1. Cinco modelos IO en Linux/Unix
Al realizar programación de red en Linux, la programación del lado del servidor a menudo necesita construir un modelo IO de alto rendimiento. Hay cinco modelos IO comunes:
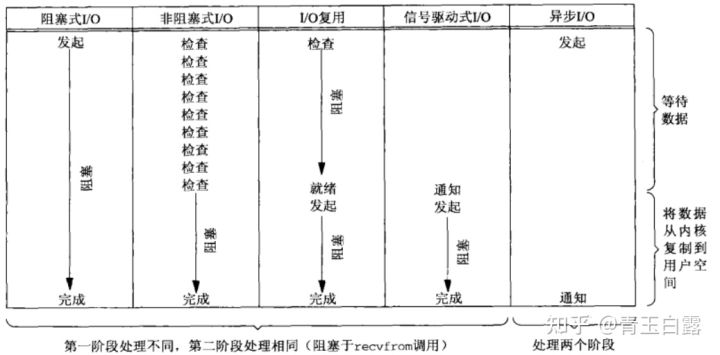
- E/S de bloqueo sincrónico (BIO, bloqueo de IO) :
cuando se llama a este tipo de función de E/S para leer datos, no regresará hasta que se lean los datos; de lo contrario, el proceso/hilo se bloqueará en la función actual , si el los datos no han sido procesados Bueno, el proceso/hilo actual está bloqueado todo el tiempo.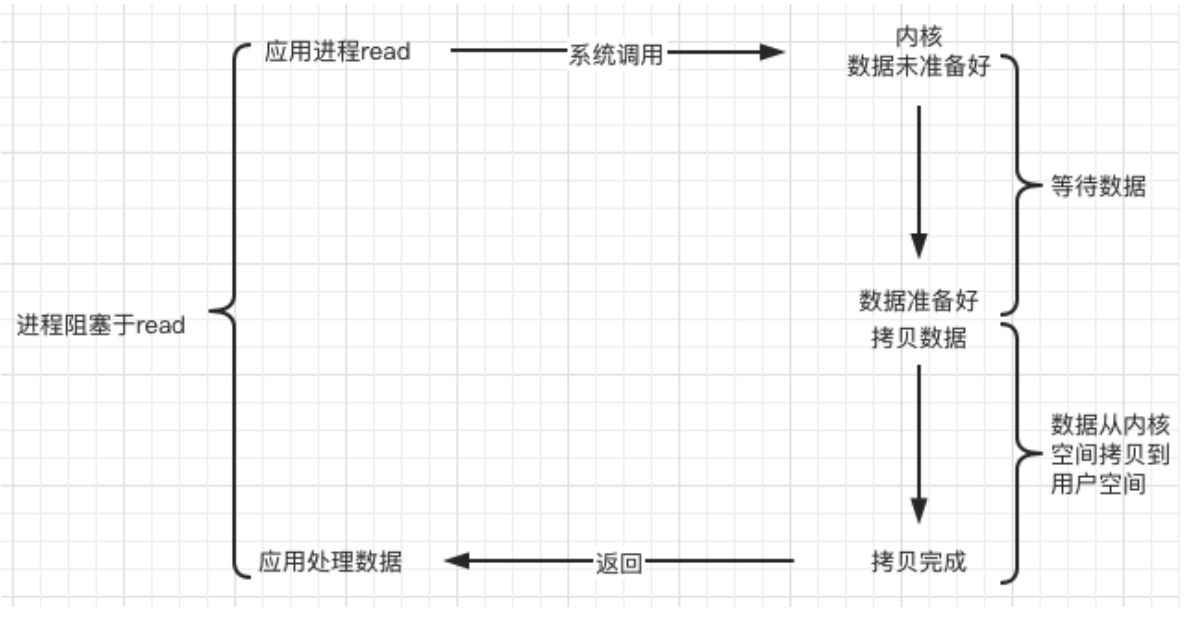
- E / S síncrona sin bloqueo (Non-blocking IO, NIO) :
espera sin bloqueo, de vez en cuando para detectar si el evento IO está listo. La llamada al sistema de ejecución de E/S sin bloqueo siempre regresa inmediatamente , y la capa superior del negocio decide si continúa esperando datos o procesa otras cosas en función de la información devuelta ; si el evento no ocurre, devuelve -1 En este momento, los dos se pueden distinguir según errno En este caso, para aceptar, recibir y enviar, errno generalmente se establece en EAGAIN cuando el evento no ocurre.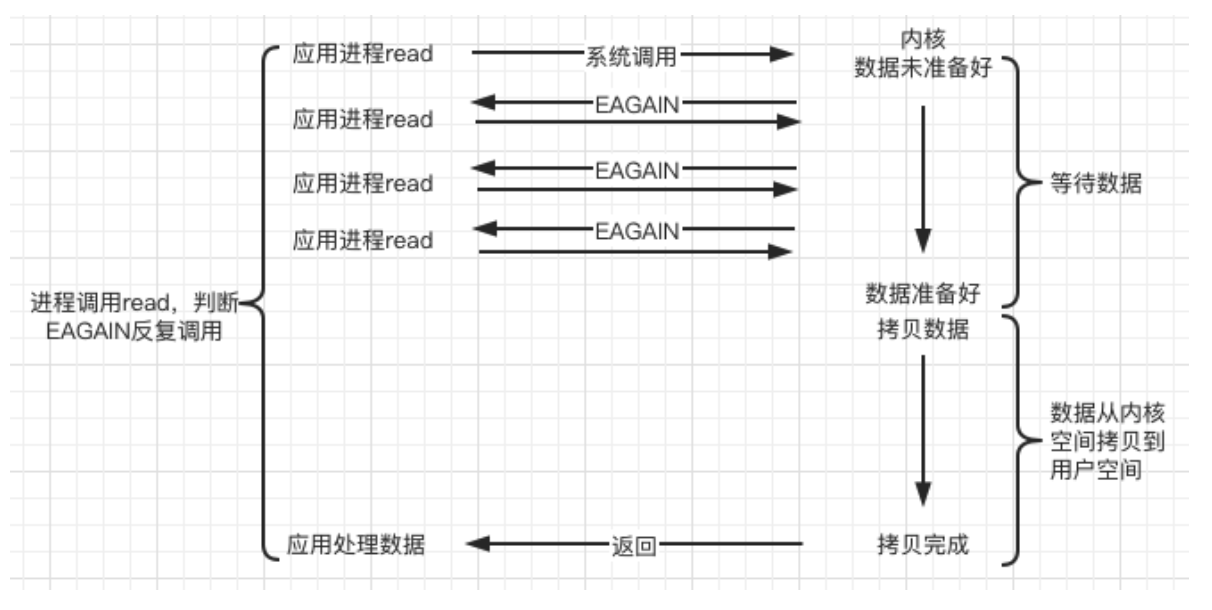
- Multiplexación de E / S (multiplexación IO) :
Linux usa funciones de selección / sondeo / epoll para implementar el modelo de multiplexación IO. Estas funciones también bloquearán el proceso (puede configurar sin bloqueo), pero estas funciones son diferentes de bloquear IO Múltiple IO Las operaciones se pueden bloquear al mismo tiempo . Además, las funciones IO de múltiples operaciones de lectura y escritura se pueden detectar al mismo tiempo . La función de operación IO no se llama realmente hasta que hay datos para leer o escribir. (Se utiliza para detectar múltiples eventos, se deben usar múltiples subprocesos/procesos para manejar una alta concurrencia)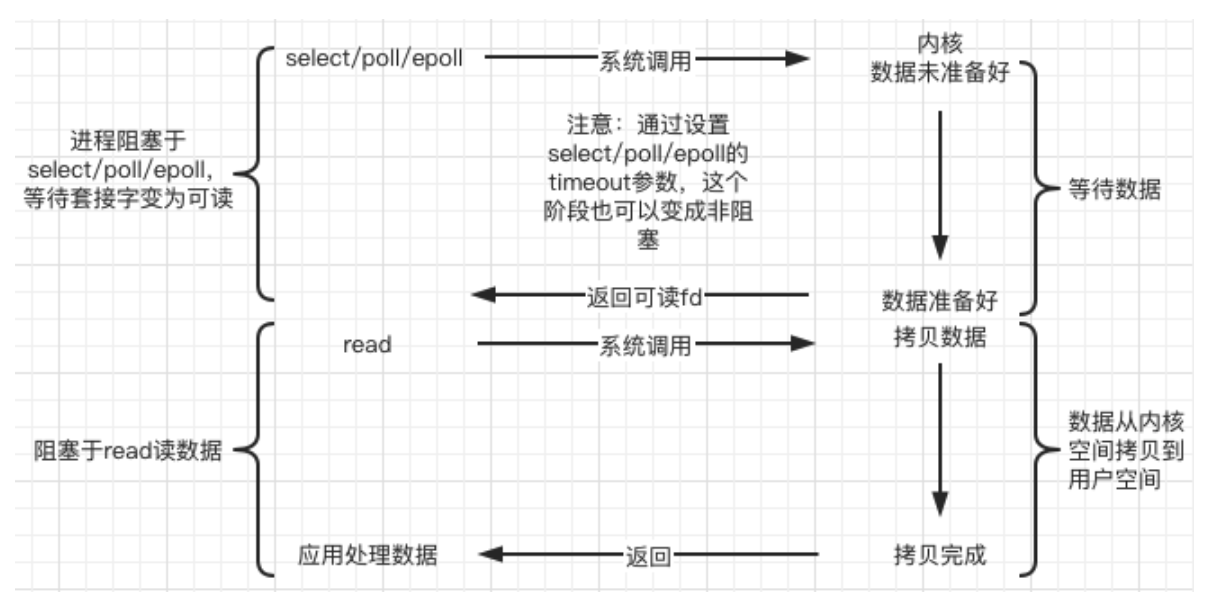
- E / S impulsada por señal (IO impulsada por señal) :
este tipo de IO en realidad usa el mecanismo de señal . Cuando el núcleo descubre que los datos están listos, usa la señal SIGIO para "activar" el programa de procesamiento de señal correspondiente . Leer datos, que también es una E/S sin bloqueo ;
