O 7º Desafio de Modelagem Matemática da Universidade MathorCup em 2017
Pergunta A: Fabricação Inteligente na Indústria de Processos
Reprodução do título original:
"Made in China 2025" é uma grande estratégia nacional para a modernização da indústria transformadora do meu país. O núcleo de sua tecnologia é a fabricação inteligente, e o grau de inteligência é equivalente ao nível da “Indústria Alemã 4.0”. As principais áreas do "Made in China 2025" incluem não apenas a indústria de fabricação de equipamentos importantes, mas também a indústria de processos de nova energia e fabricação de novos materiais.
Na indústria de processo, a metalurgia siderúrgica, a petroquímica e outras indústrias são indústrias pilares representativas da economia nacional. A função objetivo de otimização do sistema e controle inteligente de seu processo de produção inclui requisitos multiobjetivos como economia de energia, alta qualidade, baixo consumo e proteção ambiental. Para atingir tal objetivo de otimização, a tecnologia chave de controle inteligente do processo de produção deve ser ainda mais atualizada, do controle de feedback original para o controle preditivo. Ou seja, através da modelagem do sistema ciberfísico (Sistema Ciberfísico) do big data do processo produtivo, por meio da mineração de big data, determinar a melhor forma e a melhor faixa de controle de parâmetros do processo produtivo, ajustar de forma preditiva e dinâmica o controle do processo produtivo e obtenha o melhor efeito de produção.
Tomando como exemplo a fundição de ferro fundido de alta qualidade em alto-forno, o processo de fabricação de ferro em alto-forno é um processo de fundição no qual matérias-primas como minério e coque são adicionadas do topo do alto-forno na ordem de alimentação, e o ar quente é soprado continuamente a partir do fundo do alto-forno, e pó de carvão é injetado para ajustar a temperatura do forno. O período de fundição é de 6 a 8 horas a partir do momento em que a matéria-prima é adicionada ao topo do forno até a fundição em escória e ferro fundido. O alto-forno extrai escória e ferro a cada 2 horas. E a composição química do ferro fundido e da escória dessa extração foi obtida por meio de testes de laboratório. Portanto, existe uma correlação entre o teor de silício dos dois fornos, ou seja, a temperatura do forno. O processo de fabricação de ferro é um processo de produção complexo de entrada discreta, fundição contínua e saída discreta.
O mecanismo do processo de fabricação de ferro inclui não apenas o processo de reação química limitado pelo equilíbrio térmico/equilíbrio material, mas também o processo de movimento físico causado pela mistura dinâmica de fluidos trifásica. Portanto, o modelo de mecanismo completo do processo de fundição é um modelo matemático complexo composto de equações algébricas e equações diferenciais parciais.As equações do modelo são as seguintes: É um problema matemático não resolvido resolver a solução ótima das equações cinéticas mistas acima a partir do mecanismo
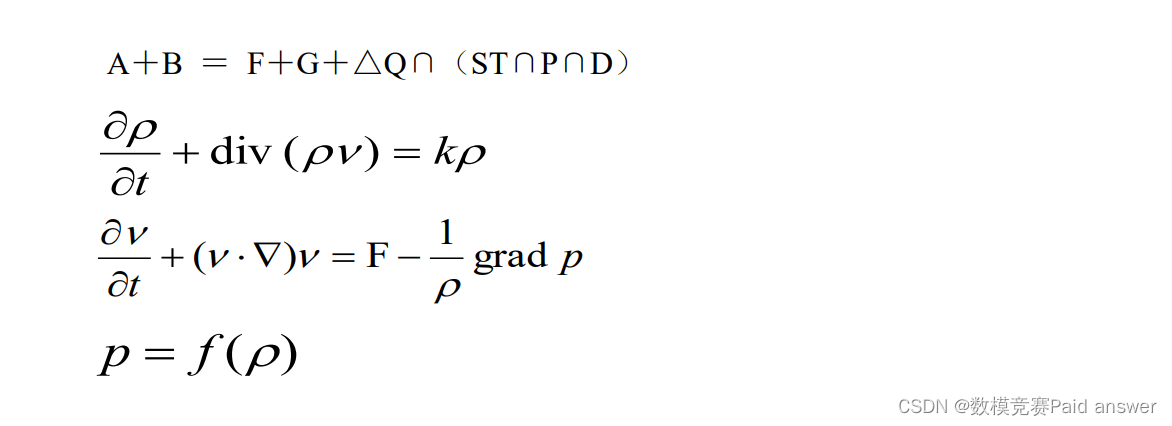
. Portanto, a otimização de processos por meio da tecnologia de mineração de big data é uma solução viável.
