Agora vou apresentar um experimento utilizando myCobot. Desta vez, os experimentos serão realizados usando simuladores Ao tentar fazer aprendizado de reforço profundo com robôs , pode ser um desafio preparar grandes quantidades de dados de treinamento em máquinas físicas. No entanto, com simuladores, é fácil coletar grandes conjuntos de dados. No entanto, os emuladores podem parecer intimidadores para aqueles que não estão familiarizados com eles. Então, tentamos usar o Isaac Gym, desenvolvido pela Nvidia, que nos permite fazer de tudo, desde a criação de ambientes experimentais até o aprendizado por reforço usando apenas código Python . Neste post, descreverei o método que usamos.
1. Introdução
1.1 O que é o Isaac Gym?
Isaac Gym é um ambiente de simulação de física desenvolvido pela Nvidia para aprendizado por reforço. Com base na biblioteca Open AI Gym, os cálculos físicos são realizados na GPU e os resultados podem ser recebidos como tensores de GPU Pytorch, permitindo simulação e aprendizado rápidos. As simulações de física são realizadas usando o PhysX, que também oferece suporte a simulações de corpos moles usando o FleX (embora algumas funcionalidades sejam limitadas ao usar o FleX).
A versão de abril de 2023 é a Prévia 3. Embora as versões anteriores tivessem bugs gritantes, a versão 6000 e posteriores tiveram melhorias e recursos adicionados, tornando-o um ambiente de simulação muito atraente. Uma versão futura do Omniverse Isaac Gym que se integra ao Isaac Sim está planejada. No entanto, o próprio Isaac Gym é independente e está disponível para experimentos em Python. Em uma postagem de blog anterior ("GPU Server Scaling and A<> Benchmarking"), foi mencionado que a pesquisa e o desenvolvimento usando o simulador Omniverse Isaac foram iniciados, mas o Isaac Gym foi priorizado para simulações de aprendizado por reforço. Talvez o maior benefício de integrar o Isaac Gym com o Omniverse seja a capacidade de usar visuais fotorrealistas para reconhecimento de imagem e simulação corporal contínua de alta precisão, como rastreamento de raios. Será emocionante ver como o futuro se desenvolve.
PhysX é um mecanismo de física desenvolvido pela Nvidia que executa cálculos de física em tempo real na GPU do emulador. Embora a versão usada por Isaac Gym não tenha sido especificada no arXiv público ou na documentação, é provável que seja baseada no PhysX 4, devido ao seu tempo e separação do FleX. No Omniverse, o PhysX 5 é usado e o FleX é integrado.
O FleX também é um mecanismo de física desenvolvido pela Nvidia, mas comparado à simulação de corpo rígido do PhysX, ele é capaz de usar a simulação baseada em partículas para representar corpos moles e fluidos.
1.2 Objetivo deste artigo
Vou contar como crio e aprendo facilmente tarefas de aprendizado por reforço usando o Isaac Gym. como um caso de teste real
1.3 Ambiente
PC1: Ubuntu 20.04, Python 3.8.10, Nvidia RTX A6000
PC2: Ubuntu 18.04, Python 3.8.0, Nvidia RTX 3060 Ti
Observe que Nvidia Driver 470 ou superior é necessário.
2. Instale
Neste capítulo, instalaremos o Isaac Gym e o IsaacGymEnvs. O ambiente recomendado é Ubuntu 18.04, 20.04, Python 3.6~3.8, Nvidia Driver==470. Observe que, como python_requires<3.9 é descrito em setup.py do Isaac Gym, ele não pode ser usado como está para 3.9 e superior. Não testei no Ubuntu 22.04, mas provavelmente ok.
