A recuperação de imagem-texto tem uma ampla gama de aplicações na vida diária.Recuperação de imagem comum inclui pesquisa de conteúdo baseada em texto e pesquisa de conteúdo baseada em imagem. Os usuários podem encontrar rapidamente as mesmas imagens ou imagens semelhantes na enorme biblioteca de imagens inserindo descrições de texto ou fazendo upload de imagens. Este método de pesquisa é amplamente utilizado em campos populares como comércio eletrônico, publicidade, design e mecanismos de pesquisa.
Com base no serviço de pesquisa em nuvem do mecanismo do vulcão ESCloud e no modelo de extração de recurso de texto de imagem CLIP, este artigo cria rapidamente uma solução de ponta a ponta para pesquisar imagens por imagens e pesquisar imagens por texto.
Introdução do princípio
A tecnologia de pesquisa de imagens, usando descrições de texto e imagens como objetos de recuperação, extrai recursos de imagem e texto, respectivamente, e estabelece correlações entre texto e imagens no modelo, então executa a recuperação de vetores de recursos em bancos de dados de imagens massivas e retorna a coleção de objetos de recuperação mais relevantes de registros. Entre eles, a parte de extração de recursos adota o modelo CLIP e a recuperação de vetores usa o serviço de pesquisa em nuvem do motor do vulcão para pesquisar rapidamente entre recursos de imagem massivos.
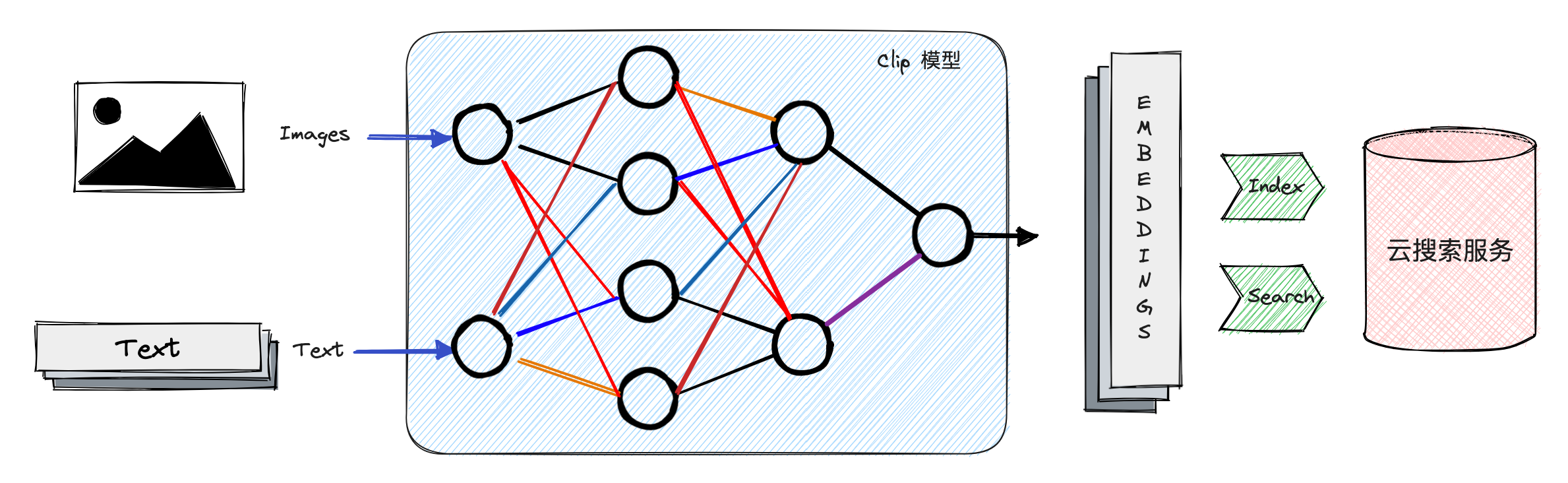
preparação dependente do ambiente
1. Faça login no serviço de pesquisa em nuvem do Volcano Engine, crie um cluster de instância e selecione 7.10 para a versão do cluster.

