Esta série de postagens de blog são notas para artigos de aprendizado profundo/visão computacional. Indique a fonte para reimpressão
标题: Tradução imagem-imagem com redes adversárias condicionais
Resumo
Investigamos redes adversárias condicionais como uma solução geral para o problema de tradução imagem-imagem. Essas redes não apenas aprendem um mapeamento de imagens de entrada para imagens de saída, mas também aprendem uma função de perda para treinar esse mapeamento. Isto torna possível aplicar a mesma abordagem geral a problemas que tradicionalmente requerem formulações de perdas muito diferentes. Demonstramos a eficácia desta abordagem em tarefas como sintetizar fotos a partir de mapas de rótulos, reconstruir objetos a partir de mapas de bordas e colorir imagens. Além disso, desde o lançamento do software pix2pix associado a este artigo, centenas de usuários do Twitter twittaram sobre experimentos artísticos utilizando nosso sistema. Como comunidade, não projetamos mais funções de mapeamento manualmente. Este trabalho mostra que podemos alcançar resultados razoáveis sem projetar funções de perda manualmente.
1. Introdução
No processamento de imagens, computação gráfica e visão computacional, muitos problemas podem ser vistos como a “tradução” de uma imagem de entrada em uma imagem de saída correspondente. Assim como um conceito pode ser expresso em inglês ou francês, uma cena pode ser renderizada como uma imagem RGB, campo de gradiente, mapa de bordas, mapa de rótulo semântico e muito mais. Análoga à tradução automática de idioma, definimos a tradução automática de imagem para imagem como o problema de converter uma possível representação de uma cena em outra, dados dados de treinamento suficientes (ver Figura 1). Tradicionalmente, cada tarefa é resolvida usando um mecanismo independente e dedicado (por exemplo, [14, 23, 18, 8, 10, 50, 30, 36, 16, 55, 58]), apesar do contexto ser sempre o mesmo: Prever pixel a pixel. O objetivo deste artigo é desenvolver uma estrutura comum para todas essas questões.
Figura 1: Muitos problemas no processamento de imagens, gráficos e visão envolvem a transformação de uma imagem de entrada em uma imagem de saída correspondente. Esses problemas geralmente são resolvidos usando algoritmos específicos da aplicação, embora o plano de fundo seja sempre o mesmo: mapear pixels para pixels. Redes Adversariais Condicionais são uma solução geral que parece funcionar bem em uma ampla variedade desses problemas. Aqui mostramos os resultados do método em vários problemas. Em cada caso, usamos a mesma arquitetura e objetivo, apenas treinados em dados diferentes.
A comunidade deu passos importantes nessa direção, e as redes neurais convolucionais (CNNs) tornaram-se uma ferramenta geral para uma variedade de problemas de previsão de imagens. As CNNs aprendem a minimizar uma função de perda – o objetivo de avaliar a qualidade do resultado – e embora o processo de aprendizagem seja automático, ainda requer muito trabalho manual para projetar perdas efetivas. Por outras palavras, ainda temos de dizer à CNN o que queremos que ela minimize. Mas, tal como o rei dourado Midas, devemos ter cuidado com os nossos desejos! Se adotarmos a abordagem ingênua de pedir à CNN para minimizar a distância euclidiana entre os pixels previstos e os pixels reais, isso tende a produzir resultados borrados [40, 58]. Isso ocorre porque a distância euclidiana é minimizada pela média de todos os resultados possíveis, resultando em ambiguidade. Criar funções de perda que possam forçar as CNNs a fazer o que realmente queremos – por exemplo, produzir imagens nítidas e realistas – é um problema em aberto que muitas vezes requer conhecimentos especializados.
Seria ideal se pudéssemos apenas especificar um objetivo de alto nível, como "tornar o resultado indistinguível da realidade", e então aprender automaticamente uma função de perda adequada para atingir esse objetivo. Felizmente, isso é exatamente o que as redes adversárias generativas (GANs) recentemente propostas fazem [22, 12, 41, 49, 59]. GANs aprendem uma perda que tenta classificar se uma imagem de saída é real ou falsa, enquanto treinam um modelo generativo para minimizar essa perda. Imagens desfocadas não serão toleradas, pois parecerão claramente falsas. Como as GANs aprendem perdas que se adaptam aos dados, elas podem ser aplicadas a muitas tarefas que tradicionalmente exigem tipos muito diferentes de funções de perda.
Neste artigo, exploramos GANs em um ambiente condicional. Assim como as GANs aprendem um modelo generativo de dados, as redes adversárias generativas condicionais (cGANs) aprendem um modelo generativo condicional [22]. Isso torna os cGANs adequados para tarefas de tradução imagem a imagem, onde geramos imagens de saída correspondentes condicionadas às imagens de entrada.
Embora os GANs tenham sido extensivamente estudados nos últimos dois anos, e muitas das técnicas exploradas neste artigo tenham sido propostas antes, os primeiros artigos focaram na aplicação específica, se os GANs condicionados por imagem podem ser usados como tradução de imagem para imagem. a solução geral para isso ainda não está clara. Nossa principal contribuição é demonstrar que GANs condicionais podem produzir resultados razoáveis em uma ampla variedade de problemas. Nossa segunda contribuição propõe uma estrutura simples suficiente para alcançar bons resultados e analisa o impacto de diversas escolhas arquitetônicas importantes. O código está disponível em https://github.com/phillipi/pix2pix.
2. Trabalho relacionado
Perdas estruturadas para modelagem de imagens Problemas de tradução de imagem para imagem são frequentemente formulados como classificação em nível de pixel ou problemas de regressão (por exemplo, [36, 55, 25, 32, 58]). Estas formulações tratam o espaço de saída como "não estruturado", o que significa que cada pixel de saída é considerado condicionalmente independente dada a imagem de entrada. Em contraste, as redes adversárias geradoras condicionais aprendem uma perda estruturada. Configuração Conjunta de Saídas de Penalidade de Perda Estruturada. Uma grande parte da literatura considera esse tipo de perda, com métodos que incluem campos aleatórios condicionais [9], métricas SSIM [53], correspondência de recursos [13], perdas não paramétricas [34], pseudo anteriores convolucionais [54] e perdas baseadas em A. na correspondência de estatísticas de covariância [27]. As Redes Adversariais Gerativas Condicionais são diferentes porque uma perda é aprendida, o que teoricamente penaliza qualquer estrutura que possa diferir entre o resultado e o alvo.
