De: Coração da Máquina
Entre no grupo de PNL—> Junte-se ao grupo de intercâmbio de PNL
O treinamento e o ajuste fino de modelos grandes exigem altos requisitos de memória de vídeo, e o estado do otimizador é um dos principais gastos da memória de vídeo. Recentemente, a equipe de Zhu Jun e Chen Jianfei da Universidade Tsinghua propôs um otimizador de 4 bits para treinamento de rede neural, que economiza sobrecarga de memória no treinamento do modelo e pode atingir uma precisão comparável à de um otimizador de precisão total.
O otimizador de 4 bits foi testado em diversas tarefas de pré-treinamento e ajuste fino e pode reduzir a sobrecarga de memória do ajuste fino do LLaMA-7B em até 57%, mantendo a precisão.
Artigo: https://arxiv.org/abs/2309.01507
Código: https://github.com/thu-ml/low-bit-optimizers
Gargalo de memória no treinamento de modelo
Do GPT-3, Gopher ao LLaMA, tornou-se um consenso da indústria que modelos grandes têm melhor desempenho. No entanto, em contraste, o tamanho da memória de vídeo de uma única GPU cresceu lentamente, o que torna a memória de vídeo o principal gargalo para o treinamento de modelos grandes.Como treinar modelos grandes com memória GPU limitada tornou-se um problema importante.
Para fazer isso, primeiro precisamos identificar as fontes de consumo de memória de vídeo. Na verdade, existem três tipos de fontes, a saber:
1. "Memória de dados" inclui os dados de entrada e o valor de ativação gerado por cada camada da rede neural. Seu tamanho é diretamente afetado pelo tamanho do lote e pela resolução da imagem/comprimento do contexto;
2. "Memória do modelo", incluindo parâmetros do modelo, gradientes e estados do otimizador, seu tamanho é proporcional ao número de parâmetros do modelo;
3. "Memória de vídeo temporária" inclui memória temporária e outros caches usados nos cálculos do kernel da GPU. À medida que o tamanho do modelo aumenta, a proporção da memória de vídeo do modelo aumenta gradualmente, tornando-se um grande gargalo.
O tamanho do estado do otimizador é determinado pelo otimizador usado. Atualmente, o otimizador AdamW é frequentemente utilizado para treinar Transformers, que precisam armazenar e atualizar dois estados do otimizador durante o processo de treinamento, ou seja, primeiro e segundo momentos. Se o número de parâmetros do modelo for N, então o número de estados do otimizador no AdamW será 2N, o que obviamente representa uma enorme sobrecarga de memória gráfica.
Tomando LLaMA-7B como exemplo, o número de parâmetros deste modelo é de cerca de 7 B. Se o otimizador AdamW de precisão total (32 bits) for usado para ajustá-lo, o tamanho da memória de vídeo ocupada pelo estado do otimizador tem cerca de 52,2 GB. Além disso, embora o otimizador SGD ingênuo não exija estados adicionais e economize a memória ocupada pelo estado do otimizador, o desempenho do modelo é difícil de garantir. Portanto, este artigo se concentra em como reduzir o estado do otimizador na memória do modelo e, ao mesmo tempo, garantir que o desempenho do otimizador não seja comprometido.
Maneiras de economizar memória do otimizador
Atualmente, em termos de algoritmos de treinamento, existem três métodos principais para economizar a sobrecarga de memória do otimizador:
1. Realizar aproximação de baixo posto no estado do otimizador através da ideia de decomposição de baixo posto (Fatorização);
2. Evite salvar a maioria dos estados do otimizador treinando apenas um pequeno conjunto de parâmetros, como LoRA;
3. Um método baseado em compressão que utiliza um formato numérico de baixa precisão para representar o status do otimizador.
Em particular, Dettmers et al. (ICLR 2022) propuseram um otimizador correspondente de 8 bits para SGD com momentum e AdamW, usando quantização em bloco e técnicas de formato numérico exponencial dinâmico. , alcançando resultados que correspondem ao otimizador de precisão total original em tarefas como modelagem de linguagem, classificação de imagens, aprendizagem autossupervisionada e tradução automática.
Com base nisso, este artigo reduz ainda mais a precisão numérica do estado do otimizador para 4 bits, propõe um método de quantização para diferentes estados do otimizador e, finalmente, propõe um otimizador AdamW de 4 bits. Ao mesmo tempo, este artigo explora a possibilidade de combinar métodos de compressão e decomposição de baixa classificação e propõe um otimizador de fator de 4 bits.Este otimizador híbrido desfruta de bom desempenho e melhor eficiência de memória. Este artigo avalia o otimizador de 4 bits em uma série de tarefas clássicas, incluindo compreensão de linguagem natural, classificação de imagens, tradução automática e ajuste fino de instruções de modelos grandes.
Em todas as tarefas, o otimizador de 4 bits alcança desempenho comparável ao otimizador de precisão total, ocupando menos memória.
Configuração de perguntas
Uma estrutura para otimizadores com eficiência de memória baseados em compactação
Primeiro, precisamos entender como introduzir operações de compressão em otimizadores comumente usados, o que é fornecido pelo Algoritmo 1. onde A é um otimizador baseado em gradiente (como SGD ou AdamW). O otimizador insere os parâmetros existentes w, gradiente ge estado do otimizador s e gera novos parâmetros e estado do otimizador. No Algoritmo 1, o s_t de precisão total existe temporariamente, enquanto o de baixa precisão (s_t ) ̅ será persistido na memória da GPU. A razão importante pela qual esse método pode economizar memória de vídeo é que os parâmetros das redes neurais são frequentemente unidos a partir dos vetores de parâmetros de cada camada. Portanto, a atualização do otimizador também é realizada camada por camada/tensor. No Algoritmo 1, o estado do otimizador de no máximo um parâmetro é deixado na memória na forma de precisão total, e os estados do otimizador correspondentes às outras camadas estão em um formato compactado. estado. .

