Prefácio: Em meu blog anterior, apresentei dois tipos de como usar SpringBoot para construir operações de múltiplas fontes de dados.Neste blog, refiro-me à estrutura principal atual e explico a última maneira de integrar múltiplas fontes de dados na forma de um blog., o processo de integração é relativamente tradicional e complicado, mas ainda explicarei claramente a ideia de cada classe de entidade para todos e fornecerei o endereço do código-fonte do Gitee no final do projeto.
Blogs anteriores:
O primeiro: SpringBoot + Jpa configura múltiplas fontes de dados Oracle (o código-fonte do Gitee é fornecido)
O segundo tipo: SpringBoot + Mybatis constrói uma breve descrição da configuração da fonte de vários dados Oracle (o código-fonte do Gitee é fornecido)
Adições subsequentes:
Índice
Dois, arquivo de configuração yml
3. Classe de enumeração de fonte de dados
Quatro, classe de ferramenta Spring
5.1, classe de processamento de comutação de fonte de dados DynamicDataSourceContextHolder
5.2, Classe de roteamento de fonte de dados dinâmica DynamicDataSource
5.3, Propriedades de configuração DruidProperties
5.4, classe de configuração principal de fonte de dados múltiplos DruidConfig
Seis, anotação de comutação de fonte de dados múltiplos personalizada do DataSource
7. A classe de aspecto da fonte de dados dinâmica DataSourceAspect
8. Captura de tela completa do projeto
1. Importe dependências pom
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Lombok驱动依赖 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- MySQL驱动依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
<!--Mybatis依赖-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<!-- 阿里数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>
<!--aop依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>Dois, arquivo de configuração yml
# Mybatis配置
mybatis:
# 配置mapper的扫描,找到所有的mapper.xml映射文件
mapper-locations: classpath:mapper/*/*.xml
# 数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
# 主库数据源
master:
url: jdbc:mysql://localhost:3306/master?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username:
password:
# 从库数据源
slave:
# 从数据源开关/默认关闭
enabled: true
url: jdbc:mysql://localhost:3306/slave?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username:
password:
# 初始连接数
initialSize: 5
# 最小连接池数量
minIdle: 10
# 最大连接池数量
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置连接超时时间
connectTimeout: 30000
# 配置网络超时时间
socketTimeout: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
# 配置一个连接在池中最大生存的时间,单位是毫秒
maxEvictableIdleTimeMillis: 900000
# 配置检测连接是否有效
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
webStatFilter:
enabled: true
statViewServlet:
enabled: true
# 设置白名单,不填则允许所有访问
allow:
url-pattern: /druid/*
filter:
stat:
enabled: true
# 慢SQL记录
log-slow-sql: true
slow-sql-millis: 1000
merge-sql: true
wall:
config:
multi-statement-allow: true
3. Classe de enumeração de fonte de dados
public enum DataSourceType
{
/**
* 主库
*/
MASTER,
/**
* 从库
*/
SLAVE
}Quatro, classe de ferramenta Spring
A principal função é fornecer um método estático para obter instâncias de Bean por nome.
1. Implemente as interfaces BeanFactoryPostProcessor e ApplicationContextAware.Quando o contêiner Spring for inicializado, salve as instâncias de ConfigurableListableBeanFactory e ApplicationContext em variáveis estáticas.
@Component marca esta classe de ferramenta para ser gerenciada pelo contêiner Spring.
@Component
public final class SpringUtils implements BeanFactoryPostProcessor, ApplicationContextAware{
/** Spring应用上下文环境 */
private static ConfigurableListableBeanFactory beanFactory;
private static ApplicationContext applicationContext;
}2. O método postProcessBeanFactory será executado antes que a definição do Bean seja carregada, mas instanciada, e a instância BeanFactory seja salva neste momento.
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException
{
SpringUtils.beanFactory = beanFactory;
}3. setApplicationContext será executado após a conclusão da preparação do contexto e a instância ApplicationContext será salva neste momento.
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException
{
SpringUtils.applicationContext = applicationContext;
}4. Forneça o método getBean para obter a instância do Bean do BeanFactory estático de acordo com o nome.
