1. Como criar um índice
- Método 1: Especifique a coluna de índice ao criar a tabela
- Método 2: Criar um índice usando ALTER TABLE
- Método 3: Use CREATE TABLE para criar um índice
2. A forma de visualizar o índice na tabela
- Método 1: Use a instrução SHOW INDEX FROM nome da tabela; instrução para exibir o índice na tabela
como:
- Método 2: Use a instrução SHOW CREATE TABLE STUDENT01; instrução para visualizar a instrução DDL da tabela, você pode ver explicitamente a instrução de criação do índice
como:
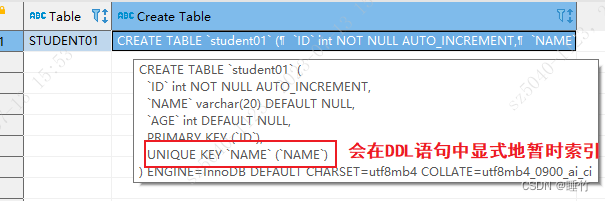
3. Especifique a coluna do índice ao criar a tabela
3.1. Criação implícita de índice
- Em campos declarados com restrições de chave primária, restrições exclusivas e restrições de chave estrangeira, os índices relacionados serão adicionados automaticamente
--创建学生表01,指定ID为主键,此时会自动添加主键索引
CREATE TABLE STUDENT01(
ID INT PRIMARY KEY AUTO_INCREMENT
,NAME VARCHAR(20) UNIQUE
,AGE INT
)
- Observe o método de índice 1 na tabela:
--查看当前表的索引
SHOW INDEX FROM STUDENT01;Os resultados do índice são os seguintes:
- Observe o método de índice 2 na tabela:
SHOW CREATE TABLE STUDENT01;O resultado é o seguinte:
Nota: Uma restrição de chave estrangeira é uma restrição entre tabelas, não um índice
Caso chave estrangeira:
--案例:
--创建TEACHER01表
CREATE TABLE TEACHER01(
ID INT PRIMARY KEY AUTO_INCREMENT
,NAME VARCHAR(20) UNIQUE
)
--创建STUDENT18表,ID与TEACHER01表中的ID关联
CREATE TABLE STUDENT18(
ID INT PRIMARY KEY AUTO_INCREMENT
,NAME VARCHAR(20) UNIQUE
,AGE INT
,CONSTRAINT STUDENT18_ID_FK FOREIGN KEY(ID) REFERENCES TEACHER01(ID) --创建外键
)
--查看索引
SHOW INDEX FROM STUDENT18;Resultados do índice na tabela STUDENT18:

3.2. Crie índices explicitamente
Formato gramatical:
CREATE TABLE nome da tabela (
nome da coluna 1 tipo de coluna 1 ,
nome da coluna 2 tipo de coluna 2 ,
...
[ÚNICO | TEXTO COMPLETO | ESPACIAL] [ÍNDICE | CHAVE] Nome do índice (nome da coluna [tamanho do índice]) [DESC | AESC]
)
- UNIQUE, FULLTEXT, SPATIAL: Parâmetros opcionais, representando índice exclusivo, índice de texto completo e índice espacial, respectivamente
- INDEX e KEY são sinônimos: ambos têm a mesma função e são usados para especificar a criação de um índice
- Nome do índice: parâmetro opcional, se omitido, o MySQL usa o nome da coluna como o nome do índice por padrão
- Comprimento do índice: parâmetro opcional, apenas campos do tipo string podem especificar o comprimento do índice
- ASC/DESC: Especifique se o valor do índice armazena os valores em ordem crescente ou decrescente
criar índice normal
--创建学生表02,指定NAME为普通索引
CREATE TABLE STUDENT02(
ID INT
,NAME VARCHAR(20)
,AGE INT
,INDEX idx_name(name)
)
--查看索引
SHOW INDEX FROM STUDENT02;Os resultados da consulta de índice são os seguintes:

Crie um índice exclusivo (vários valores nulos podem ser adicionados)
--创建学生表03,指定ID为唯一索引
CREATE TABLE STUDENT03(
ID INT
,NAME VARCHAR(20)
,AGE INT
,UNIQUE INDEX idx_name(ID)
)Índice exclusivo de teste:
--给STUDENT03表插入3条数据
INSERT INTO STUDENT03(id,name,age)
VALUES(1,'张三',18);
INSERT INTO STUDENT03(id,name,age)
VALUES(null,'张三',18);
INSERT INTO STUDENT03(id,name,age)
VALUES(null,'张三',18);
--查看所有数据
SELECT * FROM STUDENT03;O resultado é o seguinte:

Resumo: Um índice único não pode inserir repetidamente os mesmos dados, mas vários valores nulos podem ser adicionados
Criar índice de chave primária
- O índice de chave primária é criado por meio da restrição de chave primária, que é a maneira de criar o índice implicitamente
Elimine o índice de chave primária:
ALTER TABLE 表名 DROP PRIMARY KEY;Observação: quando a chave primária é autoincrementada, você precisa excluir o autoincremento primeiro e, em seguida, excluir a chave primária
Criar um índice conjunto
--创建学生表04,指定NAME、AGE和SCORE为联合索引
CREATE TABLE STUDENT04(
ID INT
,NAME VARCHAR(20)
,AGE INT
,SCORE decimal
,INDEX idx_name_age(NAME,AGE,SCORE)
);
--查看索引
SHOW INDEX FROM STUDENT04;O resultado é o seguinte:

Perceber:
- Como a ordem dos campos é NAME, AGE, SCORE quando o índice é criado, a ordem de construção da árvore B+ também é organizada primeiro por NAME, depois por AGE e finalmente por SCORE
- Princípio do prefixo mais à esquerda: se você quiser usar o índice comum, se não houver nome de campo mais à esquerda na condição where, o índice falhará
Podemos usar a palavra-chave EXPLAIN teste:
- Teste 1: Todos os campos no índice conjunto são incluídos na condição where
--EXPLAIN 测试索引,where条件中使用了NAME,AGE,SCORE
EXPLAIN
SELECT
*
FROM STUDENT04
WHERE
NAME = '张三'
AND AGE = 18
AND SCORE = 85O resultado é o seguinte: A instrução SQL acima usa o índice

- Teste 2: O campo intermediário AGE no índice comum não está incluído na condição where
--EXPLAIN 测试索引,where条件中使用了NAME,SCORE,没有使用中间的字段AGE
EXPLAIN
SELECT
*
FROM STUDENT04
WHERE
NAME = '张三'
AND SCORE = 85O resultado é o seguinte: A instrução SQL acima usa o índice

- Teste 3: A condição where não inclui o nome do campo mais à esquerda no índice comum
EXPLAIN
SELECT
*
FROM STUDENT04
WHERE
AGE = 18
AND SCORE = 85O resultado é o seguinte: O índice da instrução SQL acima é inválido

- Teste 4: crie um índice exclusivo para o nome do campo mais à esquerda e teste se deve usar um índice de coluna única ou um índice conjunto
Observação: Este teste deve garantir que os dados existam na tabela, caso contrário, o efeito não poderá ser visualizado!
--给STUDENT04表插入3条数据
INSERT INTO STUDENT04(id,name,age,score)
VALUES(1,'张三',18,85);
INSERT INTO STUDENT04(id,name,age,score)
VALUES(1,'李四',18,85);
INSERT INTO STUDENT04(id,name,age,score)
VALUES(1,'王五',18,85);
--测试索引执行情况
EXPLAIN
SELECT
*
FROM STUDENT04
WHERE
NAME = '张三'
AND AGE = 18
AND SCORE = 85O resultado é o seguinte: A instrução SQL usa um índice exclusivo em vez de um índice conjunto

