Tenho feito trabalhos relacionados à detecção recentemente e analisei o código e os documentos do fast-rcnn há alguns anos. Agora, vamos analisar o modelo mais recente e mais rápido, o yolov5. Esta série começará com a história de desenvolvimento do Yolo, até o conceito de função de perda, mAP e, finalmente, como treinar seu conjunto de dados personalizado no nível do código. Ok, vamos começar ~
1. História de desenvolvimento do YOLO (You Only Look Once)
Esta parte do conteúdo foi emprestada principalmente do artigo postado pela fera da tecnologia @Zhihu em Zhihu. Vou simplificá-lo aqui. Leia este artigo para obter detalhes específicos
[1-3].
1.1 YOLO v0
A ideia do YOLO v0 originou-se da extensão da ideia básica da CNN das tarefas de classificação à detecção.Então, primeiro, vamos dar uma olhada na diferença entre tarefas de detecção e tarefas de classificação:
- Detecção : A saída da rede deve ser as coordenadas da caixa delimitadora (caixa retangular) (representada por pelo menos 4 números, existem 2 comuns: (x1, y1, x2, y2), (x1, y1, w, h)). Quanto ao motivo pelo qual uma moldura retangular é usada, é porque, em comparação com círculos e outras formas de polígonos, as propriedades geométricas da moldura retangular a tornam mais adequada para enquadrar o objeto alvo com custo mínimo de redundância adicional.

- Classificação : Tomemos como exemplo a tarefa de classificação única mais básica. Classificação única significa que o objeto pertence apenas a uma categoria. A característica desta tarefa é que a entrada é uma imagem e a saída é sua categoria. Para a imagem de entrada, geralmente usamos um Tensor para representá-la, e sua forma é [N, C, H, W]. Para o resultado de saída, geralmente usamos um vetor one-hot para representar: [0, 0, 0, 1] [0, 0, 0, 1][ 0 ,0 ,0 ,1 ] , cuja dimensão é 1, representa a qual categoria a imagem pertence.
Ok, depois de conhecer a diferença básica entre classificação e detecção, podemos considerar a tarefa de detecção como uma tarefa de classificação ergódica (ou seja, detecção de múltiplos alvos; se for determinado que uma detecção de alvo único em uma imagem tem no máximo 1 alvo, então é é semelhante à classificação O design da rede e a saída da tarefa são semelhantes, exceto que a função de ativação da camada final totalmente conectada é diferente).
Então, como atravessá-lo? O método da classe RCNN consiste em percorrer todas as posições da imagem através de uma janela deslizante e classificar cada caixa.
No entanto, surgem problemas com este método: a incompletude do percurso afeta muito a precisão. Quanto mais preciso for o percurso, maior será a precisão do detector, mas ao mesmo tempo maior será o custo, pois é necessário considerar bboxes de diferentes escalas para percorrer toda a imagem, o que é bastante oneroso. . .
Por exemplo: Por exemplo, o tamanho da imagem de entrada é (320, 320) (320, 320)( 3 2 0 ,3 2 0 ) o que significa que há320 × 320 = 102, 400 320 \times 320 = 102, 4003 2 0×3 2 0=1 0 2 ,400 posições . _ A janela mínima é(1, 1) (1, 1)( 1 ,1 ) , máximo(320 × 320) (320 \vezes 320)( 3 2 0×3 2 0 ) , então o número de travessias é infinito. Vejamos o pseudocódigo:
Ou seja, essencialmente, estamos treinando um classificador binário. A entrada deste classificador binário é o conteúdo de uma caixa e a saída é (primeiro plano/fundo).
E isso traz mais 2 perguntas:
- ① Os quadros têm tamanhos diferentes. Os quadros de tamanhos diferentes são inseridos no mesmo classificador de dois?
Precisamos lidar com essa situação. A maneira usual é redimensionar a entrada dos dois classificadores para o mesmo tamanho fixo. Isso obviamente causará grandes problemas. Por exemplo, a altura e a largura do tensor de entrada fixa de um classificador de dois classificadores são 64. × 64 64 \vezes 646 4×6 4 , depois de deslizar o quadro, o tamanho de alguns quadros é200 × 200 200 \times 2002 0 0×2 0 0 , alguns são10 × 10 10 \times 101 0×1 0 , todos nós precisamos redimensionar essas bboxes para64 × 64 64 \times 646 4×Somente bboxes de 6 e 4 podem inserir os dois classificadores.
- ②Existem muitas imagens de fundo e poucas imagens de primeiro plano: as amostras de duas classificações são desequilibradas.
Este método de classificação de janela deslizante será muito lento e o problema de desequilíbrio de classes é sério.
Até agora, um detector foi projetado usando um algoritmo de classificação. Ele tem vários problemas. Agora é hora de otimizar (então entraremos oficialmente na série de métodos YOLO):
O autor do YOLO pensou desta forma na época: Para o classificador, a última camada totalmente conectada produzirá um vetor one-hot e, em seguida, o substituirá por (x, y, w, h, c), c representa confiança. não seria melhor transformar o problema em um problema de regressão e retornar diretamente a posição da Bounding Box?
Pronto, agora o modelo é:

