O artigo anterior apresentou, respectivamente, como o ES autodesenvolvido, forte consistência e multiatividade , e como melhorar o potencial de desempenho do ES . Como o volume diário de gravação de logs do Didi ES é da ordem de 5 PB a 10 PB, a pressão de gravação e os custos de negócios são altos. Para melhorar o desempenho de gravação do ES, permitimos que o ES suporte o algoritmo de compactação ZSTD. Este artigo se expande em Didi em detalhes.Pensando e praticando o algoritmo de compressão ZSTD.
// Plano de fundo //
ES fornece recursos externos de recuperação de dados por meio de índices (Índice), que são unidades lógicas usadas para organizar e armazenar dados. Cada índice consiste em vários fragmentos, e cada fragmento é um índice Lucene, que pode ser armazenado e processado em paralelo em diferentes nós para melhorar o desempenho e a escalabilidade. Cada fragmento consiste em um conjunto de arquivos de segmento (segmento), que são unidades menores de armazenamento e pesquisa no fragmento, e são um conjunto de arquivos físicos que contêm o índice invertido (o relacionamento de mapeamento entre termos e IDs de documentos) necessário para recuperação) e armazenamento de documentos (valores de campos e outros metadados), conforme mostra a figura a seguir:
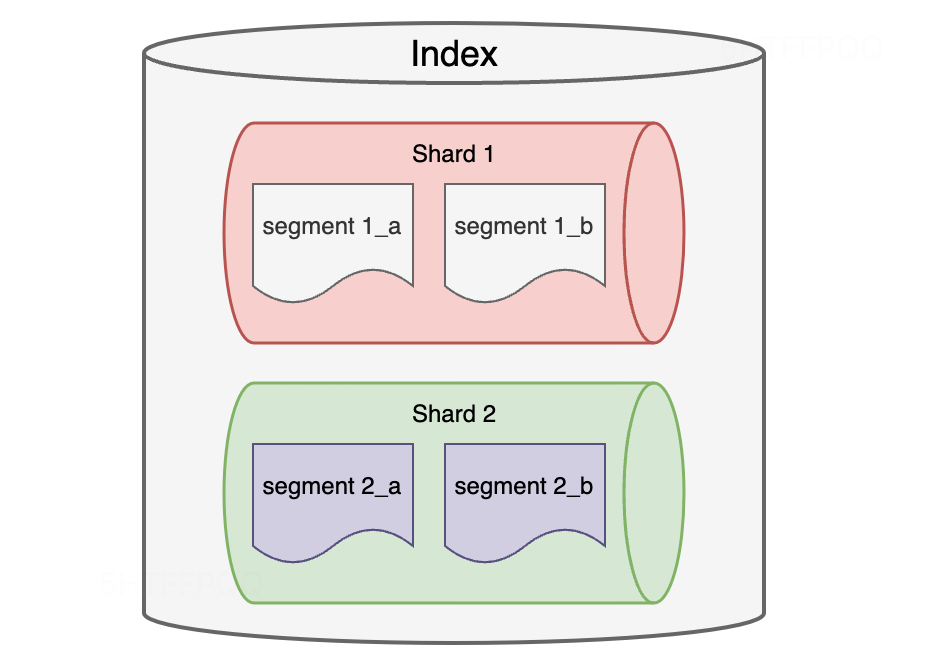
Modelo de dados ES
Como mecanismo de indexação subjacente do ES, o Lucene fornece recursos flexíveis de recuperação de dados, mas também causa sério uso de CPU e armazenamento. Com o objetivo de reduzir custos e aumentar a eficiência, no primeiro semestre de 2023, a equipe ES lançou um projeto especial de otimização da codificação de compressão Lucene para reduzir os recursos ocupados por uma unidade de Documento, melhorando o algoritmo de compressão da camada de armazenamento. Este artigo descreve o arquivo de índice subjacente do ES e apresenta a otimização da codificação de compactação de armazenamento Lucene.