Os parâmetros do processo coletados em ordem cronológica durante o processo de fabricação do ferro são uma série temporal de big data de alta dimensão. Existem centenas de fatores que influenciam. Seus indicadores finais de produção, como produção, consumo de energia e qualidade do ferro fundido, estão intimamente relacionados a um indicador intermediário de controle no processo de fundição - temperatura do forno, ou seja, o teor de silício [Si] no ferro fundido (porcentagem em massa de silício no ferro fundido). ferro). A previsão do aumento ou queda da temperatura do alto-forno após 2 ou 4 horas, ou seja, a previsão da série temporal [Si], está relacionada à direção de controle da corrente de diversos parâmetros operacionais do alto-forno. Portanto, a modelagem precisa do controle preditivo de [Si] tornou-se uma tecnologia chave para a otimização do processo de fundição e o controle preditivo.
Para simplificar o problema, este projeto fornece apenas um banco de dados composto por teor de silício [Si], teor de enxofre [S], volume de injeção de carvão PML e volume de explosão FL como base para análise de modelagem matemática e mineração de dados. O número de série N não é apenas o número de série da sequência de dados, mas também o número de série do tempo de vazamento do alto-forno.
Os requisitos para a modelagem matemática deste projeto são:
(1) A partir do big data de produção de 1000 fornos organizados em sequência [Si]-[S]-FL-PML na tabela de dados fornecida, selecionar independentemente amostras e algoritmos de aprendizagem e estabelecer [Si]] Modelos matemáticos dinâmicos de previsão, incluindo modelo de previsão de uma etapa e modelo de previsão de duas etapas. Uma discussão abrangente de suas ideias de modelagem matemática.
(2) Selecione amostras de verificação de forma independente para verificar a taxa de sucesso da previsão do modelo matemático que você estabeleceu. Incluindo a taxa de sucesso da previsão numérica e a taxa de sucesso do aumento da temperatura do forno e da previsão da direção da queda. E discuta a viabilidade de seu controle preditivo dinâmico.
(3) Tomando como exemplo o teor de enxofre [S] do índice de qualidade do ferro fundido, o teor de enxofre é baixo e a qualidade do ferro fundido é boa, o que pode produzir aço e equipamentos de alta qualidade. Tente estabelecer o modelo matemático de otimização do índice de qualidade [S] e discuta o efeito esperado do controle preditivo [Si] de acordo com os resultados do cálculo do modelo de otimização.
(4) Discuta sua experiência na modelagem de big data de controle inteligente industrial complexo.

Visão geral do processo geral de solução (resumo)
Sob a estratégia nacional de "Made in China 2025" para atualizar a indústria manufatureira do meu país, a fim de prever e controlar o processo de fabricação de ferro do alto-forno, este artigo estabeleceu um modelo de previsão de rede neural e um modelo caótico de previsão de série temporal, e melhorou o neural modelo de rede baseado em algoritmo genético (GA) O teor de enxofre [S] foi otimizado usando Particle Swarm Optimization (PSO).
Para o problema 1, em primeiro lugar, este artigo pré-processa os dados fornecidos no anexo, remove outliers e normaliza-os, obtendo 932 conjuntos de dados válidos. Em seguida, o modelo de predição da rede neural BP foi estabelecido para prever o teor de silício [Si], e a correlação entre o teor de silício [Si], teor de enxofre [S], volume de explosão FL e volume de injeção de carvão PML foi analisada. Em segundo lugar, o modelo de predição da rede neural wavelet e o modelo de predição da rede neural BP otimizado pelo Algoritmo Genético (GA) são estabelecidos e as vantagens e desvantagens dos três são comparadas. Em seguida, 922 grupos de dados de amostra de treinamento foram selecionados e 10 grupos de dados de amostra de verificação foram selecionados. Verificou-se que o modelo de predição de rede neural BP e o modelo de predição de rede neural wavelet otimizado pelo algoritmo genético tiveram melhor efeito de predição, mas o BP o modelo de predição da rede neural era pior. Finalmente, o modelo caótico de previsão de séries temporais é estabelecido neste artigo, e a previsão caótica local linear de uma etapa e a previsão de duas etapas são realizadas para o teor de silício [Si].
