De: Xinzhiyuan
Entre no grupo de PNL—> Junte-se ao grupo de intercâmbio de PNL
[Introdução Xinzhiyuan] De regras manuais, redes neurais a modelos básicos de Transformer, o futuro do processamento de linguagem natural é unificar a multimodalidade e avançar em direção à inteligência artificial geral!
Nos últimos dez anos, contando apenas com cálculos simples de redes neurais e suporte de dados de treinamento em grande escala, foram feitos avanços consideráveis no campo do processamento de linguagem natural.Modelos de linguagem pré-treinados obtidos a partir deste treinamento, como BERT, GPT- 3 e outros modelos fornecem recursos poderosos de compreensão, geração e raciocínio de linguagem geral.
Há algum tempo, Christopher D. Manning, professor da Universidade de Stanford, publicou um artigo sobre "Compreensão e raciocínio da linguagem humana" na revista Daedalus. Ele revisou principalmente a história do desenvolvimento do processamento de linguagem natural e analisou as perspectivas futuras de desenvolvimento do básico modelo.

Link do artigo: https://direct.mit.edu/daed/article/151/2/127/110621/Human-Language-Understanding-amp-Reasoning

O autor do artigo, Christopher Manning, é professor de ciência da computação e linguística na Universidade de Stanford e líder na aplicação de aprendizagem profunda ao processamento de linguagem natural. Sua pesquisa se concentra no uso de métodos de aprendizado de máquina para lidar com problemas de linguística computacional, para que os computadores possam processar, compreender e gerar de forma inteligente a linguagem humana.
O professor Manning é ACM Fellow, AAAI Fellow e ACL Fellow. Muitos de seus livros, como "Fundamentals of Statistical Natural Language Processing" e "Introduction to Information Retrieval", tornaram-se livros clássicos. Seu curso Stanford CS224n "Deep Learning for Natural Processamento de Linguagem" É uma leitura obrigatória para inúmeros praticantes de PNL começarem.
As quatro eras da PNL
A primeira era (1950-1969)
A pesquisa da PNL começou com a pesquisa da tradução automática. Naquela época, as pessoas acreditavam que a tarefa de tradução poderia continuar a se desenvolver com base nas conquistas da quebra de código durante a Segunda Guerra Mundial. Ambos os lados da Guerra Fria também estavam desenvolvendo sistemas que poderia traduzir os resultados científicos de outros países.No entanto, durante este período, quase nada se sabe sobre a estrutura da linguagem natural, inteligência artificial ou aprendizado de máquina.
Houve muito pouco esforço computacional e poucos dados disponíveis e, embora os sistemas iniciais tenham sido promovidos com grande alarde, esses sistemas apenas forneciam pesquisas de tradução em nível de palavra e alguns mecanismos simples e baseados em regras para lidar com as formas flexionais das palavras (morfologia) e ordem das palavras.
A segunda era (1970-1992)
Este período viu o desenvolvimento de uma série de sistemas de demonstração de PNL que demonstraram sofisticação e profundidade no tratamento de fenômenos como sintaxe e citação em linguagem natural, incluindo SHRDLU de Terry Winograd, LUNAR de Bill Woods, SAM de Roger Schank, LIFER de Gary Hendrix e GUS de Danny Bobrow. eram ambos sistemas construídos à mão e baseados em regras que podiam até ser usados para tarefas como consultas de banco de dados.
A linguística e a inteligência artificial baseada no conhecimento estão a avançar rapidamente, e a segunda década desta era deu origem a uma nova geração de sistemas construídos à mão, com limites claros entre o conhecimento da linguagem declarativa e o processamento processual, e com os benefícios da linguagem. teoria acadêmica.
A terceira era (1993-2012)
Durante este período, o número de textos digitais disponíveis aumentou significativamente, e o desenvolvimento da PNL gradualmente mudou para uma compreensão profunda da linguagem, extraindo informações como localização e conceitos metafóricos de dezenas de milhões de palavras de texto. No entanto, ainda era apenas com base na análise de palavras, então a maioria dos pesquisadores se concentra principalmente em recursos de linguagem anotados, como o significado de palavras marcadas, nomes de empresas, bancos de árvores, etc., e então usa técnicas de aprendizado de máquina supervisionado para construir modelos.