2.1 Academia de Isaac
Você pode baixar o pacote principal do Isaac Gym gratuitamente na página do desenvolvedor da Nvidia . A documentação é mantida em formato HTML no diretório "docs" do pacote (não no site, note). Uma vez baixado, você pode instalá-lo com o seguinte comando:
$ cd isaacgym/python$ pip install -e .cópia de
No entanto, como o PyTorch é especificado como "torch==1.8.0" e "torchvision==0.9.0", ao usar uma GPU, você deve primeiro instalá-lo a partir da página oficial correspondente ao seu ambiente. Os arquivos de configuração do ambiente virtual Docker e Conda também estão disponíveis. Como uso o venv para gerenciar meus ambientes virtuais Python, continuarei com o pip. Observe que escrevi ">" com caracteres de largura dupla devido a problemas de bloco de código
2.2IsaacGymEnvs
IsaacGymEnvs é um pacote Python para testar ambientes de aprendizado por reforço no Isaac Gym. Com referência às tarefas implementadas, os ambientes de aprendizado por reforço podem ser facilmente construídos usando os algoritmos de aprendizado por reforço implementados em jogos rl. Mesmo para aqueles que planejam escrever seus próprios algoritmos de aprendizado por reforço, é recomendável experimentar este pacote para aprender com o Isaac Gym. Ele foi originalmente incluído no Isaac Gym, distribuído no Preview3 e agora está disponível publicamente no GitHub.
$ git clone https://github.com/NVIDIA-Omniverse/IsaacGymEnvs.git$ cd IsaacGymEnvs$ pip install –e .cópia de
Com isso, a instalação necessária está concluída.
3. Demonstração
Ao instalar o Isaac Gym e examinar o pacote, você verá que há muitos ambientes de exemplo disponíveis. Eles também aparecem na documentação, mas neste artigo vamos nos concentrar em alguns exemplos relevantes para a criação de ambientes personalizados de aprendizado por reforço no Capítulo 4. Se você tiver seu ambiente configurado, é uma boa ideia tentar executar alguns desses exemplos e ver o que eles podem fazer. Você pode até achar que eles fornecem alguma orientação sobre como usar a API para realizar algo que você está interessado em tentar (sinta-se à vontade para ler a documentação se ainda não tiver certeza).
3.1.Academia Isaac
A partir do Preview 4, 27 ambientes de amostra estão disponíveis.
● “1080_balls_of_solitude.py”
O script "1080_balls_of_solitude.py" gera um conjunto de bolas em forma de pirâmide que caem. A execução do script sem opções permite apenas colisões entre esferas dentro do mesmo ambiente (ou seja, dentro da mesma pirâmide). A opção "--all_collisions" permite colisões com bolas em outros ambientes, enquanto a opção "--no_collisions" desabilita colisões entre objetos no mesmo ambiente. Este script também demonstra como configurar os parâmetros da função "create_actor" para adicionar objetos ao ambiente.
● “dof_controls.py”
Este script possui um Actor que se move em 3D, que é uma variação do conhecido problema Cartpole no OpenAI Gym. Demonstra como configurar um método de controle para cada grau de liberdade (DOF) do robô, seja posição, velocidade ou força. Uma vez definidos, esses métodos de controle não podem ser alterados durante a simulação, e os Atores só podem ser controlados pelo método escolhido. Esquecer de definir esses métodos de controle pode resultar na imobilização do atuador.
● “franka_nut_bolt_ik_osc.py”
Este script mostra o braço robótico articulado da Franka Robotics, Panda, pegando uma porca e aparafusando-a em um parafuso. Os braços são controlados usando cinemática inversa (IK). O nome do arquivo inclui "OSC", mas o controle OSC não é implementado neste script. No entanto, o script "franka_cube_ik_osc.py" inclui o controle OSC.
Com a adição de colisões SDF no Preview 4, arquivos de colisão de alta resolução podem ser carregados, permitindo o cálculo preciso das colisões entre as ranhuras da porca e do parafuso (Figura 1). Embora o carregamento inicial do SDF possa levar algum tempo, os carregamentos subsequentes são armazenados em cache e iniciados rapidamente.

Figura 1: Simulação de um braço de panda enfiando uma porca em um parafuso
● interop_torch.py
Este script demonstra como usar a função get_camera_image_gpu_tensor para obter dados do sensor diretamente de uma câmera na GPU . Os dados obtidos podem ser gerados como um arquivo de imagem usando o OpenCV, assim como uma câmera física comum. Quando executado, o script cria um diretório chamado interop_images e salva as imagens da câmera lá. Como os dados de simulação não são trocados entre GPU e CPU , as imagens podem ser processadas rapidamente. No entanto, podem ocorrer erros ao usar um ambiente multi-GPU. Uma solução sugerida nos fóruns é limitar o uso da GPU para CUDA_VISIBLE_DEVICES=0, mas isso não funciona no ambiente usado para este script.