// Introdução ao arquivo de índice Lucene //
O projeto de otimização de codificação de compactação do ES envolve o armazenamento de arquivos subjacente do Lucene. O índice Lucene consiste em um conjunto de segmentos. Cada segmento contém uma série de arquivos. Os principais tipos de arquivo são os seguintes:
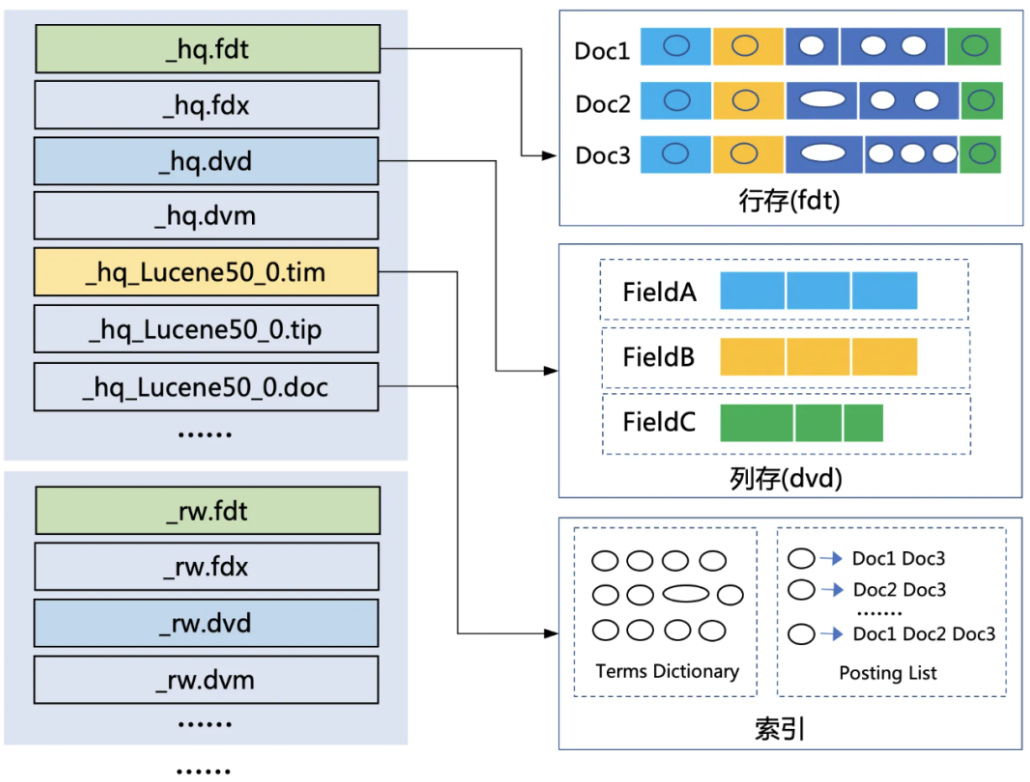
Arquivos de armazenamento de linha: incluindo arquivos de armazenamento de texto original e arquivos de índice de texto original. O arquivo de armazenamento de texto original, ou seja, o arquivo .fdt. Os dados originais gravados pelo usuário são armazenados neste arquivo. Devido à sua grande proporção, para economizar armazenamento, Lucene suporta compactação LZ4 e compactação ZIP no armazenamento de texto original; o arquivo de índice de texto original, ou seja, arquivo .fdx, armazena os dados do texto original As informações de localização no arquivo de armazenamento de texto original estabelecem um link entre o ID do documento e o texto original para suportar acesso e posicionamento rápidos.
Arquivo de armazenamento de coluna: arquivo .dvd, frequentemente usado em alguns mecanismos de análise OLAP. O arquivo de armazenamento de coluna organiza os dados por coluna, e os mesmos dados da coluna (Campo) em documentos diferentes são armazenados próximos uns dos outros, o que pode acelerar a consulta de análise de agregação de colunas. Ao mesmo tempo, o tipo de cada coluna adjacente é o mesmo e a otimização de codificação uniforme pode ser realizada durante o armazenamento para melhorar a taxa de compactação e reduzir a ocupação do espaço em disco de armazenamento.
