Bei der tatsächlichen Verwendung möchten wir manchmal den Elasticsearch-Index in einer JSON-Datei speichern. Zuvor habe ich einen Artikel „ Elasticsearch: Index Backup and Recovery “ darüber geschrieben, wie man den Elasticsearch-Index sichert. Heute verwenden wir einen Python-Ansatz, um die Sache weiter zu erforschen. Sie können alle Ereignisse in einem einzelnen Elasticsearch-Index in eine JSON-Datei exportieren. Dieses Skript verwendet die Elasticsearch-Python-API-Aufrufe PIT und search_after, um jeweils 10.000 Ereignisse zu exportieren, und fährt fort, bis alle Ereignisse exportiert sind. Millionen von Ereignissen können aus einem einzigen Elasticsearch-Index exportiert werden. Informationen zum Betrieb der Elasticsearch-Paginierung finden Sie im Artikel „ Elasticsearch: Paging-Suchergebnisse “.
Ich werde die Geschichte unter folgenden Gesichtspunkten erzählen:
- Laden Sie den Elasticsearch Exporter herunter
- Konfigurieren Sie Einstellungen für die Verbindung zu einem Elasticsearch-Cluster
- Testen Sie die Einrichtung, indem Sie einen einzelnen Index exportieren
- Filterexport
- zukünftiges Update
In der folgenden Demonstration werde ich den neuesten Elastic Stack 8.8.2 zur Demonstration verwenden.
Installieren
Wenn Sie kein eigenes Elasticsearch und Kibana installiert haben, lesen Sie bitte die folgenden Links:
-
So installieren Sie Elasticsearch unter Linux, MacOS und Windows
-
Kibana: So installieren Sie Kibana im Elastic-Stack unter Linux, MacOS und Windows
Bei der Installation haben wir uns für die Installation des Elastic Stack 8.x-Installationshandbuchs entschieden. Standardmäßig sind Elasticsearch-Installationen mit https-Zugriff gesichert.
Daten vorbereiten
In der heutigen Übung verwenden wir die mit Kibana gelieferten Daten, um Folgendes zu demonstrieren:
Nachdem wir die oben genannten Aktionen ausgeführt haben, sehen wir in Elasticsearch einen neu erstellten kibana_sample_data_flights-Index.
Exportindex
Um kibana_sample_data_flights exportieren zu können, sind wir in folgende Schritte unterteilt:
Laden Sie den Elasticsearch Exporter herunter
Wir verwenden den folgenden Befehl, um ElasticsearchExporter herunterzuladen
git clone https://github.com/liu-xiao-guo/ElasticsearchExporter
cd ElasticsearchExporter
pip3 install -r requirements.txtKonfigurieren Sie Einstellungen für die Verbindung zu einem Elasticsearch-Cluster
Wir können auf den vorherigen Blog-Beitrag „ Elasticsearch: Alles, was Sie über die Verwendung von Elasticsearch in Python – 8.x wissen müssen “ verweisen, um zu konfigurieren, wie eine Verbindung zum Elasticsearch-Cluster im Python-Client hergestellt wird. Wir müssen ElasticExporterSettings.py ändern .
Wenn Ihr Elasticsearch-Cluster https verwendet, verwenden Sie diesen Befehl, um den Fingerabdruck zu finden und CERT_FINGERPRINT zu aktualisieren.
