Encontre o método de uso no modelo Models - Hugging Face
One: Como encontrar um método unificado de uso
É o mesmo para o AutoTokenizer de processamento de texto, o nome do modelo pode ser diferente. A operação específica é a seguinte:
1. Primeiro, encontre o modelo que você precisa no modelo e clique em abrir

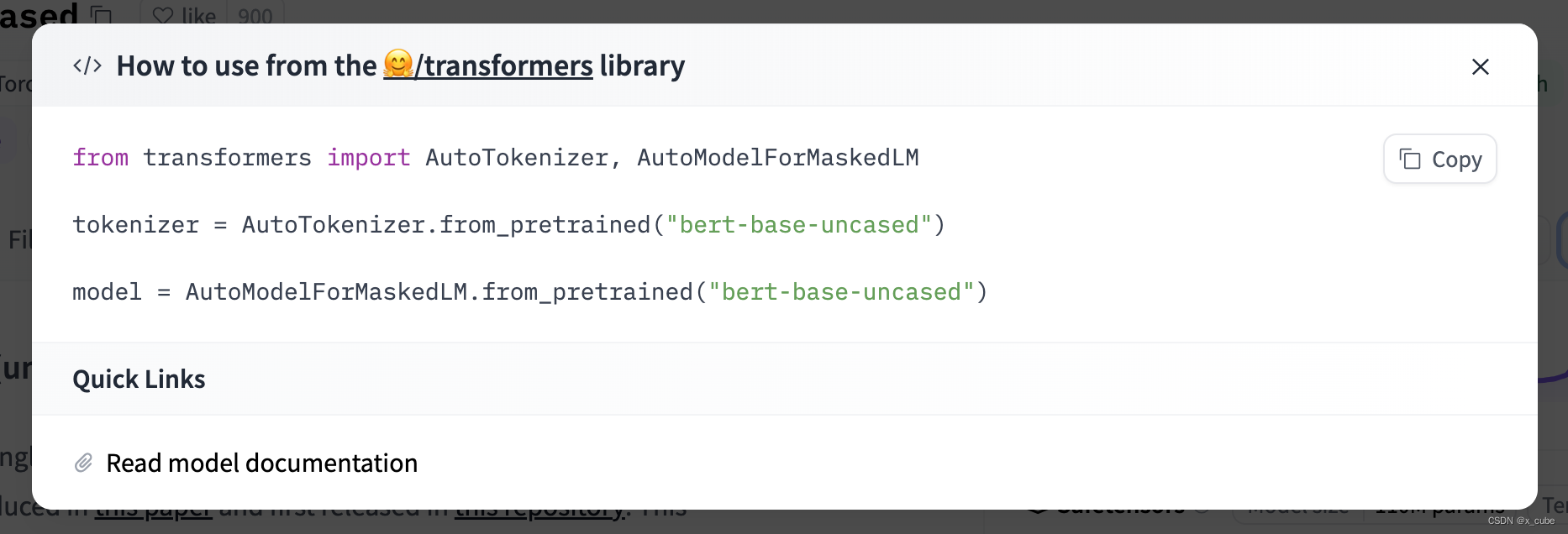
2. Clique em Use in Transformers na extrema direita

Dois: Como descobrir como usar este modelo
Deslize para o final de como usar, é como usar o pytorch, existem outras instruções.

O nome da string pode ser um caminho.
Da mesma forma, as operações de texto são as seguintes:


O método de nomenclatura exclusiva é geralmente:
Nomenclatura do tokenizador: "nome do modelo + tokenizador"
Nomenclatura de processamento de imagem: nome do modelo + ImageProcessor
Nomenclatura do nome do modelo: "nome do modelo +Modal"
Esta nomenclatura está relacionada à empresa, é melhor selecionar diretamente o modelo que você precisa e usá-lo no site oficial.
Três: Os resultados dos dois métodos são os mesmos
# -------------------- 使用 RobertaTokenizer ---------------
tokenizer = RobertaTokenizer.from_pretrained(pretrained_model_path)
inputs = tokenizer("对比原始的分词和最新的分词器", return_tensors="pt")
print(inputs['input_ids'])
# -------------------- 使用 AutoTokenizer ---------------
auto_tokenizer = AutoTokenizer.from_pretrained(pretrained_model_path) # 使用一样的
auto_inputs = auto_tokenizer('对比原始的分词和最新的分词器', return_tensors='pt')
print(auto_inputs['input_ids'])A saída é a mesma.