
"
Em 31 de julho, a comunidade chinesa Llama assumiu a liderança na conclusão daprimeira versão chinesa real do modelo grande Llama2-13B, o que otimizou e melhorou muito os recursos chineses do Llama2 desde a parte inferior do modelo. Sem dúvida, uma vez que o A versão chinesa do Llama2 é lançada, abrirá uma nova era de modelo doméstico em grande escala!
| O mais forte do mundo, mas a língua chinesa é curta
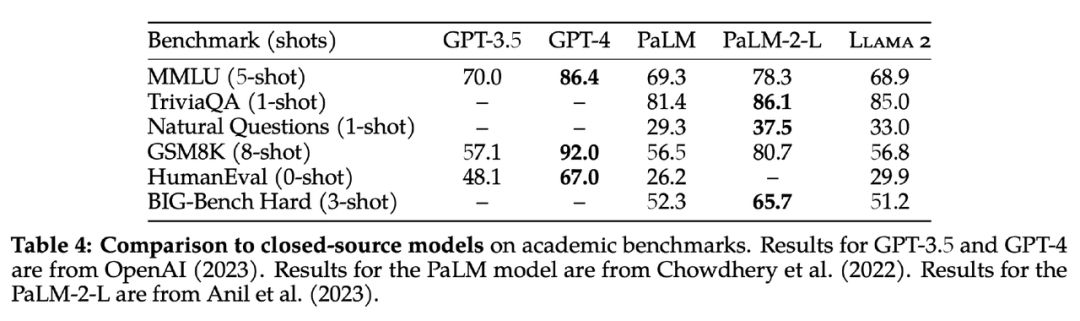
O Llama2 é atualmente o modelo grande de código aberto mais poderoso do mundo, mas sua capacidade chinesa precisa ser aprimorada . O Meta atendeu às expectativas. No início da manhã de 19 de julho, uma versão atualizada da primeira geração do LLaMA foi aberta. origem: modelos Llama2, 7B, 13B e 70B de três tamanhos Totalmente aberto e gratuito para uso comercial. Como o modelo grande de código aberto mais poderoso no campo de IA, o Llama2 é pré-treinado em 2 trilhões de dados de token e ajustado em 1 milhão de dados rotulados por humanos para obter um modelo de diálogo. Em muitos testes de referência, incluindo raciocínio, programação, diálogo e teste de conhecimento, o efeito é significativamente melhor do que o de modelos de linguagem de código aberto como MPT, Falcon e a primeira geração de LLaMA. Também é comparável ao GPT-3.5 comercial para o primeira vez Entre os modelos de código aberto Unique.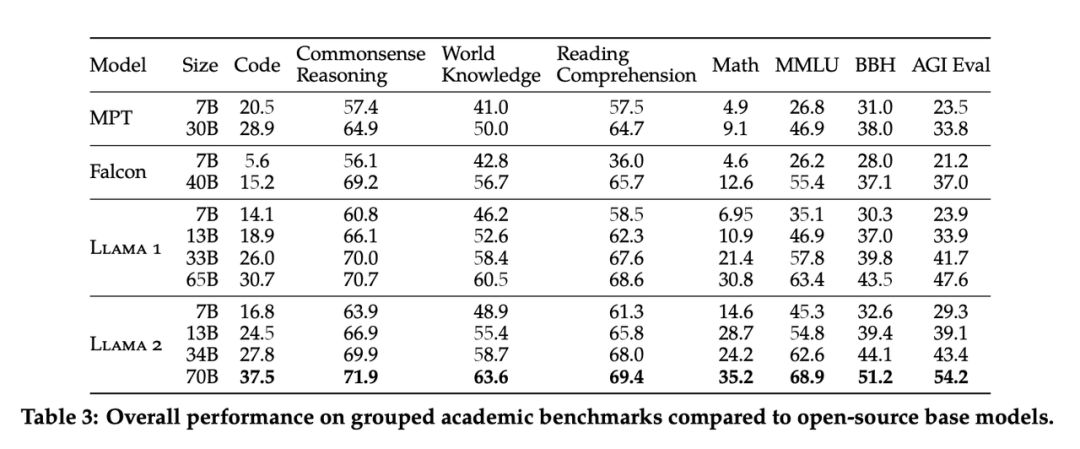
 Embora os dados pré-treinamento do Llama2 tenham dobrado em comparação com a primeira geração, a proporção de dados pré-treinamento chineses ainda é muito pequena, representando apenas
0,13
%
, o que também leva à fraca capacidade chinesa do Llama2 original .
Fizemos algumas perguntas em chinês e descobrimos que, na maioria dos casos, o Llama2 não conseguia responder em chinês ou respondia a perguntas em uma forma mista de chinês e inglês. Portanto,
é necessário otimizar o Llama2 com base em dados chineses de grande escala, para que o Llama2 tenha melhores recursos chineses.
Embora os dados pré-treinamento do Llama2 tenham dobrado em comparação com a primeira geração, a proporção de dados pré-treinamento chineses ainda é muito pequena, representando apenas
0,13
%
, o que também leva à fraca capacidade chinesa do Llama2 original .
Fizemos algumas perguntas em chinês e descobrimos que, na maioria dos casos, o Llama2 não conseguia responder em chinês ou respondia a perguntas em uma forma mista de chinês e inglês. Portanto,
é necessário otimizar o Llama2 com base em dados chineses de grande escala, para que o Llama2 tenha melhores recursos chineses.

