Diretório de artigos
- Estrutura de dados subjacente do Redis
- Modelo de rede Redis
- Estratégia de recuperação de memória
Estrutura de dados subjacente do Redis
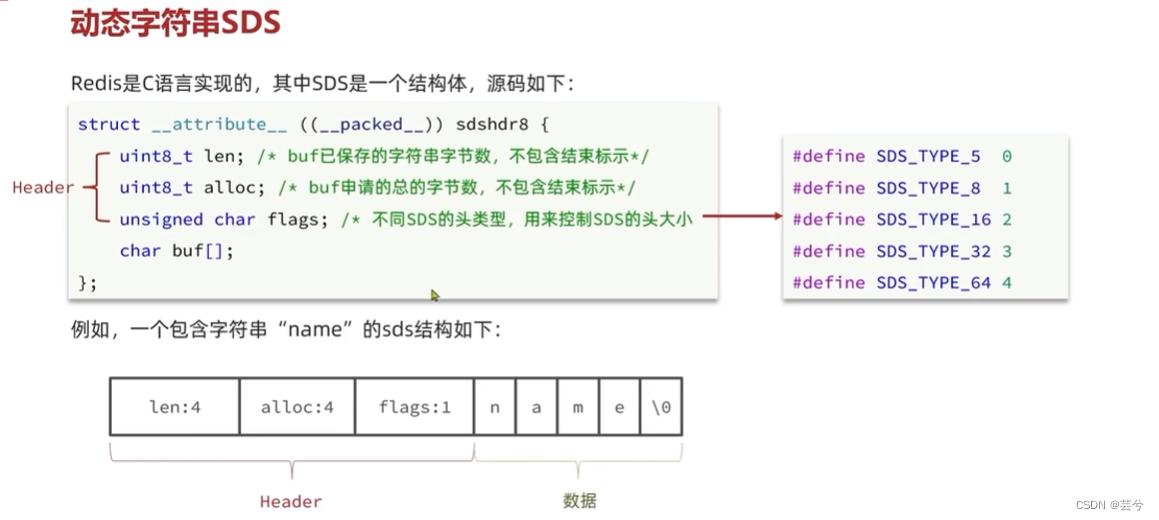
Sequência dinâmica SDS
O próprio Redis constrói uma nova estrutura de string chamada Simple Dynamic String, ou SDS, para abreviar.


Coleção de inteiros IntSet




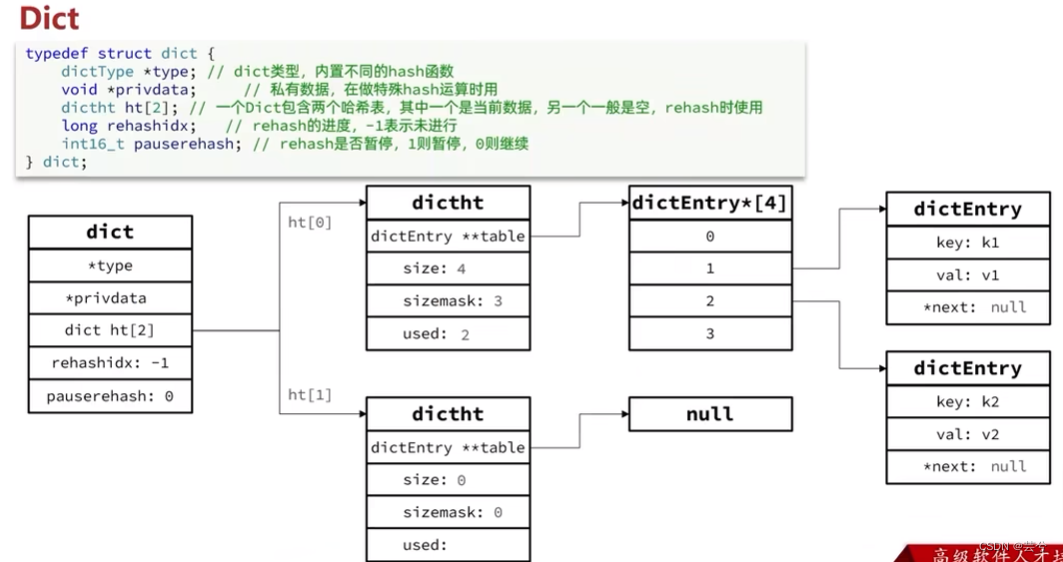
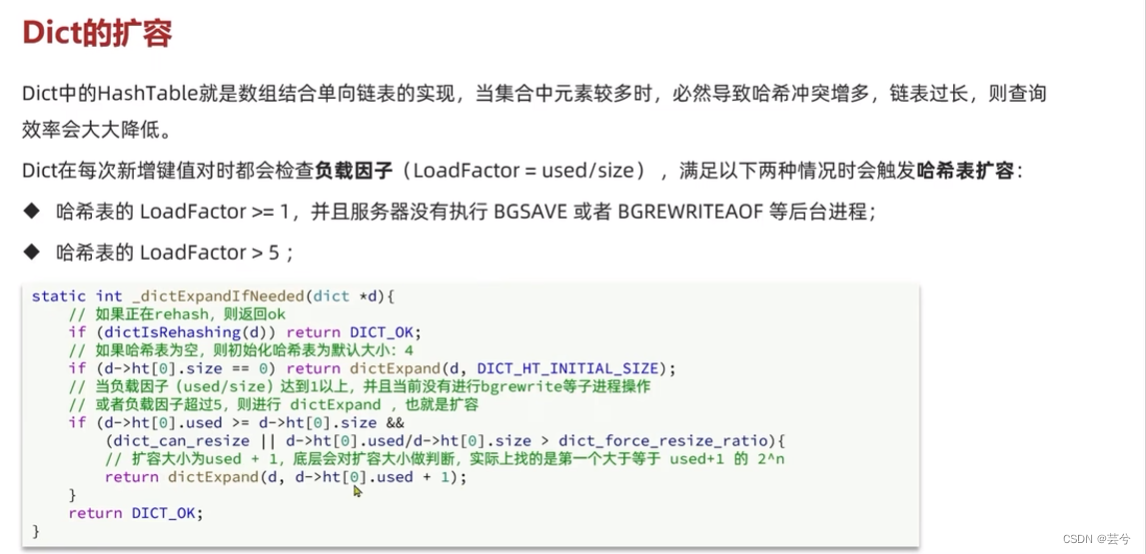
Dicionário de ditado
-
Dict consiste em três partes: tabela hash, nó hash e dicionário.