Redes Adversariais Gerativas Condicionais Não somos os primeiros a aplicar GANs a configurações condicionais. Estudos anteriores condicionaram GANs a rótulos discretos [38, 21, 12], texto [43] e, de fato, imagens. Os modelos de condicionamento de imagem abordaram o problema de previsão de imagens a partir de mapas normais [52], previsão de quadros futuros [37], geração de fotos de produtos [56] e geração de imagens a partir de anotações esparsas [28, 45] (veja [44] para obter um método autorregressivo para o mesmo problema). Existem outros artigos que também usam GANs para mapeamento imagem a imagem, mas aplicam GANs apenas incondicionalmente, contando com outros termos (como regressão L2) para forçar a saída a condicionar a entrada. Esses artigos alcançam resultados impressionantes em pintura interna [40], previsão de estado futuro [60], processamento de imagem guiado por restrições do usuário [61], transferência de estilo [35] e super-resolução [33]. Cada método é ajustado para uma aplicação específica. Nossa estrutura é diferente porque não há nada específico para o aplicativo. Isso torna nossa configuração muito mais simples do que a maioria dos outros métodos.
Nossa abordagem também difere de trabalhos anteriores em diversas opções de arquitetura para o gerador e discriminador. Diferente do trabalho anterior, para o gerador utilizamos uma arquitetura baseada em “U-Net” [47], e para o discriminador utilizamos um classificador convolucional “PatchGAN” que estrutura apenas para punir. Uma arquitetura PatchGAN semelhante foi proposta anteriormente em [35] para capturar estatísticas de estilo local. Aqui mostramos a eficácia desta abordagem em uma gama mais ampla de problemas e investigamos o impacto de diferentes dimensões de fragmentos de imagem.
3. Método
GANs são modelos generativos que aprendem com um vetor de ruído aleatório zzz para gerar a imagemyyMapeamento de y , G : z → y G : z → yG:z→e [22]. Em contraste, redes adversárias geradoras condicionais aprendem com imagens observadasxxx e vetor de ruído aleatóriozzz到yyO mapeamento de y , G : { x , z } → y G : \{x, z\} → yG:{ x ,z }→você .
Gerador GGO objetivo do treinamento de G é gerar uma saída que não possa ser detectada pelo discriminador treinado contraditoriamenteDDD se distingue das imagens "reais", o discriminadorDDO objetivo do treinamento de D é detectar o máximo possível as imagens "falsas" do gerador. Este processo de treinamento é ilustrado na Figura 2.
Figura 2: Mapeamento de Redes Adversariais Gerativas Condicionais de Treinamento a partir do Mapa de Borda → Foto. Discriminador DDD aprende a classificar tuplas falsas (sintetizadas pelo gerador) e reais {mapas de borda, fotos}. GeradorGGG aprende a enganar o discriminador. Ao contrário dos GANs incondicionais, tanto o gerador quanto o discriminador observam mapas de bordas da entrada.

3.1. Função objetivo
A função objetivo da rede adversária geradora condicional pode ser expressa como
L c GAN ( G , D ) = E x , y [ log D ( x , y ) ] + E x , z [ log ( 1 − D ( x , G ( x , z ) ) ) ] (1) L_{cGAN}(G, D) = E_{x,y}[\log D(x, y)] + E_{x,z}[\log(1 - D(x, G(x, z)) )] \tag{1}euc G A N( G ,D )=Ex , você[ lo gD ( x ,e )]+Ex , z[ lo g ( 1-D ( x ,G ( x ,z )))]( 1 )
onde gerador GGG tenta minimizar esta função objetivo, o discriminador adversárioDDD tenta maximizá-lo, ou seja,G ∗ = arg min G max DL c GAN ( G , D ) G^* = \arg\min_G \max_D L_{cGAN}(G, D)G∗=ar gminGmáx.Deuc G A N( G ,D )。
Para testar a importância do discriminador condicional, também o comparamos com a variante incondicionada, onde o discriminador não observa xxx:
LGAN ( G , D ) = E y [ log D ( y ) ] + E x , z [ log ( 1 − D ( G ( x , z ) ) ) ] (2) L_{GAN}(G , D) = E_{y}[\log D(y)] + E_{x,z}[\log(1 - D(G(x, z)))] \tag{2}euGAN _ _( G ,D )=Evocê[ lo gD ( y )]+Ex , z[ lo g ( 1-D ( G ( x ,z )))]( 2 )
Abordagens anteriores consideraram benéfico misturar objetivos GAN com perdas mais tradicionais, como distância L2 [40]. A tarefa do discriminador permanece a mesma, mas o gerador não deve apenas enganar o discriminador, mas também aproximar a saída da verdade fundamental no sentido L2. Também exploramos esta opção, usando a distância L1 em vez de L2, já que L1 incentiva menos desfoque:
LL 1 ( G ) = E x , y , z [ ∥ y − G ( x , z ) ∥ 1 ] (3) L_{L1}(G) = E_{x,y,z}[\|y - G (x, z)\|_1] \tag{3}eueu 1( G )=Ex , y , z[ ∥ y-G ( x ,z ) ∥1]( 3 )
Nosso objetivo final é
G ∗ = arg min G max D ( L c GAN ( G , D ) + λ LL 1 ( G ) ) (4) G^* = \arg\min_G \max_D (L_{cGAN}(G, D ). ) + \lambda L_{L1}(G)) \tag{4}G∗=ar gGminDmáximo( euc G A N( G ,D )+λL _eu 1( G ))( 4 )
sem zNo caso de z , a rede ainda está disponível a partir dexxx到yyy aprende o mapeamento, mas produz resultados determinísticos, portanto não pode corresponder a nenhuma distribuição diferente da função Delta. GANs condicionais anteriores reconheceram isso e forneceram ruído gaussianozzz , excetoxxx (por exemplo, [52]). Nas experiências iniciais, descobrimos que esta estratégia não é eficaz - o gerador simplesmente aprende a ignorar o ruído - o que é consistente com o trabalho de Mathieu et al.[37]. Em vez disso, para nosso modelo final, alimentamos apenas ruído na forma de dropout em algumas camadas do gerador, que é aplicado tanto no treinamento quanto no teste. Apesar do ruído de dropout, observamos apenas uma ligeira aleatoriedade na saída da rede. Projetar GANs condicionais capazes de produzir resultados altamente estocásticos e, assim, capturar a entropia total da distribuição condicional que está sendo modelada, é um importante problema não resolvido no trabalho atual.
3.2. Arquitetura de Rede
Adaptamos a arquitetura do gerador e do discriminador de [41]. Tanto o gerador quanto o discriminador utilizam módulos do formato Convolution-BatchNorm-ReLU [26]. Detalhes sobre a arquitetura podem ser encontrados no material suplementar, com os principais recursos discutidos abaixo.