Por esse motivo, a equipe de doutorado em modelo de grande escala das principais universidades da China fundou a comunidade chinesa Llama e iniciou a jornada de treinamento do modelo chinês em grande escala Llama2.
| A principal comunidade chinesa de lhamas
A comunidade chinesa Llama é a principal comunidade chinesa de modelos grandes de código aberto na China. O Github alcançou 2,4 mil estrelas em duas semanas . O Llama é liderado por equipes de doutorado da Universidade de Tsinghua, da Universidade de Jiaotong e da Universidade de Zhejiang. Ele reuniu mais de 60 engenheiros seniores na IA campo e mais de 2.000 talentos em vários setores.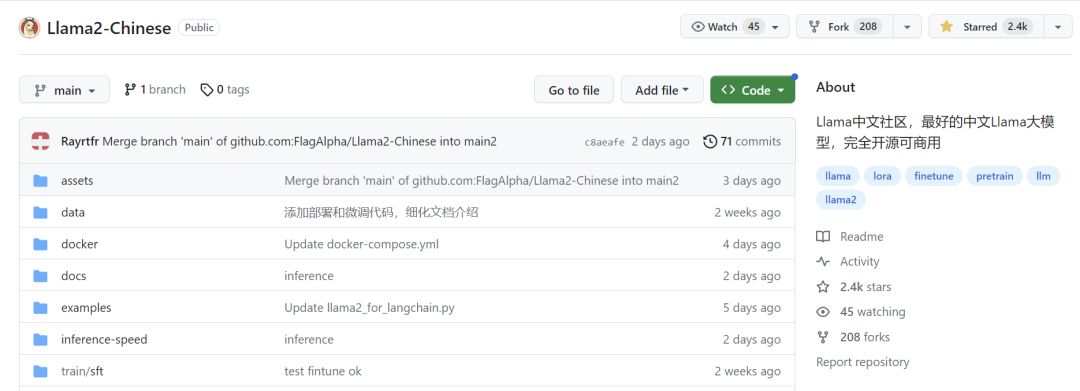
https://github.com/FlagAlpha/Llama2-Chinese
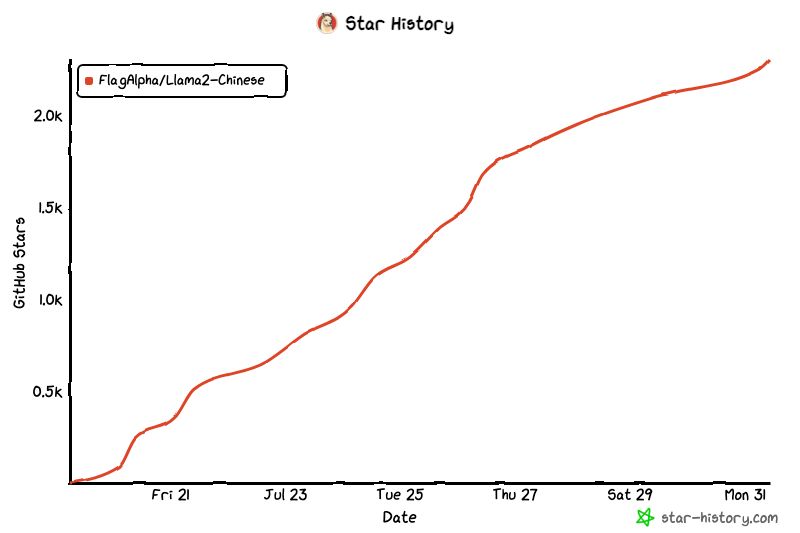
História da comunidade:

| A primeira versão chinesa pré-treinada do modelo Llama2 é lançada!
Não é um girador! É baseado no pré- treinamento do corpus chinês 200B!
Em 31 de julho, a comunidade chinesa Llama assumiu a liderança na conclusão da primeira versão chinesa real do modelo 13B Llama2 na China: Llama2-Chinese-13B, que otimizou e melhorou muito a capacidade chinesa do Llama2 na parte inferior do modelo. A cultura chinesa de Llama2 pode adotar aproximadamente duas rotas: 1. Com base no conjunto de dados de instrução chinesa existente, ajuste as instruções do modelo de pré-treinamento para que o modelo básico possa se alinhar com a capacidade de perguntas e respostas chinesas . A vantagem dessa rota é que o custo é baixo , a quantidade de dados de ajuste fino de instrução é pequena e os recursos de poder de computação necessários são pequenos , e pode realizar rapidamente o protótipo de uma lhama chinesa. Mas as deficiências também são óbvias. O ajuste fino só pode estimular a capacidade chinesa existente do modelo básico, mas como o Llama2 tem menos dados de treinamento chinês, a capacidade de ser estimulada também é limitada. Ainda precisa começar com o pré-treinamento . 2. Pré-treinamento baseado em corpus chinês de grande escala. A desvantagem desta rota é o alto custo ! Não são necessários apenas dados chineses de alta qualidade em grande escala, mas também recursos de computação em grande escala. Mas as vantagens também são óbvias, ou seja, pode otimizar a capacidade chinesa da camada inferior do modelo e realmente alcançar o efeito de curar a causa raiz, injetando poderosa capacidade chinesa no modelo grande a partir do núcleo ! Para realizar um grande modelo chinês completo a partir do kernel , escolhemos a segunda rota! Coletamos um lote de conjuntos de dados de corpus chineses de alta qualidade e otimizamos o modelo grande Llama2 a partir do pré-treinamento. Parte dos dados de pré-treinamento é a seguinte: Tipo Descrição Dados de rede Dados de rede pública na Internet, dados chineses selecionados de alta qualidade, envolvendo dados de texto longo de alta qualidade, como enciclopédias, livros, blogs, notícias, anúncios, romances etc. , conjunto de dados de competição de texto longo chinês de alta qualidade após a limpeza, conjunto de dados de competição multitarefa de processamento de linguagem natural chinês nos últimos anos, alguns conjuntos de dados limpos de cerca de 150 MNBVCMNBVC A primeira fase do Llama2- Os dados pré-treinamento do modelo chinês- 13B contém tokens de 200 B. No futuro, continuaremos atualizando iterativamente o Llama2-Chinese e aumentaremos gradualmente os dados de pré-treinamento para tokens de 1T. Além disso, abriremos gradualmente a versão chinesa de pré-treinamento do modelo 70B, portanto, fique atento! Questionamos o grande modelo de diferentes aspectos, como conhecimento geral, compreensão da linguagem, capacidade criativa, raciocínio lógico, programação de código, habilidades de trabalho, etc., e obtivemos resultados satisfatórios !
Alguns efeitos são mostrados abaixo:
Questionamos o grande modelo de diferentes aspectos, como conhecimento geral, compreensão da linguagem, capacidade criativa, raciocínio lógico, programação de código, habilidades de trabalho, etc., e obtivemos resultados satisfatórios !
Alguns efeitos são mostrados abaixo:
- conhecimento geral

- compreensão da linguagem

- capacidade criativa

- raciocínio lógico
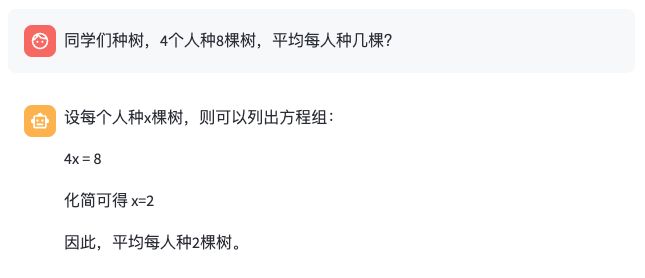
- programação de código

- capacidade de trabalho
