Diretório de artigos
prefácio
Anteriormente, apresentamos os métodos e indicadores comuns de avaliação do modelo. Agora vamos treinar o conjunto de dígitos manuscritos, avaliar nosso modelo por meio de diferentes métodos e aumentar ainda mais nossa compreensão dos métodos e indicadores de avaliação do modelo.
1. Carregamento do conjunto de dados
import matplotlib
import pandas as pd
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
#%%
from sklearn.datasets import load_digits
data=load_digits()
print(data.data.shape)

Existem 1797 (8x8) imagens digitais escritas, vamos mostrá-las
plt.gray()
plt.figure(figsize=(8,6))
plt.imshow(data.images[0])
plt.show()

Este pixel da imagem foi processado, mas ainda podemos ver claramente que é 0
2. Divida o conjunto de treinamento e o conjunto de teste, operação de embaralhamento, duas classificações
Aqui listamos a proporção do conjunto de teste para o conjunto de teste como 7:3
from sklearn.model_selection import train_test_split
X,y=data.data,data.target
X_train,y_train,X_test,y_test=train_test_split(X,y,test_size=0.3,random_state=42)
Como o conjunto de dados tem uma certa regularidade de 0 a 9, existe uma correlação entre os dois, então embaralhamos os dados de treinamento
indexs=np.random.permutation(len(X_train))#permutaion的根据给出n长度,生成一个乱的从0到n的数组
X_train,y_train=X_train[indexs],y_train[indexs]
Como o conjunto de dados tem 0 a 9, 10 tipos, vamos integrar os dados em um conjunto de classificação binária, dividido em não 2 números e 2 números
y_train_2=(y_train==2)
y_test_2=(y_test==2)
3. Modelo de treinamento e previsão
Usamos o classificador de gradiente descendente SGDClassifier do modelo linear sklearn
from sklearn.linear_model import SGDClassifier
sgd_clf=SGDClassifier(max_iter=10,random_state=42)
sgd_clf.fit(X_train,y_train_2)
y_prediction=sgd_clf.predict(X[2].reshape(1,-1))
print(y_prediction)

A previsão retorna True, vamos imprimir o número da posição para ver
print(y_prediction)
print(y[2])

Pode-se ver que a previsão foi bem sucedida
4. Avaliação do modelo
1. Validação Cruzada
A validação cruzada é dividir o conjunto de treinamento em várias partes e, em seguida, usar uma parte como conjunto de teste e as outras partes são usadas como conjunto de treinamento para verificar umas às outras até que cada parte seja avaliada como o conjunto de verificação, de modo que o O método pode comparar os conjuntos de dados Menos é mais amigável. A função cross_val_score pode nos ajudar a avaliar melhor o desempenho do modelo no conjunto de dados e escolher o modelo ideal. Ao mesmo tempo, usando a validação cruzada, podemos fazer melhor uso do conjunto de dados limitado e reduzir o overfitting do modelo.
from sklearn.model_selection import cross_val_score
cross_val_scores=cross_val_score(sgd_clf,X_train,y_train_2,cv=3,scoring='accuracy')#切割成3份
print('交叉验证得分 ',cross_val_scores)
print('交叉验证平均分 ',cross_val_scores.mean())
print('交叉验证方差 ',cross_val_scores.std())

Pode-se observar que a pontuação média ainda é bastante alta, indicando que nosso modelo é melhor
Para melhor analisar o desempenho do modelo, podemos usar cross_val_predict, que é uma função no Scikit-learn, que é usada para realizar a validação cruzada e retornar os resultados previstos do modelo.
Especificamente, a função cross_val_predict pode receber um modelo de aprendizado de máquina, dados de treinamento, variáveis de destino e parâmetros de validação cruzada e, em seguida, retornar uma matriz contendo os resultados de previsão de cada validação cruzada. Esses resultados de previsão podem ser usados para avaliar o desempenho do modelo no conjunto de dados e realizar análises e processamentos subsequentes.
Ao contrário da função cross_val_score, a função cross_val_predict retorna o resultado da previsão de cada amostra, não a pontuação de cada validação cruzada. Isso significa que podemos obter informações mais detalhadas sobre o desempenho do modelo e realizar análises e ajustes mais profundos.
from sklearn.model_selection import cross_val_predict
cross_val_predicts=cross_val_predict(sgd_clf,X_train,y_train_2,cv=3)
print('cross_val_predicts: ',cross_val_predicts)