Método de compressão principal: quantização
A quantização é uma tecnologia que utiliza valores numéricos de baixa precisão para representar dados de alta precisão. Este artigo separa a operação de quantização em duas partes: normalização e mapeamento, o que permite um design mais leve e a experimentação de um novo método de quantificação. As duas operações de normalização e mapeamento são aplicadas sequencialmente nos dados de precisão total de maneira elemento a elemento. A normalização é responsável por projetar cada elemento do tensor para o intervalo unitário, onde a normalização do tensor (normalização por tensor) e a normalização por bloco (normalização por bloco) são definidas da seguinte forma:

Diferentes métodos de normalização têm granularidades diferentes, sua capacidade de lidar com valores discrepantes será diferente e também trarão diferentes sobrecargas de memória adicionais. A operação de mapeamento é responsável por mapear valores normalizados para inteiros que podem ser representados com baixa precisão. Formalmente falando, dada uma largura de bits b (ou seja, cada valor é representado por b bits após a quantização) e uma função predefinida T

A operação de mapeamento é definida como:
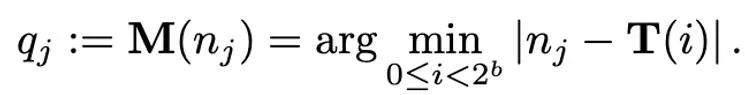
Portanto, como projetar um T apropriado desempenha um papel muito importante na redução do erro de quantização. Este artigo considera principalmente o mapeamento linear (linear) e o mapeamento exponencial dinâmico (expoente dinâmico). Finalmente, o processo de desquantização consiste em aplicar os operadores inversos de mapeamento e normalização em sequência.
Método de compressão de momento de primeira ordem
A seguir são propostos principalmente diferentes métodos de quantização para o estado do otimizador (momento de primeira ordem e momento de segunda ordem) de AdamW. Para momentos de primeira ordem, o método de quantização neste artigo é baseado principalmente no método de Dettmers et al.(ICLR 2022), usando normalização de bloco (o tamanho do bloco é 2048) e mapeamento exponencial dinâmico.
Em experimentos preliminares, reduzimos diretamente a largura de bits de 8 para 4 bits e descobrimos que o momento de primeira ordem é muito robusto à quantização e alcançou efeitos de correspondência em muitas tarefas, mas também sofreu perdas de desempenho em algumas tarefas. Para melhorar ainda mais o desempenho, estudamos cuidadosamente o padrão dos primeiros momentos e descobrimos que existem muitos valores discrepantes em um único tensor.
