Índice
1 Visão geral dos rastreadores da web
1.1 Princípio de funcionamento
2 Desenvolvimento de rastreador da Web
2.1 Processo básico do rastreador da web geral
2.2 Tecnologias comuns de rastreadores da web
2.3 Bibliotecas de terceiros comumente usadas por rastreadores da web
3 Exemplo de rastreador simples
guia de coluna

Endereço de assinatura da coluna: https://blog.csdn.net/qq_35831906/category_12375510.html

1 Visão geral dos rastreadores da web
Um web crawler, também conhecido como web spider ou web robot, é um programa automatizado usado para navegar e obter informações na Internet. Os rastreadores podem percorrer páginas da Web, coletar dados e extrair informações para processamento e análise adicionais. Os rastreadores da Web desempenham um papel importante nos mecanismos de pesquisa, coleta de dados, monitoramento de informações e outros campos.
1.1 Princípio de funcionamento
Seleção de URL inicial : o rastreador começa com um ou mais URLs iniciais, que geralmente são a página inicial ou outras páginas do site que você deseja iniciar o rastreamento.
Enviar solicitação HTTP : para cada URL inicial, o rastreador envia uma solicitação HTTP para obter o conteúdo da página da web. As solicitações podem incluir diferentes métodos HTTP, como GET e POST, e também podem definir cabeçalhos de solicitação, parâmetros e cookies.
Receber resposta HTTP : O servidor retornará uma resposta HTTP, que contém o código HTML da página web e outros recursos, como imagens, CSS, JavaScript, etc.
Analisando o conteúdo da página da Web : o rastreador usa uma biblioteca de análise de HTML (como Beautiful Soup ou lxml) para analisar o código HTML recebido e convertê-lo em uma estrutura DOM (Document Object Model).
Extração e processamento de dados : Por meio da estrutura DOM, os rastreadores extraem as informações necessárias das páginas da Web, como títulos, textos, links, imagens etc. Isso pode ser obtido por meio de seletores CSS, XPath, etc.
Armazenar dados : o rastreador armazena os dados extraídos em arquivos locais, bancos de dados ou outros sistemas de armazenamento para posterior análise e uso.
Descoberta de novos links : ao analisar páginas da Web, o rastreador encontrará novos links e os adicionará à fila de URLs a serem rastreados para que possa continuar rastreando mais páginas.
Processo de repetição : o rastreador executa as etapas acima em um loop, retira o URL da fila de URL inicial, envia uma solicitação, recebe uma resposta, analisa a página da Web, extrai informações, processa e armazena dados, descobre novos links, até o rastreamento tarefa está concluída.
Controle e manutenção : os rastreadores precisam definir a frequência de solicitação apropriada e o atraso para evitar carga excessiva no servidor. Você também precisa monitorar o status de execução do rastreador e lidar com erros e exceções.
1.2 Cenários de aplicação
Mecanismos de pesquisa : os mecanismos de pesquisa usam rastreadores para rastrear o conteúdo da Web e criar índices para que os usuários possam encontrar rapidamente informações relevantes durante a pesquisa.
Coleta de dados : Empresas, instituições de pesquisa, etc. podem usar rastreadores para coletar dados da Internet para análise de mercado, monitoramento da opinião pública, etc.
Agregação de notícias : os rastreadores podem obter títulos de notícias, resumos etc. de vários sites de notícias para plataformas de agregação de notícias.
Comparação de preços : sites de comércio eletrônico podem usar rastreadores para obter preços e informações de produtos concorrentes para análise de comparação de preços.
Análise científica : os pesquisadores podem usar rastreadores para obter literatura científica, trabalhos acadêmicos e outras informações.
1.3 Estratégia do Rastreador
General Crawler e Focused Crawler são duas estratégias diferentes de rastreamento da web usadas para obter informações na Internet. Eles funcionam de maneira diferente e são usados de maneira diferente.
Rastreador geral: Um rastreador geral é um rastreador de propósito geral cujo objetivo é percorrer o maior número possível de páginas da Web na Internet para coletar e indexar o máximo de informações possível. O rastreador geral começará a partir de um URL inicial e, em seguida, explorará mais páginas da Web por meio de rastreamento de links, rastreamento recursivo etc., para criar um índice da Web extenso.
Recursos do Rastreador Universal:
- O objetivo é coletar o máximo de informações possível.
- Comece com um ou mais URLs iniciais e siga a expansão por meio de links.
- Adequado para mecanismos de pesquisa e grandes projetos de indexação de dados.
