- 1. Visão geral do Prometeu
- 2. Instale o servidor Prometheus
- 3. Aprenda PromQL
- 4. Instale o Grafana
- 5. Use o Exportador para coletar indicadores
- 6. Alarme e notificação
- 7. Saiba mais
- Resumir
- Apêndice: O que é um banco de dados de série temporal?
Prometheus é um sistema de monitoramento e alarme de código aberto baseado em banco de dados de séries temporais. Falando em Prometheus, temos que mencionar o SoundCloud, que é uma plataforma de compartilhamento de música online, semelhante ao YouTube para compartilhamento de vídeos, porque eles estão cada vez melhores na estrada de arquitetura de microsserviços. Longe, existem centenas de milhares de serviços e muitas limitações no uso dos sistemas de monitoramento tradicionais StatsD e Graphite.
Assim, em 2012, começaram a desenvolver um novo sistema de monitorização. O autor original do Prometheus é Matt T. Proud, que também ingressou no SoundCloud em 2012. Na verdade, antes de ingressar no SoundCloud, Matt trabalhou no Google. Ele se inspirou no gerenciador de cluster do Google Borg e em seu sistema de monitoramento Borgmon, desenvolveu o código aberto sistema de monitoramento Prometheus, e como muitos projetos do Google, a linguagem de programação utilizada é Go.
Obviamente, o Prometheus, como solução de sistema de monitoramento de arquitetura de microsserviços, também é inseparável dos contêineres. Já em 9 de agosto de 2006, Eric Schmidt propôs pela primeira vez o conceito de computação em nuvem (Cloud Computing) na Search Engine Conference.Nos dez anos seguintes, o desenvolvimento da computação em nuvem foi rápido.
Em 2013, Matt Stine da Pivotal propôs o conceito de nuvem nativa (Cloud Native), que consiste em arquitetura de microsserviços, DevOps e infraestrutura ágil representada por contêineres, ajudando as empresas a entregar software de forma rápida, contínua, confiável e dimensionada.
A fim de unificar as interfaces de computação em nuvem e padrões relacionados, em julho de 2015, surgiu a Cloud Native Computing Foundation (CNCF, Cloud Native Computing Foundation) afiliada à Linux Foundation. O primeiro projeto a aderir ao CNCF foi o Kubernetes do Google, e o Prometheus foi o segundo (2016).
Atualmente, o Prometheus tem sido amplamente utilizado no sistema de monitoramento de clusters Kubernetes.Os alunos interessados na história do Prometheus podem dar uma olhada no discurso do engenheiro do SoundCloud, Tobias Schmidt, na conferência PromCon 2016: A História do Prometheus no SoundCloud.
[1. Visão geral do Prometeu
Podemos encontrar um artigo sobre por que eles precisam desenvolver um novo sistema de monitoramento Prometheus: Monitoramento no SoundCloud no blog oficial do SoundCloud. Neste artigo, eles introduziram que o sistema de monitoramento de que precisam deve atender às quatro características a seguir:
- Um modelo de dados multidimensional, para que os dados possam ser divididos e divididos à vontade, em dimensões como instância, serviço, endpoint e método.
- Simplicidade operacional, para que você possa ativar um servidor de monitoramento onde e quando quiser, mesmo em sua estação de trabalho local, sem configurar um back-end de armazenamento distribuído ou reconfigurar o mundo.
- Coleta de dados escalonável e arquitetura descentralizada, para que você possa monitorar com segurança as muitas instâncias de seus serviços e equipes independentes possam configurar servidores de monitoramento independentes.
- Por fim, uma linguagem de consulta poderosa que aproveita o modelo de dados para gerar alertas significativos (incluindo silenciamento fácil) e gráficos (para painéis e para exploração ad hoc).
Simplificando, são as seguintes quatro características:
- Modelo de dados multidimensionais
- Fácil implantação e manutenção
- Aquisição de dados flexível
- linguagem de consulta poderosa
Na verdade, os dois recursos do modelo de dados multidimensional e da poderosa linguagem de consulta são exatamente o que os bancos de dados de série temporal exigem, portanto, o Prometheus não é apenas um sistema de monitoramento, mas também um banco de dados de série temporal. Então, por que o Prometheus não usa diretamente o banco de dados de série temporal existente como armazenamento de back-end? Isso ocorre porque o SoundCloud não deseja apenas que seu sistema de monitoramento tenha as características de um banco de dados de série temporal, mas também precisa ser muito fácil de implantar e manter.
Olhando para as bases de dados de séries temporais mais populares (ver o apêndice abaixo),elas têm demasiados componentes ou têm pesadas dependências externas.Por exemplo:Druida tem um monte de componentes,incluindo Histórico,MiddleManager,Broker,Coordinator,Overlord,e Router, e também depende do ZooKeeper, armazenamento profundo (HDFS ou S3, etc.), armazenamento de metadados (PostgreSQL ou MySQL), o custo de implantação e manutenção é muito alto. O Prometheus, por outro lado, adota uma arquitetura descentralizada e pode ser implantado de forma independente, sem depender de armazenamento externo distribuído. Você pode construir um sistema de monitoramento em poucos minutos.
Além disso, o método de coleta de dados do Prometheus também é muito flexível. Para coletar os dados de monitoramento do destino, primeiro você precisa instalar o componente de coleta de dados no destino, que é chamado Exportador, que coletará os dados de monitoramento no destino e exporá uma interface HTTP para o Prometheus consultar, e o Prometheus os coletará através de dados Pull, que é diferente do modo Push tradicional.
No entanto, o Prometheus também fornece uma maneira de oferecer suporte ao modo Push, você pode enviar seus dados para o Push Gateway e o Prometheus obtém dados do Push Gateway por meio do Pull. O Exportador atual já pode coletar a maioria dos dados de terceiros, como Docker, HAProxy, StatsD, JMX, etc. Existe uma lista de Exportadores no site oficial.
Além desses quatro recursos, com o desenvolvimento contínuo do Prometheus, ele passou a suportar recursos cada vez mais avançados, como: descoberta de serviços, exibição de gráficos mais rica, uso de armazenamento externo, regras de alarme poderosas e diversos métodos de notificação. A figura a seguir é a arquitetura geral do Prometheus:
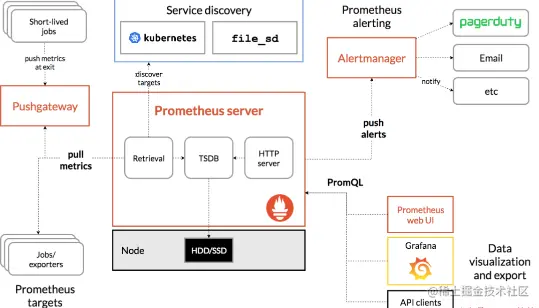
Como pode ser visto na figura acima, o ecossistema Prometheus inclui vários componentes principais: servidor Prometheus, Pushgateway, Alertmanager, Web UI, etc., mas a maioria dos componentes não é necessária, e o componente principal é, obviamente, o servidor Prometheus, que é responsável por coletar e armazenar dados de indicadores, dar suporte a consultas de expressões e gerar alarmes. A seguir instalaremos o servidor Prometheus.
