Prática de treinamento prático base zero: modelo de classificação de imagens
-Baseado no escopo do modelo da Dharma Academy
Introdução: O modelo de classificação de imagens é a tarefa mais simples e básica de visão computacional e é amplamente utilizado. Este artigo apresentará passo a passo o processo prático do modelo de classificação de imagens de treinamento baseado em zero. O artigo apresenta principalmente como ajustar o modelo com base no conjunto de dados rotulado, para que o modelo possa readaptar uma nova tarefa de classificação nos novos dados.
Depois de ler este artigo, você entenderá como usar o modelo ViT para realizar o treinamento de ajuste fino para classificação em conjuntos de dados de 14 flores e, então, compreenderá o processo de ajuste fino para a maioria das tarefas de classificação.

Primeiro, abra o site oficial do ModelScope ( https://www.modelscope.cn/home ) e entre na biblioteca de modelos.

Na página da biblioteca de modelos você pode ver que existem muitos modelos diferentes, escolhemos: Visão Computacional - Classificação Visual - Classificação Geral. Existem muitos modelos de uso geral na biblioteca de modelos. Esses modelos são relativamente clássicos e alguns são modelos de código aberto atualmente populares. Todos podem experimentá-los. Este artigo usa principalmente o modelo de classificação de imagens ViT - objetos diários chineses como exemplo para demonstrar como ajustar a tarefa de classificação.
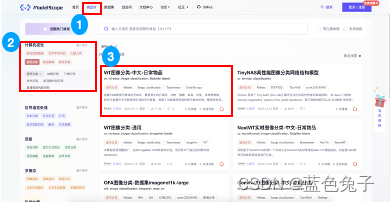
Primeiro abra esta tarefa. Como o notebook será usado para treinamento posteriormente, você precisa fazer login. O registro de um novo usuário proporcionará 100 horas de poder de computação GPU.
A tarefa primeiro apresenta os fundamentos de todo o modelo: uma visão geral do modelo diário de classificação de objetos, uma breve descrição do modelo e um exemplo de código para raciocínio.

O uso do código de amostra é muito simples: além de citar o pacote de dependência, são necessárias apenas duas linhas de código para chamar o modelo e testar a tarefa de classificação. Há também um modelo de experiência online no canto superior direito da página, que visualiza o processo de raciocínio. Você pode optar por fazer upload de fotos sozinho ou testar com fotos de amostra e pode ver os resultados clicando em Executar teste. Vai ficar um pouco lento no início da execução, pois o modelo precisa ser baixado, e depois ficará mais rápido.

Em segundo lugar, há algumas introduções aos dados do modelo, processo de treinamento do modelo, avaliação de dados e resultados.
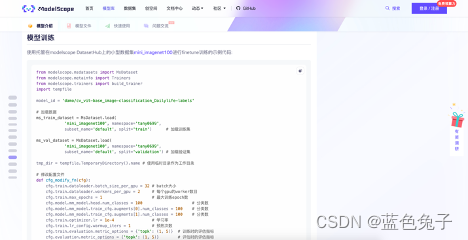
A seguir está o código de exemplo para treinamento de modelo, que também é o foco deste artigo. O código de exemplo usa um conjunto de dados mini_imagenet100 um pouco menor, um exemplo de 100 categorias para treinamento de ajuste fino, que ainda é relativamente grande para a demonstração. Portanto, modificaremos este código para se adaptar a um conjunto de dados menor e explicaremos os parâmetros do modelo com mais detalhes posteriormente.
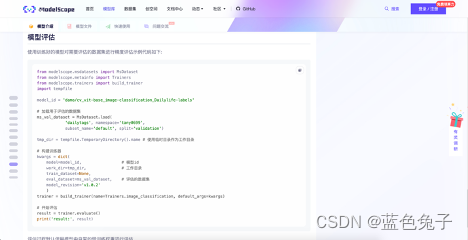
Aqui está o código de exemplo para avaliação do modelo, mostrando como o modelo avalia o conjunto de validação no conjunto de dados, que será explicado em detalhes posteriormente. Este é o conteúdo geral de toda a página de tarefas.