3.2.1 Geradores com conexões saltadas
Uma característica distintiva dos problemas de tradução imagem-imagem é que eles mapeiam uma grade de entrada de alta resolução para uma grade de saída de alta resolução. Além disso, para os problemas que consideramos, a entrada e a saída diferem na aparência da superfície, mas são representações da mesma estrutura subjacente. Assim, a estrutura da entrada se alinha aproximadamente com a estrutura da saída. Projetamos a arquitetura do gerador em torno dessas considerações.
Muitas soluções anteriores [40, 52, 27, 60, 56] para problemas neste domínio usam redes codificador-decodificador [24]. Nessas redes, a entrada passa por uma série de camadas progressivamente reduzidas até a camada gargalo, ponto em que o processo é revertido. Uma rede deste tipo exige que toda a informação flua através de todas as camadas, incluindo os estrangulamentos. Para muitos problemas de tradução de imagens, uma grande quantidade de informações de baixo nível é compartilhada entre entrada e saída, e é desejável que esta informação possa ser passada diretamente para a rede. Por exemplo, no caso da colorização de imagens, a entrada e a saída compartilham a localização das bordas salientes.
Para permitir que o gerador contorne o gargalo para fornecer informações semelhantes, adicionamos conexões de salto, seguindo o formato geral de "U-Net" [47]. Especificamente, em cada camada iieu camadan − em - eun-Adicione conexões de salto entre i , onde nnn é o número total de camadas. Cada conexão ignorada simplesmente conecta a camadaiieu camadan − em - eun-Todos os canais em i estão conectados.
3.2.2 Discriminador de Markov (PatchGAN)
A perda de L2 - e L1, veja a Fig. 3 - é conhecida por produzir resultados borrados em problemas de geração de imagens [31]. Embora essas perdas não encorajem a clareza de alta frequência, elas ainda capturam com precisão informações de baixa frequência em muitos casos. Neste caso, não precisamos de uma estrutura totalmente nova para impor a correção em baixas frequências. L1 é suficiente.
Figura 3: Perdas diferentes levam a resultados de qualidade diferentes. Cada coluna mostra os resultados do treinamento com diferentes perdas. Consulte https://phillipi.github.io/pix2pix/ para mais exemplos.

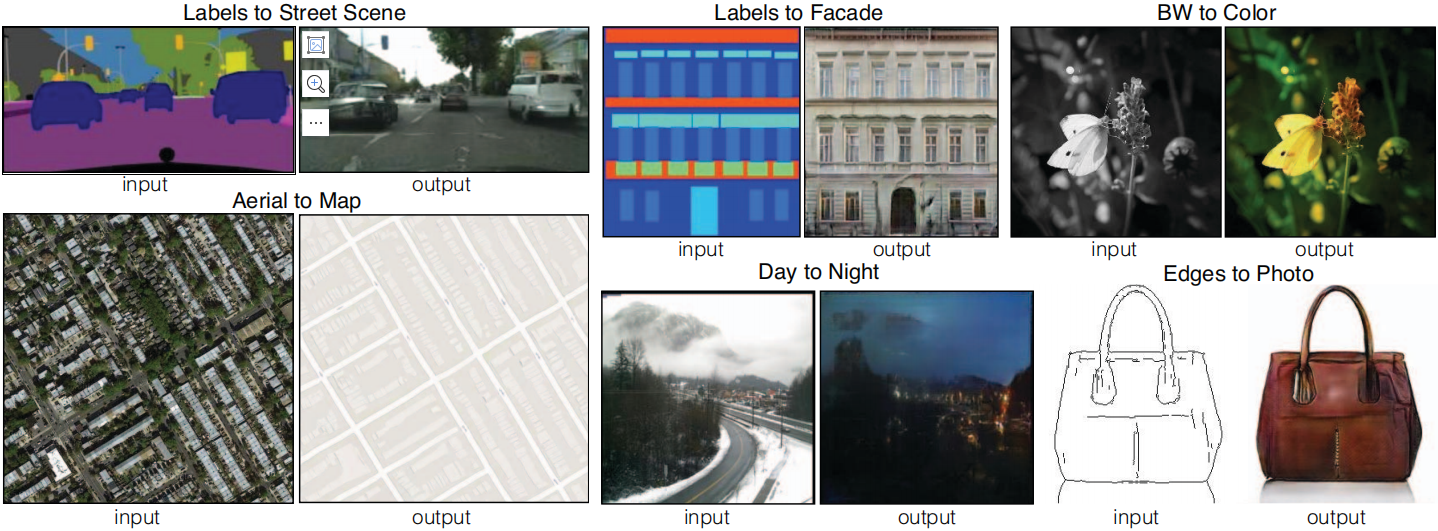
Isso motiva a restringir os discriminadores GAN a modelar apenas estruturas de alta frequência, contando com o termo L1 para impor a correção de baixa frequência (Equação 4). Para simular altas frequências, é suficiente restringir a atenção à estrutura dos fragmentos locais da imagem. Portanto, projetamos uma arquitetura discriminadora - que chamamos de PatchGAN - que penaliza apenas a estrutura na escala do patch. O discriminador tenta identificar cada N × NN × NN×N blocos são classificados para determinar se são reais ou falsos. Executamos esse discriminador em toda a imagem por convolução, calculando a média de todas as respostas para fornecerDDResultado final de D.
Na Seção 4.4, provamos que NNN pode ser muito menor que o tamanho total da imagem e ainda produzir resultados de alta qualidade. Isso é vantajoso porque PatchGANs menores têm menos parâmetros, são executados mais rapidamente e podem ser aplicados a imagens arbitrariamente grandes.
Tal discriminador modela efetivamente a imagem como um campo aleatório de Markov, assumindo independência entre pixels maiores que o diâmetro de um patch de imagem. Esta conexão foi explorada anteriormente em [35] e é uma suposição comum em modelos de textura [15, 19] e estilo [14, 23, 20, 34]. Portanto, nosso PatchGAN pode ser entendido como uma forma de perda de textura/estilo.
3.3. Otimização e inferência
Para otimizar nossa rede, seguimos a abordagem padrão em [22]: uma etapa de descida gradiente em D seguida por uma etapa em G. Usamos descida gradiente estocástica de minilote (SGD) e aplicamos o solucionador Adam [29].