[2. Instale o servidor Prometheus]
O Prometheus pode oferecer suporte a vários métodos de instalação, incluindo Docker, Ansible, Chef, Puppet, Saltstack, etc. As duas maneiras mais fáceis são apresentadas a seguir: uma é usar diretamente o arquivo executável compilado, que funciona imediatamente, e a outra é usar a imagem Docker.
[2.1 Fora da caixa]
Primeiro, obtenha a versão mais recente e o endereço de download do Prometheus na página de download do site oficial. A versão mais recente é 2.4.3 (outubro de 2018). Execute o seguinte comando para baixar e descompactar:
rubi
copiar código
$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz $ tar xvfz prometheus-2.4.3.linux-amd64.tar.gz
Em seguida, mude para o diretório descompactado e verifique a versão do Prometheus:
php
copiar código
$ cd prometheus-2.4.3.linux-amd64 $ ./prometheus --version prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449) build user: root@1e42b46043e9 build date: 20181004-08:42:02 go version: go1.11.1
Execute o servidor Prometheus:
Esse
copiar código
$ ./prometheus --config.file=prometheus.yml
[2.2 Usando imagem Docker]
É mais fácil instalar o Prometheus com Docker, basta executar o seguinte comando:
concha
copiar código
$ sudo docker run -d -p 9090:9090 prom/prometheus
Normalmente, também especificamos a localização do arquivo de configuração:
javascript
copiar código
$ sudo docker run -d -p 9090:9090 \ -v ~/docker/prometheus/:/etc/prometheus/ \ prom/prometheus
Colocamos o arquivo de configuração localmente ~/docker/prometheus/prometheus.yml, o que é conveniente para edição e visualização, e -v montamos o arquivo de configuração local no /etc/prometheus/ local por meio de parâmetros, que é o local padrão do arquivo de configuração carregado pelo prometheus no contêiner. Se não tivermos certeza de onde está o arquivo de configuração padrão, podemos primeiro executar o -v comando acima sem parâmetros e, em seguida, docker inspect verificar os parâmetros padrão do contêiner em tempo de execução nomeando (o parâmetro Args abaixo):
php
copiar código
$ sudo docker inspect 0c [...] "Id": "0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46", "Created": "2018-10-15T22:27:34.56050369Z", "Path": "/bin/prometheus", "Args": [ "--config.file=/etc/prometheus/prometheus.yml", "--storage.tsdb.path=/prometheus", "--web.console.libraries=/usr/share/prometheus/console_libraries", "--web.console.templates=/usr/share/prometheus/consoles" ], [...]
[2.3 Configurando o Prometheus]
Conforme visto nas duas seções acima, o Prometheus possui um arquivo de configuração, que é --config.file especificado por parâmetros, e o formato do arquivo de configuração é YAML. Podemos abrir o arquivo de configuração padrão prometheus.yml para ver o conteúdo interno:
vbnet
copiar código
/etc/prometheus $ cat prometheus.yml > 基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。 > > 项目地址:<https://github.com/YunaiV/onemall> # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
O arquivo de configuração padrão do Prometheus é dividido em quatro blocos:
- bloco global: a configuração global do Prometheus, como
scrape_intervalindicar com que frequência o Prometheus captura dados,evaluation_intervalindicar com que frequência detectar regras de alarme; - bloco de alerta: Em relação à configuração do Alertmanager, veremos isso mais tarde;
- bloco Rule_files: regras de alarme, veremos isso mais tarde;
- Bloco scrape_config: Isso define o alvo a ser copiado pelo Prometheus. Podemos ver que um trabalho chamado job foi configurado por padrão
prometheus. Isso ocorre porque o Prometheus também exporá seus próprios dados de indicador por meio da interface HTTP quando for iniciado, o que equivale a O Prometheus monitora a si mesmo. Embora isso seja inútil quando realmente usamos o Prometheus, podemos usar este exemplo para aprender como usar o Prometheus; podemos visitar para verhttp://localhost:9090/metricsquais indicadores o Prometheus expõe;
3. [Aprendendo PromQL]
Depois de instalar o Prometheus através das etapas acima, podemos agora começar a experimentar o Prometheus. O Prometheus fornece uma UI visual da Web para nossa conveniência, http://localhost:9090/ basta acessá-la diretamente e ela irá para a página Graph por padrão:
Visitar esta página pela primeira vez pode ser complicado. Podemos ver o conteúdo de outros menus primeiro. Por exemplo: Alertas mostra todas as regras de alarme definidas, e Status pode visualizar várias informações de status do Prometheus, incluindo informações de tempo de execução e compilação, comando -Sinalizadores de linha, configuração, regras, alvos, descoberta de serviço, etc.
Na verdade, a página Graph é a função mais poderosa do Prometheus. Aqui podemos usar uma expressão especial fornecida pelo Prometheus para consultar dados de monitoramento. Essa expressão é chamada PromQL (Prometheus Query Language). Através do PromQL, os dados podem ser consultados não apenas na página do Graph, mas também através da API HTTP fornecida pelo Prometheus. Os dados de monitoramento consultados podem ser exibidos em duas formas: lista e gráfico (correspondendo aos dois rótulos Console e Gráfico na figura acima).