3.2. Ambiente do Isaac Gym
14 tarefas de aprendizado por reforço são implementadas e podem ser comparadas usando scripts no diretório de tarefas.
● Sobre os arquivos de configuração
Prepare um arquivo de configuração escrito em YAML para cada tarefa. As configurações comuns estão localizadas em config.yaml no diretório cfg e podem ser alteradas com Hydra usando opções de linha de comando sem alterar o arquivo YAML. As configurações detalhadas para cada ambiente de tarefa e PhysX são armazenadas no diretório cfg/task/, e as seleções e estruturas de algoritmo são armazenadas no diretório cfg/train/.
● Sobre a implementação do algoritmo
O algoritmo de aprendizado por reforço é implementado usando PPO no jogo Rl. Embora docs/rl_examples.md mencione a opção de selecionar SAC, atualmente não está incluído no repositório.
As camadas NN são geralmente MLPs, e alguns modelos também incluem camadas LSTM como camadas RNN. Não há modelos de exemplo que incluam camadas CNN, embora camadas CNN também possam ser adicionadas. Na Seção 5.2, discutimos a experiência de adicionar camadas CNN ao modelo.
O código de exemplo pode ser executado no diretório isaacgymenvs onde train.py está localizado.
● Barra de cárter
python train.py task=Cartpole [opções]
Esta é a tarefa clássica do carrinho, e o objetivo é mover o carrinho de forma que o mastro não caia. Por padrão, o modelo treina por 100 épocas, o que leva cerca de 3.060 minutos em um ambiente PC2 RTX 2Ti e apenas 15 segundos no modo headless (sem visualizador). Ao testar o modelo com inferência, ele tem um bom desempenho e o bastão permanece na posição vertical (após 30 épocas de treinamento, o modelo é treinado o suficiente para manter o bastão na posição vertical). Embora aparentemente simples, o fato de que o modelo pode aprender a fazer essa tarefa com sucesso é reconfortante.
● Pilhas de cubo Franke
python train.py task=FrankaCubeStack [opções]
Esta é uma tarefa de empilhar caixas usando um braço de panda. A articulação do braço de 7 eixos é aprendida passo a passo. A configuração padrão é de 10.000 épocas, mas os movimentos do braço podem ser aprendidos em cerca de 1.000 épocas. Em um ambiente PC1 RTX A6000, leva cerca de 20 a 30 minutos para concluir o treinamento de 1.000 épocas. As Figuras 2 e 3 mostram o estado do braço antes e depois, desde o movimento aleatório até o agarrar e empilhar as caixas com sucesso.
O espaço de ação consiste em 7 dimensões das articulações do braço, enquanto o espaço de observação tem um total de 26 dimensões. A função de recompensa foi projetada para escalar de forma diferente para ações que envolvem aproximar caixas, levantar caixas, aproximar caixas umas das outras e concluir com êxito a tarefa de empilhamento.
É incrível a facilidade com que um braço pode aprender esse nível de tarefa. No entanto, é importante notar que a aprendizagem pressupõe um sistema de coordenadas mundial definido e posições e orientações conhecidas dos objetos. Portanto, pode não ser tão simples aplicar esse comportamento aprendido a robôs físicos.
Subdivisão de observação 26-dimensional:
● 7 dimensões para mover a posição e orientação da caixa
● 3 dimensões do vetor da caixa empilhada para a caixa movida
● 7 tamanhos para posição e orientação da garra
● 9 tamanhos de articulações de braço e garras

Figura 2: FrankaCubeStack antes do treinamento

Figura 3: FrankaCubeStack após o treinamento
Algumas opções comuns em train.py incluem:
● Headless (Padrão: Falso): Quando definido como Verdadeiro, o visualizador não será iniciado. Isso é útil para treinamento pesado ou ao capturar imagens da câmera, pois o visualizador pode retardar significativamente o processo.
● Test (padrão: False): Quando definido como True, o modo de aprendizado é desativado, permitindo que você execute o ambiente sem treinamento. Isso é útil para gerar ambientes e verificar os resultados do aprendizado.