-
O dicionário Dict contém duas tabelas hash, uma das quais contém os dados atuais e a outra geralmente está vazia e é usada para rehash.
-
Cada nó na tabela hash é um nó hash, e o nó hash é semelhante ao nó da lista vinculada.

Repetição progressiva no alongamento do Dict



Lista compactada ZipList



Lista rápida do QuickLisk
Embora o ZipList economize memória, a memória do aplicativo deve ser um espaço contínuo. Se a ocupação da memória for grande, a eficiência da memória do aplicativo será baixa.
Recursos da lista rápida:
- É uma lista vinculada dupla cujo nó é ZipList
- O nó adota ZipList, que resolve o problema de ocupação de memória da lista vinculada tradicional
- O tamanho do ZipList é controlado para resolver o problema de eficiência contínua do aplicativo no espaço de memória.
- Nós intermediários podem ser compactados, economizando ainda mais memória.
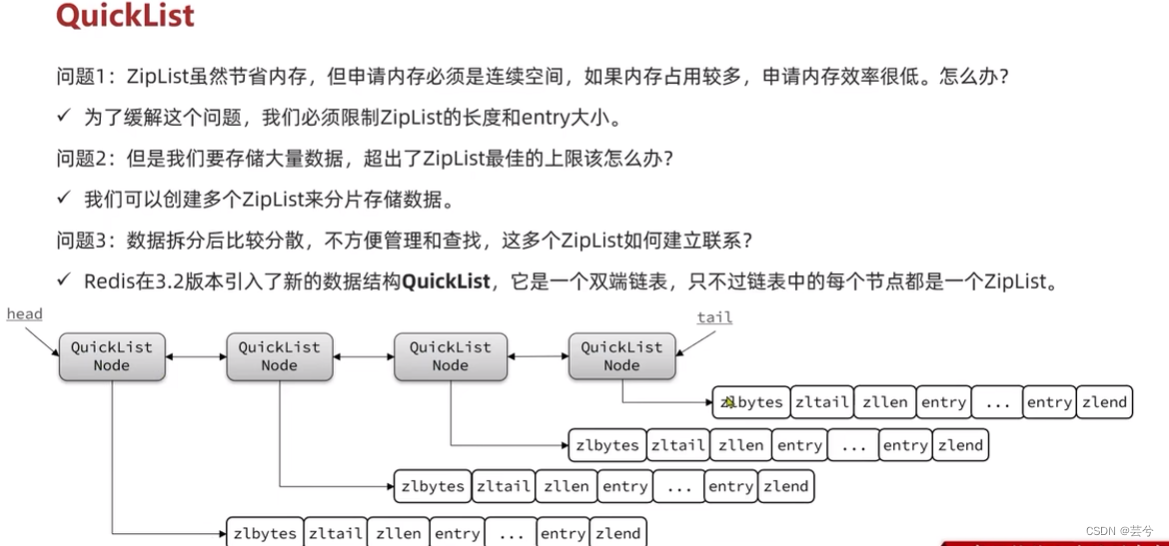
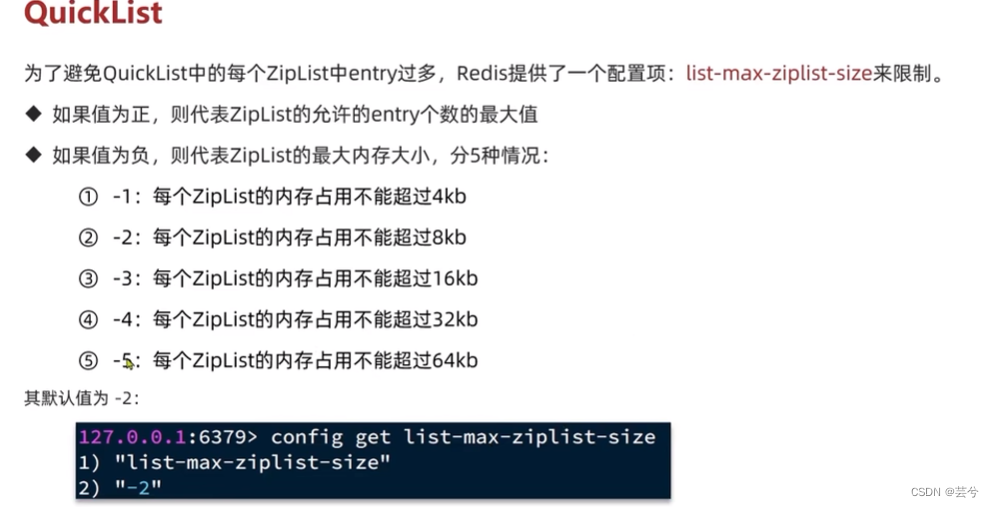


Tabela de pular SkipList
