Diretório de artigos
Prefácio
Anteriormente, apresentamos as estruturas de computação de big data Hadoop e Spark, respectivamente. Embora alguns deles tenham bons sistemas de arquivos distribuídos e mecanismos de computação distribuídos, e alguns tenham conjuntos de dados distribuídos e mecanismos de computação distribuídos baseados em memória, eles não podem lidar com eles. Os fluxos de dados de limite são efetivamente processado. Hoje compartilharemos uma introdução e análise da arquitetura do Flink, uma estrutura de computação distribuída de big data de quarta geração, e construiremos um ambiente operacional básico.
Introdução ao Flink
Apache Flink é uma estrutura e mecanismo de processamento distribuído para computação com estado em fluxos de dados ilimitados e limitados. O Flink é executado em todos os ambientes de cluster comuns e pode computar na velocidade da memória e em qualquer escala.
Os programas Stateful Flink são otimizados para acesso estadual local. O estado de uma tarefa é sempre mantido na memória ou, se o tamanho do estado exceder a memória disponível, ele é mantido em uma estrutura de dados em disco que pode ser acessada de forma eficiente. As tarefas fazem todos os seus cálculos acessando o estado local (geralmente na memória), resultando em uma latência de processamento muito baixa. O Flink persiste o estado local periodicamente e de forma assíncrona para garantir a consistência do estado exatamente uma vez em cenários de falha.
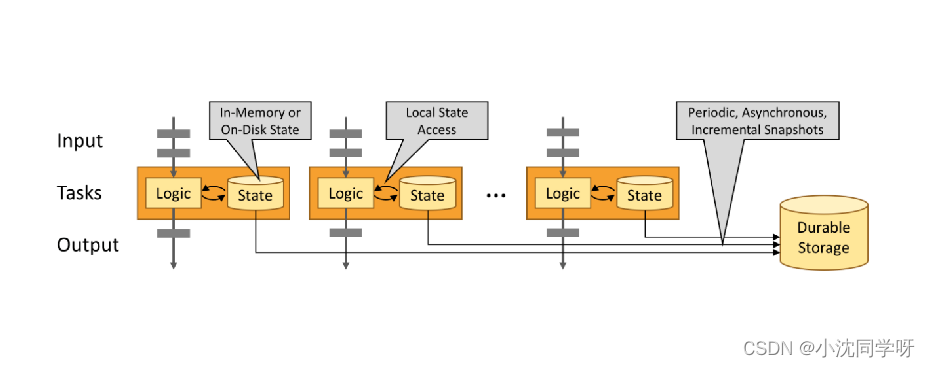
Análise de cluster Flink
O tempo de execução do Flink consiste em dois tipos de processos: um JobManager e um ou mais TaskManagers.
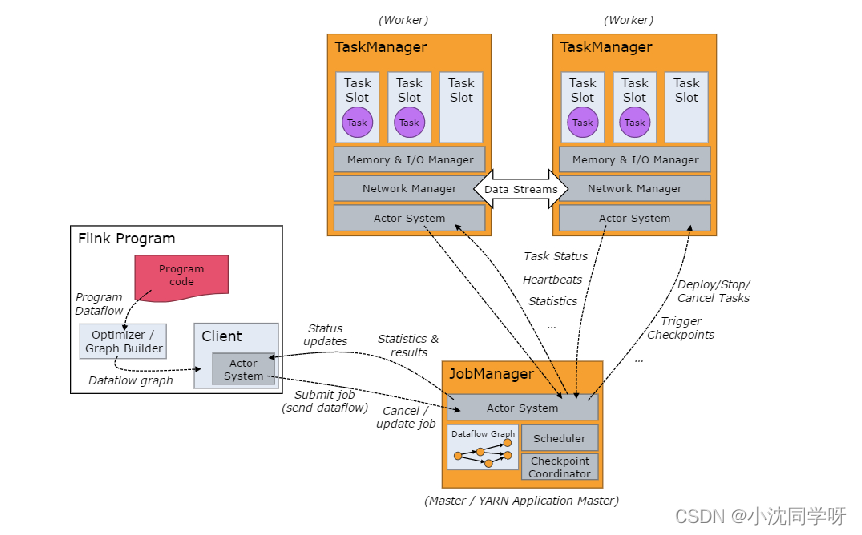
O Cliente não faz parte do tempo de execução e execução do programa, mas é utilizado para preparar o fluxo de dados e enviá-lo ao JobManager. Posteriormente, o cliente pode se desconectar (modo desanexado) ou permanecer conectado para receber relatórios de progresso (modo conectado). O cliente pode ser executado como parte de um gatilho para executar um programa Java/Scala ou pode ser executado em um processo de linha de comando ./bin/flink run….
JobManager e TaskManager podem ser iniciados de diversas maneiras: diretamente na máquina como um cluster independente, iniciados em um contêiner ou gerenciados e iniciados por meio de uma estrutura de recursos como YARN ou Mesos. TaskManagers se conectam a JobManagers, anunciam-se como disponíveis e recebem tarefas atribuídas.
