prefácio

Não vou falar sobre o quão populares são os répteis agora. Deixe-me primeiro falar sobre o que esta tecnologia pode fazer, principalmente nos três aspectos seguintes:
1. Rastrear dados, realizar pesquisas de mercado e análises de negócios Rastrear conteúdo de tópicos de alta qualidade de sites como Zhihu e Douban; obter informações de compra e venda de sites imobiliários, analisar tendências de preços de habitação e analisar preços de habitação em diferentes regiões; rastrear trabalho informações de sites de recrutamento. Analise a demanda de talentos e o nível salarial de vários setores.
2. Como dados brutos para aprendizado de máquina e mineração de dados. Por exemplo, se você quiser fazer um sistema de recomendação, poderá rastrear dados mais dimensionais para criar um modelo melhor.
3. Rastreie recursos de alta qualidade: **Imagens, textos, vídeos Rastreie imagens requintadas no jogo, obtenha recursos de imagens e comente dados de texto. Na verdade, é muito fácil dominar o método correto e ser capaz de rastrear os dados dos principais sites em um curto período de tempo. Mas é recomendável que você tenha um objetivo específico desde o início, pois guiado pelo objetivo, seu aprendizado será mais preciso e eficiente.
Aqui está um caminho de aprendizado de início rápido suave e baseado em zero para você:
-
Entenda como os répteis são implementados
-
Realize rastreamento simples de informações
-
Medidas anti-rastreador para sites especiais
-
Distribuição scrapy e avançada
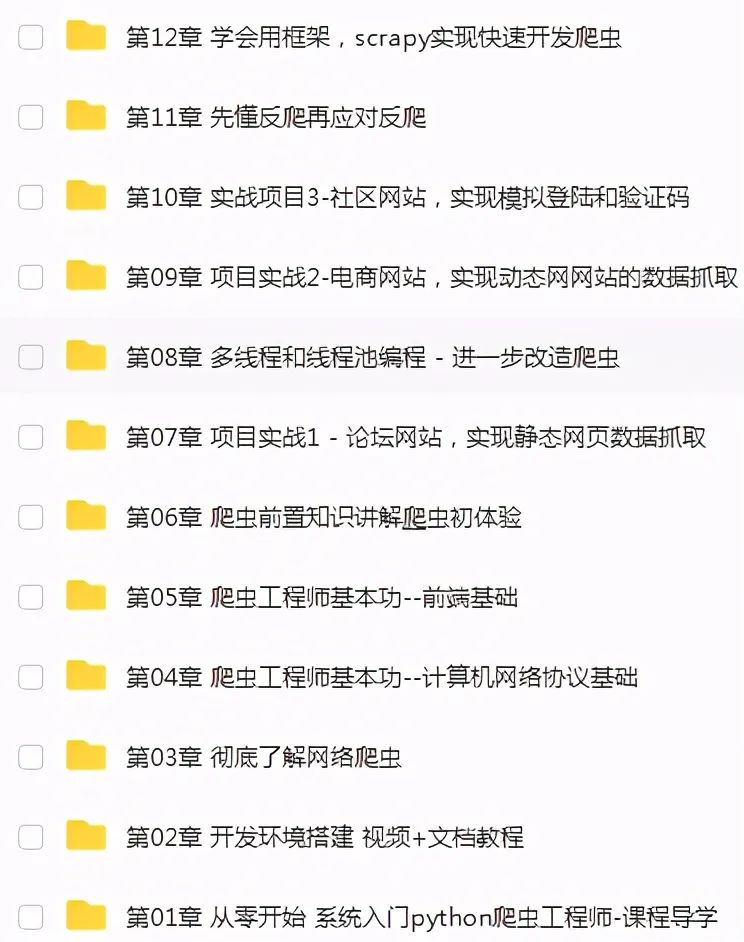
01 Entenda como os crawlers são implementados
A maioria dos rastreadores segue o processo de "envio de solicitações - obtenção de páginas - análise de páginas - extração e armazenamento de conteúdo", que na verdade simula o processo de uso de um navegador para obter informações de páginas da web. Simplificando, após enviarmos uma solicitação ao servidor, obteremos a página retornada.Após analisar a página, podemos extrair a parte da informação que desejamos e armazená-la no documento ou banco de dados especificado. Nesta parte, você pode entender simplesmente o protocolo HTTP e o conhecimento básico de páginas da web, como POST\GET, HTML, CSS e JS, e pode simplesmente entendê-lo sem aprendizado sistemático.