@SuppressWarnings("unchecked") significa suprimir avisos relacionados a transformações não verificadas e variáveis parametrizadas.
@SuppressWarnings("unchecked")
public static <T> T getBean(String name) throws BeansException
{
return (T) beanFactory.getBean(name);
}Código completo:
package com.example.multiple.utils;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.BeanFactoryPostProcessor;
import org.springframework.beans.factory.config.ConfigurableListableBeanFactory;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.stereotype.Component;
/**
* spring工具类 方便在非spring管理环境中获取bean
*/
@Component
public final class SpringUtils implements BeanFactoryPostProcessor, ApplicationContextAware
{
/** Spring应用上下文环境 */
private static ConfigurableListableBeanFactory beanFactory;
private static ApplicationContext applicationContext;
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException
{
SpringUtils.beanFactory = beanFactory;
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException
{
SpringUtils.applicationContext = applicationContext;
}
/**
* 获取对象
*
* @param name
* @return Object 一个以所给名字注册的bean的实例
* @throws BeansException
*
*/
@SuppressWarnings("unchecked")
public static <T> T getBean(String name) throws BeansException
{
return (T) beanFactory.getBean(name);
}
}
Cinco, classe de configuração
Primeiro, uma introdução básica às classes de configuração e o relacionamento entre elas
1. Suporte DynamicDataSourceContextHolder ThreadLocal, usado para armazenar a chave da fonte de dados atual .
2. DynamicDataSource personaliza a fonte de dados dinâmica e contém vários mapas de fonte de dados de destino e pode alternar dinamicamente a fonte de dados definindo a chave.
3. DruidProperties é usado para ler as propriedades de configuração da fonte de dados Druid, como o número máximo de conexões, o número mínimo de conexões, etc.
4. DruidConfig implementa a configuração de fontes múltiplas de dados do Druid , cria dois beans de fonte de dados , master e slave , e então os monta em uma fonte de dados dinâmica por meio de DynamicDataSource.
5. A
anotação DataSource é usada para marcar um método ou classe para especificar qual fonte de dados usar.
6. Para o
aspecto DataSourceAspect AOP, a chave da fonte de dados é obtida por meio da anotação DataSource antes da execução do método e é definida no DynamicDataSourceContextHolder para alternar para a fonte de dados especificada.
O fluxo de trabalho é :
1. DruidConfig primeiro cria vários beans de fonte de dados e os entrega ao DynamicDataSource para integração.
2. O método comercial especifica a fonte de dados por meio da anotação DataSource .
3. Antes de o método ser executado, DataSourceAspect lê a anotação DataSource, obtém a chave da fonte de dados e a define como ContextHolder.
4. Quando o método de negócio chamar o método da interface Mapper, o SQL será executado através de SqlSessionTemplate.
5. O DataSource usado dentro do SqlSessionTemplate é DynamicDataSource.
6. Antes de obter a Conexão, o DynamicDataSource chamará primeiro o método determineCurrentLookupKey.
7. determineCurrentLookupKey obtém a chave da fonte de dados do ContextHolder e determina a fonte de dados de destino a ser usada.
8. De acordo com a chave em ContextHolder , DynamicDataSource obtém Connection dele e roteia para a fonte de dados correspondente para executar SQL .
9. Em seguida, use esta conexão para executar SQL para concluir a operação do banco de dados.
Dessa forma, a comutação de fontes de dados múltiplos baseada em Druid é realizada , principalmente por meio de AOP + ThreadLocal para definir dinamicamente a chave da fonte de dados .
5.1, classe de processamento de comutação de fonte de dados DynamicDataSourceContextHolder
1. É definido um CONTEXT_HOLDER do tipo ThreadLocal, que fornecerá um armazenamento de cópias independente para cada thread.