Documentos relacionados ao índice: ES depende da segmentação de palavras para gerar um índice invertido, permitindo-lhe ter uma poderosa capacidade de pesquisa de texto completo. Entre os arquivos relacionados ao índice, os arquivos principais incluem: arquivos de dados de dicionário e arquivos de índice invertidos. O arquivo de dados do dicionário, ou seja, o arquivo .tim, pode extrair informações de segmentação de palavras dos dados do usuário e armazená-las no arquivo .tim por meio do tokenizador de índice configurado pelo usuário. As informações do particípio na mesma coluna são armazenadas lado a lado e organizadas por bloco; o arquivo de índice invertido, ou seja, o arquivo .doc, também conhecido como "tabela de zíper invertido", registra a lista de documentos associados a cada particípio , que pode realizar palavras rápidas para documentar a pesquisa invertida.
// Pesquisa e análise do algoritmo de compressão ZSTD //
No cluster online ES, os recursos são relativamente escassos, principalmente no cluster de log. O cluster grava mais e lê menos, e a taxa de uso da CPU é de cerca de 85% durante o período de pico. O desempenho de gravação é seu principal gargalo. Por meio de pesquisas, constatou-se que os arquivos de armazenamento de texto original respondem pela maior proporção, basicamente ultrapassando 30%, e alguns índices chegam a ultrapassar 70%. A partir disso, esclarecemos o foco da compactação do arquivo de índice e da otimização da codificação.
Atualmente, Didi ES usa a versão 7.6.0 online, e a versão Lucene correspondente é 8.4.0. Esta versão suporta duas estratégias de compactação:
BEST_SPEED é o algoritmo de compactação padrão para índices ES, usando compactação LZ4. A velocidade de compactação e descompactação é rápida, o uso da CPU é baixo, mas o efeito de compactação é fraco.
BEST_COMPRESSION, usando compactação ZIP. A velocidade de compactação e descompactação é lenta e o uso da CPU é alto, mas o efeito de compactação é bom.
