O teste é uma parte importante do lançamento e do lançamento do produto. No entanto, à medida que a escala e a complexidade do negócio continuam a aumentar, mais e mais funções precisam ser retornadas toda vez que ele fica online, o que traz uma enorme pressão para o trabalho de teste. Nesse cenário, mais e mais equipes estão começando a usar a reprodução de tráfego para realizar testes de regressão nos serviços.
Antes de construir a capacidade de reprodução de tráfego, devemos registrar o tráfego de serviços online. Normalmente, diferentes métodos de implementação devem ser selecionados com base na consideração abrangente dos requisitos sobre as características do tráfego, custos de implementação e intrusividade nos serviços.
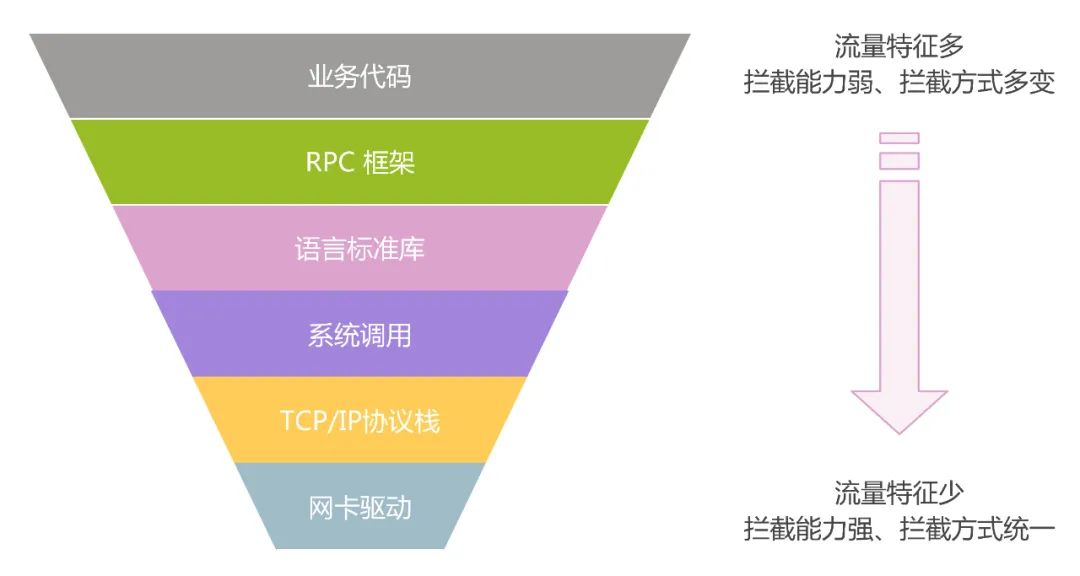
Para as linguagens Java e PHP, existem soluções relativamente maduras jvm-sandbox-repeater e rdebug na indústria, que podem basicamente obter gravação de tráfego não intrusiva e de baixo custo; mas a linguagem Go carece de ferramentas disponíveis, como jvm ou libc No meio camada, a solução existente sharingan precisa modificar o código fonte Go oficial e se intrometer no código comercial, que tem um risco maior de estabilidade; e com a atualização da versão Go oficial, são necessárias iterações de manutenção contínua, e o uso e manutenção os custos são altos.
Tendo em vista a pilha de tecnologia multilíngue da Didi, descobrimos por meio de pesquisas que uma solução de gravação de tráfego não intrusiva e multilíngue pode ser implementada por meio do eBPF, o que reduz consideravelmente os custos de uso e manutenção da gravação de tráfego.
Princípio de Registro de Tráfego
gravando conteúdo
O serviço dependente downstream precisa ser simulado durante a reprodução do tráfego, portanto, um tráfego gravado completo precisa incluir não apenas a solicitação/resposta da chamada de entrada, mas também a solicitação/resposta do serviço dependente invocado ao processar essa solicitação.