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<>();2. O método setDataSourceType é usado para definir o tipo de fonte de dados a ser usado pelo thread atual, e o tipo será armazenado no ThreadLocal de CONTEXT_HOLDER.
public static void setDataSourceType(String dsType)
{
log.info("切换到{}数据源", dsType);
CONTEXT_HOLDER.set(dsType);
}3. getDataSourceType é usado para obter o tipo de fonte de dados usado pelo thread atual, que é obtido do ThreadLocal de CONTEXT_HOLDER.
public static String getDataSourceType()
{
return CONTEXT_HOLDER.get();
}4. clearDataSourceType é usado para limpar as informações do tipo de fonte de dados do thread atual.
public static void clearDataSourceType()
{
CONTEXT_HOLDER.remove();
}Desta forma, ThreadLocal pode ser usado para compartilhar esta variável de tipo de fonte de dados dentro de um thread, e as variáveis de cada thread são independentes.
Código completo:
package com.example.multiple.config.datasource;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 数据源切换处理
*/
public class DynamicDataSourceContextHolder
{
public static final Logger log = LoggerFactory.getLogger(DynamicDataSourceContextHolder.class);
/**
* 使用ThreadLocal维护变量,ThreadLocal为每个使用该变量的线程提供独立的变量副本,
* 所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
*/
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<>();
/**
* 设置数据源的变量
*/
public static void setDataSourceType(String dsType)
{
log.info("切换到{}数据源", dsType);
CONTEXT_HOLDER.set(dsType);
}
/**
* 获得数据源的变量
*/
public static String getDataSourceType()
{
return CONTEXT_HOLDER.get();
}
/**
* 清空数据源变量
*/
public static void clearDataSourceType()
{
CONTEXT_HOLDER.remove();
}
}
5.2, Classe de roteamento de fonte de dados dinâmica DynamicDataSource
1. Esta classe DynamicDataSource herda AbstractRoutingDataSource e implementa uma fonte de dados de roteamento que alterna dinamicamente as fontes de dados.
public class DynamicDataSource extends AbstractRoutingDataSource{
}2. No método de construção, chame o método da classe pai para definir a fonte de dados padrão e todos os mapas da fonte de dados de destino.
public DynamicDataSource(DataSource defaultTargetDataSource, Map<Object, Object> targetDataSources)
{
super.setDefaultTargetDataSource(defaultTargetDataSource);
super.setTargetDataSources(targetDataSources);
super.afterPropertiesSet();
}3. O método determineCurrentLookupKey é implementado. Neste método, o tipo de fonte de dados no thread atual é obtido por meio da classe de ferramenta DynamicDataSourceContextHolder e, em seguida, a chave de pesquisa atual é definida para esse tipo de fonte de dados.
@Override
protected Object determineCurrentLookupKey()
{
return DynamicDataSourceContextHolder.getDataSourceType();
}Por fim, AbstractRoutingDataSource procurará o DataSource correspondente no mapa da fonte de dados de destino de acordo com a chave de pesquisa como fonte para obter a conexão. Dessa forma, por meio da implementação de determineCurrentLookupKey, o tipo DataSource no thread atual é retornado dinamicamente. Coopere com DynamicDataSourceContextHolder para alternar e definir o tipo de DataSource do thread. De acordo com o tipo de fonte de dados quando o thread está em execução, ele pode alternar dinamicamente para diferentes fontes de dados para obter conexões. Realizou a função de alternar dinamicamente várias fontes de dados de acordo com as condições operacionais atuais.
Código completo:
package com.example.multiple.config.datasource;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import javax.sql.DataSource;
import java.util.Map;
/**
* 动态数据源
*/
public class DynamicDataSource extends AbstractRoutingDataSource
{
public DynamicDataSource(DataSource defaultTargetDataSource, Map<Object, Object> targetDataSources)
{
super.setDefaultTargetDataSource(defaultTargetDataSource);
super.setTargetDataSources(targetDataSources);
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey()
{
return DynamicDataSourceContextHolder.getDataSourceType();
}
}
5.3, Propriedades de configuração DruidProperties
Carregue as propriedades da configuração, defina-as como DruidDataSource e crie uma instância de DataSource disponível. Há comentários sobre o código, então não vou explicar muito aqui.