● ponto de verificação (padrão: "): especifica o arquivo de pesos PyTorch a ser carregado. Os resultados do aprendizado são salvos em runs//nn/.pth, esta opção é usada para retomar o treinamento ou teste.
● num_envs (padrão: int): especifica o número de ambientes de aprendizado paralelo. É importante definir um número adequado para evitar um grande número de visualizadores durante o teste (esta opção também pode ser definida durante o treinamento, mas alterá-la pode levar a erros devido ao tamanho do lote e ao ruído).
Observe que train.py configura horizon_length e minibatch_size, mas batch_size = horizon_length * num_actors * num_agents e batch_size deve ser divisível por minibatch_size. Além disso, num_actors e num_agents são proporcionais a num_envs, portanto, alterar apenas num_envs pode causar erros.
Outras amostras são fáceis de experimentar no ambiente, então tente alguns testes interessantes.
3.3 Dicas do Visualizador
● Desenhe a malha de colisão
O simulador normalmente renderiza a malha visual do objeto, mas no visualizador do Isaac Gym você pode alterar isso para renderizar uma malha de colisão. Para fazer isso, vá para a guia Viewer na janela do menu e marque Render Collision Mesh. Se os objetos estiverem se comportando de maneira estranha, é uma boa ideia verificar se a malha de colisão foi carregada corretamente (às vezes, a malha de visão e a malha de colisão têm orientações diferentes ou a malha pode não ter sido carregada corretamente ou ter detalhes suficientes no simulador).

Figura 4: Desenhando a malha de colisão
● Reduzir o ambiente de desenho
Você pode reduzir o ambiente de renderização para apenas um sem alterar nenhuma configuração. Ao marcar "Mostrar apenas ambientes selecionados" no menu Ator (conforme Figura 5), apenas os ambientes selecionados serão mostrados. Se houver algum comportamento estranho, ele pode ser depurado exibindo o número do ambiente e renderizando apenas esse ambiente. Isso também alivia a carga de renderização e pode melhorar o FPS.
Figura 5: Numeração do ambiente de desenho
● Alterar a posição inicial da câmera
A posição e orientação inicial da câmera podem ser definidas usando o viewer_camera_look_at(viewer, middle_env, cam_pos, cam_target) do gymapi. No script de tarefa usado para treinamento, a função set_viewer precisa ser substituída para fazer alterações.
4. Ambiente Original e Criação de Tarefas
Finalmente chegou a hora de criar tarefas originais para o tema principal.
4.1. Preparação
Preparar scripts e arquivos de configuração. O objetivo é aprender uma tarefa simples, pegar objetos usando o Mycobot. Então, vamos criar uma tarefa chamada "MycobotPicking". Precisamos de três arquivos:
● Tarefa: script Python principal
● cfg/task: arquivo de configuração YAML para parâmetros de ambiente e simulação
● cfg/train: arquivos de configuração YAML para algoritmos de aprendizado, camadas de rede neural e parâmetros.
Podemos nos referir à tarefa "FrankaCubeStack" mencionada anteriormente e criar esses arquivos de acordo. Os arquivos de configuração são especialmente importantes, podemos copiá-los e modificá-los de acordo com nossos requisitos.
Como mostra a demonstração, podemos carregar scripts de tarefas do arquivo train.py usando opções de linha de comando. Portanto, precisamos adicionar uma instrução de importação para a classe de tarefa no arquivo init.py no diretório de tarefas e adicionar o nome da tarefa ao passar parâmetros.
4.2. Criação de ambiente
As classes de tarefas são criadas herdando da classe VecTask no diretório tasks/base, e as tarefas têm a seguinte estrutura, conforme mostrado na Figura 6.
