Desde a popularidade do LLM, tem havido muitos modelos excelentes na comunidade. Claro, sua maior característica é o tamanho grande. Recentemente, a comunidade tem feito muito trabalho para permitir que modelos grandes sejam executados em dispositivos de baixo custo. O gptq realiza a quantização de modelos de baixo bit, reduzindo assim os requisitos para executar modelos grandes na memória da CPU e na memória da GPU. llama. cpp realiza que modelos grandes podem ser executados na CPU/GPU local e as etapas são muito simples. replit-code-v1-3b realiza geração de código mais inteligente com modelos menores. Pode-se ver que a miniaturização e a implantação leve do modelo também são a direção de desenvolvimento de um modelo grande.
Diante disso, a equipe MegEngine desenvolveu o projeto InferLLM com duas finalidades principais:
Forneça uma estrutura de implantação local mais simples e fácil de usar do que llama.cpp para que todos possam aprender e discutir
Possibilita a implantação do modelo LLM localmente ou no final, e pode ser usado em alguns ambientes de produção reais no futuro
Comparado com o projeto llama.cpp, o InferLLM tem uma estrutura mais simples e refatorou alguns componentes comuns para evitar colocar todo o código lógico e o código Kernel em um arquivo e evitar a introdução de muitas macros no Kernel para afetar a leitura e o desenvolvimento do código. llama.cpp é não muito amigável para o aprendizado e desenvolvimento secundário. InferLLM também se baseia principalmente em llama.cpp, como: usando o formato de modelo de llama.cpp e copiando alguns códigos calculados. Ao mesmo tempo, InferLLM o refatorou para tornar o código É mais simples e direto, muito fácil de usar, e o código do framework é separado do código do Kernel.Na verdade, no raciocínio de modelo grande, o Kernel que realmente precisa ser otimizado é bem menor que o Kernel da CNN.
Além disso, o InferLLM também pode ser usado na produção, porque pode executar o modelo quantizado LLM sem problemas em um telefone celular com desempenho médio e pode conduzir o diálogo homem-máquina sem problemas. Atualmente, para executar um modelo llama 7b de 4 bits em um telefone celular , só precisa de cerca de 4G de memória, esta memória é suficiente para a maioria dos telefones móveis agora. Acredito que em um futuro próximo haverá muitos modelos leves entre os modelos grandes, que podem ser implantados e raciocinados diretamente no final. Afinal, os telefones celulares são os recursos de computação mais facilmente disponíveis para todos e não há razão para desperdiçar um cluster de computação tão grande.
