prefácio
Antes de estudar este capítulo, certifique-se de fazer os seguintes preparativos:
1. Instale e inicie o Zookeeper [ site oficial ] , se precisar de ajuda, clique para entrar ;
2. Instalei e iniciei o Kafka [ site oficial ] , se precisar de ajuda, clique para entrar .
Nota: A instalação e introdução do zk e kafka, este artigo não se concentra na introdução, consulte o link acima para obter detalhes.
_ _ _
1. Preparação
1.1. Crie um novo projeto da Web Spring Boot 2.x
1.1.1. Demonstração das etapas de criação do projeto
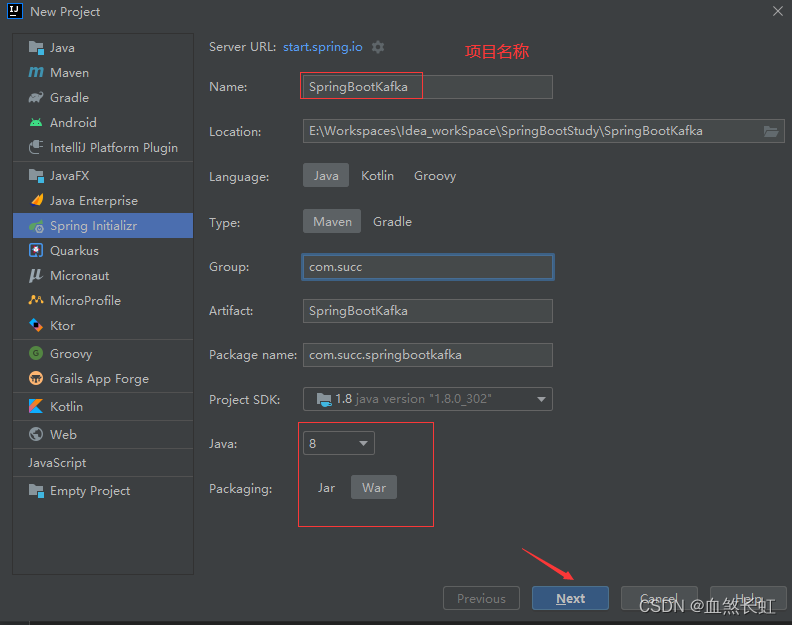 Certifique-se de verificar as opções abaixo!
Certifique-se de verificar as opções abaixo!

1.1.2. Exibição do catálogo de projetos
Observação: depois que o projeto for criado com êxito, primeiro crie o pacote e os arquivos java para preparar o caminho para o seguinte trabalho de gravação de código.

