Visão geral do conteúdo: O reconhecimento facial pode bloquear a identidade humana. Esta tecnologia é estendida aos cetáceos e existe o "reconhecimento de barbatana dorsal". "Reconhecimento de barbatana dorsal" usa tecnologia de reconhecimento de imagem para identificar espécies de cetáceos através de suas barbatanas dorsais. O reconhecimento de imagem tradicional depende de modelos de rede neural convolucional (CNN), requer um grande número de imagens de treinamento e só pode reconhecer certas espécies únicas. Recentemente, pesquisadores da Universidade do Havaí treinaram um modelo de reconhecimento de imagem multiespécies que teve bom desempenho em aplicações de cetáceos.
Palavras-chave: reconhecimento de imagem cetáceos ArcFace
Autor|daserney
Edit|Devagar, Sanyang
Este artigo foi publicado pela primeira vez na plataforma pública HyperAI Super Neural WeChat ~
Os cetáceos são os animais emblemáticos e organismos indicadores do ecossistema marinho, e têm um valor de investigação extremamente elevado para a proteção do ambiente ecológico marinho. A identificação animal tradicional requer a fotografia dos animais no local para registrar a hora e o local da aparição individual, o que envolve muitas etapas e é um processo complicado. Entre eles, a identificação de correspondência de imagens do mesmo indivíduo em imagens diferentes é particularmente demorada.
Um estudo de Tyne et al., de 2014, estimou que, durante um levantamento de um ano de captura e soltura de golfinhos-pintados (Stenella longirostris), a correspondência de imagens consumiu mais de 1.100 horas de trabalho humano, quase todo o orçamento do projeto, um terço de .
Recentemente, pesquisadores como Philip T. Patton da Universidade do Havaí (Universidade do Havaí) usaram mais de 50.000 fotos (incluindo 24 espécies de cetáceos e 39 categorias) para treinar o ArcFace Classification Head com base no reconhecimento facial. modelo de reconhecimento de imagem multi-espécies. O modelo alcançou uma taxa média de precisão (MAP) de 0,869 no conjunto de teste. Destes, 10 diretórios tiveram uma pontuação MAP superior a 0,95.
A pesquisa foi publicada na revista "Methods in Ecology and Evolution" com o título "Uma abordagem de aprendizado profundo para identificação de foto demonstra alto desempenho em duas dúzias de espécies de cetáceos".

Os resultados da pesquisa foram publicados em "Methods in Ecology and Evolution"
Endereço de papel:
https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/2041-210X.14167
Conjunto de dados: 25 espécies, 39 catálogos
Introdução de dados
Happywhale e Kaggle colaboraram com pesquisadores de todo o mundo para montar um conjunto de dados de cetáceos em grande escala e multiespécies. Este conjunto de dados foi coletado para uma competição Kaggle que pedia às equipes que identificassem cetáceos individuais a partir de imagens de suas barbatanas dorsais/laterais. O conjunto de dados contém 41 catálogos (catálogos) de 25 espécies (espécies), cada catálogo contém uma espécie e algumas espécies no catálogo aparecerão repetidamente.
O estudo removeu dois diretórios de competição porque um tinha apenas 26 imagens de baixa qualidade para treinamento e teste, enquanto o outro não tinha um conjunto de teste. O conjunto de dados final contém 50.796 imagens de treinamento e 27.944 imagens de teste, das quais 50.796 imagens de treinamento contêm 15.546 identidades. Dessas identidades, 9.240 (59%) tinham apenas uma imagem de treinamento e 14.210 (91%) tinham menos de 5 imagens de treinamento.
Conjunto de dados e endereço de código:
GitHub - knshnb/kaggle-happywhale-1º lugar
dados de treinamento
Para resolver o problema de fundos de imagem complexos, alguns competidores treinaram modelos de corte de imagem que podem detectar cetáceos automaticamente em imagens e desenhar caixas delimitadoras ao redor deles. Como pode ser visto na figura abaixo, este processo inclui 4 detectores de cetáceos, usando diferentes algoritmos, incluindo YOLOv5 e Detic. A diversidade de detectores aumenta a robustez do modelo e pode melhorar os dados experimentais. .