A tabela de salto é uma melhoria da lista vinculada original. A consulta da lista vinculada original requer travessia O (n) O(n)O(n) para cada nó, enquanto a tabela de salto se baseia na ideia de pesquisa binária para classificar o índice da lista vinculada., a essência da lista de pulos é uma lista vinculada ordenada que pode realizar a pesquisa binária.
Recursos do SkipList:
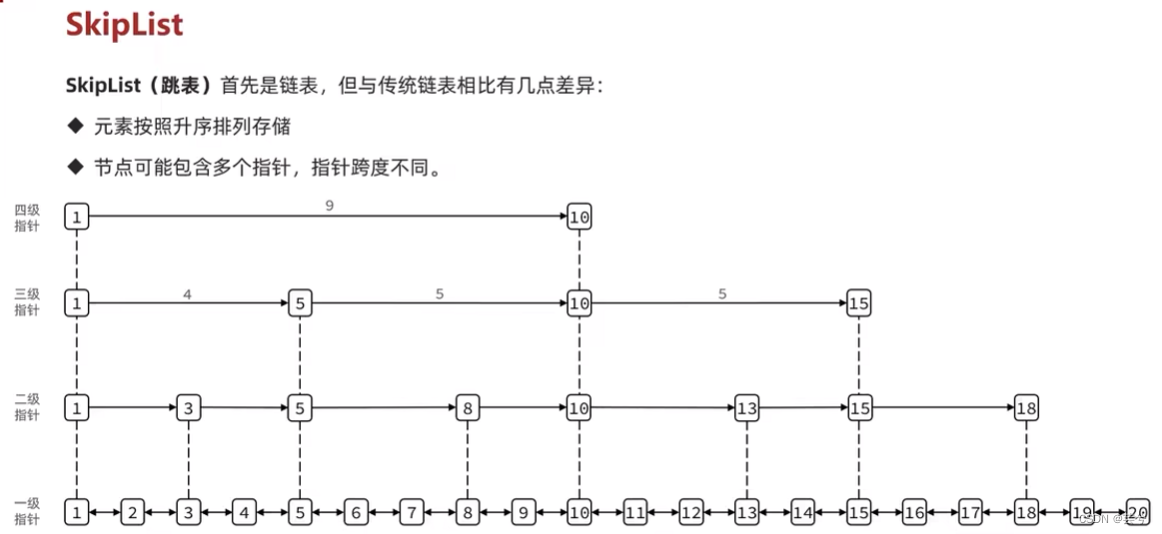
- A lista de atalhos é uma lista duplamente vinculada, cada nó contém pontuação e ele, pontuação é semelhante ao índice e ele é o conteúdo real da string armazenada, os nós são classificados por valor de pontuação e o mesmo valor de pontuação é classificado por ordem lexicográfica ele.
- Cada nó pode conter várias camadas de ponteiros e o número de camadas é um número aleatório entre 1 e 32.
- Ponteiros diferentes têm extensões diferentes para o próximo nó e, quanto maior o nível, maior será a extensão.
- A eficiência de adição, exclusão, modificação e verificação é basicamente a mesma da árvore rubro-negra, mas a implementação é mais simples.
