De modo geral, a relação entre redes neurais e big data é muito complexa e os fatores que influenciam incluem: tamanho do modelo, tamanho do conjunto de dados, desempenho da computação e outros fatores, como mão de obra, tempo, etc. O conteúdo existente está organizado da seguinte forma:
1. Volume de dados versus desempenho da rede
1. Visão Geral
Em "Revisiting Unreasonable Effectiveness of Data in Deep Learning Era", Sun e outros atribuíram o sucesso significativo da tecnologia de visão computacional nos últimos 10 anos a: 1> modelos mais complexos, 2> melhorias no desempenho da computação [ Referência 1 , Referência 2 ], 3> O surgimento de conjuntos de dados rotulados em grande escala.
Em relação à primeira questão, podemos ver melhorias no desempenho computacional e na complexidade do modelo a cada ano, desde o AlexNet de 7 camadas em 2017 até o ResNet de 101 camadas em 2015, e agora a tecnologia Transformer com um maior número de parâmetros.
Para a segunda pergunta, você pode consultar 1 e 2. Em geral, os pesquisadores descobriram que ao atualizar a GPU todos os anos, a melhoria de desempenho proporcionada pela melhoria do desempenho da GPU é ainda maior do que a atualização do próprio modelo. O poderoso poder de computação trazido pela nova GPU pode tornar a inferência de modelos mais rápida e eficiente.
Em relação à terceira questão, todos sabemos que o aprendizado profundo é baseado em dados. Portanto, se o conjunto de treinamento for expandido 10 ou 100 vezes, a precisão dobrará? Existe um gargalo? O que se segue centra-se nesta questão.
2. Objectivos da investigação

O artigo aponta que nos últimos anos o tamanho do modelo e o desempenho da GPU melhoraram, mas o conjunto de dados não, então eles construíram um conjunto de dados de 300 milhões de imagens para verificação experimental. Seus objetivos de pesquisa são:
1) Usando o algoritmo atual, se mais e mais imagens com rótulos ruidosos forem fornecidas, se o desempenho visual ainda pode ser otimizado;
2) Para tarefas de visão padrão, como classificação, detecção de objetos e segmentação de imagens, qual é a relação entre dados e desempenho;
3) Utilizar tecnologia de aprendizagem em larga escala para desenvolver modelos de última geração capazes de realizar diversas tarefas no campo da visão computacional.
3. Construção de dados
O problema está em como construir o conjunto de dados. Felizmente, o Google tem trabalhado duro para construir esses conjuntos de dados para otimizar algoritmos de visão computacional. Com os esforços de Geoff Hinton, François Chollet e outros, o Google construiu internamente um conjunto de dados contendo 300 milhões de imagens, rotulou as imagens em 18.291 categorias e nomeou-o JFT-300M (não de código aberto).
A marcação de imagens do conjunto de dados usa um algoritmo que combina sinais de rede brutos complexos com correlações entre páginas da web e feedback do usuário. Através deste método, estas 300 milhões de imagens receberam mais de 1 bilhão de tags (uma imagem pode ter múltiplas tags). Desses 1 bilhão de tags, aproximadamente 375 milhões foram selecionadas algoritmicamente para maximizar a precisão das tags das imagens selecionadas. Porém, ainda há ruído nesses rótulos: cerca de 20% dos rótulos das imagens selecionadas são ruídos. Simplificando, quanto maior a quantidade de dados, maior será o ruído e mais difícil será treinar o modelo.
4. Principais Resultados Experimentais
O autor obteve alguns resultados através de verificação experimental:
* Uma melhor aprendizagem de representação pode ajudar .
A primeira observação que fazemos é que dados em grande escala facilitam o aprendizado de representação que otimiza o desempenho em todas as tarefas de visão que estudamos. Nossas descobertas demonstram a importância de construir conjuntos de dados em grande escala para pré-treinamento. Isso também mostra que os métodos de aprendizagem de representação não supervisionada e de aprendizagem de representação semissupervisionada têm boas perspectivas. Parece que o tamanho dos dados continua a suprimir o ruído presente nos rótulos.
* À medida que a magnitude dos dados de treinamento aumenta, o desempenho da tarefa aumenta logaritmicamente.