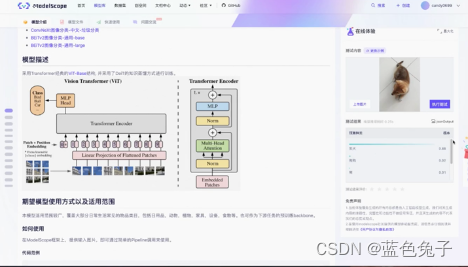
A experiência online acima obteve um resultado de teste, aqui está o resultado top5, e o número um é Shiba Inu, então o resultado da classificação desta imagem é Shiba Inu.
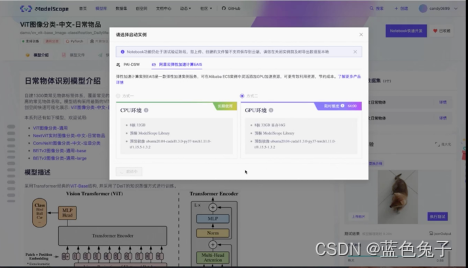
Para facilitar o experimento, primeiro abrimos o caderno. O Notebook tem duas opções, uma é PAI-DSW e a outra é Alibaba Cloud Elastic Computing. Escolhemos a segunda opção, utilizando recursos GPU gratuitos para cálculo. Após selecionar, clique em Início Rápido. Essa inicialização vai demorar um pouco mais, você pode deixar começar em segundo plano.
A seguir, explicaremos algumas informações básicas sobre o modelo. O modelo é uma aplicação do modelo do transformador em visão, chamamos-lhe ViT, abreviadamente. O modelo ViT é um trabalho pioneiro do modelo transformador na área de linguagem natural em visão computacional. O modelo no ModelScope adota a estrutura ViT-Base baseada em transformador e, com base nisso, o token de destilação é adicionado para destilação de conhecimento, ou seja, é adotado o método de treinamento de destilação de conhecimento DeiT.
Nossos dados de treinamento são pesquisados e organizados a partir de uma grande quantidade de dados de código aberto, e alguns objetos comuns com alta frequência são retidos, incluindo mais de 1300 tipos de objetos diários, como alguns animais, plantas, móveis e alimentos comuns, etc. Atualmente, o modelo pode reconhecer mais de 1300 tipos de objetos do cotidiano. Você pode visualizar o código-fonte aberto através do link do modelo, e também pode visualizar o artigo em detalhes através do link do artigo.

Você também pode encontrar o modelo que configuramos no Centro de Documentação em nosso site oficial - Model Explanation - Computer Vision Model. Aqui está uma introdução muito detalhada, incluindo a explicação detalhada do artigo. Esta é uma breve introdução ao modelo ViT que usaremos para experimentos hoje, portanto não irei apresentá-lo em detalhes aqui.
Além disso, em relação aos conjuntos de dados que queremos usar, você pode clicar em Dataset-Image-Image Classification na barra de menu superior e verá muitos conjuntos de dados que podem ser usados para experimentos.
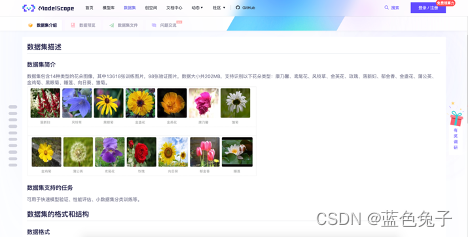
O conjunto de dados que usamos aqui é o conjunto de dados de classificação de flores. Este conjunto de dados contém 14 tipos de imagens de flores, como tipos de flores comuns, como grama-vento, dente-de-leão e crisântemo. Os dados completos têm apenas 200 MB, relativamente pequenos, adequados para a demonstração do nosso processo de ajuste fino de treinamento online. Use um pequeno conjunto de dados de 14 tipos de flores para refinar o modelo ViT recém-introduzido, para que o modelo possa reconhecer esses 14 tipos de flores.

O formato do conjunto de dados é dividido principalmente em conjunto de treinamento e conjunto de verificação. Aqui está a descrição do formato relacionado: ele é classificado de acordo com o trem e pastas válidas. Existem 2 pastas no total. As imagens com o mesmo rótulo de categoria estão na mesma pasta e o formato da imagem é Ambos estão no formato JPG e há um arquivo de etiqueta classname.txt.