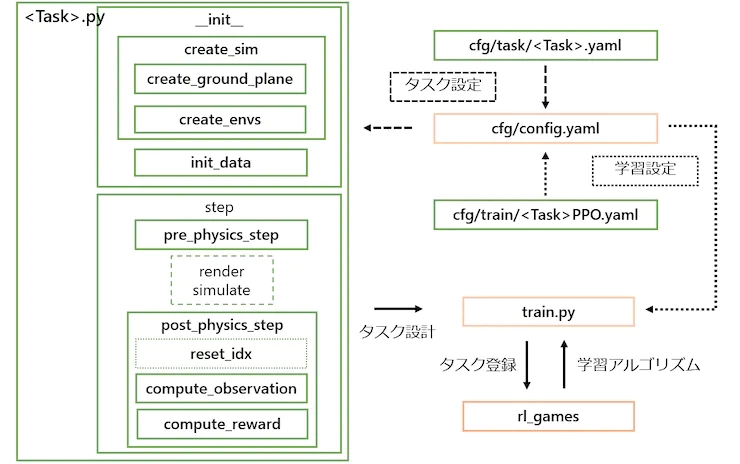
Figura 6: Configuração da tarefa. Aqueles com uma caixa laranja não precisam ser editados, e aqueles com uma caixa verde são criados para cada tarefa.
4.2.1. Processamento __init__
1. Crie o simulador e o ambiente
● create_sim: Esta função cria uma instância do simulador. O próprio processo é definido na classe pai e as propriedades são definidas no arquivo de configuração, como gravidade e tempo de passo. Semelhante ao FrankaCubeStack, esta função usa as duas funções a seguir para gerar o plano de terra e o atuador.
● create_ground_plane: Esta função gera um plano de solo a partir da direção normal do plano de entrada. Se você deseja criar um terreno irregular, pode consultar o exemplo earth_creation.
● create_envs: Esta função carrega e define as propriedades do arquivo de personagem, gera os atores e paraleliza o ambiente. Nesta tarefa, geramos myCobot a partir de URDF e objeto de destino a partir da API create_box. O URDF para myCobot é baseado no URDF usado em experimentos anteriores com o MoveIt, ao qual adicionamos uma pinça para coleta (detalhes sobre a pinça são explicados na Seção 5.1).
2. Inicialização de dados
● init_data: Esta função define variáveis de ambiente do arquivo de configuração e prepara buffers para tensores de dados processados por Isaac Gym (PhysX). Os dados necessários para computar estados e recompensas são definidos como variáveis de classe. A API carrega os dados do tensor em um buffer e o buffer é atualizado a cada etapa chamando a função de atualização correspondente.
4.2.2. Etapas de processamento
1. Processamento passo a passo:
A função de etapa principal é definida na classe pai e não precisa ser modificada. No entanto, as duas etapas a seguir são necessárias como um método abstrato:
● pre_physics_step: Manipula o ator com ações. O tamanho das ações é definido na configuração como ["env"]["numActions"]. Para o braço e pinça de 6 eixos do myCobot, definimos para 7D.
● post_physics_step: Calcula observações e recompensas. Verifique também para redefinir o ambiente. Nós o configuramos para reiniciar após atingir um máximo de 500 degraus ou após uma subida bem-sucedida.
Passos fixos, aplique simulação física → → observe a ação de cálculo de recompensa, transfira dados para aprendizado. Mesmo se você apenas escrever "passar" aqui, poderá verificar o ambiente ao iniciar o visualizador.
● reset_idx: Retorna o ambiente ao seu estado inicial. Obviamente, a aleatoriedade do estado inicial está intimamente relacionada à generalização do aprendizado. Definimos o myCobot como uma pose inicial e redefinimos aleatoriamente a posição do objeto alvo ao alcance do myCobot.
2. Cálculo de status e recompensa:
● compute_observation: Atualiza cada buffer com a função flush e coloca o estado desejado em obs_buf. O tamanho de obs_buf é definido na configuração como ["env"]["numObservation"].
● compute_reward: Calcula a recompensa. Uma recompensa é obtida quando a garra está próxima da posição de preensão do objeto alvo (entre os dedos), e uma recompensa maior é obtida conforme a altura do objeto alvo aumenta.
4.3. Implementação de treinamento
Agora que o esqueleto da tarefa foi criado, vamos treinar o modelo. Podemos começar a treinar o modelo com o seguinte comando:
python train.py task=MycobotPicking --ele anúncio menos
Após 200 épocas, os pesos iniciais serão salvos e, se a recompensa aumentar, os novos pesos serão salvos. No entanto, as tarefas que criamos podem não funcionar perfeitamente e o processo de treinamento pode parar rapidamente. Na próxima seção, discuto os ajustes que fiz na tarefa para melhorar seu desempenho.