2. Matriz de confusão-matriz de confusão
Os seguintes indicadores foram mencionados no artigo anterior, então não vamos explicar muito
Nós dissemos acimaTP,FP,TN,FNagora vamos pegar
from sklearn.metrics import confusion_matrix
confusion_matrixs=confusion_matrix(y_train_2,cross_val_predicts)
print(confusion_matrixs)

Aqui é simplesmente expresso como
[[TN FN]
[FP TP]]
Explicação: Reconhecemos com êxito 126 dígitos como 2 e reconhecemos erroneamente 4 caracteres diferentes de 2 como 2
2.1 Precisão,rechamada,f1_sorce
from sklearn.metrics import precision_score,recall_score,f1_score
precision_score=precision_score(y_train_2,cross_val_predicts)
recall_score=recall_score(y_train_2,cross_val_predicts)
f1_score=f1_score(y_train_2,cross_val_predicts)
print('精度:',precision_score)
print('召回',recall_score)
print('调和平均数:',f1_score)

2.2 A influência da curva ROC e limiar nos resultados
montamos[5,2,4,3,2,2,2,2]
É o resultado previsto pelo modelo, e da esquerda para a direita está a pontuação da decisão [12, 22, 33, 42, 54, 63, 74, 80]. Quanto maior a pontuação da decisão, maior a taxa correta. tempo, definimos a pontuação limite para 40. Em seguida, ela é dividida em duas partes pelo tamanho da pontuação, e a da esquerda é aquela em que nossa previsão falhouFN, a direita prevê o sucessoTN, por meio das respectivas fórmulas de cálculo afetará nossas pontuações de precisão e recuperação, portanto, a escolha de um limite apropriado pode melhorar efetivamente nossa avaliação de modelo.
Acima sabemos que X[2] é 2, que é True. Verificamos seu valor de pontuação de decisão. O Scikit-Learn não permite definir o limite diretamente, mas pode obter a pontuação de decisão e chamar seu método decision_function().
O Scikit-Learn não permite definir o limite diretamente, mas pode obter a pontuação de decisão,
chamando seu método decision_function()
y_sorce=sgd_clf.decision_function(X[2].reshape(1,-1))
print(y_sorce)

Podemos obter todas as pontuações de decisão ao mesmo tempo
y_sorce=cross_val_predict(sgd_clf,X_train,y_train_2,cv=3,method='decision_function')
print(y_sorce[0:15])

Obtenha todos os seus limites
preciso_recall_curve é uma função no Scikit-learn, que é usada para calcular o valor e o limite da precisão e recuperação do modelo de classificação.
Especificamente, a função precisão_recall_curve pode receber a probabilidade prevista e o rótulo real de um modelo de classificação binária e, em seguida, calcular a precisão e a taxa de rechamada sob uma série de limites, bem como o valor do limite correspondente. Esses valores de precisão, rechamada e limite podem ser usados para desenhar curvas de rechamada de precisão ou para calcular métricas de desempenho, como a precisão média do modelo.
from sklearn.metrics import precision_recall_curve
predictions,recalls,thresholds=precision_recall_curve(y_train_2,y_sorce)

Desenhamos um gráfico de linhas e observamos a situação
sns.set_theme(style="darkgrid")
data_line=pd.DataFrame({
"predictions":predictions[:len(thresholds)],"recalls":recalls[:len(thresholds)],'thresholds':thresholds})
sns.lineplot(x='thresholds',y='predictions',data=data_line)
sns.lineplot(x='thresholds',y='recalls',data=data_line)
# plt.savefig(f'D:\博客文档\模型评估\{random.randint(1,100)}.png')
plt.show()

Perto de 0, a precisão e a taxa de recuperação são as mais altas, e são próximas de 0 e simétricas, e descobrimos que a alteração do limite tem um grande impacto no resultado; portanto, precisamos ser cautelosos ao definir o limite.
- AUC值 (Área sob a curva ROC)
Para obter o limite ideal, também podemos obter o valor AUC , e a função roc_curve usada para desenhar a curva ROC é uma função na biblioteca scikit-learn para desenhar a curva ROC (Receiver Operating Characteristic Curve), que é usada para avaliar desempenho do modelo de classificação binária. A curva ROC mostra a Taxa Positiva Verdadeiratpre taxa de falso positivo (taxa de falso positivo)fprA relação entre pode nos ajudar a escolher o melhor limite para o modelo de classificação.
- Derivamos tpr, fpr, limiar, plotamos observações ROC
from sklearn.metrics import roc_curve
fpr,tpr,thresholds=roc_curve(y_train_2,y_sorce)
line_data=pd.DataFrame({
'fpr':fpr,'tpr':tpr,'thresholds':thresholds})
sns.lineplot(data=line_data,x='fpr',y='tpr',)
sns.lineplot(data=pd.DataFrame({
'x':[0,1],'y':[0,1]}))
plt.show()