indexação dinâmica
No caso de distribuição de dados conhecida, é ideal selecionar continuamente o ponto médio dos dados como a posição para estabelecimento do índice:
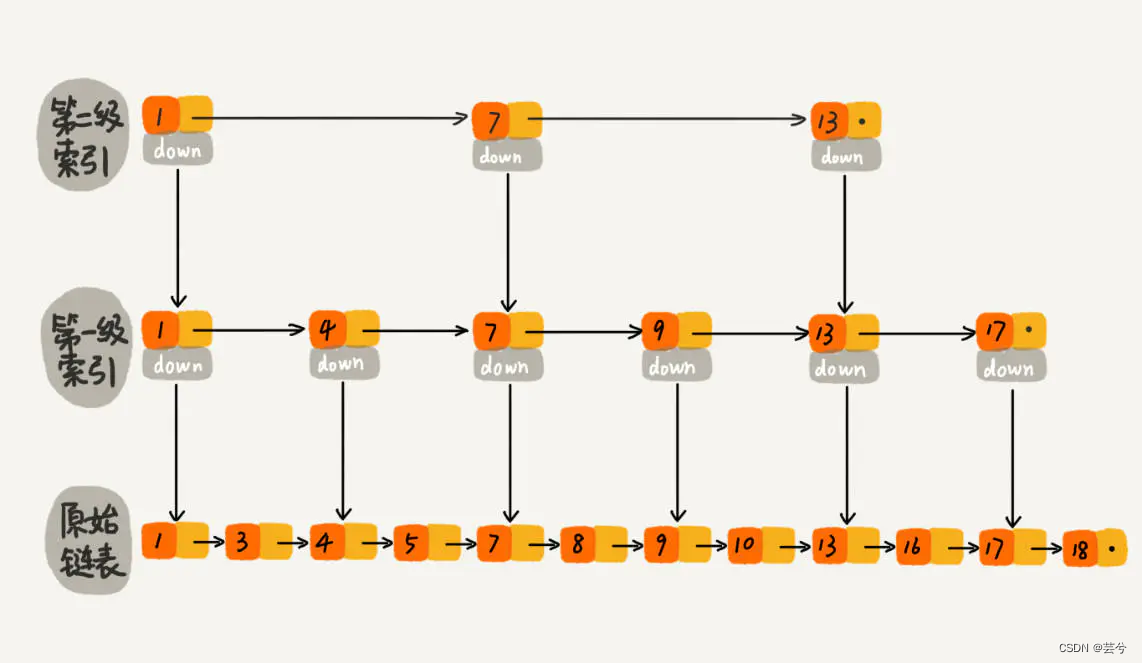
na prática, nosso processo de criação de tabelas de salto é adicionado ou excluído dinamicamente, um por um. Se continuar a adicionar dados à lista original sem actualizar o índice,pode haver muitos dados entre os dois nós do índice.Em casos extremos,a lista de saltos degenera numa lista ligada individualmente:

O índice mais ideal é o caso da pesquisa binária. Na lista vinculada original (assumindo que o comprimento é n), selecione aleatoriamente n/2 elementos como o índice primário, selecione aleatoriamente n/4 elementos como o índice secundário e selecione aleatoriamente n /2 elementos como índice secundário. Oito elementos são usados como índices de três níveis, e assim por diante, até o índice superior.
O método randomLevel() é usado na tabela de salto para implementar o processo de construção do índice acima. Este método irá gerar aleatoriamente um número entre 1 e MAX_LEVEL (MAX_LEVEL indica o nível mais