introduzir
Pertencemos ao modo SoC, ou seja, completamos a compilação e quantificação do modelo e a compilação cruzada do programa baseado em tpu-nntc e libsophon no host x86, e copiamos o programa compilado para a plataforma SoC (1684 placa de desenvolvimento/microservidor SE/módulo SM) durante a implantação. grupo) é executado.
Nota: Todos os itens a seguir são operados no sistema Ubuntu20.04. Claro, Ubuntu18 e 22 também são possíveis, porque usamos principalmente o ambiente docker oficial para configuração.
Preparação
instalar janela de encaixe
Primeiro instale o docker
# 更新一下库
sudo apt-get update
sudo apt-gefat upgrade
# 安装 docker
sudo apt-get install docker.io
# docker命令免root权限执行
# 创建docker用户组,若已有docker组会报错,没关系可忽略
sudo groupadd docker
# 将当前用户加入docker组
sudo gpasswd -a ${
USER} docker
# 重启docker服务
sudo service docker restart
# 切换当前会话到新group或重新登录重启X会话
newgrp docker
Já instalei o docker. Não testei esta etapa. Se você tiver alguma dúvida, pergunte ao Baidu.
Baixe o SDK
No site oficial da Suaneng, baixe o SDK relevante no download de dados: https://developer.sophgo.com/site/index/material/all/all.html
O kit básico inclui:
- tpu-nntc é responsável pela compilação offline e otimização do modelo de rede neural treinado na estrutura de aprendizado profundo de terceiros e gera o BModel necessário para o tempo de execução final. Atualmente suporta Caffe, Darknet, MXNet, ONNX, PyTorch, PaddlePaddle, TensorFlow, etc.
- libsophon fornece bibliotecas como BMCV, BMRuntime e BMLib, que são usadas para conduzir VPP, TPU e outros hardwares para concluir operações como processamento de imagem, operações de tensor e raciocínio de modelo para que os usuários desenvolvam aplicativos de aprendizado profundo.