Como dissemos acima, o próprio Prometheus também expõe vários indicadores de monitoramento, que também podem ser consultados na página Gráfico, expanda a caixa suspensa ao lado do botão Executar, e você pode ver vários nomes de indicadores, escolhemos um aleatoriamente , por exemplo: , este indicador promhttp_metric_handler_requests_totalindica /metrics o número de visitas, o Prometheus usa esta página para obter seus próprios dados de monitoramento. Os resultados da consulta na guia Console são os seguintes:
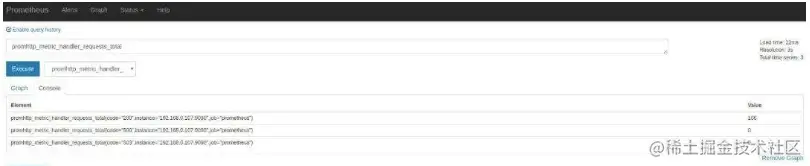
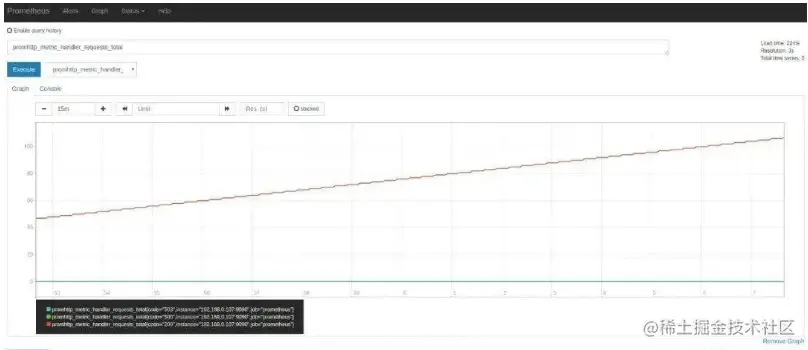
Ao apresentar o arquivo de configuração do Prometheus acima, você pode ver scrape_interval que o parâmetro é 15s, o que significa que o Prometheus visita a página a cada 15s /metrics , então atualizamos a página após 15s, e você pode ver que o valor do índice aumentará automaticamente. Isso pode ser visto mais claramente na tag Graph:
[3.1 Modelo de Dados]
Para aprender PromQL, primeiro precisamos entender o modelo de dados do Prometheus. Um dado do Prometheus consiste em um nome de indicador (métrica) e N rótulos (rótulo, N >= 0), como no exemplo a seguir:
Esse
copiar código
promhttp_metric_handler_requests_total{code="200",instance="192.168.0.107:9090",job="prometheus"} 106
O nome do índice desses dados é promhttp_metric_handler_requests_totale contém três rótulos codee o valor deste registro é 106. Conforme mencionado acima, o Prometheus é um banco de dados de série temporal, e dados com o mesmo índice e o mesmo rótulo formam uma série temporal. Se você entende os bancos de dados de série temporal com o conceito de bancos de dados tradicionais, pode considerar o nome do índice como o nome da tabela, o rótulo como o campo, o carimbo de data e hora como a chave primária e um campo do tipo float64 para representar o valor (todos os valores no Prometheus são armazenados como float64).instancejob
Este modelo de dados é semelhante ao modelo de dados OpenTSDB. Para obter informações detalhadas, consulte o documento do site oficial Modelo de dados. Além disso, em relação à nomenclatura de indicadores e rótulos, o site oficial traz algumas sugestões norteadoras, você pode consultar a Nomenclatura de métricas e rótulos.
Embora os dados armazenados no Prometheus sejam um valor float64, se dividirmos por tipo, podemos dividir os dados do Prometheus em quatro categorias:
- Contador
- Medidor
- Histograma
- Resumo
O contador é utilizado para contar, por exemplo: o número de solicitações, o número de tarefas concluídas e o número de erros ocorridos. Este valor sempre aumentará e não diminuirá. Medidor é um valor geral, que pode ser grande ou pequeno, como: mudanças de temperatura, mudanças no uso de memória. Histograma é um histograma, ou histograma, frequentemente usado para rastrear a escala de eventos, como tempo de solicitação e tamanho de resposta.
Sua particularidade é que pode agrupar o conteúdo gravado e fornecer funções de contagem e soma. O Resumo é muito semelhante ao Histograma e também é usado para rastrear a escala de eventos. A diferença é que ele fornece uma função de quantis que pode dividir os resultados do rastreamento por porcentagem. Por exemplo: o valor do quantil é 0,95, o que significa que 95% dos dados do valor amostral são obtidos. Para obter mais informações, consulte o documento do site oficial Tipos de métricas. Os conceitos de resumo e histograma são fáceis de confundir e pertencem a tipos de indicadores de nível relativamente alto. Você pode consultar a descrição de histogramas e resumos aqui.
Esses quatro tipos de dados são diferenciados apenas no lado do fornecedor do indicador, que é o Exportador mencionado acima. Se você precisar escrever seu próprio Exportador ou expor os indicadores capturados pelo Prometheus no sistema existente, você pode usar as bibliotecas cliente do Prometheus. Neste momento, você precisa considerar os tipos de dados de diferentes indicadores. Se você não precisa implementá-lo sozinho, mas usa diretamente alguns exportadores prontos e, em seguida, verifica os dados relevantes do indicador no Prometheus, então você não precisa prestar muita atenção a isso, mas entender os tipos de dados de O Prometheus também é útil para escrever PromQL correto e razoável.
[3.2 Primeiros passos com PromQL]
Começamos a aprender PromQL a partir de alguns exemplos. O PromQL mais simples é inserir diretamente o nome do índice, como:
festa
copiar código
# 表示 Prometheus 能否抓取 target 的指标,用于 target 的健康检查 up
Esta declaração verificará o status atual de todos os alvos capturados pelo Prometheus, como os seguintes:
Esse
copiar código
up{instance="192.168.0.107:9090",job="prometheus"} 1 up{instance="192.168.0.108:9090",job="prometheus"} 1 up{instance="192.168.0.107:9100",job="server"} 1 up{instance="192.168.0.108:9104",job="mysql"} 0
Você também pode especificar um rótulo para consultar:
Esse
copiar código
up{job="prometheus"}
= Esta forma de escrever é chamada de seletores de vetor instantâneos. Não apenas números podem ser usados aqui , mas também !=, =~, podem ser usados !~, como o seguinte:
Esse
copiar código
up{job!="prometheus"} up{job=~"server|mysql"} up{job=~"192.168.0.107.+"}
=~ Ele é correspondido de acordo com a expressão regular e deve estar em conformidade com a sintaxe de RE2.