Trabalhos anteriores fizeram algumas pesquisas sobre padrões discrepantes de parâmetros e valores de ativação.A distribuição dos parâmetros é relativamente suave, enquanto os valores de ativação têm as características da distribuição do canal. Este artigo descobriu que a distribuição de valores discrepantes no estado do otimizador é complexa, com alguns tensores tendo valores discrepantes distribuídos em linhas fixas e outros tensores tendo valores discrepantes distribuídos em colunas fixas.
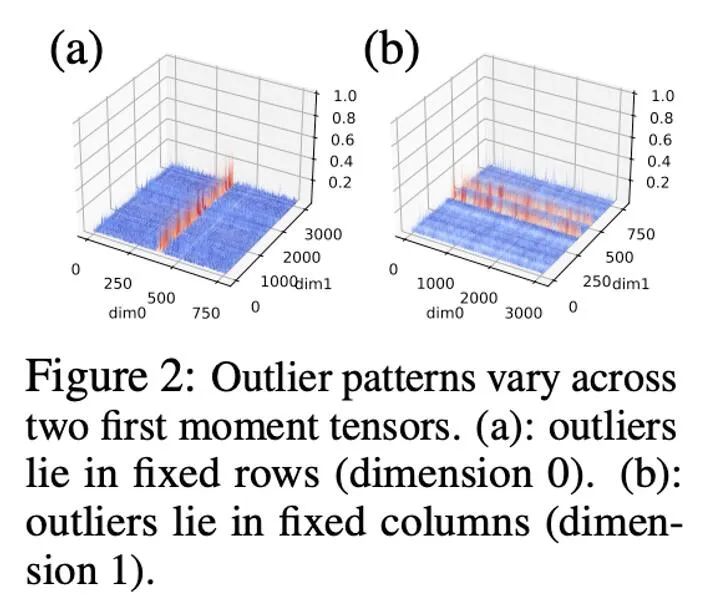
Para tensores com distribuição de outliers em colunas, a normalização do primeiro bloco de linha pode encontrar dificuldades. Portanto, este artigo propõe a utilização de blocos menores, com tamanho de bloco de 128, o que pode reduzir o erro de quantização enquanto mantém o overhead de memória adicional dentro de uma faixa controlável. A figura abaixo mostra o erro de quantização para diferentes tamanhos de bloco.

Método de compressão de momento de segunda ordem
Comparado com o momento de primeira ordem, a quantificação do momento de segunda ordem é mais difícil e trará instabilidade ao treinamento. Este artigo determina que o problema do ponto zero é o principal gargalo na quantificação de momentos de segunda ordem.Além disso, um método de normalização aprimorado é proposto para distribuições de outliers mal condicionadas: normalização de posto 1. Este artigo também tenta o método de decomposição (fatoração) do momento de segunda ordem.
Problema de ponto zero
Na quantização de parâmetros, valores de ativação e gradientes, o ponto zero é muitas vezes indispensável e também é o ponto com maior frequência após a quantização. No entanto, na fórmula iterativa de Adam, o tamanho da atualização é proporcional à potência -1/2 do segundo momento, portanto, alterá-lo na faixa próxima de zero afetará muito o tamanho da atualização, causando instabilidade.
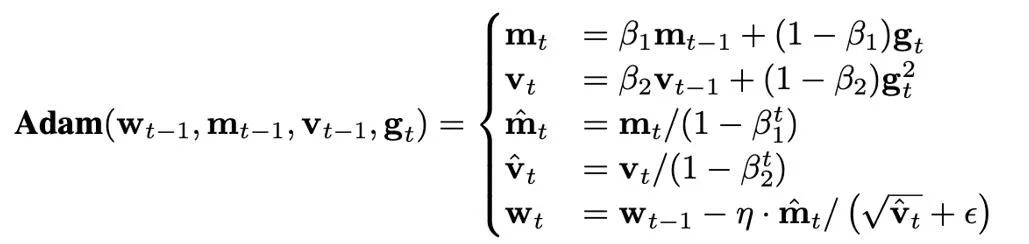
A figura abaixo mostra a distribuição do segundo momento de Adam -1/2 potência antes e depois da quantização na forma de histograma, ou seja, h (v)=1/(√v+10^(-6) ). Se os zeros forem incluídos (Figura b), a maioria dos valores será aumentada para 10 ^ 6, resultando em grandes erros de aproximação. Uma solução simples é remover os zeros do mapa exponencial dinâmico, após fazer isso (figura c), a aproximação ao segundo momento torna-se mais precisa. Em situações reais, para utilizar de forma eficaz a capacidade expressiva de valores numéricos de baixa precisão, propusemos a utilização de um mapeamento linear que remove pontos zero, e obtivemos bons resultados em experimentos.