O algoritmo de compactação do Lucene só tem efeito para o maior arquivo de armazenamento de linha, e outros arquivos são otimizados por codificação personalizada para reduzir o armazenamento. Atualmente, o cluster de log Didi ES adota o algoritmo de compactação BEST_COMPRESSION.Por meio do teste de taxa de compactação ES, verifica-se que no cenário de log, o espaço de armazenamento em disco ocupado pelo mesmo índice usando ZIP é 20% a 40% menor do que aquele de LZ4. No entanto, ao analisar o uso da CPU do cluster de log, pode-se descobrir que a proporção de CPU do módulo de compactação ES é relativamente alta, e alguns clusters de log chegam a ultrapassar 30%, conforme mostrado na figura a seguir:
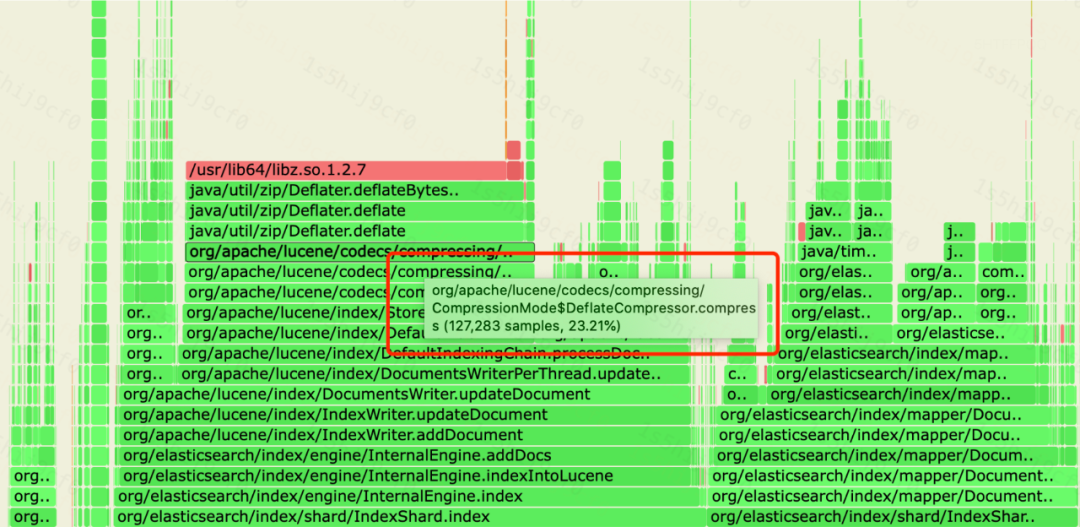
Taxa de perda de CPU
No contexto acima, investigamos o algoritmo de compactação ZSTD.A camada inferior do ZSTD (Zstandard) é implementada com base na codificação FSE, que possui excelente velocidade de compactação e descompactação. A implementação do algoritmo ZSTD foi altamente otimizada e o paralelismo do hardware pode ser totalmente utilizado por meio de conjuntos de instruções como SIMD. Ao mesmo tempo, o processo de codificação depende fortemente de operações de deslocamento para completar a comutação de estado, melhorando assim a velocidade de processamento. ZSTD adota o algoritmo de compactação de dicionário, que pode reduzir significativamente o espaço de armazenamento de dados repetidos e melhorar a taxa de compactação referenciando os itens correspondentes no dicionário. Ao mesmo tempo, o ZSTD adota uma estratégia de compactação multinível, aplica diferentes algoritmos de compactação em diferentes níveis de compactação e pode equilibrar de maneira flexível a velocidade e a taxa de compactação em diferentes cenários de aplicação.
Para verificar seu desempenho, um arquivo de log de 1 GB no Bamai online foi usado para o teste de desempenho de compactação. O teste descobriu que a velocidade de compactação do ZSTD era 4,5 vezes maior que a do ZIP, a velocidade de descompressão era 1,5 vezes maior que a do ZIP, e a taxa de compactação foi quase a mesma, conforme mostrado na figura abaixo. O algoritmo de compactação ZSTD leva em consideração a compactação “rápida” do LZ4 e o “bom efeito” da compactação ZIP.
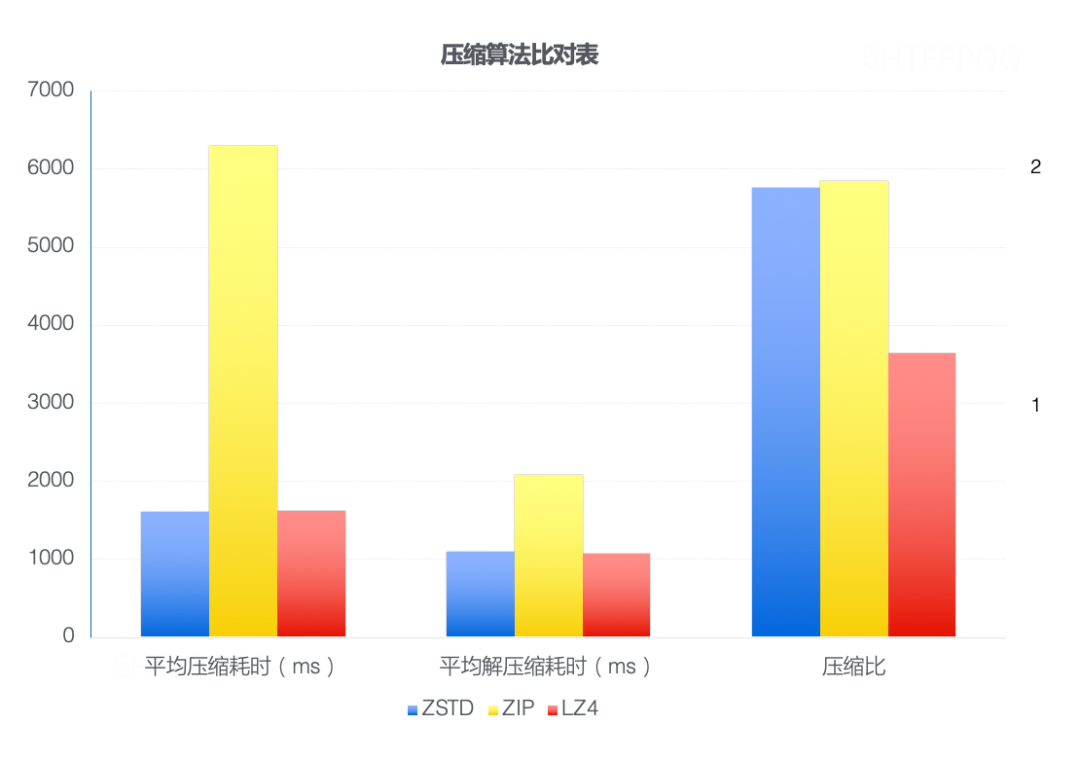