4.4. Coordenação de tarefas
Ao testar com os pesos aprendidos, você pode depurar por que o treinamento não está tendo um bom desempenho. você executou o comando
python train.py task=MycobotPicking test=True checkpoint=runs/MycobotPicking/nn/[checkpoint].pth
para testar o modelo. No entanto, você se depara com o problema de movimento inadequado da garra. Apesar de seus esforços para resolver o problema, você concluiu que URDFs não suportam estruturas de malha fechada, dificultando a simulação precisa do movimento da pinça. Portanto, você decide usar uma abordagem baseada em regras para controlar as ações de fechamento e levantamento da garra. Você conecta os dedos da pinça aos links fixos e reduz o espaço de manipulação de 7 para 6 dimensões. Você também notou que ao usar o simulador para controlar um braço de robô, é melhor usar uma garra sem loops fechados, como o braço do panda.
Outro problema que você enfrenta é que a certa distância o agente para de se aproximar do objeto e hesita em tocá-lo, resultando em uma recompensa menor. Você modifica o sistema de recompensa aumentando o valor da função de recompensa usando a distância limite como uma função degrau para que a recompensa seja maximizada quando o agente atingir o ponto de meta. Você também removeu a redefinição do ambiente após a conclusão da tarefa, pois isso faria com que o agente parasse de aprender antes de atingir a meta real. Em vez disso, você ajusta o número máximo de etapas ao número necessário para a conclusão da tarefa, aumentando a taxa de aprendizado.
Você também descobriu que punir tarefas difíceis com muita severidade torna o agente de aprendizado por reforço muito conservador. Isso dá ao agente uma personalidade mais humana, tornando o processo de aprendizagem mais interessante. Por fim, você encontrou um fenômeno semelhante na tarefa de benchmark FrankaCabinet, em que o agente para de aprender depois de puxar uma gaveta por uma certa distância, embora puxar a gaveta completamente rendesse uma recompensa maior. Em vez de corrigir o problema, você removeu a redefinição do ambiente após a conclusão da tarefa e ajustou o número máximo de etapas para concluir a tarefa com êxito.

Figura 7: myCobot se afasta do objeto
As autocolisões de braço são ignoradas. Enquanto consigo chegar à posição desejada, o braço agora está em uma posição que ignora completamente a auto-colisão, como um oito. Tentei pesquisar se é possível definir o cálculo de auto-colisão na documentação, mas não funcionou bem. Primeiro, não é realista definir todos os limites de ângulo de junta no URDF fornecido para -3,14~3,14, então decidi ajustar os limites superior e inferior de cada ângulo de junta para evitar a auto-colisão. A razão para o movimento dos ângulos da junta para o valor máximo possível ainda é desconhecida.

Figura 8: myCobot ignorando colisões acidentais
O braço não para exatamente onde deveria, mas gira em torno dele. Queremos que o movimento esteja próximo de 0 quando atingir a posição de destino, mas é difícil de conseguir e o braço vibra constantemente em torno da posição de destino. Tentamos penalizar as ações e ajustar as recompensas definindo com precisão o local de destino, mas isso não melhorou os resultados. Decidimos não nos preocupar com esse problema, pois ele pode ser tratado na prática pelo controle baseado em regras.
Embora não seja obrigatório, gostaríamos que a empunhadura ficasse voltada para baixo para uma melhor aparência. Portanto, adicionamos um termo de penalidade na função de recompensa que penaliza o ângulo da garra. A Figura 9 mostra os resultados do aprendizado antes do ajuste fino.

Figura 9: MyCobot após o aprendizado antes do ajuste fino
Os resultados dos ajustes acima são mostrados na Figura 10. Se esse nível de precisão puder ser alcançado em um robô real, ele deverá ser capaz de levantar objetos adequadamente.

Figura 10: MyCobot após o treinamento após o ajuste fino
5. Outro
Vou apresentar as histórias ruins e as que quero experimentar.
