Tensorflow2 implementa reconhecimento de dígitos manuscritos
0. Introdução ao conjunto de dados MNIST
O conjunto de dados MNIST vem do Instituto Nacional de Padrões e Tecnologia (NIST). O conjunto de treinamento consiste em números manuscritos de 250 pessoas diferentes, 50% das quais são estudantes do ensino médio e 50% da população. Funcionários do Census Bureau. O conjunto de teste também contém a mesma proporção de dados de dígitos manuscritos.
O conjunto de dados MNIST está disponível no MNIST e consiste em quatro partes:
- Imagens do conjunto de treinamento: train-images-idx3-ubyte.gz
(47 MB descompactado, contém 60.000 amostras) - Rótulos do conjunto de treinamento: train-labels-idx1-ubyte.gz
(60 KB após a descompactação, contém 60.000 rótulos) - Imagens do conjunto de teste: t10k-images-idx3-ubyte.gz
(7,8 MB após descompactação, contém 10.000 amostras) - Rótulos do conjunto de testes: t10k-labels-idx1-ubyte.gz
(10 KB após a descompactação, contém 10.000 rótulos)
As imagens no conjunto de treinamento e no conjunto de teste aqui são imagens em escala de cinza 28×28 e cada pixel é um valor em [0, 255].
O valor no conjunto de rótulos é um valor em [0, 9], que marca o número manuscrito da imagem de posição correspondente.
exemplo: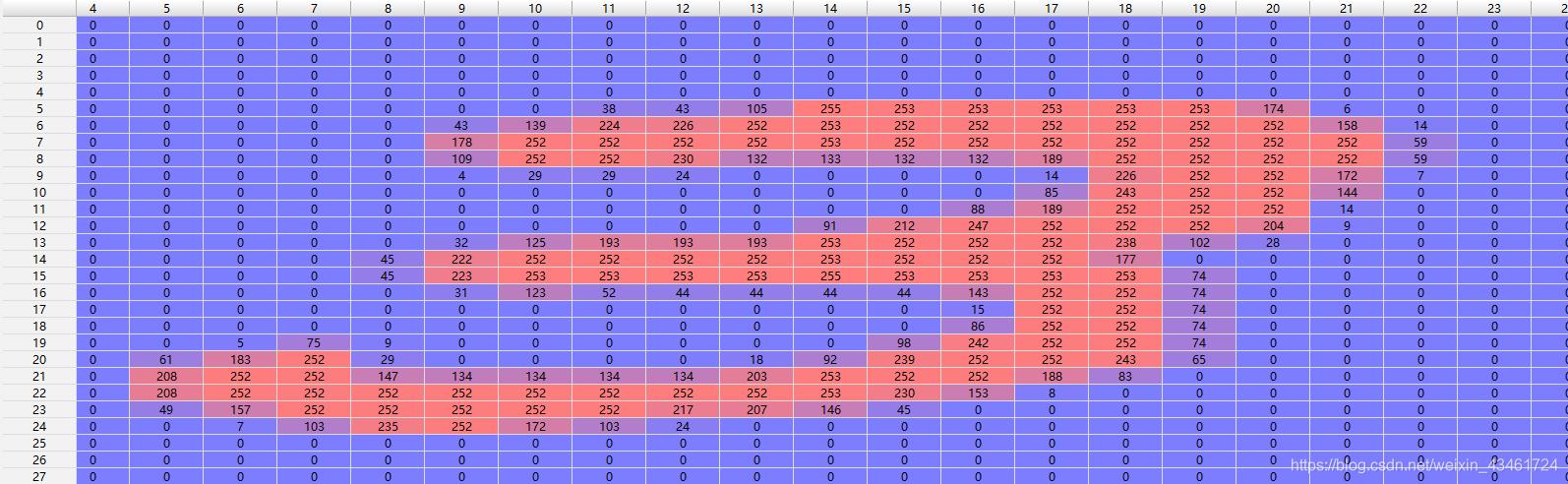
1. Detalhes do código
import tensorflow as tf
Apresente o módulo tensorflow com tf como alias
batch_size = 128
le_r = 0.2
Defina um tamanho de lote e taxa de aprendizagem
mnist = tf.keras.datasets.mnist
(ti, tl), (vi, vl) = mnist.load_data()
print('datasets:', ti.shape, tl.shape, vi.shape, vl.shape)
Use a função integrada do tensorflow para importar o conjunto de dados MNIST
E produza as dimensões dos dados:
conjuntos de dados: (60.000, 28, 28) (60.000,)
(10.000, 28, 28) (10.000,)
def fun(a, b):
a = tf.cast(a, dtype=tf.float32)
b = tf.cast(b, dtype=tf.int64)
return tf.reshape(a, [-1, 28*28])/255.0, tf.one_hot(b, depth=10)
ti, tl = fun(ti, tl)
vi, _ = fun(vi, vl)
Como as dimensões de vi e ti são [-1, 28, 28], esperamos nivelar cada amostra [28, 28] em [784] para facilitar a entrada na rede, portanto, uma função chamada fun é definida aqui, respectivamente. Execute o pré-processamento de dados em ti, tl e vi (vl não precisa ser processado). A entrada é simplesmente normalizada, ou seja, dividida por 255,0 (valor máximo - valor mínimo nos dados). E a codificação one-hot é executada nas tags.