Comparação de algoritmo de compressão
// Algoritmo de compressão ZSTD chegou //
Para concretizar o desembarque do ZSTD em Didi ES, partimos dos seguintes aspectos:
desenvolvimento de código fonte
1. Configuração ES e extensão do motor
ES configura o formato de compactação para cada índice por meio da configuração e precisa oferecer suporte ao formato de compactação ZSTD na configuração ES. ES inicializará um mecanismo para cada fragmento. Diferentes tipos ou estados de fragmentos correspondem a mecanismos diferentes. Por exemplo, o fechamento do índice corresponde ao mecanismo noop e o DCDR corresponde ao mecanismo seguinte do índice. Ele precisa ser abstraído e expandido em diferentes tipos de mecanismos de compressão ZSTD.
2. Extensão Lucene CompressionMode
Lucene é uma biblioteca de mecanismo de pesquisa de texto completo escrita em Java, e o algoritmo ZSTD é implementado com base em C++, então zstd-jni é introduzido no lado Lucene para expandir a capacidade de compactação ZSTD. Ao estender o CompressionMode, personalizando ZStandardDecompressor e ZStandardCompressor para obter compactação e descompactação de dados bloco por bloco.
ajuste de parâmetros
1. Ajuste do tamanho do pedaço
O arquivo de armazenamento de linha é organizado na forma de Chunk, e o tamanho do Chunk geralmente é de dezenas de KB. A versão Didi ES7.6.0 usa a versão Lucene 8.4, o tamanho do pedaço definido pelo algoritmo de compactação LZ4 é 16kb e o algoritmo de compactação ZIP é definido como 60kb. Depois de definir o índice para o formato de compactação ZSTD e importar um lote de dados online, os resultados da compactação são mostrados na tabela.
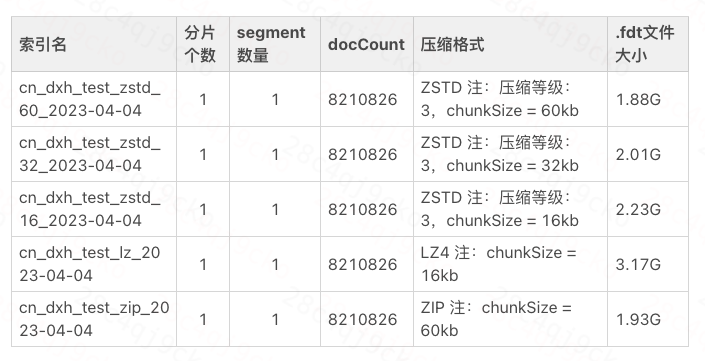
Tabela de comparação de compressão de tamanho de pedaço
Aumentar o ChunkSize pode obter dados de dicionário compartilhados em um intervalo de dados maior, obtendo assim melhores efeitos de compactação. Mas isso também levará a um maior atraso no acesso aleatório e a um aumento adicional no consumo de CPU. Para garantir que não haverá problemas de expansão de dados quando o formato de compactação do índice for alterado para ZSTD posteriormente, o ChunkSize é de 60kb.