Então como organizar o treinamento? Rotule você mesmo os dados do ponto, defina o rótulo como ( 1 , x ∗ , y ∗ , w ∗ , h ∗ ) (1, x^*, y^*, w^*, h^*)( 1 ,x∗ ,sim∗ ,c∗ ,h∗ ). Aqui**∗ representa a verdade básica (ou seja, o rótulo real). Com dados e rótulos, o treinamento pode ser realizado.
Descobriremos que este método é muito mais simples do que o método de classificação de janela deslizante de agora. Esta versão da ideia é chamada de YOLO v0 porque é a versão mais simples de You Only Look Once.
1.2 YOLO v1
YOLO v1 resolve vários problemas com base no YOLO v0:
- ① O YOLO v0 só pode realizar a detecção de um único alvo e precisa urgentemente de expansão.
A ideia da solução do YOLO v1 é utilizar a (c, x, y, w, h) como responsável por inserir o alvo de uma determinada subárea da imagem.
Ou seja, comparado a uma imagem do YOLO v0, que obtém apenas um (x, y, h, w, c), o YOLO v1 obtém n (x, y, h, w, c). Então, como obter n ( x, y 
), h, w, c) Que tal pegar os rostos de Rick e Morty que queremos? Aqui, o autor do YOLO v1 usa NMS (supressão não máxima) para filtrar bbox. O algoritmo específico é [1]:
O NMS resolve automaticamente o problema de não saber quantos alvos existem no gráfico.
- ② YOLO v0 só pode realizar detecção de categoria única e precisa urgentemente de expansão.
Uma tarefa de detecção geral requer a detecção de muito conteúdo. Por exemplo, é necessário detectar os rostos de Rick e Morty e o telescópio. Então, o que devemos fazer?
Tomando 2 categorias: face e telescópio como exemplo, deixamos a rede prever o conteúdo de N * (c, x, y, w, h) a N * (c, x, y, w, h, one-hot) . 2 categorias, one-hot é [0,1],[1,0], conforme mostrado na figura a seguir:
- ③ Detecção de alvos pequenos
Alvos pequenos são sempre mal detectados, então o YOLO v1 projeta neurônios especificamente para caber em alvos pequenos.
No código real, YOLO v1 usa 2 quíntuplos (c, x, y, w, h) para cada área, um é responsável por retornar o alvo grande e o outro é responsável por retornar o alvo pequeno. Adicione também one-hot vetor, one-Hot é [0,1],[1,0] para indicar a qual categoria pertence (face ou telescópio).

O núcleo do YOLO v1 é resolver esses três problemas em comparação com a v0. Seu diagrama de arquitetura é o seguinte (a grade representa a divisão das imagens em áreas. O exemplo acima é 4x4, mas no YOLO v1 é na verdade 7x7. A categoria é 20 categorias):