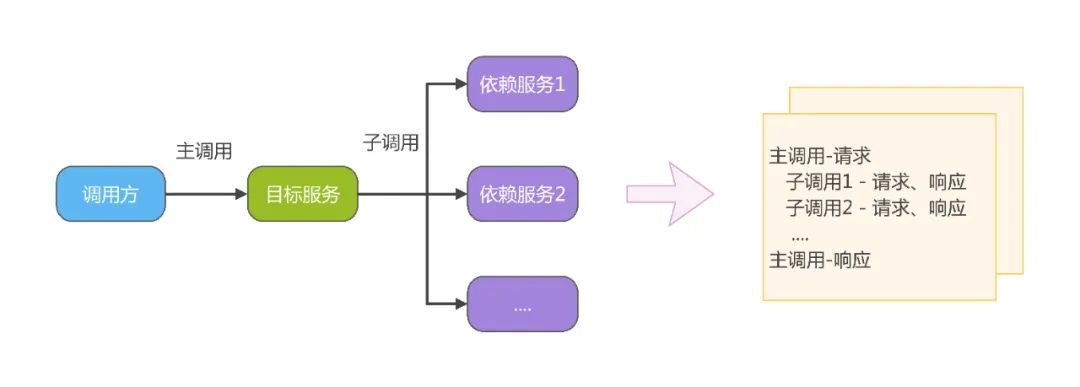
Ideias de implementação
Antes de apresentar a solução de registro de tráfego, vejamos um processo de processamento de solicitação (simplificado):
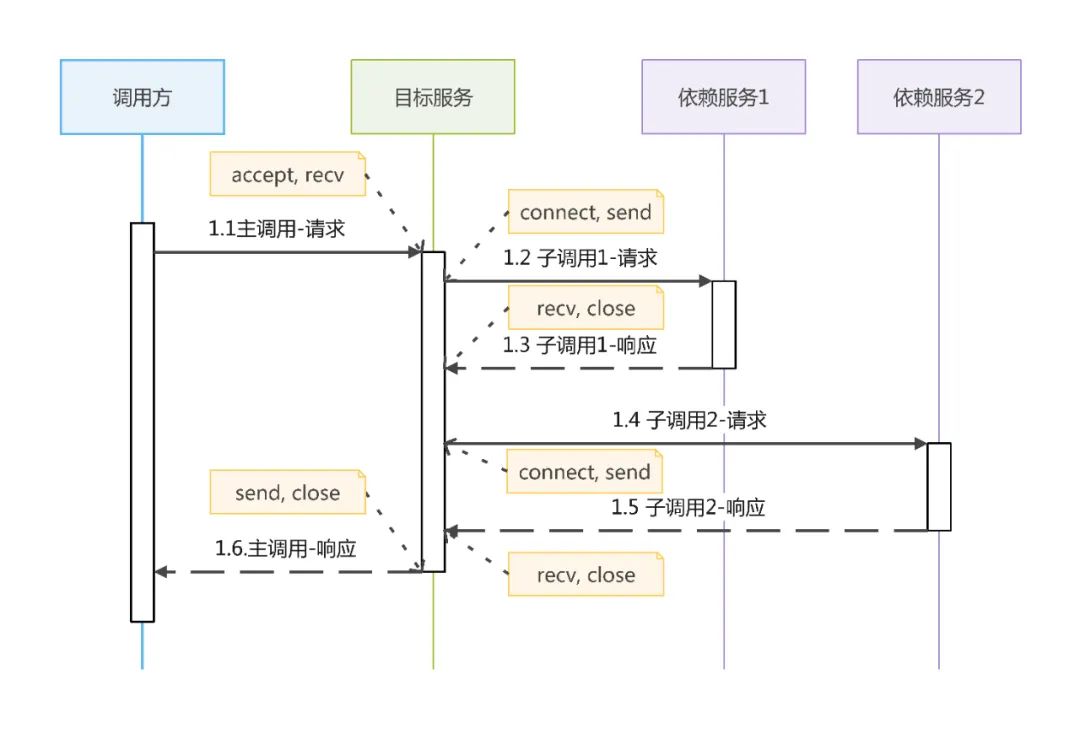
Observando o processo acima, descobrimos que o processo geral do serviço de destino que processa uma solicitação é o seguinte:
Primeiro, chame aceitar para obter a conexão do chamador;
A segunda etapa é ler os dados da solicitação chamando recv nessa conexão e analisar a solicitação;
Na terceira etapa, o serviço de destino começa a executar a lógica de negócios. Durante o processo, um ou mais serviços dependentes podem precisar ser invocados. Para cada chamada de serviço dependente, o serviço de destino precisa estabelecer uma conexão com o serviço dependente por meio de conexão, e, em seguida, envie uma solicitação nesta conexão por meio de envio de dados, receba respostas de serviço dependentes por meio de recv;
Por fim, o serviço de destino retorna os dados de resposta ao chamador por meio de send.
