Esta série de postagens de blog são notas para artigos de aprendizado profundo/visão computacional. Indique a fonte para reimpressão
标题: Olhando para ouvir no coquetel: um modelo audiovisual independente de alto-falante para separação de fala
Nota do tradutor: O "Cocktail Party" no título original significa literalmente "cocktail party". O “efeito coquetel” é um termo comumente usado na ciência da audição, um conceito derivado da incrível capacidade dos humanos de processar ambientes acústicos complexos. Considere uma cena movimentada de um coquetel onde as pessoas podem se concentrar em uma conversa ou som específico enquanto ignoram outros ruídos de fundo. Isso é o que costumamos chamar de “escuta com atenção seletiva” ou “efeito coquetel”.
Declaração de autorização:
Licença para obter uma cópia digital ou impressa de parte ou de todo este trabalho para uso pessoal ou em sala de aula, desde que não tenha fins lucrativos ou comerciais, e desde que a cópia contenha este aviso e seja citada na íntegra na primeira página , sem nenhum custo. Os direitos autorais de componentes de terceiros neste trabalho devem ser respeitados. Para outros usos, entre em contato com o proprietário/autor da obra.
© 2018 Direitos autorais do proprietário/autor.
0730-0301/2018/8-ART112
https://doi.org/10.1145/3197517.3201357
Resumo
Propomos um "modelo audiovisual" conjunto para separar um único sinal de fala de uma mistura de sons, como outros alto-falantes e ruído de fundo . Resolver esta tarefa utilizando apenas áudio como entrada é extremamente desafiador, não sendo possível correlacionar o sinal de fala isolado com o locutor no vídeo.
Neste artigo, propomos um modelo profundo baseado em rede que incorpora sinais visuais e auditivos para resolver esta tarefa.
Recursos visuais são usados para “focar” o áudio no locutor desejado na cena para melhorar a qualidade da separação da fala. Para treinar nosso modelo audiovisual conjunto, apresentamos o AVSpeech, um novo conjunto de dados que consiste em milhares de horas de videoclipes de toda a web.
Exigindo apenas que os usuários especifiquem os rostos das pessoas nos vídeos que desejam isolar, demonstramos que nosso método funciona tanto em tarefas clássicas de separação de fala, quanto em situações do mundo real que envolvem entrevistas intensas, bares barulhentos e crianças gritando.
No caso de fala mista, nosso método supera significativamente a separação de fala somente de áudio de última geração.
Além disso, nosso modelo é independente do locutor (treine uma vez, aplique a qualquer locutor), produzindo resultados que superam os métodos recentes de separação de fala de áudio e vídeo dependentes do locutor (exigindo que os falantes de interesse treinem um modelo separado).
Palavras-chave e frases adicionais
Audiovisão, separação de fontes, aprimoramento de fala, aprendizado profundo, redes neurais convolucionais (CNN), memória bidirecional de longo e curto prazo (BLSTM)
Formato de referência ACM
Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman e Michael Rubinstein. 2018. Procurando ouvir no coquetel: um modelo audiovisual independente do locutor para separação da fala. ACM Trans. Gráfico. 37, 4, Artigo 112 (agosto de 2018), 11 páginas. https://doi.org/10.1145/3197517.3201357
1. Introdução
Em ambientes barulhentos, os humanos têm a incrível capacidade de concentrar sua atenção auditiva em uma única fonte sonora, enquanto reduzem (“silenciam”) todos os outros sons e ruídos. Como o sistema nervoso realiza esse feito, conhecido como efeito coquetel [Cherry 1953], ainda não está claro.
No entanto, pesquisas mostraram que observar o rosto de quem fala pode melhorar a capacidade de uma pessoa de resolver ambiguidades perceptivas em ambientes ruidosos [Golumbic et al. 2013; Ma et al. 2009]. Neste artigo, implementamos uma expressão computacional dessa capacidade.
O primeiro autor fez este trabalho no Google como estagiário
A separação automática de fala, a separação de um sinal de áudio de entrada em fontes de fala individuais, tem sido extensivamente estudada na literatura de processamento de áudio. Como o problema é de natureza mal condicionada, é necessário conhecimento prévio ou configurações especiais de microfone para uma solução razoável [McDermott 2009].
Além disso, a separação de fala apenas de áudio sofre de um problema fundamental, o problema de permutação de rótulos [Hershey et al. 2016]: não há uma maneira fácil de associar cada fonte de áudio separada ao locutor correspondente no vídeo [Hershey et al. 2016; Yu e outros 2017].
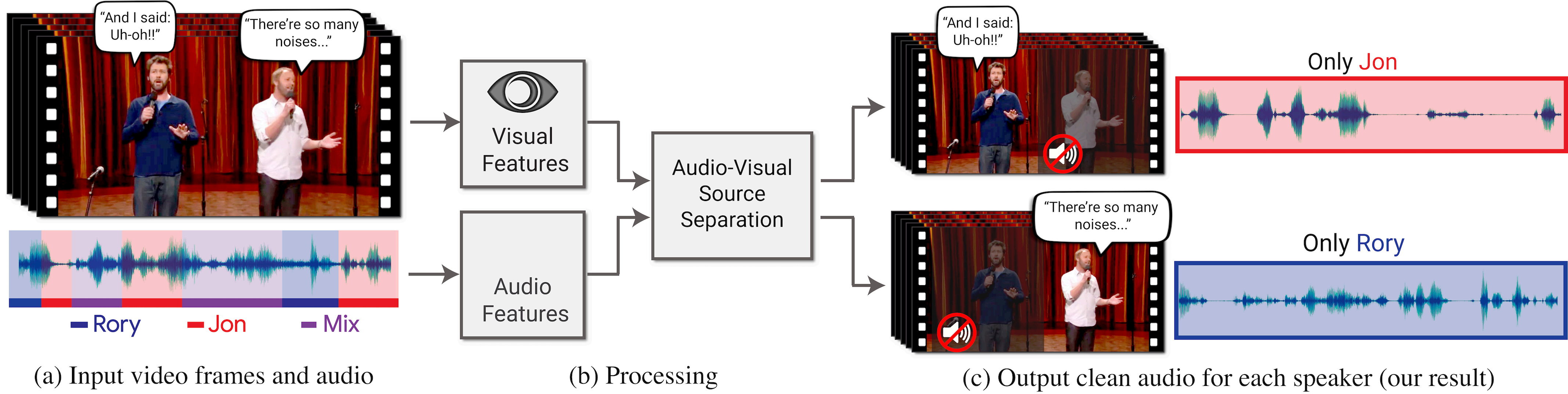
Neste trabalho, propomos uma abordagem audiovisual conjunta para “focar” um orador específico em um vídeo. O vídeo de entrada pode ser recombinado para aprimorar o áudio associado a uma pessoa específica e, ao mesmo tempo, suprimir todos os outros sons (Figura 1).
Figura 1: Propomos um modelo para isolar e aprimorar a fala específica do locutor em vídeos. (a) A entrada é um vídeo (quadro + trilha de áudio) em que uma ou mais pessoas estão falando, e a fala de interesse é perturbada por outros alto-falantes e/ou ruído de fundo. (b) Recursos audiovisuais são extraídos e inseridos em um modelo conjunto de separação de fala audiovisual. A saída é a decomposição da trilha de áudio de entrada em trilhas de fala limpas, uma trilha© para cada pessoa detectada no vídeo. Isso nos permite sintetizar vídeos nos quais a voz de uma pessoa específica é aprimorada enquanto todos os outros sons são suprimidos.
Nosso modelo é treinado usando milhares de horas de videoclipes de nosso novo conjunto de dados AVSpeech. O vídeo "Stand-Up" (semelhante a "Crosstalk") (a) na imagem é fornecido pela Equipe Coco.
Especificamente, projetamos e treinamos um modelo baseado em rede neural que toma como entrada uma mistura gravada de vozes e cortes compactos de rostos detectados em cada quadro do vídeo e segmenta a mistura em cada fluxo de áudio independente de expressão detectada do
O modelo aproveita informações visuais tanto para melhorar a qualidade da separação da fonte (em comparação com resultados usando apenas áudio) quanto para associar faixas de fala separadas com alto-falantes visíveis no vídeo. Tudo o que o usuário precisa fazer é especificar de quais rostos no vídeo deseja ouvir a fala.
Para treinar nosso modelo, coletamos 290.000 palestras de alta qualidade, palestras TED e vídeos tutoriais do YouTube e, em seguida, extraímos automaticamente cerca de 4.700 horas de fala com alto-falantes visíveis e fala limpa (sem sons interferentes) desses videoclipes (Figura 2 ).
Figura 2: Conjunto de dados AVSpeech : Primeiro, coletamos 290.000 discursos públicos on-line de alta qualidade e vídeos de palestras (a). A partir desses vídeos, extraímos clipes com fala limpa (por exemplo, sem mixagem de música, vozes de ouvintes ou outros alto-falantes) e com alto-falantes visíveis nos quadros (veja a Seção 3 e a Figura 3 para detalhes de processamento). Isso resultou em 4.700 horas de videoclipes, cada um deles com uma única pessoa conversando sem distrações de fundo (b). Os dados abrangem uma ampla variedade de pessoas, idiomas e poses faciais, com distribuições mostradas em © (idade e ângulo da cabeça estimados usando classificadores automáticos; idiomas baseados em metadados do YouTube). Para obter uma lista detalhada de fontes de vídeo no conjunto de dados, consulte a página do projeto.

Chamamos esse novo conjunto de dados de AVSpeech. Com esse conjunto de dados, geramos um conjunto de treinamento para um “coquetel sintético” – misturando vídeos de rostos contendo fala limpa com faixas de áudio de outros alto-falantes e ruído de fundo.
Demonstramos a vantagem do nosso método sobre os métodos recentes de separação de fala de duas maneiras.
- Demonstramos resultados superiores em comparação com métodos de última geração somente de áudio em misturas de fala pura.
- Demonstramos a capacidade do nosso modelo de produzir fluxos sonoros aumentados em cenários do mundo real em misturas contendo fala sobreposta e ruído de fundo.
Em resumo, nosso artigo fornece duas contribuições principais :
- Um modelo audiovisual de separação de fala que supera os modelos somente áudio e audiovisuais em tarefas clássicas de separação de fala e se aplica a cenários naturais desafiadores. Até onde sabemos, nosso artigo é o primeiro a propor um modelo para separação de fala audiovisual independente do locutor.
- Um novo conjunto de dados audiovisuais em grande escala, AVSpeech, cuidadosamente coletado e processado, contém videoclipes onde os sons audíveis pertencem a uma única pessoa visível no vídeo e estão livres de distrações de áudio de fundo. Este conjunto de dados nos permite alcançar resultados de última geração em separação de fala e potencialmente leva a estudos adicionais por parte da comunidade de pesquisa.
Nosso conjunto de dados, vídeos de entrada e saída e outros materiais suplementares estão disponíveis na página do projeto: http://looking-to-listen.github.io/.
2. Trabalho relacionado
Revisaremos brevemente trabalhos relacionados nas áreas de separação de fala e processamento de sinais audiovisuais.
Separação de Fala : A separação de fala é um problema fundamental no processamento de áudio e tem sido objeto de extensas pesquisas nas últimas décadas.
-
Wang e Chen [2017] forneceram uma visão abrangente dos métodos recentes baseados em aprendizado profundo somente de áudio para eliminação de ruído de fala [Erdogan et al., 2015; Weninger et al., 2015] e tarefas de separação de fala.
-
Duas abordagens para resolver o **problema de permutação de rótulos** mencionado acima surgiram recentemente para a separação de vários alto-falantes independentes de alto-falante no caso mono.
-
Hershey et al. [2016] propuseram um método chamado " agrupamento profundo ", no qual incorporações de fala treinadas discriminativamente são usadas para agrupar e separar diferentes fontes de fala.
-
Hershey et al. [2016] também introduziram a ideia de uma função de perda livre de permutação ou invariante à permutação, mas não acharam que funcionasse muito bem. Isik et al. [2016] e Yu et al. [2017] propuseram posteriormente um método que usa com sucesso uma função de perda invariante de permutação para treinar redes neurais profundas.