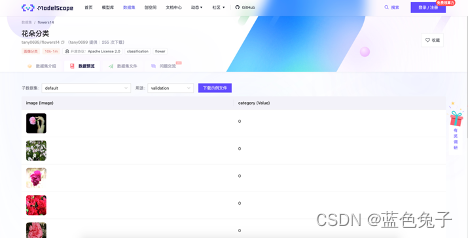
Na visualização dos dados, você pode ver a rotulagem dos dados. Por exemplo, no conjunto de verificação, o lado esquerdo é a imagem dos dados e o lado direito é o rótulo correspondente. O mesmo vale para o conjunto de treinamento.
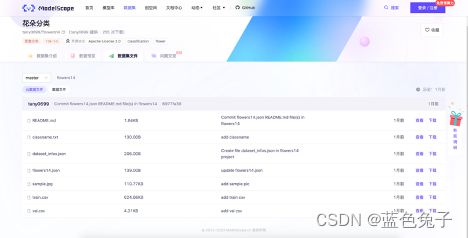
O arquivo do conjunto de dados é o arquivo de todo o conjunto de dados, que inclui o arquivo de rótulo do conjunto de validação em formato csv, o arquivo de rótulo do conjunto de treinamento e Flowers14.json.
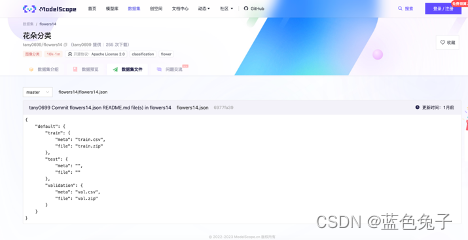
O arquivo Flowers14.json descreve o relacionamento entre todos os dados. Por exemplo, no conjunto de treinamento, meta é o arquivo de rótulo e arquivo é o arquivo compactado da imagem usada para treinamento. O mesmo se aplica ao conjunto de verificação. No arquivo classname.txt, os nomes das classes correspondentes às tags são listados em ordem.
Dentro do arquivo de dados há um arquivo compactado de dados.
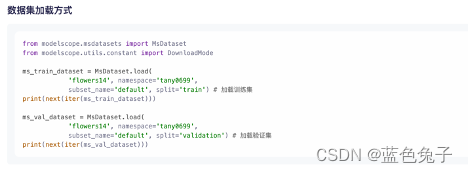
O carregamento do conjunto de dados também é muito simples, bastando uma linha de código. Depois de apresentarmos o pacote de dependência, carregue o conjunto de dados. Para carregar um conjunto de dados, você precisa preencher o nome e o namespace do conjunto de treinamento, que são os pequenos caracteres abaixo do nome dos dados correspondentes.
Flowers14 corresponde ao nome do conjunto de dados e tany0699 corresponde ao namespace. Ao carregar o conjunto de treinamento, split seleciona o trem, e ao carregar o conjunto de verificação, split seleciona a validação. Aqui estão alguns fatos básicos sobre o conjunto de dados.
Volte para a página de treinamento do modelo e abra o notebook que você iniciou anteriormente.
Após o salto, você precisa fazer login na conta vinculada ao ModelScope e Alibaba Cloud.

Abra um arquivo Python3, você pode optar por renomear o arquivo, principalmente para treinar novamente o novo conjunto de dados. Volte para a interface do modelo agora mesmo e copie o código de exemplo de ajuste fino.
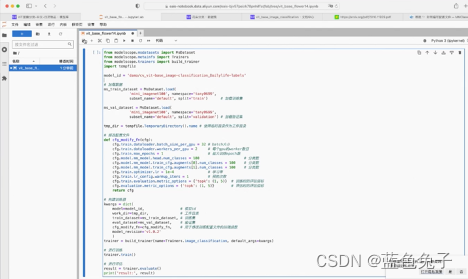
Após a cópia do código, modificamos esses parâmetros. Primeiro, importe os pacotes de dependência dentro do ModelScope. Se você tiver uma GPU local, também poderá treinar localmente. Para treinamento local, a biblioteca ModelScope deve estar pré-instalada. O documento oficial descreve como instalá-la.
Após a instalação, podemos experimentar o notebook online gratuito. Em primeiro lugar, model_id corresponde ao endereço do modelo no Model Hub , que não mudou para a nossa tarefa. Depois disso, o conjunto de dados é carregado, que carrega o conjunto de treinamento e o conjunto de verificação, respectivamente. O método de carregamento de dados foi introduzido anteriormente. Basta copiar e substituir o código de amostra do método de carregamento de dados do nosso novo conjunto de dados.