No momento da inferência, operamos a rede geradora exatamente da mesma maneira que durante a fase de treinamento. Isso difere do protocolo usual porque aplicamos dropout no momento do teste e aplicamos normalização de lote [26] usando estatísticas de lotes de teste, em vez de estatísticas agregadas de lotes de treinamento. Quando o tamanho do lote é definido como 1, esta abordagem para normalização de lote é chamada de “normalização de instância” e tem se mostrado eficaz em tarefas de geração de imagens [51]. Em nossos experimentos, usamos um tamanho de lote entre 1 e 10 de acordo com o experimento.
4. Experimente
Para explorar a generalização de GANs condicionais, testamos o método em várias tarefas e conjuntos de dados, incluindo tarefas gráficas (por exemplo, geração de fotos) e tarefas de visão (por exemplo, segmentação semântica):
- Rótulos semânticos ↔ fotos, treinados no conjunto de dados Cityscapes [11].
- Etiqueta de Arquitetura → Foto, treinada em Fachadas CMP [42].
- Mapas ↔ fotos aéreas, treinadas a partir de dados obtidos no Google Maps.
- Fotos em preto e branco → fotos coloridas, usando [48] para treinamento.
- Borda → Foto, treinada usando dados de [61] e [57]; bordas binárias geradas usando o detector de bordas HED [55] e pós-processadas.
- Esboço→Foto: O modelo borda→foto é testado no esboço desenhado à mão de [17].
- Dia → Noite, treinado nos dados de [30].
Detalhes detalhados do treinamento sobre esses conjuntos de dados podem ser encontrados no material suplementar online. Em todos os casos, a entrada e a saída são imagens de 1 a 3 canais. Os resultados qualitativos são apresentados na Figura 7, Figura 8, Figura 9, Figura 10 e Figura 11, outros resultados e casos de falha podem ser encontrados no material online (https://phillipi.github.io/pix2pix/).
4.1. Métricas de Avaliação
Avaliar a qualidade das imagens sintetizadas é um problema aberto e difícil [49]. As métricas tradicionais, como o erro quadrático médio em nível de pixel, não avaliam as estatísticas conjuntas dos resultados e, portanto, não conseguem medir a estrutura que as perdas estruturadas são projetadas para capturar.
Para avaliar de forma mais completa a qualidade visual de nossos resultados, empregamos duas estratégias. Primeiro, conduzimos um estudo de percepção “real versus falso” no Amazon Mechanical Turk (AMT). Para problemas gráficos como colorização e geração de fotos, para observadores humanos, a plausibilidade costuma ser o objetivo final. Portanto, testamos nossa geração de mapas, geração de fotos aéreas e colorização de imagens usando esta abordagem.
Em segundo lugar, medimos se as nossas paisagens urbanas sintéticas são suficientemente realistas para que os sistemas de reconhecimento disponíveis no mercado reconheçam os objetos dentro delas. Esta métrica é semelhante à “pontuação inicial” em [49], à avaliação de detecção de objetos em [52] e à medida de “interpretabilidade semântica” em [58] e [39].
Estudos de percepção AMT Para nossos experimentos AMT, seguimos o protocolo em [58]: Turkers foi apresentado a uma série de testes nos quais uma imagem "real" foi comparada a uma imagem "falsa" gerada por nosso algoritmo. Em cada tentativa, cada imagem apareceu por 1 segundo, após o qual a imagem desapareceu, e os Turkers tiveram um tempo infinito para responder qual era a falsa. As primeiras 10 imagens de cada sessão são exercícios e os Turkers recebem feedback. Nenhum feedback foi fornecido durante as 40 tentativas do experimento principal. Apenas um algoritmo é testado por vez por sessão. Os Turkers não estão autorizados a completar várias sessões. Cerca de 50 Turkers avaliam cada algoritmo. Todas as imagens são apresentadas com resolução de 256×256. Ao contrário de [58], não incluímos ensaios de vigilância. Para nossos experimentos de colorização, imagens reais e falsas são geradas a partir da mesma entrada em escala de cinza. Para mapas ↔ fotos aéreas, imagens reais e falsas não são geradas a partir da mesma entrada para dificultar a tarefa e evitar resultados de baixo nível.
Pontuações FCN Embora a avaliação quantitativa de modelos generativos seja notoriamente desafiadora, trabalhos recentes [49, 52, 58, 39] tentam medir a discriminabilidade de estímulos gerados usando classificadores semânticos pré-treinados como pseudoindicadores. A intuição é que um classificador treinado em imagens reais também será capaz de classificar corretamente imagens sintéticas se as imagens geradas forem realistas. Para tanto, adotamos a arquitetura FCN-8s [36] para segmentação semântica e a treinamos no conjunto de dados de paisagens urbanas. Em seguida, pontuamos as fotos sintetizadas comparando a precisão da classificação dessas fotos com os rótulos gerados a partir dessas fotos.
4.2. Análise de função objetiva
Quais componentes são importantes no objetivo da equação (4)? Realizamos estudos de ablação para separar a influência do termo L1, do termo GAN, e comparar usando um discriminador condicional (cGAN, Equação (1)) com um discriminador incondicional (GAN, Equação (2)).
A Figura 3 demonstra o impacto qualitativo dessas mudanças nas duas questões rótulo→foto. Usar apenas L1 leva a resultados razoáveis, mas ambíguos. Usar apenas cGAN (configuração λ = 0 na Equação (4)) produz resultados mais nítidos, mas introduz artefatos visuais em algumas aplicações. A combinação de ambos os termos (λ = 100) reduz esses artefatos.
Quantificamos essas observações usando pontuações FCN na tarefa Cityscape Label → Photo (ver Tabela 1): Os objetivos baseados em GAN alcançam pontuações mais altas, indicando que as imagens sintéticas incluem estruturas mais reconhecíveis. Também testamos o efeito da remoção da condição do discriminador (rotulado GAN). Neste caso, a perda não penaliza a incompatibilidade entre entrada e saída; ela apenas se preocupa se a saída parece real. O desempenho desta variante é muito pobre; a inspeção mostra que o gerador produz quase a mesma saída, independentemente da foto de entrada. Claramente, neste caso, a qualidade da correspondência entre a entrada e a saída da medição de perdas é muito importante e, de fato, o cGAN tem um desempenho melhor que o GAN. No entanto, é importante notar que adicionar o termo L1 também incentiva a saída a respeitar a entrada, uma vez que a perda L1 penaliza a distância entre a saída da verdade fundamental e a saída sintética, que pode não corresponder. Da mesma forma, L1+GAN também é capaz de criar renderizações realistas de maneira eficaz, respeitando o mapeamento do rótulo de entrada. Combinando todos os termos, L1+cGAN também funciona muito bem.