- O arquivo robots.txt e o mecanismo anticrawler do site precisam ser considerados.
Rastreador focado: um rastreador focado é um rastreador que se concentra em um campo ou tópico específico e rastreia seletivamente páginas da Web relacionadas a um tópico específico. Diferente dos rastreadores de uso geral, os rastreadores focados focam apenas em determinadas páginas da Web específicas para atender a necessidades específicas, como análise de opinião pública, agregação de notícias, etc.
Concentre-se nas características dos répteis:
- Concentre-se em um tópico ou campo específico.
- Rastreie seletivamente páginas da web com base em palavras-chave específicas, regras de conteúdo etc.
- Aplicável a necessidades personalizadas, como monitoramento de opinião pública, agregação de notícias, etc.
- Informações em campos específicos podem ser obtidas com mais precisão.
Em aplicações práticas, rastreadores de uso geral e rastreadores focados têm suas próprias vantagens e usos. Rastreadores de uso geral são adequados para criar índices abrangentes de mecanismos de pesquisa, bem como para análise e mineração de dados em larga escala. Rastreadores focados são mais adequados para necessidades personalizadas e podem obter informações precisas para campos ou tópicos específicos.
1.4 O desafio do rastreador
Mudanças na estrutura do site : A estrutura e o conteúdo do site podem mudar a qualquer momento, e os rastreadores precisam ser ajustados e atualizados.
Mecanismo anti-crawler : alguns sites adotaram medidas anti-crawler, como limitar a frequência de solicitações e usar códigos de verificação.
Limpeza de dados : os dados extraídos de páginas da web podem conter ruídos e precisam ser limpos e organizados.
Questões legais e morais : os rastreadores precisam cumprir as leis e regulamentos, respeitar as regras do site e não abusar ou infringir os direitos e interesses de terceiros.
Resumo : Um rastreador da Web é um programa automatizado usado para obter informações da Internet. Ele coleta e organiza dados por meio de etapas como envio de solicitações, análise de páginas da Web e extração de informações. Em diferentes cenários de aplicação, os rastreadores desempenham um papel importante, mas também precisam enfrentar vários desafios e problemas de conformidade.
2 Desenvolvimento de rastreador da Web
2.1 Processo básico do rastreador da web geral
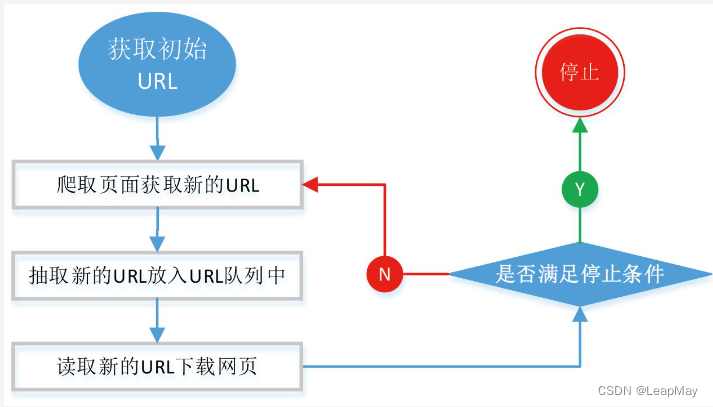
2.2 Tecnologias comuns de rastreadores da web
Um web crawler é um programa automatizado usado para coletar dados da Internet. As tecnologias de rastreador da web comumente usadas e as bibliotecas de terceiros incluem o seguinte:
1. Processamento de solicitação e resposta:
- Requests: Uma biblioteca para envio de requisições HTTP e processamento de respostas, que facilita aos rastreadores a obtenção de conteúdo web.
- httpx: similar
requests, suporta solicitações síncronas e assíncronas, adequado para rastreadores de alto desempenho.2. Analisar e extrair dados:
- Beautiful Soup: usado para analisar documentos HTML e XML e fornecer métodos fáceis para extrair os dados necessários.
- lxml: Uma biblioteca de análise de HTML e XML de alto desempenho que suporta seletores XPath e CSS.
- PyQuery: Uma biblioteca de análise baseada em jQuery que suporta seletores CSS.
3. Renderize páginas da Web dinamicamente:
- Selenium: Uma biblioteca de navegador automatizada para lidar com páginas da Web renderizadas dinamicamente, como conteúdo de carregamento de JavaScript.
4. Processamento assíncrono:
- asyncio e aiohttp: usados para processar solicitações de forma assíncrona e melhorar a eficiência dos crawlers.
5. Armazenamento de dados:
- SQLite, MySQL, MongoDB: O banco de dados é usado para armazenar e gerenciar dados rastreados.