El kernel es asíncrono en la primera etapa y síncrono en la segunda etapa ; la diferencia con IO sin bloqueo es que proporciona un mecanismo de notificación de mensajes, que no requiere sondeo y verificación continuos por parte de los procesos del usuario, reduce la cantidad de API del sistema. llamadas y mejora la eficiencia .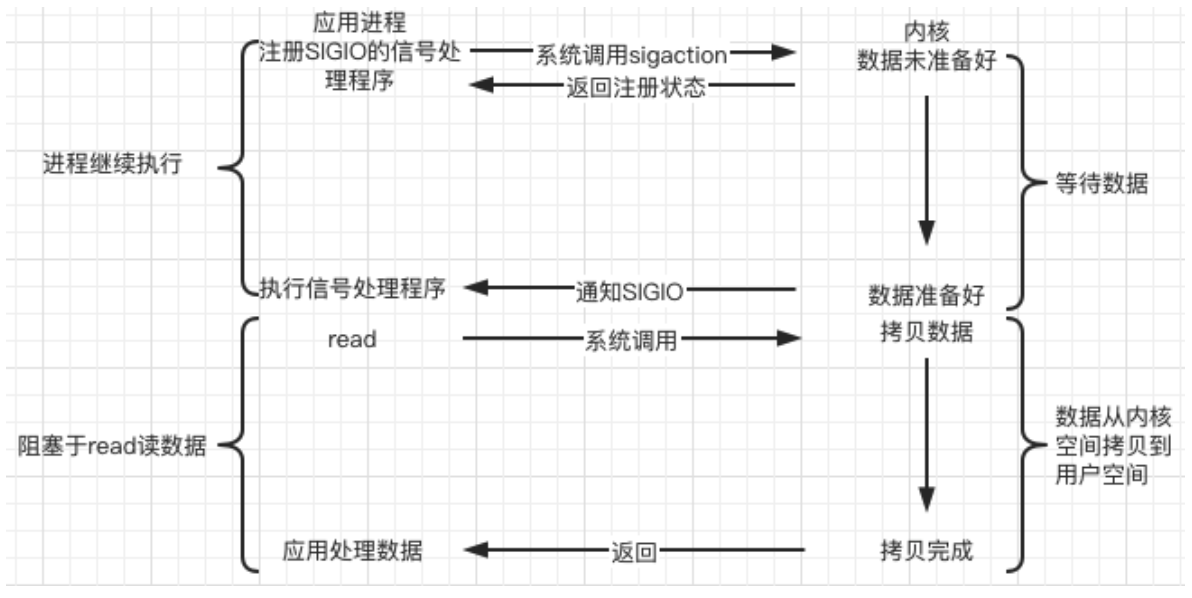
- E/S asíncrona (E/S asíncrona, AIO) :
la E/S anterior controlada por señal es el kernel que le dice a la aplicación que "los datos están listos, puede comenzar a leer, cambio"; mientras que la E/S asíncrona es un paso más: — Decía directamente: "Los datos han sido leídos, cambio".
En Linux, puede llamar a la función aio_read para indicar la palabra de descripción del kernel, el puntero del búfer y el tamaño del búfer, el desplazamiento del archivo y el método de notificación, y luego regresar inmediatamente y notificar a la aplicación después de que el kernel copie los datos en el búfer .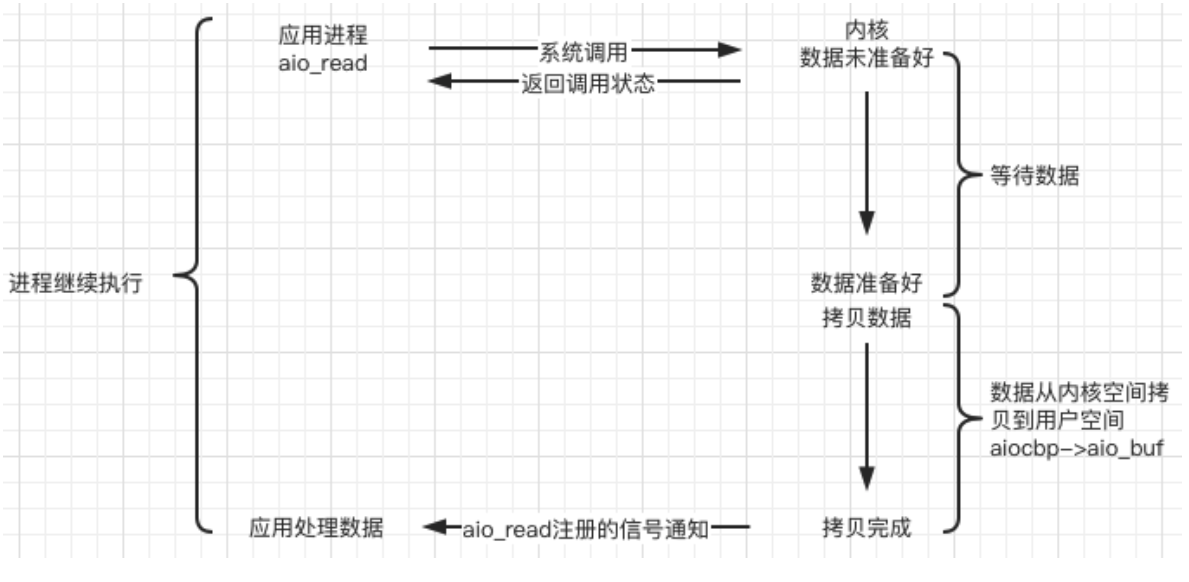
2. Servidor web
Un servidor web es un software (programa) de servidor o el hardware (computadora) que ejecuta el software del servidor . Su función principal es comunicarse con el cliente (generalmente un navegador ) a través del protocolo HTTP para recibir, almacenar y procesar solicitudes HTTP del cliente , dar una respuesta HTTP a la solicitud y devolver el contenido solicitado al cliente (archivo, página web, etc.) o devolver un mensaje de error.

Normalmente el usuario se comunica con el servidor correspondiente mediante un navegador web. Escriba " nombre de dominio " o " dirección IP: número de puerto " en el navegador y el navegador primero resolverá su nombre de dominio en la dirección IP correspondiente o enviará una solicitud HTTP al servidor web correspondiente directamente de acuerdo con su dirección IP. Este proceso primero establece una conexión con el servidor web de destino a través del protocolo de enlace de tres vías del protocolo TCP , y luego el protocolo HTTP genera un mensaje de solicitud HTTP para el servidor web de destino y lo envía al servidor web de destino a través de protocolos como TCP e IP .