O seguinte é o caso da execução do modelo de quantização chinês alpaca 7b 4bit no xiaomi9, Qualcomm SM8150 Snapdragon 855 com 4 threads:
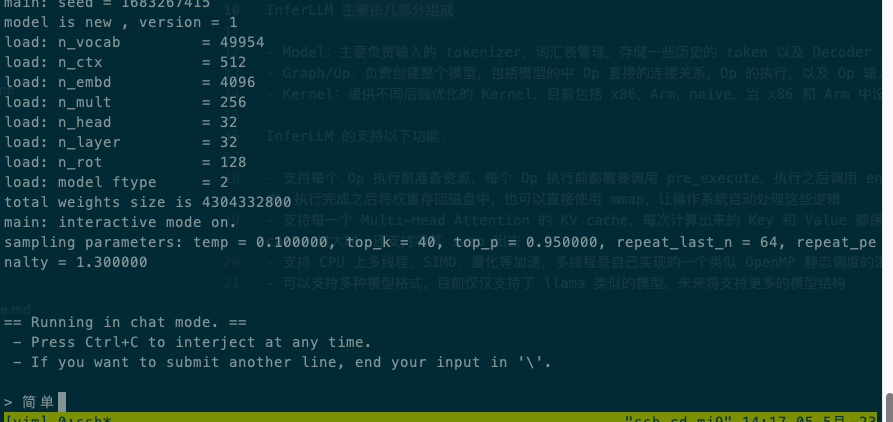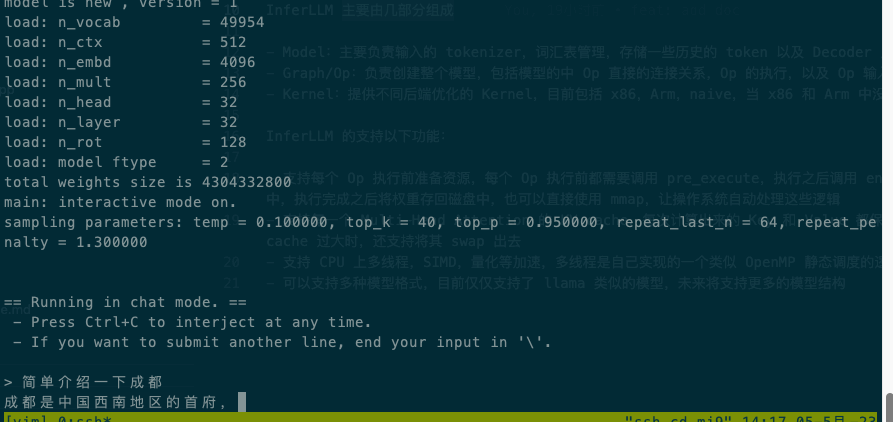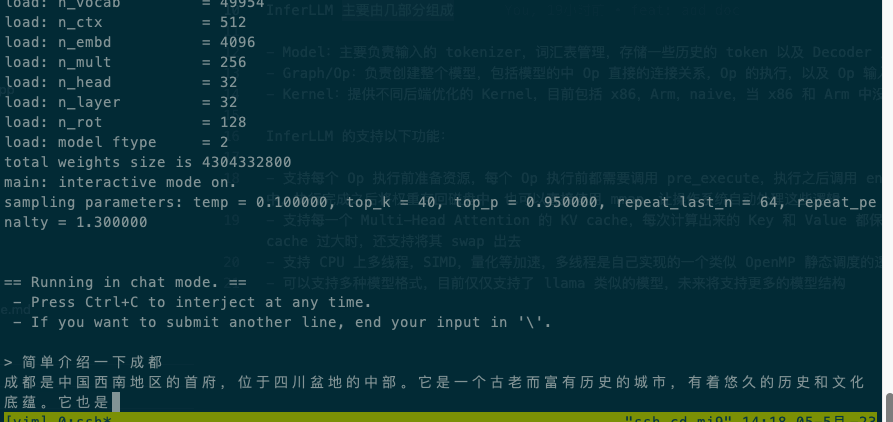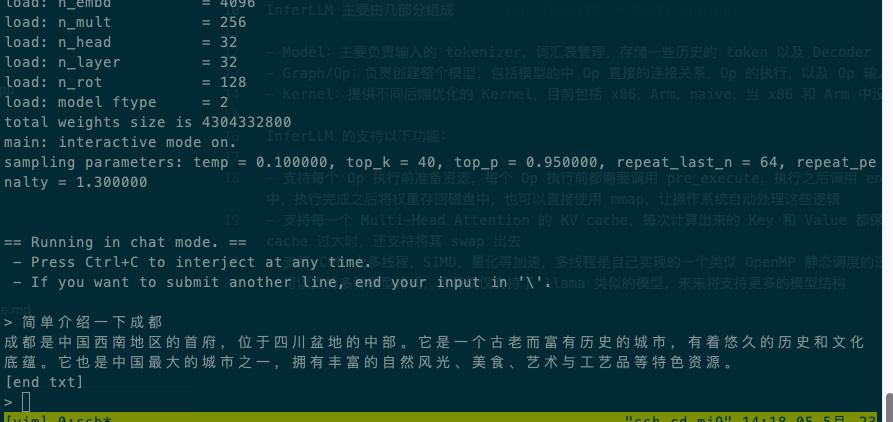
InferLLM consiste principalmente em várias partes:
Modelo: Principalmente responsável pelo tokenizador de entrada, gerenciamento de vocabulário, armazenamento de alguns tokens históricos e amostragem após o decodificador, etc.;
Graph/Op: Responsável pela criação de todo o modelo, incluindo a relação de conexão direta de Op no modelo, a execução de Op e o gerenciamento de recursos de memória como entrada e saída de Op;
Kernel: Forneça diferentes Kernels otimizados de back-end, atualmente incluindo x86, Arm e ingênuo.
InferLLM suporta principalmente as seguintes funções:
Ele suporta a preparação de recursos antes da execução de cada Op. Cada Op precisa chamar pre_execute antes da execução e chamar end_execute após a execução. Dessa forma, é conveniente ler os pesos do meio do disco para a RAM antes da execução no dispositivo com memória insuficiente e salvar os pesos de volta no disco após a conclusão da execução. Você também pode usar o mmap diretamente para permitir o sistema operacional lida automaticamente com essas lógicas;
Suporta cache KV de cada Atenção Multi-Head, cada Chave e Valor calculados são armazenados em KVStorage, KVStorage suporta indexação de id de token, e se o cache KV for muito grande, ele também suporta troca;
Suporta multi-threading na CPU, SIMD, quantização, cálculo float16 e outros métodos de aceleração. Multi-threading é uma lógica semelhante ao escalonamento estático OpenMP implementado por si só, usando um pool de threads livre de bloqueio para sincronizar entre vários threads;
Compatível com uma variedade de formatos de modelo, atualmente suporta apenas modelos semelhantes a lhamas e suportará mais estruturas de modelo no futuro.
Sejam todos bem-vindos para experimentar o InferLLM: https://github.com/MegEngine/InferLLM
Anexo: Para obter mais informações sobre o MegEngine, você pode: visualizar documentos e projetos do GitHub, ou ingressar no grupo QQ de comunicação do usuário do MegEngine: 1029741705. Bem-vindo a contribuir para a comunidade MegEngine, torne-se um Awesome MegEngineer e desfrute de inúmeros certificados de honra e presentes personalizados.
