1. Problemas práticos
Pergunta dos jogadores de golfe: Quero desativar toda a segmentação de palavras digitais puras. Este método no site oficial parece ser inválido para o segmentador de palavras ik!

Existe alguma outra maneira? O gráfico gpt diz que a segmentação de palavras pode ser combinada com expressões regulares, mas o teste parece não funcionar. Minha versão es é 8.5.3.
2. Após comunicação adicional, obtenha a descrição mais precisa do problema
O conteúdo da minha consulta pode ser: "105, Building 10, Tsinghua Garden, Haidian District, Beijing", e os resultados da segmentação de palavras chinesas do ik_smart são: "Beijing", "Haidian District", "Tsinghua Garden", "Building 10", e 105.

Expectativas do usuário: desejo apenas excluir as palavras que são números puros após a segmentação de palavras. Ou seja: espera-se que os resultados finais da segmentação sejam: "Pequim", "Distrito de Haidian", "Jardim Tsinghua" e "Edifício 10".
Para ir mais longe: 10 Edifícios é uma segmentação de palavras, e o usuário espera recuperar o resultado da segmentação de palavras: “10 Edifícios”. Mas 105 tem pouco significado, e o usuário espera remover unidades de segmentação de palavras digitais puras como "105" no estágio de segmentação de palavras.
3. Discussão sobre soluções
Existem tokenizadores que possam atender às necessidades dos usuários? Até agora não!
Então o que fazer? Apenas o tokenizer pode ser personalizado . Como dissemos antes, o núcleo do tokenizer customizado é composto de três partes conforme mostrado na figura abaixo.
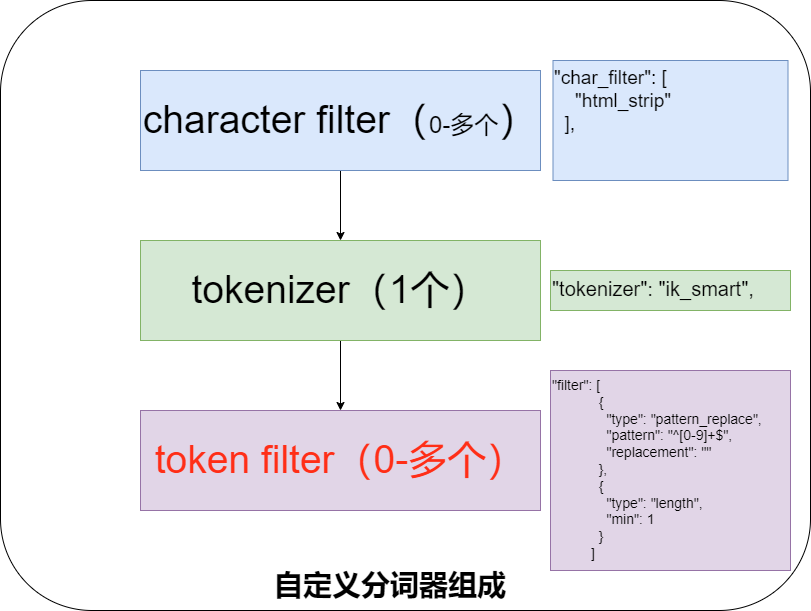
O significado das três partes é o seguinte, combinado com a figura acima será melhor compreendido.
| papel | significado |
|---|---|
| Filtro de caracteres | Processe o texto bruto antes da tokenização, como remover tags HTML ou substituir caracteres específicos. |
| Tokenizador | Defina como dividir o texto em termos ou tokens. Por exemplo, divida o texto em palavras usando espaços ou pontuação. |
| Filtro de token | Execute processamento adicional na saída de tokens pelo Tokenizer, como conversão para letras minúsculas, remoção de palavras irrelevantes ou adição de sinônimos. |
A diferença entre Filtro de Caracteres e Filtro de Token é a seguinte:
Ambos são componentes de pré-processamento de texto no Elasticsearch, mas o tempo e os objetivos de processamento são um pouco diferentes:
| Atributos | Filtro de caracteres | Filtro de token |
|---|---|---|
| Tempo de processamento | Antes do tokenizador | Depois do tokenizador |
| Objeto de ação | sequência de caracteres brutos | entrada ou token |
| A função principal | Pré-processamento de texto, como remoção de HTML, conversão de caracteres específicos | Processe termos, como letras minúsculas, remova palavras irrelevantes, aplique sinônimos, gere radicais, etc. |
| saída | Sequência modificada de caracteres | Lista processada de termos |