3. Protocolo HTTP (capa de aplicación)
3.1 Descripción general
El Protocolo de transferencia de hipertexto (Protocolo de transferencia de hipertexto, HTTP) es un protocolo simple de solicitud-respuesta (Solicitud-Respuesta) , que generalmente se ejecuta sobre TCP . Especifica qué tipo de mensajes puede enviar el cliente al servidor y qué tipo de respuestas puede obtener. Los encabezados de los mensajes de solicitud y respuesta se proporcionan en ASCII, mientras que el contenido del mensaje tiene un formato similar a MIME. HTTP es la base de la comunicación de datos de la World Wide Web (WWW, World Wide Web).
HTTP es un estándar para solicitudes y respuestas del lado del cliente (usuario) y del servidor (sitio web) . Al utilizar un navegador web, un rastreador web u otras herramientas, el cliente inicia una solicitud HTTP al puerto especificado en el servidor ( puerto 80 de forma predeterminada ). A este cliente lo llamamos agente de usuario . Algunos recursos, como archivos HTML e imágenes, se almacenan en el servidor de respuesta. A este servidor de respuesta lo llamamos servidor de origen . Puede haber varias "capas intermedias" entre el agente de usuario y el servidor de origen, como servidores proxy, puertas de enlace o túneles.
Aunque el protocolo TCP/IP es la aplicación más popular en Internet, en el protocolo HTTP no es necesario utilizarlo ni las capas que admite . De hecho, HTTP se puede implementar en cualquier protocolo de Internet u otra red. HTTP supone que sus protocolos subyacentes proporcionan un transporte confiable . Por lo tanto, puede utilizar cualquier protocolo que pueda ofrecer tales garantías. Por lo tanto, utiliza TCP como capa de transporte en la familia de protocolos TCP/IP.
Por lo general, el cliente HTTP inicia una solicitud para crear una conexión TCP al puerto especificado del servidor (puerto 80 de forma predeterminada). El servidor HTTP escucha las solicitudes de los clientes en ese puerto. Una vez recibida la solicitud, el servidor devolverá un estado al cliente, como "HTTP/1.1 200 OK", y el contenido devuelto, como el archivo solicitado, mensaje de error u otra información.
3.2 Principio de funcionamiento
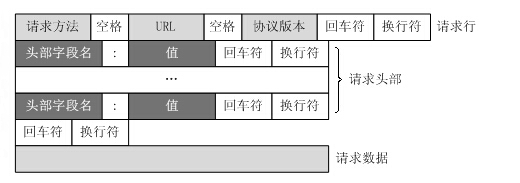
El protocolo HTTP define cómo un cliente web solicita una página web de un servidor web y cómo el servidor transmite una página web al cliente. El protocolo HTTP emplea un modelo de solicitud/respuesta. El cliente envía un mensaje de solicitud al servidor, y el mensaje de solicitud incluye el método de solicitud, la URL, la versión del protocolo, el encabezado de la solicitud y los datos de la solicitud. El servidor responde con una línea de estado que incluye la versión del protocolo, el código de éxito o error, información del servidor, encabezados de respuesta y datos de respuesta.
Pasos para la solicitud/respuesta HTTP:
0. Resolución de dirección IP
El navegador solicita al servidor DNS que resuelva la dirección IP correspondiente al nombre de dominio en la URL
1. El cliente se conecta al servidor web.
Un cliente HTTP, generalmente un navegador, establece una conexión de socket TCP con el puerto HTTP (80 por defecto) del servidor web . Por ejemplo, http://www.baidu.com. (URL)
2. Enviar solicitud HTTP
A través del socket TCP, el cliente envía un mensaje de solicitud de texto al servidor web. Un mensaje de solicitud consta de cuatro partes: línea de solicitud, encabezado de solicitud, línea en blanco y datos de solicitud . (El mensaje de solicitud se envía al servidor como los datos del tercer mensaje del protocolo de enlace de tres vías TCP)
3. El servidor acepta la solicitud y devuelve una respuesta HTTP.
El servidor web analiza la solicitud y localiza el recurso solicitado. El servidor escribe una copia del recurso en un socket TCP, que el cliente lee. Una respuesta consta de 4 partes: línea de estado, encabezado de respuesta, línea en blanco y datos de respuesta .
4. Libere la conexión TCP
Si el modo de conexión es cerrado , el servidor cerrará activamente la conexión TCP y el cliente cerrará pasivamente la conexión y liberará la conexión TCP; si el modo de conexión es mantener vivo , la conexión se mantendrá durante un período de tiempo, durante el cual podrá continuar recibiendo solicitudes.
5. El navegador del cliente analiza el contenido HTML.
El navegador del cliente primero analiza la línea de estado, buscando un código de estado que indique si la solicitud fue exitosa. Luego se analiza cada encabezado de respuesta, lo que indica el siguiente documento HTML en bytes y el conjunto de caracteres del documento. El navegador del cliente lee los datos de respuesta HTML, los formatea según la sintaxis de HTML y los muestra en la ventana del navegador.
3.3 Formato del mensaje de solicitud/respuesta
El protocolo HTTP/1.1 define ocho métodos de solicitud (también llamados "acciones") para operar recursos específicos de diferentes maneras:
1. OBTENER:
realice una solicitud de "visualización" al recurso especificado. El uso del método GET solo debe usarse para leer datos y no debe usarse para operaciones de "efectos secundarios", como en una aplicación web. Una razón para esto es que las arañas web y similares pueden acceder a GET aleatoriamente.
2. HEAD:
Al igual que el método GET, envía una solicitud de un recurso específico al servidor. Es solo que el servidor no devolverá la parte de texto del recurso. Su ventaja es que mediante este método se puede obtener "información sobre el recurso" (metada información o metadatos) sin tener que transmitir todo el contenido.
3. PUBLICAR:
envíe datos al recurso especificado y solicite al servidor su procesamiento (como enviar un formulario o cargar un archivo). Los datos se incluyen en el cuerpo de la solicitud. Esta solicitud puede crear un nuevo recurso o modificar un recurso existente, o ambas cosas.
4. PUT: cargue el contenido más reciente en la ubicación de recursos especificada.
5. ELIMINAR: Solicite al servidor que elimine el recurso identificado por el URI de solicitud.
6. TRACE: Hacer eco de la solicitud recibida por el servidor, principalmente para pruebas o diagnóstico.
7. OPCIONES:
este método permite que el servidor devuelva todos los métodos de solicitud HTTP admitidos por el recurso. Utilice '*' para reemplazar el nombre del recurso y envíe una solicitud de OPCIONES al servidor web para probar si la función del servidor funciona normalmente.
8. CONECTAR:
Reservado en el protocolo HTTP/1.1 para un servidor proxy que puede cambiar la conexión a una canalización. Normalmente se utiliza para conexiones a servidores cifrados con SSL (a través de servidores proxy HTTP no cifrados).
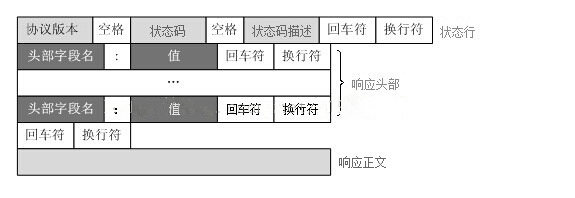
La primera línea de todas las respuestas HTTP es la línea de estado , que consta del número de versión HTTP, un código de estado de 3 dígitos y
una frase que describe el estado, separados por espacios.