Tabela 1: Pontuações FCN avaliadas na tarefa Rotulagem Semântica↔Foto no conjunto de dados Cityscapes

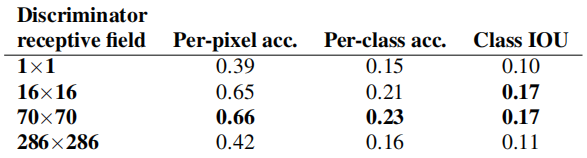
Um efeito impressionante das redes adversárias geradoras condicionais é que elas produzem imagens nítidas e a ilusão de estrutura espacial, mesmo quando está ausente no mapa de rótulos de entrada. Pode-se imaginar que a "nitidez" da dimensão espectral do cGAN tenha um efeito semelhante - mesmo que a imagem seja mais colorida. Assim como L1 incentiva o desfoque quando você não tem certeza de onde exatamente está uma borda, ele incentiva a escolha de um cinza médio quando você não tem certeza de qual valor de cor viável um pixel deve assumir. Em particular, L1 é escolhido para minimizar o valor mediano da função de densidade de probabilidade condicional de cores possíveis.
Por outro lado, uma perda adversária pode, em princípio, perceber que as saídas de cinza são irrealistas e encorajar a correspondência com a distribuição real de cores [22]. Na Figura 6, investigamos se nosso cGAN atinge esse efeito no conjunto de dados Cityscapes. Esses gráficos mostram a distribuição marginal dos valores de cores de saída no espaço de cores Lab. As linhas tracejadas indicam a distribuição da verdade básica. Claramente, L1 leva a uma distribuição mais estreita do que a distribuição da verdade básica, validando a hipótese de que L1 incentiva uma cor cinza média. Por outro lado, o uso de cGAN empurra a distribuição de saída em direção à distribuição da verdade básica.
4.3. Análise da arquitetura do gerador
A arquitetura U-Net permite que informações de baixo nível sejam transferidas rapidamente na rede. Isso leva a melhores resultados? A Figura 4 compara o desempenho do U-Net e do codificador-decodificador na geração de paisagens urbanas. O codificador-decodificador é criado apenas cortando as conexões de salto no U-Net. Em nossos experimentos, o codificador-decodificador não conseguiu aprender a gerar imagens realistas. As vantagens do U-Net não parecem estar limitadas aos GANs condicionais: o U-Net novamente alcança resultados superiores quando tanto o U-Net quanto o codificador-decodificador são treinados com perda L1 (veja a Figura 4).
Figura 4: Adicionar conexões de salto no codificador-decodificador para criar uma "U-Net" produz resultados de maior qualidade.

4.4. Do PixelGAN ao PatchGAN ao ImageGAN
Testamos o efeito da variação do tamanho N do patch do campo receptivo do discriminador, de 1 × 1 para “PixelGAN” até 286 × 286 completos para “ImageGAN” 1 . A Figura 5 mostra os resultados qualitativos desta análise e a Tabela 2 quantifica o efeito do uso dos escores FCN. Observe que no restante do artigo, salvo indicação em contrário, todos os experimentos usam um PatchGAN 70 × 70, enquanto nesta seção, todos os experimentos usam a perda L1 + cGAN.
Figura 5: Variação do tamanho do patch. Diferentes funções de perda representarão a incerteza da saída de diferentes maneiras. Sob L1, as regiões incertas ficam borradas e dessaturadas. PixelGAN em 1x1 incentiva maior diversidade de cores, mas não tem efeito nas estatísticas espaciais. O PatchGAN 16x16 produz resultados localmente nítidos, mas também produz artefatos lado a lado fora de seu alcance observável. Um PatchGAN 70×70 força uma saída nítida, mesmo que incorretamente, tanto nas dimensões espaciais quanto espectrais (riqueza de cores). O ImageGAN completo de 286 × 286 é visualmente semelhante aos resultados do PatchGAN de 70 × 70, mas um pouco inferior de acordo com nossa métrica de pontuação FCN (Tabela 2). Consulte https://phillipi.github.io/pix2pix/ para outros exemplos.

Tabela 2: Pontuações FCN para diferentes tamanhos de campos receptivos discriminadores na etiqueta Cityscapes→tarefa de foto. Observe que a imagem de entrada tem 256×256 pixels, e o tamanho maior do campo receptivo é obtido preenchendo com zeros.
PixelGAN não tem efeito na nitidez espacial, mas aumenta a riqueza de cores dos resultados (quantificado na Figura 6). Por exemplo, o barramento da Figura 5 fica cinza quando treinado com perda L1, mas fica vermelho quando é treinado com perda PixelGAN. A correspondência de histogramas de cores é um problema comum no processamento de imagens [46], e o PixelGAN pode ser uma solução leve e promissora.
Figura 6: Propriedades de correspondência de distribuição de cores do cGAN, testadas no conjunto de dados Cityscapes. (Consulte a Figura 1 do artigo original do GAN [22]). Observe que as pontuações de cruzamento do histograma são afetadas principalmente por diferenças em regiões de alta probabilidade, que não são perceptíveis no gráfico, uma vez que o gráfico mostra log de probabilidades, enfatizando assim diferenças em regiões de baixa probabilidade.
Usar um PatchGAN 16×16 é suficiente para gerar resultados nítidos e obter boas pontuações FCN, mas também leva a artefatos de ladrilho. O PatchGAN 70 × 70 mitiga esses problemas de artefatos e atinge pontuações semelhantes. Indo além deste ponto, atingir o ImageGAN completo de 286 × 286 não melhora significativamente a qualidade visual dos resultados e, de fato, reduz significativamente as pontuações FCN (Tabela 2). Isso pode ocorrer porque o ImageGAN tem mais parâmetros e maior profundidade do que o PatchGAN 70 × 70, o que pode ser mais difícil de treinar.