2. Ajuste do nível de compressão ZSTD
O ZSTD adota uma estratégia de compactação multinível, que fornece níveis de compactação de 1 a 22. Quanto maior o valor, maior a taxa de compactação, mas quanto mais lenta a velocidade de compactação e descompactação, maior o consumo de CPU. Defina diferentes níveis de compactação, importe dados de teste e os resultados da compactação são mostrados na tabela abaixo:
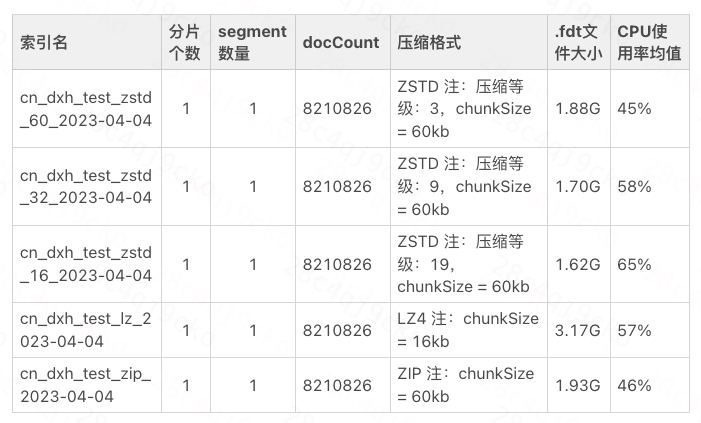
Tabela de comparação de desempenho de nível de compactação
Ao aumentar o nível de compactação, o armazenamento pode ser reduzido. Por exemplo, se o nível de compactação for ajustado para 9, o armazenamento de arquivos .fdt pode ser reduzido em cerca de 10% e o armazenamento geral do índice pode ser reduzido em 5 %. Neste momento, o consumo de CPU é basicamente o mesmo do ZIP.
O cluster de log online ES grava mais e lê menos, e todas as máquinas físicas (discos rígidos SSD) são usadas. A taxa de uso da CPU do cluster excede 80% durante o período de pico, e o nível geral de água do disco do cluster é de cerca de 55 %. A taxa de uso da CPU é o seu gargalo. Portanto, o nível de compactação utilizado é 3, o que atinge um bom equilíbrio entre velocidade e taxa de compactação, podendo reduzir ao máximo o uso da CPU do cluster.
outro
1. Resolva o problema de falha no carregamento de algumas dependências no pacote Lucene. Por exemplo: Lucene usa ivy para gerenciamento de dependências e resolve o problema de que o jar org.restlet.jee não pode ser encontrado no armazém principal do Maven durante o processo de pacote Lucene, introduzindo o repo, conforme mostrado na figura abaixo:
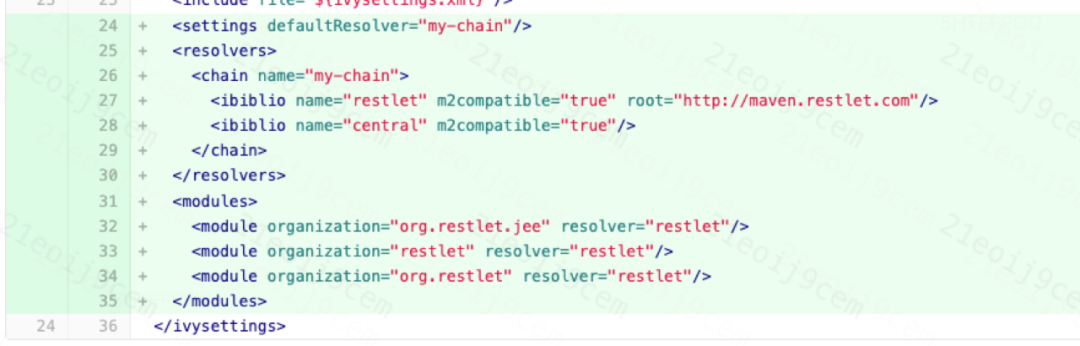
gráfico de importação de dependência ivy
2. Ao pré-inicializar o módulo zstd, o problema de falha ao carregar dinamicamente zstd-jni-jar durante o tempo de execução do ES é resolvido.
3. Ao expandir a capacidade de compactação ZSTD do mecanismo noop, o problema de falha de análise do tipo ZSTD em cenários de fechamento de índice é resolvido.