1.2, pom.xml adiciona dependências relacionadas ao spring-kafka
Nota: Existem três dependências principais adicionadas a ele, ou seja, o sistema foi configurado automaticamente, dependências principais do kafka + dependências de teste e outras dependências auxiliares relacionadas (por exemplo: lombok).
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.succ</groupId>
<artifactId>SpringBootKafaka</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>SpringBootKafaka</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<!-- 阿里巴巴 fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
1.3. No arquivo application.yml , adicione a configuração relacionada ao kafka
spring:
kafka:
# 指定 kafka 地址,我这里部署在的虚拟机,开发环境是Windows,kafkahost是虚拟机的地址, 若外网地址,注意修改为外网的IP( 集群部署需用逗号分隔)
bootstrap-servers: kafkahost:9092
consumer:
# 指定 group_id
group-id: group_id
auto-offset-reset: earliest
# 指定消息key和消息体的序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# 指定消息key和消息体的序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringSerializer
value-deserializer: org.apache.kafka.common.serialization.StringSerializer
Observação: o alias kafkahost precisa ser configurado separadamente . Se precisar de ajuda , clique para entrar ; claro, você também pode escrever diretamente o endereço IP da máquina virtual aqui (porque o ambiente de desenvolvimento é Windows e o kafka é implantado no máquina virtual, então você não pode escrever localhost aqui (equivalente a 127.0 .0.1) , caso contrário, o acesso é o localhost do windows e o kafka da máquina virtual não pode ser acessado).
auto.offset.reset possui 3 valores que podem ser configurados:
mais cedo: quando houver um deslocamento enviado em cada partição, inicie o consumo a partir do deslocamento enviado; quando não houver deslocamento enviado, inicie o consumo desde o início;
mais recente: quando houver um deslocamento enviado em cada partição, comece a consumir o deslocamento enviado; quando não houver deslocamento enviado, consuma os dados recém-gerados na partição;
nenhum: Quando houver um deslocamento enviado em cada partição do tópico, o consumo será iniciado após o deslocamento; desde que haja uma partição sem um deslocamento enviado, uma exceção será lançada;
Por padrão, é recomendável usar o mais cedo . Depois de definir esse parâmetro, o Kafka é reiniciado após a ocorrência de um erro. Se você encontrar deslocamentos não consumidos, poderá continuar consumindo.A configuração mais recente é fácil de perder mensagens . Se houver um problema com o kafka e ainda houver dados gravados no tópico, reinicie o kafka neste momento, essa configuração iniciará o consumo a partir do deslocamento mais recente e aqueles que tiverem problemas no meio será ignorado.
Observação: para obter informações de configuração mais detalhadas, consulte a extensão na parte inferior
2. Escrita de código
2.1, Ordem (ordem) Codificação Entity Bean
package model;
import lombok.*;
import java.time.LocalDateTime;
/**
* @create 2022-10-08 1:25
* @describe 订单类javaBean实体
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class Order {
/**
* 订单id
*/
private long orderId;
/**
* 订单号
*/
private String orderNum;
/**
* 订单创建时间
*/
private LocalDateTime createTime;
}
2.2. Escrita de KafkaProvider (provedor de mensagens)
package com.succ.springbootkafaka.provider;
import com.alibaba.fastjson.JSONObject;
import com.succ.springbootkafaka1.model.Order;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;
import java.time.LocalDateTime;
/**
* @create 2022-10-14 21:39
* @describe 话题的创建类,使用它向kafka中创建一个关于Order的订单主题
*/
@Component
@Slf4j
public class KafkaProvider {
/**
* 消息 TOPIC
*/
private static final String TOPIC = "shopping";
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(long orderId, String orderNum, LocalDateTime createTime) {
// 构建一个订单类
Order order = Order.builder()
.orderId(orderId)
.orderNum(orderNum)
.createTime(createTime)
.build();
// 发送消息,订单类的 json 作为消息体
ListenableFuture<SendResult<String, String>> future =
kafkaTemplate.send(TOPIC, JSONObject.toJSONString(order));
// 监听回调
future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.info("## Send message fail ...");
}
@Override
public void onSuccess(SendResult<String, String> result) {
log.info("## Send message success ...");
}
});
}
}
2.3, escrita de código KafkaConsumer (consumidor)
package consumer;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* @create 2022-10-08 1:25
* @describe 通过指定的话题和分组来消费对应的话题
*/
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = "shopping", groupId = "group_id") //这个groupId是在yml中配置的
public void consumer(String message) {
log.info("## consumer message: {}", message);
}
}
3. Teste de unidade
3.1. Preparações
3.1.1. Veja o status de inicialização do Zookeeper
Use o comando cd para entrar no diretório de instalação do zk
Inicie a instância de nó único zk por meio do script de inicialização zookeeper-server-start.sh no diretório bin :
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
Como a configuração básica desta máquina virtual zk está em vigor, ela pode ser iniciada diretamente ( se precisar de ajuda com a instalação do zk , clique para entrar )
#zkServer.sh status 查看服务状态
#zkServer.sh start 启动zk
#zkServer.sh stop 停掉zk
#zkServer.sh restart 重启zk

Conforme mostrado na figura acima, o modo de inicialização do zk é o modo singleton autônomo (sem cluster) e foi iniciado.
3.1.2, inicie o kafka
Use o comando cd para entrar no diretório bin no diretório de instalação do kafka
Entre no diretório de descompactação e inicie o Kafka em segundo plano por meio do script kafka-server-start.sh no diretório bin :
pwd
./kafka-server-start.sh ../config/server.properties

Inicie normalmente, conforme a figura abaixo:

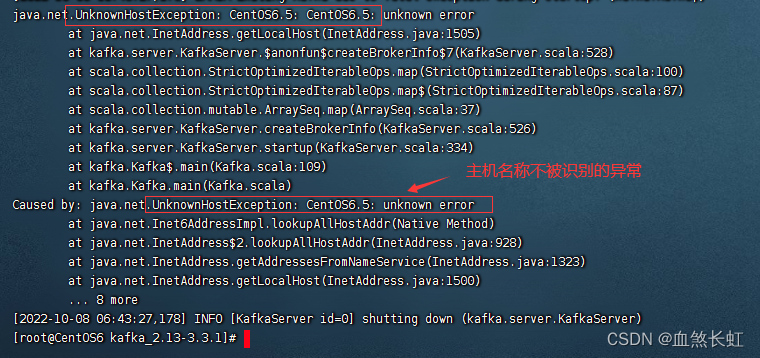
Lembrete: A solução para o problema de que o erro de inicialização do Kafka não reconhece o nome do host, clique para entrar .
java.net.UnknownHostException|erro desconhecido em java.net.Inet6AddressImpl.lookupAllHost
3.1.3. Três maneiras de visualizar o status de inicialização do kafka
jps -ml #方式一,通过jps命令查看(尾部的-ml为非必须参数)
netstat -nalpt | grep 9092 #方式二,通过查看端口号查看 lsof -i:9092 #方式三3.2, escrita de código de teste de unidade
package com.succ.springbootkafaka;
import com.succ.springbootkafaka.provider.KafkaProvider;
import org.junit.jupiter.api.Test;//注意,这个junit用自带的就可以
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.time.LocalDateTime;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class SpringBootKafakaApplicationTests {
@Autowired
private KafkaProvider kafkaProvider;
@Test
public void sendMessage() throws InterruptedException {
//如果这里打印为null,要么是zk或kafka没正常启动,此时进入linux分别查看他们状态接口,另外也需要排查一下你的yum文件配置的kafka的地址,最后排查自己的注解是否引入错误的package
System.out.println("是否为空??+"+kafkaProvider);
// 发送 1000 个消息
for (int i = 0; i < 1000; i++) {
long orderId = i+1;
String orderNum = UUID.randomUUID().toString();
kafkaProvider.sendMessage(orderId, orderNum, LocalDateTime.now());
}
TimeUnit.MINUTES.sleep(1);
}
}
3.3. Teste
3.3.1. Envie 1000 mensagens para ver se as mensagens podem ser publicadas e consumidas normalmente
O registro do console é o seguinte:

3.3.2. Verifique a lista de tópicos do Kafka para ver se o tópico "shopping" é criado normalmente
Execute o script kafka-topics.sh para visualizar a lista de tópicos no diretório bin :
Observação: se a versão do kafka for superior a 2.2+=, use o seguinte comando para visualizar
bin/kafka-topics.sh --list --bootstrap-server kafkahost:9092

Como mostrado na figura acima, você pode ver o tema de compras que acabou de criar
Observação: se sua versão kafka for inferior a 2.2-, use o seguinte comando para visualizar
bin/kafka-topics.sh --list --zookeeper kafkahost:2181O kafkahost acima é configurado no vim /etc/host , e o IP é obtido através do comando ifconfig

Até agora, o teste é bem sucedido!
4. Por que iniciar zk primeiro e depois iniciar kafka
Como a operação do kafka depende da inicialização do zk.
Especificamente, você pode entrar no diretório /conf/ do diretório de descompressão kafka
cd /usr/src/kafka_2.13-3.3.1/config/ && ls
vi server.properties


Para mais tutoriais kafka , clique para entrar
5. Trabalho de acabamento
1. Feche o Zookeeper
zkServer.sh status
zkServer.sh stop
zkServer.sh status 
2. Fechar kafka
cd /usr/src/kafka_2.13-3.3.1/ && ls
jps
bin/kafka-server-stop.sh
jps 
Obs: Se você estiver instalando e usando o kafka pela primeira vez, o comando shutdown não surtirá efeito, você precisa entrar no arquivo de configuração do kafka para fazer algumas alterações na configuração, conforme abaixo:
vim bin/kafka-server-stop.sh Encontre o código na figura abaixo e modifique-o

#PIDS=$(ps ax | grep ' kafka\.Kafka ' | grep java | grep -v grep | awk '{print $1}') PIDS=$(jps -lm | grep -i 'kafka.Kafka' |
awk '{imprimir $1}')
A função do comando modificado: use o comando jps -lm para listar todos os processos java e, em seguida, use o pipeline para filtrar o processo kafka com grep -i 'kafka.

Resumir
Através de um pequeno caso, este artigo apresenta inicialmente a integração do Spring Boot ao Kafka, e conclui a chamada dos produtores (criando tópicos para o Kafka) e consumidores (consumindo informações) do Spring Boot para completar as chamadas ao Kafka.
Claro, o uso de kafka é muito mais do que isso, e introduções cada vez mais aprofundadas serão introduzidas em diferentes páginas posteriormente.
Epílogo
Siga o caminho percorrido pelos antecessores e pise no fosso para os retardatários.
No processo de integração, é inevitável encontrar solavancos e solavancos.Felizmente, estou caminhando com você e algumas armadilhas encontradas nele estão basicamente marcadas.
Se você acha que o artigo não é ruim, seja bem-vindo para curtir e colecionar!
expandir
Configuração mais detalhada sobre arquivos yum
spring:
kafka:
bootstrap-servers: 172.101.203.33:9092
producer:
# 发生错误后,消息重发的次数。
retries: 0
#当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。
batch-size: 16384
# 设置生产者内存缓冲区的大小。
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
# acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。
# acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
acks: 1
consumer:
# 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
auto-commit-interval: 1S
# 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
# latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录)
# earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录
auto-offset-reset: earliest
# 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
enable-auto-commit: false
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 在侦听器容器中运行的线程数。
concurrency: 5
#listner负责ack,每调用一次,就立即commit
ack-mode: manual_immediate
missing-topics-fatal: false
notas
2. Coleção Kafka (1): introdução e instalação de Kafka, resumida em detalhes