1.3 YOLO v2
Embora o YOLO v1 seja muito mais rápido que os algoritmos de detecção RCNN, ele ainda apresenta problemas, como: os quadros previstos são imprecisos e muitos alvos não podem ser encontrados:
- ① A caixa prevista pelo YOLO v1 é imprecisa
A principal razão para este problema é que o YOLO v1 prevê diretamente o bbox (x, y, w, h), e essa faixa de valores é muito grande, portanto haverá problemas de imprecisão. Pense nisso quando realizamos tarefas de CV, normalizamos o processamento de imagem e dimensionamos imagens comuns de 8 bits (0-255) para [0, 1] ou [-1, 1].
A estratégia de prever diretamente a posição do YOLO v1 fará com que a rede neural fique instável no início do treinamento, mas o uso de compensações tornará o processo de treinamento mais estável e o índice de desempenho aumentará cerca de 5%.
Portanto, aprenda com essa ideia e com as ideias do tipo RCNN. YOLO v2 propõe um método que não prevê diretamente as coordenadas bbox, mas, em vez disso, prevê deslocamentos baseados em grade e deslocamentos baseados em âncora .
O autor chama isso de previsão de localização .
-
O deslocamento baseado na grade significa que a posição da âncora é fixa (a âncora é uma âncora fixa obtida agrupando todo o conjunto de dados ao criar o conjunto de dados) e o deslocamento = posição de destino-posição da âncora .
-
O deslocamento baseado em âncora significa que a posição da grade é fixa (a grade são as grades verdes de Rick e Morty acima) e o deslocamento = posição alvo-posição da grade.
Ilustrações sobre previsão de localização , de artigos de Zhihu sobre feras tecnológicas [2],

Conforme mostrado na figura acima, suponha que a figura esteja dividida em 9 grades, GT (verdade fundamental) é mostrado na caixa vermelha e Anchor é mostrado na caixa roxa ( ) 该Anchor是根据数据集的GT计算产生的,与目标GT的IoU最大的那个Anchor. Os números na imagem são as informações reais da imagem.
O valor previsto de YOLO v2 é de (x, y, h, w), x, y, h, w ∈ [0, 447] x, y, h, w \in [0,447]x ,sim ,h ,c∈[ 0 ,4 4 7 ];变为tx , ty , tw , th t_x, t_y, t_w, t_htx,tvocê,to que,th, conforme mostrado abaixo, o intervalo desses valores é muito pequeno, o que é muito útil para detectar convergência de rede.

Pode-se observar que as coordenadas da posição central do bbox vermelho do Ground Truth em comparação com o canto superior esquerdo (1, 1) da grade onde está localizado são (1,543, 1,463). Fórmula de cálculo:
tx = log ( ( bboxx − cx ) / ( 1 − ( bboxx − cx ) ) ) t_x = log((bbox_x - c_x) / (1 - (bbox_x - c_x)))tx=l o g ( ( b b o xx-cx) / ( 1-( b b o xx-cx) ) )
ty = log ( ( bboxy − cy ) / ( 1 − ( bboxy − cy ) ) ) t_y = log((bbox_y - c_y) / (1 - (bbox_y - c_y)))tvocê=l o g ( ( b b o xvocê-cvocê) / ( 1-( b b o xvocê-cvocê) ) )
tw = log ( gtw / pw ) t_w = log (gt_w / p_w)to que=l o g ( g to que/ po que)
th = log ( gth / ph ) t_h = log (gt_h / p_h)th=l o g ( g th/ ph)
O canto inferior direito é uma ilustração específica das melhorias do YOLO v2. O significado dos parâmetros é o seguinte [2]:

-
② YOLO v1 perderá muitos alvos, ou seja, o fenômeno de detecção perdida é óbvio,
porque na detecção de múltiplos alvos e multicategorias, o tamanho e a proporção dos objetos alvo são diferentes. Por exemplo, os pedestres são caixas longas e estreitas, enquanto os carros são caixas quadradas.
Com base nisso, o autor do YOLO v2 preparou antecipadamente várias caixas delimitadoras com probabilidade relativamente alta de ocorrência no conjunto de dados e, em seguida, usou-as como base para previsão. Esta é a intenção original do Anchor.
O método específico é que YOLO v2 divide a imagem em 13 × 13 13 \times 131 3×1 3 áreas, cada área possui 5 âncoras, e cada âncora corresponde a 1 categoria. Tomando 2 categorias como exemplo, conforme calculado pela fórmula a seguir, a última dimensão do Tensor previsto pela rede é 35. 35 = 5 ×
( 5 ( c , tx , ty , tw , th ) + 2 classes ) 35 = 5 \times (5 (c, t_x, t_y, t_w, t_h) + 2 classes)3 5=5×( 5 ( c ,tx,tvocê,to que,th)+2ª classe ) _ _ _ _ _ _- Como são obtidas as 5 âncoras em cada área?
Conforme mostrado na figura abaixo, para qualquer conjunto de dados, como COCO (âncora roxa), primeiro agrupe as caixas delimitadoras do GT (verdade fundamental) do conjunto de treinamento. Em quantas categorias elas estão agrupadas? Após o experimento, o autor descobriu que a recuperação versus complexidade das 5 categorias é melhor, e agora está agrupada em 5 categorias. Claro, para tarefas complexas, quanto mais categorias, maior será o mAP e a previsão mais abrangente , mas a complexidade aumenta muito. Ao mesmo tempo, a precisão do modelo não é muito melhorada, então um método relativamente de compromisso é adotado para selecionar 5 clusters, ou seja, são utilizadas 5 caixas a priori.