02 Realize rastreamento simples de informações
Existem muitos pacotes relacionados ao rastreador em Python: urllib, requests, bs4, scrapy, pyspider, etc. É recomendado que você comece com requests+Xpath. Requests é responsável por conectar-se a sites e retornar páginas da web. XPath é usado para analisar páginas da web para fácil extração de dados. Se você usou o BeautifulSoup, descobrirá que o XPath evita muitos problemas e o trabalho de verificação do código do elemento, camada por camada, é totalmente omitido. Depois de dominá-lo, você descobrirá que as rotinas básicas dos rastreadores são semelhantes, e sites estáticos em geral não são um problema, e informações públicas em sites como Zhihu e Douban podem ser rastreadas. Claro, se você precisar rastrear sites carregados de forma assíncrona, você pode aprender a capturar o navegador para analisar solicitações reais ou aprender Selenium para realizar o rastreamento automático.Dessa forma, sites dinâmicos como Zhihu, Mtime e TripAdvisor basicamente não são problema. Você também precisa entender o básico do Python, como: operações de leitura e gravação de arquivo: usadas para ler parâmetros e salvar lista de conteúdo rastreado (lista), dict (dicionário): usado para serializar julgamento de condição de dados rastreados (if/else): Resolva o julgamento no rastreador sobre a execução de loops e iterações (for ... while): usado para percorrer as etapas do rastreador
03Mecanismo anti -rastreamento para sites especiais
No processo de rastreamento, também sentirei algum desespero, como ser bloqueado pelo site, como vários códigos de verificação estranhos, restrições de acesso do userAgent, vários carregamentos dinâmicos, etc.
Ao encontrar esses métodos anti-crawler, é claro, algumas habilidades avançadas são necessárias para lidar com eles, como controle de frequência de acesso, uso de pool de IP proxy, captura de pacotes, processamento de OCR de códigos de verificação, etc.
Por exemplo, muitas vezes descobrimos que o URL de alguns sites não muda depois de virar a página, o que geralmente é um carregamento assíncrono. Usamos ferramentas de desenvolvedor para analisar informações de carregamento de páginas da web e geralmente podemos obter ganhos inesperados.
Muitas vezes, os sites preferem o primeiro entre desenvolvimento eficiente e anti-rastreadores, o que também oferece espaço para rastreadores. Dominar essas habilidades anti-rastreadores não será difícil para a maioria dos sites.
04Scrapy e distribuição avançada
O uso de solicitações + xpath e método de captura de pacotes pode de fato resolver o rastreamento de muitas informações do site, mas será difícil rastrear se a quantidade de informações for relativamente grande ou precisar ser rastreada por módulos. Posteriormente, foi aplicado ao poderoso framework Scrapy, que não só pode construir facilmente o Request, mas também possui um poderoso Seletor que pode analisar facilmente o Response.No entanto, o mais surpreendente é seu altíssimo desempenho, que pode projetar e modularizar crawlers . Depois de aprender Scrapy, tentei construir sozinho uma estrutura de rastreador simples. Ao fazer rastreamento de dados em grande escala, posso pensar em problemas de rastreamento em grande escala de uma forma estruturada e de engenharia. Isso me permite pensar sobre os problemas da perspectiva de engenharia de rastreadores. Mais tarde, gradualmente entrei em contato com rastreadores distribuídos, isso parece um blefe, mas na verdade usa o princípio de multi-threading para permitir que vários rastreadores trabalhem ao mesmo tempo, o que pode alcançar maior eficiência.
Na verdade, depois de aprender isso, você pode basicamente dizer que é um velho condutor de répteis, é difícil para leigos, mas não é tão complicado. Porque a tecnologia crawler não exige que você seja sistematicamente proficiente em um idioma, nem requer tecnologia avançada de banco de dados.A postura eficiente é aprender esses pontos de conhecimento dispersos em projetos reais, e você pode garantir que cada vez que aprender As partes que são mais necessário.
É claro que o único problema é que, em problemas específicos, como encontrar a parte dos recursos de aprendizagem que são especificamente necessários, como filtrar e identificar, é um grande problema enfrentado por muitos iniciantes. Mas não se preocupe, preparamos um curso muito sistemático sobre répteis. Além de fornecer um caminho de aprendizagem claro, selecionamos os recursos de aprendizagem mais práticos e uma enorme biblioteca de casos convencionais de répteis. Após um curto período de estudo, você será capaz de dominar bem a habilidade de rastrear e obter os dados desejados.