Figura 1: Imagens de 9 categorias no conjunto de competição e caixas delimitadoras geradas por 4 detectores de cetáceos
Cada caixa delimitadora gera uma colheita com uma probabilidade de: 0,60 para vermelho, 0,15 para verde oliva, 0,15 para laranja e 0,05 para azul. Após o corte, os pesquisadores redimensionaram cada imagem para 1024 x 1024 pixels para compatibilidade com o backbone EfficientNet-B7.
Após o redimensionamento, aplique técnicas de aumento de dados, como transformação afim, redimensionamento e corte, escala de cinza, desfoque gaussiano, etc., para evitar superajuste severo do modelo .
O aumento de dados refere-se à transformação ou expansão dos dados originais durante o processo de treinamento para aumentar a diversidade e a quantidade de amostras de treinamento, melhorando assim a capacidade de generalização e a robustez do modelo.
Treinamento Modelo: Reconhecimento de Espécies e Indivíduos em duas frentes
A figura abaixo mostra o processo de treinamento do modelo. Conforme mostrado na parte laranja da figura, os pesquisadores dividiram o modelo de reconhecimento de imagem em três partes: coluna vertebral, pescoço e cabeça.
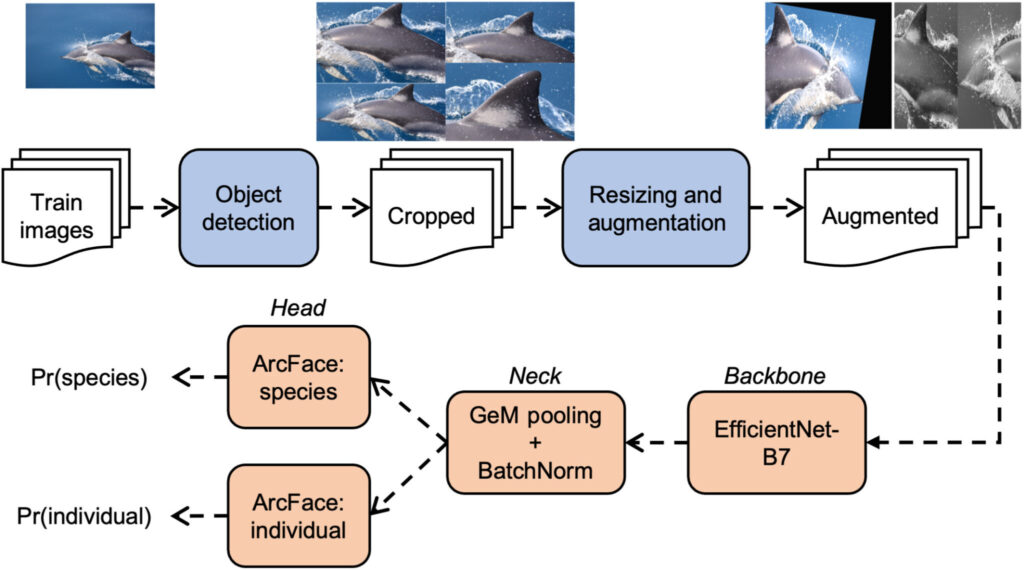
Figura 2: pipeline de treinamento do modelo de reconhecimento de imagem multiespécie
A primeira linha na figura é a etapa de pré-processamento (tome a imagem do golfinho comum Delphinus delphis como exemplo), as colheitas são geradas por 4 modelos de detecção de alvos e duas imagens de amostra são geradas pela etapa de aprimoramento de dados.
A linha inferior mostra as etapas de treinamento da rede de classificação de imagens, do backbone ao pescoço e à cabeça.
As imagens primeiro entram no backbone pela rede. Uma série de pesquisas na última década produziu dezenas de backbones populares, incluindo ResNet, DenseNet, Xception e MobileNet. O EfficientNet-B7 foi verificado para ter o melhor desempenho em aplicações de cetáceos.