El primer dígito del código de estado representa el tipo de respuesta actual:
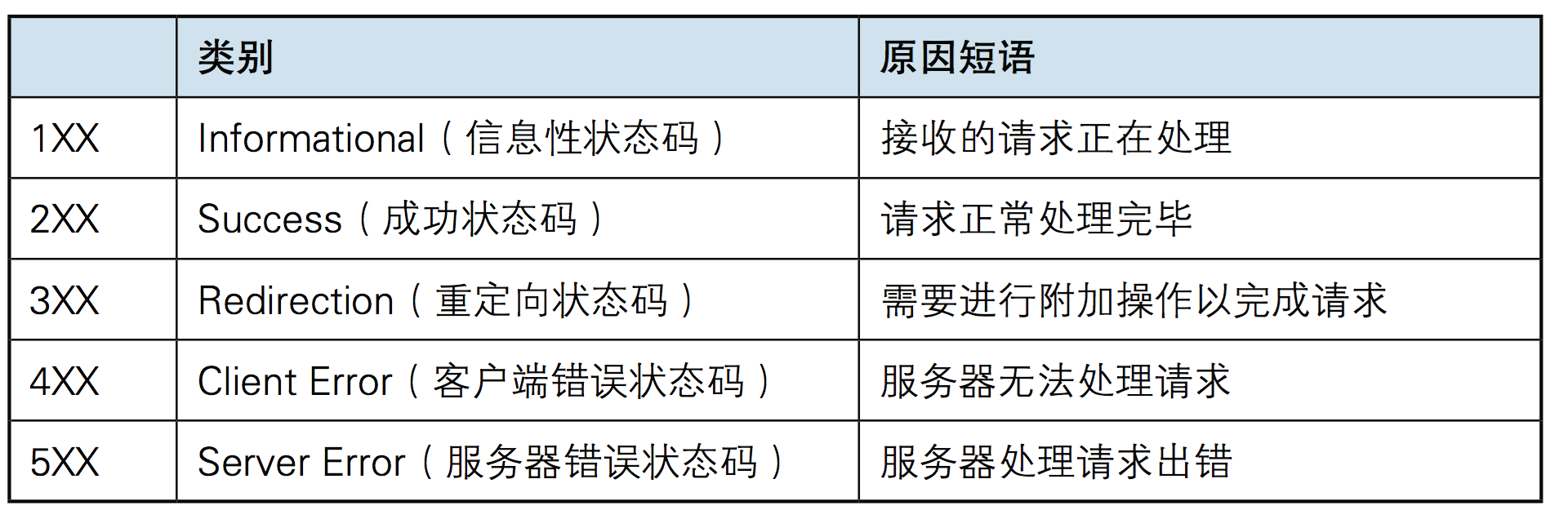
Aunque RFC 2616 recomienda frases para describir el estado, como "200 OK" y "404 No encontrado", los desarrolladores WEB aún pueden decidir qué frases usar para mostrar descripciones de estado localizadas o información personalizada.
4. El marco básico de la programación de servidores.
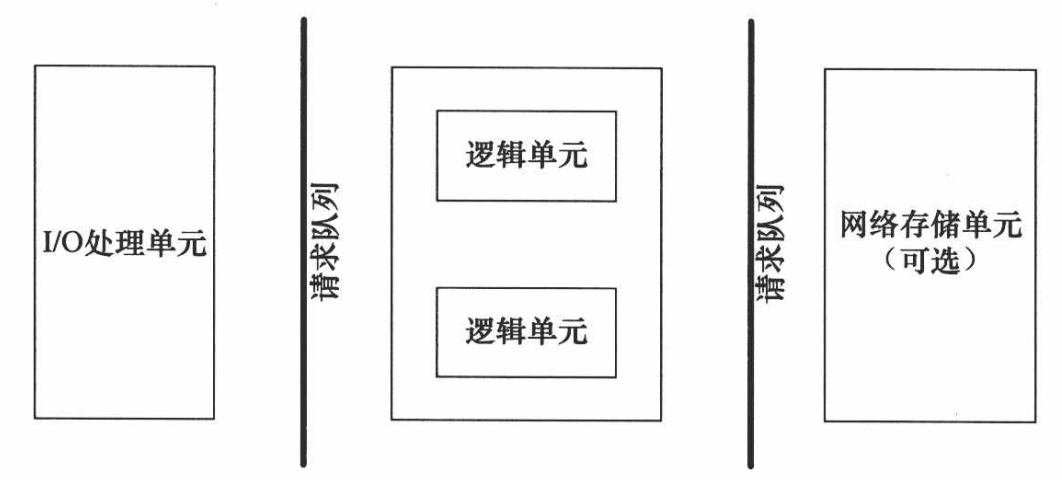
| módulo | Función |
|---|---|
| unidad de procesamiento de E/S | Manejar conexiones de clientes, leer y escribir datos de red. |
| unidad lógica | proceso o hilo de negocio |
| unidad de almacenamiento en red | base de datos, archivo o caché |
| cola de solicitudes | Método de comunicación entre cada unidad. |
La unidad de procesamiento de E/S es el módulo en el que el servidor gestiona las conexiones del cliente. Por lo general, completa las siguientes tareas: esperar y aceptar nuevas conexiones de clientes, recibir datos del cliente y devolver datos de respuesta del servidor al cliente. Sin embargo, el envío y la recepción de datos no se realizan necesariamente en la unidad de procesamiento de E/S , sino que también se pueden realizar en la unidad lógica, y la ubicación de ejecución específica depende del modo de procesamiento de eventos.
Una unidad lógica suele ser un proceso o hilo. Analiza y procesa datos del cliente y luego pasa los resultados a la unidad de procesamiento de E/S o directamente al cliente (según el modo de procesamiento de eventos). Un servidor suele tener varias unidades lógicas para implementar el procesamiento simultáneo de múltiples tareas del cliente.
Las unidades de almacenamiento de red pueden ser bases de datos, cachés y archivos, pero no son necesarias.
Una cola de solicitudes es una abstracción de cómo se comunican las unidades. Cuando una unidad de procesamiento de E/S recibe una solicitud de un cliente, necesita notificar de alguna manera a una unidad lógica para que procese la solicitud. De manera similar, cuando varias unidades lógicas acceden a una unidad de almacenamiento al mismo tiempo, también se requiere algún mecanismo para coordinar y abordar las condiciones de carrera. Las colas de solicitudes generalmente se implementan como parte de un grupo (grupo de procesos/grupo de subprocesos).
5. Modo de procesamiento de eventos
Los programas de servidor normalmente necesitan manejar tres tipos de eventos: eventos de E/S, señales y eventos de temporización.
Hay dos modos eficientes de procesamiento de eventos: Reactor y Proactor.
El modelo de E/S síncrono generalmente se usa para implementar el modo Reactor y
el modelo de E/S asíncrono generalmente se usa para implementar el modo Proactor.
5.1 Modo reactor
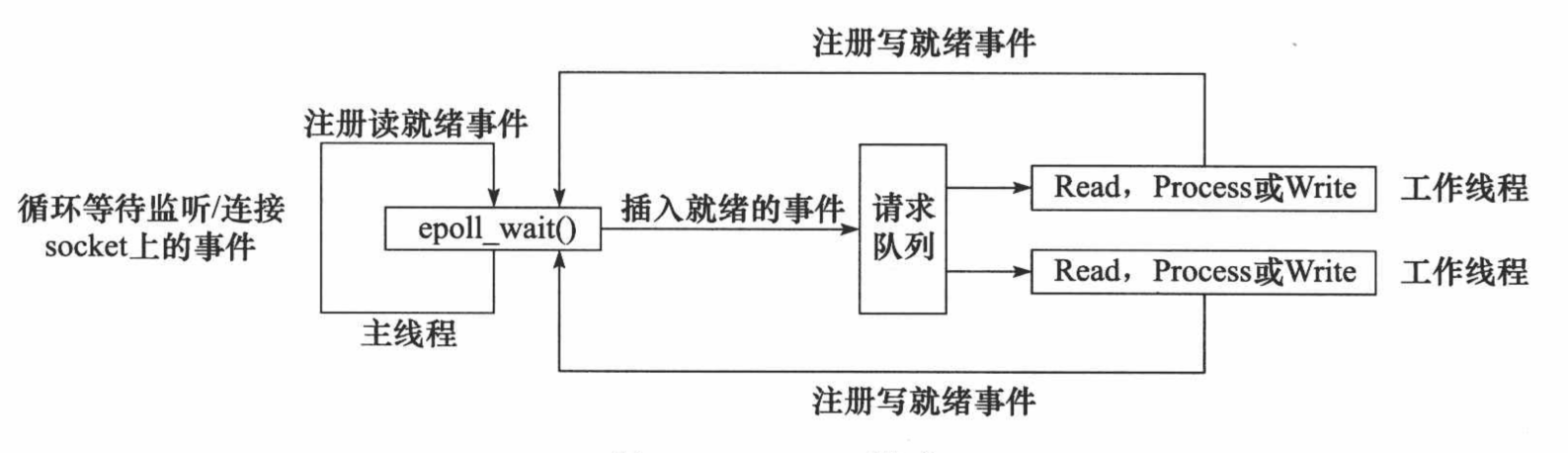
El modo reactor requiere que el subproceso principal (unidad de procesamiento de E/S) solo sea responsable de monitorear si hay un evento en el descriptor de archivo y, de ser así, notificar inmediatamente al subproceso de trabajo (unidad lógica) del evento y colocar el socket. evento legible y grabable en la solicitud. La cola se entrega al hilo de trabajo para su procesamiento. Aparte de eso, el hilo principal no realiza ningún otro trabajo sustancial. La lectura y escritura de datos, la aceptación de nuevas conexiones y el manejo de solicitudes de clientes se realizan en subprocesos de trabajo.