$ openssl s_client -connect localhost:9200 -servername localhost -showcerts </dev/null 2>/dev/null | while openssl x509 -sha256 -subject -issuer -fingerprint -noout 2>/dev/null; do :; done
subject=CN = liuxgm.local
issuer=CN = Elasticsearch security auto-configuration HTTP CA
sha256 Fingerprint=B8:B3:2F:CD:A4:D4:26:EA:E9:33:87:EA:CB:18:0B:11:68:21:0E:85:25:7C:D6:B4:12:31:9A:8F:2A:B3:BB:13
subject=CN = Elasticsearch security auto-configuration HTTP CA
issuer=CN = Elasticsearch security auto-configuration HTTP CA
sha256 Fingerprint=BD:0A:26:DC:64:6E:F1:CB:3C:B5:E1:32:E7:7D:61:13:E1:B4:6D:56:EE:39:0D:D3:C6:F0:B2:D2:B1:69:62:C4Um einen Fingerabdruck ohne Doppelpunkt zu erhalten, können wir ihn mit dem folgenden Befehl direkt abrufen:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.8.2/config/certs
$ openssl x509 -in http_ca.crt -sha256 -fingerprint | grep sha256 | sed 's/://g'
sha256 Fingerprint=BD0A26DC646EF1CB3CB5E132E77D6113E1B46D56EE390DD3C6F0B2D2B16962C4Der direkteste Weg, einen Fingerabdruck zu erhalten, besteht natürlich darin, die Datei config/kibana.yml zu öffnen:
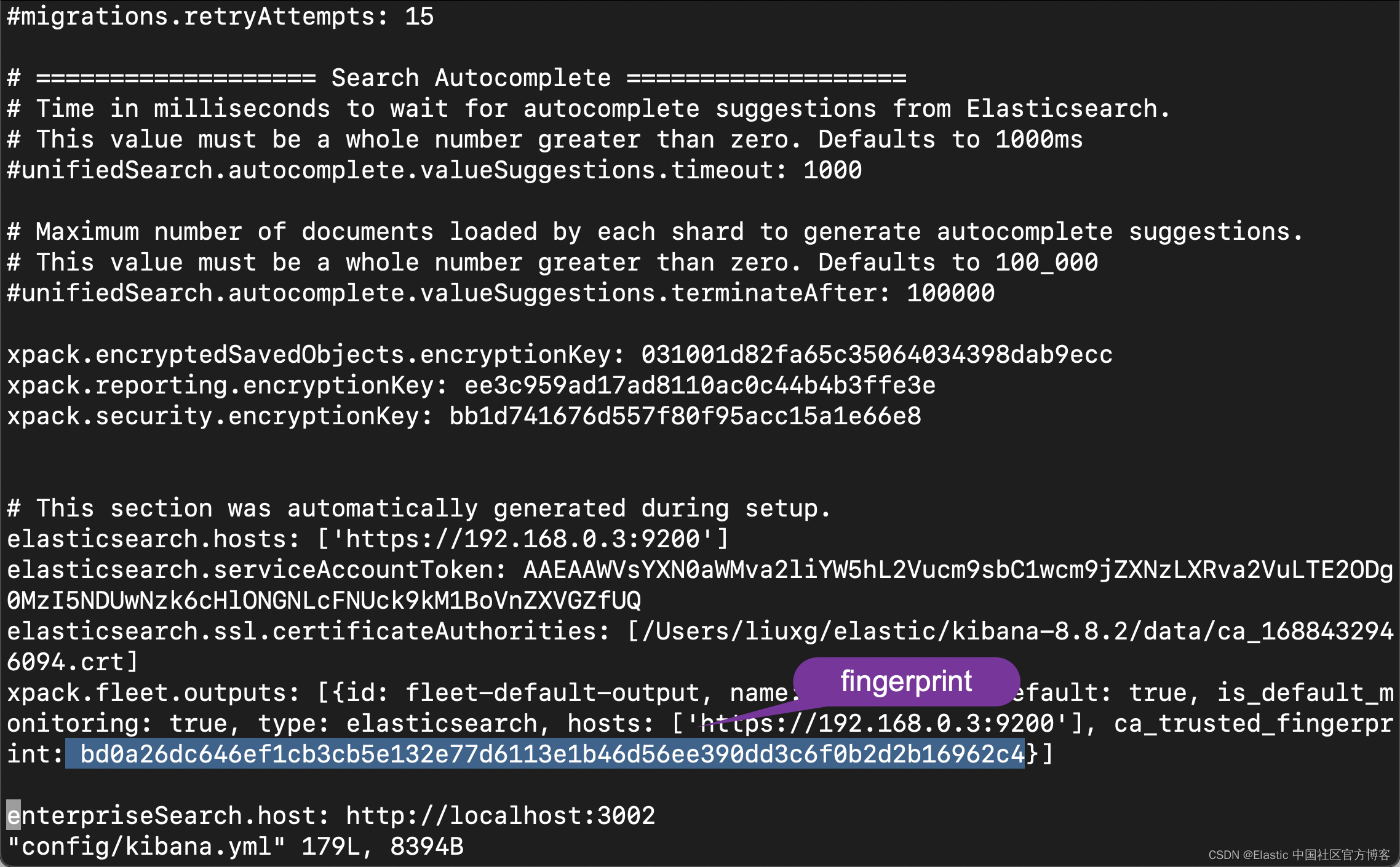
Mit dem Fingerabdruckwert müssen wir auch den elastischen Superuser und sein Passwort ermitteln. Öffnen Sie die Datei ElasticExporterSettings.py:
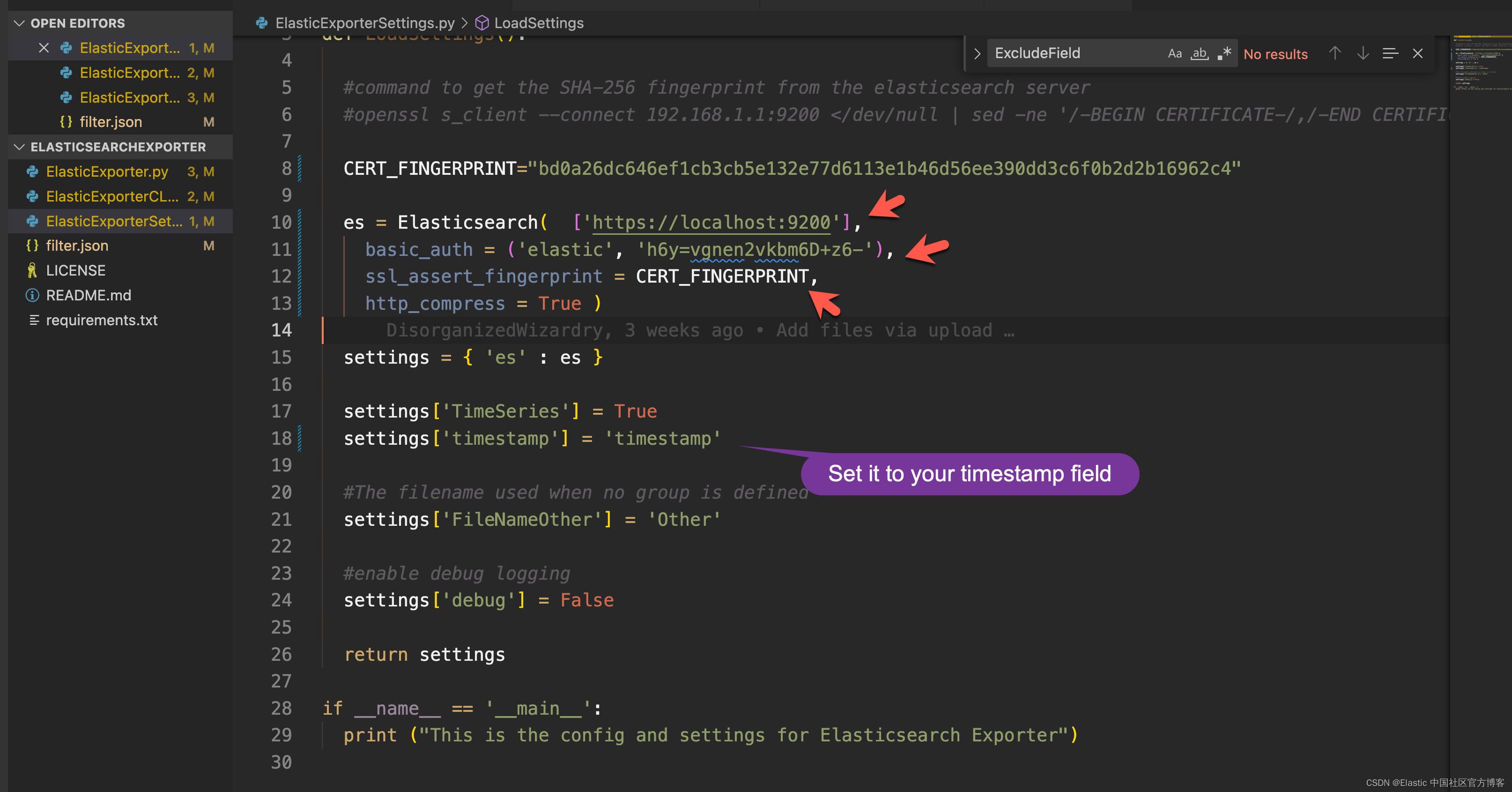
Zusammenfassend müssen Sie drei Teile ändern:
- CERT_FINGERPRINT Ihres Clusters
- Die IP-Adresse jedes Elasticsearch-Servers. Anstelle von IP-Adressen können auch DNS-Namen verwendet werden.
- Benutzername und Passwort
Testen Sie die Einrichtung, indem Sie einen einzelnen Index exportieren
