O que é aprendizado de máquina?
O aprendizado de máquina é] o campo de estudo que dá aos computadores a capacidade de aprender sem serem explicitamente programados. -Arthur Samuel, 1959
Um programa de computador pode aprender T e alguma medida de desempenho P a partir da experiência E sobre alguma tarefa, se seu desempenho em T, medido por P, melhorar com a experiência E. —Tom Mitchell, 1997
Em termos leigos, 机器学习(Aprendizado de Máquina) é a ciência da programação de computadores que pode aprender com os dados.
机器学习Como um filtro de spam no e-mail, o usuário marca exemplos de spam e correio normal e depois permite que a máquina aprenda a sinalizar spam.
Esses exemplos marcados pelo usuário para aprendizagem são chamados 训练(treinamento), e cada exemplo de treinamento passa a ser 训练实例(ou denominado 训练样本), 机器学习e o processo e faz 预测(previsões) passa a ser 模型(Modelo).
神经网络(Redes Neurais) e 随机森林(florestas aleatórias) também são 模型exemplos.
Neste caso, a tarefa T é marcar novos e-mails como spam, a experiência E são os dados de treinamento e uma medida de desempenho P precisa ser definida; por exemplo, você pode usar a proporção de e-mails classificados corretamente. Essa medida específica de desempenho é chamada de alta precisão e é frequentemente usada para tarefas de classificação.
Mas se você apenas baixar uma cópia de todos os artigos da Wikipedia, terá mais dados de conteúdo em seu computador, mas de repente não ficará melhor em nenhuma tarefa. Isto não é 机器学习.
Por que usar o aprendizado de máquina?
Descartamos os filtros 机器学习que utilizam 传统编程a forma de lidar com spam.
- 1. Primeiro, você deve verificar
垃圾邮件sua aparência. Por exemplo, promoção de evento em shopping, informações imobiliárias, recomendação de ações, etc. - 2. Sim, você deve escrever um conjunto de algoritmos de detecção para as situações acima.
- 3. Você testará seu programa e repetirá as etapas 1 e 2 até que esteja bom o suficiente.
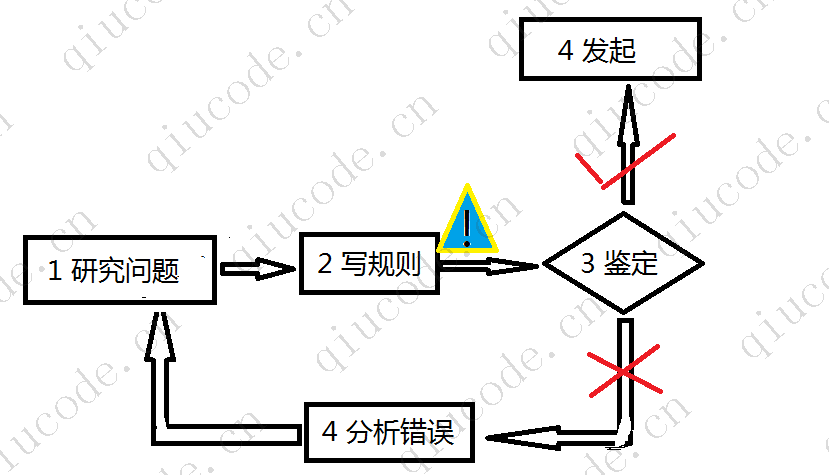
No final, é provável que o seu programa se torne uma longa lista de regras complexas – difíceis de manter.
Em contraste, 机器学习os filtros de spam baseados em técnicas que aprendem automaticamente a prever bem o spam, detectando frequências anômalas, são mais curtos, mais fáceis de manter e provavelmente mais precisos do que os exemplos de spam.