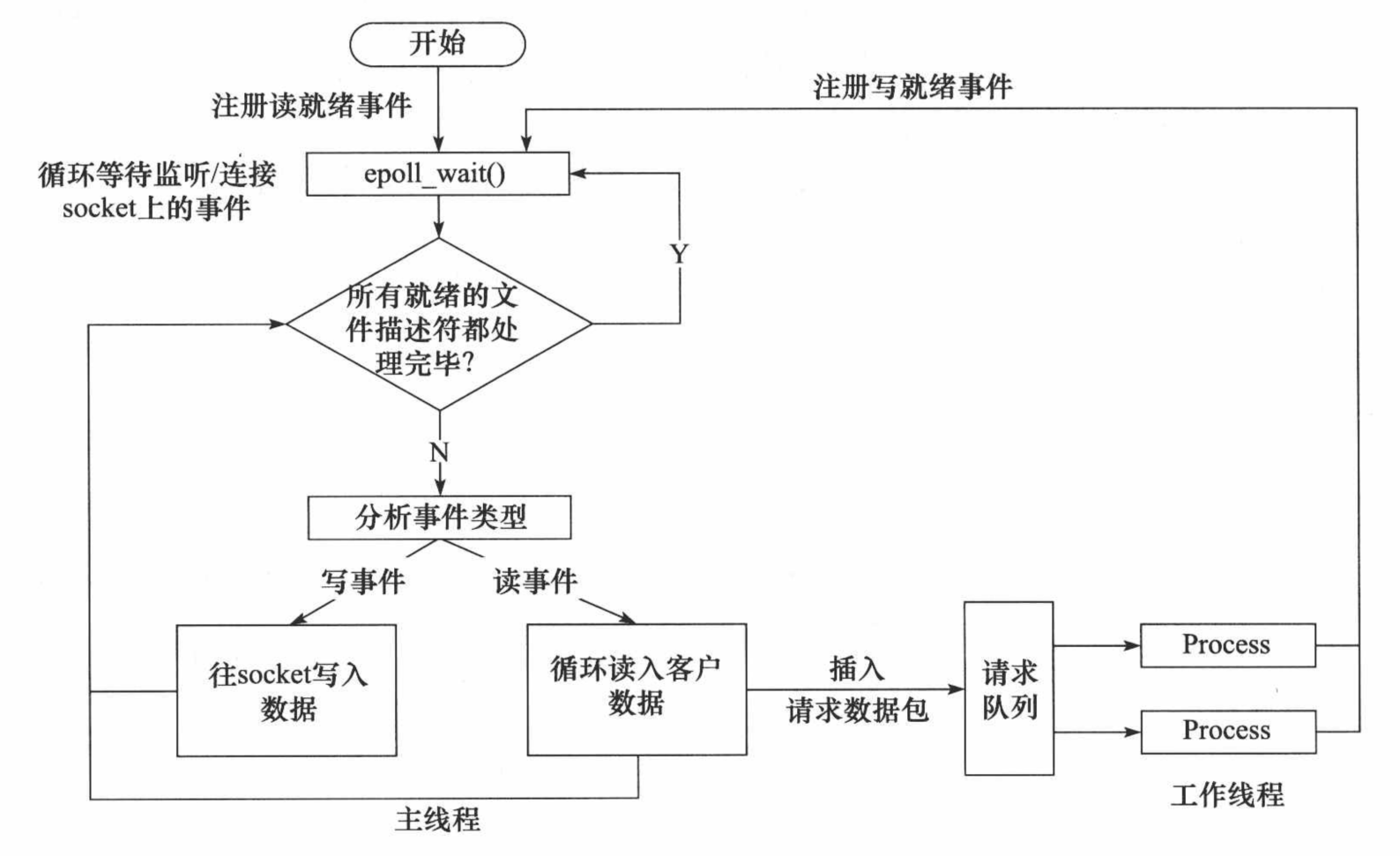
El flujo de trabajo del modo Reactor implementado usando E/S síncrona (tome epoll_wait como ejemplo) es:
1. El hilo principal registra el evento de lectura lista en el socket en la tabla de eventos del kernel de epoll.
2. El hilo principal llama a epoll_wait para esperar a que se lean los datos en el socket.
3. Cuando hay datos legibles en el socket, epoll_wait notifica al hilo principal. El hilo principal coloca eventos legibles por socket en la cola de solicitudes.
4. Se despierta un subproceso de trabajo que duerme en la cola de solicitudes, lee datos del socket, procesa la solicitud del cliente y luego registra el evento de escritura lista en el socket en la tabla de eventos del kernel de epoll.
5. Cuando el hilo principal llama a epoll_wait, espera a que se pueda escribir en el socket.
6. Cuando se puede escribir en el socket, epoll_wait notifica al hilo principal. El hilo principal coloca eventos grabables en el socket en la cola de solicitudes.
7. Se despierta un subproceso de trabajo que duerme en la cola de solicitudes y escribe el resultado del servidor que procesa la solicitud del cliente en el socket.
5.2 Modo proactor
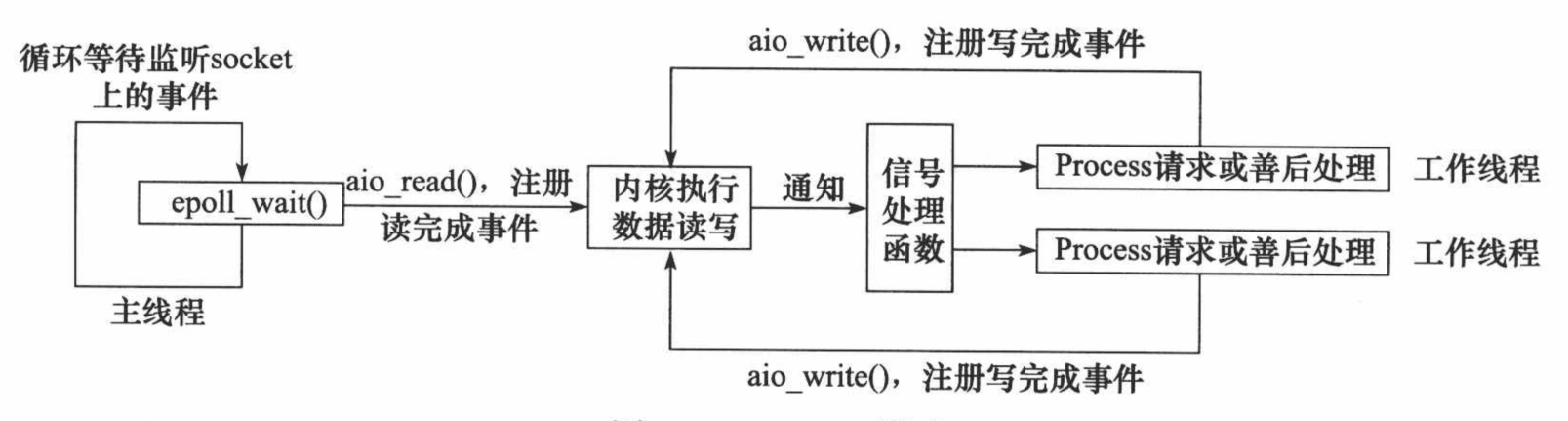
En el modo Proactor , todas las operaciones de E/S se entregan al hilo principal y al kernel para su procesamiento (para lectura y escritura), y el hilo de trabajo solo es responsable de la lógica empresarial. El flujo de trabajo del modo Proactor implementado utilizando el modelo de E/S asíncrono (tome aio_read y aio_write como ejemplos) es:
1. El hilo principal llama a la función aio_read para registrar el evento de finalización de lectura en el socket con el kernel y le dice al kernel la ubicación del búfer de lectura del usuario y cómo notificar a la aplicación cuando se completa la operación de lectura (aquí, tome una señal como ejemplo).