Normalização de classificação 1
Com base na complexa distribuição de outliers de momentos de primeira ordem e momentos de segunda ordem, e inspirado no otimizador SM3, este artigo propõe um novo método de normalização denominado normalização de classificação 1. Para um tensor de matriz não negativo x∈R^(n×m), sua estatística unidimensional é definida como:

Então a normalização de classificação 1 pode ser definida como:

A normalização de classificação 1 explora as informações unidimensionais do tensor de uma forma mais refinada e pode lidar com valores discrepantes em linhas ou colunas de maneira mais inteligente e eficiente. Além disso, a normalização de classificação 1 pode ser facilmente generalizada para tensores de alta dimensão e, à medida que o tamanho do tensor aumenta, a sobrecarga de memória adicional que ele gera é menor do que a normalização de bloco.
Além disso, este artigo descobriu que o método de decomposição de baixo escalão para momentos de segunda ordem no otimizador Adafactor pode efetivamente evitar o problema do ponto zero, portanto, a combinação de métodos de decomposição e quantização de baixo escalão também foi explorada. A figura abaixo mostra uma série de experimentos de ablação para momentos de segunda ordem, o que confirma que o problema do ponto zero é o gargalo da quantificação de momentos de segunda ordem. Também verifica a eficácia dos métodos de normalização de classificação 1 e decomposição de classificação baixa.

Resultados experimentais
Com base nos fenômenos observados e métodos de uso, o estudo finalmente propôs dois otimizadores de baixa precisão: AdamW de 4 bits e Fator de 4 bits, e os comparou com outros otimizadores, incluindo AdamW de 8 bits, Adafactor e SM3. Os estudos foram selecionados para avaliação em uma ampla gama de tarefas, incluindo compreensão de linguagem natural, classificação de imagens, tradução automática e ajuste fino de instruções de grandes modelos. A tabela abaixo mostra o desempenho de cada otimizador em diferentes tarefas.