- Nota: A âncora do YOLO v2 é obtida a partir das estatísticas do conjunto de dados (enquanto a largura, altura e tamanho da âncora no Faster-RCNN são selecionados manualmente).
- Como são obtidas as 5 âncoras em cada área?
1.4 YOLO v3
Neste ponto, a ideia básica do YOLO foi determinada, mas a partir do YOLO v2, o efeito na detecção de pequenos alvos ainda não é bom o suficiente (resnet ainda não foi lançado..., a rede para extrair recursos não é bom o suficiente~).
Com o YOLO v3, a principal melhoria aqui é a adição de previsão em várias escalas e a mudança do backbone do YOLO v2 de um Darknet de 19 camadas para um Darknet de 53 camadas [4].
- ①O cabeçote de detecção YOLO v3 de previsão multiescala é bifurcado e dividido em 3 partes, cada dimensão tem 3 âncoras:
[2]
O YOLO v3, no total, usa 9 caixas de âncora. Três para cada escala (3 grandes, 3 médias, 3 pequenas). Se você estiver treinando o YOLO em seu próprio conjunto de dados, você deve usar o agrupamento K-Means para gerar 9 âncoras.
[4]
- 13 ∗ 13 ∗ 3 ∗ ( 4 + 1 + 2 ) 13*13*3*(4+1 + 2)1 3∗1 3∗3∗( 4+1+2 )
- 26 ∗ 26 ∗ 3 ∗ ( 4 + 1 + 2 ) 26*26*3*(4+1 + 2)2 6∗2 6∗3∗( 4+1+2 )
- 52 ∗ 52 ∗ 3 ∗ ( 4 + 1 + 2 ) 52*52*3*(4+1 + 2)5 2∗5 2∗3∗( 4+1+2 )