2. El hilo principal continúa procesando otra lógica.
3. Cuando los datos del socket se leen en el búfer del usuario, el kernel enviará una señal a la aplicación para notificarle que los datos están disponibles.
4. La función de procesamiento de señales predefinida del programa de aplicación selecciona un subproceso de trabajo para procesar la solicitud del cliente. Una vez que el subproceso de trabajo termina de procesar la solicitud del cliente, llama a la función aio_write para registrar el evento de finalización de escritura en el socket con el kernel y le dice al kernel la posición del búfer de escritura del usuario y cómo notificar a la aplicación cuando se realiza la operación de escritura. esta completado.
5. El hilo principal continúa procesando otra lógica.
6. Después de que los datos en el búfer del usuario se escriben en el socket, el kernel enviará una señal a la aplicación para notificarle que los datos se han enviado.
7. La función de procesamiento de señales predefinida del programa de aplicación selecciona un subproceso de trabajo para realizar el procesamiento posterior, como decidir si cerrar el socket.
5.3 Simular el modo Proactor
Simula el modo Proactor usando E/S sincrónicas .
El principio es: el hilo principal realiza operaciones de lectura y escritura de datos, y una vez completada la lectura y escritura, el hilo principal notifica al hilo de trabajo sobre este "evento de finalización" . Luego, desde la perspectiva de los subprocesos de trabajo , obtienen directamente los resultados de la lectura y escritura de datos, y lo siguiente que deben hacer es procesar lógicamente los resultados de la lectura y escritura.
El flujo de trabajo del modo Proactor simulado utilizando el modelo de E/S síncrono (tomando epoll_wait como ejemplo) es el siguiente:
1. El hilo principal registra el evento de lectura lista en el socket en la tabla de eventos del kernel de epoll.
2. El hilo principal llama a epoll_wait para esperar a que se lean los datos en el socket.
3. Cuando hay datos legibles en el socket, epoll_wait notifica al hilo principal. El hilo principal realiza un bucle para leer datos del socket hasta que no hay más datos para leer, luego encapsula los datos leídos en un objeto de solicitud y los inserta en la cola de solicitudes.
4. Se despierta un subproceso de trabajo que duerme en la cola de solicitudes, obtiene el objeto de solicitud, procesa la solicitud del cliente y luego registra el evento de escritura lista en el socket en la tabla de eventos del kernel de epoll.
5. El hilo principal llama a epoll_wait para esperar a que se pueda escribir en el socket.
6. Cuando se puede escribir en el socket, epoll_wait notifica al hilo principal. El hilo principal escribe el resultado del servidor que procesa la solicitud del cliente en el socket.
6. Grupo de subprocesos
En la programación orientada a objetos, crear y destruir objetos lleva mucho tiempo, porque crear un objeto requiere adquirir recursos de memoria u otros recursos adicionales. Por lo tanto, una forma de mejorar la eficiencia de los programas de servicio es reducir al máximo la cantidad de creación y destrucción de objetos , especialmente la creación y destrucción de algunos objetos que consumen muchos recursos. Cómo utilizar objetos existentes para servir es un problema clave que debe resolverse. De hecho, esta es la razón por la que algunas tecnologías de "agrupación de recursos" El grupo de subprocesos proporciona una solución al problema de la sobrecarga del ciclo de vida de los subprocesos y la escasez de recursos.
El grupo de subprocesos mantiene varios subprocesos, esperando que el supervisor asigne tareas que se puedan ejecutar al mismo tiempo. Esto evita el costo de crear y destruir subprocesos al procesar tareas de corta duración . El grupo de subprocesos no solo puede garantizar la utilización completa del núcleo , sino también evitar una programación excesiva.
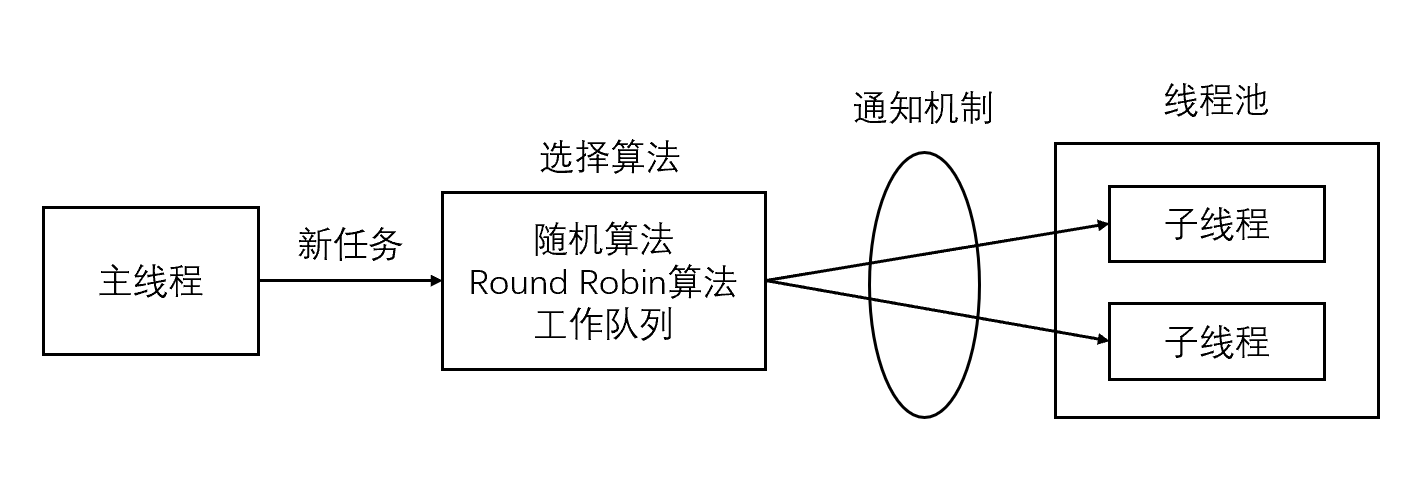
El grupo de subprocesos es un grupo de subprocesos creados previamente por el servidor, y la cantidad de subprocesos en el grupo de subprocesos debe ser similar a la cantidad de CPU. Todos los subprocesos secundarios del grupo de subprocesos ejecutan el mismo código . Cuando llega una nueva tarea, el hilo principal seleccionará un hilo secundario en el grupo de hilos para servirla de alguna manera. En comparación con la creación dinámica de subprocesos, el costo de seleccionar un subproceso existente es obviamente mucho menor. En cuanto a qué subproceso secundario elige el subproceso principal para realizar la nueva tarea, hay muchas formas:
- El hilo principal utiliza algún algoritmo para seleccionar activamente hilos secundarios . Los algoritmos más simples y más utilizados son el algoritmo aleatorio y el algoritmo Round Robin (selección por turnos), pero los algoritmos mejores y más inteligentes distribuirán las tareas de manera más uniforme entre cada subproceso de trabajo, reduciendo así la presión general sobre el servidor.
- El subproceso principal y todos los subprocesos secundarios se sincronizan a través de una cola de trabajo compartida en la que duermen los subprocesos secundarios. Cuando llega una nueva tarea, el hilo principal agrega la tarea a la cola de trabajos. Esto despertará los subprocesos secundarios que están esperando la tarea, pero solo un subproceso secundario obtendrá la "toma de control" de la nueva tarea , puede tomar la tarea de la cola de trabajos y ejecutarla, mientras que los otros subprocesos secundarios continuarán. dormir en la cola del trabajo.
Al crear un grupo de subprocesos, puede establecer el número máximo de subprocesos y el número mínimo de subprocesos en el grupo de subprocesos ;
cuando no hay tareas en la cola de tareas, el grupo de subprocesos se bloquea en la variable de condición y espera la tarea;
cuando entra una tarea, la variable de condición envía una señal o transmite para despertar. Los subprocesos son recursos compartidos para las colas de tareas en este momento y es necesario utilizar mutex para evitar conflictos de recursos.
La escalabilidad del grupo de subprocesos tiene un mayor impacto en el rendimiento.