Depois que o Backbone obtém uma imagem, ele a processa por meio de uma série de camadas convolucionais e de agrupamento para produzir uma representação 3D simplificada da imagem. Neck reduz essa saída a um vetor unidimensional, também conhecido como vetor de recursos.
Ambos os modelos de cabeça convertem vetores de características em probabilidades de classe, ou seja, Pr(espécie) ou Pr(indivíduo), para identificação de espécies e identificação individual, respectivamente. Essas cabeças de classificação são chamadas ArcFace subcêntricas com margens dinâmicas, que geralmente são aplicáveis a cenários de reconhecimento de imagens multiespécies.
Resultados experimentais: precisão média 0,869
As previsões foram feitas em 21.192 imagens no conjunto de teste (39 categorias de 24 espécies), alcançando uma precisão média (MAP) de 0,869. Conforme mostrado na figura abaixo, a precisão média varia entre as espécies e é independente do número de imagens de treinamento ou imagens de teste.
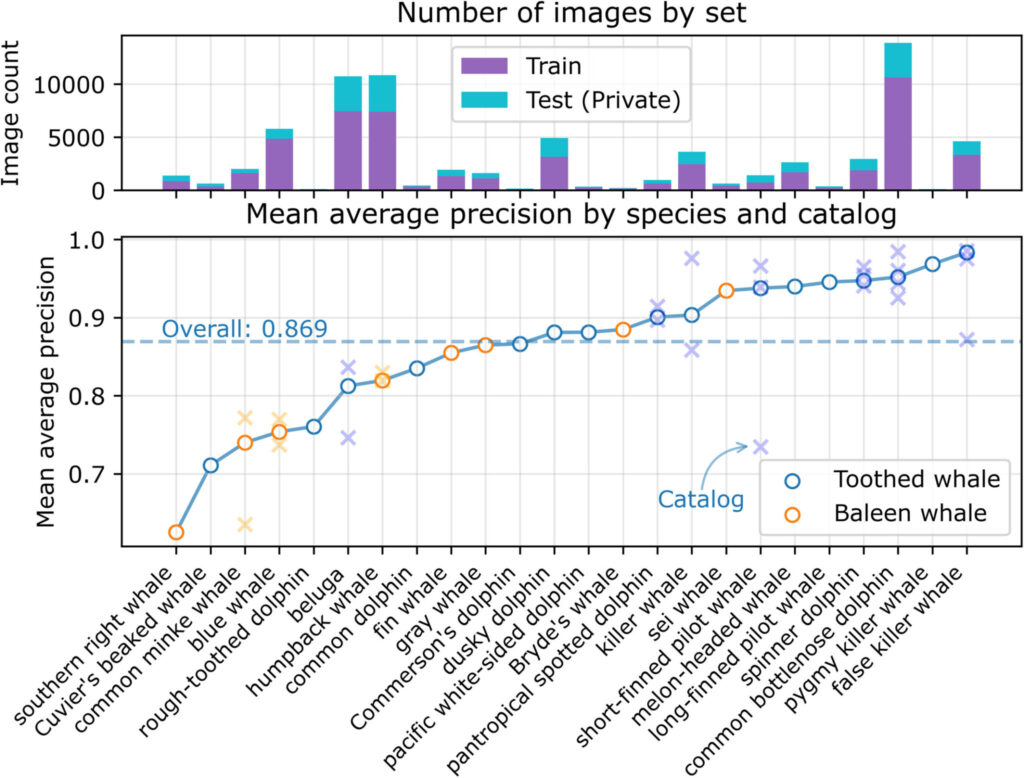
Figura 3: Precisão média no conjunto de teste
O painel superior mostra o número de imagens para cada espécie por uso (ou seja, treinamento ou teste). Espécies com múltiplos catálogos são representadas por x.
A figura mostra que o modelo teve melhor desempenho na identificação de baleias dentadas e pior na identificação de baleias de barbatanas, com apenas duas espécies de baleias de barbatanas pontuando acima da média.