alto do índice), e este método tem uma probabilidade de 1/ 2 para retornar 1, 1 Uma probabilidade de /4 retorna 2, uma probabilidade de 1/8 retorna 3 e assim por diante. (A implementação de randomLevel() pode ser chamar uma função que retorna 1 com uma probabilidade de 0,5 em um loop. Se for 1, continue a chamar a função até que seja 0.)
跳表实际上是使用了这种随机产生元素的索引高度的方式,来打乱了输入的规律性,使得整体上按索引查询某个元素的时间复杂度为O ( l o g N ) O(logN)O(logN)
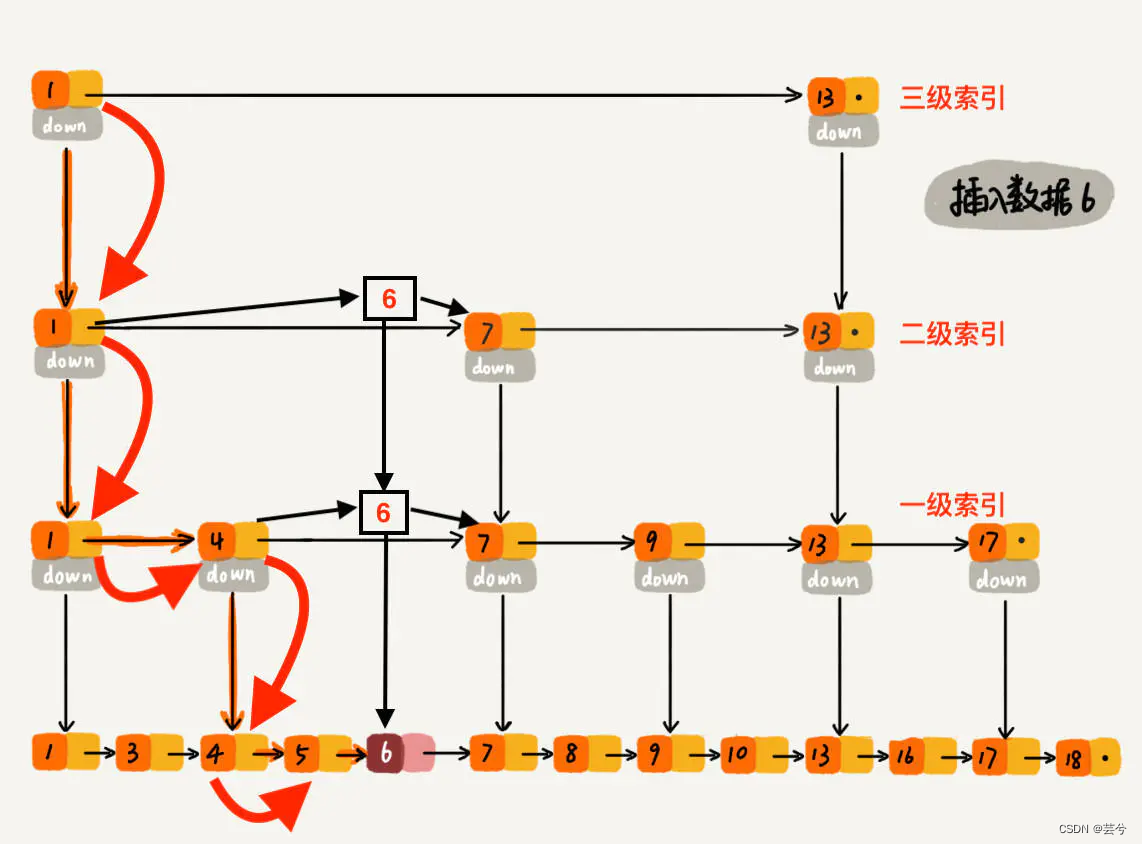
Supondo que um novo elemento 6 seja adicionado, 1 é retornado através da função randomLevel(), ou seja, uma camada de índice é estabelecida (uma camada de índice só pode ser estabelecida na camada inferior), e seu método de estabelecimento é o seguinte : começando no índice de nível mais alto do
nó de cabeçalho, se o próximo elemento de um determinado nó for maior que o elemento inserido (6), pare e insira o próximo índice da camada, e assim por diante, até que a camada atual seja a mesma como camada de índice do elemento (6), insira o nó.
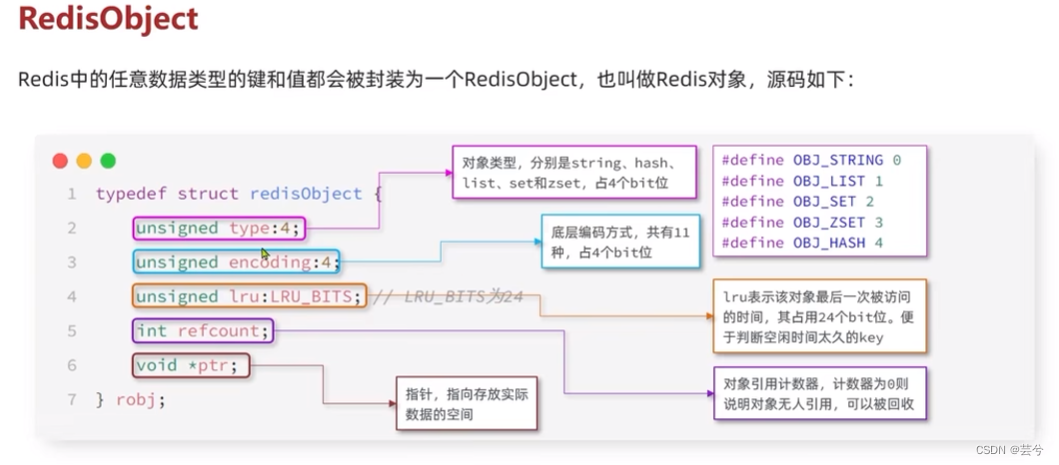
RedisObject
RedisObject é o tipo real de objetos de dados armazenados no Redis.