Comparado com YOLO v2, o número de bboxes previstos de YOLO v3 é:
(13 × 13 + 26 × 26 + 52 × 52) × 3 = 10467 (V 3) ≫ 845 (V 2) (13 × 13 × 5 ) (13 \vezes 13 + 26 \vezes 26 + 52 \vezes 52) \vezes 3 = 10467(V3) \gg 845(V2) (13 \vezes 13 \vezes 5)( 1 3×1 3+2 6×2 6+5 2×5 2 )×3=1 0 4 6 7 ( V 3 )≫8 4 5 ( V 2 ) ( 1 3×1 3×5 )
Com tantas caixas delimitadoras mais previsíveis, as capacidades do modelo foram obviamente aprimoradas.
O modelo oficial do YOLO v3 é mostrado abaixo:
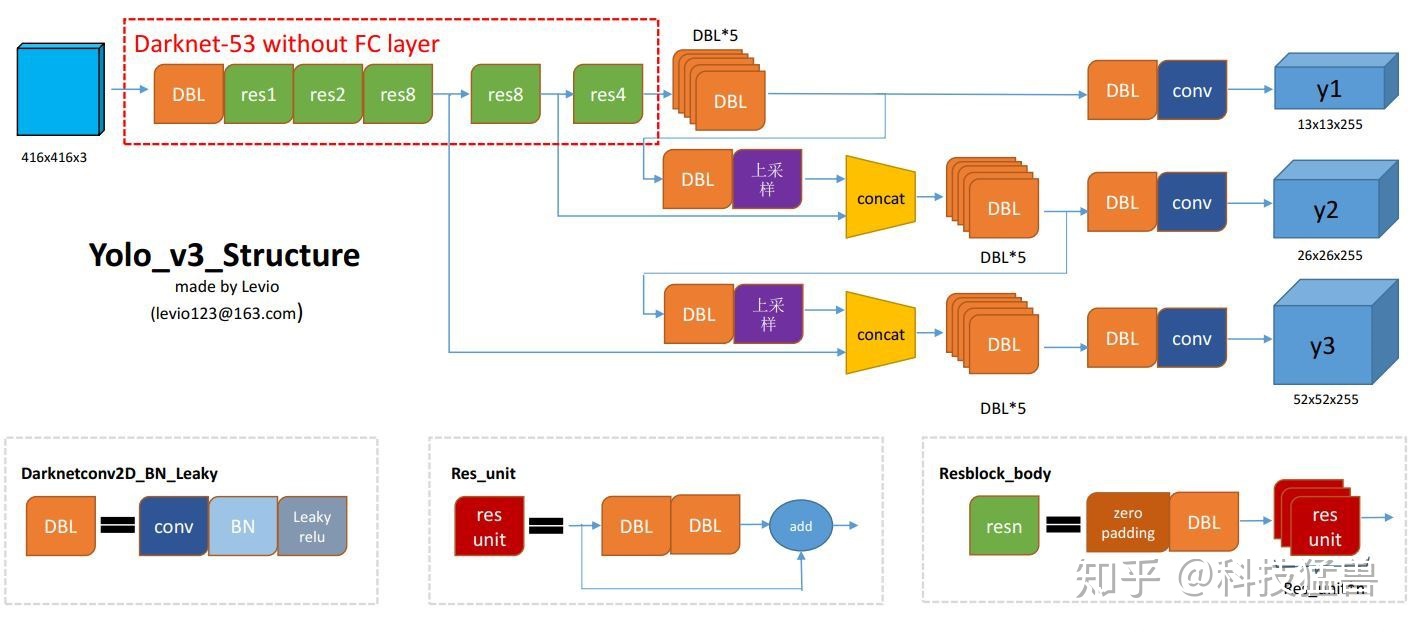
1.5 YOLO v4
Yolo v4 adiciona alguns recursos baseados na v3, principalmente três recursos:
-
① Usando múltiplas âncoras para uma única verdade básica
O YOLO v3 anterior usava uma âncora para ser responsável por um GT. No YOLO v4, várias âncoras são usadas para serem responsáveis por um GT. O método é: para GT j GT_jG TjPor exemplo, contanto que I o U ( Anchori , GT j ) > limite IoU(anchor_i, GT_j) > limiteI o U ( uma âncora _ _ _ _eu,G Tj)>limiar ,Obtendo âncora âncora_i _ _ _ _ _ _uma âncora _ _ _ _euVá para carregar GT j GT_jG Tj.
Isto equivale ao fato de que o número de suas caixas de âncora não mudou, mas a proporção de amostras positivas selecionadas aumentou, o que alivia o problema de desequilíbrio de amostras positivas e negativas (geralmente há muitos fundos). -
② Eliminar a sensibilidade da grade
Você ainda se lembra dessa foto do YOLO v2 antes? YOLO v2 e YOLO v3 prevêem tx, ty, tw, th t_x, t_y, t_w, t_htx,tvocê,to que,thEssas 4 compensações.

Na verdade, há um problema oculto aqui:

-
③ A perda de CIoU
não será introduzida por enquanto. Para obter detalhes, consulte o artigo Zhihu do chefe da fera da tecnologia[2].
1.6 YOLO v5
O YOLO v5 basicamente modifica a estrutura do YOLO v3. A introdução a seguir está dividida em vários módulos:
1.6.1 Módulo de rede
Pegue (N, 3, 640, 640) (N, 3, 640, 640)( N ,3 ,6 4 0 ,6 4 0 ) como exemplo, tomando como exemplo os Yolov5s mais leves, sua estrutura é a seguinte

