
Hoje aprenderemos o curso online do DeepLearning.AI: Construindo aplicativos de IA generativos com Gradio. Este curso fala principalmente sobre o uso do Gradio para implantar aplicativos de algoritmo de aprendizado de máquina. Hoje aprenderemos a primeira lição: Aplicativo de legenda de imagem. Leia as informações de conteúdo da imagem na foto, como mostrado na figura a seguir:

Hoje usaremos o modelo Salesforce/blip-image-captioning-base de huggingface para ler o conteúdo da imagem. blip-image-captioning-bas é um modelo treinado com parâmetros de 1400 W. O tamanho do modelo em huggingface é 990M . Existem duas maneiras para usar esse modelo, uma delas é chamar por API, a premissa é que o serviço de aplicativo desse modelo deve ser implantado no ambiente de nuvem com antecedência e, em seguida, fornecer chave de API e Inference Endpoint para chamada, dessa forma não ocupa armazenamento local recursos de espaço, mas ocupará recursos de rede. A segunda maneira é baixar o modelo blip-image-captioning-bas localmente, para que possa ser usado offline sem acessar a rede. A desvantagem é que ocupará espaço de armazenamento local e memória. Aqui vamos nos concentrar no segundo método. Para o primeiro método, também explicarei o método de chamada da API. Quanto à implantação do modelo blip-image-captioning-bas no ambiente de nuvem, os leitores precisam estudá-lo por conta própria.
Método 1: chamada de API
Quando implantamos o aplicativo blip-image-captioning-bas no ambiente de nuvem, obteremos um endereço para acessar o serviço de modelo, que é endpoint_url e uma chave de API huggingface. Em seguida, usaremos a chave api e endpoint_url para ler o conteúdo da imagem. Primeiro, armazenamos api_key e endpoint_url em um arquivo de configuração local. Informações sobre api_key e endpoint_url:
import os
import io
import IPython.display
from PIL import Image
import base64
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
hf_api_key = os.environ['HF_API_KEY']Em seguida, vamos implementar a função get_completion para ler o conteúdo da imagem. Essa função carrega o serviço de aplicativo em nuvem através dos parâmetros ENDPOINT_URL e hf_api_key e então lê o conteúdo da imagem da web.
# Helper functions
import requests, json
#Image-to-text endpoint
def get_completion(inputs, parameters=None, ENDPOINT_URL=os.environ['HF_API_ITT_BASE']):
headers = {
"Authorization": f"Bearer {hf_api_key}",
"Content-Type": "application/json"
}
data = { "inputs": inputs }
if parameters is not None:
data.update({"parameters": parameters})
response = requests.request("POST",
ENDPOINT_URL,
headers=headers,
data=json.dumps(data))
return json.loads(response.content.decode("utf-8"))Em seguida, testamos a função get_completion no notebook jupyter. Aqui, fornecemos o endereço url de uma imagem da web e, em seguida, chamamos get_completion para ler o conteúdo da imagem da web:
image_url = "https://free-images.com/sm/9596/dog_animal_greyhound_983023.jpg"
display(IPython.display.Image(url=image_url))
get_completion(image_url)
Aqui vemos que para a foto acima, a informação retornada pelo modelo é: tem um cachorro com chapéu de papai noel e lenço traduzido para o chinês é: um cachorro usando chapéu de papai noel e cachecol, essa informação é bastante precisa. Em seguida, usamos a estrutura gradio para desenvolver um aplicativo básico de leitura de informações de imagem de serviço da web modelo blip-image-captioning-bas. Aqui, chamaremos o método de interface de gradio para implementar nosso aplicativo. Interface é a principal classe avançada de Gradio. Permite criar uma GUI/demonstração baseada na Web em torno de um modelo de aprendizado de máquina (ou qualquer função Python) com algumas linhas de código. O método Interface contém pelo menos três parâmetros principais:
- fn: A função que envolve a interface. Normalmente, a função de previsão de um modelo de aprendizado de máquina. Cada argumento da função corresponde a um componente de entrada, e a função deve retornar um único valor ou uma tupla de valores, com cada elemento na tupla correspondendo a um componente de saída.