-
-
As vantagens do nosso método sobre os métodos somente de áudio são três:
-
Mostramos que nosso modelo audiovisual alcança resultados de separação de maior qualidade do que os modelos somente de áudio de última geração.
-
Nosso método funciona bem na presença de múltiplos alto-falantes misturados com ruído de fundo, um problema que, até onde sabemos, não foi resolvido de forma satisfatória por uma abordagem apenas de áudio.
-
Abordamos conjuntamente dois problemas de processamento de fala: separação de fala e associação de sinais de fala com suas faces correspondentes, que até agora foram tratados de forma independente [Hoover et al., 2017; Hu et al., 2015; Monaci, 2011].
-
Processamento de Sinais Audiovisuais : A fusão multimodal de sinais auditivos e visuais usando redes neurais para resolver vários problemas relacionados à fala está atraindo interesse crescente.
-
que inclui
-
Reconhecimento de fala audiovisual [Feng et al., 2017; Mroueh et al., 2015; Ngiam et al., 2011]
-
Previsão de fala ou texto a partir de vídeos silenciosos (leitura labial) [Chung et al., 2016; Ephrat et al., 2017]
-
Aprendizagem não supervisionada de linguagem a partir de sinais visuais e de fala [Harwath et al., 2016].
Esses métodos exploram a relação natural de sincronização entre sinais visuais e auditivos gravados simultaneamente.
-
-
Métodos audiovisuais (AV) também têm sido usados
-
Separação e aprimoramento da fala [Hershey et al., 2004; Hershey e Casey, 2002; Khan, 2016; Rivet et al., 2014].
-
Casanovas et al. [2010] usam representações esparsas para separação de fontes AV, mas são limitados por depender apenas de regiões ativas para aprender os recursos da fonte e assumir que todas as fontes de áudio são visíveis na tela.
-
Abordagens recentes usam redes neurais para realizar esta tarefa.
-
Hou et al. [2018] propõem um modelo multitarefa baseado em CNN que produz um espectrograma de fala sem ruído junto com uma reconstrução da região da boca de entrada.
-
Gabbay et al. [2017] treinaram um modelo de aumento de fala em vídeos onde outras amostras de fala do falante alvo foram usadas como ruído de fundo, um esquema que eles chamaram de “treinamento invariante de ruído”. Em trabalho paralelo, Gabbay et al. [2018] usaram uma abordagem de síntese de vídeo para áudio para filtrar áudio ruidoso.
-
-
A principal limitação desses métodos de separação de fala AV é que eles são específicos para cada locutor, o que significa que um modelo dedicado deve ser treinado separadamente para cada locutor. Embora esses trabalhos tenham feito escolhas específicas no design, limitando sua aplicabilidade a situações específicas de alto-falantes. Mas conjecturamos que a principal razão pela qual os modelos AV independentes de locutor não foram extensivamente estudados até o momento é a falta de conjuntos de dados suficientemente grandes e diversos para treinar tais modelos. E é exatamente isso que tem o conjunto de dados que construímos e disponibilizamos neste trabalho .
-
-
Até onde sabemos, nosso artigo é o primeiro a abordar o problema da separação de fala AV para falantes não relacionados. Nosso modelo é capaz de isolar e aprimorar falantes nunca vistos antes , falando idiomas que não estão no conjunto de treinamento. Além disso, nosso trabalho é único porque demonstramos separação de fala de alta qualidade em exemplos do mundo real em ambientes não cobertos por trabalhos anteriores de separação de fala apenas de áudio e audiovisual.
-
Recentemente surgiram vários trabalhos independentes e simultâneos que abordam o problema da separação da fonte sonora audiovisual usando redes neurais profundas.
-
[Owens e Efros 2018] treinaram uma rede para prever se os fluxos de áudio e visuais estão alinhados temporalmente. Os recursos aprendidos extraídos deste modelo auto-supervisionado são então usados para condicionar um modelo de separação de fonte de alto-falante na tela e fora da tela.
-
Afouras et al. [2018] realizam aprimoramento de fala usando uma rede para prever a magnitude e a fase do espectrograma de fala sem ruído.
-
Zhao et al. [2018] e Gao et al. [2018] abordam o problema intimamente relacionado de separar os sons de objetos (por exemplo, instrumentos musicais) em múltiplas telas.
-
Conjuntos de dados audiovisuais : a maioria dos conjuntos de dados AV existentes contém vídeos envolvendo apenas alguns assuntos e palavras faladas de um vocabulário limitado.
-
Por exemplo,
-
O conjunto de dados CUAVE [Patterson et al., 2002] contém 36 sujeitos, cada um dizendo os dígitos de 0 a 9 cinco vezes, para um total de 180 exemplos para cada dígito.
-
Outro exemplo é o conjunto de dados de Sentenças em Mandarim introduzido por Hou et al. [2018], que contém gravações de vídeo de 320 frases em mandarim faladas por um falante nativo. Cada frase contém 10 caracteres chineses nos quais os fonemas estão distribuídos igualmente.
-
O conjunto de dados TCD-TIMIT [Harte e Gillen, 2015] inclui 60 palestrantes voluntários com aproximadamente 200 vídeos por palestrante. Os palestrantes leram uma variedade de frases do conjunto de dados TIMIT [S Garofolo et al., 1992] e gravaram usando uma câmera voltada para frente e em um ângulo de 30 graus.
Para comparação com trabalhos anteriores, avaliamos nossos resultados nesses três conjuntos de dados.
-
-
Mais recentemente, Chung et al. [2016] introduziram um conjunto de dados de sentenças de leitura labial (LRS) em grande escala, que inclui palavras de uma variedade de falantes diferentes e um vocabulário maior. No entanto, não só este conjunto de dados não está disponível publicamente, como também não é garantido que a fala em vídeos LRS seja limpa, o que é crucial para treinar modelos de separação e aumento de fala.
3 Conjunto de dados AVSpeech
Apresentamos um novo conjunto de dados audiovisuais em grande escala contendo clipes de fala livres de sinais de fundo interferentes. Os clipes variam em duração, entre três e 10 segundos, e em cada clipe o único rosto visível no vídeo e a voz no áudio pertencem ao mesmo locutor. No total, o conjunto de dados contém aproximadamente 4.700 horas de videoclipes, abrangendo aproximadamente 150.000 falantes diferentes, abrangendo uma ampla variedade de pessoas, idiomas e poses faciais. A Figura 2 mostra alguns quadros representativos, formas de onda de áudio e algumas estatísticas do conjunto de dados.
Adotamos a abordagem de coletar o conjunto de dados automaticamente porque é importante montar um corpus tão grande sem depender de extenso feedback humano. Nosso pipeline de criação de conjunto de dados coletou trechos de aproximadamente 290.000 vídeos do YouTube, incluindo palestras (como palestras TED) e vídeos tutoriais. Para esses canais, a maioria dos vídeos contém apenas um único alto-falante, e o vídeo e o áudio geralmente são de alta qualidade.
Processo de criação do conjunto de dados . Nosso processo de coleta de conjuntos de dados possui duas etapas principais, conforme mostrado na Figura 3.
Figura 3: Processamento de vídeo e áudio para criação de conjuntos de dados : (a) Usamos detecção e rastreamento de rosto para extrair candidatos a segmentos de fala de vídeos e rejeitar quadros onde os rostos estão desfocados ou não orientados de forma suficientemente positiva. (b) Descartamos passagens contendo fala ruidosa estimando a relação sinal-ruído da fala (ver Seção 3). Os gráficos têm como objetivo demonstrar a precisão do nosso estimador SNR de fala (e, portanto, refletir a qualidade do conjunto de dados). Comparamos a SNR da fala verdadeira com a SNR prevista de uma mistura gerada pela síntese de fala limpa e ruído não verbal em níveis de SNR conhecidos. Os valores SNR previstos (em decibéis) foram calculados em média em 60 misturas geradas em cada compartimento SNR, as barras de erro representam 1 desvio padrão. Descartamos passagens com SNR de fala prevista abaixo de 17dB (marcado pela linha cinza tracejada na figura).

- Primeiro, usamos o método de rastreamento de locutor de Hoover et al. [2017] para detectar passagens em vídeos onde as pessoas estão falando ativamente e os rostos estão visíveis. As molduras faciais são descartadas do segmento se estiverem desfocadas, mal iluminadas ou com pose extrema. Se faltarem mais de 15% dos quadros faciais em um segmento, todo o segmento será descartado. Nesta fase, utilizamos a API 1 do Google Cloud Vision para o classificador e para calcular as estatísticas da Figura 2.
-
A segunda etapa na construção do conjunto de dados é refinar os segmentos de fala para conter apenas fala limpa e sem distrações. Este é um componente crítico, uma vez que essas passagens servem como base na hora do treinamento. Automatizamos esta etapa de otimização estimando a relação sinal-ruído de fala (a razão logarítmica entre o sinal de fala principal e o restante do sinal de áudio) para cada parágrafo.
-
Usamos uma rede de eliminação de ruído de voz pré-treinada apenas para áudio para prever o SNR de fala para uma determinada passagem , usando a saída sem ruído como uma estimativa do sinal limpo . A arquitetura desta rede é idêntica à da linha de base de aprimoramento de fala somente com áudio implementada na Seção 5, treinada em dados de fala de audiolivros de domínio público LibriVox.
-
Para aquelas passagens cujo SNR de fala estimado está abaixo de um certo limite, nós as descartamos. Este limiar foi definido empiricamente utilizando uma mistura sintética de fala pura e ruído que não interfere na fala em diferentes níveis de SNR2 conhecido . Essas misturas sintéticas são alimentadas em uma rede de eliminação de ruído, e o SNR de fala estimado (sem ruído) é comparado a um SNR verdadeiro (ver Figura 3 (b)).
-
- Descobrimos que no caso de SNR baixa, em média, a SNR estimada da fala é muito precisa e, portanto, pode ser considerada um bom preditor do nível de ruído bruto. No entanto, em SNRs mais elevados (isto é, passagens onde o sinal de fala original tem pouca interferência), a precisão deste estimador diminui porque o sinal de ruído torna-se fraco. O limite no qual ocorre esse enfraquecimento é de cerca de 17dB, conforme mostrado na Figura 3(b). Ouvimos uma amostra aleatória de 100 clipes que passaram por esse filtro e descobrimos que nenhum continha ruído de fundo significativo. Fornecemos exemplos de videoclipes do conjunto de dados no material suplementar.
4 Modelo de Separação de Fala Audiovisual
MODELO DE SEPARAÇÃO DE DISCURSO AUDIOVISUAL
Em alto nível, nosso modelo consiste em uma arquitetura multi-stream que toma como entrada um fluxo visual de faces detectadas e áudio com ruído e produz máscaras espectrais complexas, cada uma correspondendo a uma face detectada (veja a Figura 4).
Figura 4: A arquitetura de rede neural multi-stream do nosso modelo : o fluxo visual toma como entrada miniaturas de rostos detectados em cada quadro do vídeo, enquanto o fluxo de áudio toma como entrada a trilha de áudio do vídeo, que contém uma mistura de fala e barulho de fundo. O Visual Flow usa um modelo de reconhecimento facial pré-treinado para extrair incorporações faciais para cada miniatura e, em seguida, usa uma rede neural convolucional dilatada para aprender recursos visuais. O streaming de áudio primeiro calcula a transformada de Fourier de curto prazo (STFT) do sinal de entrada para obter um espectrograma e, em seguida, usa uma rede neural convolucional dilatada semelhante para aprender uma representação de áudio. Uma representação audiovisual conjunta é então criada concatenando os recursos visuais e de áudio aprendidos, que é posteriormente processada por um LSTM bidirecional e três camadas totalmente conectadas. A rede gera uma máscara espectral complexa para cada alto-falante, que é multiplicada pela entrada de ruído e convertida novamente em formas de onda para obter sinais de fala individuais para cada alto-falante.
