Esta série de postagens de blog são notas para artigos de aprendizado profundo/visão computacional. Indique a fonte para reimpressão
标题: Redes Adversariais Gerativas Condicionais
链接:[ 1411.1784] Redes Adversariais Gerativas Condicionais (arxiv.org)
Resumo
Redes Adversariais Gerativas [8] foram recentemente introduzidas como uma nova abordagem para treinar modelos generativos.
Neste trabalho, introduzimos uma versão condicional de Redes Adversariais Generativas simplesmente pegando os dados yy nos quais desejamos confiary é alimentado tanto para o gerador quanto para o discriminador e pode ser construído. Mostramos que este modelo pode gerar dígitos MNIST condicionados a rótulos de classe.
Também mostramos como esse modelo pode ser usado para aprender um modelo multimodal e fornecemos um exemplo preliminar de aplicação de rotulagem de imagens, no qual mostramos como esse método pode ser usado para gerar descrições que não fazem parte do rótulo de sexo dos rótulos de treinamento.
1. Introdução
Redes adversárias generativas foram recentemente introduzidas como uma estrutura alternativa para treinar modelos generativos, a fim de contornar muitas dificuldades intratáveis de cálculo de probabilidade.
As redes adversárias têm as seguintes vantagens:
-
Cadeias de Markov nunca são necessárias, apenas retropropagação é usada para obter gradientes
-
nenhum raciocínio é necessário durante o processo de aprendizagem, e
-
Vários fatores e interações podem ser facilmente incorporados ao modelo
Além disso, conforme demonstrado em [8], ele pode produzir estimativas de log-verossimilhança de última geração e amostras realistas.
Num modelo generativo incondicional, não há controle sobre o modo de geração dos dados.
Porém, ao condicionar o modelo com informações adicionais, é possível orientar o processo de geração de dados. Este condicionamento pode ser baseado em rótulos de classes, patches em dados parciais como em [5], ou mesmo em dados de modalidades diferentes.
Neste trabalho, mostramos como construir redes adversárias geradoras condicionais. Quanto aos resultados empíricos, apresentamos dois conjuntos de experimentos. Um conjunto é o conjunto de dados de dígitos MNIST baseado em rótulos de classe, e o outro é o conjunto de dados MIR Flickr 25.000 [10] para aprendizagem multimodal.
2. Trabalho relacionado
2.1 Aprendizagem Multimodal para Rotulagem de Imagens
Apesar dos muitos sucessos recentes de redes neurais supervisionadas (especialmente redes convolucionais) [13, 17], continua sendo um desafio dimensionar esses modelos para acomodar um número extremamente grande de categorias de resultados previstos . O segundo problema é que a maior parte do trabalho até à data se concentrou na aprendizagem de um mapeamento um-para-um, desde a entrada até à saída. No entanto, muitos problemas interessantes são mais naturalmente considerados como mapeamentos probabilísticos um-para-muitos . Por exemplo, no caso da rotulagem de imagens, pode haver muitos rótulos diferentes que podem ser aplicados apropriadamente a uma determinada imagem, e diferentes anotadores (humanos) podem usar termos diferentes (mas muitas vezes sinônimos ou relacionados) para descrever a mesma imagem.
-
Uma maneira de resolver o primeiro problema
- é explorar informações adicionais de outras modalidades: por exemplo, aprender representações vetoriais de rótulos usando corpora de linguagem natural onde as relações geométricas são semanticamente significativas.
- Ao fazer previsões em tais espaços, beneficiamos do facto de que quando as nossas previsões estão erradas, ainda estamos normalmente perto da verdade (por exemplo, prevendo "mesa" em vez de "cadeira"), e também do facto de podermos naturalmente se beneficiam do fato de que rótulos invisíveis realizam generalização preditiva.
- Trabalhos como [3] mostraram que mesmo um mapeamento linear simples do espaço de características da imagem para o espaço de representação de palavras pode melhorar o desempenho da classificação.
-
Uma maneira de resolver o segundo problema
- é um modelo generativo que usa probabilidades condicionais, as entradas são tratadas como variáveis condicionais e o mapeamento um-para-muitos é instanciado como uma distribuição preditiva condicional.
- [16] adotaram uma abordagem semelhante para este problema e treinaram uma máquina Boltzmann profunda multimodal no conjunto de dados MIR Flickr 25.000, como fizemos neste trabalho.
Além disso, em [12] os autores mostraram como treinar um modelo de linguagem neural multimodal supervisionado e foram capazes de gerar sentenças descritivas para imagens.