A próxima etapa é modificar o arquivo de configuração do modelo. O arquivo de configuração conterá uma variedade de conteúdo de configuração e há apenas alguns itens que precisam ser modificados. A primeira é o tamanho do lote, que é definido principalmente de acordo com o tamanho dos dados de treinamento e o tamanho da memória GPU; a segunda linha é o número de trabalhadores para carregar o conjunto de dados; o número máximo de treinamento épocas é o número de iterações para todo o conjunto de dados, que é definido aqui. É 1, principalmente por causa da relação de tempo, apenas uma iteração é treinada. As próximas três linhas são o número de categorias, que deve ser alterado para o número de categorias correspondente ao conjunto de dados, então altere-as para 14 aqui. A taxa de aprendizado aqui, porque iteramos apenas uma vez, para uma convergência melhor e mais rápida, podemos alterá-la para um valor um pouco maior. Você pode modificar esse hiperparâmetro de acordo com seus tempos reais de treinamento. O número de pré-treinamento também é definido como 1, o índice de avaliação, para a tarefa de classificação, agora usamos a precisão para avaliar, e a precisão inclui top1 e top5, e esses dois índices devem ser reavaliados.
Em seguida, construa o treinador. O treinador usa a interface build_trainer; nome é o tipo de classificação, aqui está image_classification, que significa classificação de imagem. A principal coisa que precisamos mudar é o parâmetro kwargs. Os parâmetros incluem principalmente model_id, que é o endereço do modelo mencionado anteriormente; word_dir, o diretório de trabalho, é o diretório onde os pesos do modelo gerados após o treinamento são salvos. O exemplo usa um diretório temporário, que pode ser alterado para um diretório real, como vit_base_flower; train_dataset define o conjunto de treinamento carregado; eval_dataset define o conjunto de validação carregado; cfg_modify_fn é a função de retorno de chamada do arquivo de configuração; model_revision A versão do modelo pode corresponder ao arquivo do modelo (botão mestre), você pode escolher uma versão à vontade, como 1.0.2, para que o treinador do modelo seja construído.
Em seguida, use trainer.train() para treinar. Após a conclusão do treinamento, você pode usar trainer.evaluate() para avaliar e imprimir o resultado após a avaliação. Em seguida, pressione shift + enter para executar o código e deixar o modelo iniciar o treinamento.
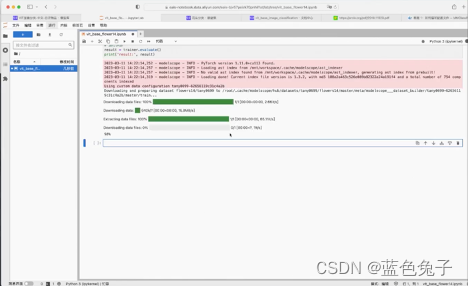
Será lento no início, porque o conjunto de dados e os pesos pré-treinados do modelo precisam ser baixados primeiro.
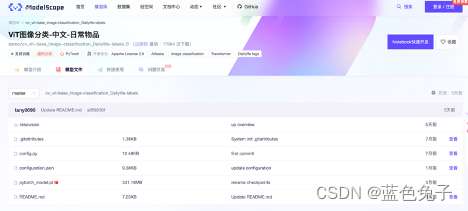
Vejamos o arquivo do modelo novamente. O arquivo do modelo também é relativamente simples. Existem duas partes principais: uma é o peso pré-treinado com nome fixo (pytorch_model.pt); a outra é o arquivo de configuração de todo o modelo (configuration.json), que define principalmente como configurar todo o modelo, como treinar e como avaliar.
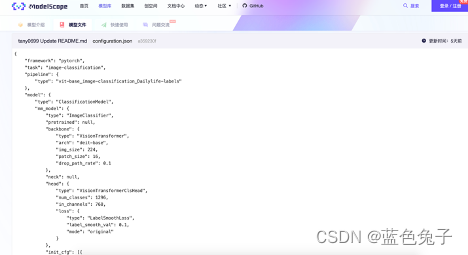
No arquivo de configuração, como o treinamento é baseado em pytorch, a arquitetura permanece inalterada. A tarefa é a classificação da imagem, o nome do pipeline também permanece o mesmo e o tipo de modelo de definição permanece o mesmo. mm_model é o arquivo de configuração do modelo compatível com a classificação mm, o backbone define o VisionTransformer, a estrutura é deit-base, o tamanho da imagem de entrada é 224, o tamanho patch_size é 16, etc. Head é VisionTransformerClsHead. O número padrão de categorias num_classes é 1296, que é o número de categorias de objetos diários. Aqui precisamos alterá-lo para 14, porque o novo conjunto de dados tem 14 categorias. A perda usa LabelSmoothLoss. Existem também alguns parâmetros de inicialização que podem ser modificados. Os métodos de treinamento e aprimoramento usam Mixup e CutMix, e esses parâmetros também podem ser definidos.