- sophon-mw encapsula BM-OpenCV, BM-FFmpeg e outras bibliotecas para conduzir VPU, JPU e outros hardwares, suporta fluxo RTSP, análise de fluxo GB28181, aceleração de codec de imagem de vídeo, etc., para que os usuários desenvolvam aplicativos de aprendizado profundo.
- sophon-sail fornece uma interface de alto nível que suporta Python/C++. É um pacote de interfaces de biblioteca subjacentes, como BMRuntime, BMCV, BMDecoder e BMLib, para que os usuários desenvolvam aplicativos de aprendizado profundo.
Você pode baixar este SDK

Contém todos os códigos dos modelos, é claro, muitos pacotes nele não são usados.
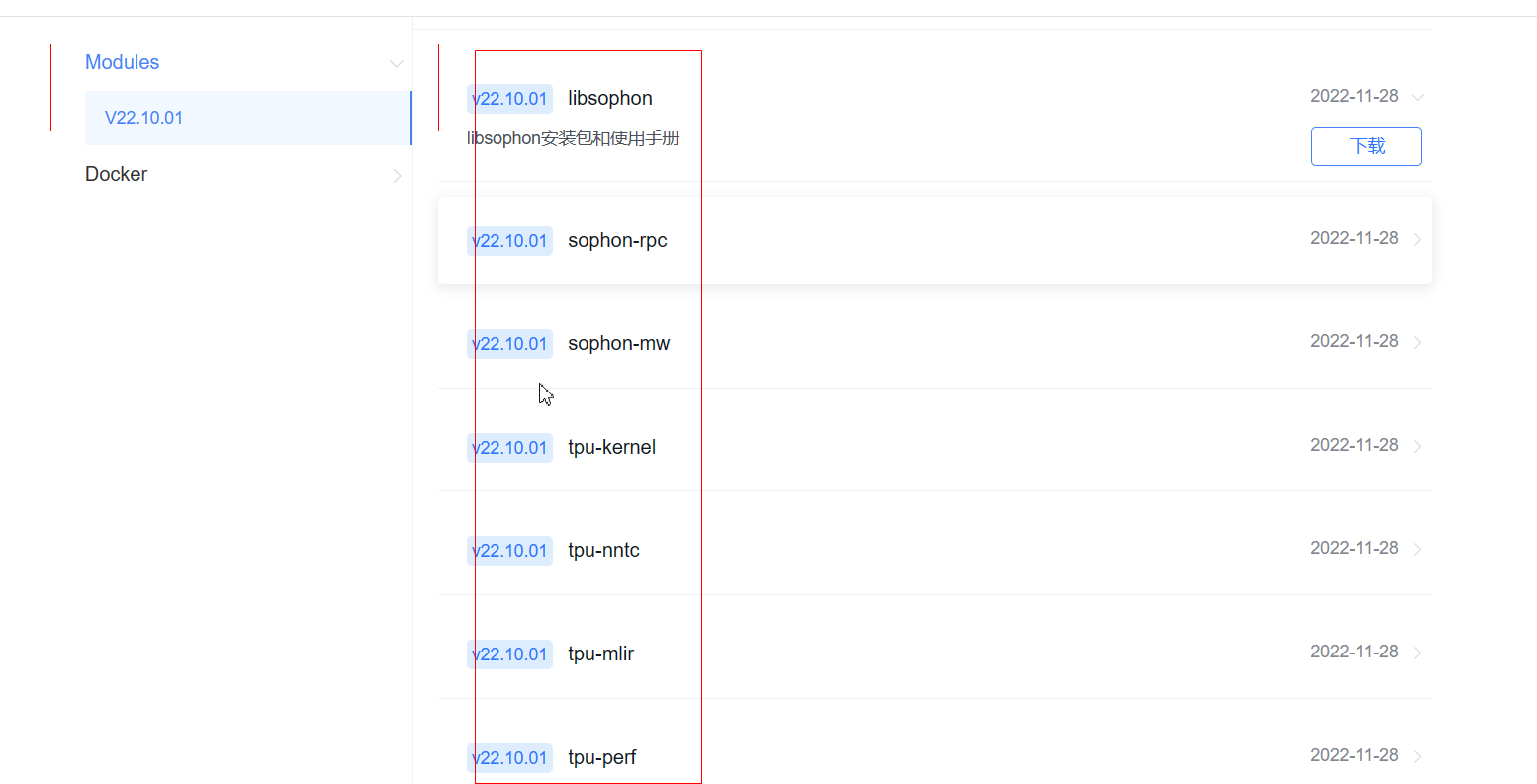
Você também pode baixar apenas o SDK que precisamos
Principalmente estes poucos:
Respectivamente wget para o local na linha,
# 先建个存放的路径
mkdir fugui
# 分别wget 到本地就行
wget https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/10/libsophon_20221027_214818.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/11/sophon-mw_20221027_183429.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/15/sophon-demo_20221027_181652.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/15/sophon-img_20221027_215835.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/15/sophon-sail_20221026_200216.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/15/sophon-demo_20221027_181652.zip
Ambiente de configuração
Instale a ferramenta de descompressão
sudo apt-get install unzip
Primeiro descompacte esses arquivos compactados