Para a segunda questão, em primeiro lugar, este artigo seleciona 922 conjuntos de dados como amostras de treinamento e 10 conjuntos de dados como amostras de verificação.O modelo tradicional de predição de rede neural BP, modelo de predição de modelo de rede neural wavelet, modelo de predição de rede neural BP baseado em otimização de algoritmo genético e caos Modelo de previsão de série temporal, prevendo respectivamente os resultados do teor de silício [Si] nas últimas 10 baterias e comparando com o valor real, calcula-se que a taxa de sucesso da previsão de BP é de 20%, a da previsão de wavelet é de 70%, e o de GA+BP é de 60%.A previsão do caos é de 80%. Em segundo lugar, os resultados do teor de silício [Si] dos últimos 10 fornos foram previstos por diferentes modelos, e a direção do aumento e queda da temperatura do forno foi prevista, e o cálculo obtido: a taxa de sucesso da previsão de BP foi de 40%, o a previsão wavelet foi de 100%, e a previsão GA + BP é 100%, e a previsão do caos é 100%. Finalmente, ao discutir a seleção da função de treinamento da rede neural, a configuração dos parâmetros de desempenho da rede neural e a
seleção do raio da vizinhança para previsão caótica de séries temporais, a viabilidade do controle preditivo dinâmico é analisada.
Para a terceira questão, em primeiro lugar, este artigo otimiza o modelo de predição da rede neural BP de acordo com o algoritmo genético (GA), prevê o teor de enxofre [S] e descobre o teor de enxofre [S] e o teor de silício [Si], volume de explosão A relação entre FL e a quantidade de injeção de carvão PML. Então, este artigo utiliza o algoritmo de otimização por enxame de partículas (PSO) para otimizar o teor de enxofre [S], e obtém-se que o teor de enxofre [S] tem um valor mínimo quando o volume de explosão é normalizado FL=0,7012 e a injeção de carvão volume PML=0,0809. Por fim, este artigo analisa o efeito esperado da previsão e controle do teor de silício [Si] sob a condição ótima de teor de enxofre [S]. ] é menor, sendo 0,5712.
Para a quarta questão, combinamos o histórico de modelagem, os resultados obtidos na resolução do modelo e as conclusões obtidas nos resultados da análise e, com base na importância do controle inteligente em indústrias de processos complexos, falamos brevemente sobre a experiência de modelagem. Através da mineração de big data, podemos determinar a melhor forma e a melhor faixa de parâmetros do processo de produção para obter o melhor efeito de produção.
Suposições do modelo:
(1) Suponha que na predição linear local caótica, a seleção da vizinhança ε seja objetiva e precisa, e a subjetividade seja pequena.
(2) Suponha que na previsão linear local caótica, as propriedades locais possam representar com precisão as propriedades globais.
(3) Suponha que na previsão de redes neurais as variáveis de entrada sejam razoavelmente eficientes como a primeira camada da rede.
(4) Presume-se que os dados fornecidos no apêndice e os dados utilizados são verdadeiros e exatos.
(5) Suponha que os dados compostos pelo teor de silício [Si], teor de enxofre [S], volume de injeção de carvão PML e volume de explosão FL no ferro fundido possam representar o processo de fabricação de ferro do alto-forno e refletir as características de produção de ferro do alto-forno.
analise de problemas:
Análise da Questão 1: Na Questão 1, o título exige que selecionemos independentemente amostras e algoritmos de aprendizagem do big data de produção de 1000 fornos organizados em sequência [Si]-[S]-FL-PML na tabela de dados fornecida e estabeleçamos [ Si] previsão de modelos matemáticos dinâmicos, incluindo modelo de previsão de uma etapa e modelo de previsão de duas etapas. O modelo de predição de uma etapa e o modelo de predição de duas etapas significam que o comprimento da etapa de predição é 1 e 2, respectivamente, e há uma correlação entre o teor de silício dos dois fornos, ou seja, a temperatura do forno. As amostras de aprendizagem aqui não podem ser todos os 1.000 lotes de big data de produção, porque precisamos verificar a taxa de sucesso da previsão do modelo matemático estabelecido na questão 2, portanto, não podemos escolher todos os dados para treinamento, mas apenas uma parte dos dados para aprendizagem e treinamento. Quanto ao algoritmo de modelagem, ele precisa ser selecionado em combinação com o problema em si.
Análise da Pergunta 2: Na Pergunta 2, a questão exige que selecionemos amostras de verificação de forma independente para verificar a taxa de sucesso da previsão do modelo matemático que estabelecemos, incluindo a taxa de sucesso da previsão numérica e a taxa de sucesso da previsão do aumento e da direção da queda da temperatura do forno. E discuta a viabilidade de seu controle preditivo dinâmico. Precisamos selecionar amostras de verificação dos dados de treinamento restantes não aprendidos no big data de produção de 1.000 fornos e verificar a taxa de sucesso, incluindo o conteúdo de [Si] e a direção do aumento e queda da temperatura do forno. A dificuldade está em discutir a viabilidade de seu controle preditivo dinâmico e como melhorar a taxa de sucesso preditivo do algoritmo.