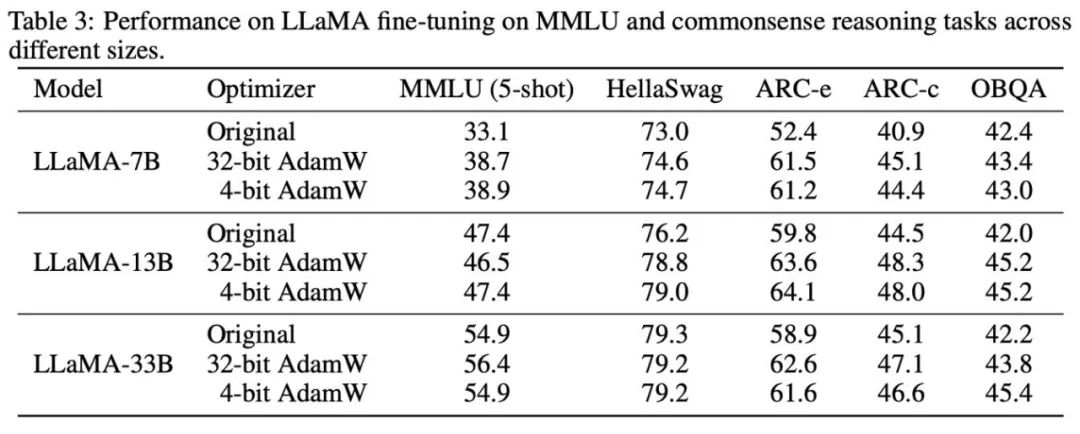
Pode-se observar que em todas as tarefas de ajuste fino, incluindo NLU, QA e NLG, o otimizador de 4 bits pode igualar ou até mesmo exceder o AdamW de 32 bits. Ao mesmo tempo, em todas as tarefas de pré-treinamento, CLS, MT e o otimizador de 4 bits atingem o mesmo nível que o AdamW completo de 32 bits. Nível de precisão comparável. Pode-se observar na tarefa de ajuste fino da instrução que o AdamW de 4 bits não destrói a capacidade dos modelos pré-treinados e, ao mesmo tempo, pode capacitá-los melhor para obter a capacidade de cumprir as instruções.
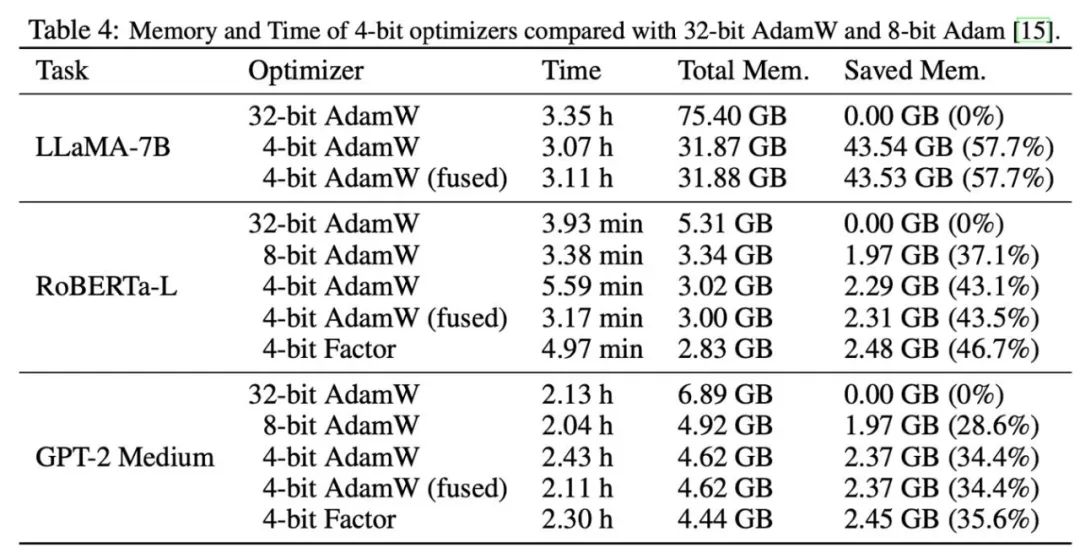
Depois disso, testamos a memória e a eficiência computacional do otimizador de 4 bits, e os resultados são mostrados na tabela abaixo. Comparado com o otimizador de 8 bits, o otimizador de 4 bits proposto neste artigo pode economizar mais memória, com uma economia máxima de 57,7% no experimento de ajuste fino LLaMA-7B. Além disso, fornecemos uma versão do operador de fusão de 4 bits do AdamW, que pode economizar memória sem afetar a eficiência computacional. Para a tarefa de ajuste fino de instruções do LLaMA-7B, o AdamW de 4 bits também traz efeitos de aceleração ao treinamento devido à redução da pressão do cache. Configurações experimentais detalhadas e resultados podem ser encontrados no link do artigo.
Substitua uma linha de código para usar no PyTorch
import lpmm
optimizer = lpmm.optim.AdamW (model.parameters (), lr=1e-3, betas=(0.9, 0.999))Fornecemos um otimizador de 4 bits pronto para uso. Você só precisa substituir o otimizador original por um otimizador de 4 bits. Atualmente, versões de baixa precisão do Adam e do SGD são suportadas. Ao mesmo tempo, também fornecemos uma interface para modificar parâmetros de quantização para suportar cenários de uso personalizados.
Entre no grupo de PNL—> Junte-se ao grupo de intercâmbio de PNL