3 Redes Adversariais Gerativas Condicionais
3.1 Gerando Redes Adversárias
Redes adversárias generativas foram recentemente introduzidas como uma nova abordagem para treinar modelos generativos.
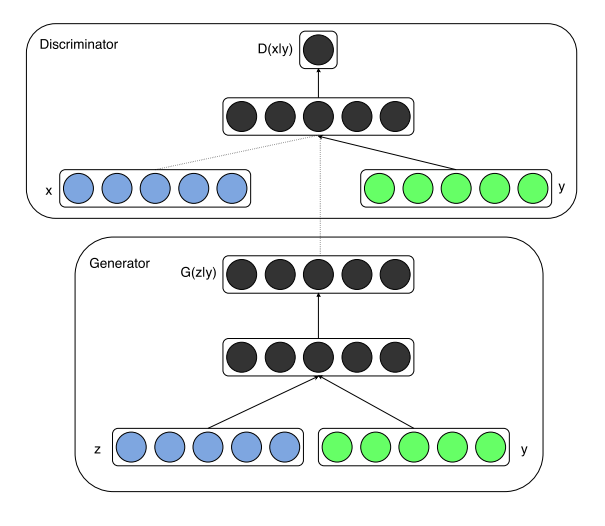
Eles consistem em dois modelos “adversários”: um modelo generativo G, que captura a distribuição dos dados; e um modelo discriminativo D, que estima a probabilidade de uma amostra provir de dados de treinamento ou G. Tanto G quanto D podem ser funções de mapeamento não linear, como perceptrons multicamadas.
Para aprender a distribuição do gerador pg p_gpgem dados xxdistribuição sobre x , o gerador começa a partir da distribuição de ruído anteriorpz ( z ) p_z(z)pz( z ) Construa a função de mapeamento G para o espaço de dados( z ; θ g ) G(z; \theta_g)G ( z ;eug) . E o discriminadorD ( x ; θ d ) D(x; \theta_d)D ( x ;eud) gera um escalar, representandoxxx vem de dados de treinamento em vez depg p_gpgA probabilidade.
Tanto G quanto D são treinados simultaneamente: ajustamos os parâmetros de G para que log ( 1 − D ( G ( z ) ) \log(1 - D(G(z))log g ( 1-D ( G ( z )) é minimizado e os parâmetros de D são ajustados para quelog D ( X ) \log D(X)ei _D ( X ) são minimizados como se estivessem seguindo uma função de valorV ( G , D ) V(G, D)V ( G ,D ) jogo minimax para dois jogadores:
min G max DV ( D , G ) = E x ∼ p dados ( x ) [ log D ( x ) ] + E z ∼ pz ( z ) [ log ( 1 − D(G(z)))]. (1) \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{dados}}(x)} [\log D(x)] + \mathbb{E} _{z \sim p_z(z)} [\log(1 - D(G(z)))]. \tag{1}GminDmáximoV ( D ,G )=Ex ∼ pdados( x )[ lo gD ( x )]+Ez ∼ pz( z )[ lo g ( 1-D ( G ( z )))] 。( 1 )
3.2 Redes Adversariais Gerativas Condicionais
Redes adversárias generativas podem ser estendidas para modelos condicionais se tanto o gerador quanto o discriminador forem baseados em alguma informação adicional yyy é condicional. aay pode ser qualquer tipo de informação auxiliar, como rótulos de classe ou dados de outros modais. Podemos passaryyy é alimentado no discriminador e gerador como uma camada de entrada adicional para realizar o condicionamento.
No gerador, o ruído de entrada anterior pz ( z ) p_z(z)pz( z )和aay é incorporado em uma representação oculta conjunta, e a estrutura de treinamento contraditório permite considerável flexibilidade na composição dessa representação oculta. 1
No discriminador, xxx和yyy é apresentado como uma entrada e alimentado para a função discriminante (neste caso, novamente incorporada pelo MLP).
A função objetivo para um jogo minimax para dois jogadores será a mesma da Equação 2
min G max DV ( D , G ) = E x ∼ p data ( x ) [ log D ( x ∣ y ) ] + E z ∼ pz ( z ) [ log ( 1 − D ( G ( z ∣ y ) ) ) ]. (2) \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{dados}}(x)} [\log D(x|y)] + \mathbb{ E}_{z \sim p_z(z)} [\log(1 - D(G(z|y)))]. \tag{2}GminDmáximoV ( D ,G )=Ex ∼ pdados( x )[ lo gD ( x ∣ y )]+Ez ∼ pz( z )[ lo g ( 1-D ( G ( z ∣ y )))] 。( 2 )
A Figura 1 ilustra a estrutura de uma rede adversária condicional simples.