5.1. A história do grabber URDF caseiro que não funciona
O URDF para myCobot é baseado no URDF usado em tentativas anteriores de mover o robô real, mas não inclui a garra. Embora exista um modelo de garra na página oficial do GitHub, ele fornece apenas um arquivo DAE com uma representação visual, conforme mostrado na Figura 11(a). Para criar um URDF que possa ser usado no simulador, é necessário um modelo 3D separado para cada peça da junta. Então, usando o Blender, dividimos as peças por juntas (Fig. 11(c)) e criamos peças de colisão simplificadas em forma de caixa, pois era difícil reproduzir formas complexas (Fig. 11(b)). Em seguida, descrevemos a estrutura de links e juntas em arquivos URDF para completar o modelo. No entanto, como o URDF não oferece suporte a modelos com estrutura de link aberta, removemos a colisão de um link na base e concluímos a conexão com o lado da ponta do dedo. Embora essa abordagem seja grosseira, conseguimos reproduzir o movimento do robô real no simulador movendo as seis juntas no mesmo ângulo. A Figura 11(d) mostra a comparação entre o modelo completo e o robô real (usando o modelo fornecido, mas com detalhes completamente diferentes). No entanto, quando realmente tentamos movê-lo, conforme descrito na Seção 4.4, ele não funciona bem. A causa é a incapacidade de mover a junta de maneira coordenada quando uma força externa é aplicada (isso pode ter sido resolvido se o controle de torque fosse implementado corretamente).

Figura 11: Criação da garra para myCobot (a) Modelo de garra publicado (b) Peças do modelo de colisão criadas a partir do modelo (c) Peças do modelo visual desmontadas do modelo da garra (d) Desenho do ginásio de Isaac Comparação com a garra real
5.2. Usando o Reconhecimento de Imagem
Nas tarefas de benchmark e MycobotPicking, usamos as informações de posição e orientação do objeto nas observações, mas não é fácil obter essas informações em tarefas reais. Portanto, seria mais valioso realizar o aprendizado por reforço usando apenas informações de câmera 2D e informações de ângulo de junta servo facilmente obtidas.
Tentamos substituir observações por imagens e usar camadas CNN para aprendizado na tarefa FrankaCubeStack. No entanto, apenas modificamos o algoritmo para aceitar entradas de imagem e, como esperado, não aprendemos bem. Não há nenhuma estrutura para adicionar informações de ângulo de junta servo como dados unidimensionais para camadas CNN, usando diretamente informações de imagem em camadas CNN aumenta a complexidade computacional e limita a paralelização do ambiente. Além disso, precisamos ajustar hiperparâmetros como taxa de aprendizado e valor de recorte, mas não buscamos isso porque o efeito não era promissor o suficiente.
Neste teste, confirmamos apenas o método de adição de camadas CNN para aprendizado. No entanto, em vez de vincular diretamente as camadas da CNN às imagens da câmera, as imagens podem ser mais eficazes quando usadas juntas.
5.3. Usando o modelo treinado em um robô real
Conforme mencionado no post anterior, tentei um experimento Sim2Real para reconhecimento espacial usando o modelo treinado junto com myCobot e RealSense. No entanto, não funciona muito bem. Embora o alongamento funcione até certo ponto, o movimento se torna errático ao se aproximar de um objeto e não pode se mover com precisão para a posição de agarrá-lo. Possíveis problemas incluem myCobot não ter capacidade suficiente para se mover com precisão para a pose alvo e pequenas diferenças se acumulando devido ao simulador prever a próxima pose alvo antes de atingir a pose alvo atual, enquanto o robô real não. Em relação ao primeiro, o myCobot usado neste experimento é um braço educacional barato com um peso portátil de 250g; portanto, se você deseja se mover com mais precisão, deve usar um braço robótico de ponta, como o usado para aprendizado por reforço. escolher. A Elephantrobotics, a empresa que fabrica o myCobot, também vende um modelo com servomotores mais fortes que podem carregar até 1kg, então eu também queria experimentar.
6. Resumo
Desta vez, usei o Isaac Gym para criar uma tarefa de aprendizado por reforço e realmente treinar o modelo. Eu experimentei projetar problemas de aprendizado por reforço para robótica e executar modelos treinados em um simulador de física 3D. É atraente poder testar um ambiente de aprendizado sem ter que escrever um algoritmo de aprendizado por reforço do zero. A disponibilidade de ambientes de benchmark facilita a comparação e validação de novos algoritmos de aprendizado, o que é uma grande vantagem para pesquisadores e analistas com diversas formações profissionais.