Notas de estudo da série de detecção de alvo de aprendizagem profunda Baidu Flying Paddle Zero-Basic Practice
Índice
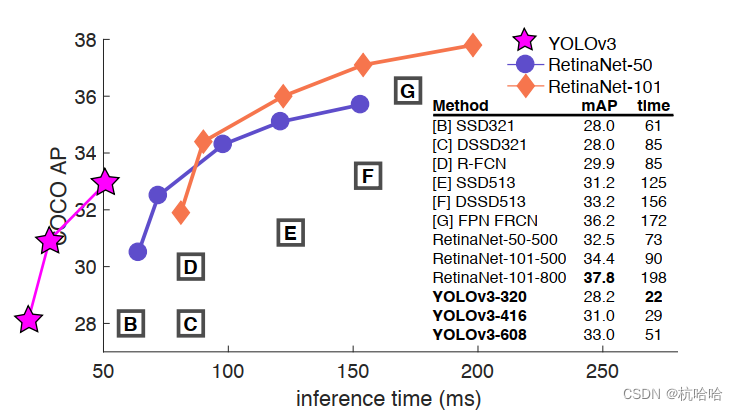
Estrutura YOLOv3
Recursos da estrutura de rede YOLOv3:
1. Somente convolução sem pooling
2.3 mapas de recursos para detectar objetos de tamanhos diferentes
3. Use a estrutura ResNet
4.3 mapas de recursos para usar add para emenda
5. Use sigmoid para obter
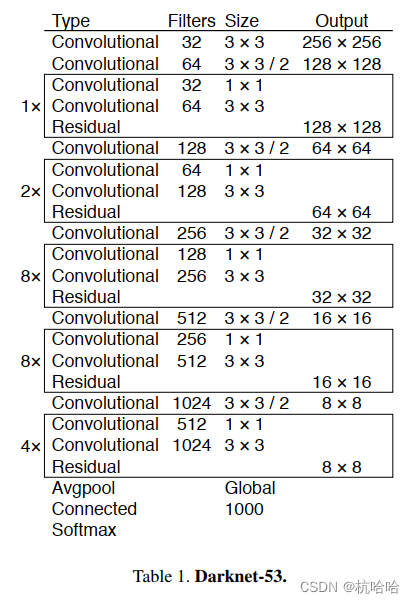
Backbone multicategoria **: Darknet53 ** Use 1 na rede backbone Os três mapas de recursos de /8, 1/16 e 1/32 são usados para fusão de mapas de recursos. Uma estrutura residual é usada na rede.
Por que usá-lo: Muito mais rápido que ResNet com a mesma precisão, mais lento, mas com maior precisão que Darknet19.


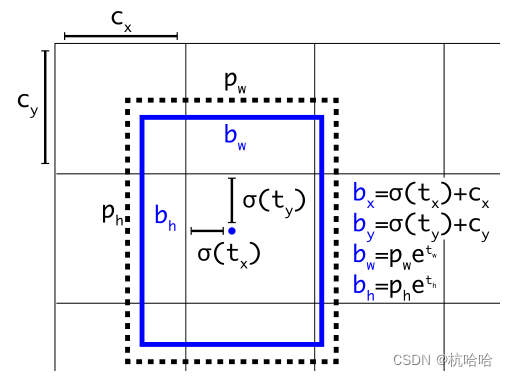
formato da forma e caixa anterior
SxSx3x(C+5) : tamanho, número de quadros anteriores 3, posição do quadro de detecção (XYHW4), confiança de detecção (1), dimensão da categoria (C)
usam agrupamento para rotular quadros e obtêm 9 quadros como caixa de inspeção a priori:
(10 × 13), (16 × 30), (33 × 23), (30 × 61), (62 × 45), (59 ×
119), (116 × 90), (156 × 198), (373 × 326).