1. Introdução ao Python
O conteúdo a seguir é o conhecimento básico necessário para todas as direções de aplicação do Python. Se você deseja fazer crawlers, análise de dados ou inteligência artificial, você deve aprendê-los primeiro. Qualquer coisa alta é construída sobre fundações primitivas. Com uma base sólida, o caminho a seguir será mais estável.Todos os materiais são gratuitos no final do artigo!!!
Incluir:
Noções básicas de informática
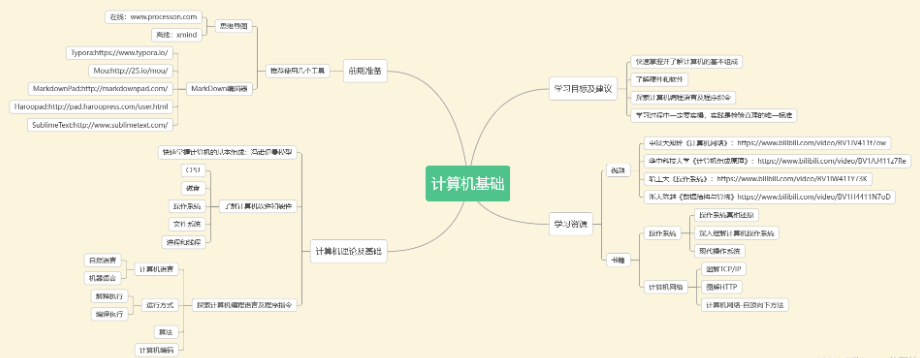
noções básicas de python

Vídeo introdutório do Python com 600 episódios:
Assistir ao vídeo de aprendizagem base zero é a maneira mais rápida e eficaz de aprender. Seguindo as ideias do professor no vídeo, ainda é muito fácil começar do básico ao aprofundado.
2. Rastreador Python
Como orientação popular, os répteis são uma boa escolha, seja para um trabalho de meio período ou como uma habilidade auxiliar para melhorar a eficiência do trabalho.
Conteúdo relevante pode ser coletado por meio da tecnologia crawler, analisado e excluído para obter as informações que realmente precisamos.
Este trabalho de coleta, análise e integração de informações pode ser aplicado em uma ampla gama de campos. Quer se trate de serviços de vida, viagens, investimentos financeiros, demanda do mercado de produtos de diversas indústrias de manufatura, etc., a tecnologia crawler pode ser usada para obter informações mais precisas e informação eficaz.

Material de vídeo do rastreador Python
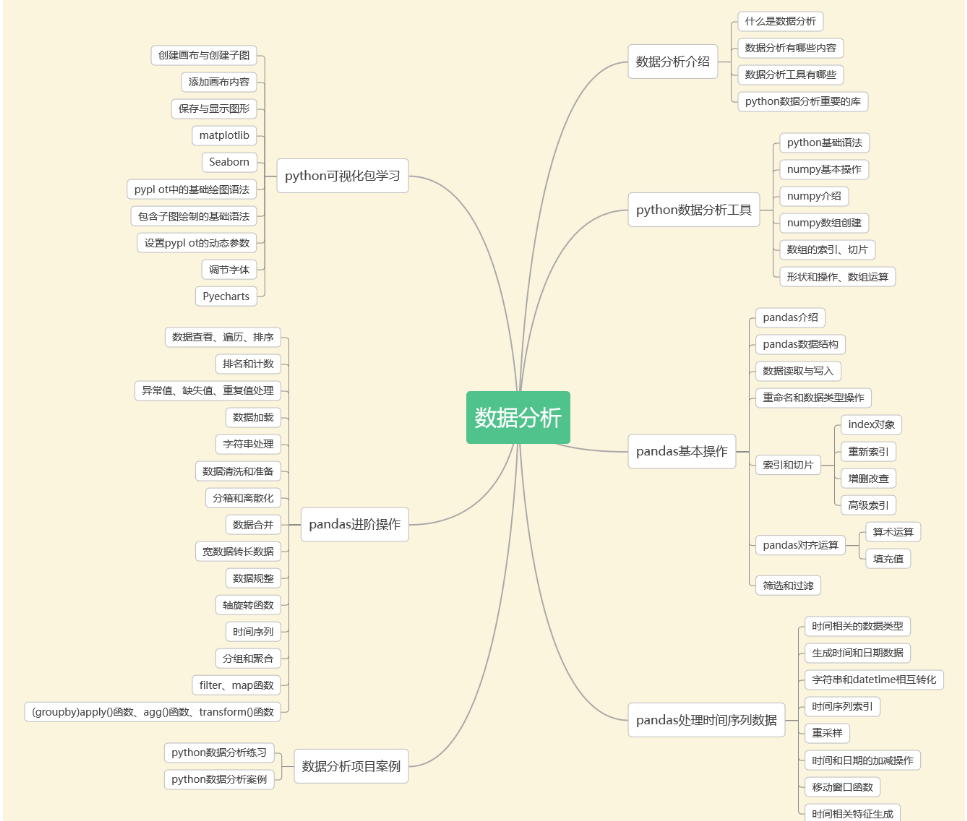
3. Análise de dados
De acordo com o relatório "Transformação Digital da Economia da China: Talentos e Emprego" divulgado pela Escola de Economia e Gestão da Universidade Tsinghua, a lacuna nos talentos de análise de dados deverá atingir 2,3 milhões em 2025.