Código completo:
package com.example.multiple.config.properties;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
/**
* druid 配置属性
*
*/
@Configuration
public class DruidProperties
{
@Value("${spring.datasource.druid.initialSize}")
private int initialSize;
@Value("${spring.datasource.druid.minIdle}")
private int minIdle;
@Value("${spring.datasource.druid.maxActive}")
private int maxActive;
@Value("${spring.datasource.druid.maxWait}")
private int maxWait;
@Value("${spring.datasource.druid.connectTimeout}")
private int connectTimeout;
@Value("${spring.datasource.druid.socketTimeout}")
private int socketTimeout;
@Value("${spring.datasource.druid.timeBetweenEvictionRunsMillis}")
private int timeBetweenEvictionRunsMillis;
@Value("${spring.datasource.druid.minEvictableIdleTimeMillis}")
private int minEvictableIdleTimeMillis;
@Value("${spring.datasource.druid.maxEvictableIdleTimeMillis}")
private int maxEvictableIdleTimeMillis;
@Value("${spring.datasource.druid.validationQuery}")
private String validationQuery;
@Value("${spring.datasource.druid.testWhileIdle}")
private boolean testWhileIdle;
@Value("${spring.datasource.druid.testOnBorrow}")
private boolean testOnBorrow;
@Value("${spring.datasource.druid.testOnReturn}")
private boolean testOnReturn;
public DruidDataSource dataSource(DruidDataSource datasource)
{
/** 配置初始化大小、最小、最大 */
datasource.setInitialSize(initialSize);
datasource.setMaxActive(maxActive);
datasource.setMinIdle(minIdle);
/** 配置获取连接等待超时的时间 */
datasource.setMaxWait(maxWait);
/** 配置驱动连接超时时间,检测数据库建立连接的超时时间,单位是毫秒 */
datasource.setConnectTimeout(connectTimeout);
/** 配置网络超时时间,等待数据库操作完成的网络超时时间,单位是毫秒 */
datasource.setSocketTimeout(socketTimeout);
/** 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 */
datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
/** 配置一个连接在池中最小、最大生存的时间,单位是毫秒 */
datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
datasource.setMaxEvictableIdleTimeMillis(maxEvictableIdleTimeMillis);
/**
* 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
*/
datasource.setValidationQuery(validationQuery);
/** 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 */
datasource.setTestWhileIdle(testWhileIdle);
/** 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 */
datasource.setTestOnBorrow(testOnBorrow);
/** 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 */
datasource.setTestOnReturn(testOnReturn);