A caixa de detecção de saída de rede é a seguinte:
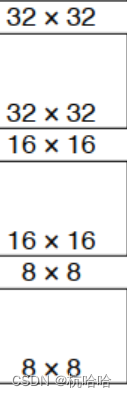
O fluxo de processamento da caixa
1. Obtido através de três mapas de características: 8 8 3, 16 16 3 , 32 32 3 , 3 caixas para cada grade , num total de 4.032 caixas.
2. Envie para cálculo de perda.
3. Defina o limite de confiança durante a inferência e, em seguida, use o NMS para gerar o resultado da previsão.
Estratégia de treinamento e função de perda
Caixa de previsão: exemplo positivo (positivo), exemplo negativo (negativo), exemplo ignorado (ignorar)
Exemplo positivo : pegue uma verdade básica e calcule o IOU com o quadro previsto. O maior deles é um exemplo positivo. O
exemplo positivo gera perda de confiança, perda de quadro de detecção e perda de categoria.
Exemplo negativo: Se o IOU com toda a verdade for menor que o valor normal (0,5), é um exemplo negativo.
Para casos negativos, apenas a confiança da classificação produz perda , o rótulo de classificação é 0 e a regressão de fronteira não produz perda.
Ignore a amostra: Exceto para o exemplo positivo, se o IOU com qualquer verdade fundamental for maior que o limite (0,5 é usado no artigo), é uma amostra ignorada. Ignorar exemplos não gera prejuízo algum.
Registro : Para exemplos negativos, participará apenas do cálculo da Perda Focal de confiança da classificação, e não afetará a Perda de classificação e regressão de quadros. Porque para os exemplos negativos, eles não contêm o objeto alvo, portanto não precisam participar do cálculo da Perda de classificação e regressão de posição do alvo.
Exemplos negativos, embora não sejam o alvo, podem ser previstos como algum alvo. Se ignorarmos completamente o caso de exemplos negativos, a rede poderá ignorar alguns exemplos negativos, que podem conter algumas características muito semelhantes ao alvo. Portanto, para exemplos negativos, precisamos penalizar na função de perda de confiança da classificação para encorajar a rede a fazer previsões mais precisas para exemplos negativos. É por isso que os exemplos negativos também precisam participar do cálculo da Perda Focal de confiança na classificação.
Função de perda: perda de confiança, perda de quadro de detecção, perda de categoria
Perda de confiança : FOCAL = FocalLoss(gamma=2, alpha=1.0, reduction="none")
perda de quadro de detecção : giou = tools.GIOU_xywh_torch(p_d_xywh, label_xywh).unsqueeze(-1)
perda de categoria:BCE = nn.BCEWithLogitsLoss(reduction="none")
Interpretação do código YOLOv3
1. Parte de encaminhamento de rede
def forward(self, x):
out = []
#通过Darknet53提取三个feature
x_s, x_m, x_l = self.__backnone(x)
#通过FPN进行concat与输出
x_s, x_m, x_l = self.__fpn(x_l, x_m, x_s)
#将三个不同尺寸的feature送入head进行解码
#也就是将三个输出解码成预测框!!