Após o pré-processamento, as dimensões de ti e vi são [60.000, 784] e [10.000, 784], respectivamente.
exemplo:
Após a normalização
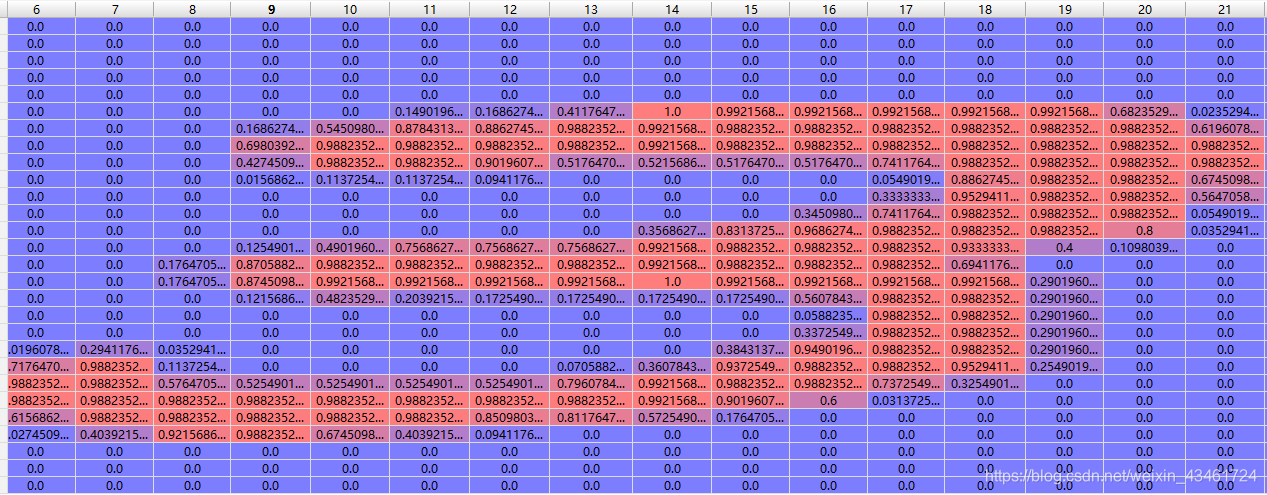
Seu rótulo correspondente 3 será expandido para [0, 0, 0, 1, 0, 0, 0, 0, 0]
Sobre a expansão do pré-processamento de dados:
d1 = tf.data.Dataset.from_tensor_slices((ti, tl)) # ti tl 自动转换为tensor
d1 = d1.shuffle(10000).batch(batch_size)
Chame a função tf.data.Dataset.from_tensor_slices() para construir uma fatia de (ti, tl): shuffle() pode embaralhar os dados. batch(batch_size) pode dividir os dados em vários grupos de dados do tamanho de batch_size e retornar um Iterable objeto usado para iterar através de grupos de dados individuais.
w1 = tf.random.normal([784, 512])
b1 = tf.zeros([512], dtype=tf.float32)
w2 = tf.random.normal([512, 10])
b2 = tf.zeros([10], dtype=tf.float32)
Construa a matriz de peso w e seu deslocamento b da primeira e segunda camadas, inicialize b para uma matriz 0; inicialize w de acordo com uma distribuição normal.
Aqui, como a dimensão ti de entrada foi processada para [-1, 784],]', nossa entrada é de 784 nós e a camada oculta do meio é de 512 nós. Como é um problema de classificação de 10 classes, a saída é 10 nós, representando números. 0~9, quanto maior a saída do nó, maior a probabilidade de representar esse número.