Figura 1: Redes Adversariais Gerativas Condicionais
4 Resultados experimentais
4.1 Modo único
Treinamos uma rede adversária generativa condicional em imagens MNIST e condicionamos em seus rótulos de classe, codificados como vetores one-hot. Na rede geradora, um ruído anterior a zz
com 100 dimensões é amostrado uniformemente do hipercubo unitárioz。zzz和aaAmbos são mapeados para camadas ocultas com ativações de unidade linear retificada (ReLu) [4, 11] de tamanho de camada 200 e 1000, respectivamente, e então mapeados para uma segunda camada ReLu oculta combinada de dimensão 1200. Temos então uma camada final de unidades sigmóides como saída para gerar amostras MNIST de 784 dimensões.
O discriminador irá xxx é mapeado para uma camada maxout[6] com 240 unidades e 5 partes, eyyy é mapeado para uma camada maxout com 50 unidades e 5 partes. Ambas as camadas ocultas são mapeadas para uma camada conjunta máxima com 240 unidades e 4 partes antes de serem alimentadas na camada sigmóide. (A arquitetura exata do discriminador não é crítica, desde que seja suficientemente capaz; descobrimos que as unidades maxout são frequentemente adequadas para esta tarefa.)
O modelo é treinado usando gradiente descendente estocástico com minilotes de tamanho 100 e uma taxa de aprendizagem inicial de 0,1 que diminui exponencialmente para 0,000001 com um fator de decaimento de 1,00004. O impulso inicial é de 0,5, aumentado para 0,7. Dropout [9] com probabilidade 0,5 é aplicado tanto ao gerador quanto ao discriminador. e pegue a melhor estimativa da probabilidade logarítmica no conjunto de validação como ponto de parada.
A Tabela 1 mostra as estimativas de probabilidade de log da janela Gaussiana Parzen para os dados de teste do conjunto de dados MNIST. Extraia 1.000 amostras de cada uma das 10 categorias e ajuste uma janela Gaussiana de Parzen a essas amostras. Em seguida, estimamos a probabilidade logarítmica do conjunto de teste usando a distribuição da janela Parzen. (Veja [8] para mais detalhes sobre como construir esta estimativa.)
Tabela 1: Estimativas de probabilidade de log MNIST baseadas em janelas Parzen. Seguimos o mesmo procedimento de [8] para calcular esses valores.

Os resultados de GAN condicional que mostramos são comparáveis a alguns outros resultados baseados em rede, mas superados por vários outros métodos, incluindo GANs incondicionais. Apresentamos esses resultados mais como prova de conceito do que como validade e acreditamos que, com uma exploração mais aprofundada do espaço e da arquitetura dos hiperparâmetros, os modelos condicionais devem igualar ou exceder os resultados incondicionais.
A Figura 2 mostra algumas amostras geradas. Cada linha está condicionada a um rótulo e cada coluna é uma amostra gerada diferente.
Figura 2: Dígitos MNIST gerados, cada linha baseada em um rótulo

4.2 Multimodal
Sites de fotos como o Flickr são fontes ricas de dados marcados na forma de imagens e seus metadados gerados pelo usuário (UGM) associados, especialmente tags de usuário. Os metadados gerados pelo usuário diferem dos esquemas de rotulagem de imagens mais "canônicos" porque geralmente são mais descritivos e semanticamente mais próximos de como as pessoas descrevem as imagens em linguagem natural, em vez de apenas identificar objetos presentes nas imagens. Outro aspecto do UGM é que os sinônimos são onipresentes e diferentes usuários podem usar diferentes vocabulários para descrever o mesmo conceito, portanto, torna-se importante padronizar efetivamente esses rótulos. Embeddings de palavras conceituais [14] podem ser muito úteis aqui, pois conceitos relacionados acabam sendo representados como vetores semelhantes.
Nesta seção, demonstramos a predição multirótulo usando redes adversárias condicionais para gerar distribuições vetoriais de rótulos automáticos (possivelmente multimodais) para imagens.
Para recursos de imagem, pré-treinamos o conjunto de dados completo do ImageNet com 21.000 rótulos [15] usando um modelo convolucional semelhante a [13]. Usamos a saída da última camada totalmente conectada com 4.096 unidades como representação da imagem.