Com uma lacuna de talentos tão grande, a análise de dados é como um vasto oceano azul! Um salário inicial de 10 mil é realmente comum.
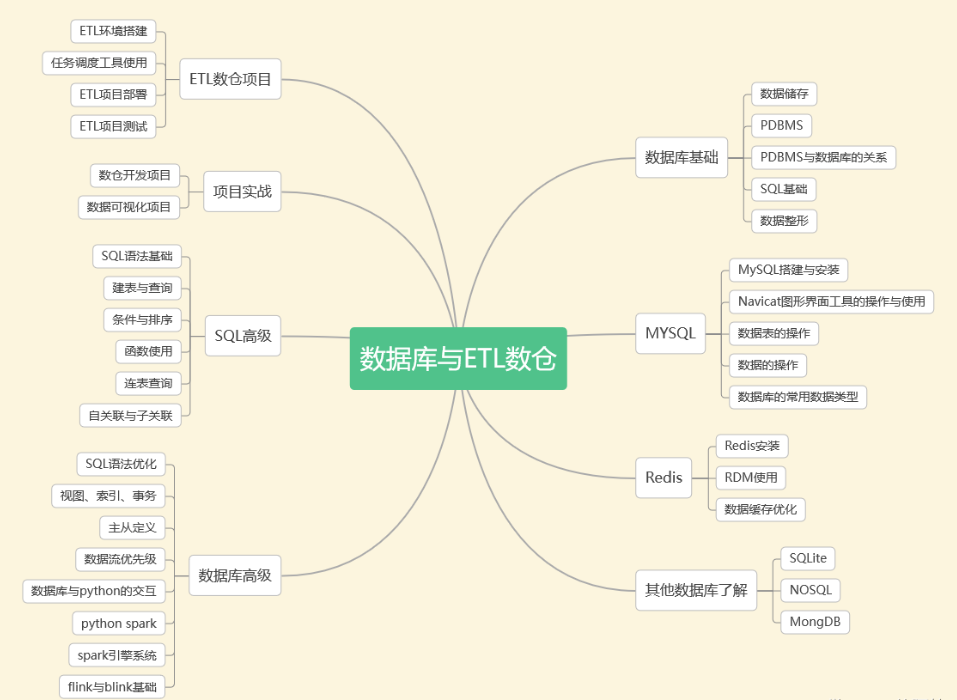
4. Banco de dados e data warehouse ETL
As empresas precisam transferir regularmente dados frios do banco de dados de negócios e armazená-los em um armazém dedicado ao armazenamento de dados históricos. Cada departamento pode fornecer serviços de dados unificados com base em suas próprias características de negócios. Este armazém é um armazém de dados.
A arquitetura tradicional de processamento de integração de data warehouse é ETL, usando os recursos da plataforma ETL, E = extrair dados do banco de dados de origem, L = limpar os dados (dados que não estão em conformidade com as regras), transformar (dimensão diferente e granularidade diferente da tabela de acordo com as necessidades do negócio) cálculo de diferentes regras de negócio), T = carrega as tabelas processadas no data warehouse de forma incremental, completa e em momentos diferentes.