Para obter a gravação do tráfego, precisamos salvar todos os dados de solicitação e resposta no gráfico. Os métodos tradicionais de gravação de tráfego precisam rastrear todos os métodos que envolvem envio/recebimento de dados, como estrutura de serviço, estrutura RPC e sdk de serviço dependente, além de coletar e salvar os dados. Devido à variedade de estruturas e SDKs, é necessário muito trabalho de transformação e desenvolvimento de código, e o custo é difícil de controlar.
Aqui, consideramos uma maneira mais geral: rastrear operações relacionadas a soquetes , como aceitar, conectar, enviar, receber, etc. Dessa forma, podemos obter um método de registro de tráfego mais geral sem nos preocuparmos com os protocolos da camada de aplicação, estruturas, SDKs, etc. usados no negócio.
No entanto, como o local de gravação está em um nível inferior, menos informações de contexto podem ser obtidas e os dados enviados e recebidos por cada soquete não são suficientes. Precisamos concatenar os dados originais com outras informações para montar um fluxo completo.
pedidos diferentes
A maioria das solicitações processadas pelos serviços online são simultâneas, e haverá várias solicitações entrelaçadas ao mesmo tempo. Registramos que os dados originais estão dispersos. Como mesclar os dados de uma mesma solicitação e distinguir os dados de diferentes solicitações? Ao analisar o processo real de processamento de solicitações, podemos encontrar facilmente:
1. Normalmente, cada solicitação é processada em um thread separado.