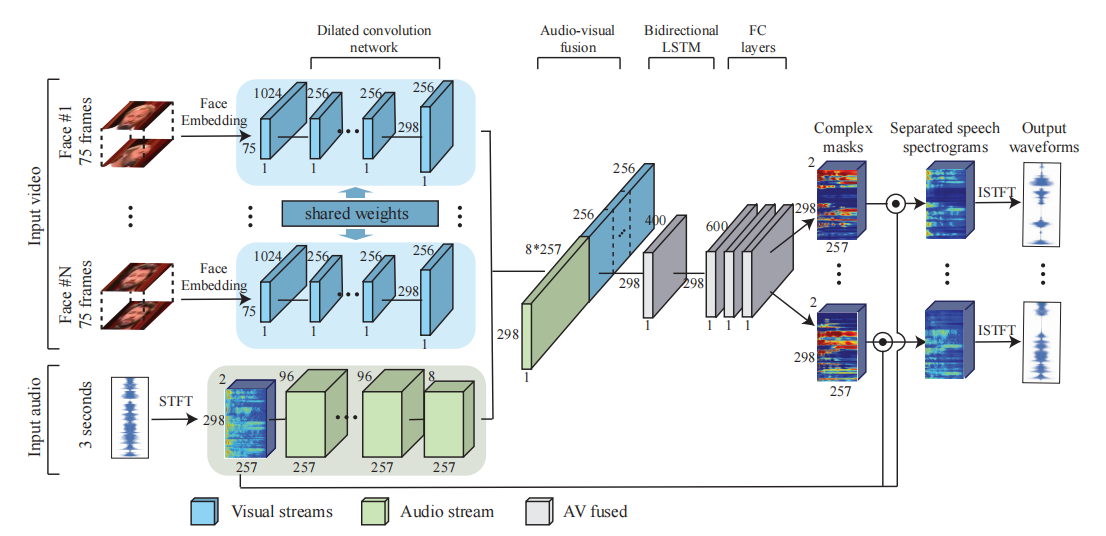
O espectro de entrada de ruído é então multiplicado pela máscara, resultando em sinais de fala individuais para cada alto-falante e suprimindo todos os outros sinais de interferência.
4.1 Representação de Vídeo e Áudio
Insira recursos . Nosso modelo aceita recursos visuais e auditivos como entrada.
-
Para videoclipes com vários alto-falantes, usamos um detector de rosto disponível no mercado (por exemplo, API Google Cloud Vision) para encontrar rostos em cada quadro (um total de 75 miniaturas de rosto por alto-falante, assumindo que cada clipe tenha 3 segundos e o quadro taxa é de 25 FPS).
-
Extraímos uma incorporação de rosto para cada miniatura de rosto detectada usando um modelo de reconhecimento facial pré-treinado. Usamos a camada espacialmente invariante mais baixa da rede, semelhante ao que Cole et al. [2016] usaram para sintetizar faces. A justificativa para isso é que esses embeddings preservam as informações necessárias para reconhecer milhões de rostos, ao mesmo tempo que removem variações irrelevantes entre as imagens, como a iluminação.
-
Na verdade, trabalhos recentes também mostraram que as expressões faciais podem ser recuperadas a partir dessas incorporações [Rudd et al., 2016]. Também tentamos usar os pixels brutos da imagem do rosto, mas isso não resultou em melhoria de desempenho.
-
-
Quanto aos recursos de áudio, calculamos a transformada de Fourier de curta duração (STFT) de um clipe de áudio de 3 segundos. Cada compartimento de frequência de tempo (TF) contém as partes reais e imaginárias de um número complexo, que tomamos como entrada. Fazemos **compressão power-law** para evitar que o áudio alto abafe o áudio suave. O mesmo processamento se aplica ao sinal ruidoso e ao sinal de referência limpo.
-
No momento da inferência, nosso modelo de separação pode ser aplicado a segmentos de vídeo arbitrariamente longos. Nosso modelo pode aceitar vários fluxos de rostos como entrada quando os rostos de vários alto-falantes são detectados em um quadro , discutiremos isso mais tarde.
saída . A saída do nosso modelo é uma máscara espectral multiplicativa que descreve a relação tempo-frequência entre a fala limpa e os distúrbios de fundo.
-
Em estudos anteriores [Wang e Chen 2017; Wang et al. 2014], observou-se que as máscaras multiplicativas são mais eficazes do que outras opções, como a previsão direta de magnitudes espectrais ou a previsão direta de formas de onda no domínio do tempo. Existem muitos objetivos de treinamento baseados em máscara na literatura de separação de fontes [Wang e Chen 2017], tentamos dois deles: máscara de proporção (RM) e máscara de proporção complexa (cRM).
-
A máscara de razão ideal (RM) é definida como a razão de magnitude entre o espectro limpo e o espectro de ruído , e é normalizada entre 0 e 1.
- Ao usar uma máscara de proporção, realizamos uma multiplicação pontual da máscara de proporção prevista e a magnitude do espectro de ruído e, em seguida, realizamos uma transformada inversa de Fourier de curto prazo (ISTFT) junto com a fase bruta de ruído para obter a forma de onda sem ruído [Wang e Chen 2017].
-
Uma máscara de proporção ideal complexa é definida como a razão entre o espectro limpo complexo e o espectro de ruído . Uma máscara de razão ideal complexa possui uma parte real e uma parte imaginária, que são estimadas separadamente no domínio real. As partes reais e imaginárias de máscaras complexas geralmente estão entre -1 e 1, no entanto, usamos a compressão da função sigmóide para restringir esses valores de máscaras complexas entre 0 e 1 [Wang et al. 2016].
- Quando o mascaramento é realizado usando uma máscara de razão ideal complexa, a forma de onda sem ruído é obtida realizando uma multiplicação complexa na máscara de razão ideal complexa prevista e no espectro de ruído, seguida por uma transformada inversa de Fourier de curto tempo (ISTFT) do resultado.
-
-
Dados vários fluxos de rostos de alto-falantes detectados como entrada, a rede gera uma máscara separada para cada alto-falante e distratores de fundo. Na maioria dos experimentos, usamos o cRM porque descobrimos que a qualidade da fala usando o cRM é significativamente melhor do que a do RM. Consulte a Tabela 6 para uma comparação quantitativa dos dois métodos.
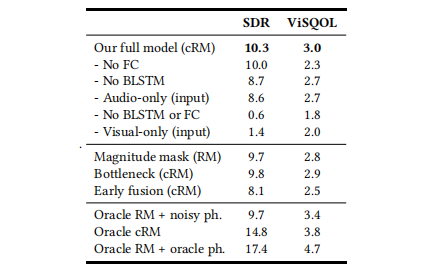
Tabela 6: Estudo de ablação : Investigamos a contribuição do nosso modelo na separação de diferentes partes de uma cena onde dois alto-falantes limpos são mixados. A relação sinal-reverberação (SDR) correlaciona-se bem com a supressão de ruído, enquanto o ViSQOL indica o nível de qualidade da fala (consulte a Seção A no Apêndice para obter detalhes).
4.2 Arquitetura de Rede
A Figura 4 fornece uma visão geral de alto nível dos módulos individuais em nossa rede, que descreveremos agora em detalhes.
Fluxos de áudio e visuais .
-
A parte de streaming de áudio do nosso modelo consiste em camadas convolucionais dilatadas com parâmetros listados na Tabela 1.
Tabela 1: As camadas convolucionais dilatadas que compõem o fluxo de áudio do nosso modelo.

-
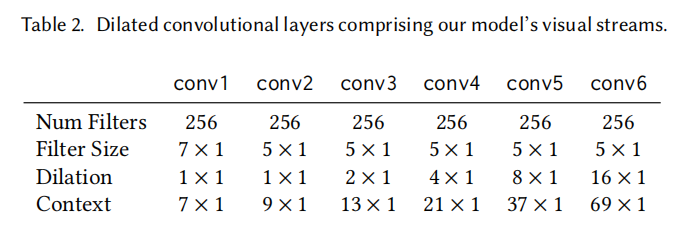
O fluxo visual do nosso modelo é usado para processar os embeddings das faces de entrada (ver Seção 4.1) e consiste em convoluções dilatadas detalhadas na Tabela 2. Observe que as convoluções e dilatações "espaciais" no fluxo visual são realizadas no eixo do tempo (em vez de no canal de incorporação de face de 1024 dimensões).
Tabela 2: As camadas convolucionais dilatadas que compõem o fluxo visual do nosso modelo.
-
Para compensar a diferença na taxa de amostragem entre os sinais de áudio e vídeo, aumentamos a resolução da saída do fluxo visual para corresponder à taxa de amostragem do espectrograma (100 Hz). Isso é feito usando interpolação simples do vizinho mais próximo na dimensão temporal de cada característica visual.
Fusão audiovisual (fusão AV) .
-
Os fluxos de áudio e visuais são mesclados concatenando os mapas de recursos de cada fluxo,
-
Em seguida, ele é alimentado em uma BLSTM (rede bidirecional de memória de longo prazo), seguida por três camadas totalmente conectadas.
-
A saída final consiste em uma máscara complexa (dois canais, real e imaginário) para cada alto-falante de entrada.
-
Os espectrogramas correspondentes (Os espectrogramas correspondentes) são obtidos pela multiplicação complexa do espectrograma da entrada ruidosa e da máscara de saída.
-
O erro quadrático (perda L2) entre o espectrograma limpo e aprimorado após a compressão de potência é usado como função de perda para treinar a rede.
-
A forma de onda de saída final é obtida pela transformada inversa de Fourier de curta duração (ISTFT), conforme descrito na Seção 4.1.
Vários alto-falantes .
Nosso modelo suporta o isolamento de vários alto-falantes visíveis de um vídeo, cada alto-falante é representado por um fluxo visual , conforme mostrado na Figura 4.
-
Para cada número de alto-falantes visíveis, treine um modelo dedicado separado. Por exemplo,
- Um modelo com um fluxo visual corresponde a um alto-falante visível
- Um modelo com fluxos visuais duplos correspondentes a dois alto-falantes visíveis
etc.
-
Todos os fluxos visuais compartilham os mesmos pesos nas camadas convolucionais. Neste caso, os recursos aprendidos de cada fluxo visual são concatenados com os recursos de áudio aprendidos antes de prosseguir com o BLSTM.
-
Vale a pena notar que, na prática, um modelo que utiliza um único fluxo visual como entrada pode ser usado para o caso geral em que o número de alto-falantes é desconhecido ou um modelo dedicado de vários alto-falantes não pode ser usado.
4.3 Detalhes de Implementação
Nossa rede é implementada usando TensorFlow, que contém operações para controlar formas de onda e transformações STFT.
-
A função de ativação do ReLU segue todas as camadas da rede, exceto a última camada (máscara), que utiliza sigmoid .
-
A normalização em lote é realizada após todas as camadas convolucionais [ Ioffe e Szegedy 2015].
-
Não usamos dropout porque treinamos com uma grande quantidade de dados e não há chance de overfitting.
-
Usamos um tamanho de lote de 6 amostras,
-
E use o otimizador Adam para 5 milhões de etapas (lotes, lotes) de treinamento,
-
A taxa de aprendizagem é 3 ⋅ 1 0 − 5 3\cdot10^{−5}3⋅1 0− 5 , que é reduzido pela metade a cada 1,8 milhão de passos.
Todos os dados de áudio são reamostrados para 16kHz e o áudio estéreo será convertido para mono usando apenas o canal esquerdo. Calcule o STFT usando um comprimento de janela de Hann de 25 ms, um comprimento de salto de 10 ms e um tamanho de FFT de 512, resultando em 257 × 298 × 2 257\times298\times2257×298×2 recursos de áudio de entrada escalar. Tomep = 0,3 p = 0,3p=0,3(A 0,3 A^{0,3}A0,3 , dos quaisAAA é o espectrograma de áudio de entrada/saída) para compressão de lei de potência.
Reamostramos os embeddings faciais de todos os vídeos para 25 quadros por segundo (FPS) antes do treinamento e da inferência, eliminando ou duplicando os embeddings. Isso resulta em um fluxo visual de entrada que consiste em 75 incorporações de faces. A detecção facial , o alinhamento e a avaliação da qualidade foram realizados utilizando as ferramentas descritas por Cole et al. [2016] . Quando um quadro ausente é encontrado em uma amostra específica, usamos um vetor zero em vez da incorporação de face.