Talvez a descoberta mais surpreendente seja a relação entre o desempenho visual da tarefa e o aprendizado do desempenho no logaritmo da quantidade de dados de treinamento. Descobrimos que a relação ainda é linear. Mesmo que o tamanho da imagem de treinamento chegue a 300 milhões, não observamos nenhuma estagnação na melhoria do desempenho. Como mostrado abaixo:

* A capacidade do modelo é crítica.
Observamos que se quisermos utilizar totalmente o conjunto de dados de 300 milhões de imagens, precisaremos de modelos maiores (mais profundos).
Por exemplo, com o ResNet-50, o aumento na pontuação de detecção de objetos COCO é muito limitado, apenas 1,87%, enquanto com o ResNet-152, esse aumento na pontuação chega a 3%.
* Treinamento de cauda longa.
Nossos dados têm caudas muito longas, mas o aprendizado da representação parece funcionar. Esta cauda longa não parece afetar negativamente o treinamento aleatório de ConvNets (o treinamento ainda convergirá).
* Novos resultados de última geração.
Nosso artigo usa JFT-300M para treinar o modelo, e muitas pontuações atingiram o nível mais alto da indústria. Por exemplo, para a pontuação de detecção de objetos COCO, um único modelo pode atingir atualmente 37,4 AP, acima dos 34,3 AP anteriores.
Deve-se ressaltar que o sistema de treinamento, o progresso do aprendizado e os parâmetros que utilizamos são baseados na experiência anterior adquirida no treinamento de ConvNets com imagens ImageNet 1M.
Como não exploramos hiperparâmetros ótimos neste trabalho (o que exigiria um esforço computacional considerável), é possível que ainda não tenhamos alcançado os melhores resultados possíveis com o treinamento com este conjunto de dados. Acreditamos, portanto, que os relatórios quantitativos de desempenho podem subestimar o impacto real neste conjunto de dados.
Este trabalho não se concentrou em dados específicos de tarefas, como estudar se mais caixas delimitadoras afetam o desempenho do modelo. Acreditamos que, apesar dos desafios, a obtenção de conjuntos de dados em larga escala para tarefas específicas deve ser um foco de pesquisas futuras.
Além disso, construir um conjunto de dados contendo 300 milhões de imagens não é o objetivo final. Devemos explorar se o modelo pode continuar a melhorar com um conjunto de dados maior (mais de 1 bilhão de imagens).
5. Outros resultados experimentais

* O ajuste fino dos pesos pré-treino é muito importante
2. Pesos pré-treino VS desempenho
1. Visão Geral
Os pesquisadores do Google publicaram um artigo chamado BigTransfer, "Big Transfer (BiT): General Visual Representation Learning" , que explora como usar efetivamente a escala de dados de imagem superconvencional para pré-treinar o modelo e conduzir sistematicamente o processo de treinamento. Pesquisa profunda.
Para explorar o impacto da escala de dados no desempenho do modelo, eles revisitaram as configurações de pré-treinamento comumente usadas atualmente (incluindo funções de ativação e normalização de pesos, largura e profundidade do modelo e estratégias de treinamento), utilizando três escalas diferentes de dados. Os conjuntos incluem: ILSVRC-2012 (1,28 milhão de imagens em 1.000 categorias), ImageNet-21k (14 milhões de imagens em 21.000 categorias) e JFT (300 milhões de imagens em 18.000 categorias). Mais importante ainda, os pesquisadores com base nesses dados podem ser explorados anteriormente escalas de dados inexploradas.
2. Conteúdo de pesquisa
* A relação entre o tamanho do conjunto de dados e a capacidade do modelo
Os autores escolheram diferentes variantes do ResNet para treinamento. Do tamanho padrão "R50x1" à largura x4, até o mais profundo "R152x4" de 152 camadas, todos foram treinados no conjunto de dados acima. Os pesquisadores fizeram então a descoberta fundamental de que, se quiserem aproveitar ao máximo o big data, também deverão aumentar a capacidade do modelo.

A metade esquerda mostra a necessidade de expandir a capacidade do modelo à medida que a quantidade de dados aumenta.A expansão da seta vermelha significa que a arquitetura do modelo pequeno se deteriora sob grandes conjuntos de dados, enquanto a arquitetura do modelo grande melhora. A figura à direita mostra que o pré-treinamento em um grande conjunto de dados não melhora necessariamente, mas requer maior tempo de treinamento e sobrecarga computacional para aproveitar ao máximo o big data.