return datasource;
}
}
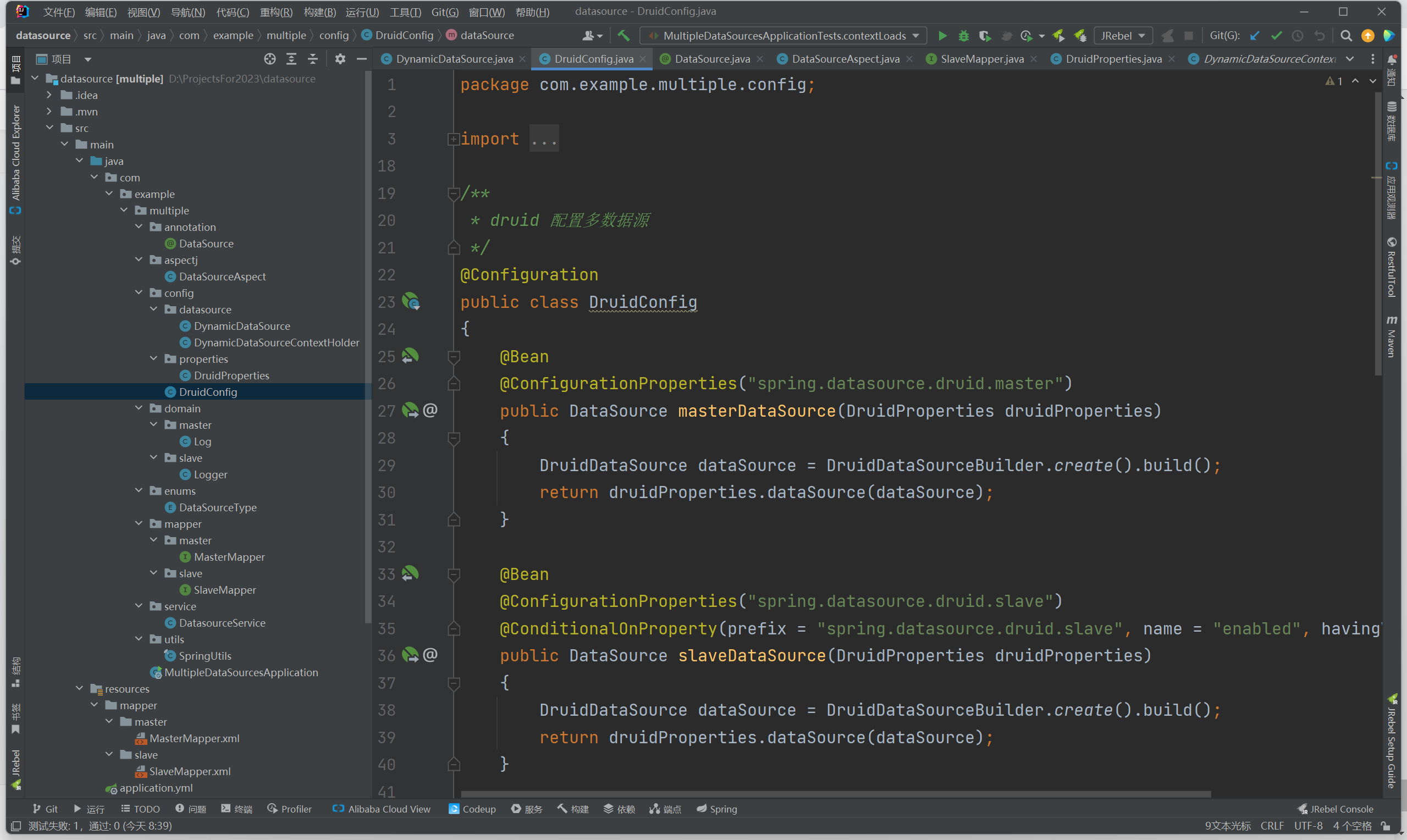
5.4, classe de configuração principal de fonte de dados múltiplos DruidConfig
1. Use @Configuration para marcar esta classe como a classe de configuração principal.
@Configuration
public class DruidConfig{
}2. Registre um Bean que cria a fonte de dados principal mestre
A primeira etapa, a anotação @ConfigurationProperties carrega a configuração da propriedade chamada "spring.datasource.druid.master".
A segunda etapa é criar uma instância DruidDataSource por meio de DruidDataSourceBuilder.
A terceira etapa é passar a instância DruidDataSource para o método dataSource de DruidProperties.
A quarta etapa, DruidProperties definirá várias propriedades de DruidDataSource de acordo com a configuração da propriedade carregada, como o número máximo de conexões, o número mínimo de conexões, etc.
Etapa 5. O método dataSource retornará a instância DruidDataSource com as propriedades definidas.
Por fim, o DruidDataSource configurado será usado como uma instância do Bean masterDataSource, portanto, ele implementa o método de configuração de propriedade de uso do Spring Boot, carrega a configuração do druid.master e o define como DruidDataSource para criar um Bean de fonte de dados mestre disponível.
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource masterDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}3. Registre um Bean que cria um salvamento a partir da fonte de dados.As etapas gerais são semelhantes às anteriores e não há mais explicações.
A função da anotação @ConditionalOnProperty é determinar se o Bean é criado de acordo com as condições fornecidas. Somente quando spring.datasource.druid.slave.enabled=true estiver configurado, o Bean deste slaveDataSource será criado.
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
@ConditionalOnProperty(prefix = "spring.datasource.druid.slave", name = "enabled", havingValue = "true")
public DataSource slaveDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}4. O método de configuração da fonte de dados setDataSource
Na primeira etapa, o método recebe um objeto Map targetDataSources, o nome da fonte de dados sourceName e o nome Bean da fonte de dados beanName como parâmetros.
A segunda etapa é obter a instância DataSource Bean correspondente ao beanName do contêiner Spring por meio da classe de ferramenta SpringUtils.