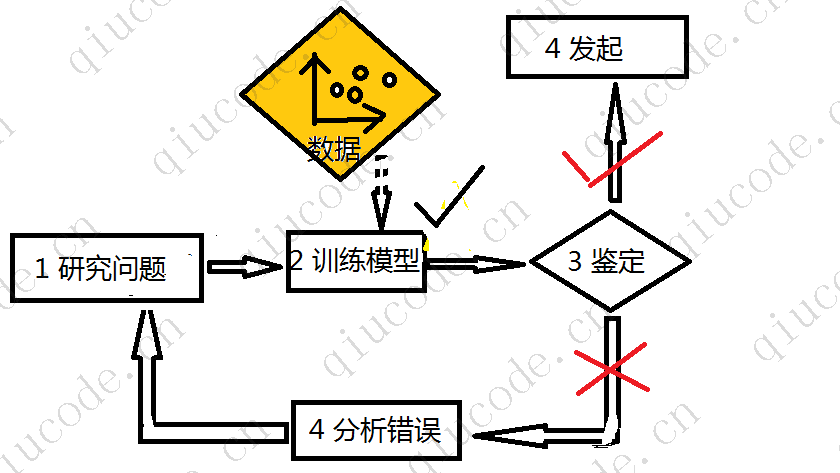
E se 垃圾邮件o remetente descobrir que todos os e-mails contendo links promocionais de eventos do marketplace estão bloqueados? Eles são obrigados a substituir o link por um link curto.
No entanto, com filtros de spam tradicionalmente programados, são necessárias técnicas mais recentes para sinalizar e-mails 短链接que promovam campanhas ocultas de mercado. Contanto que 垃圾邮件o remetente continue contornando o filtro de spam, você estará sempre no escuro para atualizar suas regras.
Por outro lado, os filtros 机器学习baseados em tecnologia 垃圾邮件percebem automaticamente que e-mails promocionais de lojas na forma de links curtos se tornam extraordinariamente frequentes em spam sinalizado pelo usuário e os sinalizam sem a sua intervenção.
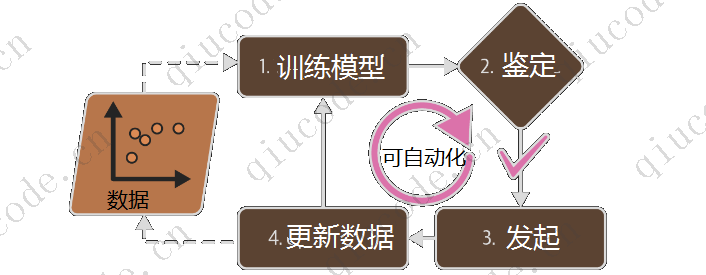
机器学习O destaque é resolver problemas complexos demais para os métodos tradicionais, ou que ainda não possuem algoritmos.
Vamos 语音识别conversar sobre isso! Se você quiser começar de forma simples e escrever um programa que possa distinguir entre um e dois, talvez você possa codificar um algoritmo para detectar a intensidade de sons altos e baixos e usá-lo para distinguir.
Obviamente, esta técnica de codificação não pode ser estendida a milhares de chineses falados por centenas de milhões de pessoas.
Pessoas diferentes usam dezenas de idiomas em ambientes barulhentos. A melhor solução até agora é escrever um 自我学习algoritmo que possa, dados muitos exemplos de gravações de texto, e eventualmente deixá-lo 机器学习aprender como um humano.
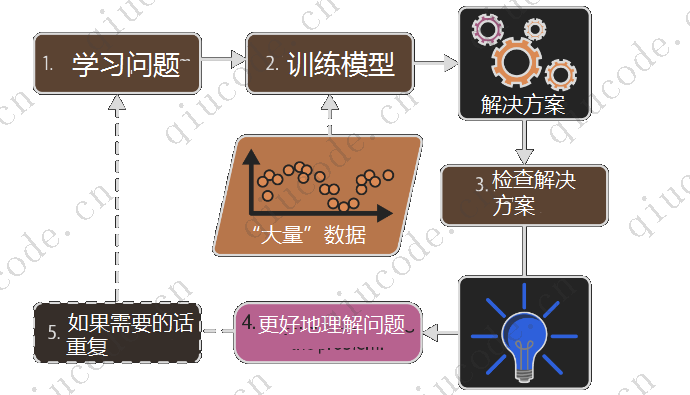
Resumindo, 机器学习é muito adequado para os seguintes cenários:
- As soluções existentes exigem muitos ajustes finos ou longas listas de regras de problemas (os modelos de aprendizado de máquina muitas vezes podem simplificar o código e ter um desempenho melhor do que os métodos tradicionais)
- Problemas complexos que não podem ser resolvidos usando métodos tradicionais (as melhores técnicas de aprendizado de máquina podem encontrar uma solução)
- Ambientes flutuantes (os sistemas de ML podem ser facilmente treinados novamente com novos dados, sempre atualizados)
- Obtenha insights sobre problemas complexos e grandes volumes de dados