Correspondendo aos seletores de vetor instantâneo, há também um seletor chamado seletores de vetor de intervalo, que pode verificar todos os dados dentro de um período de tempo:
css
copiar código
http_requests_total[5m]
Esta instrução verifica o número de solicitações HTTP capturadas em 5 minutos. Observe que o tipo de dados que ela retorna Range vectornão pode ser exibido como um gráfico no Gráfico. Em geral, ele será usado para indicadores do tipo Contador e/ rate() ou irate() funcionar em conjunto (observe a diferença entre taxa e irado).
scs
copiar código
# 计算的是每秒的平均值,适用于变化很慢的 counter # per-second average rate of increase, for slow-moving counters rate(http_requests_total[5m]) # 计算的是每秒瞬时增加速率,适用于变化很快的 counter # per-second instant rate of increase, for volatile and fast-moving counters irate(http_requests_total[5m])
Além disso, PromQL também oferece suporte a count, sum, , e outras operações de agregação min, e também oferece suporte a várias funções integradas , , , , etc. Se você estiver interessado, também podemos comparar o PromQL com o SQL, e você descobrirá que o PromQL tem uma sintaxe mais concisa e maior desempenho de consulta.maxtopkrateabsceilfloor
[3.3 API HTTP]
Não apenas podemos consultar o PromQL na página do gráfico do Prometheus, mas o Prometheus também fornece um método de API HTTP que pode integrar o PromQL de maneira mais flexível em outros sistemas. Por exemplo, Grafana, que será apresentado a seguir, usa a API HTTP do Prometheus para consultar o indicador dados. Na verdade, nossa consulta na página Graph do Prometheus também usa a API HTTP.
Vamos dar uma olhada na documentação oficial da API HTTP do Prometheus, que fornece as seguintes interfaces:
- OBTER /api/v1/query
- OBTER /api/v1/query_range
- OBTER /api/v1/series
- GET /api/v1/label/<label_name>/valores
- OBTER /api/v1/targets
- OBTER /api/v1/rules
- OBTER /api/v1/alerts
- OBTER /api/v1/targets/metadados
- OBTER /api/v1/alertmanagers
- OBTER /api/v1/status/config
- OBTER /api/v1/status/flags
A partir do Prometheus v2.1, várias novas interfaces para gerenciamento de TSDB foram adicionadas:
- POST /api/v1/admin/tsdb/instantâneo
- POST /api/v1/admin/tsdb/delete_series
- POST /api/v1/admin/tsdb/clean_tombstones
[4. Instale o Grafana]
Embora a UI da Web fornecida pelo Prometheus também possa visualizar muito bem as visualizações de diferentes indicadores, esta função é muito simples e adequada apenas para depuração. Para implementar um sistema de monitoramento poderoso, você também precisa de um painel que possa personalizar e exibir diferentes indicadores, e que possa suportar diferentes tipos de métodos de apresentação (gráfico de curva, gráfico de pizza, mapa de calor, TopN, etc.), este é o painel (Dashboard ) função.
Portanto, o Prometheus desenvolveu um sistema de painel PromDash, mas esse sistema foi logo abandonado. O funcionário começou a recomendar o Grafana para visualizar os dados do indicador do Prometheus. Ele pode ser perfeitamente combinado.
Grafana é um sistema de código aberto para visualização de dados de medição em grande escala. Possui funções muito poderosas e uma interface muito bonita. Ele pode ser usado para criar um painel de controle personalizado. Você pode configurar os dados a serem exibidos e o método de exibição no painel. Ele suporta muitas fontes de dados diferentes, como: Graphite, InfluxDB, OpenTSDB, Elasticsearch, Prometheus, etc., e também suporta muitos plug-ins.
Vamos experimentar o uso do Grafana para exibir os dados do indicador Prometheus. Primeiro, vamos instalar o Grafana. Usamos o método mais simples de instalação do Docker:
concha
copiar código
$ docker run -d -p 3000:3000 grafana/grafana
Execute o comando docker acima e o Grafana estará instalado! Você também pode usar outros métodos de instalação, consulte a documentação oficial de instalação. Após a conclusão da instalação, visitamos http://localhost:3000/ a página de login do Grafana e inserimos o nome de usuário e senha padrão (admin/admin).
Para usar o Grafana, o primeiro passo é configurar a fonte de dados e informar ao Grafana onde obter os dados. Clicamos em Adicionar fonte de dados para entrar na página de configuração da fonte de dados:
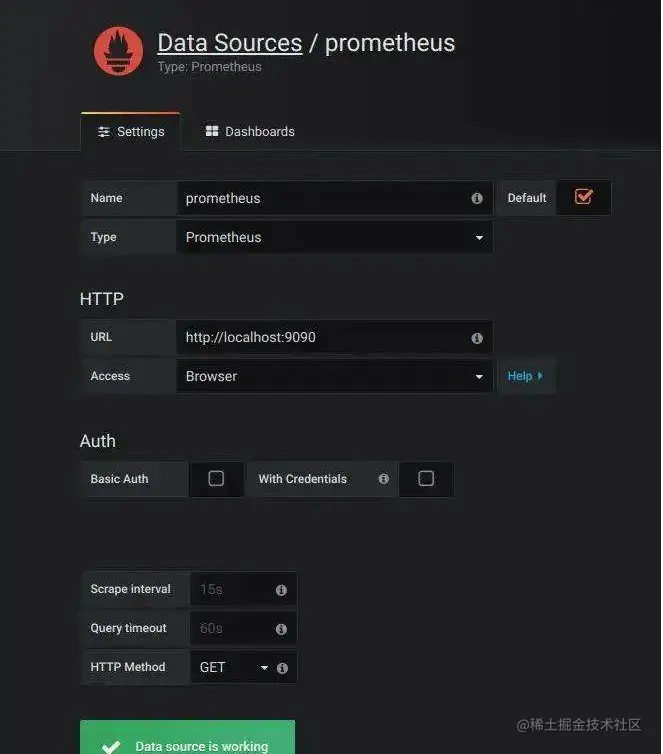
Preenchemos aqui por sua vez:
- Nome: Prometeu
- Tipo: Prometeu
- URL: http://localhost:9090
- Acesso: Navegador
Deve-se observar que Acesso aqui se refere à forma como o Grafana acessa as fontes de dados, e existem duas formas: Navegador e Proxy. O modo Navegador significa que quando o usuário acessa o painel Grafana, o navegador acessa diretamente a fonte de dados através da URL; o modo Proxy significa que o navegador acessa primeiro uma determinada interface proxy do Grafana (o endereço da interface é ), e o servidor Grafana acessa a fonte de dados /api/datasources/proxy/.URL, o que é muito útil se a fonte de dados estiver implantada na intranet e os usuários não puderem acessá-la diretamente por meio de um navegador.
Após configurar a fonte de dados, o Grafana fornecerá vários painéis configurados para você usar por padrão. Conforme mostrado na figura abaixo, três painéis são fornecidos por padrão: Estatísticas do Prometheus, Estatísticas do Prometheus 2.0 e Métricas do Grafana. Clique em Importar para importar e usar o painel.