- CSV, JSON: formatos simples para exportar e importar dados.
6. Anticrawler e proxy IP:
- Configuração do agente do usuário: defina o cabeçalho do agente do usuário da solicitação para simular diferentes navegadores e sistemas operacionais.
- Servidor proxy: Use o IP do proxy para ocultar o endereço IP real e evitar o banimento do IP.
- Processamento de captcha: use a tecnologia de reconhecimento de captcha para processar sites que exigem captchas.
7. Robots.txt e conformidade com a política do site:
- robots.txt: Um arquivo que verifica o site
robots.txte segue as regras do site.- Atraso do rastreador: defina o atraso das solicitações do rastreador para evitar carga excessiva no servidor.
8. Estrutura do rastreador:
- Scrapy: Uma poderosa estrutura de rastreamento que fornece muitas funções para organizar o processo de rastreamento.
- Splash: Um serviço de renderização JavaScript, adequado para lidar com páginas da Web dinâmicas.
2.3 Bibliotecas de terceiros comumente usadas por rastreadores da web
Os rastreadores da Web usam uma variedade de tecnologias e bibliotecas de terceiros para obter aquisição de dados, análise e processamento de páginas da Web. As seguintes são tecnologias comumente usadas e bibliotecas de terceiros para rastreadores da web:
1. Biblioteca de solicitações: o núcleo de um rastreador da Web é enviar solicitações HTTP e processar respostas. Aqui estão algumas bibliotecas de solicitação comumente usadas:
- Requests: Uma biblioteca HTTP fácil de usar para enviar solicitações HTTP e processar respostas.
- httpx: um cliente HTTP moderno que oferece suporte a solicitações assíncronas e síncronas.
2. Biblioteca de análise: A biblioteca de análise é usada para extrair os dados necessários de documentos HTML ou XML.
- Beautiful Soup: Uma biblioteca para extrair dados de documentos HTML e XML, suportando consultas e análises flexíveis.
- lxml: Uma biblioteca de análise de XML e HTML de alto desempenho que suporta os seletores XPath e CSS.
3. Repositório de dados: Armazenar os dados rastreados é uma das partes importantes do rastreador.
- SQLAlchemy: Um poderoso kit de ferramentas SQL para manipular bancos de dados relacionais em Python.
- Pandas: Uma biblioteca de análise de dados que pode ser usada para limpeza e análise de dados.
- MongoDB: Um banco de dados não relacional, adequado para armazenar e processar grandes quantidades de dados não estruturados.
- SQLite: Um banco de dados relacional embutido leve.
4. Biblioteca assíncrona: o uso de solicitações assíncronas pode melhorar a eficiência dos rastreadores.
- asyncio: biblioteca IO assíncrona do Python para escrever código assíncrono.
- aiohttp: um cliente HTTP assíncrono que suporta solicitações assíncronas.
5. Processamento de renderização dinâmica: algumas páginas da web usam JavaScript para renderização dinâmica, que precisa ser processada pelo mecanismo do navegador.
- Selenium: Uma biblioteca automatizada de manipulação de navegador para lidar com páginas renderizadas por JavaScript.
6. Resposta à tecnologia anti-crawler: Alguns sites adotam medidas anti-crawler, que requerem algumas técnicas para contornar.
- Pool de proxy: use um IP de proxy para evitar que o acesso frequente ao mesmo IP seja bloqueado.
- Randomização do User-Agent: Altere o User-Agent para emular diferentes navegadores e sistemas operacionais.
Estas são apenas algumas das técnicas e bibliotecas de terceiros comumente usadas pelos rastreadores da web. De acordo com os requisitos reais do projeto, você pode escolher tecnologias e ferramentas apropriadas para obter rastreadores da Web eficientes, estáveis e úteis.
3 Exemplo de rastreador simples
Crie um rastreador simples, como rastrear informações de texto em uma página da Web estática e exibi-las.
import requests
from bs4 import BeautifulSoup
# 发送GET请求获取网页内容
url = 'https://www.baidu.com'
response = requests.get(url)
response.encoding = 'utf-8' # 指定编码为UTF-8
html_content = response.text
# 使用Beautiful Soup解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
# 提取网页标题
title = soup.title.text
# 提取段落内容
paragraphs = soup.find_all('p')
paragraph_texts = [p.text for p in paragraphs]
# 输出结果
print("Title:", title)
print("Paragraphs:")
for idx, paragraph in enumerate(paragraph_texts, start=1):
print(f"{idx}. {paragraph}")