A quarta era (2013 até o presente)
Começaram a se desenvolver métodos de aprendizagem profunda ou redes neurais artificiais, que podem modelar o contexto em longas distâncias. Palavras e frases são representadas por espaços vetoriais de valor real de centenas ou milhares de dimensões. Distâncias em espaços vetoriais podem representar semelhanças de significado ou sintaxe. grau. , mas a execução das tarefas ainda é semelhante ao aprendizado supervisionado anterior.
Em 2018, o aprendizado de redes neurais autosupervisionadas em grande escala alcançou grande sucesso. Ele pode simplesmente inserir uma grande quantidade de texto (bilhões de palavras) para aprender conhecimento. A ideia básica é prever continuamente "dadas as primeiras palavras" Próximo palavra, repita previsões bilhões de vezes e aprenda com os erros, que podem então ser usados para respostas a perguntas ou tarefas de classificação de texto.
O impacto dos métodos autossupervisionados pré-treinados é revolucionário, produzindo um modelo poderoso sem a necessidade de anotação humana que pode ser usado para uma variedade de tarefas de linguagem natural com subsequente ajuste fino simples.
Arquitetura do modelo
Desde 2018, o principal modelo de rede neural usado em aplicações de PNL foi transformado na rede neural Transformer. A ideia central é o mecanismo de atenção. A representação de uma palavra é calculada como uma combinação ponderada de representações de palavras de outras posições.
Um objetivo autosupervisionado comum do Transofrmer é mascarar as palavras que aparecem no texto, comparar os vetores de consulta, chave e valor naquela posição com outras palavras, calcular o peso da atenção e ponderar a média e, em seguida, passar a camada totalmente conectada e normalização Camadas e resíduos são conectados para gerar novos vetores de palavras e, em seguida, repetidos várias vezes para aumentar a profundidade da rede.
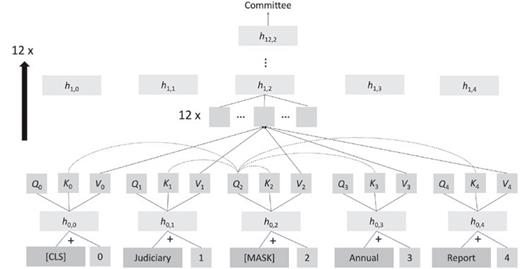
Embora a estrutura de rede do Transformer não pareça complicada e os cálculos envolvidos sejam simples, se o número de parâmetros do modelo for grande o suficiente e uma grande quantidade de dados for usada para treinamento e previsão, o modelo pode descobrir a maioria das estruturas de linguagem natural, incluindo sintaxe.Estrutura, conotação das palavras, conhecimento factual, etc.
geração imediata
De 2018 a 2020, a principal forma como os pesquisadores usaram grandes modelos de linguagem pré-treinados (LPLM) foi ajustá-los com uma pequena quantidade de dados anotados para torná-los adequados para tarefas personalizadas.
No entanto, após o lançamento do GPT-3 (Generative Pre-training Transformer-3), os pesquisadores ficaram surpresos ao descobrir que o modelo poderia ser concluído bem mesmo em novas tarefas que não foram treinadas apenas inserindo um prompt.
Em contraste, os modelos tradicionais de PNL são montados em pipeline a partir de vários componentes cuidadosamente projetados. Eles primeiro capturam a estrutura da frase e as entidades de baixo nível do texto e, em seguida, identificam os significados de nível superior antes de inseri-los em determinados campos específicos. componente de execução.
Nos últimos anos, as empresas começaram a substituir esta solução tradicional de PNL por LPLM, ajustada para realizar tarefas específicas.
maquina de tradução
Os primeiros sistemas de tradução automática só podiam cobrir estruturas linguísticas limitadas em domínios limitados.
O Google Translate, lançado em 2006, construiu pela primeira vez um modelo estatístico a partir de um corpus paralelo em grande escala; em 2016, o Google Translate foi convertido em um sistema neural de tradução automática e a qualidade foi bastante melhorada; em 2020, foi atualizado novamente para um sistema de tradução neural baseado no Transformer, que não requer mais dois. Em vez de usar corpus paralelos de idiomas diferentes, uma enorme rede pré-treinada é usada para traduzir o tipo de idioma por meio de um token especial.