Abaixo descreverei em detalhes os módulos importantes de Focus, BottleneckCSP, SPP e PANET. Como este projeto usa a estrutura de rede YOLO v5s para treinar o modelo, os diagramas de rede e exemplos abaixo são todos baseados em YOLO v5s, e a imagem de entrada é 3x640x640 .
A rede YOLO consiste em três componentes principais:
1) Backbone : Uma rede neural convolucional que agrega e forma recursos de imagem em diferentes imagens com granularidade fina.
2) Pescoço : Uma série de camadas de rede que misturam e combinam recursos de imagem e passam os recursos de imagem para a camada de predição. (geralmente FPN ou PANET)
3) Cabeça : Preveja recursos de imagem, gere caixas delimitadoras e preveja categorias.
Módulos importantes usados no YOLO V5 1.0 incluem Focus, BottleneckCSP, SPP e PANET. O aumento da resolução do modelo usa a interpolação de aumento da resolução duas vezes mais próxima nn.Upsample(mode="nearest").
É importante notar que o modelo Pretrained_model originalmente treinado para o conjunto de dados COCO no YOLO V5 1.0 usava FPN como Neck.Após 22 de junho, a Ultralytics atualizou o Neck do modelo para PANET. Muitas introduções de estrutura de rede YOLO V5 na Internet são baseadas em FPN-NECK. O treinamento do modelo neste artigo é baseado em PANET-NECK. Somente PANET-NECK é apresentado abaixo.
Para YOLO V5, seja V5s, V5m, V5l ou V5x, a espinha dorsal, o pescoço e a cabeça são os mesmos. A única diferença está nas configurações de profundidade e largura do modelo. Você só precisa modificar esses dois parâmetros para ajustar a estrutura de rede do modelo. Os parâmetros para V5l são os parâmetros padrão.
• O múltiplo de profundidade é usado para controlar a profundidade do modelo. Por exemplo, a profundidade de V5s é 0,33 e a profundidade de V5l é 1, o que significa que o número de gargalos em V5l é 3 vezes maior que o de V5s.
• width_multiple é usado para controlar o número de kernels de convolução. A largura dos V5s é 0,5, enquanto a largura do V5l é 1, o que significa que o número de kernels de convolução dos V5s é metade da configuração padrão. Claro, você também pode configure-o para 1,25 vezes, ou seja, V5x . Por exemplo, a primeira camada do backbone no arquivo yaml do YOLO V5 abaixo é [[-1, 1, Focus, [64, 3]] e a largura do V5s é 0,5, então esta camada é na verdade [[- 1, 1, Foco, [32, 3]].
Como meu objetivo é um modelo de detecção muito leve, atualmente considero apenas
o arquivo de definição de modelo de yolov5s da seguinte forma: yolov5s.yaml(para o conjunto de dados COCO), pode-se ver que ele corresponde bem à figura acima.
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
Focus
A imagem abaixo mostra a estrutura de emenda de amostragem entrelaçada Focus do YOLO V5s.

A entrada padrão do YOLO V5 é 3x640x640. A função da camada Focus é copiá-la em quatro cópias e, em seguida, cortar as quatro imagens em quatro fatias de 3x320x320 por meio da operação de fatiamento. Em seguida, use concat para conectar as quatro fatias da profundidade. e a saída é 12x320x320 e, em seguida, passa por uma camada de convolução com um número de kernel de convolução de 32 para gerar uma saída de 32x320x320. Finalmente, o resultado é inserido na próxima camada de convolução por meio de batch_norm e leaky_relu.
O efeito da camada Focus é o seguinte: 4 × 4 4 \times 44×Tomemos como exemplo a imagem 4. A imagem da esquerda é a imagem de entrada original e a imagem da direita é o mapa de recursos após o processamento do Focus.

A partir de agora (2020.09.28), a implementação é assim [5], que é igual ao passthrough do YOLO v2.

O núcleo é este código self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)). x[..., ::2, ::2]É a parte amarela, x[..., 1::2, ::2]é a parte vermelha, x[..., ::2, 1::2]é a parte verde e assim por diante.
-
BottleneckCSP
A imagem abaixo mostra a primeira estrutura BottlenneckCSP do YOLO V5s: pode-se observar que BottlenneckCSP está dividido em duas partes, Bottlenneck e CSP .

Entre eles,Bottleneckestá a estrutura residual clássica: primeiro uma camada de convolução 1x1 (conv+batch_norm+leaky relu), depois uma camada de convolução 3x3 e, finalmente, a estrutura residual é adicionada à entrada inicial[6].