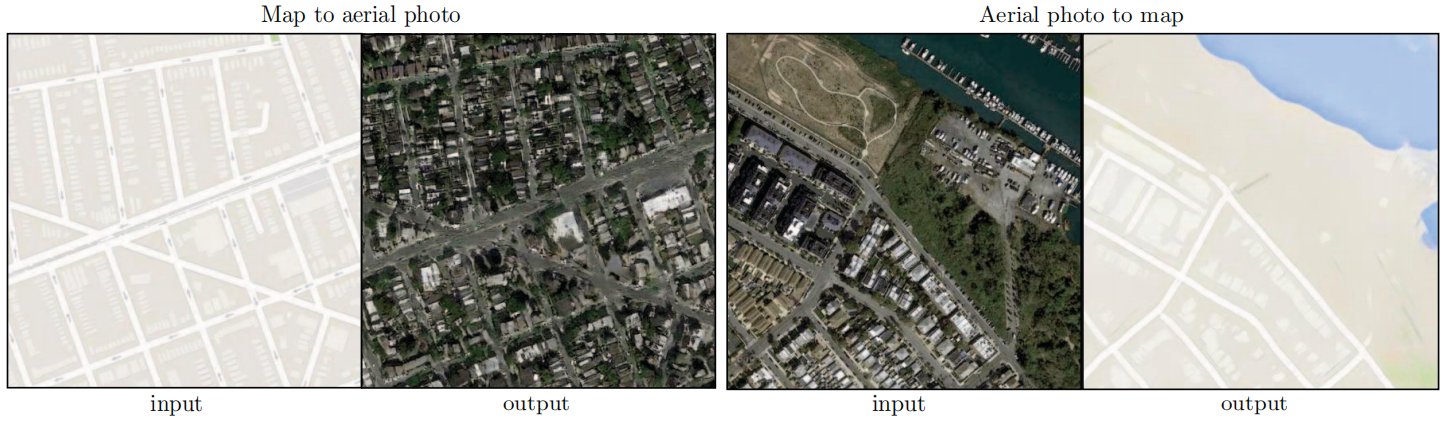
Uma vantagem das transformações totalmente convolucionais é que um discriminador de patch de tamanho fixo pode ser aplicado a imagens de tamanho arbitrário. Também podemos convolucionar o gerador em imagens maiores que as imagens de treinamento. Nós testamos na tarefa de mapa↔foto aérea. Depois de treinar o gerador em imagens 256×256, nós o testamos em imagens 512×512. Os resultados na Figura 7 demonstram a eficácia desta abordagem.
Figura 7: Exemplo de resultados do Google Maps com resolução de 512x512 (o modelo foi treinado em imagens com resolução de 256x256 e convertido em imagens maiores no momento do teste). Contraste ajustado para maior clareza.
4.5. Verificação de Percepção
Validamos a fidelidade perceptiva dos resultados nas tarefas mapa↔foto aérea e tons de cinza→cores. Os resultados dos experimentos AMT para mapas↔fotos são mostrados na Tabela 3. As fotos aéreas geradas pelo nosso método enganaram os participantes em 18,9% dos ensaios, significativamente superior à linha de base L1, que produziu resultados ambíguos e quase nunca enganou os participantes. Em contraste, na orientação foto → mapa, nosso método enganou os participantes em 6,1% dos ensaios, não significativamente diferente do desempenho da linha de base L1 (com base no teste de bootstrap). Isso pode ocorrer porque pequenos erros estruturais nos mapas são mais aparentes visualmente, enquanto os mapas têm geometria rígida, enquanto as fotos aéreas são mais caóticas.
Tabela 3: Testes AMT “real vs falso” no mapa↔tarefa de foto aérea.

Treinamos colorização no ImageNet [48] e testamos no conjunto de testes apresentado em [58, 32]. Nosso método, utilizando a perda L1+cGAN, enganou os participantes em 22,5% dos ensaios (Tabela 4). Também testamos os resultados de [58], bem como uma variante de seu método que usa uma perda L2 (veja [58] para detalhes). Os GANs condicionais pontuam de forma semelhante à variante L2 de [58] (diferença não significativa pelo teste de bootstrap), mas não no nível do método completo de [58], que trapaceou em 27,8% dos ensaios em nossos experimentos dos participantes. Observamos que seu método foi projetado especificamente para ter um bom desempenho na colorização.
Tabela 4: Testes AMT "real vs falso" na tarefa de coloração.

Figura 8: Resultados coloridos de GANs condicionais em comparação com a regressão L2 em [58] e o método completo em [60] (classificação por rebalanceamento). Os cGANs podem produzir resultados de colorização atraentes (duas primeiras linhas), mas têm um modo de falha comum de produção de resultados em tons de cinza ou dessaturados (última linha).

4.6. Segmentação Semântica
GANs condicionais parecem ser eficazes na geração de problemas altamente detalhados ou semelhantes a fotos, que são comuns em processamento de imagens e tarefas gráficas. E quanto aos problemas de visão, como a segmentação semântica, em que a saída é mais simples que a entrada?
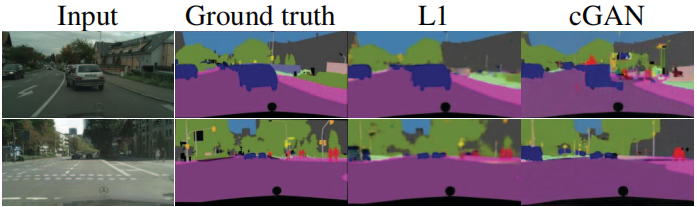
Para começar a testar isso, treinamos um cGAN (com/sem perda de L1) em fotos de paisagens urbanas → rótulos. A Figura 11 mostra os resultados qualitativos, e a precisão da classificação quantitativa é relatada na Tabela 5. Curiosamente, o cGAN treinado sem perda de L1 é capaz de resolver este problema com precisão razoável. Até onde sabemos, esta é a primeira demonstração de um GAN que gera com sucesso “rótulos” que são quase discretos, em vez de “imagens” com variação contínua 2 . Apesar de algum sucesso com cGANs, eles estão longe de ser a melhor abordagem para este problema: usar apenas a regressão L1 produz pontuações melhores do que usar cGANs, conforme mostrado na Tabela 5. Argumentamos que para problemas de visão, o alvo (ou seja, prever uma saída próxima da verdade fundamental) pode ser menos ambíguo do que o alvo para tarefas gráficas, e uma perda de reconstrução como L1 é basicamente suficiente.
Tabela 5: Desempenho na tarefa photo→label no conjunto de dados de paisagem urbana.
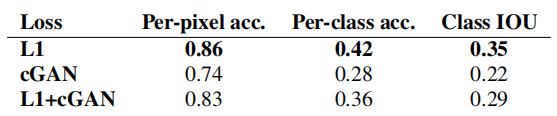
4.7. Pesquisa conduzida pela comunidade
Desde a publicação inicial do artigo e de nossa base de código pix2pix, a comunidade do Twitter, incluindo profissionais em visão computacional e gráficos, bem como artistas, aplicou com sucesso nossa estrutura a uma variedade de novas tarefas de tradução de imagem para imagem, muito além do escopo de o papel original. A Figura 10 mostra apenas alguns exemplos sob a hashtag #pix2pix, como esboço→retrato, transferência de pose “Faça como eu faço”, profundidade→visualização de rua, remoção de fundo, geração de paleta, esboço→Pokémon e o popular #edges2cats.