- entradas: Um único componente Gradio ou uma lista de componentes Gradio. Os componentes podem ser passados como objetos instanciados ou referenciados por meio de seus atalhos de string. O número de componentes de entrada deve corresponder ao número de argumentos em fn. Se definido como Nenhum, apenas os componentes de saída são exibidos.
- saídas: Um único componente Gradio ou uma lista de componentes Gradio. Os componentes podem ser passados como objetos instanciados ou referenciados por meio de seus atalhos de string. O número de componentes de saída deve corresponder ao número de valores retornados por fn. Se definido como Nenhum, apenas os componentes de entrada são mostrados.
import gradio as gr
def image_to_base64_str(pil_image):
byte_arr = io.BytesIO()
pil_image.save(byte_arr, format='PNG')
byte_arr = byte_arr.getvalue()
return str(base64.b64encode(byte_arr).decode('utf-8'))
def captioner(image):
base64_image = image_to_base64_str(image)
result = get_completion(base64_image)
return result[0]['generated_text']
gr.close_all()
demo = gr.Interface(fn=captioner,
inputs=[gr.Image(label="Upload image", type="pil")],
outputs=[gr.Textbox(label="Caption")],
title="Image Captioning with BLIP",
description="Caption any image using the BLIP model",
allow_flagging="never",
examples=["christmas_dog.jpeg", "bird_flight.jpeg", "cow.jpeg"])
demo.launch(share=True, server_port=55354)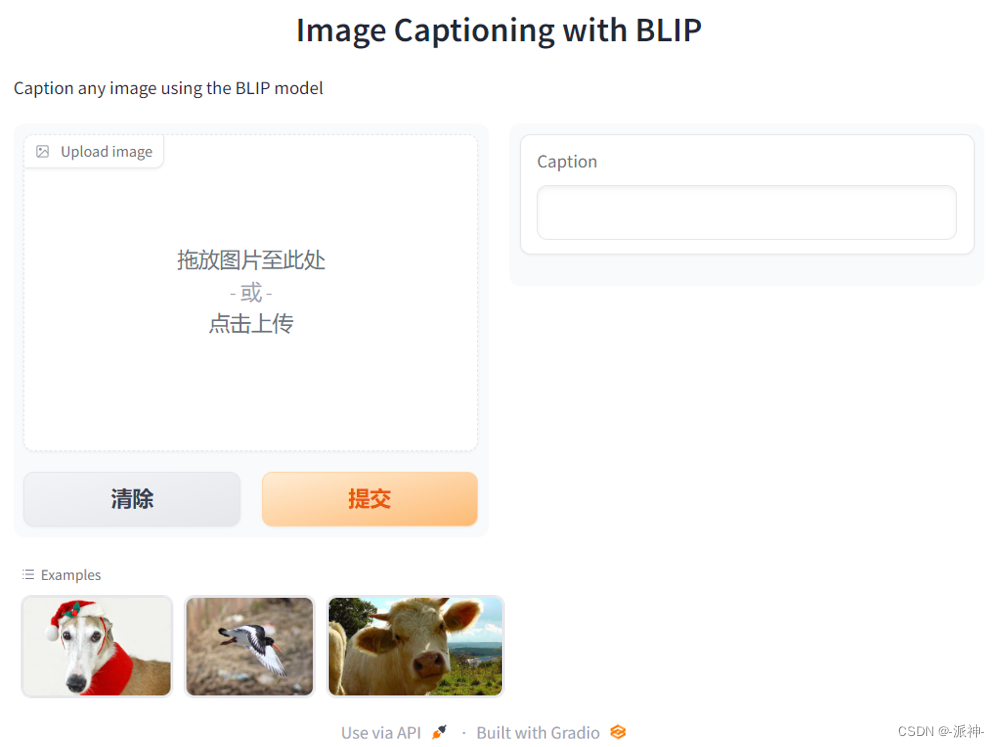
Em seguida, clicamos em qualquer imagem na categoria Exemplos na parte inferior e, em seguida, clicamos em Enviar:

Aqui podemos ver que quando clicamos na imagem em Exemplos na parte inferior e, em seguida, clicamos no botão enviar, as informações de texto do conteúdo da imagem aparecerão na caixa de texto Legenda à direita.