out.append(self.__head_s(x_s))
out.append(self.__head_m(x_m))
out.append(self.__head_l(x_l))
if self.training:
p, p_d = list(zip(*out))
return p, p_d # smalll, medium, large
else:
p, p_d = list(zip(*out))
return p, torch.cat(p_d, 0)
2. Parte YOLOv3_head
O princípio é a implementação destas fórmulas:
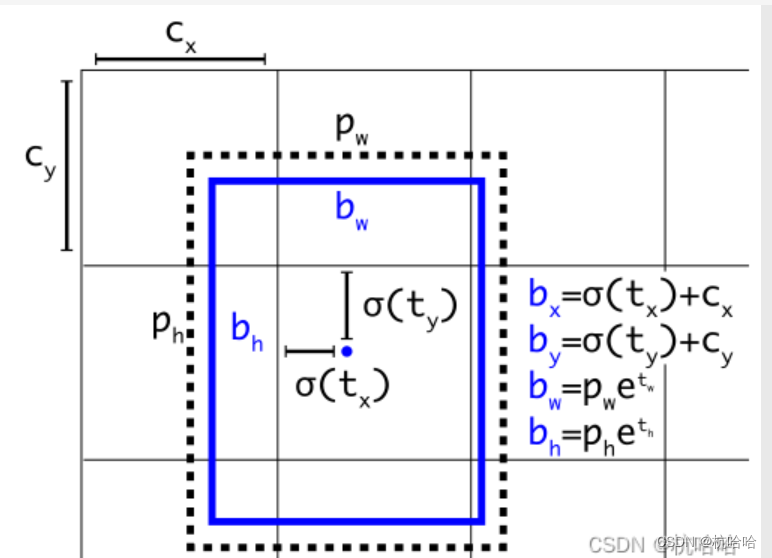
class Yolo_head(nn.Module):
def __init__(self, nC, anchors, stride):
super(Yolo_head, self).__init__()
# anchors是先验框(v3中是每个尺度三个先验框),nA是先验框的个数,nC是类别的个数,stride是步长
self.__anchors = anchors
self.__nA = len(anchors)
self.__nC = nC
self.__stride = stride
def forward(self, p):
# 获取输入的batch_size和特征图大小
bs, nG = p.shape[0], p.shape[-1]
# 将p转为bs,nA,nC+5,nG,nG的形状,注意这里将类别+5是因为每个anchor对应的输出包含:tx,ty,tw,th,confidence,类别概率
# 因此5+C的形状
p = p.view(bs, self.__nA, 5 + self.__nC, nG, nG).permute(0, 3, 4, 1, 2)
# 将预测的特征图解码,返回解码后的预测值
p_de = self.__decode(p.clone())
return (p, p_de)
def __decode(self, p):
# 获取batch_size和输出大小
batch_size, output_size = p.shape[:2]
# 获取当前设备
device = p.device
# 获取步长和先验框,转化为device类型
stride = self.__stride
anchors = (1.0 * self.__anchors).to(device)
# 预测中心坐标、宽高、置信度以及类别概率
conv_raw_dxdy = p[:, :, :, :, 0:2]
conv_raw_dwdh = p[:, :, :, :, 2:4]
conv_raw_conf = p[:, :, :, :, 4:5]
conv_raw_prob = p[:, :, :, :, 5:]
# 将特征图中心坐标转为全图坐标
y = torch.arange(0, output_size).unsqueeze(1).repeat(1, output_size)
x = torch.arange(0, output_size).unsqueeze(0).repeat(output_size, 1)
grid_xy = torch.stack([x, y], dim=-1)
grid_xy = grid_xy.unsqueeze(0).unsqueeze(3).repeat(batch_size, 1, 1, 3, 1).float().to(device)
# 计算预测的坐标和宽高
pred_xy = (torch.sigmoid(conv_raw_dxdy) + grid_xy) * stride
pred_wh = (torch.exp(conv_raw_dwdh) * anchors) * stride
# 将预测的坐标和宽高拼接在一起得到预测的边界框
pred_xywh = torch.cat([pred_xy, pred_wh], dim=-1)
# 计算预测的置信度和类别概率
pred_conf = torch.sigmoid(conv_raw_conf)
pred_prob = torch.sigmoid(conv_raw_prob)
# # 将预测的边界框、置信度和类别概率拼接在一起得到最终的预测
pred_bbox = torch.cat([pred_xywh, pred_conf, pred_prob], dim=-1)
return pred_bbox.view(-1, 5 + self.__nC) if not self.training else pred_bbox
 Esta seção do código serve para determinar o ponto central da âncora, o ponto central é o canto superior esquerdo de cada grade e cada grade gera três caixas anteriores.
Esta seção do código serve para determinar o ponto central da âncora, o ponto central é o canto superior esquerdo de cada grade e cada grade gera três caixas anteriores.