Figura 9: Resultados do nosso método em diversas tarefas (dados de [42] e [17]). Observe que os resultados do Sketch→Photo são gerados por um modelo treinado na detecção automática de bordas e testado em esboços desenhados por humanos. Consulte o material on-line para obter exemplos adicionais.

Figura 10: Um exemplo de aplicativo de comunidade on-line desenvolvido com base em nossa base de código pix2pix: #edges2cats [3] por Christopher Hesse, Sketch → Portrait [7] por Mario Kingemann, "Do As I Do" Pose Transformation [2] por Brannon Dorsey, Depth → Streetview [5] de Jasper van Loenen, Background Removal [6] de Kaihu Chen, Palette Generation [4] de Jack Qiao e Sketch → Pokémon [1] de Bertrand Gondouin.

Figura 11: Aplicando GANs condicionais à segmentação semântica. O cGAN gera imagens nítidas que à primeira vista se assemelham às reais, mas na verdade contêm muitos pequenos objetos fantasmas.
5. Conclusão
Os resultados deste artigo demonstram que redes adversárias condicionais são uma abordagem promissora para muitas tarefas de tradução imagem a imagem, especialmente aquelas que envolvem saída gráfica altamente estruturada. Estas redes aprendem a adaptar as perdas a tarefas e dados específicos, tornando-as aplicáveis a uma variedade de contextos diferentes.
obrigado
Agradecemos a Richard Zhang, Deepak Pathak e Shubham Tulsiani pelas discussões úteis, a Saining Xie por sua ajuda com o detector de bordas HED e à comunidade online por suas contribuições na exploração de muitas aplicações e na sugestão de melhorias. Este trabalho foi apoiado em parte pela NSF SMA-1514512, NGA NURI, IARPA através de doações de hardware do Laboratório de Pesquisa da Força Aérea, Intel Corp, Berkeley Deep Drive e Nvidia.
referência
- Bertrand Gondouin. https://twitter.com/bgondouin/status/818571935529377792. Acessado em 21/04/2017.
- Brannon Dorsey. https://twitter.com/brannondorsey/status/806283494041223168. Acessado em 21/04/2017.
- Cristóvão Hesse. https://affinelayer.com/pixsrv/. Acesso: 21/04/2017.
- Jack Qiao. http://colormind.io/blog/. Acesso: 21/04/2017.
- Jasper van Loenen. https://jaspervanloenen.com/neural-city/. Acessado em 21/04/2017.
- Kaihu Chen. http://www.terraai.org/imageops/index.html. Acessado em 21/04/2017.
- Mário Klingemann. https://twitter.com/quasimondo/status/826065030944870400. Acessado em 21/04/2017.
- A. Buades, B. Coll e J.-M. Morel. Um algoritmo não local para remoção de ruído de imagens. Em CVPR, volume 2, páginas 60–65. IEEE, 2005.
- L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy e AL Yuille. Segmentação semântica de imagens com redes convolucionais profundas e CRFs totalmente conectados. Em ICLR, 2015.
- T. Chen, M.-M. Cheng, P. Tan, A. Shamir e S.-M. Hu. Sketch2photo: montagem de imagens na internet. Transações ACM em Gráficos (TOG), 28(5):124, 2009.
- M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth e B. Schiele. O conjunto de dados Cityscapes para compreensão semântica da cena urbana. Em CVPR, 2016.
- EL Denton, S. Chintala, R. Fergus, et al. Modelos de imagens generativas profundas usando uma pirâmide Laplaciana de redes adversárias. Em NIPS, páginas 1486–1494, 2015.
- A. Dosovitskiy e T. Brox. Geração de imagens com métricas de similaridade perceptiva baseadas em redes profundas. Pré-impressão do arXiv arXiv:1602.02644, 2016.
- AA Efros e WT Freeman. Quilting de imagens para síntese e transferência de texturas. Em SIGGRAPH, páginas 341–346. ACM, 2001.
- AA Efros e TK Leung. Síntese de texturas por amostragem não paramétrica. No ICCV, volume 2, páginas 1033–1038. IEEE, 1999.
- D. Eigen e R. Fergus. Previsão de profundidade, normais de superfície e rótulos semânticos com uma arquitetura convolucional multiescala comum. Em Anais da Conferência Internacional IEEE sobre Visão Computacional, páginas 2650–2658, 2015.
- M. Eitz, J. Hays e M. Alexa. Como os humanos esboçam objetos? SIGGRAPH, 31(4):44–1, 2012.
- R. Fergus, B. Singh, A. Hertzmann, ST Roweis e WT Freeman. Removendo a trepidação da câmera de uma única fotografia. Em ACM Transactions on Graphics (TOG), volume 25, páginas 787–794. ACM, 2006.
- LA Gatys, AS Ecker e M. Bethge. Síntese de texturas e geração controlada de estímulos naturais utilizando redes neurais convolucionais. Pré-impressão do arXiv arXiv:1505.07376, 2015.
- LA Gatys, AS Ecker e M. Bethge. Transferência de estilo de imagem usando redes neurais convolucionais. CVPR, 2016.
- J. Gauthier. Redes adversárias generativas condicionais para geração de faces convolucionais. Projeto de aula para Stanford CS231N: Redes Neurais Convolucionais para Reconhecimento Visual, semestre de inverno, 2014(5):2, 2014.
- I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville e Y. Bengio. Redes adversárias geradoras. Em NIPS, 2014.
- A. Hertzmann, CE Jacobs, N. Oliver, B. Curless e DH Salesin. Analogias de imagens. Em SIGGRAPH, páginas 327–340. ACM, 2001.
- GE Hinton e RR Salakhutdinov. Reduzindo a dimensionalidade dos dados com redes neurais. Ciência, 313(5786):504–507, 2006.
- S. Iizuka, E. Simo-Serra e H. Ishikawa. Haja cor!: Aprendizagem conjunta de ponta a ponta de antecedentes de imagens globais e locais para colorização automática de imagens com classificação simultânea. Transações ACM em Gráficos (TOG), 35(4), 2016.
- S. Ioffe e C. Szegedy. Normalização em lote: Acelerando o treinamento profundo da rede, reduzindo a mudança interna de covariáveis. 2015.
- J. Johnson, A. Alahi e L. Fei-Fei. Perdas perceptivas para transferência de estilo em tempo real e super-resolução. 2016.