Cenários de aplicação Flink
1. Aplicativos orientados
Os aplicativos orientados a eventos são um tipo de aplicativo com estado que extrai dados de um ou mais fluxos de eventos e aciona cálculos, atualizações de status ou outras ações externas com base em eventos recebidos.
Exemplos típicos de aplicativos orientados a eventos#
Antifraude
Detecção de anomalias
Alarme baseado em regras
Monitoramento de processos de negócios
(redes sociais) Aplicativo Web
2. Aplicativo de análise de dados
As tarefas de análise de dados precisam extrair informações e indicadores valiosos de dados brutos, a fim de obter as informações mais recentes dados Para resultados de análise, você deve primeiro adicioná-los ao conjunto de dados de análise e executar novamente a consulta ou executar o aplicativo e, em seguida, gravar os resultados no sistema de armazenamento ou gerar um relatório.
Exemplos típicos de aplicação de análise de dados
#Monitoramento da qualidade da rede de telecomunicações
Atualizações de produtos e análise de avaliação experimental em aplicativos móveis
Análise ad hoc de dados em tempo real em tecnologia de consumo
Análise gráfica em grande escala
3. Aplicação de pipeline de dados
Extract-Transform-Load (ETL) é um Um método comum para converter e migrar dados entre sistemas de armazenamento. Os trabalhos ETL normalmente são acionados periodicamente para copiar dados de um banco de dados transacional para um banco de dados analítico ou data warehouse.
Construção de índice de consulta em tempo real
no comércio eletrônico ETL contínuo no comércio eletrônico
Construindo o ambiente operacional básico do Flink
Instalação do Docker
Instale o docker e docker-compose e conceda permissões
docker与docker-compose安装
#安装docker社区版
yum install docker-ce
#版本查看
docker version
#docker-compose插件安装
curl -L https://github.com/docker/compose/releases/download/1.21.2/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
#可执行权限
chmod +x /usr/local/bin/docker-compose
#版本查看
docker-compose version
gravação de arquivo docker-compose
vim docker-compose-flink.yaml
version: "3.3"
services:
jobmanager:
image: registry.cn-hangzhou.aliyuncs.com/senfel/flink:1.9.2-scala_2.12
expose:
- "6123"
ports:
- "8081:8081"
command: jobmanager
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: registry.cn-hangzhou.aliyuncs.com/senfel/flink:1.9.2-scala_2.12
expose:
- "6121"
- "6122"
depends_on:
- jobmanager
command: taskmanager
links:
- "jobmanager:jobmanager"
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
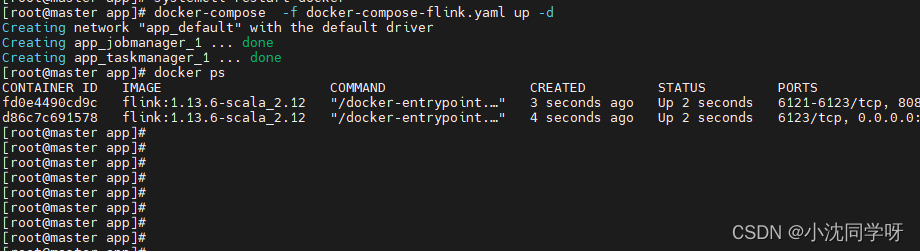
Crie e execute o contêiner
docker-compose -f docker-compose-flink.yaml up -d
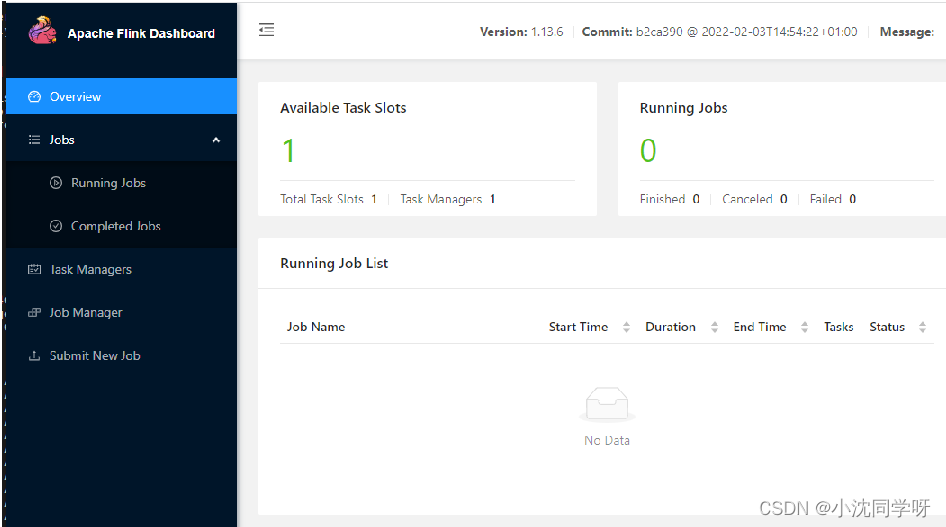
Acesse a interface web do Flink
ip:8081