Vale a pena notar que YOLO V5 controla a profundidade do modelo através de múltiplos de profundidade , por exemplo, a profundidade de V5s é 0,33 , enquanto a profundidade de V5l é 1. Ou seja, o número de gargalos no gargaloCSP de V5l é 3 vezes maior do que V5s. O primeiro BottlenneckCSP no modelo O número padrão de gargalos é x3. Para V5s, há apenas um gargalo na imagem acima.O código do autor é o seguinte: vale a pena notar que e é width_multiple , que indica a proporção entre o número de núcleos de convolução atualmente operados e o número padrão
[7]:

Como pode ser visto no código BottleneckCSP acima, ele divide a ramificação em 2 blocos , dividido em ramos y1 e y2,
entre os quais o ramo 1 (y1) realiza a operação de Gargalo * N, e o ramo 2 (y2) realiza a redução do canal.Por
fim, concatene os dois ramos e, em seguida, passe por uma série de operações de bn , agir e Conv (a imagem abaixo é de William em Zhizhi) publicou artigos[6]).

-
SPP
SPP é uma camada de pooling espacial . A entrada é 512x20x20. Depois de uma camada de convolução 1x1, a saída é 256x20x20 e, em seguida, é amostrada através de três Maxpools paralelos de diferentes tamanhos de kernel (5, 9, 13). Observe que para ramificações diferentes , os tamanhos de preenchimento são [5,9,13]//2 respectivamente. Além disso, como stride = 1, o resultado após cada agrupamento é 256x20x20, portanto, os resultados podem ser emendados e adicionados aos seus recursos iniciais. Saída 1024x20x20 e, finalmente, use um kernel de convolução de 512 para restaurá-lo para 512x20x20 (a imagem abaixo é de um artigo Zhihu da Technology Beast[3]).

-
PANet
A estrutura PAN vem do artigo Path Aggregation Network[8]. Sua intenção original é ser usada em tarefas de segmentação de instâncias (Segmentação de Instâncias). Sua estrutura de modelo é a seguinte: O

extrator de recursos desta rede adota um novo bottom-up aprimorado (Bottom Up ).A estrutura FPN melhora a propagação de recursos de baixo nível (Parte a). Cada estágio do terceiro caminho toma como entrada os mapas de características do estágio anterior e os processa com camadas convolucionais 3x3. As saídas são adicionadas aos mapas de características do mesmo estágio do caminho de cima para baixo por meio de conexões laterais, e esses mapas de características fornecem informações para o próximo estágio (parte b).Ao mesmo tempo , o pooling de recursos adaptativos é usado para restaurar os caminhos de informação danificados entre cada região candidata e todos os níveis de recurso, agregar cada região candidata em cada nível de recurso e evitar ser alocado arbitrariamente (Parte c).
YOLO V5 empresta uma estrutura PANET modificada do YOLO V4: PANET normalmente usa pooling de recursos adaptativos para adicionar camadas adjacentes para previsão de máscara. No entanto, este método é um pouco complicado ao usar PANET no YOLO v4, então, em vez de adicionar camadas adjacentes usando pooling de recursos adaptativos, os autores do YOLO v4 executam uma operação Concat nelas, o que melhora a precisão da previsão.

YOLO V5 também usa operação em cascata. Para obter detalhes, consulte a imagem grande do modelo e a operação Concat correspondente no diagrama de rede Netron.

1.6.2 Melhorias no processamento de dados
O conteúdo a seguir foi reproduzido de
[3]um artigo Zhihu da Technology Beast
- Aumento de dados em mosaico
[3]

