapa de calor. Se o valor original da célula for maior que 1, é "***", caso contrário é " ";
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = NA, #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = matrix(ifelse(data > 1, "***", ""), nrow = nrow(data)),#使用“display_numbers” 根据热图单元格的数值进行标记,若该单元格原始数值大于1,则为 “***”,否则为 " ";
fontsize_number = 10, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30") #表示热图单元格上显示的数据字体颜色
Figura 6 O mapa de calor após definir os marcadores de distinção de células do mapa de calor
3.5 Embelezamento e personalização do mapa de calor
3.5.1 Título do mapa de calor e rótulos de linhas e colunas
Use "show_rownames", "show_colnames", "main" para definir nomes de linhas, exibição de nomes de colunas e títulos:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = T, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
show_rownames = F, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题") #表示热图的标题名字

Figura 7 O mapa de calor após definir os nomes das linhas do mapa de calor, exibição do nome da coluna e título
3.5.2 Configuração do tamanho da fonte do mapa de calor
Use "fontsize", "fontsize_row" e "fontsize_row" para definir o tamanho da fonte, o nome da linha e o tamanho da fonte do nome da coluna no mapa de calor. O padrão é consistente com o tamanho da fonte:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = 6, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = T, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题") #表示热图的标题名字

Figura 8 O mapa de calor após definir o tamanho da fonte, o nome da linha e o tamanho da fonte do nome da coluna no mapa de calor.
3.5.3 Personalização do mapa de calor
3.5.3.1 Legenda de configuração de cores do mapa de calor
Use "color", "legend", "legend_breaks", etc. para definir a cor do mapa de calor, exibição da legenda, intervalo da legenda, etc.:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = NA, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = F, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题", #表示热图的标题名字
color = colorRampPalette(c("navy","white","firebrick3"))(100), #表示热图颜色,(100)表示100个等级
legend = T, #表示是否显示图例,值为TRUE或FALSE
legend_breaks = NA, #设置图例的范围legend_breaks=c(-2.5,0,2.5)表示图例断点的设置,默认为NA,
legend_labels = NA) #表示图例断点的标签

Figura 9 Mapa de calor com cor do mapa de calor e conjunto de legenda
3.5.3.2 Ângulo do rótulo e posição da partição do mapa de calor sob condição não agrupada
Use "angle_col" para definir o ângulo dos rótulos das colunas; "gaps_row" e "gaps_col" definem a posição de quebra do mapa de calor nas direções de linha e coluna quando o agrupamento de linhas e colunas não é executado:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = F, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = NA, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = F, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题", #表示热图的标题名字
color = colorRampPalette(c("navy","white","firebrick3"))(100), #表示热图颜色,(100)表示100个等级
legend = T, #表示是否显示图例,值为TRUE或FALSE
legend_breaks = NA, #设置图例的范围legend_breaks=c(-2.5,0,2.5)表示图例断点的设置,默认为NA,
legend_labels = NA, #表示图例断点的标签
angle_col = "45", #表示列标签的角度
gaps_row = NULL, #仅在未进行行聚类时使用,表示在行方向上热图的隔断位置
gaps_col = c(1,2,3,4,5,6)) #仅在未进行列聚类时使用,表示在列方向上热图的隔断位置
Figura 10 Mapa de calor após definir os ângulos dos rótulos das colunas e as partições das colunas
3.5.3.3 Personalizar rótulos de linhas e colunas
Use "gaps_row" e "gaps_col" para personalizar rótulos de linhas e colunas:
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = NA, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = F, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题", #表示热图的标题名字
color = colorRampPalette(c("navy","white","firebrick3"))(100), #表示热图颜色,(100)表示100个等级
legend = T, #表示是否显示图例,值为TRUE或FALSE
legend_breaks = NA, #设置图例的范围legend_breaks=c(-2.5,0,2.5)表示图例断点的设置,默认为NA,
legend_labels = NA, #表示图例断点的标签
angle_col = "45", #表示列标签的角度
gaps_row = NULL, #仅在未进行行聚类时使用,表示在行方向上热图的隔断位置
gaps_col = c(1,2,3,4,5,6), #仅在未进行列聚类时使用,表示在列方向上热图的隔断位置
labels_row = NULL, #表示使用行标签代替行名
labels_col = c("sample1","sample2","sample3","sample4","sample5","sample6")) #表示使用列标签代替列名

Figura 11 Mapa de calor de rótulos de colunas completos personalizados
3.6 Salvamento do mapa de calor
Salve o mapa de calor usando "nome do arquivo", "largura" e "altura":
pheatmap(data, scale = "row", #表示进行均一化的方向,值为 “row”, “column” 或者"none"
clustering_distance_rows = "euclidean", clustering_distance_cols = "euclidean",#表示行、列聚类使用的度量方法,默认为欧式距离“euclidean”, "correlation"表示按照 Pearson correlation方法进行聚类
clustering_method = "complete", #表示聚类方法,包括:‘ward’, ‘ward.D’, ‘ward.D2’, ‘single’, ‘complete’, ‘average’, ‘mcquitty’, ‘median’, ‘centroid’
cluster_rows = T,cluster_cols = T, #cluster_rows表示仅对行聚类,cluster_cols表示仅对列聚类,值为TRUE或FALSE
cutree_rows = NA, cutree_cols = NA, #若进行了行/列聚类,根据行/列聚类数量分隔热图行,cutree_rows=num分割行,cutree_cols=num分割列
treeheight_row = 30, treeheight_col = 30, #若行、列聚类树高度调整
border_color = "grey60", #表示热图每个小的单元格边框的颜色,默认为 "grey60"
cellwidth = 60, cellheight = 7.5, #表示单个单元格的宽度\高度,默认为 “NA”
display_numbers = F, #表示是否在单元格上显示原始数值或按照特殊条件进行区分标记
fontsize_number = 6, #表示热图上显示数字的字体大小
number_format = "%.2f", #表示热图单元格上显示的数据格式,“%.2f” 表示两位小数,“%.1e”表示科学计数法
number_color = "grey30", #表示热图单元格上显示的数据字体颜色
fontsize =10, fontsize_row = 6, fontsize_col = 10, #热图中字体大小、行、列名字体大小
show_rownames = T, show_colnames = T, #表示是否显示行名、列名
main = "Gene标题", #表示热图的标题名字
color = colorRampPalette(c("navy","white","firebrick3"))(100), #表示热图颜色,(100)表示100个等级
legend = T, #表示是否显示图例,值为TRUE或FALSE
legend_breaks = NA, #设置图例的范围legend_breaks=c(-2.5,0,2.5)表示图例断点的设置,默认为NA,
legend_labels = NA, #表示图例断点的标签
angle_col = "45", #表示列标签的角度
gaps_row = NULL, #仅在未进行行聚类时使用,表示在行方向上热图的隔断位置
gaps_col = c(1,2,3,4,5,6), #仅在未进行列聚类时使用,表示在列方向上热图的隔断位置
labels_row = NULL, #表示使用行标签代替行名
labels_col = c("sample1","sample2","sample3","sample4","sample5","sample6"), #表示使用列标签代替列名
filename = NA, #表示保存图片的位置及命名
width = NA, height = NA) #表示输出绘制热图的宽度/高度Bem, esse compartilhamento termina aqui. Na próxima edição, compartilharemos o desenho de agrupamento de grupos de mapas de calor.

Digitalize o código QR e siga a conta oficial para obter mais conteúdo, bem como o código correspondente e dados de demonstração.