Importamos o painel Prometheus 2.0 Stats e você pode ver o seguinte painel de monitoramento. Se a sua empresa tiver condições, você pode solicitar um monitor grande para pendurar na parede, projetar esse painel na tela grande e observar o status do sistema online em tempo real, pode-se dizer que é muito legal.
[5. Use o Exportador para coletar indicadores]
Até agora, o que vimos são apenas alguns indicadores que não têm uso prático.Se quisermos realmente usar o Prometheus em nosso ambiente de produção, muitas vezes precisamos prestar atenção a vários indicadores, como carga da CPU do servidor, uso de memória, IO Overhead, tráfego de entrada e saída e muito mais.
Como mencionado acima, o Prometheus usa Pull para obter dados do indicador. Para obter dados do alvo, o Prometheus deve primeiro instalar um programa de coleta de indicadores no alvo e expor uma interface HTTP para o Prometheus consultar. Este programa de coleta de indicadores é chamado Exportador. Diferente os indicadores necessitam de diferentes exportadores para serem coletados. Já existe um grande número de exportadores disponíveis, cobrindo quase todos os tipos de sistemas e software que comumente usamos.
O site oficial lista uma lista de exportadores comumente usados. Cada exportador segue um acordo portuário para evitar conflitos portuários, ou seja, começando em 9100 e aumentando sequencialmente. Aqui está a lista completa dos portos exportadores. Vale ressaltar também que alguns softwares e sistemas não necessitam de instalação do Exporter, pois eles próprios possuem a função de expor dados de indicadores no formato Prometheus, como Kubernetes, Grafana, Etcd, Ceph, etc.
Nesta seção, vamos coletar alguns dados úteis.
[5.1 Coletar métricas do servidor]
Primeiro, vamos coletar os indicadores do servidor. Isso requer a instalação do node_exporter. Este exportador é usado para coletar sistemas de kernel *NIX. Se o seu servidor for Windows, você pode usar o exportador WMI.
Assim como o servidor Prometheus, o node_exporter também está disponível imediatamente:
rubi
copiar código
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz $ tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz $ cd node_exporter-0.16.0.linux-amd64 $ ./node_exporter
Após o início do node_exporter, visitamos a seguinte /metrics interface para ver se conseguimos obter os indicadores do servidor normalmente:
concha
copiar código
$ curl http://localhost:9100/metrics
Se tudo estiver bem, podemos modificar o arquivo de configuração do Prometheus e adicionar o servidor a scrape_configs ele:
arduino
copiar código
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['192.168.0.107:9090'] - job_name: 'server' static_configs: - targets: ['192.168.0.107:9100']
Após modificar a configuração, você precisa reiniciar o serviço do Prometheus ou enviar HUP um sinal para fazer o Prometheus recarregar a configuração:
php
copiar código
$ killall -HUP prometheus
Em Status -> Targets of Prometheus Web UI, você pode ver o servidor recém-adicionado:
Na caixa suspensa de indicadores na página Gráfico, você pode ver muitos indicadores cujos nomes começam com nó. Por exemplo, entramos para node_load1 observar a carga do servidor:
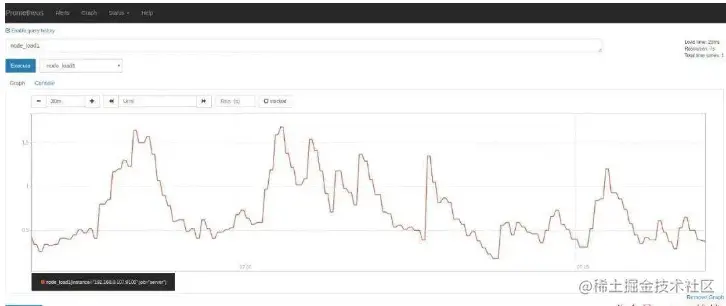
Se você deseja visualizar as métricas do servidor no Grafana, pode pesquisar na página Dashboards do Grafana.Existem node exportermuitos modelos de painel que podem ser usados diretamente, como Node Exporter Server Metrics ou Node Exporter Full. Abrimos a página do painel de importação do Grafana e inserimos a URL do painel ( grafana.com/dashboards/… ID (405).
[Precauções]
Em geral, o node_exporter é executado diretamente no servidor onde as métricas devem ser coletadas.Não é oficialmente recomendado usar o Docker para executar o node_exporter. Se for necessário executá-lo no Docker, você deve prestar atenção especial, pois o sistema de arquivos e a rede do Docker possuem seus próprios namespaces e os dados coletados não são o indicador real do host. Você pode usar algumas soluções alternativas, como adicionar os seguintes parâmetros ao executar o Docker:
festa
copiar código
docker run -d \ --net="host" \ --pid="host" \ -v "/:/host:ro,rslave" \ quay.io/prometheus/node-exporter \ --path.rootfs /host
Para obter mais informações sobre node_exporter, você pode consultar a documentação do node_exporter e o guia oficial do Prometheus Monitorando métricas de host Linux com o Node Exporter.Além disso, este artigo Como instalar o Prometheus usando Docker no Ubuntu 14.04 de Julius Volz também é uma boa entrada material.
[5.2 Coletando métricas do MySQL]
mysqld_exporter é um exportador fornecido oficialmente pela Prometheus. Primeiro baixamos a versão mais recente e a descompactamos (pronta para uso):
rubi
copiar código
$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz $ tar xvfz mysqld_exporter-0.11.0.linux-amd64.tar.gz $ cd mysqld_exporter-0.11.0.linux-amd64/
mysqld_exporter precisa se conectar ao mysqld para coletar suas métricas. Existem duas maneiras de configurar a fonte de dados mysqld. A primeira é através de uma variável de ambiente DATA_SOURCE_NAME, que é chamada de DSN (Data Source Name), e deve estar em conformidade com o formato DSN, um formato DSN típico se parece com este user:password@(host:port)/:.
concha
copiar código
$ export DATA_SOURCE_NAME='root:123456@(192.168.0.107:3306)/' $ ./mysqld_exporter
Outra forma é através do arquivo de configuração, o arquivo de configuração padrão é ~/.my.cnf, ou --config.my-cnf especificado pelos parâmetros:
Esse
copiar código
$ ./mysqld_exporter --config.my-cnf=".my.cnf"
O formato do arquivo de configuração é o seguinte:
Esse
copiar código
$ cat .my.cnf [client] host=localhost port=3306 user=root password=123456
Se você deseja importar indicadores MySQL para o Grafana, você pode consultar estes JSONs do Dashboard.