Resumo de uso do índice combinado
- Siga o princípio do prefixo mais à esquerda: quando o campo mais à esquerda do índice comum não for usado na condição where, o índice falhará
De acordo com o princípio de estabelecimento da árvore B+: os registros de dados no nó são classificados primeiro de acordo com o campo mais à esquerda e depois classificados de acordo com a ordem dos outros campos no índice. Portanto, se o campo mais à esquerda não for usado como condição in where, Então a classificação inicial (entrada) dos registros de dados do nó da árvore B+ não é usada e os campos classificados posteriormente não terão efeito, resultando em falha de índice
- A ordem dos campos na condição where não afeta o índice comum
- Na condição where, desde que o campo mais à esquerda seja usado, o índice de junção entrará em vigor
- Quando uma tabela tem vários índices para ir, qual índice para ir será selecionado de acordo com o custo de consulta do otimizador
4. Após a criação da tabela, use ALTER TABLE para adicionar índices
gramática:
ALTER TABLE nome da tabela ADD [tipo de índice] INDEX nome do índice (nome do campo);
- O nome do índice pode ser omitido
- [Tipo de índice]: pode ser omitido, a omissão é um índice normal, se o tipo de índice for especificado, então INDEX também pode ser omitido
como:
CREATE TABLE STUDENT05(
ID INT
,NAME VARCHAR(20)
,AGE INT
,SCORE decimal
);
--给STUDENT05表SCORE字段创建普通索引
ALTER TABLE STUDENT05 ADD INDEX (score);
--给STUDENT05表NAME字段创建唯一索引
ALTER TABLE STUDENT05 ADD UNIQUE IDX_NAME(NAME);
--给STUDENT05表NAME,AGE,SCORE字段创建联合索引
ALTER TABLE STUDENT05 ADD INDEX IDX_NAME_AGE_SCORE(NAME,AGE,SCORE);5. Após a criação da tabela, use CREATE INDEX para adicionar o índice
gramática:
CREATE [tipo de índice] INDEX nome do índice ON nome da tabela (nome do campo);
- O tipo de índice pode ser omitido
- O nome do índice não pode ser omitido
- A palavra-chave INDEX não pode ser omitida
como:
CREATE TABLE STUDENT06(
ID INT
,NAME VARCHAR(20)
,AGE INT
,SCORE decimal
);
--给STUDENT06表SCORE字段创建普通索引
CREATE INDEX idx_score ON STUDENT06(SCORE);
--给STUDENT06表NAME字段创建唯一索引
CREATE UNIQUE INDEX idx_name ON STUDENT06(NAME);
--给STUDENT05表NAME,AGE,SCORE字段创建联合索引
CREATE UNIQUE INDEX IDX_NAME_AGE_SCORE ON STUDENT06(NAME,AGE,SCORE);6. A diferença entre o método ALTER TABLE e o método CREATE INDEX
- Ao criar um índice não comum no modo ALTER, a palavra-chave INDEX pode ser omitida, mas no modo CREATE o INDEX não pode ser omitido
- O método ALTER não precisa especificar o nome do índice, e o nome do campo é usado como o nome do índice por padrão, enquanto o método C REATE não pode omitir o nome do índice
7. Exclua o índice
Cenário de exclusão de índice:
- O número de índices da tabela é grande. Quando um grande número de adições, exclusões e alterações são necessárias, os índices podem ser excluídos primeiro e, em seguida, os dados podem ser excluídos.
Método 1:
ALTER TABLE nome da tabela DROP nome do índice;
Método 2:
DROP INDEX nome do índice ON nome da tabela;
Perceber:
- Quando o campo de um índice de coluna única for excluído, o índice será excluído automaticamente
- Quando um campo do índice conjunto é excluído, o índice conjunto excluirá automaticamente o campo
8. Índice descendente
- Os índices armazenam valores-chave em ordem crescente por padrão
- Na sintaxe do MySQL. A sintaxe de índice descendente é suportada desde a versão 4.0, mas na verdade a definição DESC é ignorada
- A versão MySQL8.0 começou a realmente oferecer suporte ao índice descendente (suportado apenas pelo InnoDB)
O índice ascendente criado pelo MySQL antes de 8.0 ainda é usado para verificação reversa, o que reduz muito a eficiência do banco de dados.
Em alguns cenários, os índices descendentes são de grande importância. Por exemplo:
Se uma consulta precisar classificar várias colunas e os requisitos de ordem forem inconsistentes, o uso de um índice decrescente evitará que o banco de dados use operações adicionais de classificação de arquivos , melhorando assim o desempenho.
caso:
1> No MySQL8, ao criar uma tabela, crie um índice conjunto e especifique a em ordem crescente e b em ordem decrescente no índice
CREATE TABLE STUDENT07(
a INT
,b INT
,INDEX IDX_A_B(a ASC,b DESC)
);2> Insira 799 partes de dados simulados usando procedimentos armazenados
-- 创建存储过程
DELIMITER //
CREATE PROCEDURE STUDENT07_insert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<800
DO
insert into STUDENT07 select rand()*80000,rand()*80000;
SET i=i+1;
END WHILE;
commit;
END //
DELIMITER ;
-- 调用存储过程
CALL STUDENT07_insert();3> Teste usando índice decrescente
EXPLAIN SELECT * FROM STUDENT07 ORDER BY a,b DESC LIMIT 5;Resultado: Isso prova que a classificação usa o índice e o desempenho é bom

4> Exclua o índice conjunto acima, crie um novo índice conjunto, a é ascendente, b também é ascendente (simulando versões abaixo do MySQL8)
-- 删除原来的索引
DROP INDEX IDX_A_B ON STUDENT07;
-- 创建新的联合索引,a升序,b也升序(模拟MySQL8以下的版本)
CREATE INDEX IDX_A_B ON STUDENT07(a,b); --默认就是升序的5> teste não usa índice decrescente
EXPLAIN SELECT * FROM STUDENT07 ORDER BY a,b DESC LIMIT 5;Resultado: filesort usado (filesort, desempenho ruim)