2. Para melhorar a velocidade de processamento, é possível criar sub-threads para chamar serviços dependentes simultaneamente.
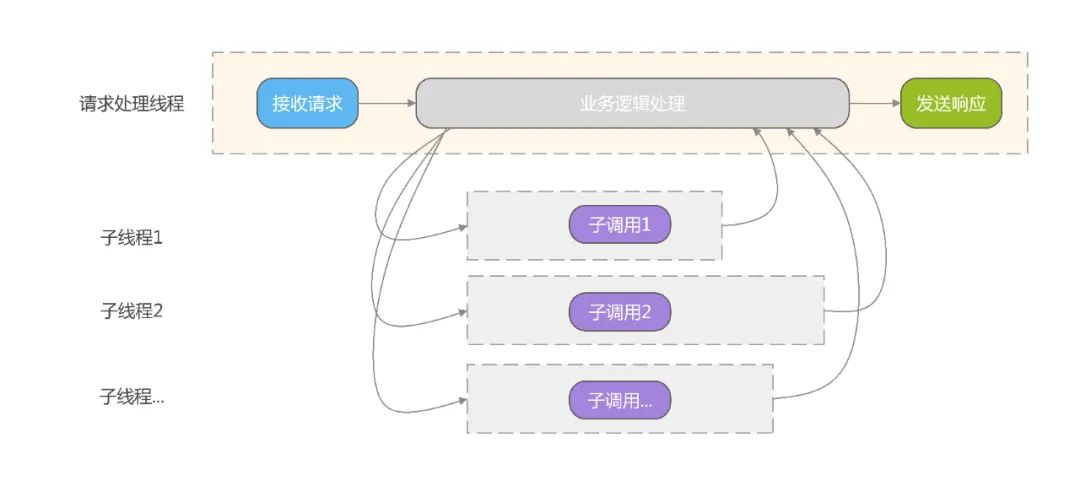
Na verdade, subthreads também podem criar subthreads para formar o relacionamento de thread mostrado na figura a seguir:
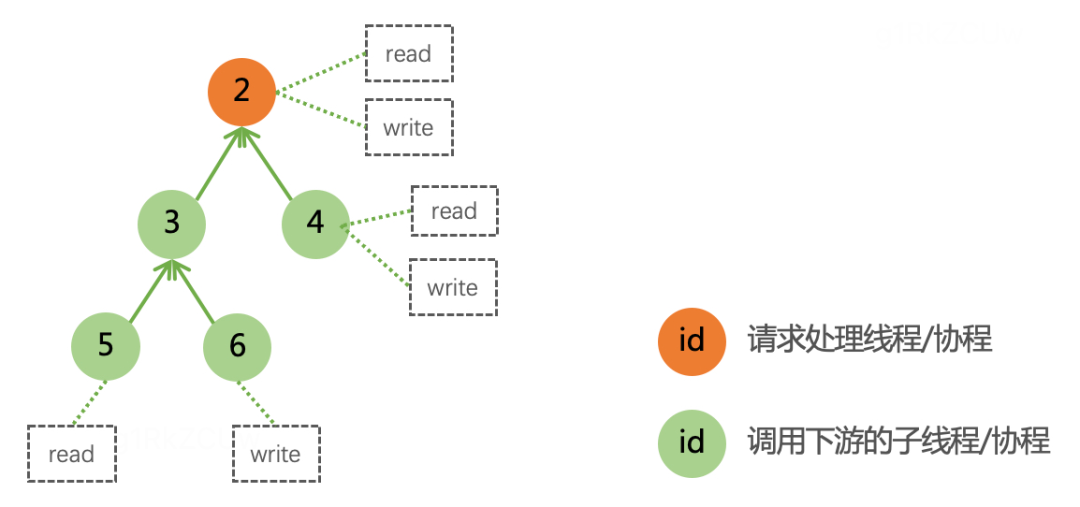
Para este cenário envolvendo sub-threads, precisamos apenas mesclar os dados dos sub-threads no thread de processamento da solicitação. Cada requisição corresponde a uma thread de processamento de requisições e a uma série de sub-threads.Finalmente, podemos distinguir diferentes requisições de acordo com o ID da thread .
Diferenciar tipos de dados
Cada fluxo contém dois tipos de dados: a solicitação e a resposta da chamada de entrada e a solicitação e a resposta da chamada dependente downstream. Precisamos distinguir quando a gravação de tráfego. Ao observar o processo de processamento da solicitação, não é difícil encontrarmos as regras:
1. A requisição e resposta da chamada de entrada são recebidas e enviadas no socket obtido por accept, os dados de recv são requisição, e os dados de send são resposta.
2. A requisição e resposta de chamadas dependentes downstream são recebidas e enviadas no socket obtido por connect, os dados de send são request, e os dados de recv são resposta, diferentes sockets correspondem a diferentes downstream calls.
Portanto, podemos distinguir diferentes tipos de dados e diferentes chamadas dependentes de downstream de acordo com o tipo de soquete e identificação .