[Precauções]
Por uma questão de simplicidade,root é usado diretamente no mysqld_exporter para conectar-se ao banco de dados.Em um ambiente real,um usuário separado pode ser criado para mysqld_exporter e receber permissões limitadas (PROCESS,REPLICATION CLIENT, SELECT),e é melhor restringir it O número máximo de conexões (MAX_USER_CONNECTIONS).
SQL
copiar código
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
[5.3 Coletar métricas Nginx]
O funcionário fornece duas maneiras de coletar indicadores Nginx.
A primeira é a biblioteca métrica Nginx, que é um script Lua (prometheus.lua), e o Nginx precisa habilitar o suporte Lua (módulo libnginx-mod-http-lua). Por conveniência, você também pode usar o OPM (OpenResty Package Manager) do OpenResty ou luarocks (O gerenciador de pacotes Lua) para instalar.
O segundo é o exportador Nginx VTS. Este método é muito mais poderoso que o primeiro. É mais simples de instalar e suporta mais indicadores. Depende do módulo nginx-module-vts. O módulo vts pode fornecer um grande número de indicadores Nginx dados, essas métricas podem ser visualizadas em JSON, HTML, etc. O exportador Nginx VTS /status/format/json converte o formato de dados do vts para o formato do Prometheus capturando a interface.
No entanto, uma nova interface foi adicionada na versão mais recente do nginx-module-vts: /status/format/prometheus, esta interface pode retornar diretamente o formato do Prometheus. A partir deste ponto, também podemos ver a influência do Prometheus. Estima-se que o exportador Nginx VTS será retirado em breve (TODO: a ser verificado).
Além disso, existem muitas outras maneiras de coletar indicadores Nginx, por exemplo: alguns indicadores relativamente simples podem ser obtidos nginx_exporter acessando a página de estatísticas que acompanha o Nginx (é necessário abrir o módulo); coletar e analisar o acesso Nginx por meio do log do protocolo syslog para contar alguns indicadores relacionados às solicitações HTTP; da mesma forma , o protocolo syslog também é usado para coletar logs de acesso, mas é escrito em linguagem Crystal. Além disso, com base em Openresty, Prometheus, Consul e Grafana, foram implementadas estatísticas de tráfego para nomes de domínio e níveis de Endpoint./nginx_statusngx_http_stub_status_modulenginx_request_exporternginx-prometheus-shiny-exporternginx_request_exportervovolie/lua-nginx-prometheus
Os alunos que precisarem ou tiverem interesse podem instalar e experimentar por conta própria de acordo com a documentação, por isso não vou experimentá-los um por um aqui.
[5.4 Coletando métricas JMX]
Por fim, vamos dar uma olhada em como coletar indicadores de aplicativos Java. Os indicadores de aplicativos Java geralmente são obtidos por meio de JMX (Java Management Extensions). Como o nome indica, JMX é uma extensão para gerenciar Java, que pode facilmente gerenciar e monitorar a execução do programa Java.
O JMX Exporter é usado para coletar métricas JMX. Muitos sistemas que usam Java podem usá-lo para coletar métricas, como Kafaka, Cassandra, etc. Primeiro baixamos o JMX Exporter:
concha
copiar código
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar
-javaagent JMX Exporter é um programa Java Agent, que é carregado por parâmetros ao executar um programa Java :
Esse
copiar código
$ java -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9404:config.yml -jar spring-boot-sample-1.0-SNAPSHOT.jar
Entre eles, 9404 é a porta para o JMX Exporter expor indicadores e config.yml é o arquivo de configuração do JMX Exporter. Para seu conteúdo, consulte as instruções de configuração do JMX Exporter. Em seguida, verifique se os dados do indicador foram obtidos corretamente:
concha
copiar código
$ curl http://localhost:9404/metrics
[6. Alarme e notificação]
Neste ponto, podemos coletar uma grande quantidade de dados de indicadores e exibi-los através de um painel poderoso e bonito. Porém, como sistema de monitoramento, a função mais importante é ser capaz de detectar a tempo os problemas do sistema e notificar a tempo o responsável pelo sistema, que é o Alerta.
A função de alarme do Prometheus é dividida em duas partes: uma é a configuração e detecção das regras de alarme, e envia o alarme para o Alertmanager, e a outra é o Alertmanager, que é responsável por gerenciar esses alarmes, remover dados duplicados, agrupar e rotear para o método de recepção correspondente.Soar o alarme. Os métodos de recebimento comuns incluem: Email, PagerDuty, HipChat, Slack, OpsGenie, WebHook, etc.
[6.1 Configurar regras de alarme]
Quando apresentamos o arquivo de configuração do Prometheus acima, aprendemos que seu arquivo de configuração padrão prometheus.yml tem quatro blocos principais: global, alerting, rule_files, scrape_config, onde rule_files o bloco é o item de configuração da regra de alarme e o bloco de alerta é usado para configurar o Alertmanager, que discutiremos na próxima seção, veja novamente. Agora, vamos rule_files adicionar um arquivo de regras de alerta ao bloco:
vbnet
copiar código
rule_files: - "alert.rules"
Em seguida, consulte a documentação oficial para criar um arquivo de regras de alerta alert.rules:
festa
copiar código
groups: - name: example rules: # Alert for any instance that is unreachable for >5 minutes. - alert: InstanceDown expr: up == 0 for: 5m labels: severity: page annotations: summary: "Instance {
{ $labels.instance }} down" description: "{
{ $labels.instance }} of job {
{ $labels.job }} has been down for more than 5 minutes." # Alert for any instance that has a median request latency >1s. - alert: APIHighRequestLatency expr: api_http_request_latencies_second{quantile="0.5"} > 1 for: 10m annotations: summary: "High request latency on {
{ $labels.instance }}" description: "{
{ $labels.instance }} has a median request latency above 1s (current value: {
{ $value }}s)"
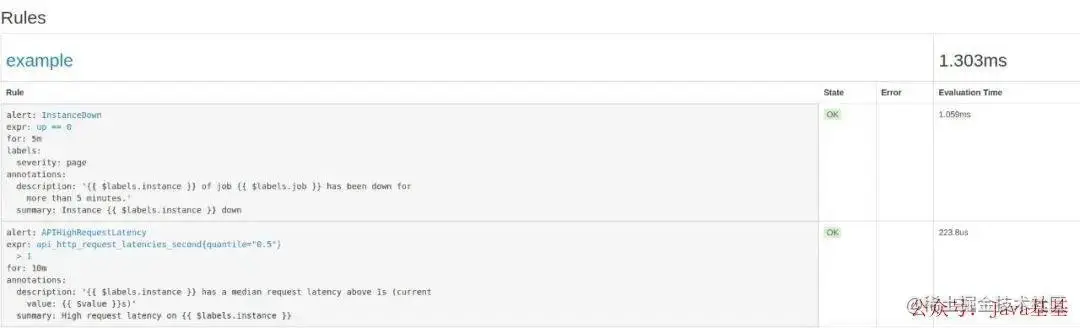
Este arquivo de regras contém duas regras de alerta: InstanceDown e APIHighRequestLatency. api_http_request_latencies_second{quantile="0.5"} > 1Como o nome indica, InstanceDown indica que um alarme é acionado quando a instância está inativa (up === 0), e APIHighRequestLatency indica que um alarme é acionado quando metade do atraso da solicitação da API é maior que 1s ( ).