Diferença essencial : o Filtro de Caracteres processa no nível do caractere original , enquanto o Filtro de Token processa no nível da palavra após a segmentação da palavra .
Até agora, vamos analisar as necessidades do usuário e esperar remover o “número” após a segmentação da palavra. Ou seja, o processamento do filtro Token após a segmentação de palavras é a solução superior.
Como lidar com o filtro Token? Considere uma expressão regular que é processada uniformemente no nível numérico, e a expressão regular para números é: "^[0-9]+$".
^[0-9]+$ pode ser dividido em várias partes para interpretação:
^: Este símbolo indica a posição inicial da partida. Ou seja, o conteúdo correspondente deve começar no início da sequência de destino.
[0-9]: Esta é uma classe de personagem. Corresponde a qualquer caractere de um dígito de 0 a 9.
+: Este é um quantificador. Indica que o conteúdo anterior (neste caso a classe de caracteres [0-9]) deve ocorrer uma ou mais vezes.
$: Este símbolo indica a posição final da partida. Ou seja, o conteúdo correspondente deve atingir o final da string de destino.
Portanto, no geral, o significado desta expressão regular é: a string contém apenas um ou mais caracteres numéricos do início ao fim, e nenhum outro caractere.
Por exemplo:
"123" corresponde a este regex.
"0123" também corresponde.
Nem "abc", "123a" ou "a123" correspondem.
Em suma, a expressão regular atende basicamente às necessidades dos usuários.
Durante a implementação real, descobrimos que o link do filtro correspondente: filtro "pattern_replace-tokenfilter". Essa filtragem alcançará a substituição no nível do caractere, podemos substituir os números correspondentes regulares por um determinado caractere, como o caractere de espaço "".
No entanto, o requisito ainda não foi atendido e o usuário espera que os caracteres de espaço sejam eliminados. Neste momento, temos que considerar como remover o espaço "".
Verifique o documento oficial do filtro para saber que existe um filtro "analyse-length-tokenfilter", que pode filtrar caracteres de espaço com comprimento 0, definindo o comprimento mínimo como 1.
Desde então, o plano foi inicialmente finalizado.
4. Finalize e verifique inicialmente a solução
Após a discussão acima. Temos uma estratégia de três etapas.
Passo 0: O tokenizer ainda escolhe ik_smart, que é altamente consistente com as necessidades do usuário.
Etapa 1: Encontre os dados numéricos e use o filtro regular "pattern_replace filter" para conseguir. ==> A expressão regular ^[0-9]+$ é substituída por um caractere específico ==> "".
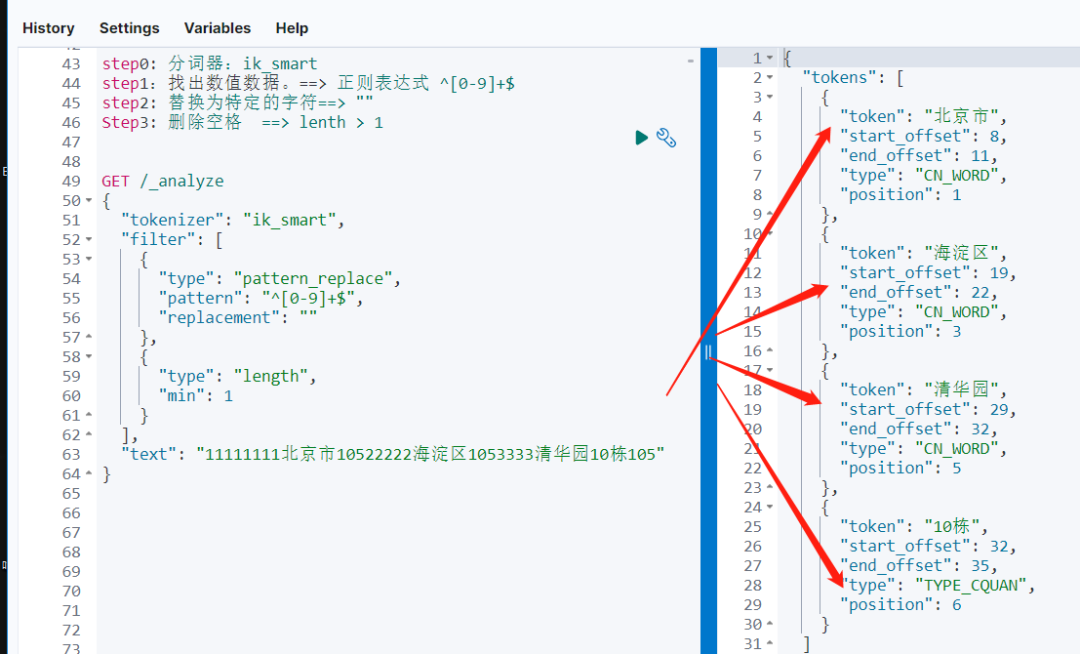
Passo 2: Remova os espaços, com a ajuda do filtro de comprimento. ==> lenth > 1 Verifique em um intervalo pequeno:
GET /_analyze
{
"tokenizer": "ik_smart",
"filter": [
{
"type": "pattern_replace",
"pattern": "^[0-9]+$",
"replacement": ""
},
{
"type": "length",
"min": 1
}
],
"text": "11111111北京市10522222海淀区1053333清华园10栋105"
}Depois de complicar o texto de entrada, os resultados da segmentação de palavras ainda podem atender às expectativas.