Realização de registro de tráfego
Considerando que a maioria dos serviços já está na nuvem, a solução precisa suportar a implantação em contêineres. O programa eBPF é executado no kernel e todos os contêineres no mesmo host compartilham o mesmo kernel, portanto, o programa eBPF só precisa ser carregado uma vez para registrar os dados de todos os processos. O plano geral é o seguinte:
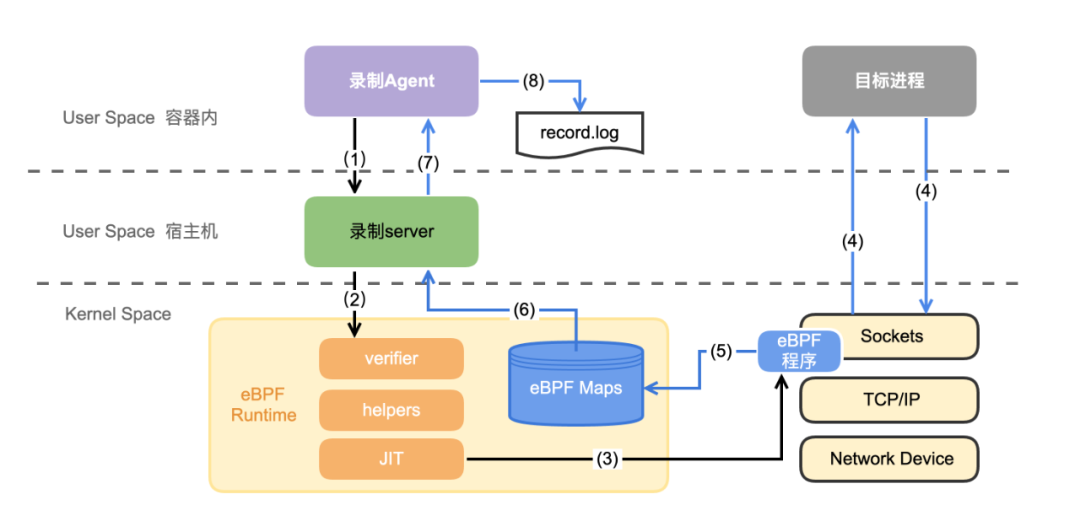
Agente de gravação : implantado no mesmo contêiner que o processo de destino, encontre o pid do processo de destino a ser gravado de acordo com o nome do processo, (1) controle o servidor de gravação para ativar/desativar a gravação; (7) receba dados brutos de o servidor de gravação, analise-o no tráfego completo, (8) Salve no arquivo de log.
Servidor de gravação : implantado na máquina host, responsável por (2, 3) carregar/montar o programa eBPF, (6) ler dados brutos do mapa eBPF.
Programa eBPF : responsável por (5) ler os dados originais da função montada e gravá-los no mapa eBPF quando o processo de destino (4) envia e recebe dados.
Selecione um ponto de inserção
De acordo com a discussão anterior, as operações de soquete que precisamos rastrear incluem:
aceitar e conectar são usados para distinguir os tipos de soquete.
send e recv são usados para capturar dados enviados e recebidos.
close é usado para identificar o fim da chamada.
Para a linguagem Go, também é necessário obter o ID da goroutine que executa a operação de soquete acima e rastrear o relacionamento pai-filho da goroutine.
Antes de desenvolver um programa eBPF, você precisa selecionar um local de montagem de programa eBPF adequado. Diferentes tipos de programas eBPF têm diferentes contextos que podem ser obtidos e diferentes funções bpf-helper que podem ser chamadas. Os dados que precisamos registrar são apenas TCP e UDP, para que possam ser montados nas seguintes funções do kernel através do kprobe:
inet_accept
inet_stream_connect
inet_sendmsg
inet_recvmsg
inet_release
Para rastrear o relacionamento entre goroutines, podemos montar o uprobe na função runtime.newproc1 do tempo de execução Go e obter as informações de goroutine correspondentes de callergp e newg.
Desenvolver programas de eBPF
Embora a gravação de tráfego envolva várias funções do kernel, o processo é basicamente o mesmo. O exemplo a seguir apresenta os dados do soquete de gravação como um exemplo a ser apresentado em detalhes.
Assinatura da função:
int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size)Descrição do parâmetro:
ponteiro de soquete de meia
msg os dados para enviar
tamanho O comprimento dos dados a enviar
valor de retorno:
O comprimento dos dados enviados é retornado em caso de sucesso e um código de erro é retornado em caso de falha.