CutMix usa apenas duas imagens para emenda, enquanto o aprimoramento de dados Mosaic usa 4 imagens para emenda por escala aleatória, corte aleatório e arranjo aleatório.
Suas principais vantagens são:
① Enriquecer o conjunto de dados : usar 4 imagens aleatoriamente, dimensioná-las aleatoriamente e, em seguida, distribuí-las aleatoriamente para emenda, o que enriquece muito o conjunto de dados de detecção. Em particular, o dimensionamento aleatório adiciona muitos alvos pequenos, tornando a rede mais robusta.
② Reduza o uso da GPU : Algumas pessoas podem dizer que o dimensionamento aleatório e o aprimoramento comum de dados também podem ser feitos, mas o autor considera que muitas pessoas podem ter apenas uma GPU, portanto, durante o treinamento aprimorado do Mosaic, os dados de 4 imagens podem ser calculados diretamente, fazendo Mini- O tamanho do lote não precisa ser grande e uma GPU pode obter melhores resultados.
- Cálculo da caixa de âncora adaptativa
[3]
No algoritmo Yolo, para diferentes conjuntos de dados, haverá caixas de âncora com comprimento e largura iniciais.
Durante o treinamento da rede, a rede gera o quadro previsto com base no quadro âncora inicial e, em seguida, compara-o com a verdade do quadro real, calcula a diferença entre os dois e, em seguida, atualiza-o ao contrário para iterar os parâmetros da rede.
Portanto, a caixa de âncora inicial também é uma parte importante, como a caixa de âncora inicialmente definida por Yolov5 no conjunto de dados Coco:

Em Yolov3 e Yolov4, ao treinar diferentes conjuntos de dados, o valor da caixa de âncora inicial é calculado através de um separado programa. .
No entanto, Yolov5 incorpora esta função no código e calcula de forma adaptativa os melhores valores da caixa de âncora em diferentes conjuntos de treinamento durante cada treinamento.
Claro, se você acha que o efeito da caixa de âncora calculada não é muito bom, você também pode desativar a função de cálculo automático da caixa de âncora no código [9].
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
- Dimensionamento de imagem adaptável
[3]
Em algoritmos comuns de detecção de alvos, imagens diferentes têm comprimentos e larguras diferentes, portanto, um método comum é dimensionar uniformemente as imagens originais para um tamanho padrão e depois enviá-las para a rede de detecção.
Por exemplo, 416 × \times é comumente usado no algoritmo Yolo× 416,608× \vezes× 608 e outros tamanhos, por exemplo, dimensione a imagem 800*600 abaixo:, conforme mostrado na figura: No entanto,

isso foi melhorado no código Yolov5 e também é um bom truque que torna a velocidade de inferência do Yolov5 mais rápida.
O autor acredita que quando o projeto é realmente utilizado, muitas imagens apresentam proporções diferentes, portanto, após dimensionamento e preenchimento, os tamanhos das bordas pretas em ambas as extremidades são diferentes. Se houver mais preenchimento, haverá redundância de informações, o que irá afetar a velocidade de inferência.
datasets.pyPortanto, foram feitas modificações na função do código Yolov5 letterboxpara adicionar de forma adaptativa as bordas pretas mínimas à imagem original, conforme mostrado na figura: as bordas pretas

em ambas as extremidades da altura da imagem são reduzidas, e a quantidade de cálculo também será será reduzido durante a inferência, ou seja, a velocidade de detecção do alvo será melhorada.
Através desta simples melhoria, a velocidade de inferência foi melhorada em 37%, o que pode ser considerado um efeito óbvio.
O preenchimento em Yolov5 é cinza, ou seja, (114, 114, 114), que tem o mesmo efeito, e o método de redução de bordas pretas não é utilizado durante o treinamento, mas sim o método de preenchimento tradicional, ou seja, dimensionamento para Tamanho 416*416. Somente ao testar e usar a inferência do modelo, o método de redução das bordas pretas é usado para melhorar a velocidade de detecção e inferência do alvo.
- Aumento de amostras positivas
[3]
Isso é o mesmo que Usando multi-âncoras para verdade básica única do YOLO v4 .

2. Resumo
A imagem abaixo é um resumo do autor sobre as características de cada geração da série YOLO, entre elas, a parte Perda será discutida na Série 3.

Artigo de referência
[1] Você nunca deve ter visto uma interpretação do modelo da série YOLO tão fácil de entender (de v1 a v5) (Parte 1) [2]
Você nunca deve ter visto uma série YOLO tão fácil de entender (de v1 a v5) v5) interpretação do modelo (Parte 2)
[3] Você nunca deve ter visto uma série YOLO tão fácil de entender (de v1 a v5) interpretação do modelo (Parte 2)
[4] O que há de novo no YOLO v3?
[5] Foco camada de YOLO v5
[6] Use YOLO V5 para treinar a rede automática de detecção de alvo de condução
[7] Camada de gargalo de YOLO v5
[8] Rede de agregação de caminho para segmentação de instância: CVPR2018
[9] Código YOLO v5 train.py