Por fim, armazene a instância DataSource obtida no mapa de targetDataSources de acordo com sourceNamekey.
public void setDataSource(Map<Object, Object> targetDataSources, String sourceName, String beanName)
{
try
{
DataSource dataSource = SpringUtils.getBean(beanName);
targetDataSources.put(sourceName, dataSource);
}
catch (Exception e)
{
e.printStackTrace();
}
}Dessa forma, o DataSource é carregado por meio do beanName e armazenado no targetDataSources usando o sourceName customizado como chave. O objetivo é construir um relacionamento de mapeamento entre um nome personalizado e uma instância de fonte de dados, que existe no contêiner targetDataSources. Isso pode realizar o gerenciamento de configuração de várias fontes de dados e obter instâncias de fontes de dados correspondentes por meio de diferentes sourceNames.
5. Realize a configuração da fonte de dados dinâmica
A primeira etapa é criar um Mapa para armazenar a fonte de dados de destino e colocar o Bean denominado masterDataSource no Mapa como a fonte de dados principal.
A segunda etapa é chamar o método setDataSource para colocar o Bean denominado slaveDataSource no Mapa e definir a Chave como SLAVE.
Por fim, use a instância da fonte de dados primária e o Mapa da fonte de dados para criar uma instância DynamicDataSource e defina-a como Primária, que é a fonte de dados padrão.
@Bean(name = "dynamicDataSource")
@Primary
public DynamicDataSource dataSource(DataSource masterDataSource)
{
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceType.MASTER.name(), masterDataSource);
setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");
return new DynamicDataSource(masterDataSource, targetDataSources);
}Código completo:
package com.example.multiple.config;
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import com.example.multiple.config.datasource.DynamicDataSource;
import com.example.multiple.enums.DataSourceType;
import com.example.multiple.config.properties.DruidProperties;
import com.example.multiple.utils.SpringUtils;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
/**
* druid 配置多数据源
*/
@Configuration
public class DruidConfig
{
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource masterDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
@ConditionalOnProperty(prefix = "spring.datasource.druid.slave", name = "enabled", havingValue = "true")
public DataSource slaveDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
@Bean(name = "dynamicDataSource")
@Primary
public DynamicDataSource dataSource(DataSource masterDataSource)
{
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceType.MASTER.name(), masterDataSource);
setDataSource(targetDataSources, DataSourceType.SLAVE.name(), "slaveDataSource");
return new DynamicDataSource(masterDataSource, targetDataSources);
}
/**
* 设置数据源
*
* @param targetDataSources 备选数据源集合
* @param sourceName 数据源名称
* @param beanName bean名称
*/
public void setDataSource(Map<Object, Object> targetDataSources, String sourceName, String beanName)
{
try
{
DataSource dataSource = SpringUtils.getBean(beanName);
targetDataSources.put(sourceName, dataSource);
}
catch (Exception e)
{
e.printStackTrace();
}
}
}
Seis, anotação de comutação de fonte de dados múltiplos personalizada do DataSource
1. @Target e @Retention indicam que a anotação pode ser usada em métodos e classes e pode ser retida até o tempo de execução.
2. @Documented indica que a anotação será incluída no javadoc.
3. @Inherited significa que a anotação pode ser herdada por subclasses.
A anotação possui apenas um atributo de valor, o tipo é enumeração DataSourceType e o valor padrão é MASTER.
@Target({ ElementType.METHOD, ElementType.TYPE })
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface DataSource
{
/**
* 切换数据源名称
*/
public DataSourceType value() default DataSourceType.MASTER;
}7. A classe de aspecto da fonte de dados dinâmica DataSourceAspect
1. @Aspect marca esta classe como uma classe de aspecto, @Order especifica a ordem de carregamento dos beans e @Component marca esta classe como um contêiner Spring para hospedagem.
@Aspect
@Order(1)
@Component
public class DataSourceAspect{
}2. @Pointcut define o ponto de corte, aqui está o método ou classe que corresponde a todas as anotações @DataSource.
@Pointcut("@annotation(com.example.multiple.annotation.DataSource)"
+ "|| @within(com.example.multiple.annotation.DataSource)")
public void dsPointCut()
{
}3. Obtenha a fonte de dados que precisa ser trocada
O primeiro passo é obter a assinatura do método através de point.getSignature() e convertê-la para o tipo MethodSignature.