Como o comprimento dos dados realmente enviados só pode ser obtido quando a função retornar, precisamos desenvolver dois programas para concluir o seguinte trabalho, respectivamente:
Argumentos de função de log e contexto na entrada da função
Registre o conteúdo real dos dados enviados quando a função retornar
Programa eBPF de entrada de função:
SEC("kprobe/inet_sendmsg")
int BPF_KPROBE(inet_sendmsg_entry, struct socket *sock, struct msghdr *msg)
{
struct probe_ctx pctx = {
.bpf_ctx = ctx,
.version = EVENT_VERSION,
.source = EVENT_SOURCE_SOCKET,
.type = EVENT_SOCK_SENDMSG,
.sr.sock = sock,
};
int err;
// 过滤掉不需要录制的进程
if (pid_filter(&pctx)) {
return 0;
}
// 读取 socket 类型信息
err = read_socket_info(&pctx, &pctx.sr.sockinfo, sock);
if (err) {
tm_err2(&pctx, ERROR_READ_SOCKET_INFO, __LINE__, err);
return 0;
}
// 记录 msg 中的数据信息
err = bpf_probe_read(&pctx.sr.iter, sizeof(pctx.sr.iter), &msg->msg_iter);
if (err) {
tm_err2(&pctx, ERROR_BPF_PROBE_READ, __LINE__, err);
return 0;
}
// 将相关上下文信息保存到 map 中
pctx.id = bpf_ktime_get_ns();
err = save_context(pctx.pid, &pctx);
if (err) {
tm_err2(&pctx, ERROR_SAVE_CONTEXT, __LINE__, err);
}
return 0;
}A função retorna um programa eBPF:
SEC("kretprobe/inet_sendmsg")
int BPF_KRETPROBE(inet_sendmsg_exit, int retval)
{
struct probe_ctx pctx = {
.bpf_ctx = ctx,
.version = EVENT_VERSION,
.source = EVENT_SOURCE_SOCKET,
.type = EVENT_SOCK_SENDMSG,
};
struct sock_send_recv_event event = {};
int err;
// 过滤掉不需要录制的进程
if (pid_filter(&pctx)) {
return 0;
}
// 如果发送失败, 跳过录制数据
if (retval <= 0) {
goto out;
}
// 从 map 中读取提前保存的上下文信息
err = read_context(pctx.pid, &pctx);
if (err) {
tm_err2(&pctx, ERROR_READ_CONTEXT, __LINE__, err);
goto out;
}
// 构造 sendmsg 报文
event.version = pctx.version;
event.source = pctx.source;
event.type = pctx.type;
event.tgid = pctx.tgid;
event.pid = pctx.pid;
event.id = pctx.id;
event.sock = (u64)pctx.sr.s;
event.sock_family = pctx.sr.sockinfo.sock_family;
event.sock_type = pctx.sr.sockinfo.sock_type;
// 从 msg 中读取数据填充到 event 报文, 并通过 map 传递到用户空间
sock_data_output(&pctx, &event, &pctx.sr.iter);
out:
// 清理上下文信息
err = delete_context(pctx.pid);
if (err) {
tm_err2(&pctx, ERROR_DELETE_CONTEXT, __LINE__, err);
}
return 0;
}ficar louco
Para a linguagem Go, precisamos realizar a concatenação de dados de acordo com o id da goroutine ao enviar e receber dados.Como obtê-lo no programa eBPF? Ao analisar o código-fonte de go, descobrimos que o id da goroutine está armazenado em struct g, e o ponteiro g atual pode ser obtido por meio de getg().
função getg:
// getg returns the pointer to the current g.
// The compiler rewrites calls to this function into instructions
// that fetch the g directly (from TLS or from the dedicated register).