unzip \*.zip
Crie um contêiner docker:
#如果当前系统没有对应的镜像,会自动从docker hub上下载;此处将tpu-nntc的上一级目录映射到docker内的/workspace目录;这里用了8001到8001端口的映射(使用ufw可视化工具会用到端口号)。如果端口已被占用,请根据实际情况更换为其他未占用的端口。
:~/fugui# docker run -v $PWD/:/workspace -it sophgo/tpuc_dev:latest
Digite tpu-nntc, descompacte o pacote
root@39d67fa4c7bb:/workspace/fugui/tpu-nntc_20221028_200521# tar -zxvf tpu-nntc_v3.1.3-242ef2f9-221028.tar.gz
Digite tpu-nntc_v3.1.3-242ef2f9-221028 e execute o comando para inicializar o ambiente de software
source scripts/envsetup.sh
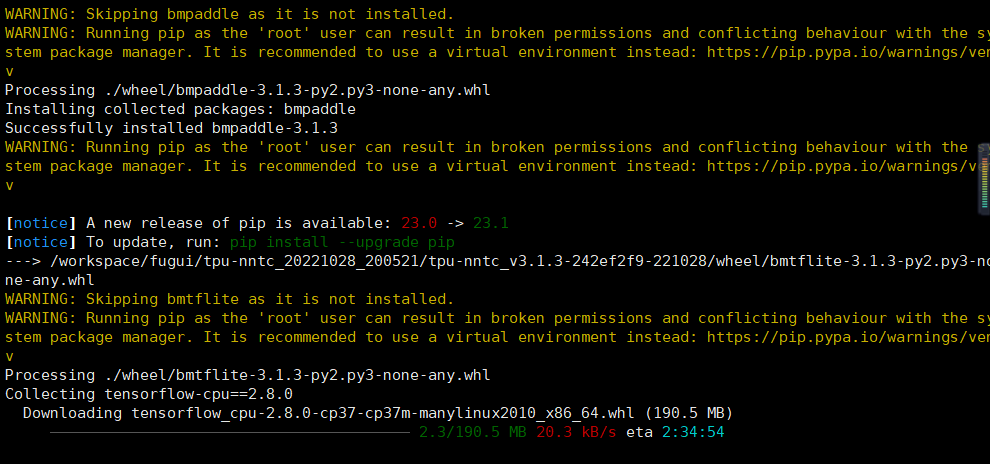
Quando o download do tensorflow é relativamente lento, todos nós usamos pytorch, apenas ctrl c para ignorá-lo e não o instalamos.
Yolov5
O modelo oficial não será demonstrado aqui e usaremos diretamente nosso próprio modelo treinado para raciocínio quantitativo.
Nota: a versão yolov5 v6.1 deve ser usada aqui
Não vou falar sobre como treinar, consulte: este artigo
É melhor usar o treinamento yolov5s e depois converter o modelo treinado. Por exemplo, estou treinando detecção de capacete. Agora gerei o arquivo de peso best.pt. Para distingui-lo, renomeei-o paraanquanmao.pt
Coloque-o no diretório raiz do yolov5 e modifique a função forward em yolo.py no arquivo de modelos. Alterar return x if self.training else (torch.cat(z, 1), x)para:
return x if self.training else x
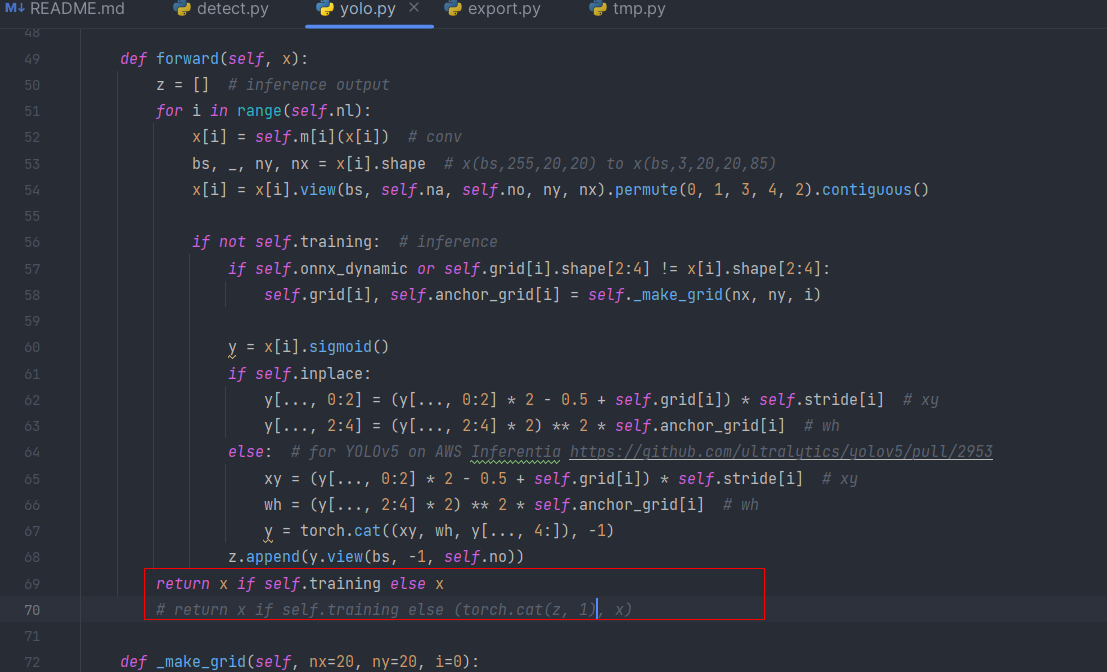
então corra
python export.py --weight anquanmao.pt --include torchscript
Isso gerou anquanmao.torchscripto arquivo
Abra este arquivo de peso para ver se é igual ao meu, desde que seja yolov5 6.1, deve ser igual.