- L. Karacan, Z. Akata, A. Erdem e E. Erdem. Aprender a gerar imagens de cenas externas a partir de atributos e layouts semânticos. Pré-impressão do arXiv arXiv:1612.00215, 2016.
- D. Kingma e J. Ba. Adam: Um método para otimização estocástica. ICLR, 2015.
- P.-Y. Laffont, Z. Ren, X. Tao, C. Qian e J. Hays. Atributos transitórios para compreensão e edição de alto nível de cenas externas. Transações ACM em Gráficos (TOG), 33(4):149, 2014.
- ABL Larsen, SK Sønderby e O. Winther. Codificação automática além de pixels usando uma métrica de similaridade aprendida. Pré-impressão do arXiv arXiv:1512.09300, 2015.
- G. Larsson, M. Maire e G. Shakhnarovich. Aprendendo representações para colorização automática. ECCV, 2016.
- C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al. Super-resolução de imagem única fotorrealista usando uma rede adversária generativa. Pré-impressão do arXiv arXiv:1609.04802, 2016.
- C. Li e M. Varinha. Combinação de campos aleatórios de Markov e redes neurais convolucionais para síntese de imagens. CVPR, 2016.
- C. Li e M. Varinha. Síntese de textura pré-computada em tempo real com redes adversárias generativas markovianas. ECCV, 2016.
- J. Long, E. Shelhamer e T. Darrell. Redes totalmente convolucionais para segmentação semântica. Em CVPR, páginas 3431–3440, 2015.
- M. Mathieu, C. Couprie e Y. LeCun. Predição profunda de vídeo em várias escalas além do erro quadrático médio. ICLR, 2016.
- M. Mirza e S. Osindero. Redes adversárias geradoras condicionais. Pré-impressão do arXiv arXiv:1411.1784, 2014.
- A. Owens, P. Isola, J. McDermott, A. Torralba, EH Adelson e WT Freeman. Sons indicados visualmente. Em Anais da Conferência IEEE sobre Visão Computacional e Reconhecimento de Padrões, páginas 2405–2413, 2016.
- D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell e AA Efros. Codificadores de contexto: aprendizado de recursos por pintura interna. CVPR, 2016.
- A. Radford, L. Metz e S. Chintala. Aprendizagem de representação não supervisionada com redes adversárias generativas convolucionais profundas. Pré-impressão do arXiv arXiv:1511.06434, 2015.
- RS Radim Tylecek. Modelos de padrões espaciais para reconhecimento de objetos com estrutura regular. Em Proc. GCPR, Saarbrucken, Alemanha, 2013.
- S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele e H. Lee. Texto adversário generativo para síntese de imagens. Pré-impressão do arXiv arXiv:1605.05396, 2016.
- S. Reed, A. van den Oord, N. Kalchbrenner, V. Bapst, M. Botvinick e N. de Freitas. Gerando imagens interpretáveis com estrutura controlável. Relatório técnico, Relatório técnico, 2016.
- SE Reed, Z. Akata, S. Mohan, S. Tenka, B. Schiele e H. Lee. Aprendendo o que e onde desenhar. Em Avanços em Sistemas de Processamento de Informação Neural, páginas 217–225, 2016.
- E. Reinhard, M. Ashikhmin, B. Gooch e P. Shirley. Transferência de cores entre imagens. IEEE Computação Gráfica e Aplicações, 21:34–41, 2001.
- O. Ronneberger, P. Fischer e T. Brox. U-net: Redes convolucionais para segmentação de imagens biomédicas. Em MICCAI, páginas 234–241. Springer, 2015.
- O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, et al. Desafio de reconhecimento visual de imagem em grande escala. IJCV, 115(3):211–252, 2015.
- T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford e X. Chen. Técnicas aprimoradas para treinamento de GANs. Pré-impressão do arXiv arXiv:1606.03498, 2016.
- Y. Shih, S. Paris, F. Durand e WT Freeman. Alucinação baseada em dados de diferentes horas do dia a partir de uma única foto externa. Transações ACM em Gráficos (TOG), 32(6):200, 2013.
- D. Ulyanov, A. Vedaldi e V. Lempitsky. Normalização de instâncias: o ingrediente que falta para uma estilização rápida. Pré-impressão do arXiv arXiv:1607.08022, 2016.
- X. Wang e A. Gupta. Modelagem generativa de imagens usando estilo e estrutura de redes adversárias. ECCV, 2016.
- Z. Wang, AC Bovik, HR Sheikh e EP Simoncelli. Avaliação da qualidade de imagem: da visibilidade do erro à similaridade estrutural. Transações IEEE sobre processamento de imagens, 13(4):600–612, 2004.
- S. Xie, X. Huang e Z. Tu. Aprendizagem top-down para rotulagem estruturada com pseudoprior convolucional. 2015.
- S. Xie e Z. Tu. Detecção de bordas aninhadas holisticamente. Em ICCV, 2015.
- D. Yoo, N. Kim, S. Park, AS Paek e IS Kweon. Transferência de domínio em nível de pixel. ECCV, 2016.
- A. Yu e K. Grauman. Comparações visuais refinadas com aprendizagem local. Em CVPR, 2014.
- R. Zhang, P. Isola e AA Efros. Colorização de imagens coloridas. ECCV, 2016.
- J. Zhao, M. Mathieu e Y. LeCun. Rede adversária generativa baseada em energia. Pré-impressão do arXiv arXiv:1609.03126, 2016.
- Y. Zhou e TL Berg. Aprendendo transformações temporais a partir de vídeos de lapso de tempo. Em ECCV, 2016.
- J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman e AA Efros. Manipulação visual generativa na variedade de imagens naturais. In ECCV, 2016.
rede rsarial. Pré-impressão do arXiv arXiv:1609.03126, 2016. - Y. Zhou e TL Berg. Aprendendo transformações temporais a partir de vídeos de lapso de tempo. Em ECCV, 2016.
- J.-Y. Zhu, P. Kr¨ahenb¨uhl, E. Shechtman e AA Efros. Manipulação visual generativa na variedade de imagens naturais. Em ECCV, 2016.
Conseguimos essa variação de tamanho de patch ajustando a profundidade do discriminador GAN. Detalhes desse processo, bem como a arquitetura do discriminador, podem ser encontrados no material suplementar online. ↩︎
Observe que os mapas de rótulos que usamos para treinamento não são exatamente valores discretos, pois são redimensionados dos mapas originais por meio de interpolação bilinear e salvos como imagens JPEG, que podem conter alguns artefatos de compressão. ↩︎