O tempo de treinamento também desempenha um papel crítico no desempenho do modelo. Se não for realizado treinamento suficiente em um conjunto de dados em grande escala para ajustar a sobrecarga computacional, o desempenho cairá significativamente (metade dos pontos vermelhos para os pontos azuis na figura acima diminuirão), mas pode ser obtido ajustando adequadamente o tempo de treinamento do modelo. Melhorias significativas de desempenho.
* BN normalizado apropriado pode efetivamente melhorar o desempenho
1> Substituir BN normalizado em lote por GN normalizado em grupo pode efetivamente melhorar o desempenho do modelo pré-treinado em conjuntos de dados de grande escala.As razões vêm principalmente de dois aspectos:
- Primeiro, o estado do BN precisa ser ajustado ao migrar do pré-treinamento para a tarefa alvo, mas o GN é apátrida, evitando assim a dificuldade de ajuste;
- Em segundo lugar, o BN utiliza as estatísticas de cada lote, mas essas estatísticas tornam-se pouco confiáveis para pequenos lotes em cada dispositivo, e o treinamento em vários dispositivos é inevitável para modelos grandes. Como a GN não precisa calcular estatísticas para cada lote, mais uma vez evita esse problema com sucesso;
* Transferir aprendizagem
Com base nos métodos usados na construção do BERT, os pesquisadores ajustaram o modelo BiT em uma série de tarefas posteriores. Apenas dados muito limitados foram usados no processo de ajuste. O modelo pré-treinado já possui uma boa compreensão dos recursos visuais.

Tamanho dos dados, ILSVRC < ImageNet < JFT-300M. Ao usar muito poucas amostras para realizar a aprendizagem por transferência no BiT, os pesquisadores descobriram que à medida que a quantidade de dados e a capacidade da arquitetura usada no processo de pré-treinamento aumentavam, o desempenho do modelo migrado resultante aumentava. também aumentou significativamente. Ao aumentar a capacidade do modelo no conjunto de dados menor ILSVRC, os ganhos obtidos pela migração do CIFAR são menores nos casos de 1 e 5 disparos (linha verde na figura abaixo). Ao pré-treinar no conjunto de dados JFT em grande escala, o aumento na capacidade do modelo trará ganhos significativos (mostrados pela linha vermelha-marrom).O BiT-L pode atingir 64% e 95% em amostras únicas e cinco amostras. Precisão .
3. Conclusão
Este estudo descobriu que, sob o treinamento de dados gerais em grande escala, uma estratégia de migração simples pode alcançar resultados impressionantes, seja ela baseada em big data, dados de amostra pequena ou mesmo dados de amostra única, por meio de modelos pré-treinados em grande escala em downstream tarefas podem alcançar melhorias significativas de desempenho. Os modelos pré-treinados do BiT fornecerão aos pesquisadores de visão uma nova alternativa aos modelos pré-treinados do ImageNet.
Três, duas excelentes respostas de Zhihu
1. Ângulo 1
Recomenda-se ler atentamente a Seção 3.2 do livro clássico PRML (é claro, para entender 3.2, você deve ler primeiro o Capítulo 1), que explica em detalhes o que acontecerá quando a quantidade de dados aumentar . As principais conclusões são as seguintes:
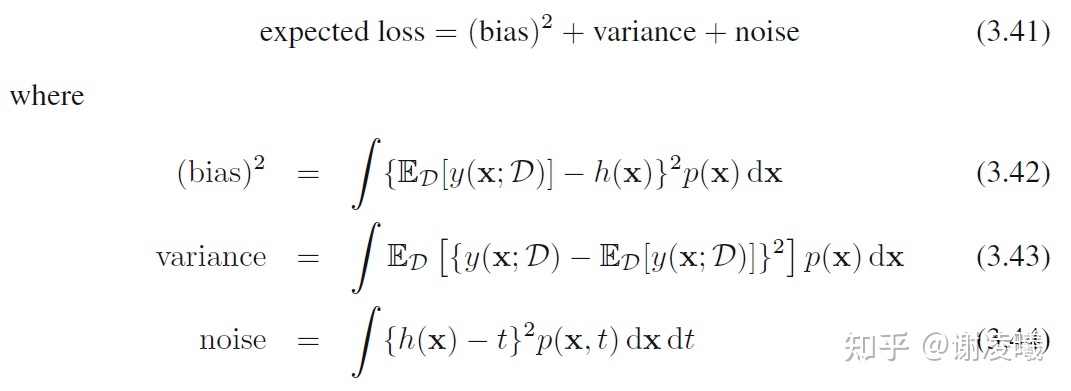
Quando a quantidade de dados é fixa, há um equilíbrio entre viés e variância: quando um aumenta, o outro diminui. À medida que a quantidade de dados aumenta, a soma destes dois termos pode ser ainda mais reduzida, mas o termo ruído não pode ser eliminado.