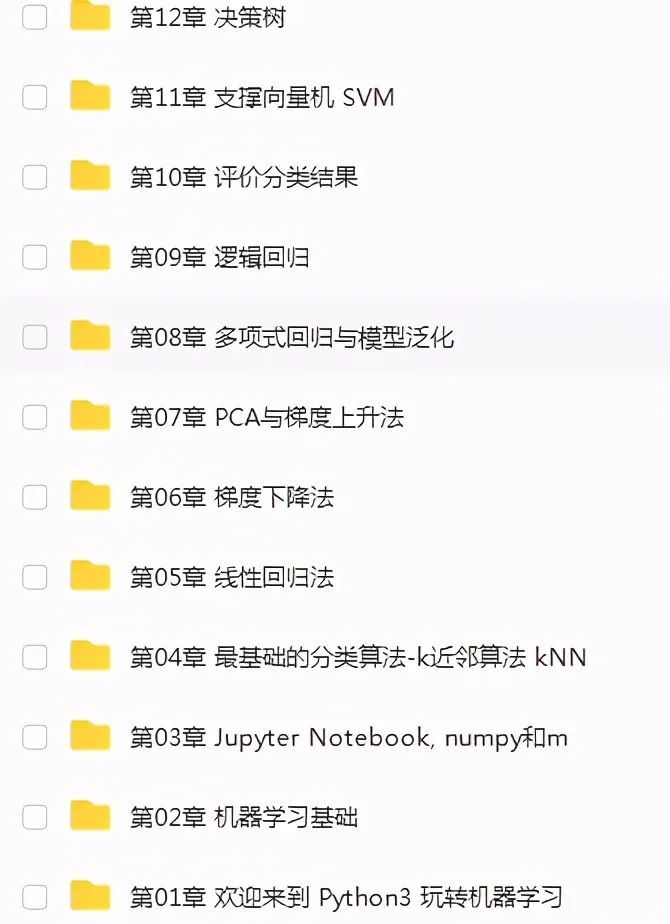
5. Aprendizado de máquina
O aprendizado de máquina consiste em aprender parte dos dados do computador e, em seguida, prever e julgar outros dados.
Basicamente, o aprendizado de máquina consiste em “usar algoritmos para analisar dados, aprender com eles e, em seguida, tomar decisões ou previsões sobre novos dados”. Ou seja, um computador usa os dados obtidos para obter um determinado modelo e, em seguida, usa esse modelo para fazer previsões. Este processo é um pouco semelhante ao processo de aprendizagem humana. Por exemplo, as pessoas podem prever novos problemas após obterem certa experiência.

Materiais de aprendizado de máquina:
6. Python avançado
Do conteúdo gramatical básico a muitos pontos de conhecimento avançado e aprofundado, para entender o design da linguagem de programação, depois de aprender aqui, você basicamente entende todos os pontos de conhecimento, desde o básico até o avançado em python.

Neste ponto, você pode basicamente atender aos requisitos de emprego da empresa. Se você ainda não sabe onde encontrar materiais de entrevista e modelos de currículo, também compilei uma cópia para você. Pode-se realmente dizer que é um aprendizado sistemático rota para babá e.
Mas a aprendizagem da programação não se consegue da noite para o dia, mas requer persistência e formação a longo prazo. Ao organizar este percurso de aprendizagem, espero progredir juntamente com todos, podendo eu próprio rever alguns pontos técnicos. Quer você seja um novato em programação ou um programador experiente que precisa ser avançado, acredito que todos podem ganhar algo com isso.
Pode ser alcançado durante a noite, mas requer persistência e treinamento a longo prazo. Ao organizar este percurso de aprendizagem, espero progredir juntamente com todos, podendo eu próprio rever alguns pontos técnicos. Quer você seja um novato em programação ou um programador experiente que precisa ser avançado, acredito que todos podem ganhar algo com isso.
Coleção de dados
Esta versão completa do conjunto completo de materiais de aprendizagem Python foi carregada no CSDN oficial. Se precisar, você pode clicar no cartão WeChat de certificação oficial da CSDN abaixo para obtê-lo gratuitamente ↓↓↓ [Garantido 100% gratuito ]

Bom artigo recomendado
Entenda a perspectiva do python: https://blog.csdn.net/SpringJavaMyBatis/article/details/127194835
Saiba mais sobre a linha lateral de meio período do python: https://blog.csdn.net/SpringJavaMyBatis/article/details/127196603