func getg() *gDe acordo com o comentário da função, o ponteiro g atual é colocado no armazenamento local do thread (TLS) e o código que chama getg() é reescrito pelo compilador. Para encontrar a implementação de getg(), vemos que getg é chamado na função runtime.newg, desmontamos e descobrimos que o ponteiro de g está armazenado no endereço de memória do registrador fs -8:
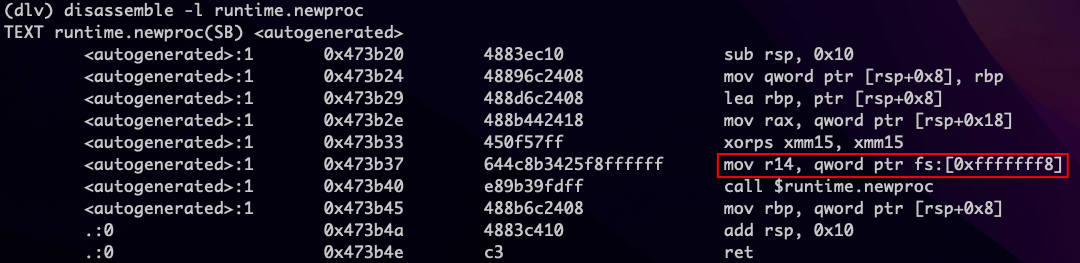
Em seguida, encontramos o campo goid em struct g (localizado em runtime/runtime2.go):
type g struct {
.... 此处省略大量字段
goid int64
.... 此处省略大量字段
}Depois de obter o ponteiro de g, basta adicionar o deslocamento do campo goid para obter o goid. Ao mesmo tempo, considerando que o deslocamento do goid pode ser diferente entre as diferentes versões do go, podemos finalmente obter o goid atual no programa eBPF da seguinte forma:
static __always_inline
u64 get_goid()
{
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
unsigned long fsbase = 0;
void *g = NULL;
u64 goid = 0;
bpf_probe_read(&fsbase, sizeof(fsbase), &task->thread.fsbase);
bpf_probe_read(&g, sizeof(g), (void*)fsbase-8);
bpf_probe_read(&goid, sizeof(goid), (void*)g+GOID_OFFSET);
return goid;
}problemas encontrados
Embora o programa eBPF possa ser desenvolvido em linguagem C, ele é bastante diferente do processo de desenvolvimento de linguagem C comum, que adiciona muitas restrições.
A seguir estão os problemas e soluções mais críticos encontrados durante o desenvolvimento:
Variáveis globais, strings constantes ou arrays não são permitidos e podem ser armazenados em um mapa.
A chamada de função não é suportada, pode ser resolvida por inline inline.
O espaço da pilha não pode exceder 512 bytes, e o mapa do tipo array pode ser usado como buffer, se necessário.
Ele não pode acessar diretamente a memória no modo de usuário e no modo kernel, mas através de funções relacionadas do bpf-helper.
O número de instruções em um único programa não pode exceder 1.000.000. Tente manter a lógica do programa eBPF o mais simples possível e conclua o processamento complexo no programa de modo de usuário.
O ciclo deve ter um limite superior claro para o número de vezes e não pode ser julgado apenas pelo tempo de execução.
Os membros da estrutura devem estar alinhados à memória, caso contrário, alguma memória pode não ser inicializada, fazendo com que o verificador relate um erro.
Depois que o código é otimizado pelo compilador, o verificador pode relatar falsamente o problema de acesso à memória fora dos limites. Você pode adicionar um julgamento if ao código para ajudar o verificador a identificá-lo. Se necessário, pode ser resolvido por montagem em linha .
....
Com a melhoria gradual do clang e o suporte do kernel para ebpf, muitos problemas estão sendo gradualmente resolvidos e a experiência de desenvolvimento subsequente se tornará mais suave.