Tarefa de perguntas e respostas
O sistema de perguntas e respostas precisa encontrar informações relevantes em uma coleção de textos e, em seguida, fornecer respostas a perguntas específicas.Existem muitos cenários de aplicação comercial direta a jusante, como suporte ao cliente pré-venda e pós-venda.
Os sistemas modernos de resposta a perguntas de redes neurais têm alta precisão na extração de respostas que existem no texto e também são muito bons na classificação de textos que não possuem respostas.
Tarefas de classificação
Para tarefas comuns da PNL tradicional, como identificar nomes de pessoas ou organizações em um trecho de texto ou classificar sentimentos (positivos ou negativos) sobre um produto em um texto, os melhores sistemas atualmente ainda são ajustados com base no LPLM.
geração de texto
Além de muitos usos criativos, os sistemas generativos também podem escrever artigos de notícias estereotipados, como reportagens esportivas, resumos automatizados, etc., e também podem gerar relatórios com base nos resultados dos exames dos radiologistas.
Mas embora funcione bem, os pesquisadores ainda se perguntam se esses sistemas realmente entendem o que estão fazendo ou se são apenas reescritas complexas e sem sentido.
significado
Lingüística, filosofia da linguagem e linguagens de programação estudam métodos de descrição de significado, nomeadamente semântica denotacional ou teoria de referência: o significado de uma palavra, frase ou sentença é o significado do mundo que ela descreve. Um conjunto de objetos ou situações ( ou sua abstração matemática).
A semântica distributiva simples da PNL moderna acredita que o significado de uma palavra é apenas uma descrição de seu contexto. Manning acredita que o significado surge da compreensão da rede de conexões entre as formas da linguagem e outras coisas. Se for denso o suficiente, a forma da linguagem pode ser bem compreendido.
O sucesso do LPLM em tarefas de compreensão linguística e as amplas perspectivas de estender a aprendizagem auto-supervisionada em larga escala a outras modalidades de dados, como visão, robótica, gráficos de conhecimento, bioinformática e dados multimodais, tornam a IA mais geral.
modelo básico
Além dos primeiros modelos básicos, como BERT e GPT-3, os modelos de linguagem também podem ser conectados com redes neurais de gráficos de conhecimento, dados estruturados ou outros dados sensoriais podem ser obtidos para alcançar a aprendizagem multimodal, como o modelo DALL-E Após a aprendizagem auto-supervisionada de um corpus de imagens e textos emparelhados, o significado do novo texto pode ser expresso através da geração de imagens correspondentes.
Ainda estamos nos primórdios do desenvolvimento de modelos básicos, mas no futuro a maioria das tarefas de processamento e análise de informações, mesmo tarefas como controle de robôs, poderão ser realizadas por relativamente poucos modelos básicos.
Embora o treinamento de modelos de base grandes seja caro e demorado, uma vez concluído o treinamento, é muito fácil adaptá-lo a diferentes tarefas, e a saída do modelo pode ser ajustada diretamente usando linguagem natural.
Mas esta abordagem também apresenta riscos:
1. O poder e a influência de que gozam as instituições capazes de formar modelos básicos podem ser demasiado grandes;
2. Um grande número de usuários finais pode sofrer preconceitos durante o treinamento do modelo;
3. Como o modelo e seus dados de treinamento são muito grandes, é difícil avaliar se é seguro usar o modelo em um ambiente específico.
Embora estes modelos possam, em última análise, compreender apenas vagamente o mundo e careçam de capacidades de raciocínio lógico ou causal cuidadoso a nível humano, a ampla validade dos modelos básicos também significa que há muitos cenários que podem ser aplicados e que podem ser desenvolvidos em modelos reais dentro a próxima década.Inteligência artificial geral.
Referências:
https://direct.mit.edu/daed/article/151/2/127/110621/Human-Language-Understanding-amp-Reasoning
Entre no grupo de PNL—> Junte-se ao grupo de intercâmbio de PNL