Análise da Questão 3: Na Questão 3, o título exige que tomemos como exemplo o teor de enxofre [S] do índice de qualidade do ferro fundido. O teor de enxofre é baixo e a qualidade do ferro fundido é boa, o que pode produzir alta- aço de qualidade e equipamentos de alta qualidade. Tente estabelecer o modelo matemático de otimização do índice de qualidade [S] e discuta o efeito esperado do controle preditivo [Si] de acordo com os resultados do cálculo do modelo de otimização. Através da mineração de big data, determine a melhor forma e a melhor faixa de controle de parâmetros do processo de produção, ajuste preditiva e dinamicamente o controle do processo de produção, obtenha o melhor efeito de produção, estabeleça um modelo de otimização e discuta o controle preditivo de [Si].
Análise da Questão 4: Na Questão 4, o tópico exige que discutamos nossa experiência na modelagem de big data de controle inteligente da indústria de processos complexos, que precisa ser discutida em combinação com os resultados e o histórico de nosso modelo.
Estabelecimento e solução de modelo Miniatura geral do artigo



Para todos os trabalhos, veja abaixo "Modelagem apenas de cartões de visita QQ" Clique no cartão de visita QQ
Código do programa: (código e documentação não gratuitos)
O procedimento real é mostrado na captura de tela
1 def BP(sampleinnorm, sampleoutnorm,hiddenunitnum=3):
2 # 超参数
3 maxepochs = 60000 # 最大迭代次数
4 learnrate = 0.030 # 学习率
5 errorfinal = 0.65*10**(-3) # 最终迭代误差
6 indim = 3 # 输入特征维度3
7 outdim = 2 # 输出特征唯独2
8 # 隐藏层默认为3个节点,1层
9 n,m = shape(sampleinnorm)
10 w1 = 0.5*np.random.rand(hiddenunitnum,indim)-0.1 #8*3维
11 b1 = 0.5*np.random.rand(hiddenunitnum,1)-0.1 #8*1维
12 w2 = 0.5*np.random.rand(outdim,hiddenunitnum)-0.1 #2*8维
13 b2 = 0.5*np.random.rand(outdim,1)-0.1 #2*1维
14
15 errhistory = []
16
17 for i in range(maxepochs):
18 # 激活隐藏输出层
19 hiddenout = sigmod((np.dot(w1,sampleinnorm).transpose()+b1.transpose())).transpose()
20 # 计算输出层输出
21 networkout = (np.dot(w2,hiddenout).transpose()+b2.transpose()).transpose()
22 # 计算误差
23 err = sampleoutnorm - networkout
24 # 计算代价函数(cost function)sum对数组里面的所有数据求和,变为一个实数
25 sse = sum(sum(err**2))/m
26 errhistory.append(sse)
27 if sse < errorfinal: #迭代误差
28 break
29 # 计算delta
30 delta2 = err
31 delta1 = np.dot(w2.transpose(),delta2)*hiddenout*(1-hiddenout)
32 # 计算偏置
33 dw2 = np.dot(delta2,hiddenout.transpose())
34 db2 = 1 / 20 * np.sum(delta2, axis=1, keepdims=True)
35
36 dw1 = np.dot(delta1,sampleinnorm.transpose())
37 db1 = 1/20*np.sum(delta1,axis=1,keepdims=True)
38
39 # 更新权值
40 w2 += learnrate*dw2
41 b2 += learnrate*db2
42 w1 += learnrate*dw1
43 b1 += learnrate*db1
44
45 return errhistory,b1,b2,w1,w2,maxepochs
import numpy as np
#定义激活函数
def sigmoid(x,deriv=False):
if deriv == True:
return x*(1-x)
return 1/(1+np.exp(-x))
x = np.array([[0,0,0],[0,1,1],[1,0,1],[0,0,1],[0,0,1]])
print(x.shape)
#指定label值
y = np.array([[0],[1],[1],[0],[0]])
print(y.shape)
#指定随机化种子,使得每次随机值一样
np.random.seed(1)
#定义三层的神经网络
w0 = 2*np.random.random((3,4)) - 1
w1 = 2*np.random.random((4,1)) - 1
print(w0)
print(w1)
for j in range(6000):
l0 = x
l1 = sigmoid(np.dot(l0,w0))
l2 = sigmoid(np.dot(l1,w1))
#真实值-预测值
l2_error = y - l2
if j%1000 == 0 :
print("error"+str(np.mean(np.abs(l2_error))))
l2_delta = l2_error*sigmoid(l2,deriv=True)
l1_error = l2_delta.dot(w1.T)
l1_delta = l1_error*sigmoid(l1,deriv=True)
#更新w0 w1
w1 += l1.T.dot(l2_delta)
w0 += l0.T.dot(l1_delta)