5 Experimentos e Resultados
Testamos nosso método sob várias condições e comparamos os resultados quantitativa e qualitativamente com métodos de separação e aprimoramento de fala somente de áudio (AO) e audiovisual (AV) de última geração.
Comparação com somente áudio.
-
Atualmente, não existem sistemas de última geração de aprimoramento/separação de fala somente com áudio disponíveis publicamente, e há relativamente poucos conjuntos de dados disponíveis publicamente para treinamento e avaliação de aprimoramento de fala somente com áudio.
-
Embora exista uma extensa literatura sobre separação cega de fontes de sinais de áudio [Comon e Jutten 2010], a maioria dessas técnicas requer múltiplos canais de áudio (múltiplos microfones) e, portanto, não são adequadas para nossa tarefa.
Por essas razões, implementamos um modelo básico de aprimoramento de fala somente com áudio com uma arquitetura semelhante ao nosso modelo de streaming de áudio (Fig. 4, quando o streaming visual é removido). Quando treinado e avaliado no conjunto de dados CHiME-2 amplamente utilizado em trabalhos de aprimoramento de fala [Vincent et al., o mono de última geração também resulta em 14,75 dB.
Portanto, nosso modelo de aumento somente de áudio é considerado uma linha de base quase de última geração.
Para comparar nossos resultados de separação com modelos somente de áudio de última geração, implementamos o método de treinamento invariante à permutação introduzido por Yu et al. [2017].
- Observe que a separação de fala usando este método requer conhecimento prévio do número de fontes presentes na gravação e atribuição manual de cada canal de saída ao rosto do locutor correspondente (nosso método AV faz isso automaticamente).
Usamos esses métodos AO em todos os experimentos sintéticos na Seção 5.1 e realizamos comparações de qualidade em vídeos reais na Seção 5.2.
Comparação com métodos audiovisuais recentes.
-
Como os métodos audiovisuais existentes de separação e aprimoramento da fala são específicos do locutor , não podemos compará-los facilmente em experimentos com fala mista sintética (Seção 5.1), nem executá-los em vídeo natural (Seção 5.1).Seção 5.2).
-
No entanto, mostramos comparações quantitativas com esses métodos em conjuntos de dados existentes, executando nossos modelos em vídeos desses artigos. Discutimos essa comparação com mais detalhes na Seção 5.3.
-
Além disso, apresentamos comparações qualitativas no material do apêndice.
5.1 Análise Quantitativa da Fala Mista Sintetizada
Geramos dados para diversas tarefas diferentes de separação de fala monofônica. Cada tarefa requer sua própria combinação exclusiva de configurações de ruído de fundo de fala e não fala. Descrevemos a seguir o processo generativo para cada variante dos dados de treinamento e os modelos associados para cada tarefa, que são treinados do zero.
-
Em todos os casos, clipes de fala limpos e imagens faciais correspondentes são do nosso conjunto de dados AVSpeech (AVS).
-
O ruído de fundo sem fala vem do AudioSet [Gemmeke et al. 2017], um conjunto de dados em grande escala que consiste em clipes anotados manualmente de vídeos do YouTube.
A qualidade da fala separada foi avaliada usando a melhoria da relação sinal-distorção (SDR) na caixa de ferramentas BSS Eval [Vincent et al. 2006], que é uma métrica comumente usada para avaliar a qualidade da separação da fala (consulte a Seção A no Apêndice para detalhes).
Extraímos segmentos não sobrepostos de 3 segundos de nosso conjunto de dados (por exemplo, um segmento de 10 segundos geraria três segmentos de 3 segundos). Geramos 1,5 milhão de discursos mistos sintéticos para todos os modelos e experimentos. Para cada experimento, 90% dos dados gerados são usados como conjunto de treinamento e os 10% restantes são usados como conjunto de teste. Não usamos nenhum conjunto de validação, pois nenhum ajuste de parâmetro ou parada antecipada foi realizado.
Um alto-falante+ruído (Um alto-falante+ruído (1S+Ruído)).
Esta é uma tarefa clássica de aprimoramento de fala em que os dados de treinamento são gerados pela combinação linear de fala limpa não normalizada e ruído AudioSet :
Mixi = AVS j + 0,3 ∗ A audio Set Mix_i=AVS_j+0,3*AudioSet_kM eu xeu=A V Sj+0,3∗Conjunto de áudio _ _ _ _ _k
em:
- AVSj AVS_jA V SjEste é AVS AVSUm enunciado em A V S
- Áudio Setk AudioSet_kConjunto de áudio _ _ _ _ _k是A audio Set e AudioSetUm fragmento no AudioSet cuja magnitude é multiplicada por 0,3
- M ixi Mix_iM eu xeué uma amostra do conjunto de dados de fala mista sintética
Nossos modelos somente de áudio funcionam muito bem neste caso, uma vez que as frequências próprias do ruído geralmente estão bem separadas daquelas da fala. Nosso modelo audiovisual (AV) tem desempenho comparável à linha de base somente áudio (AO), ambos com SDR de 16dB (ver primeira coluna da Tabela 3).
Tabela 3: Análise quantitativa e comparação com separação e aprimoramento de fala somente de áudio : melhoria de qualidade (em SDR, consulte a Seção A no Apêndice para obter detalhes) em função do número de fluxos visuais de entrada, usando diferentes configurações de rede. A primeira linha (somente áudio) é a nossa implementação de um modelo de separação de fala de última geração e mostrada como linha de base.

Dois alto-falantes limpos (Dois alto-falantes limpos (2S limpos)).
O conjunto de dados usado para este cenário de separação de dois alto-falantes foi gerado pela mistura de fala limpa de dois alto-falantes diferentes em nosso conjunto de dados AVS:
Mixi = AVS j + AVS k Mix_i = AVS_j + AVS_kM eu xeu=A V Sj+A V Sk
em:
-
AVSj AVS_jA V SjSoma AVS k AVS_kA V Sksão amostras de fala limpas de diferentes vídeos de origem no conjunto de dados
-
M ixi Mix_iM eu xeué uma amostra do conjunto de dados de fala mista sintética
Além do nosso modelo de linha de base AO, treinamos dois modelos AV diferentes nesta tarefa:
-
(i) Um modelo que aceita apenas um fluxo visual como entrada e emite apenas seu sinal sem ruído correspondente.
Neste caso, no momento da inferência, o sinal sem ruído de cada alto-falante é obtido fazendo duas passagens diretas pela rede (uma para cada alto-falante). A média dos resultados de SDR deste modelo produz uma melhoria de 1,3 dB em relação ao nosso modelo de linha de base AO (segunda coluna da Tabela 3).
-
(ii) Aceita simultaneamente informações visuais de dois alto-falantes como entrada na forma de dois fluxos visuais separados (conforme descrito na Seção 4).
Neste caso, a saída consiste em duas máscaras, uma para cada alto-falante, e apenas uma passagem direta é necessária para inferência. O uso deste modelo obtém um aumento adicional de 0,4 dB, para uma melhoria total de 10,3 dB no SDR. Intuitivamente, o processamento conjunto dos dois fluxos visuais fornece mais informações à rede e impõe mais restrições na tarefa de separação, levando a melhores resultados.
A Figura 5 mostra o SDR aprimorado para esta tarefa com base no SDR de entrada, incluindo o modelo de linha de base somente de áudio e nosso modelo audiovisual de dois alto-falantes.
Figura 5: SDR de entrada versus SDR de saída aprimorado : Este é um gráfico de dispersão que mostra o desempenho de separação (melhoria de SDR) na tarefa de separar dois alto-falantes limpos (2S limpos) em função do SDR original (ruidoso). Cada ponto corresponde a uma única amostra audiovisual de 3 segundos no conjunto de teste.

Dois alto-falantes + ruído (Dois alto-falantes + ruído (2S + Ruído)).
Aqui consideramos a tarefa de isolar a voz de um locutor de uma mistura de dois falantes e ruído de fundo não falado. Até onde sabemos, esta tarefa audiovisual não foi resolvida antes. Os dados de treinamento são obtidos combinando a fala limpa de dois alto-falantes diferentes (conforme gerado pela tarefa limpa 2S) com Audio S et AudioSetO ruído de fundo do A u d i o Set é mixado: M ixi = AVS j + AVS k + 0,3 ∗ A audio S etl Mix_i=AVS_j+AVS_k+0.3 * AudioSet_l
M eu xeu=A V Sj+A V Sk+0,3∗Conjunto de áudio _ _ _ _ _eu
Neste caso, treinamos a rede AO com três saídas, uma para cada alto-falante e ruído de fundo.
Além disso, treinamos modelos com duas configurações diferentes,
-
Aquele que recebe um fluxo visual como entrada
- A configuração de um modelo AV para um fluxo visual é a mesma do modelo (i) em experimentos anteriores.
-
O outro recebe dois fluxos visuais como entrada
- O modelo AV dos dois fluxos visuais emite três sinais, um para cada alto-falante e ruído de fundo.
Conforme mostrado na Tabela 3 (terceira coluna), o ganho SDR de 0,1 dB para o modelo AV para um fluxo visual e 0,5 dB para o modelo AV de dois fluxos visuais em relação ao modelo de linha de base somente de áudio leva a uma melhoria geral do SDR de até 10,6dB.
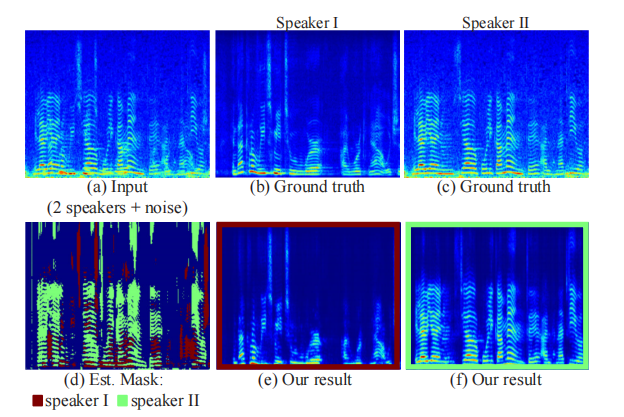
A Figura 6 mostra a máscara inferida e o espectrograma de saída para um segmento de amostra desta tarefa, juntamente com sua entrada ruidosa e espectrograma verdadeiro.
Figura 6: Exemplos de áudio de entrada e saída: a linha superior mostra o espectrograma de áudio para um segmento de nossos dados de treinamento envolvendo dois alto-falantes e ruído de fundo (a), e o espectrograma real separado para cada alto-falante (b, c). Na linha inferior, mostramos nossos resultados: a máscara estimada do nosso método para o segmento, sobreposta a um espectrograma com cores diferentes para cada alto-falante (d), e o espectro de saída correspondente para cada alto-falante Fig.
Três alto-falantes limpos (Três alto-falantes limpos (3S limpos)).
O conjunto de dados para esta tarefa é feito misturando fala limpa de três falantes diferentes:
Mixi = AVS j + AVS k + AVS l Mix_i=AVS_j+AVS_k+AVS_lM eu xeu=A V Sj+A V Sk+A V Seu
Semelhante às tarefas anteriores, treinamos um modelo AV que recebe um, dois e três fluxos visuais como entrada e emite um, dois e três sinais, respectivamente.
Descobrimos que mesmo com um único fluxo visual, o modelo AV supera o modelo AO em 0,5dB em comparação. A configuração de dois fluxos visuais também proporciona a mesma melhoria ao modelo AO, enquanto o uso de três fluxos visuais leva a um ganho de 1,4dB, elevando a melhoria geral do SDR para 10dB (quarta coluna da Tabela 3).
Separação do mesmo sexo.
Muitos métodos anteriores de separação de fala funcionam mal ao tentar separar misturas de fala contendo fala do mesmo gênero [Delfarah e Wang 2017; Hershey et al. 2016].
A Tabela 4 mostra a nossa qualidade de separação de acordo com diferentes combinações de género.
Tabela 4: **Separação do mesmo sexo. **Os resultados nesta tabela são do experimento limpo 2S, mostrando que nosso método é robusto para separar a fala de misturas do mesmo gênero.

Curiosamente, o nosso modelo tem um melhor desempenho (ligeiramente à frente) na combinação mulher-mulher, mas também tem um bom desempenho noutras combinações, mostrando que é robusto em relação ao género.