Após a configuração, você precisa reiniciar o servidor Prometheus e visitar http://localhost:9090/rules para ver as regras recém-configuradas:
O Access http://localhost:9090/alerts pode visualizar os alarmes gerados de acordo com as regras configuradas:
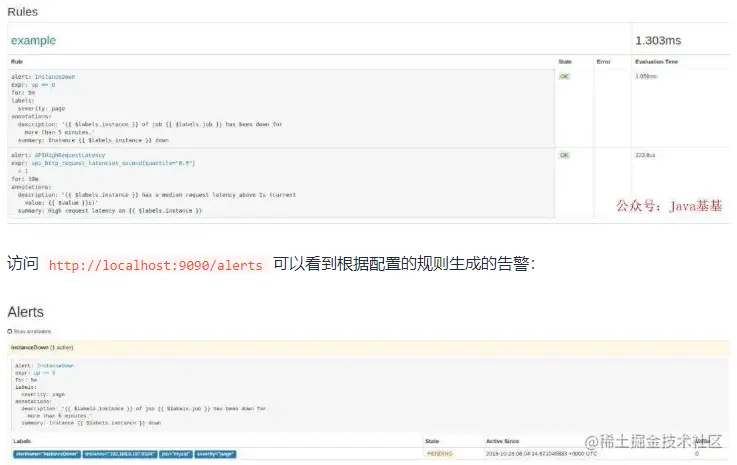
Aqui paramos uma instância e podemos ver que há um status de alerta PENDING, o que significa que a regra de alerta foi acionada, mas a condição de alerta ainda não foi atingida. Isso ocorre porque o parâmetro aqui configurado for é 5m, ou seja, o alarme será acionado após 5 minutos, aguardamos 5 minutos e podemos observar que o status deste alerta mudou FIRING.
[6.2 Use o Alertmanager para enviar notificações de alarme]
Embora a /alerts página do Prometheus possa ver todos os alarmes, ainda falta a última etapa: enviar notificações automaticamente quando um alarme é acionado. Isso é feito pelo Alertmanager, primeiro baixamos e instalamos o Alertmanager, como outros componentes do Prometheus, o Alertmanager também vem pronto para uso:
concha
copiar código
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz $ tar xvfz alertmanager-0.15.2.linux-amd64.tar.gz $ cd alertmanager-0.15.2.linux-amd64 $ ./alertmanager
Após o Alertmanager ser iniciado, ele pode ser http://localhost:9093/ acessado por padrão, mas o alerta ainda não está visível, pois não configuramos o Alertmanager no Prometheus, então voltamos ao arquivo de configuração do Prometheus prometheus.ymle adicionamos as seguintes linhas:
yaml
copiar código
alerting: alertmanagers: - scheme: http static_configs: - targets: - "192.168.0.107:9093"
Esta configuração informa ao Prometheus que quando ocorrer um alarme, envie as informações do alarme para o Alertmanager, cujo endereço é http://192.168.0.107:9093. O Alertmanager também pode ser especificado usando linhas nomeadas:
Esse
copiar código
$ ./prometheus -alertmanager.url=http://192.168.0.107:9093
Visite o Alertmanager novamente neste momento e você verá que o Alertmanager recebeu um alerta:
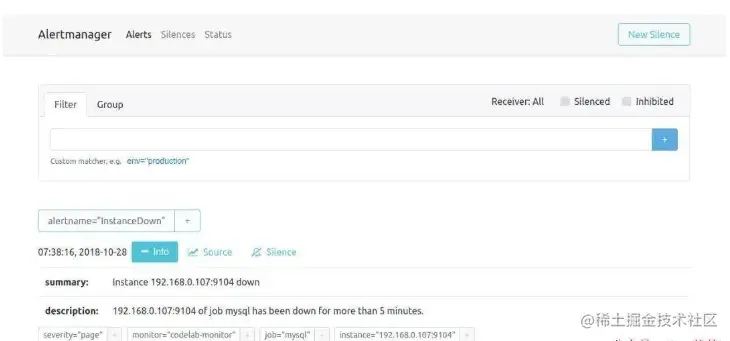
A seguinte questão é como deixar o Alertmanager nos enviar as informações do alarme, abrimos o arquivo de configuração padrão alertmanager.ym:
vbnet
copiar código
global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
Consulte o manual de configuração oficial para entender as funções de cada item de configuração. O bloco global representa algumas configurações globais; o bloco de rota representa a rota de notificação e a notificação de alarme pode ser enviada para diferentes receptores de acordo com rótulos diferentes. Não há rotas item configurado aqui, que representa todos os alarmes Ambos são enviados para o receptor web.hook definido abaixo; se você deseja configurar múltiplas rotas, pode consultar este exemplo:
Lua
copiar código
routes: - receiver: 'database-pager' group_wait: 10s match_re: service: mysql|cassandra - receiver: 'frontend-pager' group_by: [product, environment] match: team: frontend
Em seguida, o bloco de receptores representa o método de recebimento da notificação de alarme. Cada receptor contém um nome e um xxx_configs. Diferentes configurações representam diferentes métodos de recebimento. O Alertmanager possui os seguintes métodos de recebimento integrados:
- email_config
- hipchat_config
- pagerduty_config
- pushover_config
- folga_config
- opsgenie_config
- victorops_config
- wechat_configs
- webhook_config
Embora existam muitos métodos de recepção, a maioria deles raramente é usada na China. Os mais utilizados são ninguém menos que email_config e webhook_config, além disso, wechat_configs pode suportar a utilização do WeChat para envio de alarmes, o que está bastante de acordo com as condições nacionais.