// efeito on-line //
Após três meses de prática e otimização, a versão ES-ZSTD foi lançada em 16 clusters, e o formato de compactação do índice completo do cluster de log (6w+) e alguns índices de cluster públicos foram alterados para ZSTD. Após o lançamento, todos os logs pico de clusters A redução média no uso da CPU chega a 15% , permitindo que o ES forneça serviços de recuperação de maior desempenho e menor custo. Os principais efeitos são os seguintes:
maior desempenho
1. O efeito online de um cluster de log A
Depois que um cluster de log ES A lançou a versão ES-ZSTD e mudou a compactação de comutação de índice completa para o formato ZSTD, o uso da CPU do cluster durante o período de pico diminuiu 18% e a rejeição de gravação diminuiu 50% ano após ano. -ano.
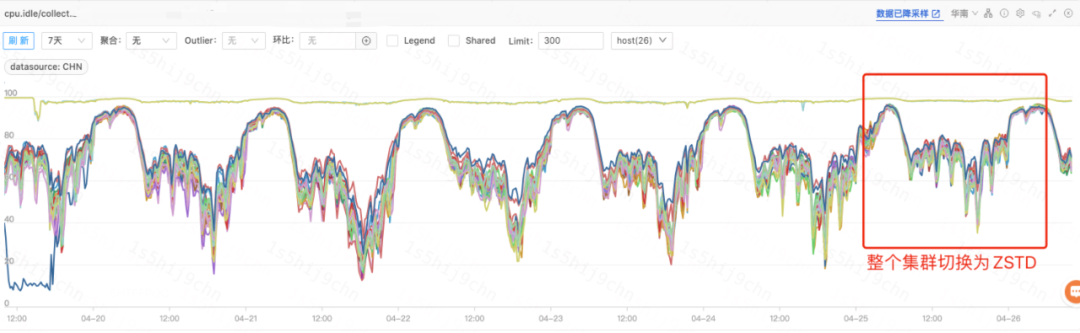
Gráfico de CPU inativa do cluster (cluster A)
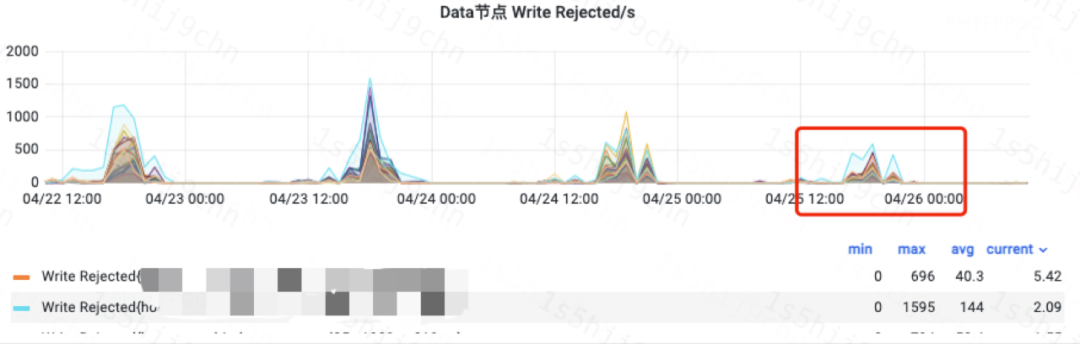
DataNode grava o gráfico de rejeição (cluster A)
2. O efeito de comutação de um índice logarítmico supergrande M
Depois que o formato de compactação M de um índice de log on-line supergrande do ES é alterado de ZIP para ZSTD, o uso da CPU do cluster diminui em 15% e o desempenho de gravação aumenta em 25% quando o número de entradas gravadas permanece o mesmo .