Als Test dafür, dass das Skript richtig konfiguriert ist und eine Verbindung zum Elasticsearch-Cluster herstellen kann, verwende ich diesen Befehl, um alle Dokumente in einen einzigen Index zu exportieren. Wir erstellen zunächst ein Unterverzeichnis namens exported im aktuellen Verzeichnis:
$ pwd
/Users/liuxg/tmp/ElasticsearchExporter
$ mkdir exported
$ ls
ElasticExporter.py LICENSE filter.json
ElasticExporterCLI.py README.md requirements.txt
ElasticExporterSettings.py exportedpython3 ElasticExporterCLI.py --index=kibana_sample_data_flights --backup-folder=exported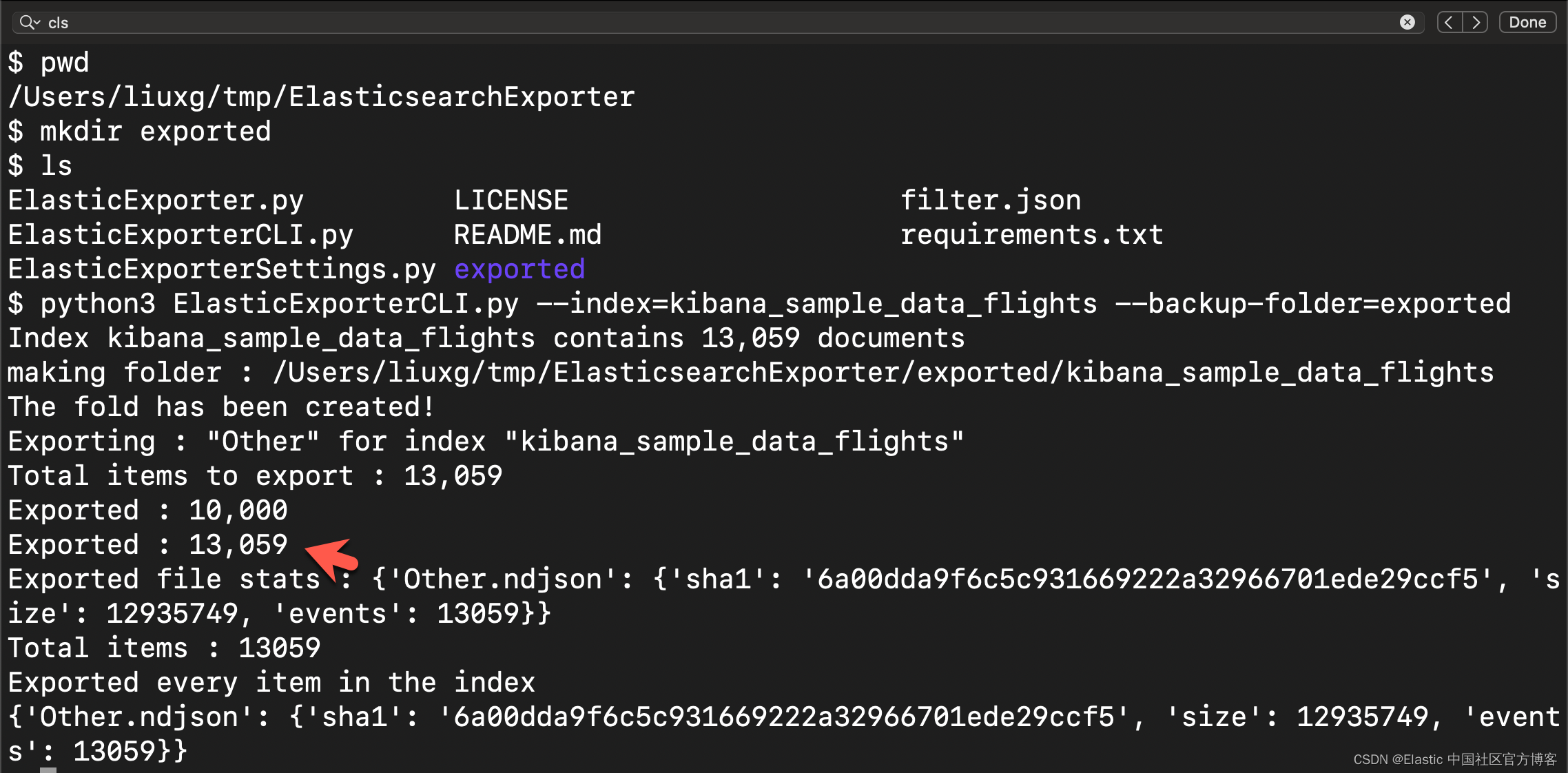
Aus der obigen Ausgabe können wir ersehen, dass 13.059 Dokumente verarbeitet wurden. Wir können das geschriebene JSON-Dokument im aktuell exportierten Verzeichnis anzeigen:

Wir können uns das gesicherte JSON-Dokument ansehen. Die Ausgabedatei wird als durch Zeilenumbrüche getrennte JSON-Datei formatiert. Einige Prüfsummen werden in denselben Ordner geschrieben. Diese Dateien werden verwendet, um den erneuten Export exportierter Indizes zu verhindern.
Filterausgang
Um die exportierten Ereignisse zu filtern, können Sie den Filter mithilfe des Abfragedateiparameters übergeben. Wir finden eine Datei namens filter.json im Stammverzeichnis:
{
"bool": {
"filter": [
{
"range": {
"timestamp": {
"format": "strict_date_optional_time",
"gte": "2023-07-25T04:00:00.000Z",
"lte": "2023-07-28T07:00:00.000Z"
}
}
}
]
}
}Dies ist eine einfache Abfrage zum Filtern nach Zeit. Sie können es entsprechend Ihren Anforderungen ändern. Oben habe ich basierend auf dem Zeitbereich des Index kibana_sample_data_flights konfiguriert.