Na verdade, é difícil cobrir todos os aspectos do método de notificação de alarme, porque existem vários softwares de mensagens, e cada país pode ser diferente, e é impossível cobri-lo completamente, então o Alertmanager decidiu não adicionar novos receptores, mas recomenda o uso de webhook para integrar métodos de recebimento personalizados. Você pode consultar esses exemplos de integração, como conectar o DingTalk ao Prometheus AlertManager WebHook.
[7. Saiba mais]
Até agora, aprendemos a maioria das funções do Prometheus. Combinando Prometheus + Grafana + Alertmanager podemos construir um sistema de monitoramento muito completo. Mas no uso real encontraremos mais problemas.
[7.1 Descoberta de serviço]
Como o Prometheus obtém ativamente dados de monitoramento por meio do Pull, é necessário especificar manualmente a lista de nós de monitoramento. Quando o número de nós de monitoramento aumenta, o arquivo de configuração precisa ser alterado toda vez que um nó é adicionado, o que é muito problemático. Neste caso tempo, é necessário usar o mecanismo de descoberta de serviço (descoberta de serviço, SD) para resolver.
O Prometheus oferece suporte a uma variedade de mecanismos de descoberta de serviço e pode obter automaticamente os alvos a serem coletados. Você pode consultá-los aqui. Os mecanismos de descoberta de serviço incluídos incluem: azure, consul, dns, ec2, openstack, file, gce, kubernetes, marathon, triton, zookeeper (nerve, serverset), o método de configuração pode consultar a página de configuração do manual. Pode-se dizer que o mecanismo SD é muito rico, mas devido aos recursos de desenvolvimento limitados, nenhum novo mecanismo SD foi desenvolvido e apenas o mecanismo SD baseado em arquivo é mantido.
Existem muitos tutoriais na Internet sobre descoberta de serviços, como o artigo Advanced Service Discovery in Prometheus 0.14.0 no blog oficial do Prometheus para descoberta de serviços.
Além disso, o site oficial também fornece um exemplo introdutório de descoberta de serviço baseado em arquivo.O tutorial introdutório do workshop Prometheus escrito por Julius Volz também usa DNS-SRV para descoberta de serviço.
[7.2 Gerenciamento de configuração de alarme]
Nem a configuração do Prometheus nem a configuração do Alertmanager fornecem uma API para modificarmos dinamicamente. Um cenário muito comum é que precisamos fazer um sistema de alarme baseado em Prometheus com regras personalizáveis. Os usuários podem criar, modificar ou excluir regras de alarme na página de acordo com suas necessidades, ou modificar métodos e contatos de notificação de alarme, como em Pergunta de este usuário nos Grupos do Google do Prometheus: Como adicionar dinamicamente regras de alertas em regras.conf e arquivo yml do prometheus via API ou algo assim?
Mas, infelizmente, Simon Pasquier disse abaixo que não existe tal API no momento, e não existe tal plano para desenvolver tal API no futuro, porque tais funções deveriam ser entregues a Puppet, Chef, Ansible, Salt, etc. • Sistema de gerenciamento de configuração.
[7.3 Usando Pushgateway]
Pushgateway é usado principalmente para coletar alguns empregos de curto prazo. Como esses empregos existem por um curto período de tempo, eles podem desaparecer antes que o Prometheus chegue ao Pull. O oficial tem uma boa descrição de quando usar o Pushgateway.
[Resumir]
Este blog refere-se a um grande número de materiais chineses sobre Prometheus na Internet, incluindo documentos e blogs, como o manual chinês não oficial do Prometheus em 1046102779, o e-book "Prometheus Actual Combat" de Song Jiayang, aqui para prestar homenagem a esses autores originais . Na página Mídia da documentação oficial do Prometheus, muitos recursos de aprendizagem também são fornecidos.
Em relação ao Prometheus, ainda há uma parte muito importante do conteúdo que este blog não cobre. Conforme mencionado no início do blog, o Prometheus é o segundo projeto a ingressar no CNCF depois do Kubernetes. O Prometheus está intimamente integrado ao Docker e ao Kubernetes. Usando o Prometheus como sistema de monitoramento para Docker e Kubernetes, ele está se tornando cada vez mais popular.
Para monitoramento do Docker, você pode consultar um guia no site oficial: Monitorando métricas de contêiner do Docker usando cAdvisor, que apresenta como usar o cAdvisor para monitorar contêineres; no entanto, o Docker agora também oferece suporte nativo ao monitoramento do Prometheus, consulte o documento oficial do Docker Coletar métricas do Docker com Prometheus; Em relação ao monitoramento do Kubernetes, existem muitos recursos sobre o Promehtheus na comunidade chinesa do Kubernetes. Além disso, o e-book "Como monitorar o Kubernetes com Elegance" também tem uma introdução mais abrangente ao monitoramento do Kubernetes.
Nos últimos dois anos, o Prometheus desenvolveu-se muito rapidamente e a comunidade também está muito ativa.Há cada vez mais pessoas estudando o Prometheus na China. Com a popularização de conceitos como microsserviços, DevOps, computação em nuvem e nuvem nativa, cada vez mais empresas começam a usar Docker e Kubernetes para construir seus próprios sistemas e aplicações, e sistemas de monitoramento antigos, como Nagios e Cacti, se tornarão cada vez mais Quanto menos aplicável, acredito que o Prometheus eventualmente se tornará um sistema de monitoramento mais adequado para ambientes em nuvem.
[Apêndice: O que é um banco de dados de série temporal? ]
Conforme mencionado acima, o Prometheus é um sistema de monitoramento baseado em banco de dados de séries temporais, que geralmente é abreviado como TSDB (Time Series Database). Muitos sistemas de monitoramento populares usam bancos de dados de séries temporais para salvar dados, porque as características dos bancos de dados de séries temporais coincidem com as dos sistemas de monitoramento.
- Aumento: São necessárias operações de gravação frequentes e são escritas em ordem cronológica
- Excluir: Não há necessidade de excluir aleatoriamente, geralmente todos os dados em um bloco de tempo serão excluídos diretamente
- Mudança: Não há necessidade de atualizar os dados gravados
- Verificação: Necessidade de suporte a operações de leitura altamente simultâneas. As operações de leitura são lidas em ordem crescente ou decrescente de acordo com o tempo. A quantidade de dados é muito grande e o cache não funciona.
Há uma classificação de bancos de dados de séries temporais em DB-Engines, aqui estão os principais (outubro de 2018):
- InfluxDB: influxdata.com/
- Kdb+: kx.com/
- Grafite: graphiteapp.org/
- RRDtool: oss.oetiker.ch/rrdtool/
- OpenTSDB: opentsdb.net/
- Prometeu: prometheus.io/
- Druida: druid.io/