A segunda etapa é chamar o método findAnnotation de AnnotationUtils, tomar o método como destino e obter a anotação @DataSource nele.
A terceira etapa, se a anotação não estiver vazia, retorne a anotação diretamente.
Por fim, se não houver anotação no método, procure novamente a anotação @DataSource com a classe onde o método está localizado e retorne.
public DataSource getDataSource(ProceedingJoinPoint point)
{
MethodSignature signature = (MethodSignature) point.getSignature();
DataSource dataSource = AnnotationUtils.findAnnotation(signature.getMethod(), DataSource.class);
if (Objects.nonNull(dataSource))
{
return dataSource;
}
return AnnotationUtils.findAnnotation(signature.getDeclaringType(), DataSource.class);
}4. @Around define a lógica de processamento do ponto de corte como aprimoramento surround
A primeira etapa é chamar o método getDataSource para obter a anotação DataSource exigida pelo método de destino.
A segunda etapa é determinar se a anotação não está vazia, chamar o método setDataSourceType de DynamicDataSourceContextHolder e definir o valor da anotação (tipo de fonte de dados) para ela.
A terceira etapa é chamar o método continue de ProceedingJoinPoint para executar o método de destino.
Finalmente, finalmente, chame o método clearDataSourceType de DynamicDataSourceContextHolder para limpar o DataSourceType local do thread.
@Around("dsPointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable
{
DataSource dataSource = getDataSource(point);
if (dataSource != null)
{
DynamicDataSourceContextHolder.setDataSourceType(dataSource.value().name());
}
try
{
return point.proceed();
}
finally
{
// 销毁数据源 在执行方法之后
DynamicDataSourceContextHolder.clearDataSourceType();
}
}Código completo:
package com.example.multiple.aspectj;
import com.example.multiple.annotation.DataSource;
import com.example.multiple.config.datasource.DynamicDataSourceContextHolder;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.core.annotation.AnnotationUtils;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import java.util.Objects;
/**
* 多数据源处理
*/
@Aspect
@Order(1)
@Component
public class DataSourceAspect
{
protected Logger logger = LoggerFactory.getLogger(getClass());
@Pointcut("@annotation(com.example.multiple.annotation.DataSource)"
+ "|| @within(com.example.multiple.annotation.DataSource)")
public void dsPointCut()
{
}
@Around("dsPointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable
{
DataSource dataSource = getDataSource(point);
if (dataSource != null)
{
DynamicDataSourceContextHolder.setDataSourceType(dataSource.value().name());
}
try
{
return point.proceed();
}
finally
{
// 销毁数据源 在执行方法之后
DynamicDataSourceContextHolder.clearDataSourceType();
}
}
/**
* 获取需要切换的数据源
*/
public DataSource getDataSource(ProceedingJoinPoint point)
{
MethodSignature signature = (MethodSignature) point.getSignature();
DataSource dataSource = AnnotationUtils.findAnnotation(signature.getMethod(), DataSource.class);
if (Objects.nonNull(dataSource))
{
return dataSource;
}
return AnnotationUtils.findAnnotation(signature.getDeclaringType(), DataSource.class);
}
}
8. Captura de tela completa do projeto
O texto acima explica a configuração básica de várias fontes de dados. O resto são algumas operações rotineiras de integração do MyBatis. Eu as coloquei na nuvem de código, então não vou escrever muito aqui. O pacote completo de construção do projeto é assim.
9. Como usar
Use a anotação personalizada @DataSource na camada Mapeador ou na camada Serviço para alternar para a fonte de dados especificada.
@Mapper
@DataSource(DataSourceType.SLAVE)
public interface SlaveMapper {
public List<Logger> select();
}O resultado da operação é o seguinte:

10. Código-fonte do Gitee
Configure sua própria fonte de dados mestre-escravo no arquivo yml e inicie o projeto com um clique
Endereço do projeto: SpringBoot integra MyBatis para construir múltiplas fontes de dados MySQL
11. Resumo
O texto acima é minha análise técnica de como o SpringBoot integra múltiplas fontes de dados. É também uma forma mais tradicional e mais complicada. Se você tiver alguma dúvida, seja bem-vindo para discutir na área de comentários!