2.Preparação da dependência da chave do cliente Python
pip install -U sentence-transformers # 模型相关 pip install -U elasticsearch7==7.10.1 # ES向量数据库相关 pip install -U pandas #分析splash的csv
Preparação do conjunto de dados
Escolhemos o Unsplash como o conjunto de dados da imagem. Para obter detalhes, consulte: https://unsplash.com/data. Neste exemplo, optamos por baixar o conjunto de dados Lite, que contém aproximadamente 25.000 fotos. Quando o download for concluído, você receberá um arquivo compactado que contém um arquivo CSV que descreve a imagem. Ao ler o arquivo CSV com Pandas, obteremos o endereço URL da imagem.
def read_imgset(): path = '${下载的数据集所在路径}' documents = ['photos', 'keywords', 'collections', 'conversions', 'colors'] datasets = {} for doc in documents: files = glob.glob(path + doc + ".tsv*") subsets = [] for filename in files: # pd 分析csv df = pd.read_csv(filename, sep='\t', header=0) subsets.append(df) datasets[doc] = pd.concat(subsets, axis=0, ignore_index=True) return datasets
Seleção de modelo
Este artigo seleciona o modelo de pesquisa de imagens por imagens e imagens por texto . Este modelo é treinado com base no modelo do artigo OpenAI 2021. O modelo CLIP pode vincular imagens e texto. O objetivo é obter um modelo que possa expressar ambos imagens e texto clip-ViT-B-32.Modelo
Preparação do Mapeamento ESCloud
PUT image_search { "mappings": { "dynamic": "false", "properties": { "photo_id": { "type": "keyword" }, "photo_url": { "type": "keyword" }, "describe": { "type": "text" }, "photo_embedding": { "type": "knn_vector", "dimension": 512 } } }, "settings": { "index": { "refresh_interval": "60s", "number_of_shards": "3", "knn.space_type": "cosinesimil", "knn": "true", "number_of_replicas": "1" } } }
Operação do banco de dados ESCloud
conectar
Faça login no serviço de pesquisa em nuvem do Volcano Engine, selecione a instância recém-criada e selecione para copiar o endereço de acesso à rede pública (se estiver fechado, você pode optar por abri-lo):

# 连接云搜索实例 cloudSearch = CloudSearch("https://{user}:{password}@{ES_URL}", verify_certs=False, ssl_show_warn=False)
escrever
from sentence_transformers import SentenceTransformer from elasticsearch7 import Elasticsearch as CloudSearch from PIL import Image import requests import pandas as pd import glob from os.path import join # We use the original clip-ViT-B-32 for encoding images img_model = SentenceTransformer('clip-ViT-B-32') text_model = SentenceTransformer('clip-ViT-B-32-multilingual-v1') # Construct request for es def encodedataset(photo_id, photo_url, describe, image): encoded_sents = { "photo_id": photo_id, "photo_url": photo_url, "describe": describe, "photo_embedding": img_model.encode(image), } return encoded_sents # download images def load_image(url_or_path): if url_or_path.startswith("http://") or url_or_path.startswith("https://"): return Image.open(requests.get(url_or_path, stream=True).raw) else: return Image.open(url_or_path) # 从unsplash的csv文件解出图片url,然后下载图片, # 下载完了后用model 生成embedding,并构造成ES的请求进行写入 def get_imgset_and_bulk(): datasets = read_imgset() datasets['photos'].head() kwywords = datasets['keywords'] docs = [] #遍历CSV, 根据photo_url 去download photo for idx, row in datasets['photos'].iterrows(): print("Process id: ", idx) # 获取CSV 中的url photo_url = row["photo_image_url"] photo_id = row["photo_id"] image = load_image(photo_url) # 找到photo_id 且 suggested true 对应的图片描述 filter = kwywords.loc[(kwywords['photo_id'] == photo_id) & (kwywords['suggested_by_user'] == 't')] text = ' '.join(set(filter['keyword'])) # 封装写入ES的请求 one_document = encodedataset(photo_id=photo_id, photo_url=photo_url, describe=text, image=image) docs.append({"index": {}}) docs.append(one_document) if idx % 20 == 0: # 20条一组进行写入 resp = cloudSearch.bulk(docs, index='image_search') print(resp) docs = [] return docs if __name__ == '__main__': docs = get_imgset_and_bulk() print(docs)
Investigar
Pesquisar imagens por texto: vetorização de texto, executar consulta knn
def extract_text(text): # 文搜图 res = cloudSearch.search( body={ "size": 5, "query": {"knn": {"photo_embedding": {"vector": text_model.encode(text), "k": 5}}}, "_source": ["describe", "photo_url"], }, index="image_search2", ) return res fe = FeatureExtractor() @app.route('/', methods=['GET', 'POST']) def index(): # ... resp = fe.extract_text(text) return render_template('index.html', query_text=text, scores=resp['hits']['hits']) # ...
Pesquise por pôr do sol e imprima o resultado

Pesquisar por imagem: vetorização de imagem, executar consulta knn
def extract(img): # 图搜图 res = cloudSearch.search( body={ "size": 5, "query": {"knn": {"photo_embedding": {"vector": img_model.encode(img), "k": 5}}}, "_source": ["describe", "photo_url"], }, index="image_search2", ) return res fe = FeatureExtractor() @app.route('/', methods=['GET', 'POST']) def index(): # ... # Save query image img = Image.open(file.stream) # PIL image uploaded_img_path = "static/uploaded/" + datetime.now().isoformat().replace(":", ".") + "_" + file.filename img.save(uploaded_img_path) # Run search resp = fe.extract(img) return render_template('index.html', query_path=uploaded_img_path, scores=resp['hits']['hits']) # ...
Pesquise fotos de selos e imprima os resultados

O serviço de pesquisa em nuvem do motor do vulcão ESCloud é compatível com Elasticsearch, Kibana e outros softwares e plug-ins de código aberto comumente usados, fornecendo recuperação de várias condições de texto estruturado e não estruturado, estatísticas e relatórios, permitindo implantação com um clique, dimensionamento elástico, simplificação operação e manutenção e construção rápida Recursos de negócios, como análise de toras e análise de recuperação de informações.