Alterar anquanmao.torchscriptpara anquanmao.torchscript.pt(ou seja, adicionar um .pt no final)
Em seguida, copie este arquivo para o seu servidor x86, o caminho é:
/root/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/data
Depois encontre algumas fotos do seu treinamento, ou seja, capacetes, umas 200 fotos bastam
Faça upload também para essa pasta
Então o modelo pode ser transformado
# 先备份一下
root@39d67fa4c7bb:/workspace/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/scripts# cp 2_2_gen_int8bmodel.sh 3_2_gen_int8bmodel.sh
vi cp 2_2_gen_int8bmodel.sh
Em seguida, modifique o conteúdo interno, 200 é demais, a conversão é muito lenta, 50 é o suficiente

Modifique model_info.sh
root@39d67fa4c7bb:/workspace/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/scripts# vi model_info.sh
echo "start fp32bmodel transform, platform: ${platform} ......"
root_dir=$(cd `dirname $BASH_SOURCE[0]`/../ && pwd)
build_dir=$root_dir/build
# 将这里修改为我们刚才存放的.torchscript.pt文件地址
src_model_file=${root_dir}/data/anquanmao.1_3output.torchscript.pt
src_model_name=`basename ${
src_model_file}`
# 这里也修改下吧 yolov5s ——> anquanmao
dst_model_prefix="anquanmao"
dst_model_postfix="coco_v6.1_3output"
fp32model_dir="${root_dir}/data/models/${platform}/fp32model"
int8model_dir="${root_dir}/data/models/${platform}/int8model"
lmdb_src_dir="${root_dir}/data/images"
# 这里修改为我们上传的图片地址
image_src_dir="${root_dir}/data/anquanmao"
# lmdb_src_dir="${build_dir}/coco2017val/coco/images/"
#lmdb_dst_dir="${build_dir}/lmdb/"
img_size=${2:-640}
batch_size=${3:-1}
iteration=${4:-2}
img_width=640
img_height=640
Você precisa adicionar permissões antes de executar o comando de conversão, caso contrário ele não poderá ser executado
root@39d67fa4c7bb:/workspace/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/scripts# sudo chmod 777 *
Em seguida, execute a conversão para o modelo int8bmodel, o mesmo vale para a conversão para FP32
root@39d67fa4c7bb:/workspace/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/scripts# ./ 2_2_gen_int8bmodel.sh
Máquinas com baixo desempenho ficarão muito lentas, basta aguardar a conclusão
Compilar o programa yolov5 c++
/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build#
cd cpp/deepsort_bmcv
mkdir build && cd build
# 请根据实际情况修改-DSDK的路径,需使用绝对路径
cmake -DTARGET_ARCH=soc -DSDK=/workspace/soc-sdk ..