Para a representação mundial, primeiro coletamos texto da concatenação de tags de usuário, títulos e descrições dos metadados do conjunto de dados YFCC100M2 . Após o pré-processamento e limpeza do texto, treinamos um modelo de grama ignorada [14] com um tamanho de vetor de palavras de 200. Omitimos qualquer palavra que ocorra menos de 200 vezes no vocabulário, resultando assim em um dicionário de tamanho 247465.
Durante o treinamento da rede adversária, mantemos fixos o modelo convolucional e o modelo de linguagem. E a retropropagação através desses modelos fica como trabalho futuro.
Para nossos experimentos, usamos o conjunto de dados MIR Flickr 25.000 [10] e extraímos recursos de imagem e rótulo usando o modelo convolucional e o modelo de linguagem que descrevemos acima. Imagens sem rótulos são omitidas e as anotações são consideradas rótulos extras. Os primeiros 150.000 exemplos são usados como conjunto de treinamento. Imagens com vários rótulos são repetidas no conjunto de treinamento, uma vez para cada rótulo associado.
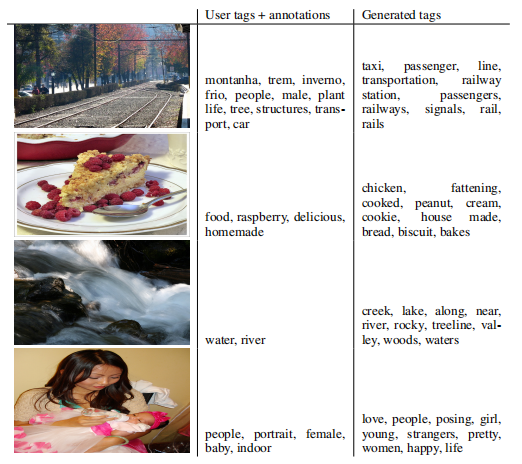
Para avaliação, geramos 100 amostras para cada imagem e encontramos as 20 palavras mais próximas usando a similaridade de cosseno da representação vetorial das palavras no vocabulário de cada amostra. Em seguida, selecionamos as 10 palavras mais frequentes em todas as 100 amostras. A Tabela 4.2 mostra alguns exemplos de rótulos e anotações atribuídos pelo usuário e rótulos gerados.
O gerador do melhor modelo de trabalho recebe ruído gaussiano de tamanho 100 como um ruído anterior e o mapeia para uma camada ReLu de 500 dimensões. E mapeie o vetor de recursos da imagem de 4.096 dimensões para a camada oculta ReLu de 2.000 dimensões. Ambas as camadas são mapeadas para uma camada linear de 200 dimensões que produzirá os vetores de palavras resultantes.
O discriminador consiste em camadas ocultas ReLu de 500 e 1200 dimensões para vetores de palavras e recursos de imagem, respectivamente, e uma camada máxima com 1000 unidades e 3 partes como camada de conexão, finalmente inserindo uma única unidade sigmoidal.
O modelo é treinado usando gradiente descendente estocástico com um tamanho de lote de 100 e uma taxa de aprendizado inicial de 0,1, que diminui exponencialmente para 0,000001 com um fator de decaimento de 1,00004. Também foi utilizado um momentum com valor inicial de 0,5, que foi aumentado para 0,7. O dropout com probabilidade 0,5 é aplicado tanto no gerador quanto no discriminador.
As escolhas de hiperparâmetros e arquitetura foram obtidas por meio de validação cruzada e uma mistura de pesquisa aleatória em grade e seleção manual (embora dentro de um espaço de pesquisa limitado).
5 Futuro do trabalho
Os resultados mostrados neste artigo são muito preliminares, mas demonstram o potencial das redes adversárias condicionais e mostram-se promissores para aplicações interessantes e úteis.
Em futuras explorações até o workshop, esperamos apresentar modelos mais complexos, bem como uma análise mais detalhada e completa de seu desempenho e propriedades.
Tabela 2: Gerar amostras de rótulos
Além disso, nos experimentos atuais, usamos apenas cada rótulo individualmente. No entanto, ao usar vários rótulos simultaneamente (colocando efetivamente o problema de geração como um problema de "geração de conjunto"), esperamos alcançar melhores resultados.