5. Implementação prática de segmentação de palavras personalizadas
Com a implementação preliminar anterior, a segmentação personalizada de palavras torna-se fácil.
DELETE my-index-20230811-000002
PUT my-index-20230811-000002
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"tokenizer": "ik_smart",
"filter": [
"regex_process",
"remove_length_lower_1"
]
}
},
"filter": {
"regex_process": {
"type": "pattern_replace",
"pattern": "^[0-9]+$",
"replacement": ""
},
"remove_length_lower_1": {
"type": "length",
"min": 1
}
}
}
},
"mappings": {
"properties": {
"address":{
"type":"text",
"analyzer": "my_custom_analyzer"
}
}
}
}
POST my-index-20230811-000002/_analyze
{
"text": [
"1111北京市3333海淀区444444清华园10栋105"
],
"analyzer": "my_custom_analyzer"
}A definição do índice é interpretada da seguinte forma:
| papel | subseção | nome | descrever |
|---|---|---|---|
| Configurações | Analisador | my_custom_analyzer |
Tokenizers usados: ik_smart- Filtros usados: regex_process,remove_length_lower_1 |
| Configurações | Filtro | regex_process |
Tipo: pattern_replaceum padrão que corresponde a todos os dígitos e os substitui por uma string vazia |
| Configurações | Filtro | remove_length_lower_1 |
tipo: lengthgarante que apenas os termos com comprimento maior ou igual a 1 sejam mantidos |
| Mapeamentos | Propriedades | address |
Tipo: textAnalisador usado: my_custom_analyzer |
O principal objetivo da configuração acima é criar um analisador personalizado que possa processar texto em chinês, substituir tokens puramente digitais por tokens vazios e garantir que os tokens vazios não sejam incluídos nos resultados da análise.
O resultado final é o seguinte e o efeito esperado é alcançado.

6. Resumo
Quando a segmentação de palavras padrão tradicional não consegue atender às nossas necessidades específicas e complexas, lembre-se de que há outro truque: segmentação de palavras personalizada.
Depois de lembrar as três partes da segmentação de palavras personalizadas, desmonte as necessidades de problemas complexos e o problema será resolvido.
A interpretação do vídeo é a seguinte:
Bem-vindos a todos para prestarem atenção à minha conta de vídeo e compartilharem os produtos secos avançados do Elasticsearch de vez em quando!
7, referência
https://www.elastic.co/guide/en/elasticsearch/reference/current/análise-overview.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/análise-comprimento-tokenfilter.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/análise-pattern_replace-tokenfilter.html
Leitura recomendada
Primeiro lançamento em toda a rede! De 0 a 1 vídeo de liberação do Elasticsearch 8.X
Peso Pesado | Dead Lista de Cognição da Metodologia Elasticsearch 8.X
Segmentação de palavras personalizadas do Elasticsearch, comece com uma pergunta

Adquira mais produtos secos com mais rapidez e menos tempo!
Melhore com mais de 2.000 entusiastas da Elastic em todo o mundo!

Na era dos modelos grandes, aprenda produtos secos avançados um passo à frente!