make
copiar para placa de desenvolvimento
scp ../yolov5_bmcv.soc [email protected]:/data/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv
Placa de desenvolvimento em execução
linaro@bm1684:/data/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv$ ./yolov5_bmcv_drawr.soc --input=rtsp://admin:sangfor@[email protected] --bmodel=BM1684/yolov5s_v6.1_3output_int8_1b.bmodel
rastreamento de alvo
Nota: Todas as conversões de modelo estão no ambiente docker
Entre primeiro no docker
Aqui vamos compilar no ambiente docker, então primeiro entre no docker
:~/tpu-nntc# docker run -v $PWD/:/workspace -it sophgo/tpuc_dev:latest
Inicialize o ambiente
root@2bb02a2e27d5:/workspace/tpu-nntc# source ./scripts/envsetup.sh
Instale o compilador no docker
root@2bb02a2e27d5:/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build# sudo apt-get install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu libeigen3-dev
Esta rotina C++ depende do Eigen, você precisa executar o seguinte comando na máquina onde o programa C++ está compilado para instalar:
sudo apt install libeigen3-dev
Primeiro baixe os arquivos relevantes, principalmente o vídeo de teste de rastreamento, imagem de teste, peso de rastreamento do alvo, peso de detecção do alvo
# 安装unzip,若已安装请跳过
sudo apt install unzip
chmod -R +x scripts/
./scripts/download.sh
Em seguida, compile o código c++
/workspace/sophon-demo/sample/DeepSORT/cpp/deepsort_bmcv/build#
cd cpp/deepsort_bmcv
mkdir build && cd build
# 请根据实际情况修改-DSDK的路径,需使用绝对路径。
cmake -DTARGET_ARCH=soc -DSDK=/workspace/soc-sdk ..
make
Neste momento, o arquivo deepsort_bmcv.soc será gerado e copiado para a caixa
:/workspace/sophon-demo/sample/DeepSORT/cpp/deepsort_bmcv# scp -r deepsort_bmcv.soc [email protected]:/data/yolo/sophon-demo/sample/DeepSORT/cpp
vídeo de teste
./deepsort_bmcv.soc --input=rtsp://admin:sangfor@[email protected] --bmodel_detector=../../BM1684/yolov5s_v6.1_3output_int8_1b.bmodel --bmodel_extractor=../../BM1684/extractor_fp32_1b.bmodel --dev_id=0
Execute o código relevante, isto é para detectar a imagem
cd python
python3 deepsort_opencv.py --input ../datasets/mot15_trainset/ADL-Rundle-6/img1 --bmodel_detector ../models/BM1684/yolov5s_v6.1_3output_int8_1b.bmodel --bmodel_extractor ../models/BM1684/extractor_fp32_1b.bmodel --dev_id=0
rastreamento de vídeo
python3 deepsort_opencv.py --input ../datasets/test_car_person_1080P.mp4 --bmodel_detector ../models/BM1684/yolov5s_v6.1_3output_int8_1b.bmodel --bmodel_extractor ../models/BM1684/extractor_fp32_1b.bmodel --dev_id=0
Rastreando vídeo da câmera local
python3 deepsort_opencv.py --input rtsp://admin:sangfor@[email protected] --bmodel_detector ../models/BM1684/yolov5s_v6.1_3output_int8_1b.bmodel --bmodel_extractor ../models/BM1684/extractor_fp32_1b.bmodel --dev_id=0
Estimativa de pose humana
python3 python/openpose_opencv.py --input rtsp://admin:sangfor@[email protected] --bmodel models/BM1684/pose_coco_fp32_1b.bmodel --dev_id 0
Os arquivos gerados serão colocados sample/YOLOv5/data/models/BM1684/int8model/anquanmao_batch1em
:~/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/data/models/BM1684/int8model/anquanmao_batch1# ls
compilation.bmodel input_ref_data.dat io_info.dat output_ref_data.dat
Em seguida, envie o modelo convertido para a placa de desenvolvimento
scp compilation.bmodel linaro@{开发板ip地址}:/data/{你的yolov5存放路径}
Configuração do ambiente da placa de desenvolvimento
Construir ambiente libsophon
cd libsophon_<date>_<hash>
# 安装依赖库,只需要执行一次
sudo apt install dkms libncurses5
sudo dpkg -i sophon-*.deb
# 在终端执行如下命令,或者log out再log in当前用户后即可使用bm-smi等命令
source /etc/profile
python3 yolov5_new_1.py --input rtsp://admin:[email protected] --bmodel yolov5s_v6.1_3output_fp32_1b.bmodel