Outra direção óbvia para o trabalho futuro é construir esquemas conjuntos de formação para aprender modelos linguísticos. Trabalhos como [12] mostram que podemos aprender modelos de linguagem apropriados para tarefas específicas.
obrigado
Este projeto é desenvolvido no âmbito do Pylearn2 [7] e gostaríamos de agradecer aos desenvolvedores do Pylearn2. Gostaríamos também de agradecer a Ian Goodfellow pelas discussões úteis durante sua gestão na Université de Montréal. Os autores gostariam de agradecer à equipe de visão e aprendizado de máquina e à equipe de engenharia de produção do Flickr por seu apoio (em ordem alfabética: Andrew Stadlen, Arel Cordero, Clayton Mellina, Cyprien Noel, Frank Liu, Gerry Pesavento, Huy Nguyen, Jack Culpepper, John Ko , Pierre Garrigues, Rob Hess, Stacey Svetlichnaya, Tobi Baumgartner e Ye Lu).
referências
- Bengio, Y., Mesnil, G., Dauphin, Y. e Rifai, S. (2013). Melhor mesclagem por meio da representação de profundidade. No ICML'2013.
- Bengio, Y., Thibodeau-Laufer, E., Alain, G. e Yosinski, J. (2014). Redes aleatórias generativas profundas que podem ser treinadas via retropropagação. Nos Anais da 30ª Conferência Internacional sobre Aprendizado de Máquina (ICML'14).
- Frome, A., Corrado, GS, Shlens, J., Bengio, S., Dean, J., Mikolov, T., e outros (2013). Conceber: um modelo de incorporação semântica visual profunda. Em Avanços em Sistemas de Processamento de Informação Neural, pp.
- Glorot, X., Bordes, A. e Bengio, Y. (2011). Redes Neurais Retificadoras Esparsas Profundas. Na Conferência Internacional sobre Inteligência Artificial e Estatística, pp.
- Goodfellow, I., Mirza, M., Courville, A. e Bengio, Y. (2013a). Máquina Boltzmann de profundidade multipredição. Em Avanços em Sistemas de Processamento de Informação Neural, pp.
- Goodfellow, IJ, Warde-Farley, D., Mirza, M., Courville, A. e Bengio, Y. (2013b). Rede de saída máxima. No ICML'2013.
- Goodfellow, IJ, Warde-Farley, D., Lamblin, P., Dumoulin, V., Mirza, M., Pascanu, R., Bergstra, J., Bastien, F., e Bengio, Y. (2013c). Pylearn2: uma biblioteca de pesquisa de aprendizado de máquina. Pré-impressão do arXiv arXiv:1308.4214.
- Goodfellow, IJ, Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., e Bengio, Y. (2014). Redes Adversariais Gerativas. no NIPS'2014.
- Hinton, GE, Srivastava, N., Krizhevsky, A., Sutskever, I. e Salakhutdinov, R. (2012). Melhorar as redes neurais evitando a co-adaptação de detectores de recursos. Relatório Técnico, número: arXiv:1207.0580.
- Huiskes, MJ e Lew, MS (2008). avaliação de pesquisa mir flickr. Em MIR'08: Conferência Internacional ACM 2008 sobre Recuperação de Informação Multimídia, Nova York, EUA. ACM.
- Jarrett, K., Kavukcuoglu, K., Ranzato, M. e LeCun, Y. (2009). Qual é a melhor arquitetura multinível para reconhecimento de objetos? no ICCV'09.
- Kiros, R., Zemel, R. e Salakhutdinov, R. (2013). Modelos de linguagem neural multimodais. Nos Anais do Workshop NIPS sobre Aprendizado Profundo.
- Krizhevsky, A., Sutskever, I. e Hinton, G. (2012). Classificação ImageNet usando redes neurais convolucionais profundas. Em Avanços em Sistemas de Processamento de Informação Neural 25 (NIPS'2012).
- Mikolov, T., Chen, K., Corrado, G. e Dean, J. (2013). Estimativa eficiente de representações de palavras em espaços vetoriais. Na Conferência Internacional sobre Representações de Aprendizagem: Workshop Track.
- Russakovsky, O. e Fei-Fei, L. (2010). Aprendizagem de atributos em conjuntos de dados em grande escala. No Simpósio Internacional sobre Partes e Atributos da Conferência Europeia sobre Visão Computacional (ECCV), Creta, Grécia.
- Srivastava, N. e Salakhutdinov, R. (2012). Aprendizagem Multimodal com Máquinas Deep Boltzmann. No NIPS'2012.
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., e Rabiovich, A. (2014). Vá mais fundo com a convolução. Pré-impressão do arXiv arXiv:1409.4842.