1. Crear demasiados subprocesos desperdiciará ciertos recursos y algunos subprocesos no se utilizarán por completo.
2. Destruir demasiados hilos hará perder tiempo al crearlos nuevamente más tarde.
3. Crear subprocesos con demasiada lentitud provocará largas esperas y un rendimiento deficiente.
4. La destrucción de subprocesos es demasiado lenta, lo que provoca la escasez de otros recursos de subprocesos.
Los componentes principales del grupo de subprocesos :
1. Administrador del grupo de subprocesos (ThreadPoolManager): se utiliza para crear y administrar el grupo de subprocesos;
2. Subproceso de trabajo (WorkThread): subprocesos en el grupo de subprocesos;
3. Interfaz de tarea (Tarea): cada tarea must La interfaz implementada se utiliza para la ejecución de las tareas de programación del hilo de trabajo
4. Cola de tareas: se utiliza para almacenar tareas no procesadas. Proporciona un mecanismo de amortiguación.
Los escenarios de aplicación del grupo de subprocesos :
1. Se requiere una gran cantidad de subprocesos para completar la tarea y el tiempo para completar la tarea es relativamente corto; 2.
Aplicaciones con requisitos de rendimiento estrictos;
3. Aceptar una gran cantidad de solicitudes repentinas , pero no hará que el servidor falle. Aplicaciones con una gran cantidad de subprocesos.
El factor limitante más directo para la cantidad de subprocesos en el grupo de subprocesos es la cantidad N de procesadores (procesadores/núcleos) de la unidad central de procesamiento (CPU): si su CPU tiene 4 núcleos, para tareas que requieren un uso intensivo de la CPU (como edición de video Para tareas que consumen recursos informáticos de la CPU), es mejor establecer el número de subprocesos en el grupo de subprocesos en 4 (o +1 para evitar el bloqueo de subprocesos causado por otros factores); para tareas con uso intensivo de IO, generalmente más que la CPU El número de núcleos , porque la competencia entre subprocesos no son los recursos informáticos de la CPU sino IO , y el procesamiento de IO generalmente es lento. Los subprocesos con más núcleos lucharán por más tareas para la CPU, de modo que la CPU no estará inactiva durante el procesamiento del subproceso. El proceso de IO conduce al desperdicio de recursos.
- Se intercambia espacio por tiempo , desperdiciando recursos de hardware del servidor a cambio de eficiencia operativa.
- Un grupo es una colección de recursos que se crean e inicializan completamente cuando se inicia el servidor y se denomina recurso estático .
- Cuando el servidor ingresa a la etapa de operación formal y comienza a procesar las solicitudes de los clientes, si necesita recursos relacionados, se puede obtener directamente del grupo sin asignación dinámica .
- Cuando el servidor termina de procesar una conexión de cliente, puede volver a colocar los recursos relacionados en el grupo, sin ejecutar llamadas al sistema para liberar recursos.
7. Máquina de estados finitos
Un método de programación eficiente dentro de la unidad lógica: máquina de estados finitos (máquina de estados finitos) .
Algunos encabezados de protocolo de capa de aplicación contienen campos de tipo de paquete de datos, y cada tipo se puede asignar a un estado de ejecución de una unidad lógica, y el servidor puede escribir la lógica de procesamiento correspondiente en función de él. La siguiente es una máquina de estados finitos independiente del estado :
STATE_MACHINE( Package _pack )
{
PackageType _type = _pack.GetType();
switch( _type )
{
case type_A: // 状态A
process_package_A( _pack );
break;
case type_B: // 状态B
process_package_B( _pack );
break;
}
}
Esta es una máquina de estados finitos simple, excepto que cada estado de la máquina de estados es independiente entre sí, es decir, no hay transición entre estados. La transición entre estados requiere el disco interno de la máquina de estados, como se muestra en el siguiente código:
STATE_MACHINE()
{
State cur_State = type_A;
while( cur_State != type_C ) // 停止状态
{
Package _pack = getNewPackage();
switch( cur_State )
{
case type_A: // 状态A处理 -> 状态B
process_package_state_A( _pack );
cur_State = type_B; // 状态转换
break;
case type_B: // 状态B处理 -> 状态C
process_package_state_B( _pack );
cur_State = type_C; // 状态转换
break;
}
}
}La máquina de estados contiene tres estados: tipo_A, tipo_B y tipo_C, donde tipo_A es el estado inicial de la máquina de estados y tipo_C es el estado final de la máquina de estados. El estado actual de la máquina de estados se registra en la variable cur_State. Durante un ciclo, la máquina de estado primero obtiene un nuevo paquete de datos a través del método getNewPackage y luego juzga cómo procesar el paquete de datos de acuerdo con el valor de la variable cur_State. Una vez procesado el paquete de datos, la máquina de estado realiza la transición de estado pasando el valor del estado objetivo a la variable cur_State. Luego, cuando la máquina de estados ingrese al siguiente ciclo, ejecutará la lógica correspondiente al nuevo estado.
9. Evento EPOLLONESHOT
Incluso si se puede utilizar el modo ET , un evento en un socket puede activarse varias veces . Esto puede causar un problema en programas concurrentes. Por ejemplo, un hilo comienza a procesar los datos después de leer los datos en un determinado socket, y durante el proceso de procesamiento de datos, hay nuevos datos para leer en el socket (EPOLLIN se activa nuevamente) y se activa otro hilo. en este momento Lea estos nuevos datos. Entonces existe una situación en la que dos subprocesos operan un socket al mismo tiempo . Una conexión de socket solo es procesada por un subproceso a la vez , lo que se puede lograr utilizando el evento EPOLLONESHOT de epoll.
Para el descriptor de archivo registrado con el evento EPOLLONESHOT, el sistema operativo activa como máximo un evento legible, escribible o anormal registrado en él, y solo se activa una vez , a menos que usemos la función epoll_ctl para restablecer el evento EPOLLONESHOT registrado en el descriptor de archivo.
De esta manera, cuando un subproceso está procesando un determinado socket, es imposible que otros subprocesos tengan la oportunidad de operar el socket. Pero pensándolo al revés, una vez que un hilo procesa el socket registrado con el evento EPOLLONESHOT , el hilo debe restablecer inmediatamente el evento EPOLLONESHOT en el socket para garantizar que el evento EPOLLONESHOT se pueda activar cuando el socket sea legible la próxima vez. Esto, a su vez, brinda a otros subprocesos de trabajo la oportunidad de continuar procesando el socket.
10. Prueba de estrés del servidor
Webbench es una excelente y conocida herramienta de pruebas de estrés de rendimiento web en Linux. Está desarrollado por Lionbridge Corporation.
- Pruebe el rendimiento de diferentes servicios en el mismo hardware y el funcionamiento del mismo servicio en diferentes hardware .
- Muestra dos cosas sobre el servidor: la cantidad de solicitudes de respuesta por segundo y la cantidad de datos transmitidos por segundo .
Principio básico: Webbench primero bifurca múltiples subprocesos y cada subproceso realiza pruebas de acceso web en un bucle. El proceso hijo le dice al proceso padre el resultado del acceso a través de la tubería, y el proceso padre hace las estadísticas finales.
webbench -c 1000 -t 30 http://192.168.15.128:9999/index.html
参数:
-c 表示客户端数
-t 表示时间
11. Manejo de números de señal y error.
11.1 TUBO DE SEGURIDAD
En la programación de redes, la señal SIGPIPE es muy común. ( enlace de referencia )
La señal SIGPIPE se activará cuando los datos se escriban continuamente (segundo) en una conexión de tubería o enchufe que esté cerrada por el extremo de escritura , y la operación de escritura que activa la señal SIGPIPE establecerá errno en EPIPE .
En la comunicación TCP, cuando una de las partes de la comunicación cierra la conexión, si la otra parte continúa enviando datos, de acuerdo con las disposiciones del protocolo TCP, recibirá un mensaje de respuesta RST. Si vuelve a enviar datos a este servidor, el El sistema enviará una señal SIGPIPE al proceso, indicándole que la conexión se ha desconectado y que no se pueden escribir más datos.

El comportamiento predeterminado de la señal SIGPIPE es finalizar el proceso y definitivamente no queremos que el programa se cierre debido a un error de operación de escritura, especialmente como programa de servidor. Así que debemos lidiar con esta señal. Aquí presentamos dos formas de lidiar con la señal SIGPIPE:
- Configure la función de procesamiento de señal SIG_IGN para SIGPIPE, ignore esta señal
signal(SIGPIPE, SIG_IGN);Una operación de escritura que genera la señal SIGPIPE establecerá errno en EPIPE.
Por lo tanto, al escribir datos en el socket cerrado por segunda vez, se devolverá -1 y errno se establecerá en EPIPE. De esta manera, puede saber que el extremo del par se ha cerrado y luego tratarlo en consecuencia sin provocar que se cierre todo el proceso.