A linha tracejada representa a curva ROC para um classificador puramente aleatório; um bom classificador está o mais longe possível dessa linha (no canto superior esquerdo) e fica claro que nosso classificador de modelo é muito bom.
Também podemos calcular nosso valor AUC com roc_auc_score
from sklearn.metrics import roc_auc_score
roc_auc_score=roc_auc_score(y_train_2,y_sorce)
print("AUC值:",roc_auc_score)

Pontuação yyds, eu realmente espero que o valor AUC de todos os meus modelos futuros seja tão alto
- Encontrar o limite ideal geralmente precisa ser determinado combinando os cenários de aplicação reais e os indicadores de desempenho do modelo de classificação.
Um método comumente usado é determinar o limite ideal com base nos pontos de coordenadas na curva ROC. Na curva ROC, podemos encontrar o limite ótimo calculando as coordenadas FPR e TPR correspondentes a cada limite. Normalmente, podemos escolher o limite ideal de acordo com os seguintes indicadores:
-
Maximize TPR: Quando prestamos mais atenção à taxa de recuperação do modelo (ou seja, a taxa de verdadeiro positivo), podemos escolher o limite que maximiza o TPR como o limite ideal.
-
Minimizar FPR: Quando prestamos mais atenção à taxa de precisão do modelo (ou seja, taxa de falsos positivos), podemos escolher o limite que minimiza o FPR como o limite ideal.
-
Maximize AUC: Quando queremos considerar de forma abrangente a precisão e a recuperação do modelo, podemos escolher o limite que maximiza a AUC (Área sob a curva) como o limite ideal.
-
Exemplo Se prestarmos mais atenção à taxa de rechamada do modelo, podemos continuar a usar os valores fpr, tpr, limiares acima.
from sklearn.metrics import roc_curve
fpr,tpr,thresholds=roc_curve(y_train_2,y_sorce)
# 找到最大化 TPR 的阈值
good_threshold = thresholds[np.argmax(tpr)]
print('最优阈值',good_threshold)

Adicione-o ao modelo e calcule a taxa de recall
recall_scores=recall_score(y_train_2,cross_val_predicts)
print('没设置最优阈值recall_sorce:',recall_scores)
y_pred=(cross_val_predicts>good_threshold)
recall_score=recall_score(y_train_2,y_pred)
print('设置最优阈值后recall_sorce:',recall_scores)
O resultado é bastante embaraçoso. Podemos ver na figura acima que nosso modelo de classificação ainda é muito bom, então não pode ser otimizado, talvez, talvez.
Em seguida, execute-o novamente e ainda funcionará.


- Ou usamos o método mais antigo, cada limite é testado novamente
from sklearn.metrics import recall_score
for threshold in thresholds:
b_recall_scoress = recall_score(y_train_2, cross_val_predicts)
y_pred = (cross_val_predicts > threshold)
e_recall_score = recall_score(y_train_2, y_pred)
max_good_threshold.append(threshold)
beging_recalls.append(b_recall_scoress)
end_recalss.append(e_recall_score)
end_good_recalls_index=np.argmax(end_recalss)
b_recalss=beging_recalls[end_good_recalls_index]
e_threshold=max_good_threshold[end_good_recalls_index]
e_reclass=end_recalss[end_good_recalls_index]
print('最优阈值',e_threshold)
print('优化前',b_recalss)
print('优化后',e_reclass)
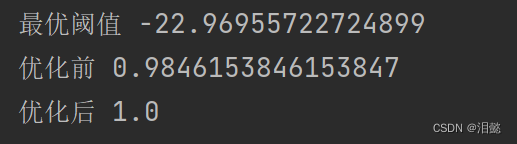
Após a otimização do limite, o recall ainda é significativamente melhorado
V. Resumo
Nesta seção, explicamos vários métodos de avaliação do modelo e obtemos o limite ideal em detalhes, o que nos ajudará a avaliar e otimizar melhor o modelo.
Espero que você me apoie muito, vou trabalhar mais para aprender e compartilhar coisas mais interessantes