5.2 Separação de Fala no Mundo Real
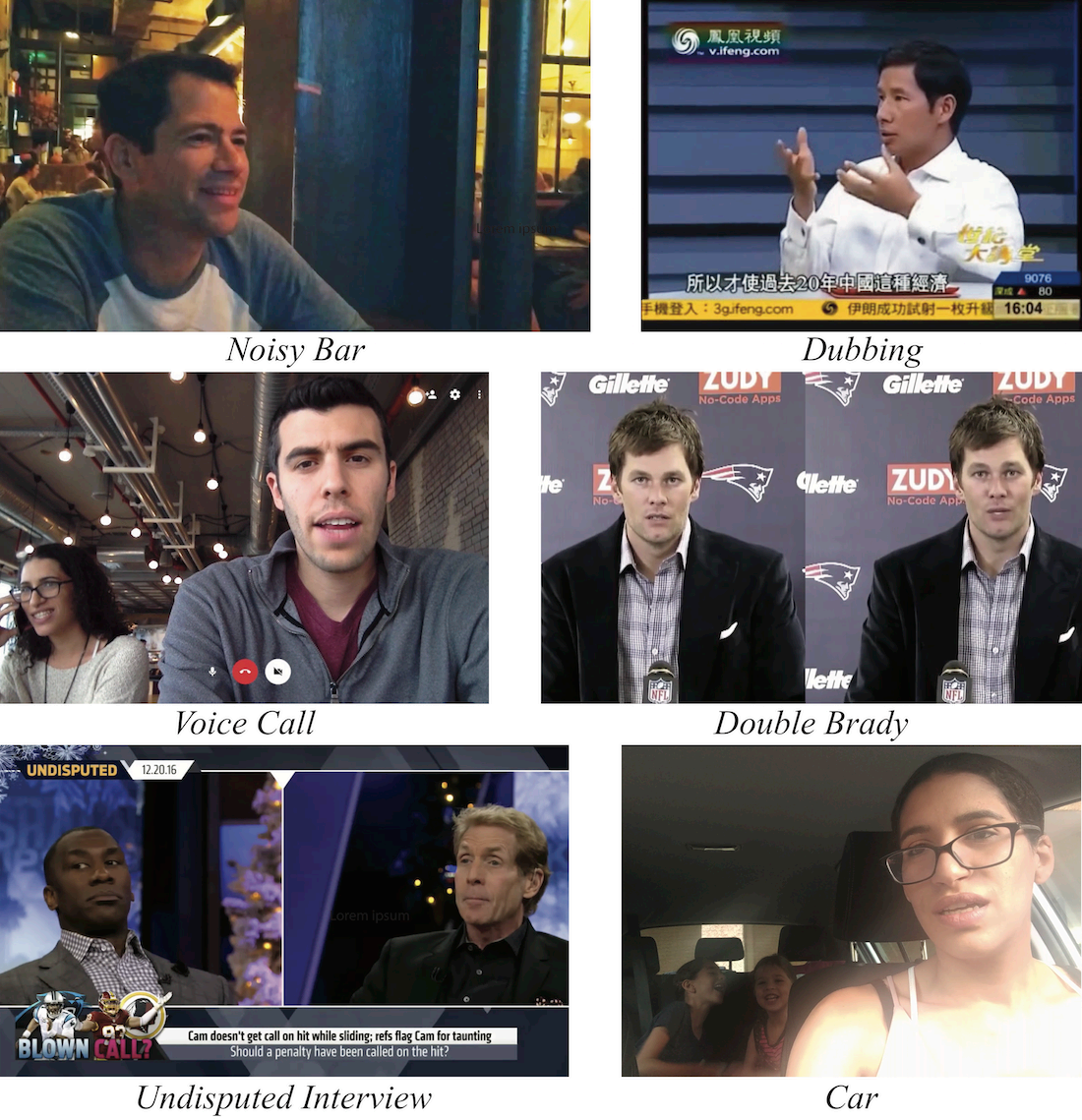
Para demonstrar as capacidades de separação de fala do nosso modelo em cenários do mundo real, testámo-lo numa variedade de vídeos contendo debates e entrevistas acalorados, bares barulhentos e crianças aos gritos (ver Figura 7).
Figura 7: Separação de fala em estado selvagem : mostra quadros representativos de vídeos naturais aplicando nosso método em vários cenários do mundo real. Todos os vídeos e resultados podem ser encontrados no material apêndice. Vídeo "Entrevista Undisputed" cortesia da Fox Sports.
Em cada cena, treinamos o modelo usando vários fluxos de entrada visual que correspondiam ao número de alto-falantes visíveis no vídeo.
- Por exemplo, para um vídeo com dois alto-falantes visíveis, usamos um modelo de dois alto-falantes.
Realizamos a separação usando um único avanço por vídeo, uma operação suportada pelo nosso modelo porque nossa arquitetura de rede nunca impõe uma persistência temporal específica.
- Isso evita a necessidade de pós-processamento e integração de resultados em segmentos mais curtos do vídeo.
Como esses exemplos não possuem áudio de referência limpo, esses resultados e sua comparação com outros métodos são avaliados qualitativamente; eles são apresentados em nosso apêndice.
Vale ressaltar que nosso método não suporta processamento em tempo real e atualmente nosso aprimoramento de fala é mais adequado para a fase de pós-processamento de vídeo.
-
O vídeo sintético "Double Brady" em nosso apêndice destaca a exploração da informação visual por nosso modelo, uma vez que a separação da fala é difícil neste caso apenas pelas frequências características da fala contidas no áudio.
-
No cenário "Noisy Bar", nosso método apresenta algumas limitações na separação da fala de uma mixagem com SNR baixo. Neste caso, o ruído de fundo é quase completamente suprimido, mas a qualidade da fala de saída é significativamente reduzida.
- Sun et al. [2017] observaram que essa limitação decorre do uso de métodos baseados em máscara para separação e, neste caso, a previsão direta do espectrograma sem ruído pode ajudar a superar esse problema.
- No caso clássico de aprimoramento de fala, ou seja, um alto-falante e ruído de fundo sem fala, nosso modelo AV atinge resultados semelhantes ao nosso forte modelo de linha de base AO. Suspeitamos que isso ocorre porque as frequências próprias do ruído são muitas vezes claramente separadas das da fala, de modo que a adição de informação visual não forneceu poder discriminativo adicional.
5.3 Comparação com trabalhos anteriores de separação e aprimoramento de fala audiovisual
Nossa avaliação não estaria completa sem comparar nossos resultados com os de trabalhos anteriores de separação e aprimoramento de fala audiovisual.
A Tabela 5 contém comparações em três conjuntos de dados audiovisuais diferentes (Mandarim, TCD-TIMIT e CUAVE, ver Secção 2), utilizando os protocolos de avaliação e métricas descritos nos respectivos artigos.
Tabela 5: Comparação com trabalhos existentes de separação de fala audiovisual : Comparamos nossos resultados de separação e aprimoramento de fala em vários conjuntos de dados com aqueles de trabalhos anteriores, usando o protocolo de avaliação relatado no artigo original e a pontuação objetiva. É importante notar que os métodos anteriores dependem do falante, enquanto nossos resultados são obtidos usando um modelo geral independente do falante.

As pontuações de qualidade objetiva relatadas são PESQ [Rix et al. 2001], STOI [Taal et al. 2010] e SDR [Vincent et al. 2006] no kit de ferramentas de avaliação BSS. Os resultados qualitativos dessas comparações estão disponíveis na página do nosso projeto.
É importante observar que esses métodos anteriores exigiam o treinamento de um modelo especializado (dependente do locutor) para cada locutor em seus conjuntos de dados individualmente, enquanto nossa avaliação de seus dados foi realizada usando nosso conjunto de dados AVS de uso geral. Modelo treinado (independente do locutor). Embora nunca tenhamos encontrado esses falantes específicos, nossos resultados são significativamente melhores que os relatados no artigo original, indicando a forte capacidade de generalização do nosso modelo.
5.4 Aplicado à transcrição de vídeo
Embora este artigo se concentre na separação e aprimoramento da fala, nosso método também pode ser usado para reconhecimento automático de fala (ASR) e transcrição de vídeo.
Para testar este conceito, realizamos os seguintes experimentos qualitativos. Carregamos os resultados da separação de fala do vídeo "Stand-Up" no YouTube e comparamos os resultados da geração automática de legendas3 do YouTube com os resultados gerados pela parte correspondente do vídeo original com fala mista. Para partes do vídeo "Stand-Up" original, o sistema ASR não conseguiu gerar legendas no segmento de voz mista do vídeo. A fala de ambos os locutores foi incluída no resultado, resultando em frases de difícil leitura.
No entanto, as legendas resultantes são significativamente mais precisas para os nossos resultados de fala separados. Apresentamos o vídeo totalmente legendado no material apêndice.
5.5 Análise Adicional
Também realizamos extensos experimentos para compreender melhor o comportamento do modelo e o impacto de seus diferentes componentes nos resultados.
Estudo de ablação
Para entender melhor a contribuição de diferentes partes do nosso modelo, realizamos experimentos de ablação na tarefa de separar a fala de uma mistura de dois falantes limpos (2S Clean). Além de remover vários módulos de rede combinados (fluxos visuais e de áudio, camadas BLSTM e FC), também investigamos variações de nível superior, como diferentes máscaras de saída (magnitudes), reduzindo os recursos visuais aprendidos a cada intervalo de tempo. , e um método de fusão diferente (fusão precoce).
-
Nos primeiros modelos de fusão, não tínhamos fluxos visuais e de áudio separados, mas combinávamos as duas modalidades na entrada. Isto é através
- As dimensões de cada incorporação visual são reduzidas para corresponder às dimensões do espectrograma em cada intervalo de tempo usando duas camadas totalmente conectadas,
- Os recursos visuais são então empilhados como um terceiro "canal" do espectrograma e processados conjuntamente em todo o modelo para conseguir isso.
-
A Tabela 6 mostra os resultados dos nossos experimentos de ablação. A tabela inclui avaliações usando SDR e ViSQOL [Hines et al., 2015], uma medida objetiva projetada para aproximar o Mean Opinion Score (MOS) da qualidade da fala por ouvintes humanos. As pontuações do ViSQOL são calculadas em um subconjunto aleatório de 2.000 amostras de nossos dados de teste. Descobrimos que o SDR está intimamente relacionado à quantidade de ruído residual no áudio separado, enquanto o ViSQOL caracteriza melhor a qualidade da fala de saída. Consulte a Parte A do Apêndice para obter mais detalhes sobre essas pontuações. RMs e cRMs “Oracle” são máscaras adquiridas conforme descrito na Seção 4.1, usando espectrogramas reais de valor real e de valor complexo, respectivamente.
As descobertas mais interessantes deste estudo são a redução do MOS ao usar máscaras de magnitude de valor real em vez de máscaras de magnitude de valor complexo , e a eficácia inesperada de compactar a informação visual em um escalar por intervalo de tempo, conforme descrito abaixo.
Recursos de gargalo
Nota do tradutor: A razão pela qual é chamado de gargalo é porque a camada de gargalo se parece mais com um gargalo.
Em nossa análise de ablação, descobrimos que uma rede que comprime informações visuais em um escalar a cada passo de tempo (“Gargalo (cRM)”) tem um desempenho quase tão bom quanto nosso modelo completo (“Modelo completo (cRM)”) (apenas 0,5dB diferença). Este último usa 64 escalares por intervalo de tempo.
Como o modelo utiliza sinais visuais? (Como o modelo utiliza o sinal visual?)
Nosso modelo usa incorporações de faces como representações visuais de entrada (Seção 4.1). Queremos entender as informações capturadas nesses recursos de alto nível e determinar quais regiões nos quadros de entrada do modelo são usadas para separar a fala.
Para tanto, seguimos um protocolo semelhante ao [Zeiler e Fergus 2014; Zhou et al. 2014] para visualização do campo receptivo da rede visual. Estendemos este protocolo de imagens 2D para vídeos 3D (espaço-tempo).