Portanto, este problema tem as seguintes conclusões simples e preliminares:
- Se a quantidade de dados for ilimitada e anotada com precisão, então, em teoria, o modelo de aprendizado de máquina pode se ajustar a uma função perfeita, desde que o modelo tenha complexidade e precisão suficientes. A propósito, cenários de dados infinitamente precisos são possíveis, como o uso de um mecanismo virtual para gerar dados. Neste momento, embora um modelo não possa usar dados ilimitados em um tempo limitado, à medida que o treinamento avança, a quantidade de dados pode se tornar infinita.
- Se a quantidade de dados for ilimitada, mas não rotulada com precisão, a precisão do modelo final será limitada pelo ruído do rótulo.
- Se a quantidade de dados for limitada, o modelo deve fazer uma compensação entre viés e variância: para fazer o modelo funcionar de forma estável em uma ampla gama de dados de teste (a variância é pequena), a precisão geral da previsão do modelo diminuirá (o viés é grande); para que o modelo tenha um bom desempenho em algum subconjunto de dados de teste (com um pequeno viés), o modelo deve sacrificar a precisão em outros dados de teste possíveis.
2. Ângulo 2
Em particular, quando você tem dados de treinamento suficientes, o erro de generalização provavelmente será muito pequeno. Isso pode ser concluído a partir da teoria clássica do aprendizado de máquina:
Se for um espaço finito e 0 <<
1, então para qualquer
:
onde m representa o número de dados de treinamento. Quando m tende ao infinito, ou seja, há amostras de treinamento suficientes, e a diferença entre o classificador aprendido e o classificador ideal
torna-se menor com o passar do tempo. Na fórmula acima, significa que a diferença entre os dois é menor que um, o que é particularmente pequeno.A probabilidade do número ser maior que
, ou seja, a probabilidade de isso acontecer é muito alta.
Novamente, essa rede se ajustará demais? Overfitting é uma questão importante no campo do aprendizado de máquina e está intimamente relacionado à estrutura da rede, método de treinamento, dificuldade dos dados, etc. Por exemplo, se você tem uma grande quantidade de dados, mas são quase iguais (a similaridade entre os dados é alta), então a rede está realmente inadequada, porque os dados no mundo real são mais complexos; de outra perspectiva extrema , se você Os dados não são apenas grandes, mas também diferentes, o que obviamente levará a um ajuste excessivo.
Finalmente, quando a quantidade de dados é enorme, a rede pode ficar saturada. Mas, como na pergunta anterior, ainda depende da qualidade dos seus dados. Idealmente, se uma rede for usada para acomodar todos os dados conhecidos no mundo, então é claro que ela ficará saturada.
Nota: É mencionado na teoria acima que o espaço de hipóteses é limitado. Mas não podemos ter certeza se o espaço de hipóteses é realmente limitado quando há muitos dados de treinamento, então ainda não podemos responder a esta questão. Afinal, o aprendizado de máquina é uma ciência baseada em dados.
4. Pensamento pessoal:
Volume de dados, pesos de modelos pré-treinados, qualidade de dados, capacidade da rede neural
Quanto mais dados, melhor será a previsão, mas quando o tamanho da amostra de treinamento for grande, se houver poucas camadas de rede e treinamento de recursos insuficiente, isso levará a um treinamento insuficiente. Portanto, quanto maior o conjunto de dados, melhor será o efeito.Um dos pré-requisitos é que a capacidade de extração de recursos da rede não possa ser muito baixa (problema de capacidade da rede neural).
Quanto maior a quantidade de dados, maior será a exigência do tamanho da amostra, e a qualidade dos dados precisa ser melhorada, pois não pode conter muito ruído e dados semelhantes, o que terá um impacto negativo no aprendizado da rede.
Os pesos dos modelos pré-treinados em grandes conjuntos de dados têm bons efeitos de transferência em outros conjuntos de dados.
referência:
https://blog.csdn.net/emprere/article/details/98858910