- Utilice el indicador MSG_NOSIGNAL de la función de envío para evitar que las operaciones de escritura activen la señal SIGPIPE
send(sockfd , buf , size , MSG_NOSIGNAL);De manera similar, podemos juzgar si el extremo de lectura del socket está cerrado de acuerdo con el error enviado por la función de envío.
Además, también podemos utilizar la función de multiplexación IO para detectar si el extremo de lectura de la conexión de tubería y enchufe se ha cerrado. Tome la encuesta como ejemplo: cuando la otra parte cierra la conexión del socket, se activará el evento POLLRDHUP en el socket .
11.2 Interrupción del sistema, EINTR y SA_RESTART
Una llamada lenta al sistema es una llamada a función que bloqueará , generalmente una llamada IO o una función con un bloqueo. Como aceptar , leer, esperar, sem_timedwait, etc., estas funciones pueden bloquear el proceso actual durante un período de tiempo, por lo que son "lentas". ( enlace de referencia )
Durante el período de bloqueo, el proceso puede recibir algunas señales del kernel. Estas señales tienen alta prioridad y deben procesarse primero. La señal no se puede procesar hasta que se completen estas llamadas. Entonces, el sistema primero procesa la señal y luego obliga a estas funciones a regresar en forma de error . El código de error errno es EINTR y la descripción del error correspondiente es "Llamada al sistema interrumpida". Todo este proceso es una interrupción del sistema .
Para evitar la parada inesperada del programa causada por señales normales, necesitamos procesar estas señales, los métodos comunes son:
- Reiniciar artificialmente las llamadas al sistema interrumpidas (más confiable y efectiva)
Cuando se ejecutan algunas llamadas al sistema IO, como la lectura en espera de entrada, si se recibe una señal, el sistema interrumpirá la lectura y ejecutará la función de procesamiento de señal. Después de que regresa la función de procesamiento, la llamada al sistema original falla, devuelve -1 y establece errno en EINTR. Una llamada al sistema interrumpida es una llamada incompleta. Su falla es temporal. Si se llama nuevamente, puede tener éxito. Esto no es una falla real, por lo que esta situación debe manejarse:
while(!stop){
int num = epoll_wait(epoll_fd, events, MAX_EVENT_SIZE, -1); // 阻塞,返回事件数量
if(num < 0 && errno != EINTR){ // 这里忽略了返回的EINTR错误号,并往下执行
EMlog(LOGLEVEL_ERROR,"EPOLL failed.\n");
break;
}
....
}-
Establezca la propiedad SA_RESTART al instalar la señal
Para resolver este problema desde el punto de vista de la señal, al instalar la señal, configure el atributo SA_RESTART , luego, cuando la función de procesamiento de señal regrese, la llamada al sistema no dejará de regresar, pero la llamada al sistema interrumpida por la señal se reanudará automáticamente. .
Ejemplo:
La señal del despertador SIGALRM interrumpe la llamada al sistema de lectura. Si el atributo SA_RESTART no se establece al instalar la señal SIGALRM, la señal interrumpirá la llamada del sistema de lectura. Si se establece el atributo SA_RESTART, la lectura podrá restaurar la llamada del sistema sin generar un error EINTR.
struct sigaction action;
action.sa_handler = handler_func;
sigemptyset(&action.sa_mask);
action.sa_flags = 0;
/* 设置SA_RESTART属性 */
action.sa_flags |= SA_RESTART;
sigaction(SIGALRM, &action, NULL);Sin embargo, tenga en cuenta que no todas las llamadas al sistema se pueden restaurar automáticamente . Por ejemplo, cuando msgsnd/msgrcv envía/recibe mensajes en modo bloque, se interrumpirá porque el proceso recibe una señal. En este punto, msgsnd/msgrcv devolverá -1 y errno se establecerá en EINTR. E incluso si se configura SA_RESTART al insertar la señal, no tiene ningún efecto.
- ignorar la señal
Al instalar una señal, indique explícitamente al sistema que no se generarán interrupciones para esa señal.
struct sigaction action;
action.sa_handler = SIG_IGN;
sigemptyset(&action.sa_mask);
sigaction(SIGALRM, &action, NULL);11.3 OTRA VEZ
El código de error EAGAIN , literalmente, es un mensaje para volver a intentarlo .
Este error ocurre a menudo cuando la aplicación realiza algunas operaciones sin bloqueo (en archivos o sockets). Para sockets sin bloqueo, EAGAIN no es un error. En VxWorks y Windows, EAGAIN se llama EWOULDBLOCK .
// 接收一个socket连接
int cfd = accept(lfd, (struct sockaddr *)&cliaddr, &len);
// 设置非阻塞
int flag = fcntl(cfd, F_GETFL);
flag |= O_NONBLOCK;
fcntl(cfd, F_SETFL, flag);Por ejemplo, abra el archivo /socket/FIFO con el indicador O_NONBLOCK, si realiza una operación de lectura continua y no hay datos para leer. En este momento, el programa no se bloqueará y esperará a que los datos estén listos para regresar, la función de lectura devolverá -1 y establecerá errno en EAGAIN, indicando a su aplicación que no hay datos para leer ahora, inténtelo nuevamente más tarde. .
Solución:
Juzgue el resultado devuelto y el error correspondiente, omita cuando se lean los datos y agregue el socket al monitoreo de eventos legibles de epoll.
// 添加epoll节点,设置边沿触发 epev.events = EPOLLIN | EPOLLET; epev.data.fd = cfd; epoll_ctl(epfd, EPOLL_CTL_ADD, cfd, &epev); while((len = read(curfd, buf, sizeof(buf))) > 0 ){ // 循环读完所有数据 printf("recv data : %s\n", buf); write(curfd, buf, len); } if(len == -1) { if(errno == EAGAIN) { // socket为非阻塞且数据被读完时,会返回EAGAIN错误号 printf("data over...\n"); }else { perror("read"); exit(-1); } } else if(len == 0) { printf("client closed...\n"); epoll_ctl(epfd, EPOLL_CTL_DEL, curfd, NULL); close(curfd); }
Por ejemplo, cuando la aplicación establece el atributo O_NONBLOCK en el socket, si el búfer de envío está lleno, el envío devolverá un error EAGAIN.
Si se produce un error EAGAIN en la función de envío, no se debe llamar a la función de envío para enviar datos hasta que se pueda escribir en el estado actual del socket. Antes de enviar datos, agregue EPOLLOUT al evento de monitoreo del socket y cancele el monitoreo de EPOLLOUT después de enviar todos los datos.
O cuando comience a enviar datos al socket, primero inserte los datos en el búfer de envío y agregue el socket al detector de eventos grabable. Cuando el socket activa un evento de escritura (EPOLLOUT), llame a la función socket_send para enviar datos y, una vez enviados todos los datos, borre el estado listo de EPOLLOUT.
Por ejemplo, cuando una llamada al sistema (como una bifurcación) falla porque no hay suficientes recursos (como la memoria virtual), devuelva EAGAIN para solicitarle que vuelva a llamar (tal vez tenga éxito la próxima vez).
12. Diagrama de bloques del proyecto
Marco técnico:
1. Grupo de subprocesos + socket sin bloqueo + epoll + modelo de concurrencia de procesamiento de eventos
2. Máquina de estado que analiza solicitudes HTTP
3. Mecanismo de latido
4. Sistema de registro simple
contenido principal:
1. Utilice socket para realizar la comunicación entre el servidor y el cliente del navegador;
2. Utilice la tecnología de detección de eventos epoll para realizar la multiplexación de IO y mejorar la eficiencia operativa;
3. Adopte un modo de procesamiento de eventos que simule Proactor y utilice un grupo de subprocesos para implementar un mecanismo de subprocesos múltiples , Logre una alta comunicación concurrente y reduzca la sobrecarga causada por la creación y destrucción frecuente de subprocesos (señales y mutex)
4. El proceso principal es responsable de leer y escribir eventos, y los subprocesos son responsables de la lógica empresarial, utilizando un finito máquina de estado para analizar el mensaje de solicitud HTTP (GET); generar el mensaje de respuesta correspondiente.
5. Utilice la estructura de datos de la lista vinculada para implementar el mecanismo de latido (procesamiento de detección de tiempo de espera).

Dirección de descarga: archivo
Contraseña: webt