Mais especificamente, usamos um oclusor espaço-temporal (patch 4 de 11px × 11px × 200ms ) em forma de janela deslizante. Para cada oclusor espaço-temporal, alimentamos o vídeo ocluído em nosso modelo e comparamos o resultado Socc da separação de fala resultante com o resultado Sori para o vídeo original (não ocluído).
Para quantificar a diferença entre as saídas da rede, utilizamos o SNR, considerando resultados sem oclusões como "sinal" 5 . Ou seja, para cada oclusor de espaço-tempo, calculamos:
E = 10 ⋅ log ( S orig 2 ( S occ − S orig ) 2 ) (1) E=10\cdot{log(\frac{ { S_ {orig
} }^2}{(S_{occ}-S_{orig})^2})}\tag{1}E=10⋅eu o g (( Socc-Sou eu vou)2Sou eu vou2)( 1 )
Repetir esse processo para todos os oclusores espaço-temporais no vídeo resulta em um mapa de calor para cada quadro. Para visualização, normalizamos o mapa de calor para o SNR máximo do vídeo:
E ~ = E max − E \tilde{E}=E_{max}−EE~=Ema x-E
在E ~ \tilde{E}E~ , um valor grande corresponde a um oclusor que tem maior influência no resultado da separação da fala.
Na Figura 8, mostramos os resultados do mapa de calor para quadros representativos de vários vídeos (os vídeos completos do mapa de calor estão disponíveis na página do projeto). Como esperado, a maior contribuição para a região da face está localizada principalmente ao redor da boca, porém os resultados da visualização mostram que outras regiões como olhos e bochechas também contribuem até certo ponto.
Figura 8: Como o modelo ** utiliza sinais visuais? **Mostramos mapas de calor sobrepostos a quadros de entrada representativos de vários vídeos, visualizando a contribuição (em decibéis, veja o texto) de diferentes regiões para nossos resultados de separação de fala, variando do azul (baixa contribuição) ao vermelho (alta contribuição).

Efeito da falta de informação visual
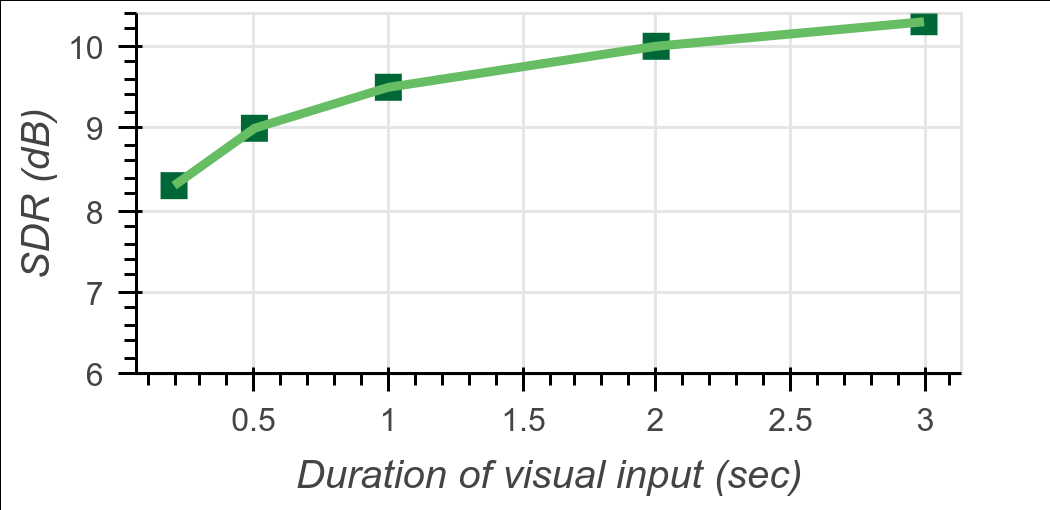
Testamos ainda mais a contribuição da informação visual para o modelo, removendo gradualmente as incorporações visuais. Especificamente, primeiro executamos o modelo e usamos o vídeo completo de 3 segundos para avaliação, resultando na qualidade da separação da fala com informações visuais. Em seguida, descartamos progressivamente os encaixes em ambas as extremidades do parágrafo e reavaliamos a qualidade da separação para durações visuais de 2 s, 1 s, 0,5 se 0,2 s.
O resultado é mostrado na Figura 9. Curiosamente, ao descartar até 2/3 das incorporações visuais em uma passagem, a qualidade da separação da fala cai em média apenas 0,8 dB. Isso mostra que o modelo é robusto à falta de informações visuais, que podem ocorrer em cenários do mundo real devido a movimentos da cabeça ou oclusões.
Figura 9: Efeito da informação visual ausente : Esta figura mostra o efeito da duração da informação visual na melhoria do SDR de saída em uma cena de 2 alto-falantes limpos (2S limpos). Testamos zerando gradualmente as incorporações da face de entrada de ambas as extremidades da amostra. Os resultados mostram que mesmo um pequeno número de quadros visuais é suficiente para uma separação de alta qualidade.
para concluir
Propomos um novo modelo de rede neural audiovisual para separação de fala de canal único e independente do locutor. Nosso modelo funciona bem em vários cenários desafiadores, incluindo mixagens de vários alto-falantes com ruído de fundo. Para treinar o modelo, criamos um novo conjunto de dados audiovisuais que consiste em milhares de horas de videoclipes de locutores visíveis e fala limpa coletados da web. Nosso modelo alcança resultados de última geração em separação de fala e mostra aplicações potenciais em legendagem de vídeo e reconhecimento de fala. Também realizamos extensos experimentos analisando o comportamento e a eficácia do nosso modelo e de seus componentes individuais. No geral, nosso método representa um avanço importante na separação e aprimoramento da fala audiovisual.
obrigado
Gostaríamos de agradecer a Yossi Matias e ao Google Research Israel pelo apoio a este projeto, e a John Hershey pela sua valiosa contribuição. Gostaríamos também de agradecer a Arkady Ziefman por sua ajuda com o design das figuras e edição de vídeo, e a Rachel Soh por nos ajudar a licenciar o conteúdo do vídeo nos resultados.
referências
- T. Afouras, JS Chung e A. Zisserman. 2018. Diálogo: Aprimoramento profundo da fala audiovisual. Em arXiv:1804.04121.
- Anna Llagostera Casanovas, Gianluca Monaci, Pierre Vandergheynst e Rémi Gribonval.2010. "Separação cega de fontes de áudio-vídeo com base em representações redundantes esparsas".IEEE Transactions on Multimedia 12, 5 (2010), 358–371.
- E Colin Cherry, 1953. "Algumas experiências em reconhecimento de fala com uma e duas orelhas".Journal of the Acoustical Society of America 25, 5 (1953), 975–979.
- Joon Son Chung, Andrew W. Senior, Oriol Vinyals e Andrew Zisserman. 2016. Frases de leitura labial na natureza. CoRR abs/1611.05358 (2016).
- Forrester Cole, David Belanger, Dilip Krishnan, Aaron Sarna, Inbar Mosseri e William T Freeman. 2016. Sintetizando rostos normalizados a partir de características de identidade facial. CVPR'17.
- Pierre Comon e Christian Jutten. 2010. Manual de separação cega de fontes: análise e aplicações de componentes independentes. Academic Press.
- Masood Delfarah e DeLiang Wang. 2017. Caracterização da separação de fala monofônica baseada em mascaramento em ambientes reverberantes.Transações IEEE/ACM em processamento de áudio, fala e linguagem 25 (2017), 1085–1094.
- Ariel Ephrat, Tavi Halperin e Shmuel Peleg. 2017. Reconstrução de fala aprimorada a partir de vídeo silencioso. ICCV 2017 Workshop de visão computacional.
- Hakan Erdogan, John R. Hershey, Shinji Watanabe e Jonathan Le Roux. 2015. Separação de fala aprimorada e sensível à fase com redes neurais recorrentes profundas.Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP) (2015).
- Weijiang Feng, Naiyang Guan, Yuan Li, Xiang Zhang e Zhigang Luo. 2017. Reconhecimento de fala audiovisual com redes neurais recorrentes multimodais. 2017 Conferência Conjunta Internacional sobre Redes Neurais (IJCNN). IEEE, 681–688.
- Aviv Gabbay, Ariel Ephrat, Tavi Halperin e Shmuel Peleg. 2018. Vendo através do ruído: separação e aprimoramento de alto-falantes usando fala derivada visualmente. Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP) (2018).
- Aviv Gabbay, Asaph Shamir e Shmuel Peleg. 2017. Aprimoramento visual da fala usando treinamento antirruído. pré-impressão arXiv arXiv:1711.08789 (2017).
- R. Gao, R. Feris e K. Grauman. 2018. Aprendendo a separar sons de objetos assistindo a vídeos não rotulados. pré-impressão arXiv arXiv:1804.01665 (2018).
- Jort F. Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal e Marvin Ritter. 2017. Audiosets: um conjunto de dados de ontologia e rotulagem humana de eventos de áudio. IEEE 2017 ICASSP Conference Proceedings.
- Elana Zion Golumbic, Gregory B Cogan, Charles E. Schroeder e David Poeppel. 2013. A entrada visual melhora o rastreamento de envelopes de fala seletivos no córtex auditivo em "Cocktail". Neuroscience, Official Journal of the American Academy of Neuroscience 33 Edição 4 ( 2013), 1417–26.
- Naomi Harte e Eoin Gillen.2015. TCD-TIMIT: Um Corpus Audiovisual de Fala Contínua.IEEE Transactions on Multimedia 17, 5 (2015), 603–615.
- David F. Harwath, Antonio Torralba e James R. Glass. 2016. Aprendizagem não supervisionada da linguagem falada com contexto visual. Em NIPS.
- John Hershey, Hagai Attias, Nebojsa Jojic e Trausti Kristjansson.2004. Modelos Gráficos Audiovisuais para Processamento de Fala.Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP).
- John R Hershey e Michael Casey. 2002. Separação de som audiovisual usando modelos ocultos de Markov. Avanços em sistemas de processamento de informações neurais. 1173–1180.
- John R. Hershey, Zhuo Chen, Jonathan Le Roux e Shinji Watanabe.2016. Clustering profundo: incorporações discriminativas para segmentação e separação.Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP) (2016), 31–35.
- Andrew Hines, Eoin Gillen, Damien Kelly, Jan Skoglund, Anil C. Kokaram e Naomi Harte. 2015. ViSQOLAudio, uma métrica objetiva de qualidade de áudio para codecs de baixa taxa de bits. Journal of the Acoustical Society of America, Vol. 137, No. 6 (2015), EL449–55.
- Andrew Hines e Naomi Harte. 2012. Predição da inteligibilidade da fala medida usando um índice de similaridade de gráfico neural.Speech Communication 54 No. 2 (2012), 306–320. DOI: http://dx.doi.org/10.1016/j.speccom.2011.09.004
- Ken Hoover, Sourish Chaudhuri, Caroline Pantofaru, Malcolm Slaney e Ian Sturdy. 2017. Enfrentando o som: fundindo sinais de áudio e visuais em vídeo para identificar alto-falantes. CoRR abs/1706.00079 (2017).
- Jen-Cheng Hou, Syu-Siang Wang, Ying-Hui Lai, Jen-Chun Lin, Yu Tsao, Hsiu-Wen Chang e Hsin-Min Wang. 2018. Audiovisão usando redes neurais convolucionais profundas multimodais, aprimoramento de fala. "IEEE Transações sobre Tópicos Emergentes em Inteligência Computacional, Vol. 2, Nº 2 (2018), 117–128.
- Yongtao Hu, Jimmy SJ Ren, Jingwen Dai, Chang Yuan, Li Xu e Wenping Wang. 2015. Nomenclatura detalhada de palestrantes multimodais. Anais da 23ª conferência internacional ACM sobre multimídia. ACM, 1107–1110.
- Sergey Ioffe e Christian Szegedy. 2015. Normalização em lote: acelerando o treinamento de rede profunda reduzindo a mudança interna de covariáveis. Conferência Internacional sobre aprendizado de máquina.
- Yusuf Isik, Jonathan Le Roux, Zhuo Chen, Shinji Watanabe e John R Hershey. 2016. Separação monofônica de vários alto-falantes usando clustering profundo. Interspeech (2016), 545–549.