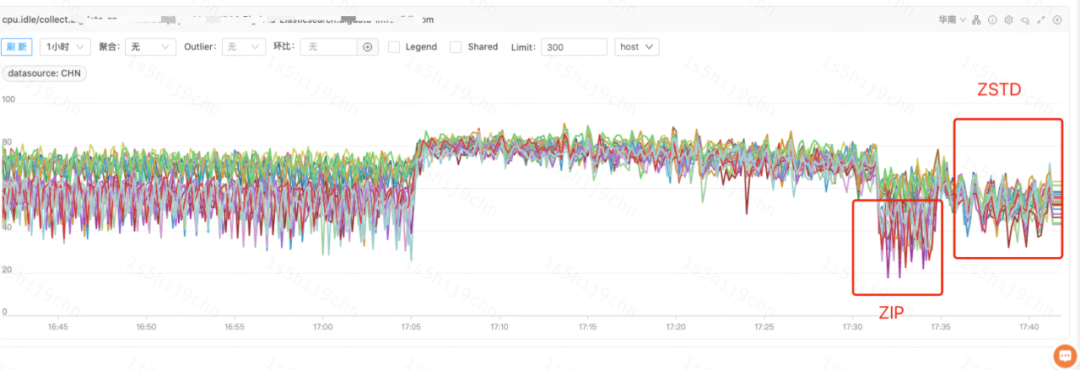
Gráfico de CPU inativa do cluster (cluster B)
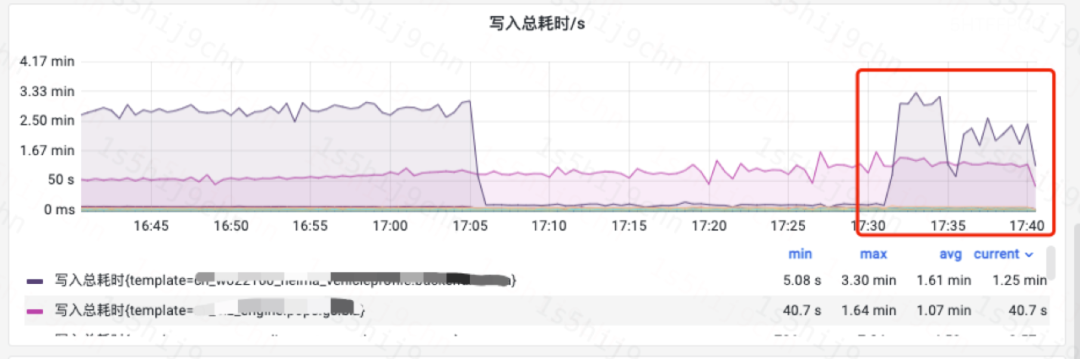
Tempo total de escrita do índice (índice M)
custo mais baixo
1. Mudança de índice de formato de compactação LZ4 para efeito ZSTD
O cluster de log ES ainda possui alguns índices de log compactados pelo LZ4. Depois de mudar esses índices de log para o formato de compactação ZSTD, o armazenamento médio do índice cai 30%, conforme mostrado na figura a seguir:
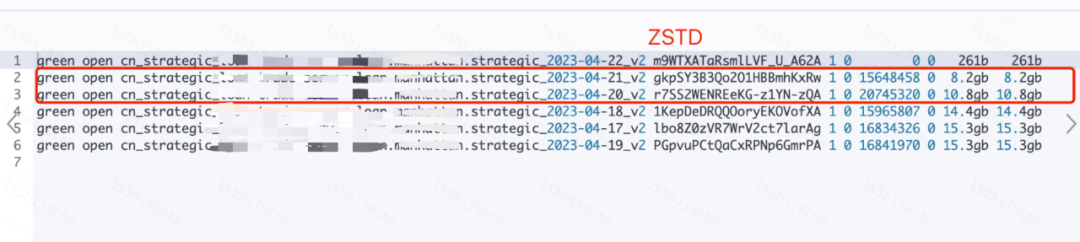
mapa de armazenamento de índice
2. Redução do cluster de log
Depois de mudar o formato de compactação de índice para ZSTD, a CPU do cluster pode ser efetivamente reduzida, para que os recursos do cluster possam ser ajustados. Atualmente, mais de 20 máquinas foram reduzidas e ainda estão off-line.
// Resumo //
ZSTD ajuda ES a fornecer serviços de recuperação de maior desempenho e menor custo. Posteriormente, projetos como separação leitura-gravação e atualização da versão principal do ES serão lançados um após o outro para impulsionar ainda mais o desenvolvimento dos negócios.