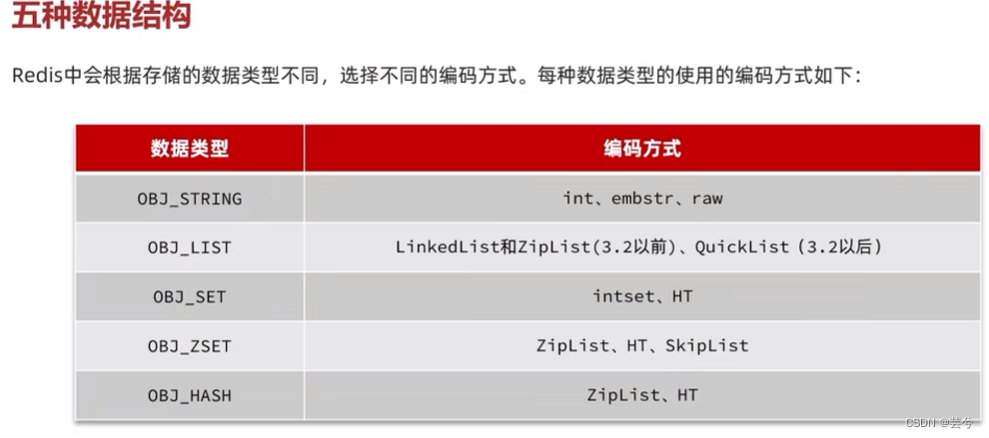
Implementação de tipo de variável e estrutura de dados
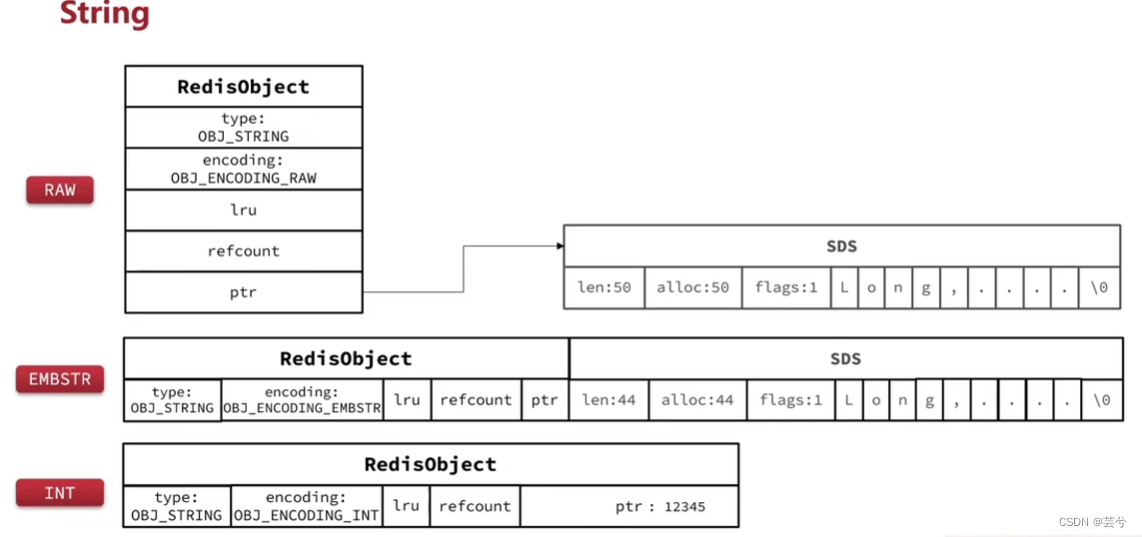
Corda
O RedisObject do tipo String contém muitas informações de cabeçalho, então se você pode usar o tipo numérico, tente usar uma coleção para salvá-lo, para que mais elementos possam ser armazenados em um RedisObject.
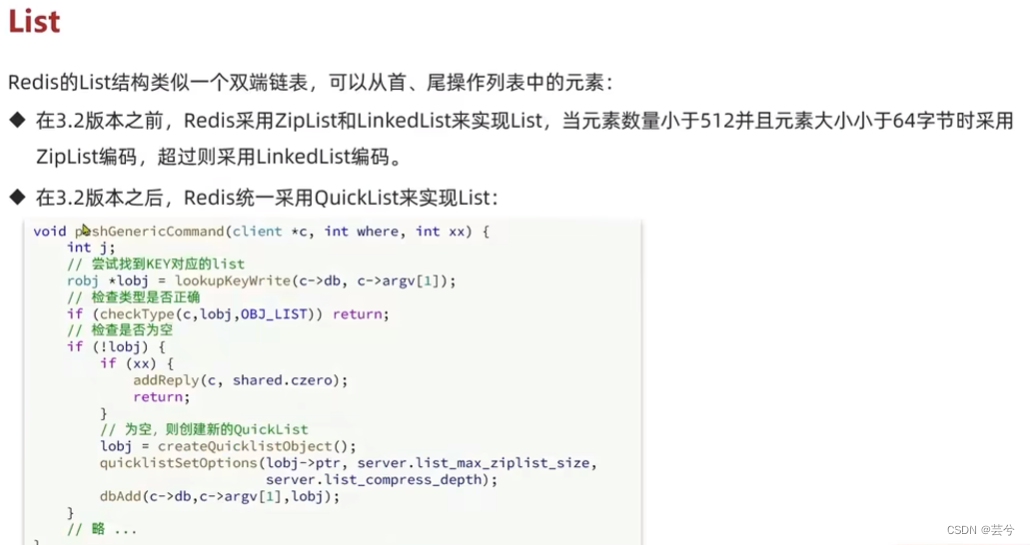
Lista
Antes da versão 3.2, era implementado por ZipList e LinkedList. Após a versão 3.2, era implementado por QuickList.
Definir
- Para eficiência e exclusividade da consulta, Set é implementado usando Dict.
- Ao armazenar todos os dados como números inteiros, isso pode ser realizado usando a codificação IntSet.