Mecanismo de Segurança
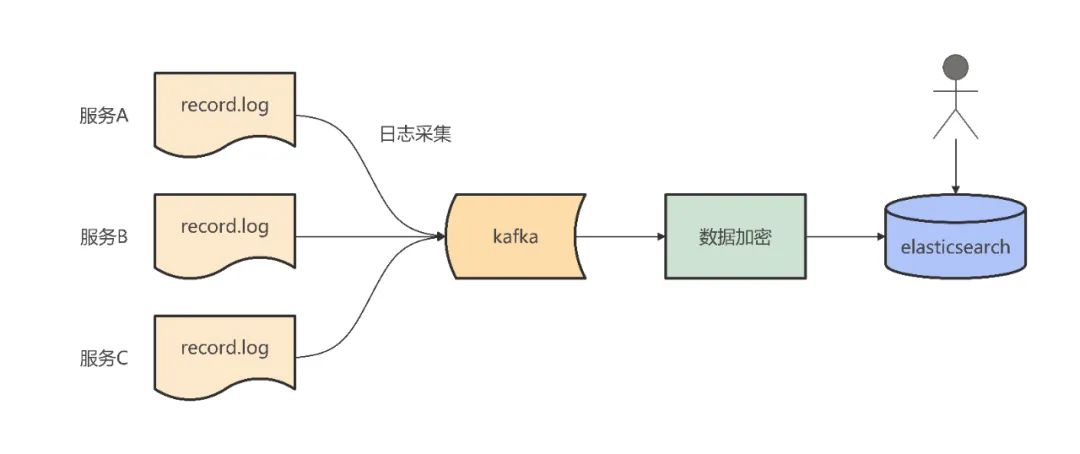
Para garantir a segurança dos dados de tráfego e reduzir o impacto da dessensibilização de dados no desempenho das máquinas online, optamos por criptografar durante a fase de coleta de tráfego:
Resumir
Este artigo apresenta a aplicação do eBPF na direção do registro de tráfego, esperando ajudá-lo a reduzir os custos de implementação e acesso do registro de tráfego e criar rapidamente recursos de reprodução de tráfego. Devido a limitações de espaço, muitos detalhes de gravação de tráfego não podem ser compartilhados. O plano é abrir o código da solução no futuro. Bem-vindo a continuar prestando atenção ao projeto de código aberto Didi. Para obter mais informações sobre os cenários de aplicação do eBPF, os alunos interessados também podem ler " EBPF Kernel Technology in Didi Cloud's Native Landing Practice " para saber mais.
Limitando-se ao nível técnico do autor, inevitavelmente haverá alguns erros e omissões no artigo, você pode deixar uma mensagem na área de comentários para fazer correções, e esperamos mais trocas e discussões no futuro.
FIM
Apresentação do autor e do departamento
O autor deste artigo, Wang Chaofeng, é da equipe de tecnologia de viagem on-line da Didi. Ecologia de fornecimento de capacidade de transporte B-end, ecologia de segurança de viagens e serviços. Governe a ecologia e o sistema de segurança central para criar uma plataforma de viagens que seja segura, confiável, eficiente, conveniente e confiável para o usuário.
Ofertas de trabalho
Estamos recrutando para o back-end da equipe e requisitos de teste. Os parceiros interessados são bem-vindos. Você pode escanear o código QR abaixo e enviar seu currículo diretamente. Aguardamos sua adesão!
Engenheiro de P&D
Descrição do trabalho:
1. Responsável pela pesquisa de fundo e desenvolvimento de sistemas de negócios relacionados, incluindo projeto de arquitetura de negócios, desenvolvimento, controle de complexidade e melhoria do desempenho do sistema e eficiência de pesquisa e desenvolvimento;
2. Com senso comercial, por meio de pesquisa técnica e inovação contínuas, melhora de forma iterativa os dados principais do negócio, juntamente com produtos e operações.

Engenheiro de Desenvolvimento de Testes
Descrição do trabalho:
1. Construir um sistema de garantia de qualidade aplicável ao negócio de transporte de carros on-line, formular e promover a implementação de soluções técnicas de qualidade relevantes e continuar a garantir a qualidade do negócio;
2. Compreensão profunda do negócio, estabelecer comunicação com várias funções no negócio, resumir problemas de negócios e pontos problemáticos, criar valor para o negócio de forma abrangente e trabalhar sem limites fixos;
3. Melhorar a qualidade do código de negócios e a eficiência de entrega aplicando infraestrutura de qualidade relevante;
4. Precipitar soluções de teste eficientes e fornecer soluções generalizadas para apoiar aplicações de desembarque em outras linhas de negócios;
5. Resolver problemas difíceis e problemas técnicos complexos na garantia de qualidade empresarial;
6. Exploração prospectiva no campo da tecnologia de qualidade.