Wir können die folgende Konfiguration auf der Befehlszeile durchführen:
--query-file=filter.jsonWir gehen wie folgt vor. Zuerst löschen wir die oben generierten Dateien:
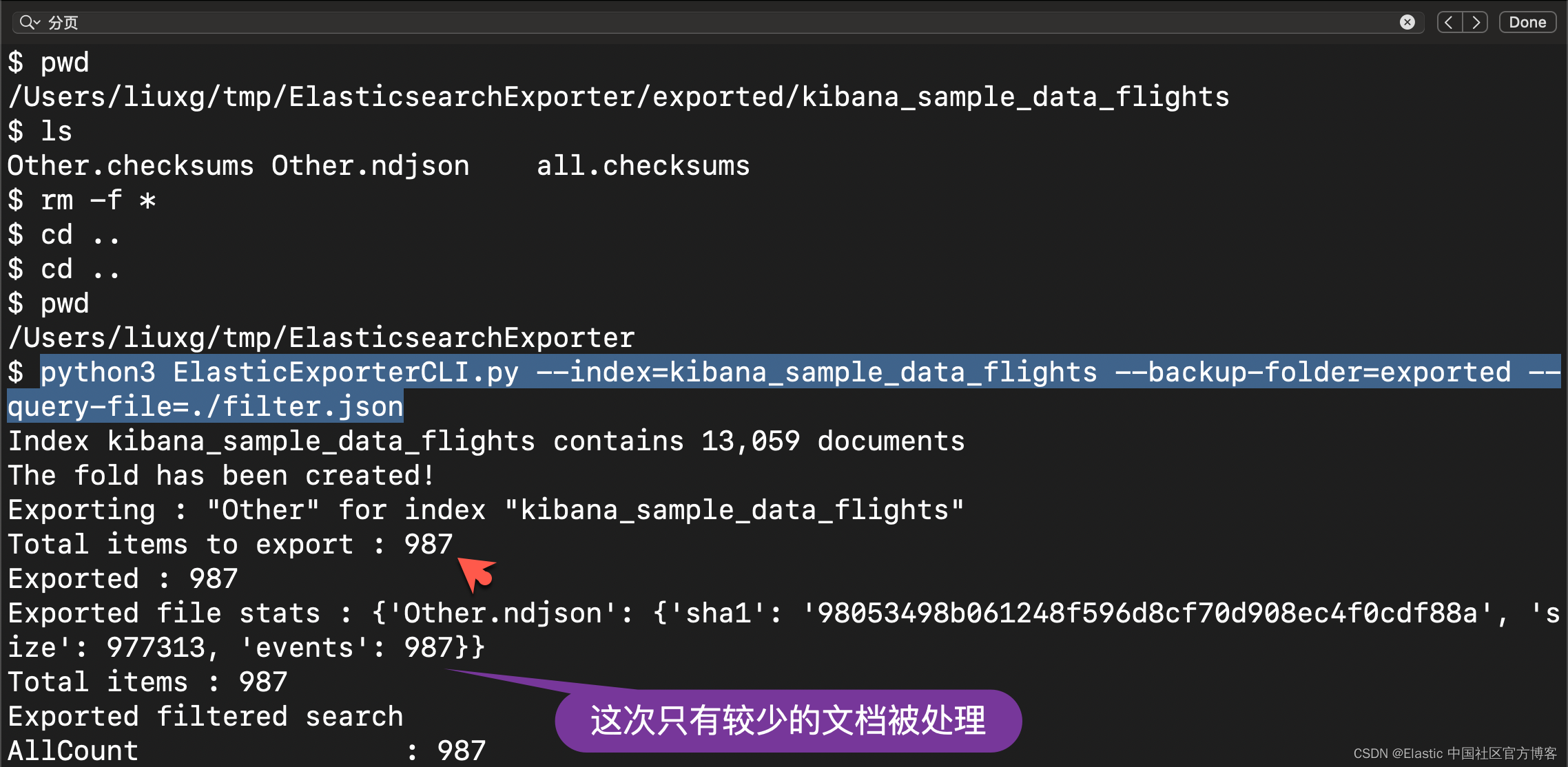
Natürlich können wir diese Suchkonfiguration in Kibana erhalten, zum Beispiel:

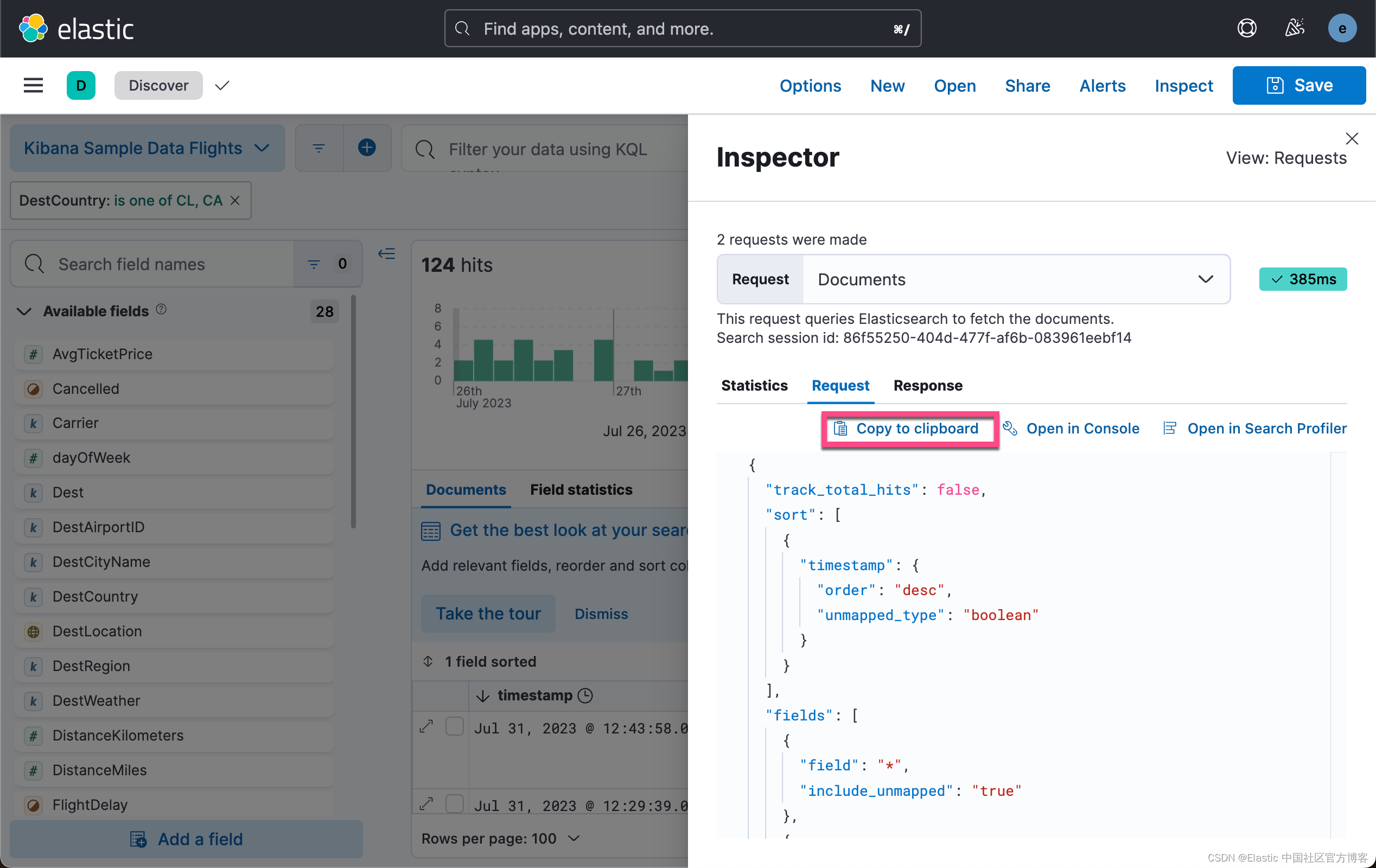
Wir klicken oben auf „In Zwischenablage kopieren“, um die gewünschte Suche auszuwählen:
{