- Faheem Khan. 2016. Separação de alto-falantes audiovisuais. Dissertação de doutorado. Universidade de East Anglia.
- Wei Ji Ma, Xiang Zhou, Lars A. Ross, John J. Foxe e Lucas C. Parra. 2009. Reconhecimento lexical auxiliado pela interpretação bayesiana de espaços de características de alta dimensão em ruído moderado. PLoS ONE Volume 4 (2009), 233 –252.
- Josh H McDermott. 2009. O problema do coquetel. Biologia Atual 19 No. 22 (2009), R1024 – R1027.
- Gianluca Monaci. 2011. Desenvolvimento de localização visual de alto-falante para áudio em tempo real. Conferência de processamento de sinais, 19ª Europa 2011. IEEE, 1055–1059.
- Youssef Mroueh, Etienne Marcheret e Vaibhava Goel. 2015. Aprendizado multimodal profundo para reconhecimento de fala audiovisual. Em 2015, Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP). IEEE, 2130–2134.
- Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee e Andrew Y. Ng. 2011. Aprendizado profundo multimodal. Em ICML.
- Andrew Owens e Alexei A Efros.2018. Análise de cena audiovisual usando recursos multissensoriais autosupervisionados. (2018).
- Eric K. Patterson, Sabri Gurbuz, Zekeriya Tufekci e John N. Gowdy. 2002. "Alto-falantes móveis, estudo de recursos independentes de alto-falante e resultados de linha de base no CUAVE Multimodal Speech Corpus". Eurasian Journal of Advanced Signal Processing Volume 2002 (2002) , 1189–1201.
- Jie Pu, Yannis Panagakis, Stavros Petridis e Maja Pantic. 2017. Localização e separação de objetos audiovisuais usando classificação baixa e esparsidade. Em 2017, Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP). IEEE, 2901–2905.
- Bertrand Rivet, Wenwu Wang, Syed M. Naqvi e Jonathon A. Chambers. 2014. Separação audiovisual de alto-falantes: uma visão geral dos principais métodos.IEEE Journal of Signal Processing 31 (2014), 125–134.
- Antony W Rix, John G Beerends, Michael P Hollier e Andries P Hekstra. 2001. Avaliação Perceptual da Qualidade da Fala (PESQ) - Uma Nova Abordagem para Avaliação da Qualidade da Fala de Redes Telefônicas e Codecs. Acústica, Processamento de Fala e Sinal "2001 Internacional Conferência (ICASSP'01). IEEE, 749–752.
- Ethan M Rudd, Manuel Günther e Terrance E Boult. 2016. Moon: Uma rede de otimização de objetivos mistos para reconhecimento de atributos faciais. Conferência Europeia sobre Visão Computacional. Springer, 19–35.
- JS Garofolo, Lori Lamel, WM Fisher, Jonathan Fiscus, D S. Pallett, NL Dahlgren e V Zue. 1992. O TIMIT Speech Corpus. (1992).
- Lei Sun, Jun Du, Li-Rong Dai e Chin-Hui Lee. 2017. Aprimoramento de fala de aprendizagem profunda multiobjetivo baseado em LSTM-RNN. no HSCMA.
- Cees H Taal, Richard C Hendriks, Richard Heusdens e Jesper Jensen. 2010. Medidas de inteligibilidade objetiva de curto prazo para fala ruidosa ponderada por frequência e tempo. Em 2010 Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP). IEEE, 4214–4217.
- Emmanuel Vincent, Jon Barker, Shinji Watanabe, Jonathan Le Roux, Francesco Nesta e Marco Matassoni.2013. Segundo desafio "The Bell" de separação e reconhecimento de fala: conjuntos de dados, tarefas e linhas de base. Em 2013 Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP). IEEE, 126–130.
- E. Vincent, R. Gribonval e C. Fevotte.2006. Medições de desempenho para separação cega de fontes de áudio. Transações em Processamento de Áudio, Fala e Linguagem, Vol. 14, Nº 4 (2006), 1462–1469.
- DeLiang Wang e Jitong Chen. 2017. Separação de fala supervisionada com base em aprendizagem profunda: uma pesquisa. CoRR abs/1708.07524 (2017).
- Yuxuan Wang, Arun Narayanan e DeLiang Wang. 2014. Objetivos de treinamento para separação supervisionada de fala. Transações IEEE/ACM em processamento de áudio, fala e linguagem (TASLP) 22 No. 12 (2014), 1849–1858.
- Ziteng Wang, Xiaofei Wang, Xu Li, Qiang Fu e Yonghong Yan. 2016. Oracle Performance Investigation of Ideal Masks. Na IWAENC.
- Felix Weninger, Hakan Erdogan, Shinji Watanabe, Emmanuel Vincent, Jonathan Le Roux, John R. Hershey e Björn W. Schuller.2015. Aprimoramento de fala usando redes neurais recorrentes LSTM e sua aplicação ao ASR robusto de ruído. Na LVA/ICA.
- Dong Yu, Morten Kolbæk, Zheng-Hua Tan e Jesper Jensen.2017. Treinamento invariante à permutação de modelos profundos para separação de fala de vários alto-falantes independente de locutor. Na Conferência Internacional IEEE sobre Acústica, Fala e Processamento de Sinais (ICASSP) (2017), 241–245.
- Matthew D Zeiler e Rob Fergus.2014. Visualizando e compreendendo redes convolucionais. Na Conferência Europeia de Visão Computacional. Springer, 818–833.
- Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott e Antonio Torralba. 2018. O Som dos Pixels. (2018).
- Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva e Antonio Torralba.2014. Detectores de objetos de ocorrência em CNNs de cena profunda. pré-impressão arXiv arXiv:1412.6856 (2014).
REFERÊNCIAS
- T. Afouras, JS Chung e A. Zisserman. 2018. A conversa: aprimoramento profundo da fala audiovisual. Em arXiv:1804.04121.
- Anna Llagostera Casanovas, Gianluca Monaci, Pierre Vandergheynst e Rémi Gribonval. 2010. Separação cega de fontes audiovisuais baseada em representações redundantes esparsas. Transações IEEE em Multimídia 12, 5 (2010), 358–371.
- E Colin Cherry. 1953. Algumas experiências de reconhecimento de fala, com uma e com duas orelhas. O Jornal da Sociedade Acústica da América 25, 5 (1953), 975–979.
- Joon Son Chung, Andrew W. Sênior, Oriol Vinyals e Andrew Zisserman. 2016. Frases de leitura labial em estado selvagem. CoRR abs/1611.05358 (2016).
- Forrester Cole, David Belanger, Dilip Krishnan, Aaron Sarna, Inbar Mosseri e William T Freeman. 2016. Sintetizando rostos normalizados a partir de características de identidade facial. Em CVPR'17.
- Pierre Comon e Christian Jutten. 2010. Manual de separação cega de fontes: análise e aplicações de componentes independentes. Imprensa acadêmica.
- Masood Delfarah e DeLiang Wang. 2017. Recursos para separação de fala monoaural baseada em mascaramento em condições reverberantes. Transações IEEE/ACM em processamento de áudio, fala e linguagem 25 (2017), 1085–1094.
- Ariel Ephrat, Tavi Halperin e Shmuel Peleg. 2017. Reconstrução de fala aprimorada de vídeo silencioso. No Workshop ICCV 2017 sobre Visão Computacional para Mídia Audiovisual.
- Hakan Erdogan, John R. Hershey, Shinji Watanabe e Jonathan Le Roux. 2015. Separação de fala sensível à fase e com reconhecimento aprimorado usando redes neurais recorrentes profundas. Conferência Internacional IEEE sobre Acústica, Processamento de Fala e Sinais (ICASSP) (2015).
- Weijiang Feng, Naiyang Guan, Yuan Li, Xiang Zhang e Zhigang Luo. 2017. Reconhecimento de fala audiovisual com redes neurais recorrentes multimodais. Em Redes Neurais (IJCNN), Conferência Conjunta Internacional de 2017 sobre. IEEE, 681–688.
- Aviv Gabbay, Ariel Ephrat, Tavi Halperin e Shmuel Peleg. 2018. Vendo através do ruído: separação e aprimoramento do alto-falante usando fala derivada visualmente. Conferência Internacional IEEE sobre Acústica, Processamento de Fala e Sinais (ICASSP) (2018).
- Aviv Gabbay, Asaph Shamir e Shmuel Peleg. 2017. Aprimoramento visual da fala usando treinamento invariante de ruído. Pré-impressão do arXiv arXiv:1711.08789 (2017).
- R. Gao, R. Feris e K. Grauman. 2018. Aprendendo a separar sons de objetos assistindo a vídeos sem rótulo. Pré-impressão do arXiv arXiv:1804.01665 (2018).
- Jort F. Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal e Marvin Ritter. 2017. Conjunto de áudio: uma ontologia e um conjunto de dados rotulados por humanos para eventos de áudio. Em Proc. IEEE ICASSP 2017.
- Elana Zion Golumbic, Gregory B Cogan, Charles E. Schroeder e David Poeppel. 2013. A entrada visual melhora o rastreamento seletivo do envelope de fala no córtex auditivo em um “coquetel”. The Journal of neuroscience: o jornal oficial da Society for Neuroscience 33 4 (2013), 1417–26.
- Naomi Harte e Eoin Gillen. 2015. TCD-TIMIT: Um corpus audiovisual de fala contínua. Transações IEEE em Multimídia 17, 5 (2015), 603–615.
- David F. Harwath, Antonio Torralba e James R. Glass. 2016. Aprendizagem não supervisionada da linguagem falada com contexto visual. No NIPS.
- John Hershey, Hagai Attias, Nebojsa Jojic e Trausti Kristjansson. 2004. Modelos gráficos audiovisuais para processamento de fala. Na Conferência Internacional IEEE sobre Acústica, Processamento de Fala e Sinais (ICASSP).
- John R Hershey e Michael Casey. 2002. Separação de som audiovisual por meio de modelos ocultos de Markov. Em Avanços em Sistemas de Processamento de Informação Neural. 1173–1180.
- John R. Hershey, Zhuo Chen, Jonathan Le Roux e Shinji Watanabe. 2016. Clustering profundo: incorporações discriminativas para segmentação e separação. Conferência Internacional IEEE sobre Acústica, Processamento de Fala e Sinais (ICASSP) (2016), 31–35.
- Andrew Hines, Eoin Gillen, Damien Kelly, Jan Skoglund, Anil C. Kokaram e Naomi Harte. 2015. ViSQOLAudio: Uma métrica objetiva de qualidade de áudio para codecs de baixa taxa de bits. O Jornal da Sociedade Acústica da América 137 6 (2015), EL449–55.
- Andrew Hines e Naomi Harte. 2012. Predição da inteligibilidade da fala usando uma medida de índice de similaridade de neurogramas. Fala Comun. 54, 2 (fevereiro de 2012), 306–320. DOI: http://dx.doi.org/10.1016/j.speccom.2011.09.004
- Ken Hoover, Sourish Chaudhuri, Caroline Pantofaru, Malcolm Slaney e Ian Sturdy. 2017. Dando um rosto à voz: fundindo sinais de áudio e visuais em um vídeo para determinar os alto-falantes. CoRR abs/1706.00079 (2017).
- Jen-Cheng Hou, Syu-Siang Wang, Ying-Hui Lai, Jen-Chun Lin, Yu Tsao, Hsiu-Wen Chang e Hsin-Min Wang. 2018. Aprimoramento de fala audiovisual usando redes neurais convolucionais profundas multimodais. Transações IEEE sobre Tópicos Emergentes em Inteligência Computacional 2, 2 (2018), 117–128.
- Yongtao Hu, Jimmy SJ Ren, Jingwen Dai, Chang Yuan, Li Xu e Wenping Wang. 2015. Nomenclatura profunda de alto-falantes multimodais. Nos Anais da 23ª Conferência Internacional ACM sobre Multimídia. ACM, 1107–1110.
- Sergey Ioffe e Christian Szegedy. 2015. Normalização em lote: acelerando o treinamento profundo da rede reduzindo a mudança interna de covariáveis. No ICML.
- Yusuf Isik, Jonathan Le Roux, Zhuo Chen, Shinji Watanabe e John R Hershey. 2016. Separação de vários alto-falantes de canal único usando cluster profundo. Interfala (2016), 545–549.