ambiente de compilação c++
Instale a libsophon
Digite o caminho de sophon-img_20221027_215835
Descompacte o pacote tar dentro
:~/fugui/sophon-img_20221027_215835# tar -zxvf libsophon_soc_0.4.2_aarch64.tar.gz
Copie o diretório da biblioteca relevante e o diretório do arquivo de cabeçalho para a pasta soc-sdk
:~/fugui/sophon-img_20221027_215835/libsophon_soc_0.4.2_aarch64/opt/sophon/libsophon-0.4.2# sudo cp -rf include lib ~/fugui/soc-sdk
Instale sophon-opencv e sophon-ffmpeg
Digite sophon-mw primeiro, descompacte sophon-mw-soc_0.4.0_aarch64.tar.gzo pacote tar
:~/fugui/sophon-mw_20221027_183429# tar -zxvf sophon-mw-soc_0.4.0_aarch64.tar.gz
Copie os arquivos relacionados para soc-sdk
:~/fugui/sophon-mw_20221027_183429/sophon-mw-soc_0.4.0_aarch64/opt/sophon# cp -rf sophon-ffmpeg_0.4.0//lib sophon-ffmpeg_0.4.0/include/ ~/fugui/soc-sdk
:~/fugui/sophon-mw_20221027_183429/sophon-mw-soc_0.4.0_aarch64/opt/sophon# cp -rf sophon-opencv_0.4.0//lib sophon-opencv_0.4.0/include/ ~/fugui/soc-sdk
É muito simples, basta copiá-lo e o ambiente de compilação cruzada está configurado
Ambiente TPU-NNTC
Aqui vamos compilar no ambiente docker, então primeiro entre no docker
:~/fugui# docker run -v $PWD/:/workspace -it sophgo/tpuc_dev:latest
Em seguida, digite tpu-nntc, inicialize o ambiente
root@2bb02a2e27d5:/workspace/tpu-nntc# source ./scripts/envsetup.sh
Instale o compilador no docker
root@2bb02a2e27d5:/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build# sudo apt-get install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu
Insira o caminho sophon-demo
baixar arquivos relacionados
:~/fugui/sophon-demo/sample/YOLOv5# chmod -R +x scripts/
:~/fugui/sophon-demo/sample/YOLOv5# ./scripts/download.sh
compilar yolov5
Estamos apenas compilando aqui e não podemos rodar em dispositivos x86. Precisamos copiá-los para nossa plataforma 1684
destino cmake
root@2bb02a2e27d5:/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build# cmake -DTARGET_ARCH=soc -DSDK=/workspace/soc-sdk ..
em fazer
root@2bb02a2e27d5:/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build# make
O arquivo .soc aparecerá
[Falha na transferência de imagem do link externo, o site de origem pode ter um mecanismo de link anti-roubo, é recomendado salvar a imagem e carregá-la diretamente (img-eWPar5Yp-1692844732110)(https://gitee.com/lizheng0219/picgo_img/ raw/master/img202325/image -20230421134631891.png)]
Transfira o arquivo de saída para nossa placa de desenvolvimento e execute-o
scp -r yolov5_bmcv [email protected]:/data/sophon-demo/sample/YOLOv5/cpp/
executar imagem de inferência
./yolov5_bmcv.soc --input=../../coco128 --bmodel=../../python/yolov5s_v6.1_3output_fp32_1b.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=../../coco.names
vídeo de raciocínio
./yolov5_bmcv.soc --input=../../test.avi --bmodel=../../python/yolov5s_v6.1_3output_fp32_1b.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=../../coco.names
webcam de raciocínio c++
./yolov5_bmcv.soc --input=rtsp://admin:sangfor@[email protected] --bmodel=/data/ai_box/yolov5s_640_coco_v6.1_3output_int8_1b_BM1684.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=../../coco.names
./yolov5_bmcv.soc --input=rtsp://admin:sangfor@[email protected] --bmodel=/data/models/all16_v6.1_3output_int8_4b.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=/data/models/all16.names
Webcam: capacete
./yolov5_bmcv.soc --bmodel=anquanmao.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=../../coco.names
Raciocínio Python
python3 yolov5_opencv.py --input rtsp://admin:[email protected] --bmodel ../yolov5s_v6.1_3output_int8_4b.bmodel
O front-end exibe apenas uma câmera, e só precisamos fazer com que uma câmera use vários raciocínios algorítmicos.