Método 2: chamada local
Para implementar chamadas locais, precisamos baixar o modelo para o local. Existem 2 maneiras de baixar o modelo para o local. O primeiro método é usar o método pipeline. Quando o método pipeline é usado para baixar o modelo, o modelo será salvo na unidade atual da unidade c por padrão. Na pasta .cache da pasta do usuário, é muito inconveniente gerenciar o modelo e ocupa espaço na unidade c. O segundo método é usar o método manual para ir para a página onde o modelo huggingface está localizado e importar manualmente o modelo necessário O arquivo e seus arquivos de suporte são baixados. Geralmente, existem duas versões do modelo publicadas no huggingface, uma é a versão do pytorch e a a outra é a versão do tensorflow. Se sua máquina estiver instalada com pytorch, basta baixar o modelo da versão pytorch. Tudo bem, se o tensorflow estiver instalado, basta baixar a versão tensorflow do modelo.
Aqui, eu baixo principalmente todos os modelos e seus arquivos de suporte automaticamente por meio do método de pipeline e, em seguida, copio todos esses arquivos de modelo para a pasta designada para gerenciamento unificado. O seguinte é baixar o modelo por meio do método de pipeline:
from transformers import pipeline
get_completion = pipeline("image-to-text",
model="Salesforce/blip-image-captioning-base")Quando o comando pipelien for executado, o modelo será baixado para o subarquivo .cache na pasta do usuário atual da unidade local C. O seguinte é o caminho padrão para salvar o modelo em minha máquina:
C:\Users\tzm\.cache\huggingface\hub\models--Salesforce--blip-image-captioning-base\snapshots\89b09ea1789f7addf2f6d6f0dfc4ce10ab58ef84

Aqui vemos que pytorch_model.bin é o arquivo de modelo. Ele tem 966M, menos de 1G. Em seguida, copio todos esses modelos e seus arquivos de suporte para a pasta de modelo no diretório de trabalho do programa e, em seguida, podemos carregar o local modelo. Sim, também usamos gradio para ler o conteúdo da imagem. Aqui definimos uma variável model_path para o caminho de armazenamento do modelo. O código para carregar o modelo vem da página inicial do modelo de huggingface:
from transformers import BlipProcessor, BlipForConditionalGeneration
import gradio as gr
model_path = './model/'
processor = BlipProcessor.from_pretrained(model_path)
model = BlipForConditionalGeneration.from_pretrained(model_path)
def captioner(raw_image):
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
caption = processor.decode(out[0], skip_special_tokens=True)
return caption
gr.close_all()
demo = gr.Interface(fn=captioner,
inputs=[gr.Image(label="Upload image", type="pil")],
outputs=[gr.Textbox(label="Caption")],
title="Image Captioning with BLIP",
description="Caption any image using the BLIP model",
allow_flagging="never",
examples=["christmas_dog.jpeg", "bird_flight.jpeg", "cow.jpeg"])
demo.launch(share=True, server_port=8080)
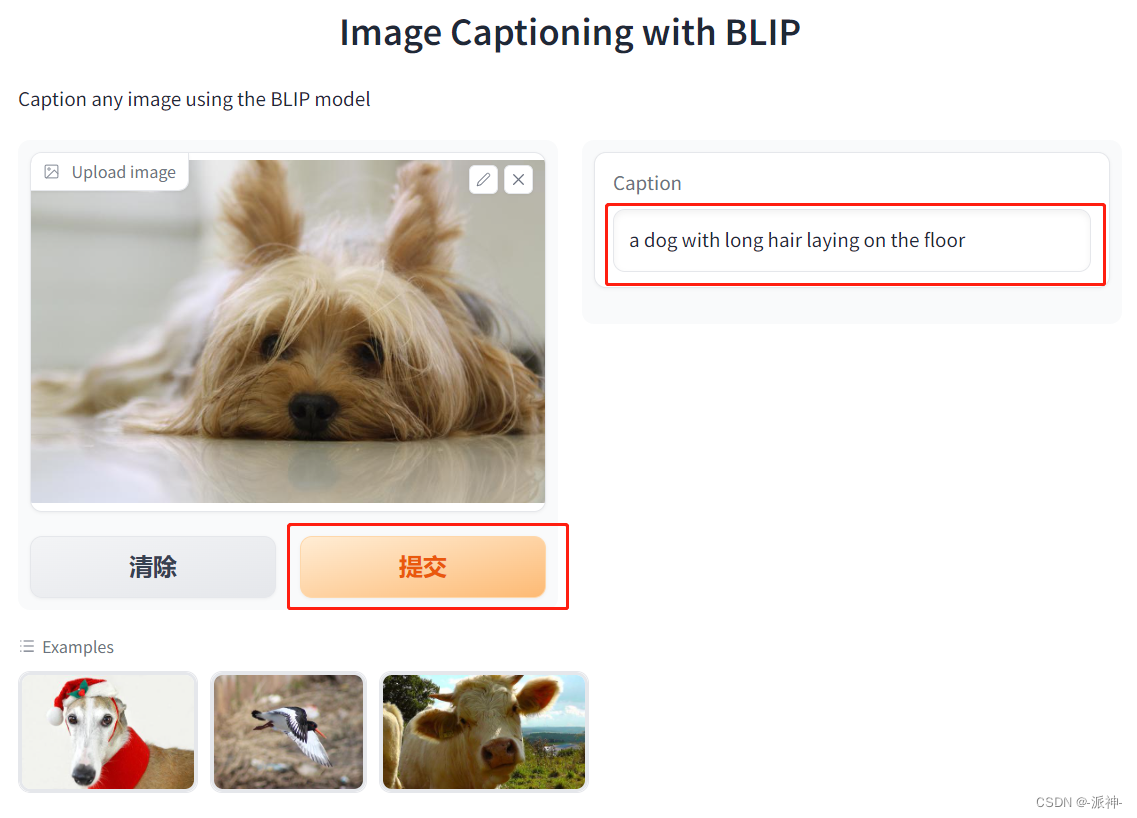
Aqui, ao iniciar o serviço, entramos no navegador: http://127.0.0.1:8080 e abrirá a página do app, conforme a figura acima, desta vez carregamos uma foto de fora, e em seguida, clique no botão enviar. A caixa de texto Legenda à direita exibe as informações do conteúdo da imagem.
Resumir
Hoje aprendemos como ler informações de conteúdo de imagem por meio do modelo blip-image-captioning-bas. Geralmente, existem duas maneiras de usar esse modelo, uma é a chamada da API, mas a aplicação do modelo precisa ser implantada em a nuvem, e o outro é Um é baixar o modelo localmente e, em seguida, carregar o modelo localmente, ambos os métodos têm suas próprias vantagens e desvantagens. Além disso, também aprendemos como usar o gradio para desenvolver um aplicativo da web que lê o conteúdo da imagem com base no modelo blip-image-captioning-bas. Ao mesmo tempo, também aprendemos o método principal Interface e seus principais parâmetros do gradio. Espero que o conteúdo de hoje seja útil para que todos aprendam gradio.
Referências
Salesforce/blip-image-captioning-base · Rosto de abraço