De volta ao processo de treinamento, o número de épocas, a taxa de aprendizado atual, o tempo restante estimado, a memória de vídeo usada e a perda podem ser impressos.
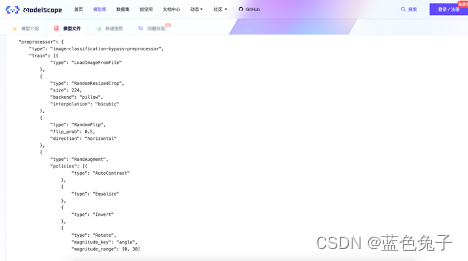
Voltar ao arquivo de configuração.
O tipo no pré-processador permanece inalterado; o processo de treinamento, como carregamento de imagens, dimensionamento aleatório e tamanho de corte 224, inversão aleatória e aprimoramento de dados, etc., pode ser definido no arquivo e, finalmente, normalização; o mesmo se aplica à verificação definir, cortar a imagem, redimensionar para 256, depois cortar para 224 e, finalmente, normalizar.
O número de batch_size usado no processo de treinamento, o número de trabalhadores, o número máximo de iterações e a avaliação é realizada a cada poucas iterações durante a avaliação (aqui está 1 vez), usando precisão para avaliação e salvando o peso do modelo uma vez a cada iteração, o número máximo de pesos salvos é 20, e as configurações no otimizador, incluindo tipo de otimização, taxa de aprendizado e outros parâmetros podem ser modificadas no arquivo. A estratégia de taxa de aprendizagem pode ser utilizada CosineAnnealing, e alguns parâmetros relacionados também podem ser definidos. Finalmente, a configuração de avaliação também pode ser definida, como o tamanho de batch_size durante a avaliação, o número de trabalhadores, o método de precisão usado para avaliação e o método de avaliação de top1 ou top5.
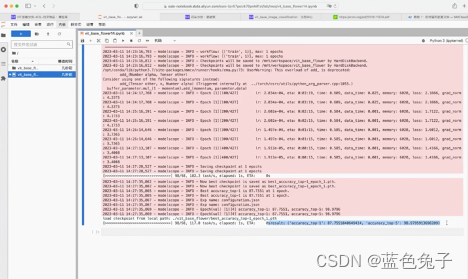
O treinamento foi concluído e você pode ver que os resultados foram impressos: a precisão do top1 é 87,75 e a precisão do top5 é 98,97. Demora cerca de 3 minutos para treinar uma vez.

Os pesos recém-treinados foram salvos no diretório de trabalho. Existem dois arquivos de log no diretório, que são os logs do processo de treinamento, que são exatamente iguais aos resultados que acabamos de imprimir. Existe um arquivo de configuração de modelo, que é exatamente igual ao arquivo de configuração que acabamos de mencionar. Por exemplo, o número de categorias que alteramos agora foi alterado para 14, porque a função de retorno de chamada foi usada agora e os parâmetros modificados diretamente também são salvos no arquivo. Há também o peso salvo para cada época, que agora só é treinado uma vez, portanto há apenas uma época_1. Existem também conexões suaves para os últimos pesos salvos e um conjunto de validação para salvar os melhores pesos do modelo durante o treinamento.