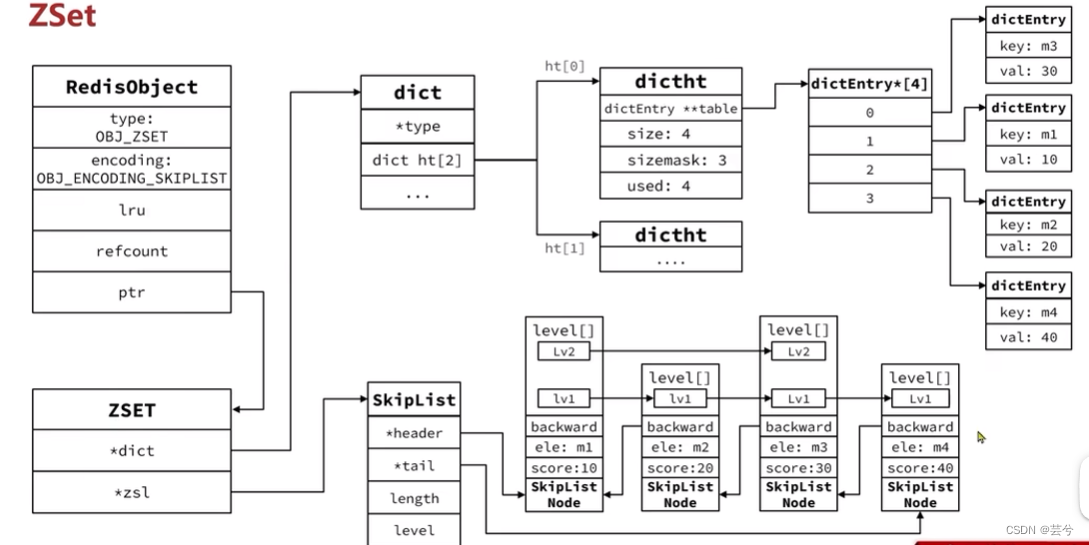
ZSet
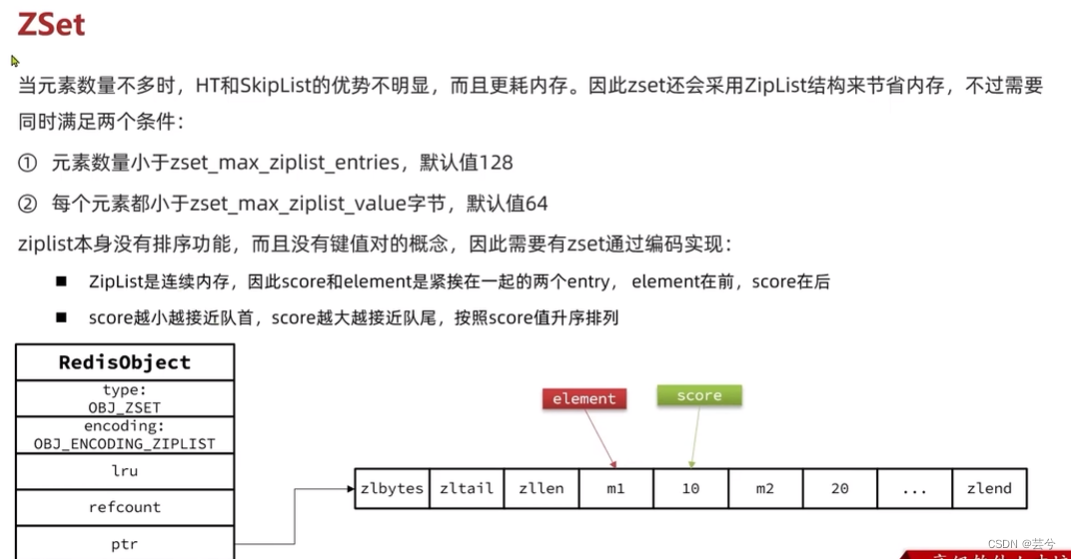
ZSet (coleção ordenada) é realizado por meio de duas estruturas de dados: tabela de salto (para garantir a ordem) e dicionário (para garantir a eficiência da existência da consulta): mas quando o número de elementos não é grande, as vantagens de HT e SkipList não são
óbvias , e ZSet usará a estrutura ZipList para economizar memória:
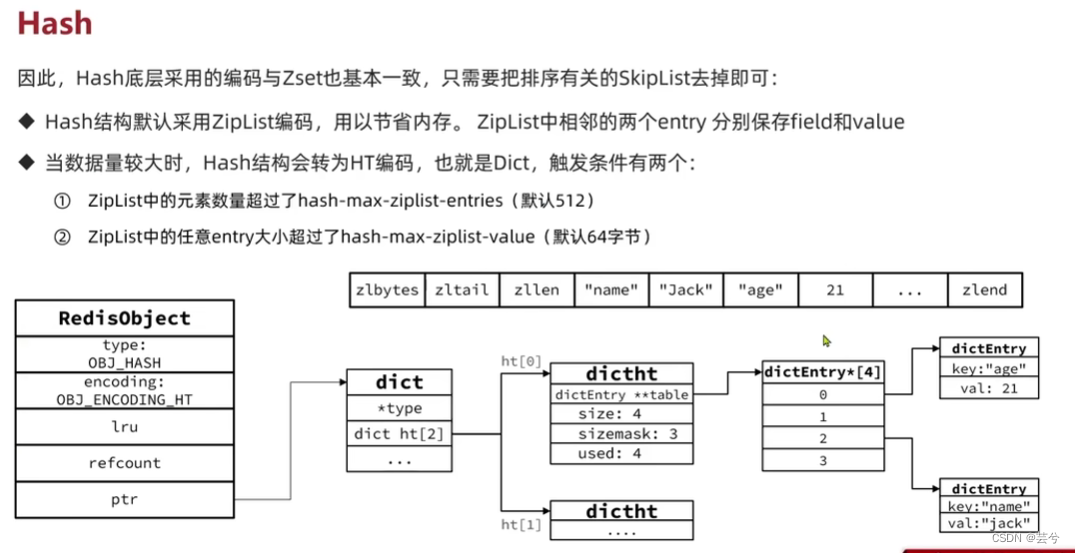
Cerquilha
Modelo de rede Redis
O Redis é de thread único ou multithread?