As câmeras que não são exibidas também devem ser raciocinadas em segundo plano em tempo real, e a polícia deve ser chamada a tempo quando houver algum problema.
Dessa forma, precisamos fazer um algoritmo múltiplo de inferência de câmera única (algoritmo único de câmera única também é adequado, coloque todas as detecções em um modelo e produza apenas aquele que ele escolher ao gerar)
É relativamente simples treinar todos os modelos de maneira unificada e raciocinar em segundo plano
pipeline de sophon
compilação local
docker run -v $PWD/:/workspace -p 8001:8001 -it sophgo/tpuc_dev:latest
source scripts/envsetup.sh
sudo apt-get install -y gcc-aarch64-linux-gnu g++-aarch64-linux-gnu libeigen3-dev
./tools/compile.sh soc /workspace/soc-sdk
Placa de desenvolvimento em execução
linaro@bm1684:/data/sophon-pipeline/release/video_stitch_demo$ ./soc/video_stitch_demo --config=cameras_video_stitch1.json
Jardas inglesas
export PYTHONPATH=$PYTHONPATH:/system/libexport
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/system/lib/
Pitão
pip3 install sophon_arm-master-py3-none-any.whl --force-reinstall
pip3 install opencv-python-headless<4.3
Comando de execução da placa de desenvolvimento
python3 python/yolov5_opencv.py --input ../data/images/coco200/000000009772.jpg --model ../compilation.bmodel --dev_id 0 --conf_thresh 0.5 --nms_thresh 0.5
python3 python/yolov5_opencv.py --input ../data/xiyanimg/000017.jpg --model ../compilation.bmodel --dev_id 0 --conf_thresh 0.5 --nms_thresh 0.5
python3 python/yolov5_video.py --input rtsp://admin:sangfor@[email protected] --model ../compilation.bmodel
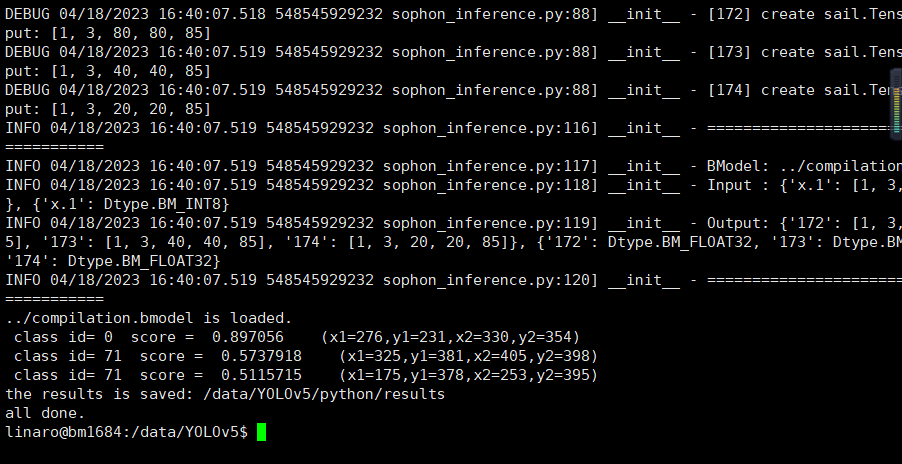
python3 python/yolov5_video.py --input rtsp://admin:[email protected] --model ../compilation.bmodel --dev_id 0 --conf_thresh 0.5 --nms_thresh 0.5
tar -zxf ~/Release_221201-public/sophon-mw_20221227_040823/sophon-mw-soc_*_aarch64.tar.gz