Referências
- Bengio, Y., Mesnil, G., Dauphin, Y. e Rifai, S. (2013). Melhor mixagem por meio de representações profundas. No ICML'2013.
- Bengio, Y., Thibodeau-Laufer, E., Alain, G. e Yosinski, J. (2014). Redes estocásticas generativas profundas treináveis por backprop. Nos Anais da 30ª Conferência Internacional sobre Aprendizado de Máquina (ICML'14).
- Frome, A., Corrado, GS, Shlens, J., Bengio, S., Dean, J., Mikolov, T., et al. (2013). Devise: Um modelo de incorporação visual-semântica profunda. Em Avanços em Sistemas de Processamento de Informação Neural, páginas 2121–2129.
- Glorot, X., Bordes, A. e Bengio, Y. (2011). Redes neurais retificadoras esparsas profundas. Na Conferência Internacional sobre Inteligência Artificial e Estatística, páginas 315–323.
- Goodfellow, I., Mirza, M., Courville, A. e Bengio, Y. (2013a). Máquinas Boltzmann profundas de multipredição. Em Avanços em Sistemas de Processamento de Informação Neural, páginas 548–556.
- Goodfellow, IJ, Warde-Farley, D., Mirza, M., Courville, A. e Bengio, Y. (2013b). Redes Maxout. No ICML'2013.
- Goodfellow, IJ, Warde-Farley, D., Lamblin, P., Dumoulin, V., Mirza, M., Pascanu, R., Bergstra, J., Bastien, F., e Bengio, Y. (2013c). Pylearn2: uma biblioteca de pesquisa de aprendizado de máquina. Pré-impressão do arXiv arXiv:1308.4214.
- Goodfellow, IJ, Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., e Bengio, Y. (2014). Redes adversárias geradoras. No NIPS'2014.
- Hinton, GE, Srivastava, N., Krizhevsky, A., Sutskever, I. e Salakhutdinov, R. (2012). Melhorar as redes neurais evitando a co-adaptação de detectores de recursos. Relatório técnico, arXiv:1207.0580.
- Huiskes, MJ e Lew, MS (2008). A avaliação de recuperação do mir flickr. No MIR '08: Anais da Conferência Internacional ACM de 2008 sobre Recuperação de Informações Multimídia, Nova York, NY, EUA. ACM.
- Jarrett, K., Kavukcuoglu, K., Ranzato, M. e LeCun, Y. (2009). Qual é a melhor arquitetura multiestágio para reconhecimento de objetos? Em ICCV'09.
- Kiros, R., Zemel, R. e Salakhutdinov, R. (2013). Modelos de linguagem neural multimodal. Em Proc. Workshop de aprendizagem profunda do NIPS.
- Krizhevsky, A., Sutskever, I. e Hinton, G. (2012). Classificação ImageNet com redes neurais convolucionais profundas. Em Avanços em Sistemas de Processamento de Informação Neural 25 (NIPS'2012).
- Mikolov, T., Chen, K., Corrado, G. e Dean, J. (2013). Estimativa eficiente de representações de palavras no espaço vetorial. Na Conferência Internacional sobre Representações de Aprendizagem: Workshops Track.
- Russakovsky, O. e Fei-Fei, L. (2010). Atribuir aprendizagem em conjuntos de dados em grande escala. Na Conferência Europeia de Visão Computacional (ECCV), Workshop Internacional sobre Peças e Atributos, Creta, Grécia.
- Srivastava, N. e Salakhutdinov, R. (2012). Aprendizagem multimodal com máquinas Boltzmann profundas. No NIPS'2012.
Visão (ECCV), Workshop Internacional sobre Peças e Atributos, Creta, Grécia. - Srivastava, N. e Salakhutdinov, R. (2012). Aprendizagem multimodal com máquinas Boltzmann profundas. No NIPS'2012.
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., e Rabiovich, A. (2014). Indo mais fundo com convoluções. Pré-impressão do arXiv arXiv:1409.4842.
Atualmente, simplesmente alimentamos a entrada condicional e o ruído anterior como entrada para uma única camada oculta do MLP, mas pode-se imaginar o uso de interações de ordem superior, permitindo mecanismos generativos complexos que seriam muito intratáveis em estruturas generativas tradicionais. ↩︎
Conjunto de dados Creative Common 100M do Yahoo Flickr: http://webscope.sandbox.yahoo.com/catalog.php?datatype=i&did=67. ↩︎