Também houve diferenças no desempenho do modelo para espécies multicategorias. Por exemplo, as pontuações MAP entre diferentes categorias da baleia minke comum (Balaenoptera acutorostrata) são 0,79 e 0,60, respectivamente. Outras espécies, como baleias beluga (Delphinapterus leucas) e orcas, também mostraram grandes diferenças de desempenho entre os catálogos.
A esse respeito, embora os pesquisadores não tenham encontrado uma razão que pudesse explicar essa diferença de desempenho em nível de categoria, eles descobriram que alguns indicadores qualitativos, como ambigüidade, singularidade, confusão de marcadores, distância, contraste e salpicos, podem afetar a pontuação de precisão do imagem.

Figura 4: Variáveis que podem afetar as diferenças de desempenho no nível do diretório
Cada ponto na figura representa uma categoria no conjunto de dados da competição e os pixels representam a imagem e a largura da caixa delimitadora. IDs distintos representam o número de indivíduos distintos no conjunto de treinamento. No entanto, não há correlação clara entre MAP em nível de catálogo e largura média da imagem, largura média da caixa delimitadora, número de imagens de treinamento, número de indivíduos distintos e número de imagens de treinamento por indivíduo.
Com base no exposto, os pesquisadores propuseram que, quando o modelo é usado para previsão, a precisão média de 10 catálogos representando 7 espécies é superior a 0,95 e o desempenho é melhor do que o modelo de previsão tradicional, o que mostra ainda que o uso do modelo pode identificar corretamente os indivíduos. Além disso, os pesquisadores também resumiram 7 pontos de atenção na pesquisa de cetáceos durante o experimento:
- A identificação da nadadeira dorsal teve o melhor desempenho.
- Diretórios com menos recursos individuais distintos têm desempenho ruim.
- A qualidade da imagem é importante.
- Identificar os animais pela cor pode ser difícil.
- Espécies com maiores diferenças nas características em relação ao conjunto de treinamento pontuam mais pobres.
- O pré-processamento continua sendo um obstáculo.
- As variações nos marcadores animais podem afetar o desempenho do modelo.
Happywhale: Uma plataforma de ciência cidadã para pesquisa de cetáceos
Happywhale, mencionado na introdução do conjunto de dados neste artigo, é uma plataforma de ciência cidadã para compartilhar imagens de cetáceos com o objetivo de desbloquear conjuntos de dados massivos, facilitar a correspondência rápida de IDs com fotos e criar engajamento científico para o público.

Endereço do site oficial do Happywhale:
A Happywhale foi fundada em agosto de 2015. Seu cofundador, Ted Cheeseman, é naturalista. Ele cresceu em Monterey Bay, Califórnia. Ele adorava observar baleias desde criança e já viajou várias vezes para a Antártica e a África do Sul. Ilha da Geórgia Expedition, com mais de 20 anos de experiência em exploração antártica e gestão de turismo polar.

Ted Cheeseman, co-fundador da Happywhale
Em 2015, Ted deixou a Cheesemans' Ecology Safaris (uma agência de viagens ecológicas fundada em 1980 pelos pais de Ted, que também são naturalistas) que trabalhou por 21 anos para se dedicar ao projeto Happywhale - coletando dados de pesquisas científicas para melhor entender e proteger baleias .
Em apenas alguns anos, Happywhale.com tornou-se um dos maiores contribuintes para o campo da pesquisa de cetáceos, oferecendo muitos insights sobre a compreensão dos padrões de migração de cetáceos, além do grande volume de imagens de identificação de cetáceos.
Link de referência:
[1] https://baijiahao.baidu.com/s?id=1703893583395168492
[2]https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0086132
[3]https://phys.org/news/2023-07-individual-whale-dolphin-id-facial.html#google_vignette
[4] https://happywhale.com/about
Este artigo foi publicado pela primeira vez na plataforma pública HyperAI Super Neural WeChat ~