- Se você falar apenas sobre a parte principal do negócio do Redis (processamento de comandos), todos eles são de thread único.
- Se você falar sobre todo o Redis, é multithreading.
Por que o Redis escolhe thread único?
- Persistência à parte, Redis é uma operação de memória pura com uma velocidade de execução muito rápida. Seu gargalo de desempenho é a latência da rede e não a velocidade de execução, portanto, o multithreading não trará grandes melhorias de desempenho.
- Multithreading pode levar à troca excessiva de contexto de thread, trazendo sobrecarga desnecessária.
- A introdução de multi-threading enfrentará problemas de segurança de thread, e é necessário introduzir bloqueios e outros meios para garantir a segurança de thread.A complexidade de implementação é alta e o desempenho será bastante reduzido.
modo de notificação de eventos epoll

Estratégia de recuperação de memória
política de expiração
Como o Redis sabe se uma chave expirou?

Use dois Dicts para registrar pares chave-valor e chave-TTL respectivamente, notifique o TTL e verifique se ele expirou
Ele é excluído imediatamente quando o TTL expira?
Não, o Redis adota as duas estratégias de expiração a seguir:
- exclusão preguiçosa
- Exclusão periódica
A exclusão lenta significa que quando a mesma chave for acessada novamente mais tarde, ele verificará se a chave expirou e a excluirá se expirar.

No método de exclusão lenta, os dados que expiraram, mas não foram acessados no futuro, sempre sobreviverão e ocuparão memória. Neste momento, o Redis introduziu uma estratégia de exclusão periódica:
Ao definir uma tarefa agendada, a chave é amostrada periodicamente para determinar se ela expirou e, se expirou, excluí-la.
A exclusão periódica possui dois modos de funcionamento:
- Na função initServer() do Redis, a chave expirada será limpa de acordo com a frequência de server.hz, o modo é LENTO e o padrão é 10 vezes por segundo.
- Antes de cada loop de eventos do Redis, a função beforeSleep() é chamada de volta para realizar a limpeza das chaves expiradas, e o modo é FAST.
- SLOW executa frequências baixas, mas limpa mais profundamente. O modelo FAST executa em altas frequências, mas em intervalos curtos.


Estratégia de eliminação
Tempo de execução da estratégia de eliminação de memória:
o Redis tentará eliminar a memória no método processCommand() de processamento de comandos do cliente.
Redis suporta 8 estratégias diferentes para eliminação de chaves.A estratégia de eliminação padrão é noeviction, que não elimina nenhuma chave, mas não permite que novos dados sejam gravados quando a memória está cheia.
Outras estratégias comuns de eliminação de memória são geralmente divididas em processamento de todas as chaves e processamento de chaves com conjunto TTL.
Isso inclui priorizar a eliminação de chaves que estão prestes a expirar de acordo com o TTL.
Eliminação aleatória para todas as chaves, eliminação aleatória para chaves com conjunto TTL.
Todas as chaves ou chaves com TTL definidas são eliminadas com base no algoritmo LRU.
Todas as chaves ou chaves com TTL definidas são eliminadas com base no algoritmo LFU.

LRU e LFU
- LRU (menos usado recentemente), usado menos recentemente. Subtraia o horário do último acesso do horário atual. Quanto maior o valor, maior a prioridade de eliminação.
- LRU é baseado no tempo e sensível ao tempo.Recentemente, as teclas de atalho emergentes têm maior probabilidade de residir na memória, enquanto as chaves que não são usadas há muito tempo têm maior probabilidade de serem eliminadas.
- LFU (menos utilizado), o menos utilizado. A frequência de acesso de cada chave será unificada e quanto menor o valor, maior será a prioridade de eliminação.
- LFU é sensível à frequência e é mais adequado para armazenar chaves que contêm vários pontos de acesso. O último acesso a uma determinada chave foi às 12h00 de ontem, e em 5 minutos às 12h00 de ontem, 200 acessos de alta frequência foram feitos Se hoje ainda houver essa demanda ao meio-dia, de acordo com a estratégia LFU, as teclas de atalho de ontem ficarão residentes na memória.