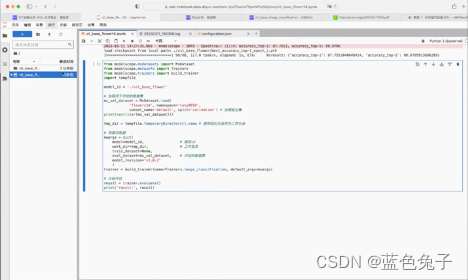
Após o modelo ser treinado, ele precisa ser avaliado. O desempenho do modelo treinado no conjunto de validação pode ser avaliado. Podemos copiar diretamente o código de amostra para avaliação do modelo, da mesma forma, o conjunto de dados pode ser modificado para o conjunto de verificação carregado no experimento agora, que é a avaliação do novo conjunto de verificação. O model_id anterior é o modelo no Model Hub e agora foi alterado para o diretório de trabalho onde o treinamento é salvo. Mas observe que o nome do arquivo de peso do modelo no diretório do modelo é fixo pytorch_model.pt, então você precisa renomear o arquivo de peso para pytorch_model.pt. O diretório de trabalho pode usar um diretório de trabalho temporário e o conjunto de verificação é o conjunto de dados que precisa ser avaliado. Após a construção do treinador, chame trainer.evaluate() para avaliar e imprima o resultado após a avaliação. Execute o código pressionando shift+enter para iniciar a avaliação.
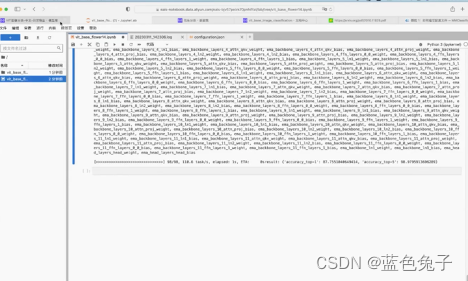
O processo de avaliação é relativamente rápido, pelos resultados impressos verifica-se que o resultado do top1 é 87,75 e o resultado do top5 é 98,97, que é exatamente igual ao resultado do treinamento.
Depois que o modelo for treinado, a inferência poderá ser realizada e o código de inferência poderá ser copiado diretamente da página de tarefas do modelo.
Para usar o modelo treinado, primeiro carregue o pacote de dependência e, em seguida, use o pipline para construir o pipline de inferência. O tipo de tarefa inserido aqui permanece inalterado e o modelo é alterado para o caminho do modelo recém-treinado: vit_base_flower. O endereço da imagem pode ser um URL acessível ou um caminho de imagem local. Agora você pode baixar uma imagem à vontade, como uma imagem de girassol, chamada test.webp. Depois de baixar localmente, você pode arrastar a imagem diretamente para a interface para fazer upload e, em seguida, copiar o nome da imagem. Altere o endereço da imagem para o caminho local ./test.webp e você poderá classificar e testar esta imagem.

Os cinco primeiros resultados são exibidos nos resultados da inferência, e o girassol ocupa o primeiro lugar, portanto, o resultado da classificação e previsão desta imagem é o girassol. No entanto, as probabilidades correspondentes são muito baixas, indicando que a formação não é particularmente suficiente. Como apenas uma iteração é treinada, ainda há muito espaço para melhorias. Você pode ajustar os hiperparâmetros e tentar treinar. Por exemplo, o número máximo de épocas pode ser aumentado e a taxa de aprendizado pode ser diminuída. Mais treinamento pode ter melhores resultados.
Isso conclui o processo de pré-treinamento de todo o modelo de classificação.
Existem muitos outros modelos de classificação no ModelScope, e o processo de treinamento de outros modelos é semelhante ao processo de tarefa do treinamento atual. Por exemplo, o modelo geral de classificação de imagens ViT é exatamente igual ao modelo recém-treinado, mas o conjunto de dados pré-treinado é diferente. O modelo de objeto diário usa nosso conjunto de dados autoconstruído e o modelo geral usa o conjunto de dados público ImageNet 1k. Além disso, existe um modelo NextViT de classificação em tempo real mais prático, que é mais adequado para a indústria devido à sua velocidade rápida e bom efeito de classificação. Você também pode dar uma olhada em outros modelos, como classificação de lixo. Há também o recentemente popular BEiT, que é a versão v2, e você também pode ajustá-lo. Cada tarefa terá uma introdução ao modelo, uma descrição do modelo e alguns links, bem como código de inferência, código de treinamento de ajuste fino e código de avaliação, que podem ser copiados e executados diretamente.
Este é o fim do tutorial de treinamento de ajuste fino para classificação de imagens. Se você estiver interessado, pode acessar o site oficial do ModelScope ( https://www.modelscope.cn/home ) para saber mais e experimentar.
Nota: Se for um modelo público/aplicativo de espaço de criação público, o seguinte código de autorização não é necessário no código:
from modelscope.hub.api import HubApi
YOUR_ACCESS_TOKEN = '请从ModelScope个人中心->访问令牌获取'
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)