Em relação à expansão de inicialização de peso:
Depois, itere o conjunto de dados para otimização da descida do gradiente e produza a precisão da rede no conjunto de verificação em um período fixo.
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1)
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))
Visto separadamente:
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
A primeira é executar um total de 10 épocas, ou seja, 10 loops grandes. Cada loop grande primeiro inicializa d2 como o iterador de d1 e, em seguida, itera d1 por meio do loop for. As dimensões de d1, x e y, exceto o o último é [128, 784], [128, 10].
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1) # [TensorShape([128, 500])
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
@ significa multiplicação de matrizes
A poderosa diferenciação automática do Tensorflow é usada aqui. tape.watch([w1, b1, w2, b2]) significa registrar as informações de gradiente de w1, b1, w2, b2, para que não haja necessidade de empacotar um pacote para w1, b1 , w2, b2.Camada tf.Variable().
a1 é a saída final da camada oculta de h2 após ser processada pela função de ativação sigmoid().
Finalmente, defina a função de perda. O valor desta função representa o grau de desvio entre nossa saída final de [-1, 10] e o rótulo [-1, 10]. O erro quadrático médio pode ser usado aqui, mas o efeito é melhor usar a função de entropia cruzada como função de perda. A função de entropia cruzada pode refletir com mais precisão a lacuna entre duas distribuições de probabilidade.
Aqui, como não realizamos o processamento softmax na saída de saída para torná-la compatível com as características da distribuição de probabilidade (a soma é 1), definimos from_logits como True, o que retornará à chamada de softmax_cross_entropy_with_logits_v2() para nos ajudar a executar softmax processamento dentro da função.
Aqui está uma demonstração da derivação automática do tensorflow, e você também pode encontrar a derivada de segunda ordem por meio de aninhamento.
With tf.GradientTape() as tape:
Build computation graph
loss=fθ(x)
[w_grad] = tape.gradient(loss,[w])
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
grads = tape.gradient(loss, [w1, b1, w2, b2]) retira a matriz derivada parcial de w1, b1, w2, b2 para loss (função de perda) (grads = [dw1, db1, dw2, db2] )
As linhas 4, 5, 6 e 7 atualizam os parâmetros na direção da redução do gradiente.
Cada vez que 100 lotes são executados (são realizadas 100 descidas de gradiente), uma mensagem de conclusão é emitida.
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))
Neste momento, 1 época foi concluída e c1 e c2 são o processo de propagação direta do conjunto de verificação. Neste momento, a dimensão c2 é [10000, 10], ou seja, cada linha é a saída de uma imagem de amostra do conjunto de verificação após o processamento da rede. Não há necessidade de realizar processamento softmax nela. Precisamos apenas retirar o nó inferior do nó com o maior valor de saída entre os nós 10. Você pode saber o valor previsto desta imagem de amostra usando o padrão.
A função tf.argmax() é usada aqui para obter o subscrito do maior elemento em cada linha. A dimensão out2 processada é [10.000,], que corresponde aos valores previstos de 10.000 imagens do conjunto de verificação.
Em seguida, compare out2 com o conjunto de tags vl, converta os valores verdadeiro e falso para 1 ou 0 e some para obter o número de imagens previstas corretamente. Em seguida, divida por vl.shape[0], que é 10.000 , para obter o número previsto. A taxa de precisão aumentou.

Depois de executá-lo, você pode ver que a precisão desta rede na previsão de dígitos manuscritos é de cerca de 91%.Se você usar uma rede convolucional, poderá obter melhor precisão.
2. Visão geral do código
import tensorflow as tf
batch_size = 128
le_r = 0.2
def fun(a, b):
a = tf.cast(a, dtype=tf.float32)
b = tf.cast(b, dtype=tf.int64)
return tf.reshape(a, [-1, 28*28])/255.0, tf.one_hot(b, depth=10)
mnist = tf.keras.datasets.mnist
(ti, tl), (vi, vl) = mnist.load_data()
print('datasets:', ti.shape, tl.shape, vi.shape, vl.shape)
ti, tl = fun(ti, tl)
vi, _ = fun(vi, vl)
d1 = tf.data.Dataset.from_tensor_slices((ti, tl)) # ti tl 自动转换为tensor
d1 = d1.shuffle(10000).batch(batch_size)
w1 = tf.random.normal([784, 512])
b1 = tf.zeros([512], dtype=tf.float32)
w2 = tf.random.normal([512, 10])
b2 = tf.zeros([10], dtype=tf.float32)
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1)
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))