"bool": {
"filter": [
{
"range": {
"timestamp": {
"format": "strict_date_optional_time",
"gte": "2023-07-25T16:52:09.937Z",
"lte": "2023-07-31T05:40:19.805Z"
}
}
},
{
"bool": {
"minimum_should_match": 1,
"should": [
{
"match_phrase": {
"DestCountry": "CL"
}
},
{
"match_phrase": {
"DestCountry": "CA"
}
}
]
}
}
]
}
}Fügen Sie das oben kopierte Ergebnis in die Datei filter.json ein und führen Sie den obigen Vorgang erneut aus:
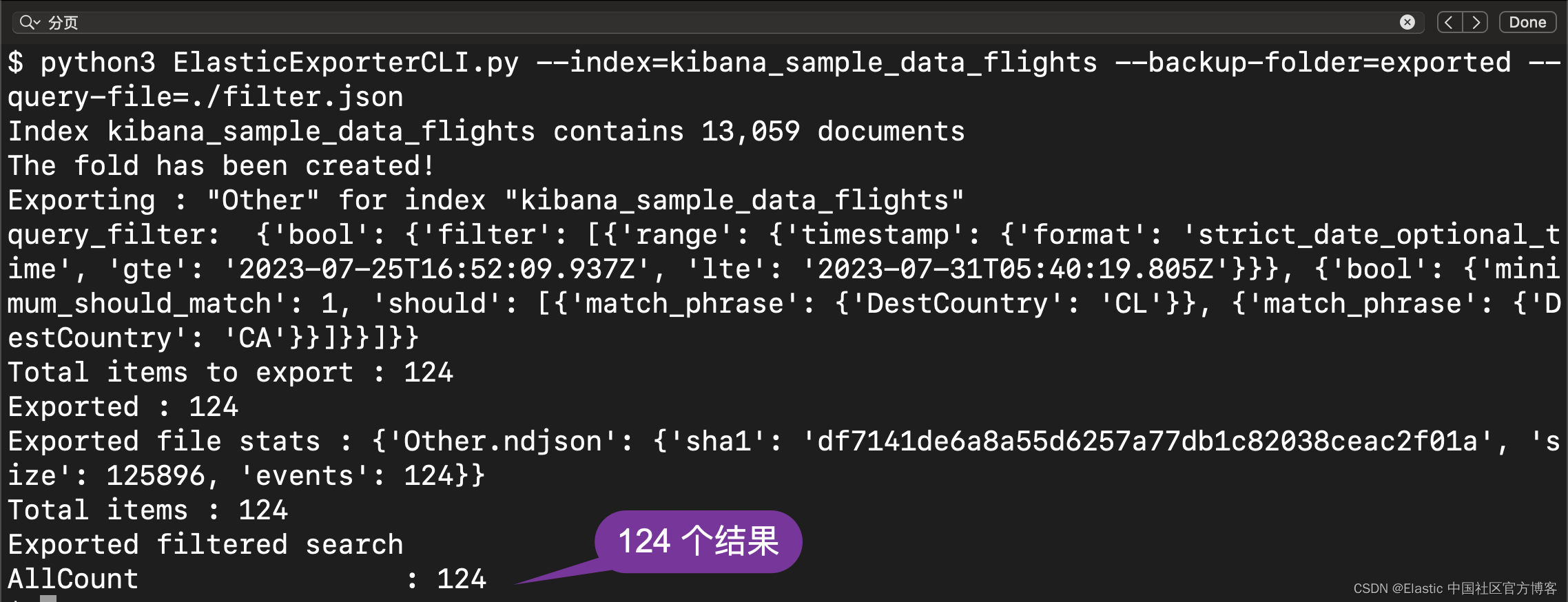
Dies ist das gleiche Ergebnis, das wir oben in Kibana gezeigt haben.
In dem von mir bereitgestellten Beispiel wurde nur eine kleine Datenmenge exportiert. Das Skript ist in der Lage, große Datenmengen zu exportieren. Damit können alle Ereignisse und Indizes in einem Elasticsearch-Cluster exportiert werden, selbst wenn der Cluster Terabytes an Daten und Milliarden von Ereignissen enthält.