- Faheem Khan. 2016. Separação de alto-falantes audiovisuais. Ph.D. Dissertação. Universidade de East Anglia.
- Wei Ji Ma, Xiang Zhou, Lars A. Ross, John J. Foxe e Lucas C. Parra. 2009. A leitura labial auxilia no reconhecimento de palavras mais em ruído moderado: uma explicação bayesiana usando espaço de recursos de alta dimensão. PLoS ONE 4 (2009), 233 – 252.
- Josh H. McDermott. 2009. O problema do coquetel. Biologia Atual 19, 22 (2009), R1024 – R1027.
- Gianluca Monaci. 2011. Rumo à localização de alto-falantes audiovisuais em tempo real. Na Conferência de Processamento de Sinais, 2011 19º Europeu. IEEE, 1055–1059.
- Youssef Mroueh, Etienne Marcheret e Vaibhava Goel. 2015. Aprendizagem multimodal profunda para reconhecimento de fala audiovisual. Em Acústica, Processamento de Fala e Sinais (ICASSP), Conferência Internacional IEEE 2015 sobre. IEEE, 2130–2134.
- Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee e Andrew Y. Ng. 2011. Aprendizado profundo multimodal. No ICML.
- Andrew Owens e Alexei A Efros. 2018. Análise de cena audiovisual com recursos multissensoriais autosupervisionados. (2018).
- Eric K. Patterson, Sabri Gurbuz, Zekeriya Tufekci e John N. Gowdy. 2002. Moving-Talker, estudo de recursos independentes de locutor e resultados de linha de base usando o CUAVE Multimodal Speech Corpus. EURASIP J. Adv. Assinatura. Processo. 2002 (2002), 1189–1201.
- Jie Pu, Yannis Panagakis, Stavros Petridis e Maja Pantic. 2017. Localização e separação de objetos audiovisuais usando classificação baixa e dispersão. Em Acústica, Processamento de Fala e Sinais (ICASSP), Conferência Internacional IEEE 2017 sobre. IEEE, 2901–2905.
- Bertrand Rivet, Wenwu Wang, Syed M. Naqvi e Jonathon A. Chambers. 2014. Separação de fontes de fala audiovisual: uma visão geral das principais metodologias. Revista IEEE Signal Processing 31 (2014), 125–134.
- Antony W Rix, John G Beerends, Michael P Hollier e Andries P Hekstra. 2001. Avaliação perceptiva da qualidade da fala (PESQ) - um novo método para avaliação da qualidade da fala de redes telefônicas e codecs. Em Acústica, Fala e Processamento de Sinais, 2001. Procedimentos.(ICASSP'01). Conferência Internacional IEEE de 2001 sobre, Vol. 2. IEEE, 749–752.
- Ethan M Rudd, Manuel Günther e Terrance E Boult. 2016. Moon: Uma rede de otimização de objetivo misto para o reconhecimento de atributos faciais. Na Conferência Europeia sobre Visão Computacional. Springer, 19–35.
- JS Garofolo, Lori Lamel, WM Fisher, Jonathan Fiscus, DS Pallett, NL Dahlgren e V Zue. 1992. TIMIT Corpus de fala contínua acústica-fonética. (11 1992).
- Lei Sun, Jun Du, Li-Rong Dai e Chin-Hui Lee. 2017. Aprendizado profundo de múltiplos alvos para aprimoramento de fala baseado em LSTM-RNN. No HSCMA.
- Cees H Taal, Richard C Hendriks, Richard Heusdens e Jesper Jensen. 2010. Uma medida de inteligibilidade objetiva de curto prazo para fala ruidosa ponderada por frequência e tempo. Em Acoustics Speech and Signal Processing (ICASSP), Conferência Internacional IEEE 2010 sobre. IEEE, 4214–4217.
- Emmanuel Vincent, Jon Barker, Shinji Watanabe, Jonathan Le Roux, Francesco Nesta e Marco Matassoni. 2013. O segundo desafio de separação e reconhecimento de fala 'chime': conjuntos de dados, tarefas e linhas de base. Conferência Internacional IEEE 2013 sobre Acústica, Fala e Processamento de Sinais (2013), 126–130.
- E. Vincent, R. Gribonval e C. Fevotte. 2006. Medição de desempenho na separação cega de fontes de áudio. Trad. Áudio, Fala e Lang. Processo. 14, 4 (2006), 1462–1469.
- DeLiang Wang e Jitong Chen. 2017. Separação de fala supervisionada com base em aprendizado profundo: uma visão geral. CoRR abs/1708.07524 (2017).
- Yuxuan Wang, Arun Narayanan e DeLiang Wang. 2014. Sobre metas de treinamento para separação supervisionada da fala. Transações IEEE/ACM em processamento de áudio, fala e linguagem (TASLP) 22, 12 (2014), 1849–1858.
- Ziteng Wang, Xiaofei Wang, Xu Li, Qiang Fu e Yonghong Yan. 2016. Investigação de desempenho do Oracle das máscaras ideais. Em IWAENC.
- Felix Weninger, Hakan Erdogan, Shinji Watanabe, Emmanuel Vincent, Jonathan Le Roux, John R. Hershey e Björn W. Schuller. 2015. Aprimoramento de fala com redes neurais recorrentes LSTM e sua aplicação para ASR robusto a ruído. Em LVA/ICA.
- Dong Yu, Morten Kolbæk, Zheng-Hua Tan e Jesper Jensen. 2017. Treinamento invariante de permutação de modelos profundos para separação de fala multi-locutor independente de locutor. Conferência Internacional IEEE sobre Acústica, Processamento de Fala e Sinais (ICASSP) (2017), 241–245.
- Matthew D Zeiler e Rob Fergus. 2014. Visualizando e compreendendo redes convolucionais. Na conferência europeia sobre visão computacional. Springer, 818-833.
- Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott e Antonio Torralba. 2018. O Som dos Pixels. (2018).
- Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva e Antonio Torralba. 2014. Detectores de objetos emergem em cenas profundas. pré-impressão arXiv arXiv:1412.6856 (2014).
Uma medida objetiva para avaliar a qualidade da separação
A.1 Relação sinal-ruído (SDR)
A relação sinal-distorção (SDR), introduzida por Vincent et al. em 2006, é uma de uma série de métricas usadas para avaliar algoritmos de separação cega de fonte de áudio (BASS), onde o sinal da fonte original existe como um fato básico. Essas métricas são baseadas na decomposição de cada sinal de fonte estimado na parte da fonte verdadeira (s_target) e nos termos de erro correspondentes à interferência (e_interf), ruído aditivo (e_noise) e artefatos induzidos por algoritmos (e_artif).
SDR é a pontuação mais geral e costuma ser usada para relatar o desempenho de algoritmos de separação de fala. É medido em decibéis (dB) e é definido da seguinte forma:
SDR : = 10 ⋅ log 10 ( ∣ ∣ S alvo ∣ ∣ 2 ∣ ∣ einterf + enoise + eartif ∣ ∣ 2 ) (2) SDR:=10\cdot \ log_{10}(\frac{||S_{alvo}||^{2}}{||e_{interf}+e_{ruído}+e_{artif}||^{2}})\tag{ 2}SDR _ _:=10⋅ei _10(∣∣ eem t e f+enão , eu sei+ea r t i f∣ ∣2∣∣S _alvo _ _ _ _ _∣ ∣2)( 2 )
Remetemos o leitor ao artigo original para obter detalhes sobre a decomposição do sinal em suas partes componentes. Encontramos uma boa correlação entre esta métrica e a quantidade de ruído residual após a separação.
A.2 Monitor objetivo de qualidade de voz virtual (ViSQOL)
O Virtual Voice Quality Objective Listener (ViSQOL) é um modelo objetivo de qualidade de fala proposto por Hines et al. [2015]. Esta métrica modela a percepção da qualidade da fala humana usando uma medida de similaridade espectral-temporal entre sinais de fala de referência (r) e degradados (d) e é baseada no Neurogram Similarity Index Measure (NSIM) [Hines e Harte 2012]. NSIM é definido da seguinte forma:
NSIM ( r , d ) = 2 μ r μ d + C 1 μ r 2 + μ d 2 + C 1 ⋅ σ rd + C 2 σ r σ d + C 2 (3) NSIM(r , d)=\frac{2\mu_{r}\mu_{d}+C_{1}}{\mu_{r}^{2}+\mu^{2}_{d}+C_{1} } \cdot\frac{\sigma_{rd}+C_{2}}{\sigma_{r}\sigma_{d}+C_{2}}\tag{3}X eu estou ( r ,e )=euR2+eud2+C12 metrosReud+C1⋅pRpd+C2prd _+C2( 3 )
Aqui, µs e σs são a média e o coeficiente de correlação entre o sinal de referência e o sinal degradado, respectivamente, calculados entre os espectrogramas. No ViSQOL, o NSIM é calculado nos blocos espectrais do sinal de referência e seus blocos correspondentes do sinal degradado. O algoritmo então agrega e converte as pontuações NSIM em uma pontuação média de opinião (MOS) entre 1 e 5.
DR é a pontuação mais geral e costuma ser usada para relatar o desempenho de algoritmos de separação de fala. É medido em decibéis (dB) e é definido da seguinte forma:
SDR : = 10 ⋅ log 10 ( ∣ ∣ S alvo ∣ ∣ 2 ∣ ∣ einterf + enoise + eartif ∣ ∣ 2 ) (2) SDR:=10\cdot \ log_{10}(\frac{||S_{alvo}||^{2}}{||e_{interf}+e_{ruído}+e_{artif}||^ {2}})\tag{ 2}SDR _ _:=10⋅ei _10(∣∣ eem t e f+enão , eu sei+ea r t i f∣ ∣2∣∣S _alvo _ _ _ _ _∣ ∣2)( 2 )
Remetemos o leitor ao artigo original para obter detalhes sobre a decomposição do sinal em suas partes componentes. Encontramos uma boa correlação entre esta métrica e a quantidade de ruído residual após a separação.
A.2 Monitor objetivo de qualidade de voz virtual (ViSQOL)
O Virtual Voice Quality Objective Listener (ViSQOL) é um modelo objetivo de qualidade de fala proposto por Hines et al. [2015]. Esta métrica modela a percepção da qualidade da fala humana usando uma medida de similaridade espectral-temporal entre sinais de fala de referência (r) e degradados (d) e é baseada no Neurogram Similarity Index Measure (NSIM) [Hines e Harte 2012]. NSIM é definido da seguinte forma:
NSIM ( r , d ) = 2 μ r μ d + C 1 μ r 2 + μ d 2 + C 1 ⋅ σ rd + C 2 σ r σ d + C 2 (3) NSIM(r , d)=\frac{2\mu_{r}\mu_{d}+C_{1}}{\mu_{r}^{2}+\mu^{2}_{d}+C_{1} } \cdot\frac{\sigma_{rd}+C_{2}}{\sigma_{r}\sigma_{d}+C_{2}}\tag{3}X eu estou ( r ,e )=euR2+eud2+C12 metrosReud+C1⋅pRpd+C2prd _+C2( 3 )
Aqui, µs e σs são a média e o coeficiente de correlação entre o sinal de referência e o sinal degradado, respectivamente, calculados entre os espectrogramas. No ViSQOL, o NSIM é calculado nos blocos espectrais do sinal de referência e seus blocos correspondentes do sinal degradado. O algoritmo então agrega e converte as pontuações NSIM em uma pontuação média de opinião (MOS) entre 1 e 5.
https://cloud.google.com/vision/ ↩︎
Essas misturas modelam bem os tipos de perturbações em nosso conjunto de dados, que normalmente envolvem um único orador sendo perturbado por sons não falados, como aplausos do público ou música de abertura. ↩︎
https://support.google.com/youtube/answer/6373554?hl=en ↩︎
Usamos uma duração de 200 ms para cobrir a faixa típica de duração do fonema: 30-200 ms. ↩︎
Encaminhamos os leitores ao material suplementar para verificar se nossos resultados de separação de fala em vídeos não ocluídos, que consideramos "corretos" neste exemplo, são realmente precisos. ↩︎